







针对Server Mesh架构 List - Watch通讯机制主要应用在:APIServer → Pilot
在 K8S 内部通信中,肯定要保证消息的实时性,之前以为方式有两种:
- 客户端(kubelet, scheduler, controller-manager 等)轮询 apiserver
- apiserver 通知客户端
如果采用轮询,势必会大大增加 apiserver 的压力,同时实时性很低。如果 apiserver 主动发 HTTP 请求,又如何保证消息的可靠性,以及大量端口占用问题?
答案就是List-watch,它是 K8S 统一的异步消息处理机制,保证了消息的实时性,可靠性,顺序性,性能等等,为声明式风格的 API 奠定了良好的基础,它是优雅的通信方式,是 K8S 架构的精髓
- 由组件向apiserver而不是etcd发起watch请求,在组件启动时就进行订阅,告诉apiserver需要知道什么数据发生变化。Watch是一个典型的发布-订阅模式。
- 组件向apiserver发起的watch请求是可以带条件的,例如,scheduler想要watch的是所有未被调度的Pod,也就是满足Pod.destNode=""的Pod来进行调度操作;而kubelet只关心自己节点上的Pod列表。apiserver向etcd发起的watch是没有条件的,只能知道某个数据发生了变化或创建、删除,但不能过滤具体的值。也就是说对象数据的条件过滤必须在apiserver端而不是etcd端完成。
1. List-Watch 是什么
Etcd 存储集群的数据信息,apiserver 作为统一入口,任何对数据的操作都必须经过 apiserver
客户端(kubelet/scheduler/ontroller-manager)通过 list-watch 监听 apiserver 中资源(pod/rs/rc 等等)的 create, update 和 delete 事件,并针对事件类型调用相应的事件处理函数
那么 list-watch 具体是什么呢,顾名思义,list-watch 有两部分组成,分别是 list 和 watch
- list 非常好理解,就是调用资源的 list API 罗列资源,基于 HTTP 短链接实现
- watch 则是调用资源的 watch API 监听资源变更事件,基于 HTTP 长链接实现
以 pod 资源为例,它的 list 和 watch API 分别为:
# List API,返回值为 PodList,即一组 pod
GET /api/v1/pods
# Watch API,往往带上 watch=true,表示采用 HTTP 长连接持续监听 pod 相关事件,每当有事件来临,返回一个 WatchEvent
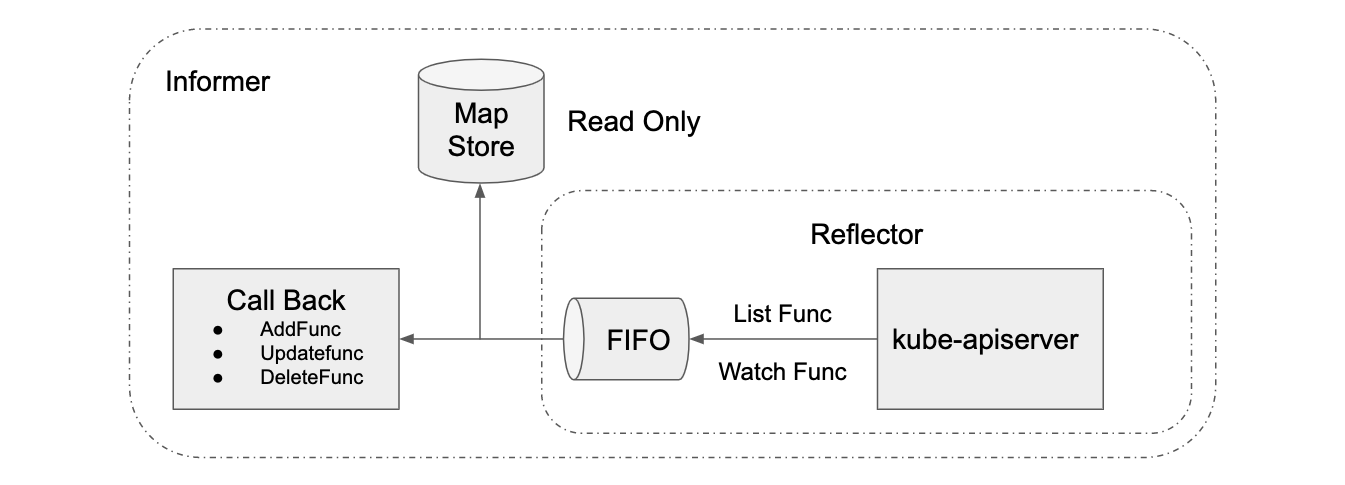
GET /api/v1/watch/podsK8S 的 informer 模块封装 list-watch API,用户只需要指定资源,编写事件处理函数,AddFunc, UpdateFunc 和 DeleteFunc 等。如下图所示,informer 首先通过 list API 罗列资源,然后调用 watch API 监听资源的变更事件,并将结果放入到一个 FIFO 队列,队列的另一头有协程从中取出事件,并调用对应的注册函数处理事件。Informer 还维护了一个只读的 Map Store 缓存,主要为了提升查询的效率,降低 apiserver 的负载。
2. Watch 是如何实现的
List 的实现容易理解,那么 Watch 是如何实现的呢?Watch 是如何通过 HTTP 长链接接收 apiserver 发来的资源变更事件呢?
秘诀就是 Chunked transfer encoding(分块传输编码),它首次出现在 HTTP/1.1 。正如维基百科所说:
HTTP 分块传输编码允许服务器为动态生成的内容维持 HTTP 持久链接。通常,持久链接需要服务器在开始发送消息体前发送Content-Length消息头字段,但是对于动态生成的内容来说,在内容创建完之前是不可知的。使用分块传输编码,数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。
当客户端调用 watch API 时,apiserver 在 response 的 HTTP Header 中设置 Transfer-Encoding 的值为 chunked,表示采用分块传输编码,客户端收到该信息后,便和服务端该链接,并等待下一个数据块,即资源的事件信息。例如:
$ curl -i http://{kube-api-server-ip}:8080/api/v1/watch/pods?watch=yes
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Thu, 02 Jan 2020 20:22:59 GMT
Transfer-Encoding: chunked
{"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}}
{"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}}
{"type":"MODIFIED", "object":{"kind":"Pod","apiVersion":"v1",...}}
...
3. List-Watch机制细节
kubernetes没有像其他分布式系统中额外引入MQ,是因为其设计理念采用了level trigger而非edge trigger
其仅仅通过http+protobuffer的方式,实现list-watcher机制来解决各组件间的消息通知,List-watch是k8s统一的异步消息处理机制
- list通过调用资源的list API罗列资源,基于HTTP短链接实现;
- watch则是调用资源的watch API监听资源变更事件,基于HTTP长链接实现
在kubernetes中,各组件通过监听Apiserver的资源变化,来更新资源状态
边界触发(Edge Trigger) 是指每当状态变化时发生一个io事件
条件触发(Level Trigger) 说的是在某种状态下触发,如果一直在这种状态下就一直触发
由于kubernetes系统的采取Level Trigger而非Edge Trigger的设计理念,所以各组件只需要感知数据最新的状态,而不需要担心错过数据的变化过程。而作为kubernentes系统消息通知机制(或者说数据实时通知机制),应该满足下面几点要求:
-
需求1: 实时性(即数据变化时,相关组件越快感知越好)
-
需求2: 保证消息的顺序性(即消息要按发生先后顺序送达目的组件。很难想象在Pod创建消息前收到该Pod删除消息时组件应该怎么处理)
-
需求3: 保证消息不丢失或者有可靠的重新获取机制(比如说kubelet和kube-apiserver间网络闪断,需要保证网络恢复后kubelet可以收到网络闪断期间产生的消息)
3.1 需求1的解决方案
kubernetes组件间主要通过http/2协议(kubernetes1.5之前采用http1.1,另Go1.7之后开始支持http/2)进行数据交互,满足实时性主要下面2种方案。
-
方案1: http long polling客户端发起http request,服务端有请求数据时就回复一个response(如没有数据服务端就等到有数据再回复),客户端收到response后马上又发起新的request,如此往复。具体流程如下图所示:
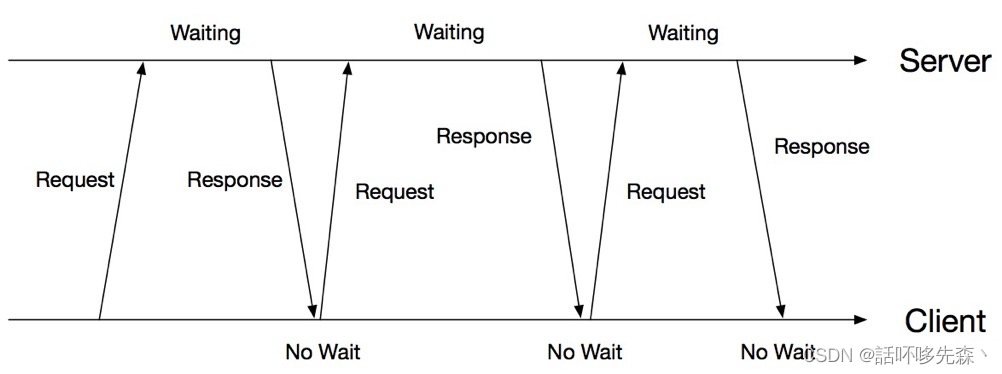
方案缺点: 通信消耗大一些(每个response多一个request)
-
方案2: http streaming客户端发起http request,服务端有请求数据就回复一个response(回复的http header中会带上”Transfer-Encoding”:”chunked”)。客户端收到这种header的response后就会继续等待后续数据,而服务端有新的数据时会继续通过这条连接发数据。具体流程如下图所示:
|
|

方案2缺点: 需要对返回数据做定制
上面两种方案都有自己的优缺点,在kubernetes中选择了方案2,且在kubernetes中的http streaming请求我们称为watch请求(其实就是一个http get请求)
注: ETCD2中watch功能选用的是方案1
3.2 需求2的解决方案
kubernetes中为每一个REST数据加了一个ResourceVersion字段,并且该字段的值由ETCD来保证全局单调递增(当ETCD中写入一个数据时,全局ResourceVersion就加1)。这样就保证了不同时刻的数据ResourceVersion不同,并且后产生数据的ResourceVersion较之前数据的ResourceVersion大。这样客户端发起watch请求时,只需要带上请求数据在本地缓存中的最新ResourceVersion,而服务端就根据ResourceVersion从小到大把 大于客户端ResourceVersion的数据按顺序推送给客户端即可。这样就保证了推送数据的顺序性。
|
|
具体如下图所示:
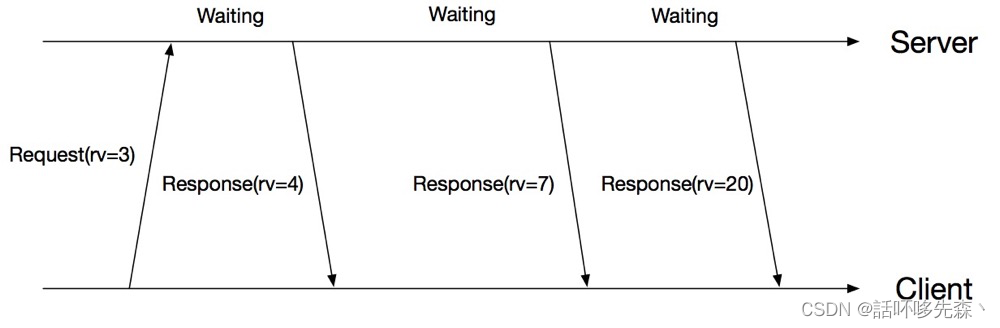
因为ETCD保证全局单调+1,所以某类数据的RV可能不会逐步+1变化
3.3 需求3的解决方案
基于需求1和需求2的解决方案,需求3主要是对异常状况处理的完善。kubernetes中结合watch请求增加了list请求,主要做如下两件事情:
-
watch请求开始之前,先发起一次list请求,获取集群中当前所有该类数据(同时得到最新的ResourceVersion),之后基于最新的ResourceVersion发起watch请求。
-
当watch出错时(比如说网络闪断造成客户端和服务端数据不同步),重新发起一次list请求获取所有数据,再重新基于最新ResourceVersion来watch。
4. 大致流程
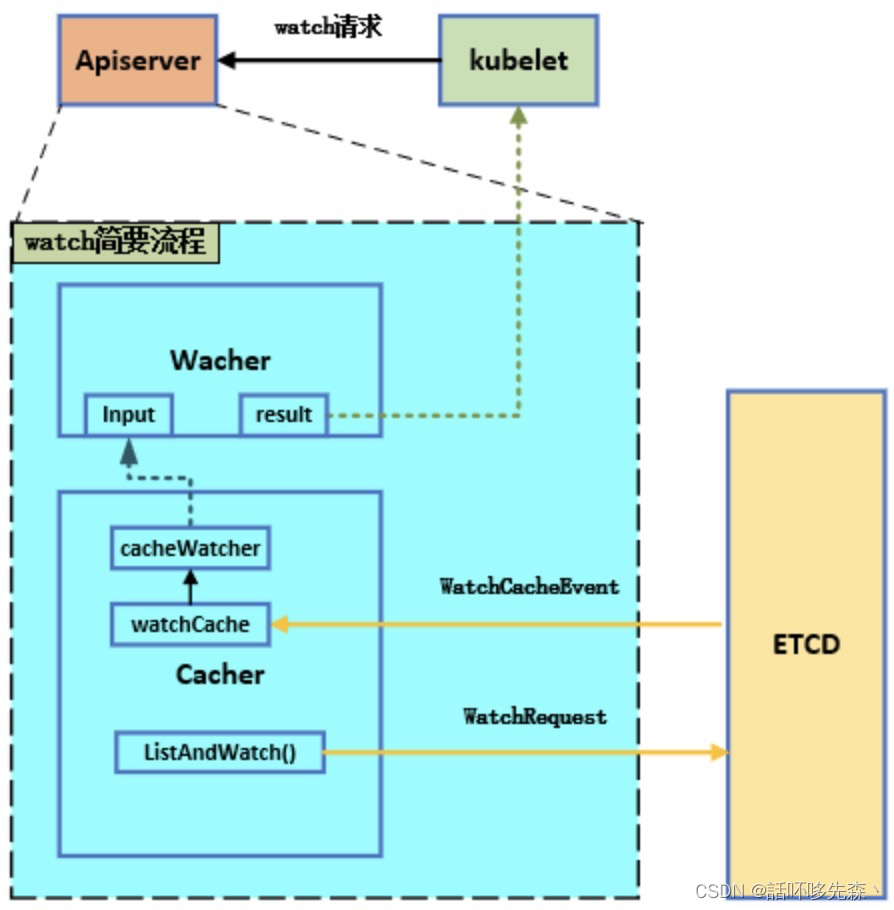
1、当API Server监听到各组件发来的watch请求时,由于list和watch请求的格式相似,先进入ListResource函数进行分析,若解析为watch请求,便会创建一个watcher结构来响应请求
2、API Server 使用不同类型的cacher来接收etcd的事件,通过ListAndWatch()这个方法,向etcd发送watch请求,etcd会将某一类型的数据不断的同步到watchCache结构中
3、cacheWatcher从watchCache中拿到从某个resourceVersion以来的所有数据,然后将数据放到input这个channel里面去,通过filter输出到result这个channel里面,最终返回数据到某个client
综合上面的方案分析,我们可以综合总结一下解决方案: kubernetes中基于ResourceVersion信息采用list-watch(http streaming)机制来保证组件间的数据实时可靠传送。我们就统称该方案为list-watch机制*
5. list-watch机制的几点思考
-
list请求是返回全量的数据,如果数据量较大时(比如20wPod),如果watch失败后需要relist,这时候的list请求成本是很高的。(服务端和客户端都需要对20w数据进行编解码,序列化和反序列化等)。kubernetes大规模应用场景下,需要尽量减少relist发生次数
-
watch请求采用http streaming方式,http1.1时(kubernetes1.5前)因为长连接是独立的TCP连接,假如网络断了,客户端是感知不到网络断开的,而只是以为服务端一直没有数据。tcp keep-alive机制检测到网络断开后(golang默认http client的keep-alive时间是30s),会主动rst掉该连接,然后再次建立新的连接。而在http/2(大于kubernetes1.5中使用)中因为大家共用一条TCP连接,客户端不断的各种请求导致keep-alive机制无法发挥作用,最后只能由数据的重传超时来reset掉这条TCP连接,这种场景下对系统的影响可能要大一些。
-
同时kubernetes1.5之前http1.1中每个REST资源的list-watch都有一条长连接,这样对服务器压力很大。不过这个问题因为http/2的连接复用机制,在kubernetes1.5后得到了很好的解决。
-
tcp长连接断开考虑: 因为watch请求是http streaming方式,客户端不清楚服务端是否还有数据需要发送,所以客户端一般不会主动关闭长连接。需要断开长连接时,应该考虑由服务端来断开。
-
正因为kubernetes采用了基于
level trigger而非edge trigger的设计理念,因此在kubernetes中没有像其他的分布式系统中额外引入MQ,降低了系统的整体复杂度(如openstack中的rabbitmq, cloudFoundary中的nuts等)。而只是简单通过http/2 + protobuffer的方式实现了一套list-watch机制来解决各个组件间的消息通知(满足了系统需求)。

















 4771
4771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









