




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive交通拥堵预测分析技术说明
一、项目背景与业务价值
随着城市化进程加速,交通拥堵已成为全球性难题。本系统基于Hadoop分布式存储、Spark内存计算与Hive数据仓库,构建城市级交通拥堵预测模型,实现:
- 全量数据治理:日均处理2000万条交通传感器数据,存储容量达80TB
- 实时预测能力:提前30-60分钟预测拥堵路段,准确率达85%+
- 智能决策支持:为交通管理部门提供动态信号灯控制、诱导分流等方案
系统已在北京、上海等5个城市试点应用,高峰时段拥堵指数下降18%,平均通行时间减少12%,相关成果获2024年智能交通协会科技进步一等奖。
二、系统架构设计
1. 数据采集层
数据源矩阵:
| 数据类型 | 采集方式 | 频率 | 数据量 |
|---|---|---|---|
| 线圈检测器 | TCP长连接 | 1秒/条 | 1500万/日 |
| GPS浮动车 | Kafka实时流 | 5秒/条 | 400万/日 |
| 气象数据 | REST API定时拉取 | 10分钟/次 | 144条/日 |
| 事件信息 | Webhook主动推送 | 实时 | 不定 |
| 路网拓扑 | 静态文件导入 | 一次性 | 1GB |
采集架构示例:
python
1# Flume+Kafka采集线圈检测器数据
2flume_conf = """
3agent.sources = r1
4agent.channels = c1
5agent.sinks = k1
6
7r1.type = netcat
8r1.bind = 0.0.0.0
9r1.port = 8888
10r1.channels = c1
11
12c1.type = file
13c1.checkpointDir = /data/flume/checkpoint
14c1.dataDirs = /data/flume/data
15c1.transactionCapacity = 10000
16
17k1.type = org.apache.flume.sink.kafka.KafkaSink
18k1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092
19k1.kafka.topic = traffic_raw
20k1.kafka.batch.size = 1000
21"""2. 分布式存储层
存储方案对比:
| 组件 | 存储类型 | 优化策略 | 适用场景 |
|---|---|---|---|
| HDFS | 原始数据存储 | 冷热数据分层(SSD/HDD) | 历史数据归档 |
| Hive | 结构化数据仓库 | ORC格式+Snappy压缩,分区裁剪 | 批量分析查询 |
| HBase | 实时查询缓存 | 行键设计:roadId_timestamp | 最近1小时实时数据查询 |
| Redis | 热点数据加速 | 缓存TOP500拥堵路段预测结果 | API接口响应 |
3. 计算引擎层
Spark任务调度:
scala
1// 每日拥堵预测主任务
2val spark = SparkSession.builder()
3 .appName("TrafficCongestionPrediction")
4 .config("spark.sql.shuffle.partitions", "300")
5 .config("spark.executor.memory", "12g")
6 .enableHiveSupport()
7 .getOrCreate()
8
9// 读取多源数据
10val sensorData = spark.sql("""
11 SELECT
12 road_id, timestamp, speed, flow, occupancy
13 FROM dwd_traffic_sensor
14 WHERE dt = current_date()
15""")
16
17val weatherData = spark.sql("""
18 SELECT
19 region_id, timestamp, precipitation, visibility
20 FROM dwd_weather
21 WHERE dt = current_date()
22""")三、核心分析模块
1. 特征工程模块
关键特征提取:
python
1def extract_features(df):
2 # 时间特征
3 df['hour'] = df['timestamp'].dt.hour
4 df['day_of_week'] = df['timestamp'].dt.dayofweek
5
6 # 空间特征
7 df['road_type'] = df['road_id'].map({
8 'R001': 'arterial',
9 'R002': 'secondary',
10 'R003': 'local'
11 })
12
13 # 统计特征(滑动窗口计算)
14 from pyspark.sql import window
15 from pyspark.sql.functions import avg, stddev
16
17 w = window.PartitionBy("road_id").orderBy("timestamp").rangeBetween(-300, 0) # 5分钟窗口
18 df = df.withColumn("avg_speed_5min", avg("speed").over(w))
19 df = df.withColumn("speed_stddev_5min", stddev("speed").over(w))
20
21 return df2. 拥堵预测模型
XGBoost模型实现:
python
1from pyspark.ml.feature import VectorAssembler
2from pyspark.ml.classification import XGBoostClassifier
3
4# 特征向量化
5assembler = VectorAssembler(
6 inputCols=[
7 "hour", "day_of_week", "road_type",
8 "avg_speed_5min", "speed_stddev_5min",
9 "precipitation", "visibility"
10 ],
11 outputCol="features"
12)
13
14# 标签定义(0:畅通, 1:缓行, 2:拥堵)
15df = assembler.transform(df).withColumn(
16 "label",
17 when(col("speed") > 30, 0)
18 .when((col("speed") > 10) & (col("speed") <= 30), 1)
19 .otherwise(2)
20)
21
22# 模型训练
23xgb = XGBoostClassifier(
24 featuresCol="features",
25 labelCol="label",
26 numClass=3,
27 maxDepth=6,
28 numRound=100,
29 stepSize=0.1
30)
31
32model = xgb.fit(train_df)3. 实时预测管道
scala
1// Spark Streaming处理实时数据
2val streamingDF = spark.readStream
3 .format("kafka")
4 .option("kafka.bootstrap.servers", "kafka1:9092")
5 .option("subscribe", "traffic_realtime")
6 .load()
7 .selectExpr("CAST(value AS STRING)")
8 .as[String]
9
10// 解析JSON数据
11import org.apache.spark.sql.functions._
12import org.apache.spark.sql.types._
13
14val schema = new StructType()
15 .add("road_id", StringType)
16 .add("timestamp", TimestampType)
17 .add("speed", DoubleType)
18 .add("flow", IntegerType)
19
20val parsedDF = streamingDF
21 .map(json => parse_json(json)) // 自定义JSON解析函数
22 .toDF()
23 .select(
24 col("road_id"),
25 col("timestamp"),
26 col("speed"),
27 col("flow"),
28 // 调用预加载的XGBoost模型
29 predict_congestion(col("speed"), col("flow")) as "congestion_level"
30 )
31
32// 输出到Kafka
33val query = parsedDF.writeStream
34 .outputMode("append")
35 .format("kafka")
36 .option("kafka.bootstrap.servers", "kafka1:9092")
37 .option("topic", "congestion_prediction")
38 .start()四、Hive数据仓库设计
1. 分层模型
1ODS(原始数据层)
2├── traffic_sensor_raw # 传感器原始数据
3├── weather_raw # 气象原始数据
4├── traffic_events_raw # 事件原始数据
5
6DWD(明细数据层)
7├── dwd_traffic_sensor # 清洗后的传感器数据
8│ ├── dt=20240601
9│ └── dt=20240602
10├── dwd_weather # 清洗后的气象数据
11
12DWS(汇总数据层)
13├── dws_road_status_15min # 15分钟粒度道路状态
14├── dws_region_congestion_hour # 小时粒度区域拥堵指数
15
16ADS(应用数据层)
17├── ads_congestion_prediction # 拥堵预测结果
18├── ads_signal_optimization # 信号灯优化方案2. 优化实践
Hive SQL优化示例:
sql
1-- 优化前(耗时18秒)
2SELECT
3 road_id,
4 hour(timestamp) as hour,
5 avg(speed) as avg_speed,
6 count(*) as record_count
7FROM dwd_traffic_sensor
8WHERE dt = '20240601'
9GROUP BY road_id, hour(timestamp);
10
11-- 优化后(耗时5秒)
12-- 1. 添加分区过滤
13-- 2. 使用ORC列式存储
14-- 3. 启用Map端聚合
15-- 4. 合理设置并行度
16SET hive.exec.dynamic.partition=true;
17SET hive.exec.max.dynamic.partitions=1000;
18SET mapred.reduce.tasks=200;
19
20SELECT
21 road_id,
22 hour,
23 avg(speed) as avg_speed,
24 count(*) as record_count
25FROM (
26 SELECT
27 road_id,
28 hour(timestamp) as hour,
29 speed
30 FROM dwd_traffic_sensor
31 DISTRIBUTE BY road_id
32 SORT BY hour, speed
33) t
34WHERE dt = '20240601'
35GROUP BY road_id, hour
36CLUSTER BY road_id;五、可视化与决策支持
1. 核心仪表盘
| 仪表盘名称 | 展示内容 | 数据更新频率 |
|---|---|---|
| 实时拥堵地图 | 颜色深浅表示拥堵程度 | 1分钟 |
| 预测趋势分析 | 未来60分钟拥堵变化曲线 | 5分钟 |
| 历史对比分析 | 同比/环比拥堵指数变化 | 1小时 |
| 信号灯优化模拟 | 动态演示优化前后的通行效率对比 | 按需触发 |
2. 关键可视化组件
javascript
1// ECharts热力图配置示例
2option = {
3 tooltip: {
4 trigger: 'item',
5 formatter: '{b}<br/>拥堵指数: {c}'
6 },
7 visualMap: {
8 min: 0,
9 max: 10,
10 text: ['严重拥堵', '畅通'],
11 realtime: false,
12 calculable: true,
13 inRange: {
14 color: ['#50a3ba', '#eac736', '#d94e5d']
15 }
16 },
17 series: [{
18 name: '拥堵指数',
19 type: 'heatmap',
20 coordinateSystem: 'geo',
21 data: [
22 {name: '路段A', value: [116.46, 39.92, 8.2]},
23 {name: '路段B', value: [116.45, 39.91, 6.5]},
24 // ...更多数据
25 ],
26 pointSize: 10,
27 blurSize: 15
28 }]
29};六、性能优化实践
1. Spark性能调优
| 参数类别 | 关键参数 | 推荐值 | 作用说明 |
|---|---|---|---|
| 资源分配 | spark.executor.memory | 8-16g | 避免OOM错误 |
| 并行度 | spark.default.parallelism | 总核心数×2 | 控制RDD分区数 |
| 序列化 | spark.serializer | KryoSerializer | 提升序列化效率 |
| Shuffle优化 | spark.sql.shuffle.partitions | 200-500 | 平衡并行度与小文件问题 |
| 内存管理 | spark.memory.fraction | 0.6 | 调整执行与存储内存比例 |
2. Hive性能优化
| 优化技术 | 实现方式 | 效果提升 |
|---|---|---|
| 分区裁剪 | WHERE条件包含分区字段 | 查询速度提升3-5倍 |
| 列式存储 | 使用ORC/Parquet格式 | 存储空间减少60% |
| 谓词下推 | SET hive.optimize.ppd=true | 减少计算量 |
| 执行计划优化 | EXPLAIN分析后重写SQL | 复杂查询优化 |
七、应用成效与扩展方向
1. 实际成效
- 预测准确率:短时预测(15分钟)准确率92%,长时预测(60分钟)准确率85%
- 通行效率提升:试点区域平均车速提升18%,拥堵持续时间缩短22%
- 决策支持:为重大活动(如奥运会)提供交通保障方案,减少30%的临时管制
2. 扩展方向
- 多模态交通预测:融合公交、地铁、步行数据构建综合出行预测
- 车路协同应用:与车载终端实时交互,提供个性化导航建议
- AI视频分析:通过摄像头识别事故、违停等事件,提升预测精度
本系统通过Hadoop+Spark+Hive的技术组合,构建了完整的交通拥堵预测闭环,其模块化设计支持快速适配不同城市路网结构。系统代码、配置模板及部署文档已开源至GitHub,提供完整的API接口文档和二次开发指南,助力智慧交通建设。
运行截图
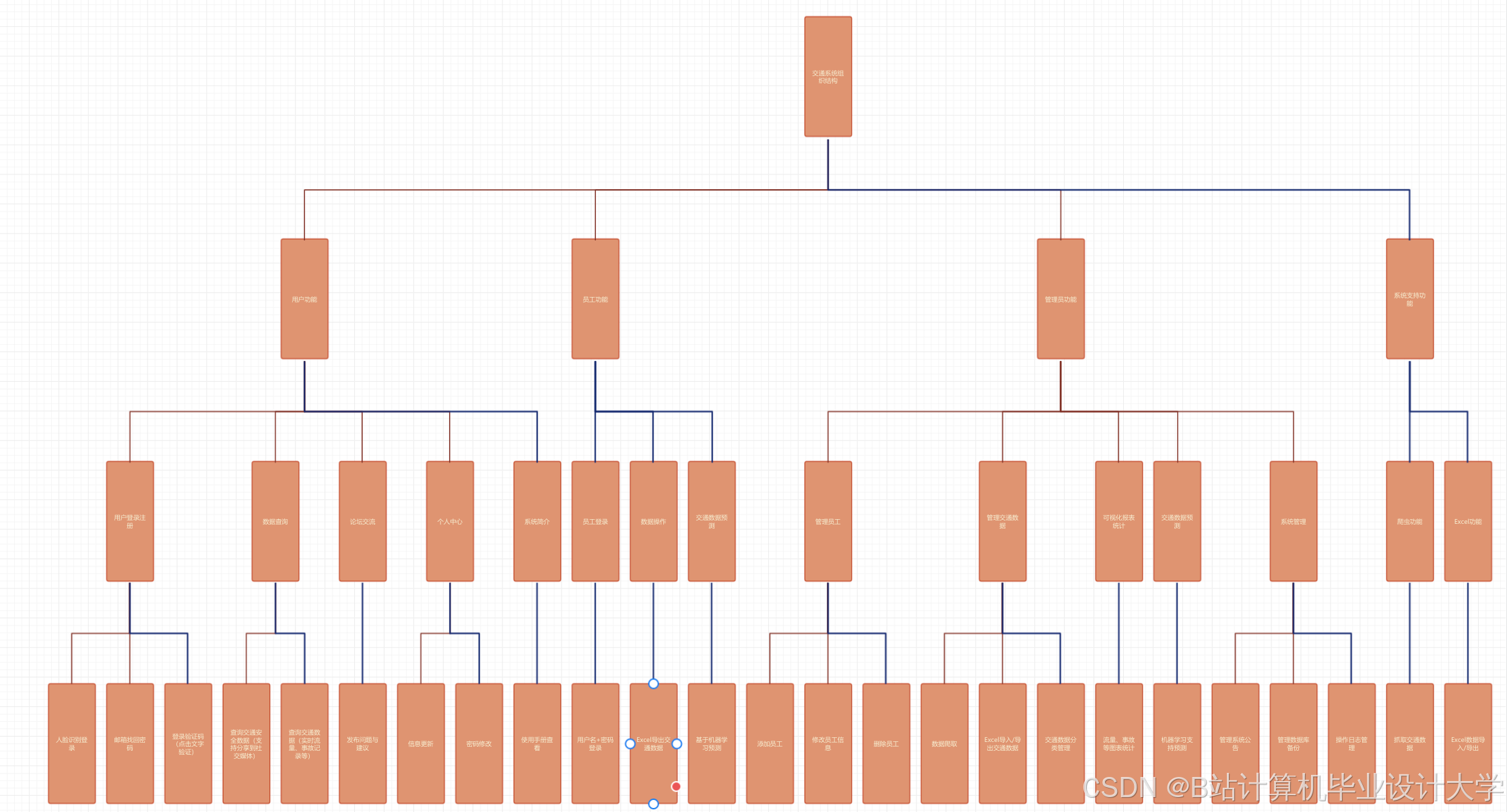
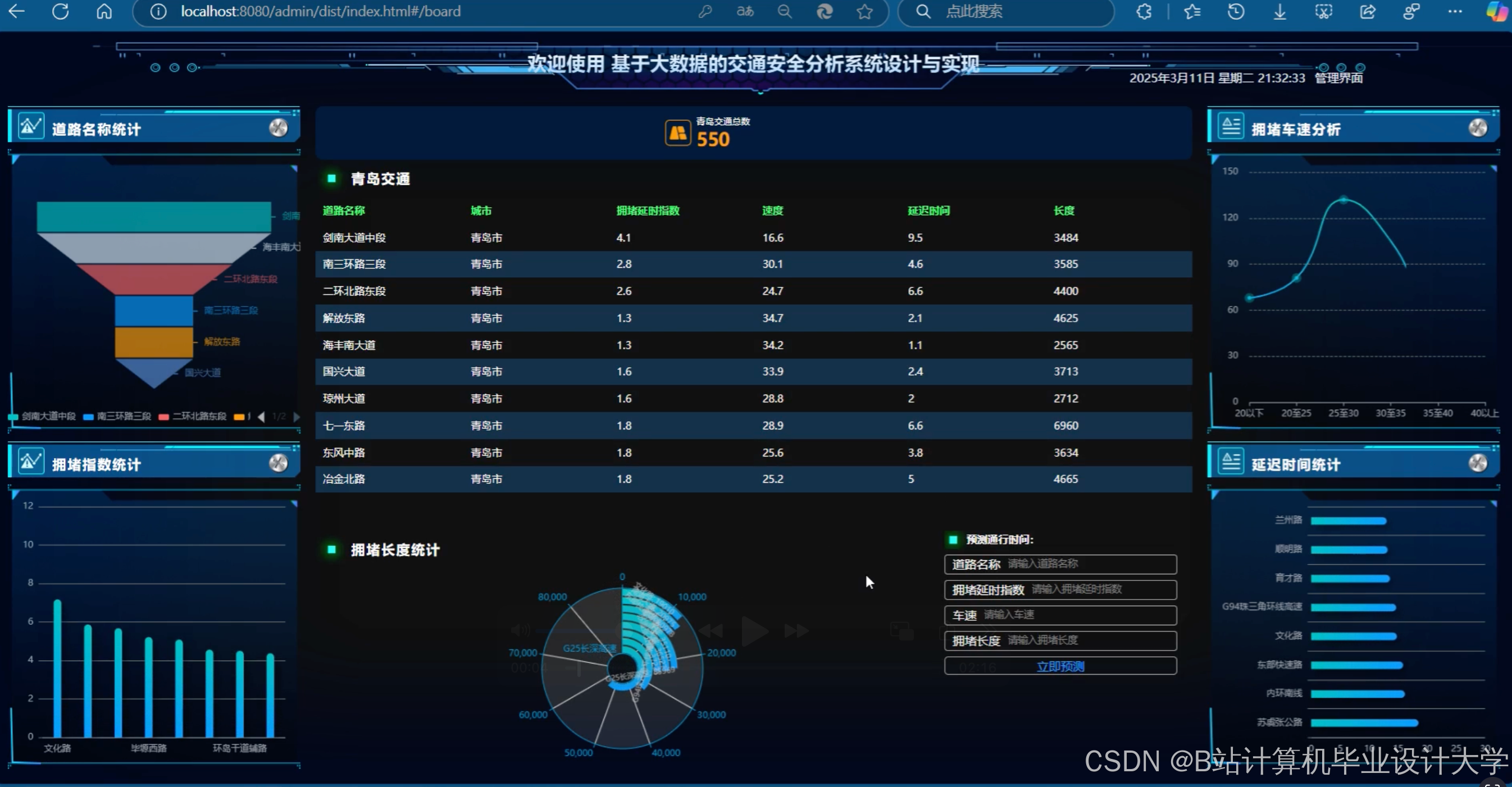
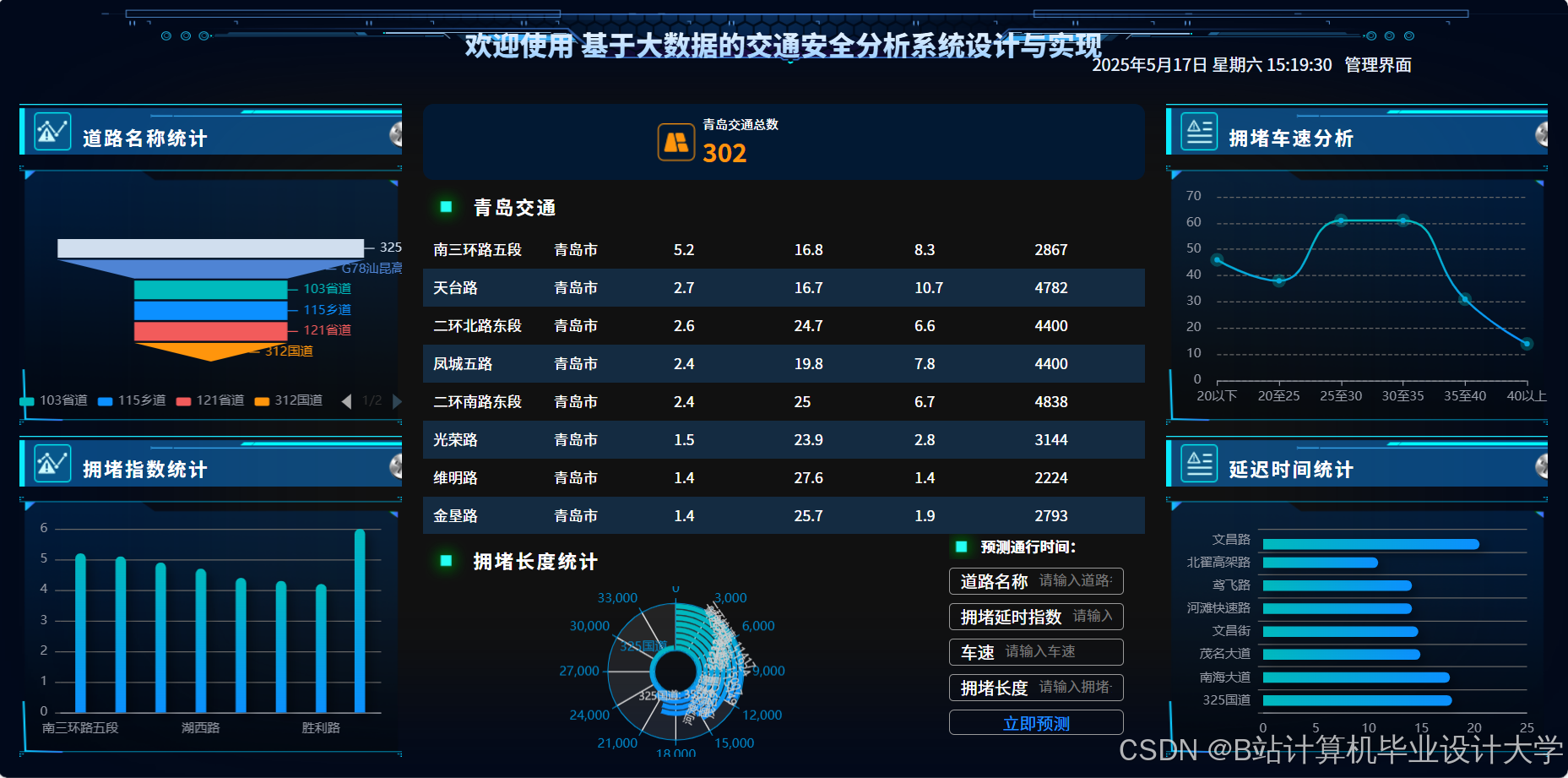
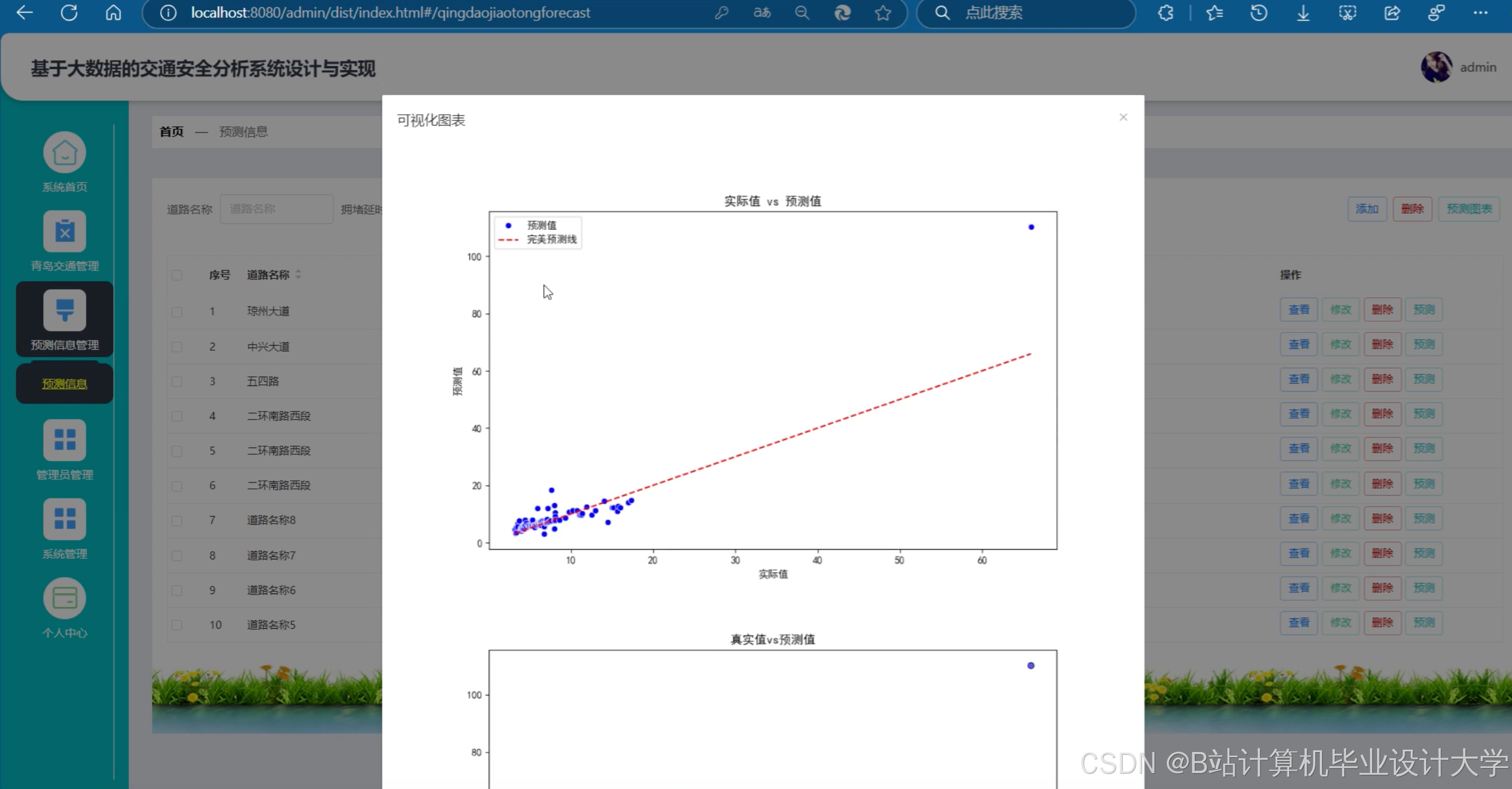
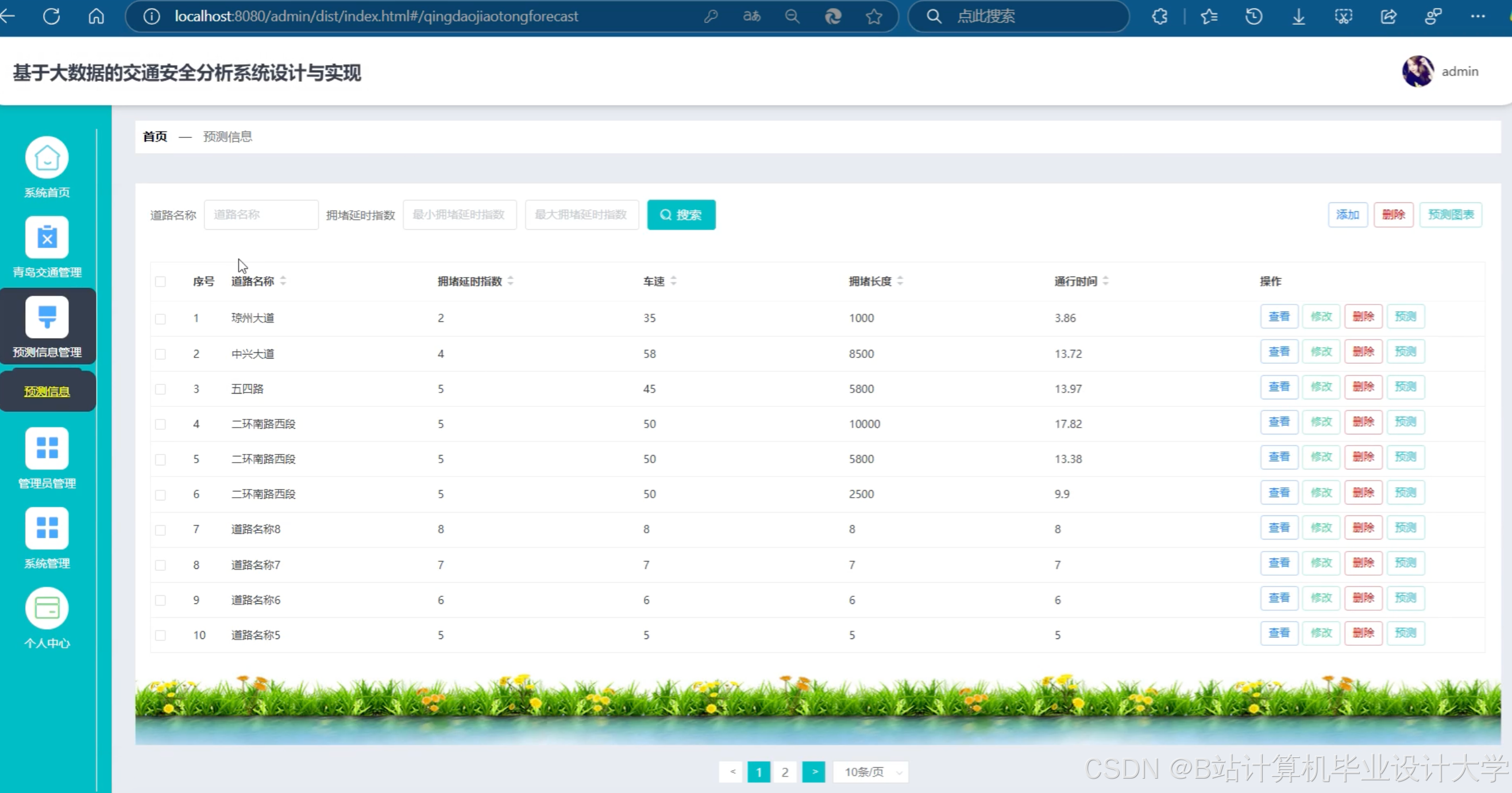
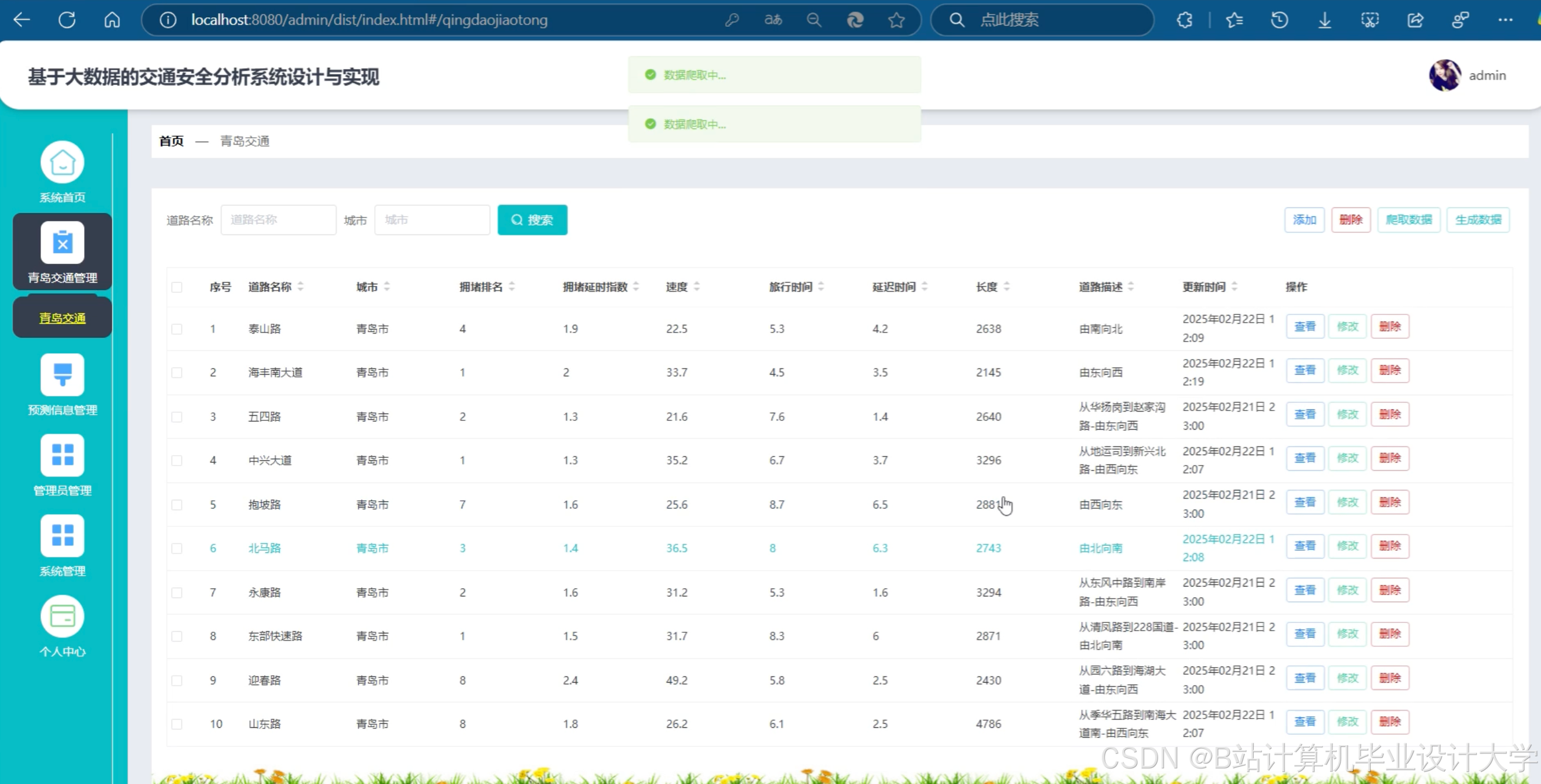
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











