







【译者水平有限,如有不恰之处请以原文为准】
摘要
在本文中,我们提出使用序列到序列模型进行命名实体识别(NER),并探索了这种模型在渐进式NER设置(迁移学习(TL)设置)中的有效性。我们在源数据上训练一个初始模型,并将其转换为一个模型,该模型可以在源数据不再可用时在后续步骤中识别目标数据中的新NE类别。我们的解决方案包括:(i)重塑和重新参数化第一个学习模型的输出层,以识别新的NE;(ii)保持架构的其余部分不变,以便用从初始模型传输的参数对其进行初始化;以及(iii)根据目标数据对网络进行微调。最重要的是,我们设计了一种基于序列到序列(Seq2Seq)模型的新NER方法,它可以在我们的渐进式设置中直观地更好地工作。我们将我们的方法与双向LSTM进行了比较,后者是一种强神经NER模型。我们的实验表明,Seq2Seq模型在标准NER设置下表现良好,在渐进设置下更稳健。我们的方法可以识别以前看不见的NE类别,同时保留所见数据的知识。
1.引言
标准NER模型在具有相同NE标签集的数据上进行训练和测试。在本文中,我们探索了一种渐进式设置,其中(i)在初始步骤中,模型在具有某些NE类别的数据集DS上训练;以及(ii)在后续步骤中,我们在包含DS中所有类别以及新类别的数据集DT上进一步训练模型,而不使用DS中的示例,因为我们假设它们不再可用。我们的目标是学习在DT中识别新的NE类别,同时保留以前看到的类别的知识。
本研究的动机是NER模型在行业场景中的应用,不同的公司可能旨在识别文本中不同类型的NE。例如,对金融感兴趣的用户可能会瞄准公司或银行等实体,而对政治感兴趣的其他用户则会瞄准参议员、法案、部委等实体。然而,大多数用户都希望识别某些类型的常见NE类别,如位置或日期。这些常见的NE通常会提供更多可用的标记数据。因此,在新领域中利用这些数据的方法非常有用。此外,仅使用基于此类数据训练的模型的可能性非常重要,因为它避免了NER设计者将大多数训练数据交付给用户以适应新领域。上面的设置描述了一个TL问题,其中域保持不变,但任务的输出空间发生了变化:我们的渐进任务的图形说明如图1所示。
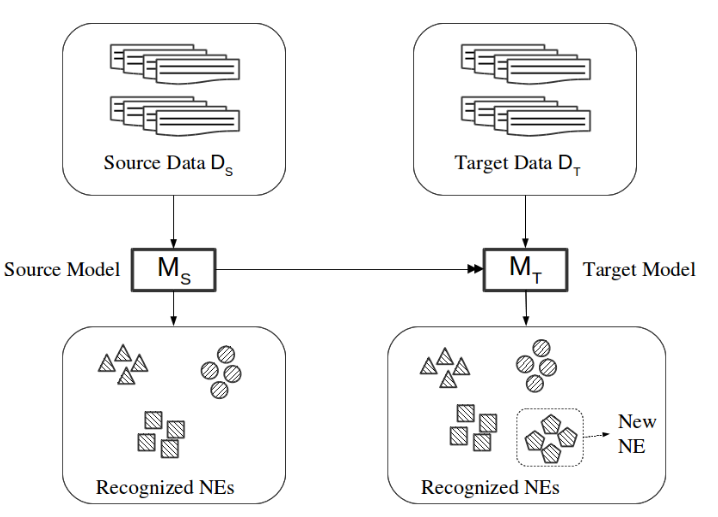
图1:渐进NER任务设置。
由于NER的当前最新技术水平是由神经模型提供的(Lample等人,2016年; Chiu和Nichols,2016年),我们关注他们。特别是,我们使用双向LSTM(BLSTM)实现基线模型,因为它有效,并且不需要对任务进行繁重的特征工程。与许多其他更复杂的最新模型相比,BLSTM实现了有竞争力的性能,而且复杂得多。这种模型的缺点是,尽管它的预测将输入单词的上下文考虑在内了,但是它没有显式地建模标签序列的依赖性。为了更好地捕获这些依赖关系,我们建议对NER使用Seq2Seq模型。
我们推测Seq2Seq模型适合我们的NER任务,原因如下:(i)它们可用于从源语言(词序列)翻译为目标语言(标签序列);(ii)在解码器端,当前预测能够通过将先前的输出与当前输入一起输入来考虑先前的预测。这是构建NER的重要属性,因为输出序列之间有一些依赖性假设(例如,B-SYS后面不能是I-PER)。直观地,Seq2Seq模型可以将从输入到输出的映射分为两个步骤:将从输入到中间隐藏空间的信息编码,并将中间信息解码到输出空间。当输出空间发生变化时,正如我们的实验中那样,模型应该更好地利用之前学到的知识的使用,因为输入的编码仍然与之前的任务相似。
我们的任务解决方案包括:(i)通过添加新NE类别的神经元来修改模型的输出层;(ii)将在数据DS上训练的源模型中的参数传输到在数据DT上训练的目标模型;以及(iii)在目标数据上微调获得的网络。对于提出的Seq2Seq模型,我们仅在解码器端修改输出层。我们对渐进NER进行了广泛的实验,分析了两种模型的性能。我们的主要贡献是双重的,我们表明Seq2Seq模型:(i)对于NER任务有效,以及(ii)在渐进NER环境中更稳健,因为它不会忘记之前学到的有关所见NE类别的知识。
2.相关工作
在本节中,我们报告了标准NER任务当前最新模型的相关工作,以及迁移学习和渐进学习领域的相关工作。
2.1 NER的神经模型
NER的早期工作重点是为该任务设计有用的语言特征(Chieu和Ng,2003年; Carreras等人,2003年; Florian等人,2003年)。深度学习的最新进展带来了新方法,并为任务带来了更高的性能。标准NER上的当前最先进模型主要是神经模型,特别是循环神经网络。这些模型结合了单词(有时也包括字符)级嵌入和/或用于识别NE的额外形态单词特征。示例包括Lample等人(2016)提出的BLSTM(双向LSTM)模型上的CRF(条件随机场)以及Chiu和Nichols(2016)提出的具有卷积字符特征提取器的BLSTM。我们实施BLSTM作为渐进NER的基线模型,因为它是一个有效的模型,不需要对任务进行繁重的特征工程。BLSTM模型的性能在不同的作品中得到了报道(Lample等人,2016; Chiu和Nichols,2016):这也使我们更容易与其他作品进行全面比较。
2.2 Seq2Seq 模型
尽管Seq2Seq模型以前没有用于NER任务,但在各种应用中取得了巨大成功,例如(BahDanau等人,2014年; Luong等人,2015年)、语音识别(Lu等人,2016年;张等人,2017年),提问解答(Yin等人,2016年; Zhou等人,2015)等。Seq2Seq模型的思想是由编码器将变长源序列映射到固定长度的向量表示,然后由解码器将其重新映射回变长目标序列。Seq2Seq模型由Cho等人(2014年)提出,用于学习用于统计机器翻译的短语表示。他们报告了日志线性模型性能的经验改进,同时将Seq2Seq模型计算的短语对的条件概率作为额外特征。Sutskever等人(2014)还提出了一种更通用的端到端方法,以学习将一种语言的源句子映射到另一种语言的翻译句子。
为了缓解映射到固定长度的向量造成的瓶颈,BahDanau等人(2014)提出了注意力机制。注意力机制充当源序列和目标序列中相关部分的软对齐。它是通过将预测调节在上下文向量上来实现的,该上下文向量是由编码器隐藏状态的加权和计算的。Luong等人(2015)进一步提出了全局关注和局部关注,以探索不同关注机制的有效性。我们提出的NER模型与BahDanau等人(2014)提出的Seq2Seq架构相同,只是我们将LSTM单元用于编码器和解码器,而不是简单的RNN单元。我们还在输入词序列和输出标签序列之间强制执行显式对齐,因为源序列和目标序列在NER任务中具有一对一的映射。
2.3迁移学习和渐进学习
大多数机器学习方法假设用于训练和测试的数据具有相同的特征空间和分布。TF(迁移学习)是一种为了放宽这一假设而出现的技术,允许将以前学到的知识用于新任务或新领域(Pan和Yang,2010)。基于神经网络的TL已被证明对于图像识别非常有效(Donahue等人,2014年; Razavian等人,2014年)。至于NLP,Mou等人(2016)表明TL也可以成功应用于语义等效的NLP任务。TL也应用于NER,以将NER数据集中的模型和特征与不同NE实体传输(Qu等人,2016年; Kim等人,2015年)。
3.问题表述
在标准NER任务中,模型学会最大化条件概率P(Y| X)其中X = x1,x2,...,xn(xi ∈ X )是输入词序列,Y = y1,y2,...,yn(yi ∈ Y)是输出标签序列。X和Y分别表示输入和输出空间。在我们的设置中,在初始步骤中,NER系统在源数据集DS上进行训练,DS具有C 个NE类。然后,在随后的步骤中,模型仅用目标数据集DT来呈现,该目标数据集DT包含用来自初始步骤的NE类和E个新类注释的新示例。初始模型需要进行调整,以便能够识别新的E类。
4.模型
我们实现了(1)BLSTM模型,和(2)用于渐进NER的基于注意力的Seq2Seq模型。预计两个模型的输入和输出表示相同。
4.1单词和字符嵌入
输入序列中的单词由其单词级和字符级嵌入来表示。对于单词级表示,我们使用预训练的词嵌入来初始化嵌入查找表,以将输入词x(由整数索引表示)映射到向量w。
通常使用字符级表示,因为NER任务对单词的形态特征(例如大写)敏感。它们被证明为NER提供了有用的信息(Lample等人,2016年)。我们使用随机初始化的字符嵌入查找表,然后将嵌入传递给字符级BLSTM(详细信息在4.2中描述)以获得x的字符级嵌入e。
输入序列中第t个单词文本的完整表示是其单词级嵌入wt和字符级嵌入et的连接。
4.2双向LSTM
BLSTM模型由正向LSTM和反向LSTM组成,它以左向右和相反的顺序读取输入序列(表示为上一小节中描述的词向量)。BLSTM的输出ht通过前向和后向输出的连接获得的:![]() ,其中:
,其中:
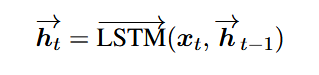
和
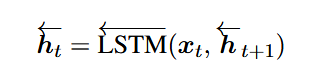
ht捕获xt的左右上下文,然后被送入全连接层。全连接层的输出是pt。最终预测是通过对所有可能标签的softmax获得的,
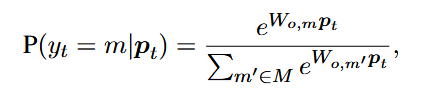
其中Wo是要学习的参数,M代表所有可能的输出标签的集合。在字符级BSL TM的情况下,前向和后向LSTM采用字符向量序列[z1,z2,.,zk]作为输入,其中k是单词中的字符数。通过连接![]() 和
和![]() 来获得时间t的单词的最终字符级嵌入et。
来获得时间t的单词的最终字符级嵌入et。
4.3基于注意力的Encoder-Decoder
编码器和解码器中都使用LSTM单元。在编码器端,我们使用BLSTM来捕获输入序列中单词的左右上下文信息。编码器的输入是每个单词的单词和字符级嵌入的连接,与上面描述的BLSTM相同。BILSTM每一个时间步t的输出ht被用于后续的注意力计算。在解码器端,我们使用单层LSTM,从句子的开始到结束一步一步地生成标签预测。前向编码器RNN的最后一个隐藏状态用作初始解码器隐藏状态。在每个解码时间步,解码器隐藏状态st通过st = σ(st-1,ct,yt-1,ht)计算,其中st-1是先前的解码器隐藏状态,ct是上下文向量,yt-1是先前的预测。ct计算为编码器隐藏状态序列的加权和,如下所示
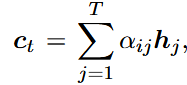
其中T是句子的总长度。通过对前一解码器隐藏状态st-1和对齐的编码器隐藏状态hj应用评分函数来获得权重αij。有关如何计算注意力的更多细节可以在BahDanau等人(2014)的工作中找到。
由于我们有一个特定的序列到序列任务,其中位置t的输入的每个元素映射到同一位置t的输出的元素,因此我们通过将时间t的编码器隐藏状态ht反馈给解码器来定义编码器和解码器之间的显式对齐。我们还通过将解码器LSTM的循环步骤限制为T,限制解码器输出恰好T标签预测。这确保了输入词和输出标签之间的一对一映射。yt的最终预测是通过将st传递到全连接层,然后在该层的输出上应用softmax函数来进行的(与第4.2节中描述的相同)。
4.4渐进适应
我们提出的渐进NER方法是通过预训练源模型,将参数传输到目标模型,然后微调该模型。一开始模型在标签数据上训练,直到达到最优参数![]() 。
。![]() 包括关于输出层的参数
包括关于输出层的参数![]() 和关于其他所有层的参数
和关于其他所有层的参数![]() 。为了识别新的NE类别,对BLSTM之后的全连接层进行了重大修改,即网络的输出层。在BLSTM架构中,全连接层将BLSTM的输出h映射到大小为nC的向量p。n是取决于数据集的标记格式的因素(例如,如果数据集采用BIOES格式(The BIOES format (short for Begin, Inside, Outside, End and Single) is a common tagging format for tagging tokens.),则n = 4,因为对于每个NE类别,将有4个输出标签B-NE、I-NE、E-NE和S-NE)。为了识别目标NE,我们为输出层之前的所有层构建相同的模型架构,并通过初始步骤中获得的
。为了识别新的NE类别,对BLSTM之后的全连接层进行了重大修改,即网络的输出层。在BLSTM架构中,全连接层将BLSTM的输出h映射到大小为nC的向量p。n是取决于数据集的标记格式的因素(例如,如果数据集采用BIOES格式(The BIOES format (short for Begin, Inside, Outside, End and Single) is a common tagging format for tagging tokens.),则n = 4,因为对于每个NE类别,将有4个输出标签B-NE、I-NE、E-NE和S-NE)。为了识别目标NE,我们为输出层之前的所有层构建相同的模型架构,并通过初始步骤中获得的![]() 初始化它们的所有参数。我们用nE节点扩展输出层,其中E是新NE类别的数量。这些都是用从随机分布
初始化它们的所有参数。我们用nE节点扩展输出层,其中E是新NE类别的数量。这些都是用从随机分布![]() 中提取的权重来初始化的,其中μ和σ是同一层中预训练权重的平均值和标准差。(我们使用在验证集上产生更高准确性的方法来初始化权重。我们的初始化选项是:(i)将所有参数设置为零;(ii)使用随机分布
中提取的权重来初始化的,其中μ和σ是同一层中预训练权重的平均值和标准差。(我们使用在验证集上产生更高准确性的方法来初始化权重。我们的初始化选项是:(i)将所有参数设置为零;(ii)使用随机分布![]() ,其中μ = 0.0,σ= 1.0;以及(iii)使用随机分布
,其中μ = 0.0,σ= 1.0;以及(iii)使用随机分布![]() ,其中μ和σ是同一层中预训练权重的均值和标准差。)这样,全连接层
,其中μ和σ是同一层中预训练权重的均值和标准差。)这样,全连接层![]() 的相关权重矩阵也从原始形状nC * p更新为形状(nC + nE)* p的新矩阵
的相关权重矩阵也从原始形状nC * p更新为形状(nC + nE)* p的新矩阵![]() 。请注意,
。请注意,![]() 和
和![]() 本质上是矩阵
本质上是矩阵![]() 和
和![]() 中的权重。新的模型参数以与初始步骤相同的方式更新。
中的权重。新的模型参数以与初始步骤相同的方式更新。
5.实验
5.1数据
我们通过修改CONLL 2003 NER数据集(Language-Independent Named Entity Recognition (II))以适应我们的实验设置来使用它。原始数据集包括具有四种类型命名实体的新闻文章-组织、个人、位置和杂项(分别由ORG、PER、SYS和MISC表示)。O标签指示不属于这四个命名实体中任何一个的令牌。实体标签以BIOES格式注释。出于实验的目的,我们将训练集洗牌并划分为80%/20%的分区,作为初始和后续步骤的DS和DT,因为我们假设目标数据的大小将小于源数据的大小。就句子实例而言,验证和测试集在两个步骤中是相同的,但在标签注释方面有所不同。特别是,我们通过以下方式创建四个数据集:(i)选择四个类别之一作为在后续步骤中要识别的新NE类别;以及(ii)用D train_S、D valid_S和DTest_S中的O(不是实体)替换此类类别的标签。例如,当我们使用LOC作为新NE时,我们将所有LOC标签注释替换为O,其中它们出现在D train_S、D valid_S和D test_S中。相反,在D train_T、D valid_T和D Test_T中,我们保留LOC标签注释。每种实例的标签统计摘要见表1。
除了将数据集分为DS和DT两个部分外,我们不会对数据集执行任何特定的预处理,除了将所有数字替换为0以缩小词汇表的大小。
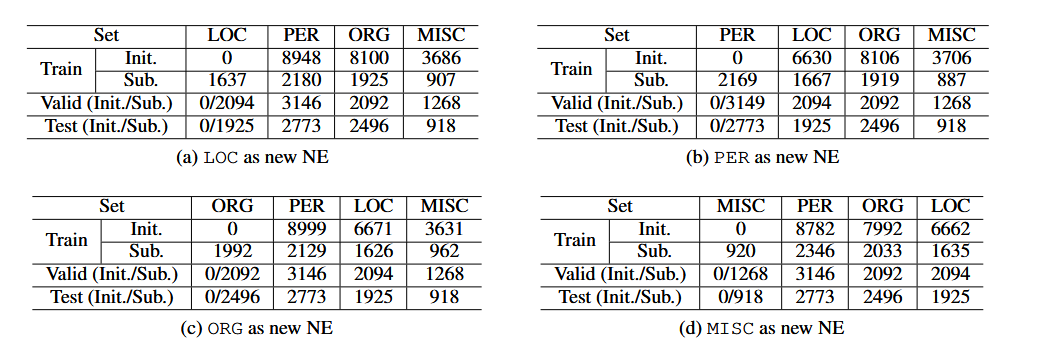
表1:为渐进NER实验定制CONLL数据集后的标签数量。Init.及Sub.分别代表初始步骤和后续步骤。
5.2模型
我们使用100维GLOVE预训练嵌入(http://nlp.stanford.edu/data/glove.6B.zip)来初始化单词嵌入查找表。由于我们不对输入序列中的token进行小写处理,对于那些在预训练词嵌入中没有直接映射的单词,若在预训练词嵌入中能找到其小写形式,则将其初始化为对应的小写形式。我们用<UNK>替换不常见的单词,即在训练集或测试集中出现的单词少于两个。<UNK>的单词嵌入是通过从[-0.25,0.25]之间的均匀分布中随机初始化的。
我们通过随机搜索(Bergstra和Bengio,2012)对两个模型的每个超参数在不同的时间间隔上执行超参数优化,包括BLSTM的字符和单词级嵌入的大小、批量大小、学习率、dropout率和梯度剪裁的最大值。表2显示了每个超参数的间隔和最终值,其中最终值是每个实验设置中在验证集(Dvalid S)上提供最佳性能的值。
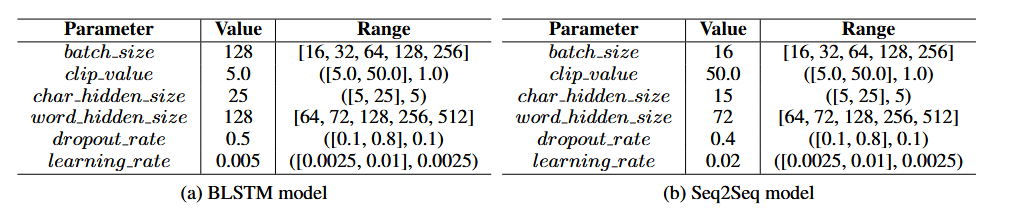
表2:BLSTM和Seq 2Seq模型的超参数的值范围和最终值。
5.3训练
这两个模型都在PyTorch中实现(Paszke等人,2017年)(The source code is available at https://github.com/liah-chan/sequence2sequenceNER)。我们使用momentum为0.9的随机梯度下降来最小化multi-class cross entropy。我们在这两个模型中应用了dropout层来控制过拟合。在每个步骤中,我们允许的最大epoch数为200。如果验证集中的F1分数在30个epoch内没有改善,则强制提前停止训练。从我们的初步实验中,我们发现,在后续步骤中保持传输参数固定通常会对两个模型产生更差的结果。因此,在后续步骤中,传输的参数不是固定的,而是与网络的其余部分一起更新。我们使用CONLL脚本评估模型的F1评分。
5.4结果
我们的基线BLSTM模型的性能与Lample等人(2016)或Chiu和Nichols(2016)报告的BLSTM模型一致。在NER的传统设置下,我们获得了89.74分的F1总分。Seq2Seq模型在F1中比基线模型高出1.24个百分点,达到90.98个百分点。后者与CONLL数据集报告的一些最新结果相当。
5.4.1源数据的性能
BLSTM和Seq 2Seq模型在我们的渐进学习环境中的性能分别如表3和表4所示。子级表(a)、(b)、(c)和(d)报告不同实验设置下的测试F1在后续步骤中识别不同目标新NE。Init.表示初始步骤中的F1分数,而Sub.表示后续步骤中的分数。Rand.报告通过相同的模型架构获得的测试F1分数,但参数随机初始化,并在后续步骤中使用所有目标数据进行训练。
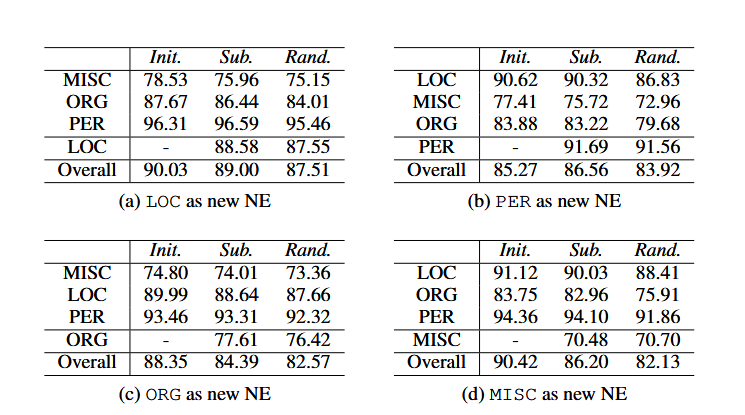
表3:BLSTM模型在每个类别上的测试F1。
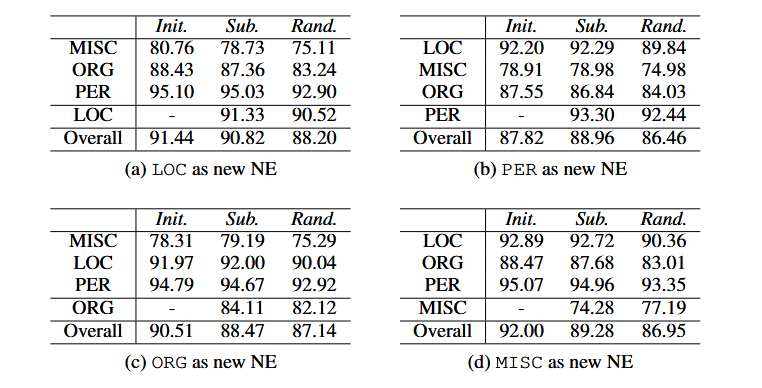
表4:Seq 2Seq模型在每个类别上的测试F1。
初始步骤中的训练以及后续步骤中随机初始化参数的模型的训练可以被视为标准NER任务。我们进一步报告了初始步骤中两个模型的性能以及图2中随机初始化参数的性能比较。我们可以看到Seq 2Seq模型在所有实验设置中都优于BLSTM模型。这支持了我们的论点,即Seq 2Seq模型可以是比BLSTM更好的NER任务方法,因为它能够利用之前预测的标签。
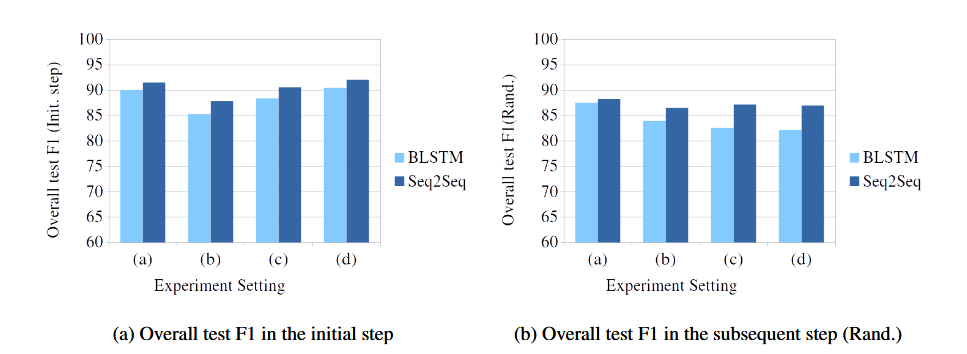 图2:BLSTM和Seq 2Seq模型在标准NER任务上的比较。
图2:BLSTM和Seq 2Seq模型在标准NER任务上的比较。
5.4.2传输参数与随机初始化参数
从构建方式来看,对于新的命名实体,初始步骤和后续步骤的数据之间总是存在标签不一致的情况,因为在初始步骤的数据中它被标注为“O”(非实体)。通过比较使用随机初始化参数的模型的F1值(每张表中的“Rand.”列)和在后续步骤中使用迁移参数的模型的F1值(每张表中的“Sub.”列),我们可以得出一些有趣的观察结果。几乎在所有情况下,使用迁移参数能产生更好的性能,F1值大约高出2到3个百分点。就目标新命名实体类别而言,使用迁移参数的模型比仅使用随机初始化参数的模型表现更好。这是因为在后续步骤中,我们允许迁移参数与模型的其他参数一起更新。这种方法可以纠正初始步骤中因将目标新标签视为“O”而学到的错误知识。唯一的例外是当使用“MISC”(杂项)作为目标新命名实体时。对于双向长短期记忆网络(BLSTM)和序列到序列(Seq2Seq)模型,随机初始化参数得到的F1值高于使用迁移参数的模型得到的F1值。这可能是因为“MISC”类别是由不属于其他类别的命名实体组成的集合。因此,这类命名实体的上下文可能差异很大,这使得从先前学到的关于该命名实体类别的错误知识中恢复过来更具挑战性,例如,在后续步骤中其新的上下文和信息更为稀疏。在后续步骤中,我们最多允许进行200个训练轮次(epoch),同时当验证集上的F1分数在超过30个轮次内没有提升时,强制停止训练。即使我们将使用随机初始化参数的模型的训练轮次增加到60,迁移参数仍然表现更好。我们还观察到,使用迁移参数的模型在后续训练中收敛更快,大约在20个轮次左右。这表明我们的渐进式学习技术使模型能够更准确地预测新类别,并且用时更短。也就是说,迁移参数不仅有助于模型达到更优的性能,还为模型提供了更好的初始化,使其能够更快地收敛。
5.4.3 原始NE类vs新的NE类
原始命名实体类别的F1值的提升或下降,是衡量模型在保留从初始步骤迁移而来的已学知识方面表现优劣的一个指标。在表5中,我们报告了使用双向长短期记忆网络(BLSTM)和序列到序列(Seq2Seq)模型时,针对每个原始命名实体类别,初始步骤和后续步骤之间测试F1值的差异。在该表中,数值越低意味着F1分数的损失越小,也就是说,模型在保留对初始步骤中已出现的命名实体类别的性能方面表现得更好。几乎在所有情况下,序列到序列(Seq2Seq)模型的F1值下降幅度较小。在某些情况下,序列到序列(Seq2Seq)模型能够从后续数据中进一步学习,并且在这些原始命名实体类别上取得更好的性能。例如,当使用“PER”(人物)作为新的命名实体类别时,序列到序列(Seq2Seq)模型能够提升在“LOC”(地点)和“MISC”(杂项)类别上的性能,而双向长短期记忆网络(BLSTM)模型的F1值却下降了。
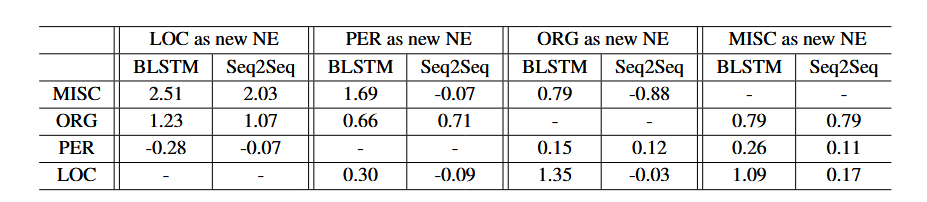
表5:测试F1分数从初始步骤到后续步骤的差异(值越低越好,而负值表示模型能够进一步改进)。
模型在学习识别新命名实体类别的能力,直接通过不同设置下目标命名实体类别在后续步骤中的测试F1分数体现出来,如表6所示。从表中可以明显看出,在所有情况下,序列到序列(Seq2Seq)模型的测试F1分数至少高出2到3个百分点。在“ORG”(组织)标签的情况下,序列到序列(Seq2Seq)模型的性能比双向长短期记忆网络(BLSTM)模型高出近7个百分点。通过比较在原始标签和目标新标签上的性能,如图3所示,我们可以看到,无论是在原始命名实体类别还是在新的命名实体类别上,序列到序列(Seq2Seq)模型的性能都优于作为基线的双向长短期记忆网络(BLSTM)模型。可以得出结论,在后续步骤中,序列到序列(Seq2Seq)模型在识别新的目标命名实体类别方面更具稳健性,同时它也不会降低对原始命名实体类别的性能表现。
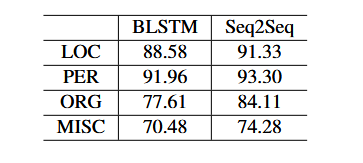
表6:后续步骤中新目标NE上的测试F1。
6.结论
在这项工作中,我们建议将基于注意力的Seq2Seq模型用于标准NER任务和渐进式NER任务,这是NER行业级应用的一个更实际的场景。我们认为Seq2Seq模型适用于这两种情况。我们的实验结果支持我们的说法,因为Seq2Seq模型在标准和渐进NER设置中都优于BLSTM。进一步的分析表明,Seq2Seq模型在保留从源数据中学习的知识和从目标数据中学习新知识方面都更好。我们还证明了所提出的渐进式学习技术在NER任务中的有效性。在未来的工作中,我们希望尝试其他数据集,并将我们的方法扩展到仅用新的NE类别注释的目标数据。将我们的模型和技术应用于其他领域,如领域适应或少镜头学习,也会很有趣。
致谢
这项研究得到了Almawave S.r.l.的部分支持。我们要感谢Giuseppe Castellucci、Andrea Favalli和Raniero Romagnoli通过对神经模型在工业世界现实问题中的应用进行有益的讨论,启发了这项工作。
参考文献
见原文

















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









