




 文章探讨了大型语言模型的潜在风险,尤其是用于恶意目的,如虚假信息和学术作弊。提出了一种水印技术,通过在生成文本中嵌入不可见的模式,以检测机器生成的内容。研究展示了如何在生成过程中加入水印,并通过实验评估了其强度和文本质量的平衡。
文章探讨了大型语言模型的潜在风险,尤其是用于恶意目的,如虚假信息和学术作弊。提出了一种水印技术,通过在生成文本中嵌入不可见的模式,以检测机器生成的内容。研究展示了如何在生成过程中加入水印,并通过实验评估了其强度和文本质量的平衡。
大型语言模型,如最近开发的ChatGPT,可以撰写文件、创建可执行代码和回答问题,通常具有人类般的能力。
随着这些大模型的应用越来越普遍,越来越大的风险也显现了出来,它们可能被用于恶意目的。这些恶意目的包括:在社交媒体平台上利用自动机器人进行社交工程和选举操纵活动,制造虚假新闻和网页内容,以及利用人工智能系统在学术写作和编程作业中作弊等。
此外,在互联网上充斥着的AI生成数据的广泛存在使得未来数据集的构建工作变得更加复杂,因为合成数据的质量通常不及人类内容,很多研究者不得不在模型训练之前进行检测和排除。
出于以上的种种原因,检测和监管AI生成文本成为减少大模型危害的关键。
针对这个问题,有一篇论文提出了一种对大型语言模型的输出添加水印的方法 —— 将信号嵌入到生成的文本中,这些信号对人类来说是不可见的,但可以通过算法检测到。无需重新训练语言模型即可生成水印,无需访问 API 或参数即可检测水印。
这篇文章思考如何检测一段文本是大模型的输出。他们发现的水印技术可能是一种好的检测方案。水印是指文本中的隐藏模式,对人类来说不可察觉,但可以通过算法识别为机器生成的文本。
这篇文章提出了一种高效的水印技术,可以从短长度的token(仅需25个token)中检测到机器生成的文本,同时误报率(将人类文本标记为机器生成)的概率极低。
水印检测算法可以公开,让第三方(例如社交媒体平台)自行运行,或者可以保持私密,并通过API运行。
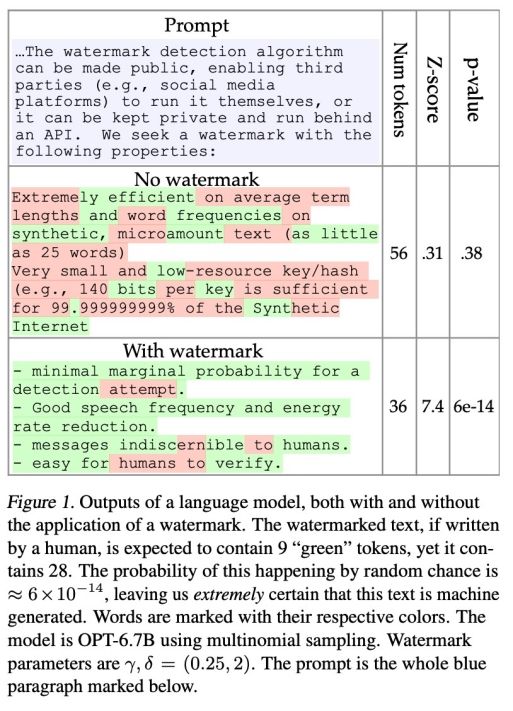
为了检测水印,该论文还提出了一种具有可解释 p 值的统计测试方法,以及用于分析水印敏感度的信息论框架。该研究所提方法简单新颖,并提供了彻底的理论分析和扎
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









