







 本文介绍了Python处理Excel的模块xlwings和pandas,讲解了xlwings的工作簿和单元格操作,以及Numpy数组的使用。重点阐述了pandas的Series和DataFrame数据结构,包括文件的读写、数据筛选、排序和运算。
本文介绍了Python处理Excel的模块xlwings和pandas,讲解了xlwings的工作簿和单元格操作,以及Numpy数组的使用。重点阐述了pandas的Series和DataFrame数据结构,包括文件的读写、数据筛选、排序和运算。
一 xlwings安装与功能介绍
使用特定模块前,需要在程序最前面进行模块导入,和JAVA导入依赖包一样。
import 模块名
也可以加上from语句导入特定的子模块(主要是防止某些模块太大影响加载速度)
from 模块名 import 函数名(也可以用*代表所有)
1.1 os模块
os模块包含了与操作系统相关的一些功能,加上海量的辅助功能包,可以实现非常强大的功能。
getcwd():获取当前运行pytho代码文件的路径
import os
path = os.getcwd()
print(path)以上程序会输出vscode定义的path工程文件的存储路径。
listdir():获取某个文件夹所有文件和子文件夹的名称
import os
path = 'd:\\python'
list = os.listdir(path)
print(list)1.2 excel相关的模块
在处理Excel的时候需要对操作系统的文件进行操作,所以通常需要引入OS模块。
下图列举了与Excel高度相关的一些模块,后面用的比较多的是xlwings,其他模块可能会少量使用。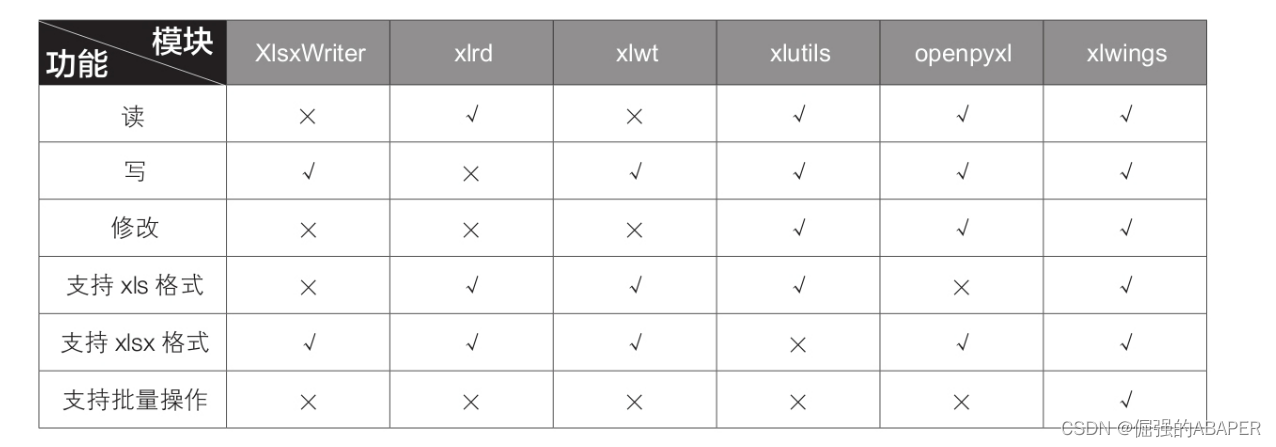
二 xlwings功能介绍
2.1 操作工作簿
- 创建新的工作簿
import xlwings as xw # 引入xlwings app = xw.App(visible=True,add_book=False) # 声明app workbook = app.books.add() # 新增workbook workbook.save(r'd:\pytest\test.xlsx') # 存储到本地路径 app.quit() # 退出APP
- 打开已经存在的工作簿
import xlwings as xw # 引入xlwings
app = xw.App(visible=True,add_book=False) # 声明app
try:
workbook = app.books.open(r'd:\pytest\test1.xlsx')
except FileNotFoundError:
print('不存在的文件!')
2.2 操作工作表和单元格
import xlwings as xw # 引入xlwings
app = xw.App(visible=True,add_book=False) # 声明app
try:
workbook = app.books.open(r'd:\pytest\test.xlsx')
except FileNotFoundError:
print('不存在的文件!')
worksheet = workbook.sheets.add('产品统计表')
worksheet.range('A1').value = '编号'
workbook.save()
workbook.close()
app.quit()三 Numpy
NumPy(Numberical Python),是一个高效的、强大的数学计算模块,用于数学分析与数学计算。
通常在做Excel大数据分析时需要用到Numpy与Pandas相结合。
3.1 数组
和JAVA程序一样,数组分为一维数组和多位数组,一维数组与列表有相似之处。
import numpy as np
a = [1,2,3,4]
b = np.array([1,2,3,4])
print(a)
print(b)
print(type(a))
print(type(b))
np.arange(para1) #只有一个参数:起点默认为0,para1为终点,步长为1,左闭右开
np.arange(para1,para2) #两个参数:起点para1,终点para2,步长为1,左闭右开
np.arange(para1,para2,para3) #三个参数:起点para1,终点para2,步长para3,左闭右开
import numpy as np
x = np.arange(5)
print(x)
y = np.arange(5,10)
print(y)
z = np.arange(5,10,2)
print(z)得到输出如下

random()函数: 创建随机一维数组。
import numpy as np
x = np.random.randn(3) #服从正态分布 均值0,标注差为1
print(x) ![]()
reshape(): 创建二维数组
import numpy as np
y = np.arange(12).reshape(3,4)
print(y)
randint() 创建随机整数二维数组
import numpy as np
e = np.random.randint(0,10,(4,4))
print(e)
四 pandas-数据分析与清洗
pandas模块是基于NumPy的一个开源Python模块,应用于数据分析,数据清洗和数据准备等工作。pandas提供了非常直观的数据结构以及强大的数据处理功能,基本上Excel能够做到的,都可以通过pandas实现。
pandas包含Series和DataFrame两种数据结构。
4.1 Series
类似于通过NumPy模块创建的一维数据,不同的是Series对象不仅包含数值,还包含一组索引。
import pandas as pd
s = pd.Series(['丁一','王二','张三'])
print(s)4.2 DataFrame
DataFrame是一个二维数据表格结构。
4.2.1 二维数据表格DataFrame的创建与索引的修改
- DataFrame创建
DataFrame()函数:基于列表创建DataFrame
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]])
print(a)
- 自定义行与列索引
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
print(a)
另外一种定义方法
import pandas as pd
a = pd.DataFrame()
date = [1,3,5]
score = [2,4,6]
a['date'] = date
a['score'] = score
print(a)- 通过字段创建DataFrame
通过字段创建DataFrame会默认以键名作为列索引
import pandas as pd
b = pd.DataFrame({'a':[1,3,5],'b':[2,4,6]},index=['X','Y','Z'])
print(b)
4.3 文件读写
Pandas模块支持从多种格式数据文件中读取和写入数据,包括Excel,TXT,CSV等文件格式。
4.3.1 文件读取
import pandas as pd
data = pd.read_exel('data.xlsx',sheetname=0,encoding='utf-8')
/* 相对路径
sheetname可以为数字,0代表第一个工作表,也可以用工作表名称
encoding编码方式 gbk/utf-8
*/
data = pd.read_csv('data.csv',delimiter=',',encoding = 'utf-8')
/*
delimiter用于分隔符,这里为逗号
*/
4.3.2 文件写入
import pandas as pd
data = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['A列','B列']) #创建DataFrame
data.to_excel('data.xlsx') #写入Excel
4.3.3 数据处理
首先创建一个DataFrame
data = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],index=['r1','r2','r3],colums=[
'c1','c2','c3])- 数据选取
选取第一列a = data['c1'] print a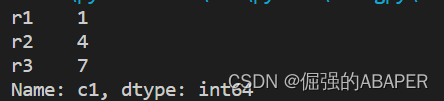
选取多列
c = data[['c1'],['c3']] 按照行选取
#选取第2~3行的数据,注意序号从0开始,左闭右开
a = data[1:3]pandas模块官方文档推荐使用iloc方法根据行序号来选取数据
b = data.iloc[1:3]选取单行,就必须用iloc方法.
c = data.iloc[-1] #选取倒数第一行选取多行
d = data.loc[['r2','r3']] #根据行序号选取数据
d = data.head() #选取前5行数据,不足5行选取全部数据
d = data.head(2) #选取前两行数据
a = data[['c1','c3'][0:2] # 选取 C1和C3列的前两行数据
a = data[[0:2],['c1':'c3'] # 同上
b = data.iloc[[0:2][['c1','c3']] #pandas中习惯先选取行再选取列
数据筛选
a = data[data['c1'] >1] & (data['c2'] == 5)] # &与 / 或数据排序
a = data.sort_values(by='c2',ascending=False) # false表示倒序,true表示升序 数据运算
data['C4'] = data['C3']-data['C1'] # 会生成新的结果列数据删除
Drop()函数可以删除DataFrame中的指定数据
- index用于指定要删除的行
- columns指定要删除的列
- inplace默认值为False,表示该删除操作不改变原来的DataFrame,而是返回一个执行删除操作后的新DataFrame,如果设置为True,则会直接在原DataFrame中进行删除操作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









