



四大数据结构的共同点
①都是容器类型:都能存储多个元素
②都支持多种数据类型:可以混合存储不同类型的数据(如:int/str/float等)
③都支持迭代:都可以用for循环遍历
④都支持in操作:都可以用in判断元素是否存在
⑤都是Python内置类型:无需导入任何模块
⑥都支持len()函数:能用len()获取元素数量
四大数据结构核心区别对照表

注意:集合和字典均使用花括号{}表示,但使用有差别,如d={}是创建一个空字典,若要创建一个空集合的话则要用d=set()。同样元组使用的小括号(),为避免与普通表达式混淆,在定义只有一个元素的元组时,要在元素后面加逗号如t=(88,)
四种类型使用案例如下:
1.列表(list)——你的万能工具箱
示例代码:
# 创建1个购物车列表
shopping_car = ["牛奶", "面包", "鸡蛋"]
# 动态操作(列表的优势!)
# 增加数据
shopping_car.append("苹果")
# 移除数据,如第二个
shopping_car.pop(1)
# 修改数据,如第一个
shopping_car[0] = "酸奶"
print(shopping_car)
输出结果:
# 输出:['酸奶', '鸡蛋', '苹果']
什么时候用列表?
- 需要保持记录顺序
- 存在频繁增-删-改
- 比如:待办事项、日志流水记录
2.元组(tuple)——不可变的保险箱
示例代码如下:
# 定义配置信息(不许修改)
DATABASE_CONFIG = (
"127.0.0.1", # 主机
3306, # 端口
"admin", # 用户名
"123456", # 密码
)
# 安全使用配置
host, port, user, pwd = DATABASE_CONFIG
print(f"正在连接{host}:{port}...")
# 若尝试修改元组的内容,会报错!!!
DATABASE_CONFIG[0] = "192.168.1.1" # 报错!
代码运行结果:
正在连接127.0.0.1:3306...
另,元组还常见于函数有多个返回值时:
# 定义一个多返回值的函数
def get_user_info(user_id):
return ("王小明", 28, "工程师")
# 姓名 # 年龄 # 职业
name, age, job = get_user_info(1001)
print(f"{name}({age}岁)是一名{job}")
什么时候用元组?
- 数据一旦写入就焊死,不想被该
- 需要作为字典键(字典的Key不重复)
- 比如:作为配置项、函数返回值
3. 字典(dict)——闪电般的查找器
示例代码如下:
# 构建用户数据字典
users = {101: {"name": "小明", "age": 18}, 102: {"name": "小红", "age": 20}}
# 闪电查找(比列表快N倍!)
print(users[102]["name"]) # 输出:小红
# 增加数据
users[103] = {"name": "小刚", "age": 22}
# 修改数据
users[102] = {"name": "小哈哈", "age": 22}
# 删除数据
del users[101]
print(users)
代码运行结果:
小红
{102: {'name': '小哈哈', 'age': 22}, 103: {'name': '小刚', 'age': 22}}
什么时候用字典?
- 需要键-值映射
- 快速查找需求
- 比如:参数列表、配置文件
4.集合(set)——去重小能手
示例代码:
# 构造1个数字集合
input_numbers = {12, 5, 8, 12, 8}
# 输出:{8, 12, 5} 自动去重!
print(input_numbers)
# 集合运算(超方便)
A = {1, 2, 3}
B = {2, 3, 4}
print(A | B) # 并集:{1, 2, 3, 4}
print(A & B) # 交集:{2, 3}
print(A - B) # 差集:{1}
什么时候用集合?
- 需要去除重复值
- 集合运算交 / 并 / 差
- 比如:过滤黑名单、求共同好友
使用时选择的流程:
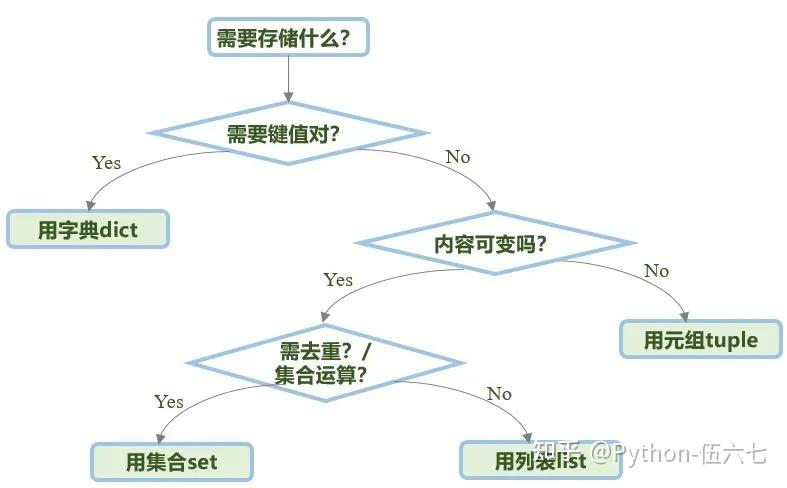
记住这些区别,能在编程时做出最佳的选择!
给自己做个记录,也希望能帮到认真学习的你!❤


















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









