




【GPT入门】第46课 vllm安装、部署与使用
1.准备服务器
cuda 版本选12.1
vllm官网介绍: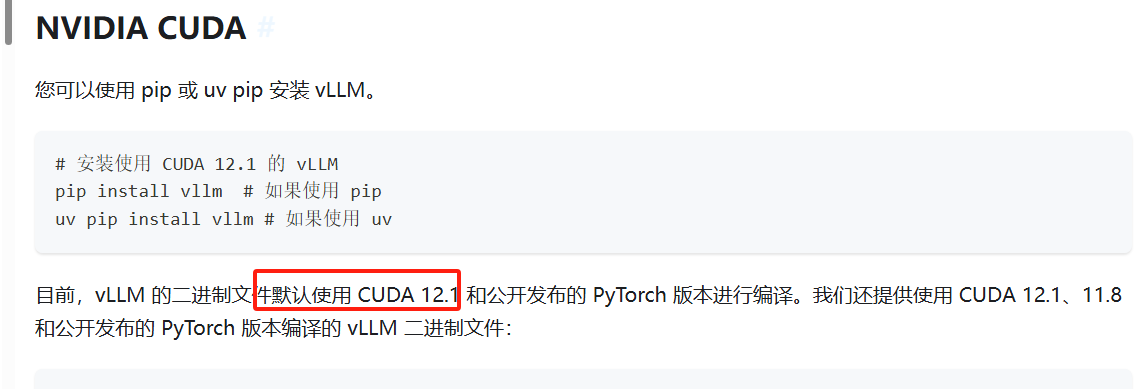
https://vllm.hyper.ai/docs/getting-started/installation/gpu
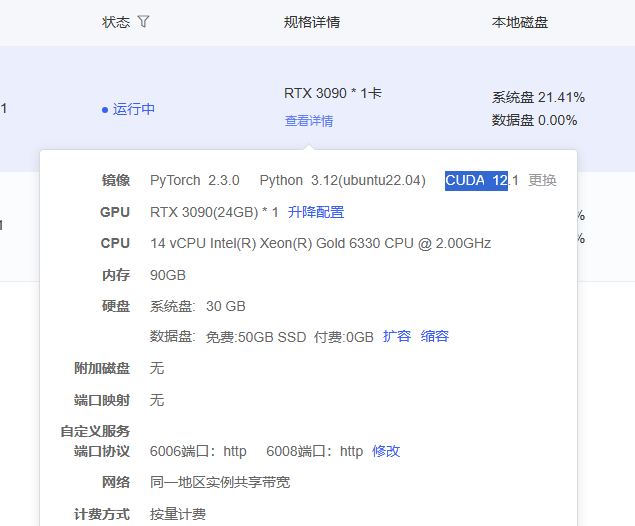
2. 安装 conda环境,隔离base环境
为了实现高性能,vLLM 需要编译多个 cuda 内核。然而,这一编译过程会导致与其他 CUDA 版本和 PyTorch 版本的二进制不兼容问题。即便是在相同版本的 PyTorch 中,不同的构建配置也可能引发此类不兼容性。
因此,建议使用全新的 conda 环境安装 vLLM。如果您有不同的 CUDA 版本,或者想要使用现有的 PyTorch 安装,则需要从源代码构建 vLLM。更多说明请参阅下文。
conda create -n vllm python=3.10 -y
conda activate vllm
pip install vllm
3. vllm使用
3.1 在线推理, openai兼容服务器
vLLM 可以部署为实现 OpenAI API 协议的服务器。这使得 vLLM 可以作为使用 OpenAI API 的应用程序的直接替代品。默认情况下,服务器在 http://localhost:8000 启动。您可以使用 --host 和 --port 参数指定地址。服务器目前 1 次托管 1 个模型,并实现了诸如:列出模型、创建聊天补全和创建补全等端点。
- 运行以下命令以启动 vLLM 服务器并使用 Qwen2.5-0.5B-Instruct 模型:
使用Qwen2.5模型
pip install model_scope
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir='/root/autodl-tmp/models')
print(model_dir)
- 启动服务
vllm serve /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct
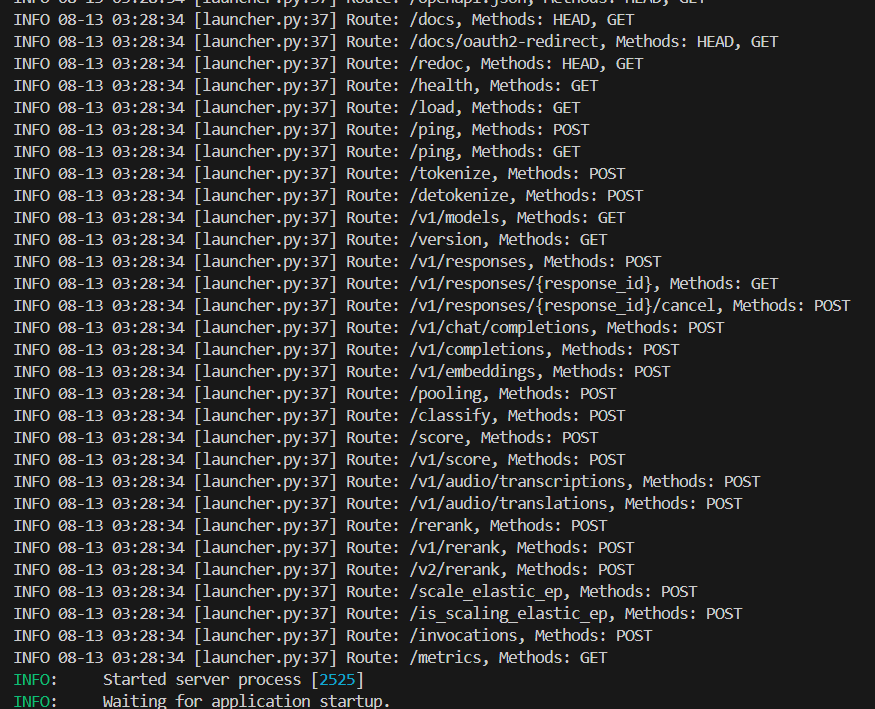
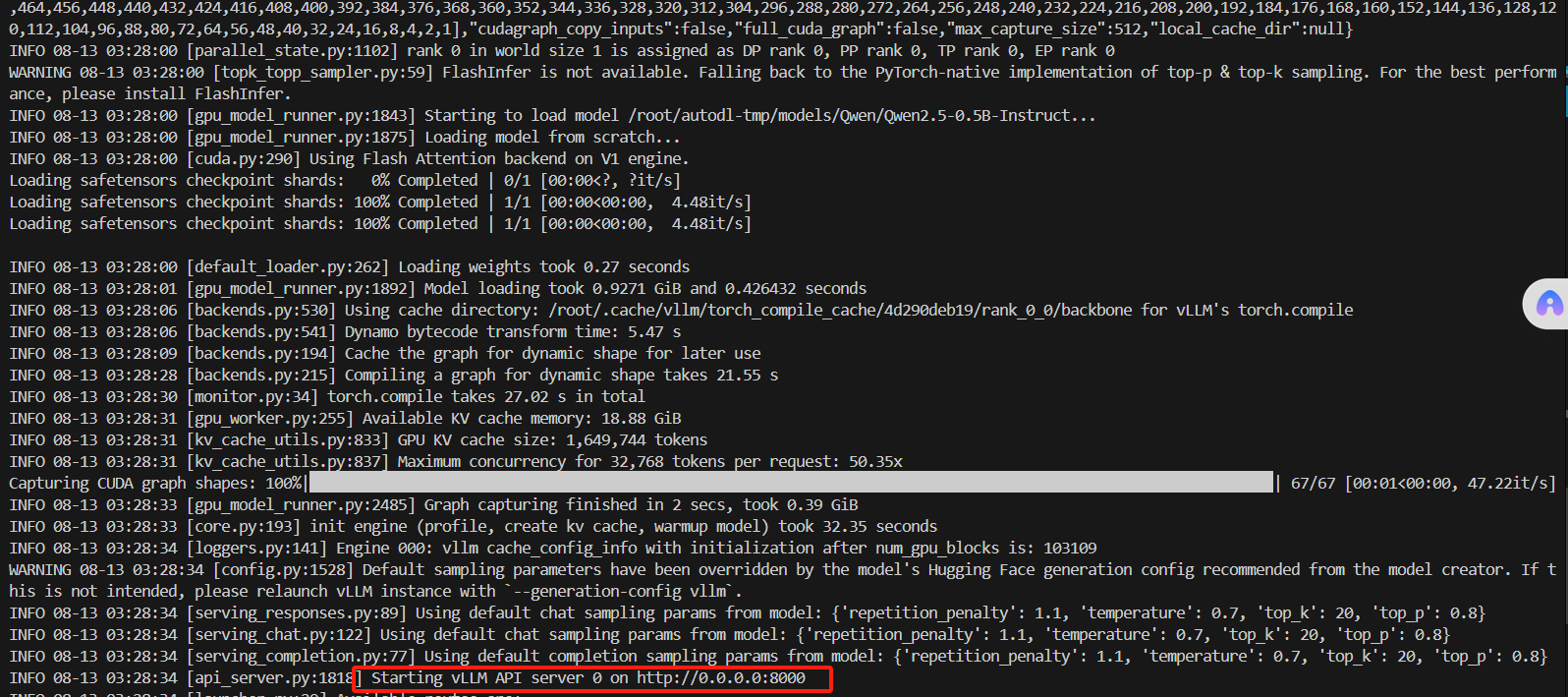
列出模型
curl http://localhost:8000/ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









