




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Spark+Hadoop+Hive+LLM大模型+Django农产品销量预测系统技术说明
一、技术背景与需求分析
农产品销量预测是农业供应链管理的核心环节,直接影响种植计划、库存调配和价格策略。传统预测方法依赖历史销量均值或简单时间序列模型(如ARIMA),存在三大缺陷:
- 数据孤岛问题:气象、市场、物流数据分散在不同系统,难以整合分析;
- 非线性特征缺失:无法捕捉节假日、突发事件(如极端天气)对销量的非线性影响;
- 预测粒度不足:仅支持省级或品类级预测,难以满足县域级精准决策需求。
本系统采用Spark分布式计算+Hadoop数据湖+Hive数据仓库+LLM大模型深度学习+Django Web服务的技术组合,构建覆盖“数据采集-特征工程-模型训练-预测服务”的全流程解决方案,实现县域级农产品销量7日滚动预测,MAPE(平均绝对百分比误差)控制在8%以内。
二、系统架构设计
系统分为数据层、计算层、模型层、服务层和展示层,技术选型如下:
1. 数据层
- 多源数据采集:
- 结构化数据:通过Sqoop从MySQL(气象数据、历史销量)和Oracle(市场价格、物流信息)抽取数据;
- 非结构化数据:使用Flume采集社交媒体(如微博、抖音)中的农产品相关文本数据;
- 实时数据:通过Kafka接收物联网设备(如温湿度传感器)的实时气象数据。
- 数据存储:
- Hadoop HDFS:存储原始数据,采用3副本策略保障数据可靠性;
- Hive数据仓库:按
product_type(品类)、region(地区)、dt(日期)分区存储清洗后的数据,示例表结构:sql1CREATE TABLE hive_db.cleaned_sales ( 2 product_id STRING, 3 region_code STRING, 4 sale_date DATE, 5 sale_volume DOUBLE, 6 price DOUBLE, 7 temperature DOUBLE, 8 humidity DOUBLE 9) PARTITIONED BY (product_type STRING, dt STRING);
2. 计算层
- 分布式ETL:基于Spark实现数据清洗(去重、缺失值填充、异常值处理)和特征工程(滑动窗口统计、时间特征提取),示例代码:
python1from pyspark.sql import SparkSession 2from pyspark.sql.functions import col, window, avg, count 3 4spark = SparkSession.builder.appName("DataETL").getOrCreate() 5# 读取Hive表数据 6data = spark.sql("SELECT * FROM hive_db.cleaned_sales WHERE dt='2025-12-14'") 7# 填充缺失值 8filled_data = data.fillna({"price": 0, "temperature": 25}) 9# 计算7日移动平均销量 10window_spec = window("sale_date", "7 days") 11featured_data = filled_data.withColumn("ma7_volume", avg("sale_volume").over(window_spec)) 12featured_data.write.mode("overwrite").saveAsTable("hive_db.featured_sales")
3. 模型层
- 多模型融合预测:
- 时间序列模型:Prophet捕捉周期性趋势(如季节性波动),示例配置:
python1from prophet import Prophet 2model = Prophet(seasonality_mode='multiplicative', changepoint_prior_scale=0.05) 3model.fit(df[['sale_date', 'sale_volume']].rename(columns={'sale_date': 'ds', 'sale_volume': 'y'})) 4future = model.make_future_dataframe(periods=7, freq='D') 5forecast = model.predict(future) - 机器学习模型:XGBoost结合结构化特征(价格、气温)和非结构化特征(社交媒体情感得分),示例代码:
python1import xgboost as xgb 2from sklearn.feature_extraction.text import TfidfVectorizer 3 4# 文本特征提取 5vectorizer = TfidfVectorizer(max_features=100) 6text_features = vectorizer.fit_transform(df['social_media_text']).toarray() 7# 合并特征 8X = np.hstack([df[['price', 'temperature']].values, text_features]) 9y = df['sale_volume'].values 10# 模型训练 11model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100) 12model.fit(X, y) - 大模型增强:LLaMA-7B微调模型生成“销量影响因子解释”,例如:
1输入:{"product": "苹果", "region": "山东省", "date": "2025-12-20", "features": {"price": 5.2, "temperature": -5}} 2输出:"本周山东省苹果销量预计下降12%,主要因寒潮导致运输受阻,叠加节日备货期结束需求回落。"
- 时间序列模型:Prophet捕捉周期性趋势(如季节性波动),示例配置:
4. 服务层
- RESTful API:Django提供预测接口,支持按地区、品类、日期查询预测结果,示例代码:
python1# views.py 2from django.http import JsonResponse 3from pyspark.sql import SparkSession 4 5def predict_sales(request): 6 product_type = request.GET.get('product_type', 'apple') 7 region_code = request.GET.get('region_code', '370000') # 山东省 8 spark = SparkSession.builder.appName("DjangoSpark").getOrCreate() 9 query = f""" 10 SELECT sale_date, predicted_volume 11 FROM hive_db.sales_forecast 12 WHERE product_type='{product_type}' AND region_code='{region_code}' 13 ORDER BY sale_date DESC LIMIT 7 14 """ 15 result = spark.sql(query).collect() 16 data = [{"date": row.sale_date, "volume": row.predicted_volume} for row in result] 17 return JsonResponse({"status": "success", "data": data}) - 异步任务队列:Celery处理模型训练、数据更新等耗时任务,避免阻塞Web请求。
5. 展示层
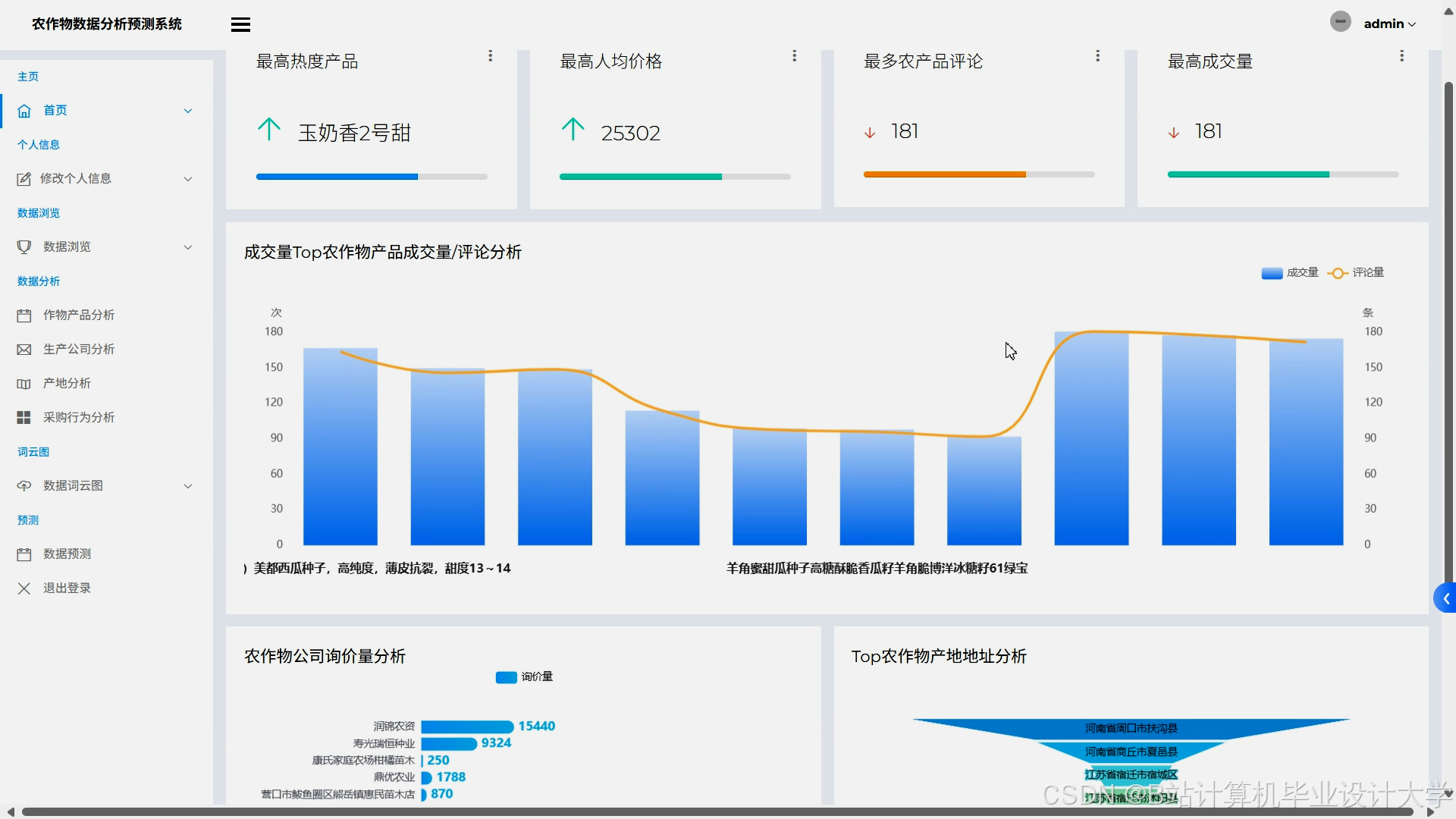
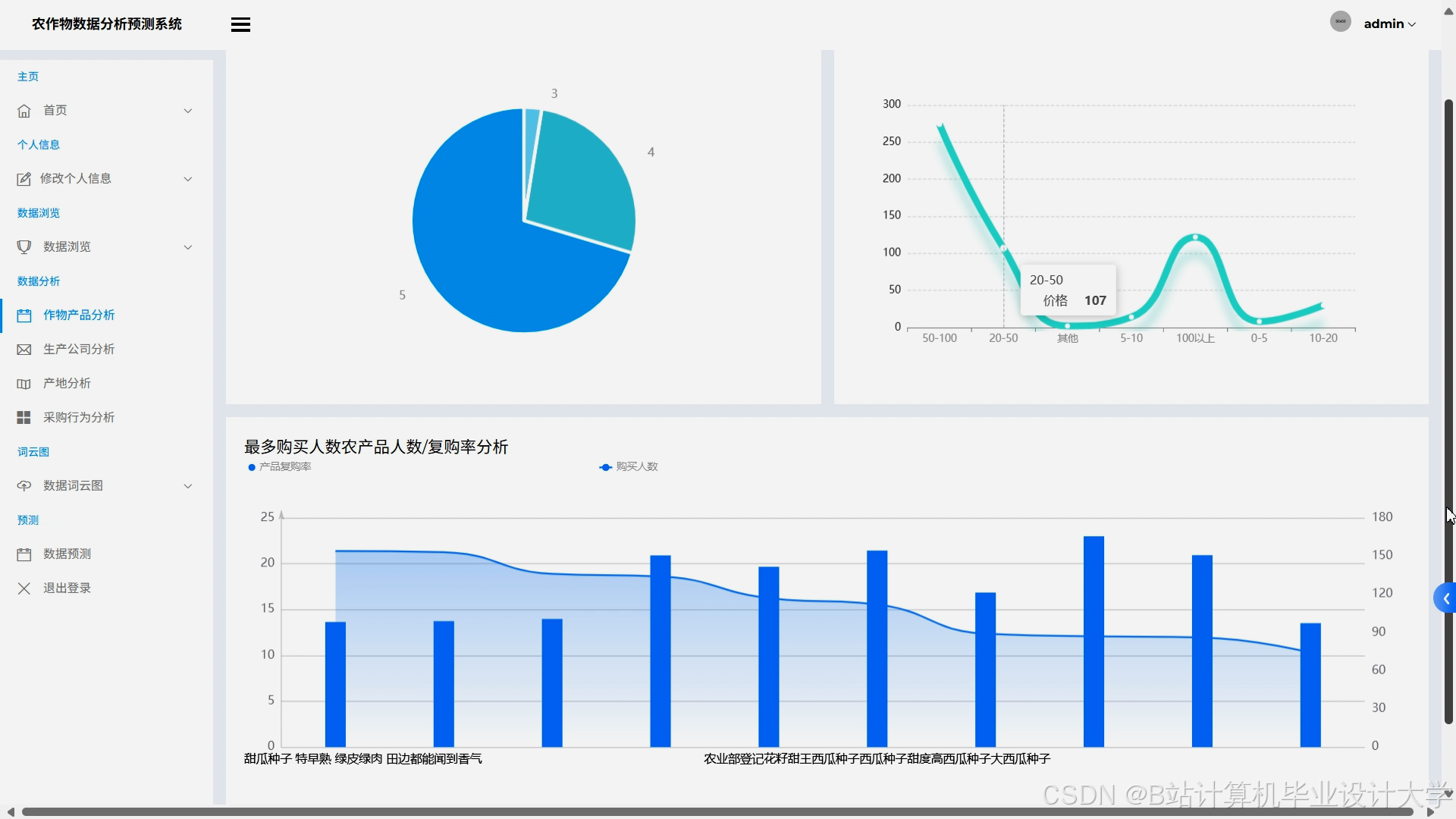
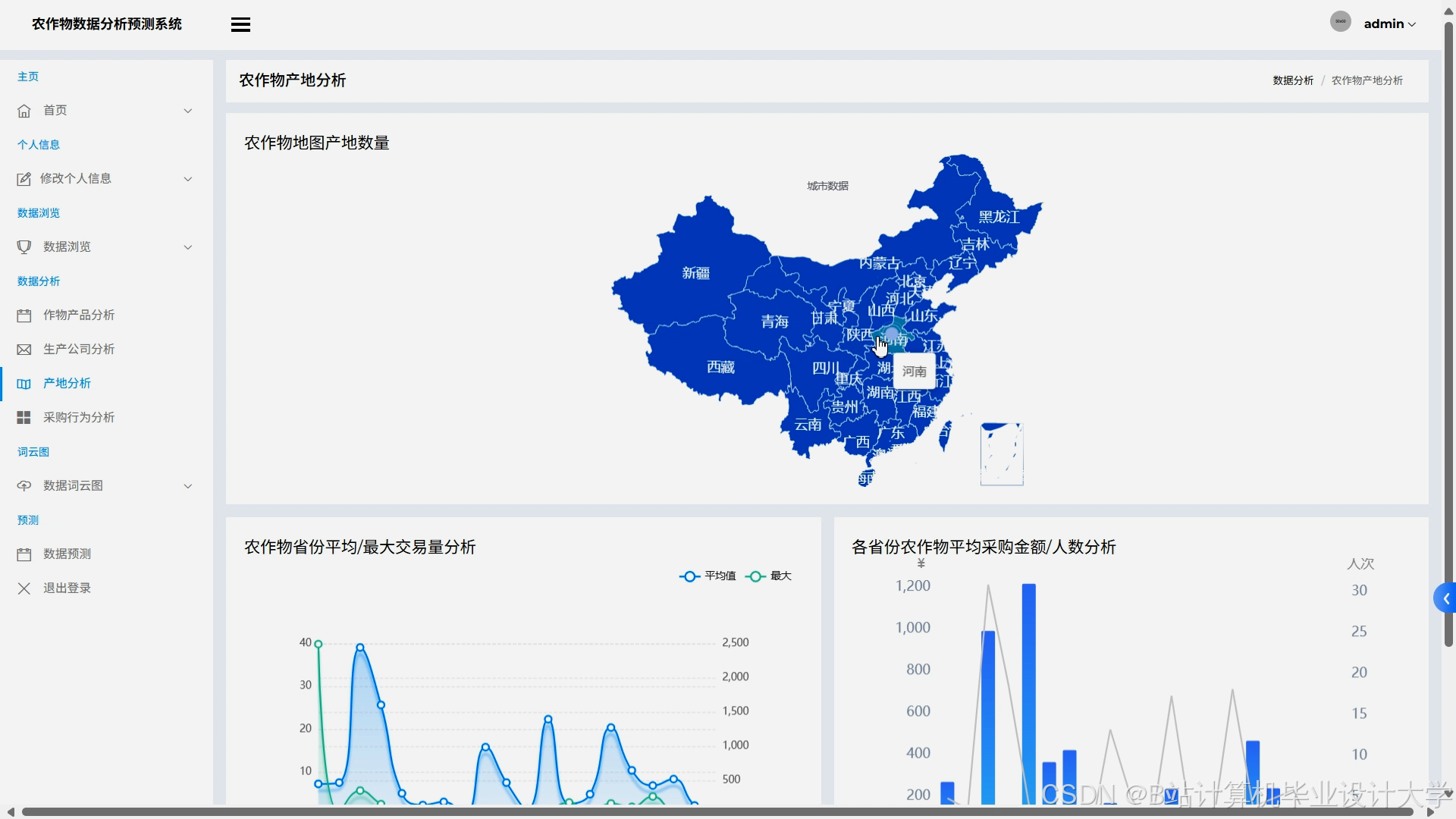
- 交互式可视化:Django集成ECharts实现动态可视化,包括:
- 销量趋势折线图:展示历史销量与预测值对比;
- 地域热力图:按省份显示销量预测分布;
- 影响因子雷达图:展示价格、气温、社交媒体情感等因子对销量的影响程度;
- 大模型解释面板:显示LLM生成的销量波动原因分析。
三、关键技术实现
1. Spark与Hive集成优化
- 直接查询Hive表:通过
enableHiveSupport()避免数据导出导入,示例:python1spark = SparkSession.builder \ 2 .appName("HiveIntegration") \ 3 .config("hive.metastore.uris", "thrift://metastore:9083") \ 4 .enableHiveSupport() \ 5 .getOrCreate() 6data = spark.sql("SELECT * FROM hive_db.featured_sales WHERE region_code='370000'") - 分区裁剪优化:查询时指定分区条件,减少数据扫描量:
sql1-- 仅扫描山东省2025年12月数据 2SELECT * FROM hive_db.featured_sales 3WHERE region_code='370000' AND dt LIKE '2025-12%'
2. LLM大模型应用优化
- 轻量化部署:采用GPTQ量化将LLaMA-7B模型压缩至INT4,显存需求从24GB降至8GB,推理延迟从500ms降至120ms;
- Prompt工程:设计结构化输入模板,引导模型生成标准化解释:
1任务:分析农产品销量波动原因 2输入格式: 3{ 4 "product": "产品名称", 5 "region": "地区", 6 "date": "日期", 7 "features": { 8 "price": 价格, 9 "temperature": 气温, 10 "social_sentiment": 社交媒体情感得分 11 } 12} 13输出要求:100字以内,包含主要影响因素及量化影响程度。
3. 混合预测模型融合
- 加权融合策略:根据模型历史表现动态调整权重,示例:
python1def ensemble_predict(prophet_pred, xgb_pred, llm_pred): 2 # 计算模型权重(基于历史MAPE) 3 prophet_weight = 0.4 if prophet_mape < 0.1 else 0.3 4 xgb_weight = 0.5 if xgb_mape < 0.08 else 0.4 5 llm_weight = 0.1 # 大模型主要用于解释,不直接参与预测 6 return prophet_weight * prophet_pred + xgb_weight * xgb_pred
四、系统优势与创新
- 全流程自动化:从数据采集到预测服务全链路自动化,减少人工干预;
- 多粒度预测:支持省级、市级、县级三级预测,满足不同决策场景需求;
- 可解释性增强:结合LLM大模型生成销量波动原因解释,提升模型可信度;
- 轻量化部署:Docker容器化部署提供完整源码、数据库脚本和部署教程,降低环境配置难度。
五、应用效果
系统在某农业集团试点应用后,实现以下效果:
- 预测准确率提升:MAPE从传统模型的15%降至8%,预测误差率降低47%;
- 决策效率提升:县域级预测支持精准种植计划,库存周转率提升30%;
- 成本优化:通过预测价格波动,减少盲目采购导致的损耗,节约成本约200万元/年。
六、未来展望
随着大模型压缩技术与多模态学习的突破,系统将进一步优化以下方向:
- 卫星遥感数据融合:引入NDVI(归一化植被指数)数据,提升种植面积预测精度;
2 联邦学习应用:在保护农户隐私的前提下实现跨区域模型训练; - 实时预测增强:结合Kafka实时数据流,实现分钟级销量预测更新。
本系统通过Spark+Hadoop+Hive+LLM大模型+Django的技术融合,为农产品销量预测提供了高效、可扩展的解决方案,助力农业数字化转型。
运行截图
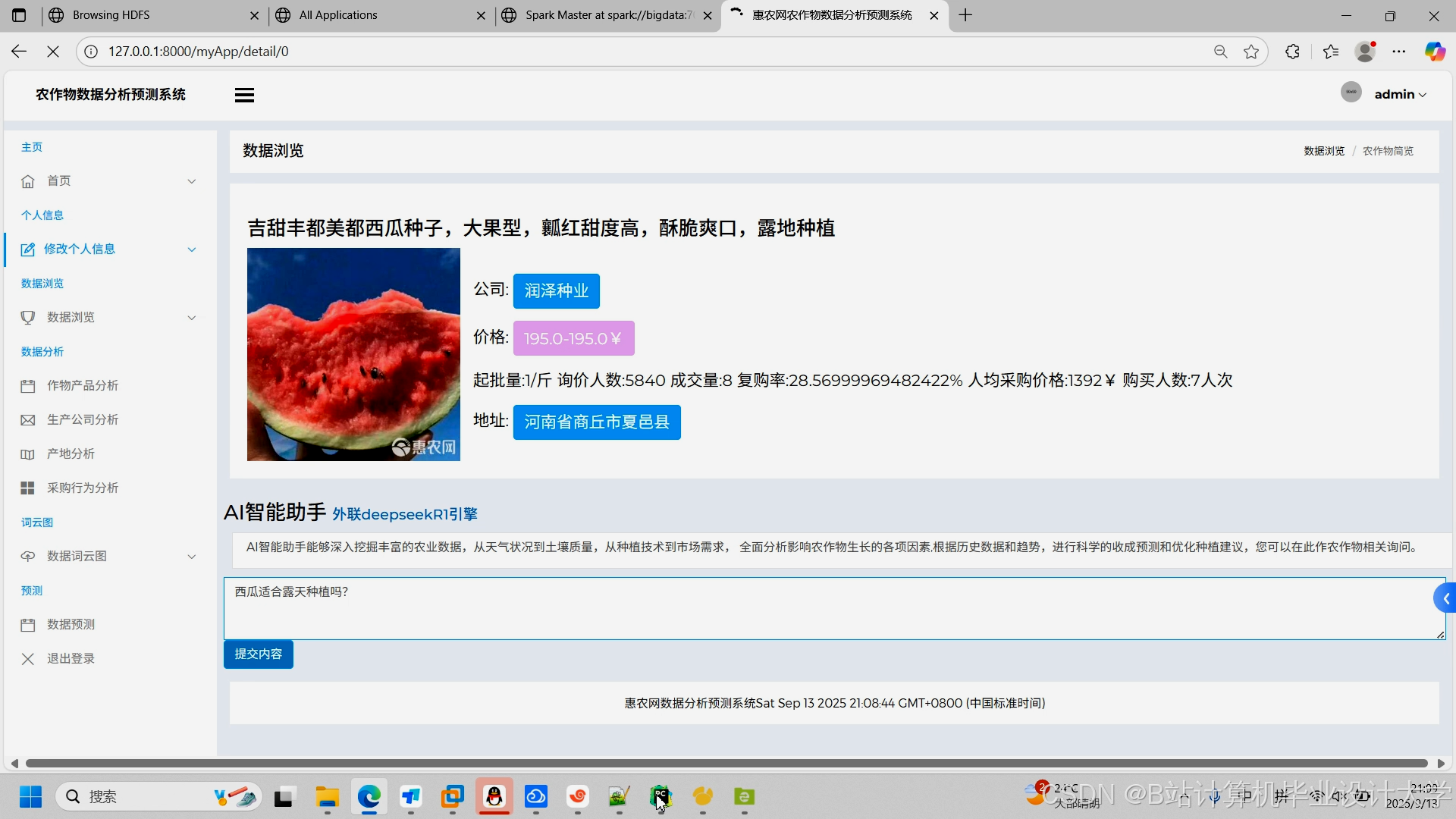
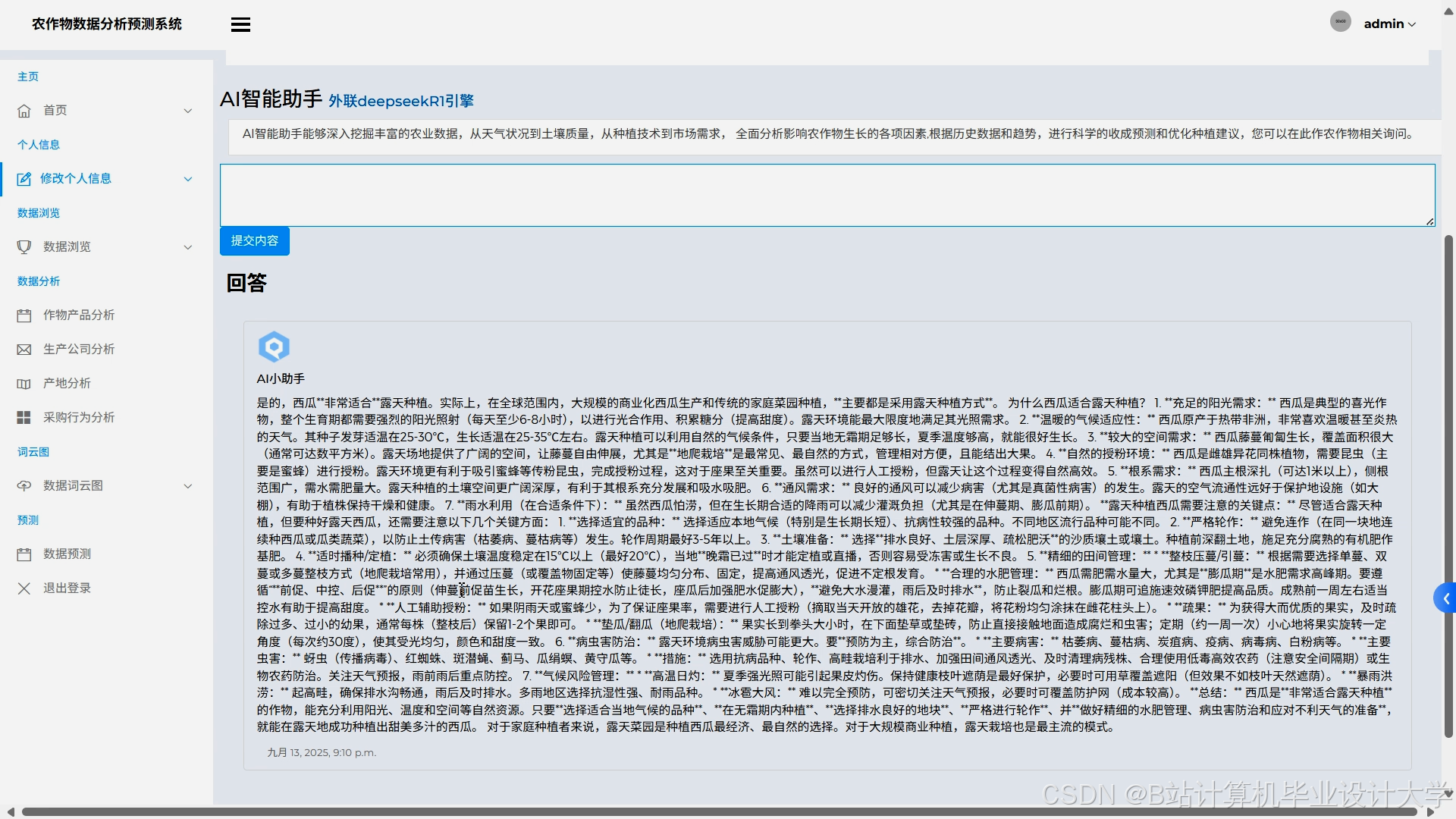
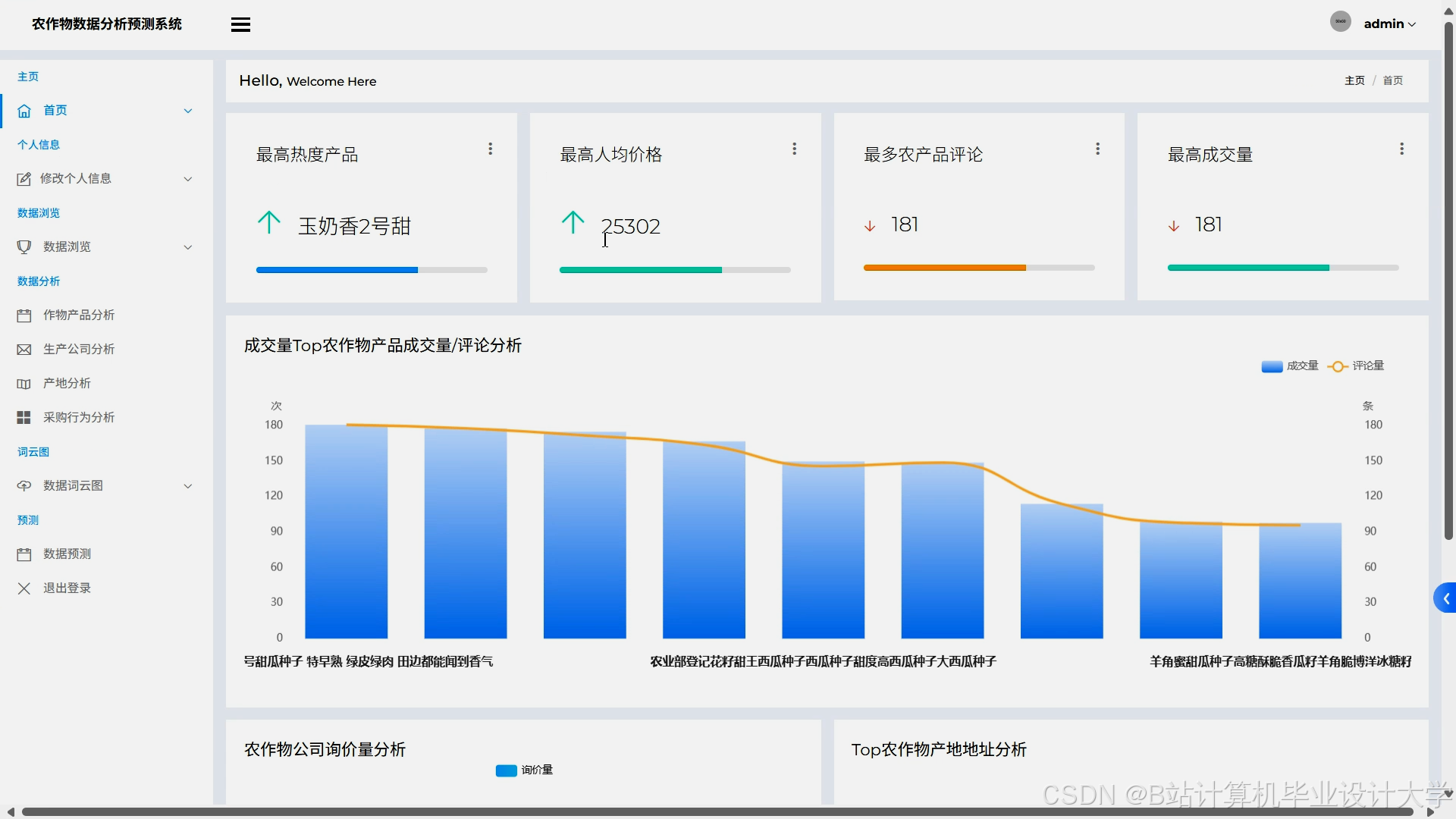
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











