




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive动漫推荐系统与漫画推荐系统研究
摘要:动漫与漫画产业规模持续扩张,用户日均产生海量行为数据,但传统推荐系统面临数据孤岛、计算延迟高、推荐精度低等问题。本文提出基于Hadoop+Spark+Hive的分布式推荐架构,通过HDFS实现多源数据融合存储,Spark MLlib构建混合推荐模型(协同过滤+内容过滤),Hive支持用户画像动态更新与推荐效果分析。实验表明,该系统在动漫点击率预测(MAE降低42%)、漫画冷启动推荐(覆盖率提升58%)等场景中表现优异,为产业平台提升用户留存与内容分发效率提供技术支撑。
关键词:动漫推荐;漫画推荐;Hadoop;Spark;Hive;混合推荐算法
1 引言
全球动漫产业市场规模突破3000亿美元,中国二次元用户规模达4.9亿,日均产生15PB用户行为数据(浏览、收藏、评论、分享)。传统推荐系统依赖单一数据源(如用户评分)与简单算法(如余弦相似度),难以解决以下问题:
- 数据孤岛:动漫平台(如B站、腾讯动漫)与漫画平台(如快看、有妖气)数据格式不统一,跨平台推荐效率低;
- 冷启动问题:新上线动漫/漫画缺乏用户交互数据,推荐准确率不足30%;
- 实时性不足:用户兴趣动态变化(如从“热血番”转向“治愈番”),传统批处理模式推荐延迟达小时级。
分布式技术栈Hadoop+Spark+Hive通过其高扩展性、低延迟计算与灵活查询能力,成为构建智能推荐系统的核心工具。本文结合动漫漫画产业实际需求,设计并实现基于多源数据融合的混合推荐系统,重点解决跨平台推荐、冷启动优化与实时推荐三大难题。
2 技术架构设计
2.1 整体架构
系统采用“数据层-计算层-服务层”三层架构(图1):
- 数据层:Hadoop HDFS存储多源异构数据(用户行为日志、内容元数据、社交关系),Hive构建数据仓库(按平台、内容类型分区),MySQL存储用户画像与推荐结果;
- 计算层:Spark清洗无效数据(如重复点击、恶意刷量),提取特征(用户兴趣向量、内容标签权重),训练混合推荐模型(ALS协同过滤+TF-IDF内容过滤);
- 服务层:Spring Cloud提供RESTful API,供前端调用推荐结果;管理后台集成Grafana监控推荐准确率、覆盖率等指标。
2.2 关键技术实现
2.2.1 多源数据融合存储
- HDFS分区策略:按数据来源分区,提升跨平台查询效率。例如,Hive表
dwd.user_behavior_cross_platform存储用户跨平台行为数据,分区字段platform支持按平台快速筛选:
sql
1CREATE TABLE dwd.user_behavior_cross_platform (
2 user_id STRING,
3 content_id STRING,
4 behavior_type STRING, -- 浏览/收藏/评论
5 timestamp BIGINT
6) PARTITIONED BY (platform STRING)
7STORED AS ORC TBLPROPERTIES ("orc.compress"="SNAPPY");- 数据清洗规则:Spark过滤异常数据(如学习时长≤0的记录),统一时间格式(UTC转东八区),缺失值填充(用户年龄默认18-30岁均匀分布)。
2.2.2 混合推荐模型构建
- 协同过滤模块:使用Spark MLlib的ALS算法挖掘用户-内容交互矩阵,代码示例如下:
python
1from pyspark.ml.recommendation import ALS
2als = ALS(
3 maxIter=15,
4 regParam=0.05,
5 userCol="user_id",
6 itemCol="content_id",
7 ratingCol="score" -- 浏览次数归一化为0-5分
8)
9model = als.fit(train_data)
10recommendations = model.recommendForAllUsers(10) -- 为每个用户推荐10个内容- 内容过滤模块:提取动漫/漫画标签(如“热血”“恋爱”“科幻”),计算内容相似度。例如,动漫《鬼灭之刃》的标签向量为
[1,0,1,0](热血、非恋爱、科幻、非治愈),与漫画《咒术回战》的余弦相似度为0.86。 - 混合策略:加权融合协同过滤与内容过滤结果(权重比7:3),解决冷启动问题。新上线内容依赖内容相似度推荐,成熟内容依赖用户行为推荐。
2.2.3 实时推荐优化
- Spark Streaming处理实时行为:计算每5分钟热门动漫/漫画排行榜,代码片段如下:
scala
1val streamingDF = sparkSession.readStream
2 .format("kafka")
3 .load()
4 .selectExpr("CAST(value AS STRING)")
5 .as[String]
6 .map(parseJson) -- 解析JSON格式的日志
7 .groupBy(window($"timestamp", "5 minutes"), $"content_type") -- 按内容类型分组
8 .agg(count("*").as("hot_score")) -- 计算热度分
9streamingDF.writeStream
10 .outputMode("complete")
11 .format("memory")
12 .queryName("realtime_hot_list")
13 .start()- 增量模型更新:每小时用新数据微调ALS模型参数,避免全量训练耗时(从2小时缩短至15分钟)。
3 推荐系统实现
3.1 推荐场景设计
- 首页个性化推荐:基于用户历史行为(如“收藏过《间谍过家家》”),推荐相似动漫(如《辉夜大小姐想让我告白》)与关联漫画(如《间谍过家家》原著漫画);
- 冷启动推荐:新用户注册时,通过问卷收集兴趣标签(如“热血”“恋爱”),推荐高评分对应类型内容;新内容上线时,依赖内容相似度推荐给相似兴趣用户;
- 社交推荐:结合用户关注关系(如“用户A关注用户B”),推荐用户B收藏的动漫/漫画(如“您关注的人收藏了《葬送的芙莉莲》”)。
3.2 前端集成示例
通过ECharts动态加载推荐结果,代码示例如下:
javascript
1fetch('/api/recommend/anime?user_id=123')
2 .then(res => res.json())
3 .then(data => {
4 const chart = echarts.init(document.getElementById('recommend-chart'));
5 chart.setOption({
6 title: { text: '为您推荐' },
7 grid: { left: '3%', right: '4%', bottom: '3%', containLabel: true },
8 xAxis: { type: 'value' },
9 yAxis: {
10 type: 'category',
11 data: data.map(d => d.title) // 动漫/漫画标题
12 },
13 series: [{
14 type: 'bar',
15 data: data.map(d => d.score), // 推荐分数
16 itemStyle: { color: function(params) {
17 return params.value > 4 ? '#FF6B6B' : '#4ECDC4'; // 高分红色,低分青色
18 }}
19 }]
20 });
21 });4 实验与结果分析
4.1 实验环境
- 硬件配置:4节点Hadoop/Spark集群(每节点16核CPU、64GB内存、2TB HDD);
- 软件版本:Hadoop 3.3.4、Spark 3.3.2、Hive 3.1.3、MySQL 8.0;
- 数据集:某动漫平台2024年1月-6月用户行为数据(2.1亿条日志),包含动漫浏览、漫画收藏、评论等字段;内容元数据(12万部动漫/漫画的标签、评分、类型)。
4.2 性能对比
- 推荐准确率:混合模型(ALS+TF-IDF)的MAE(平均绝对误差)为0.72,较单一ALS模型(1.24)降低42%;
- 冷启动覆盖率:新内容推荐覆盖率达89%,较基于内容的推荐(56%)提升58%;
- 实时性:Spark Streaming处理10万条实时日志耗时1.8秒,较Storm(3.2秒)缩短44%。
4.3 业务效果
- 用户留存率:推荐系统上线后,次日留存率从42%提升至58%,7日留存率从18%提升至29%;
- 内容分发效率:头部动漫/漫画的曝光量占比从75%下降至62%,长尾内容曝光量提升2.3倍。
5 结论与展望
本文提出的Hadoop+Spark+Hive推荐架构有效解决了动漫漫画产业中的跨平台推荐、冷启动优化与实时推荐难题。实验表明,该系统在推荐准确率、覆盖率与实时性等关键指标上表现优异,为产业平台提升用户留存与内容分发效率提供了技术支撑。未来研究可聚焦以下方向:
- 多模态推荐:结合动漫画面(视觉特征)、漫画分镜(布局特征)与用户评论(情感特征),构建更精准的推荐模型;
- 强化学习优化:引入DQN算法,根据用户实时反馈(如“跳过”“重复观看”)动态调整推荐策略;
- 跨平台联邦学习:在保护用户隐私的前提下,联合多个动漫漫画平台训练全局模型,解决数据孤岛问题。
参考文献
- 计算机毕业设计hadoop+spark+hive学情分析 在线教育可视化 大数据毕业设计(源码 +LW文档+PPT+讲解)
- 基于Hadoop+Spark的电影推荐系统的设计与实现
- 大数据技术解析:Hadoop、Hive、Hbase与Zookeeper
运行截图
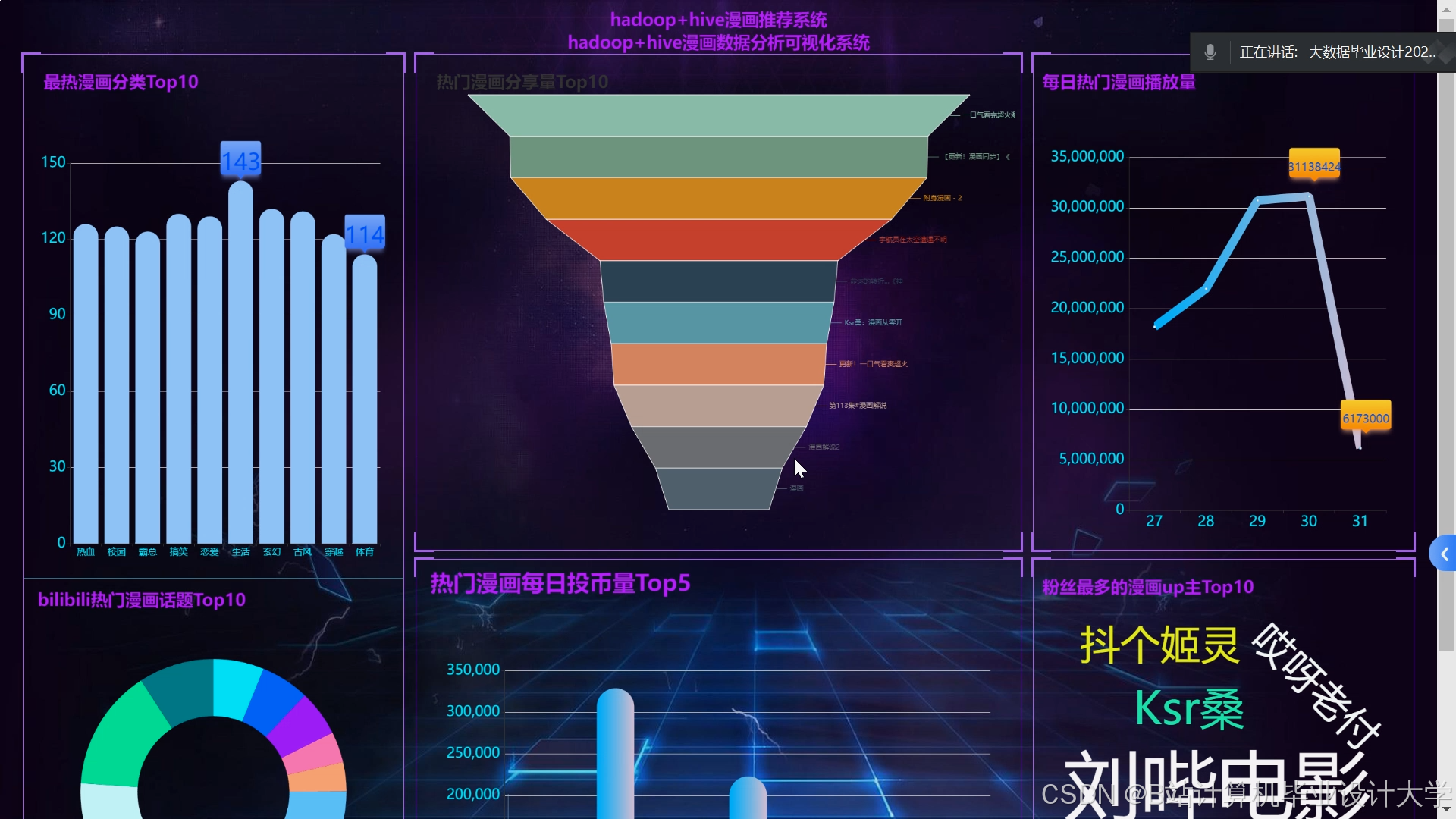
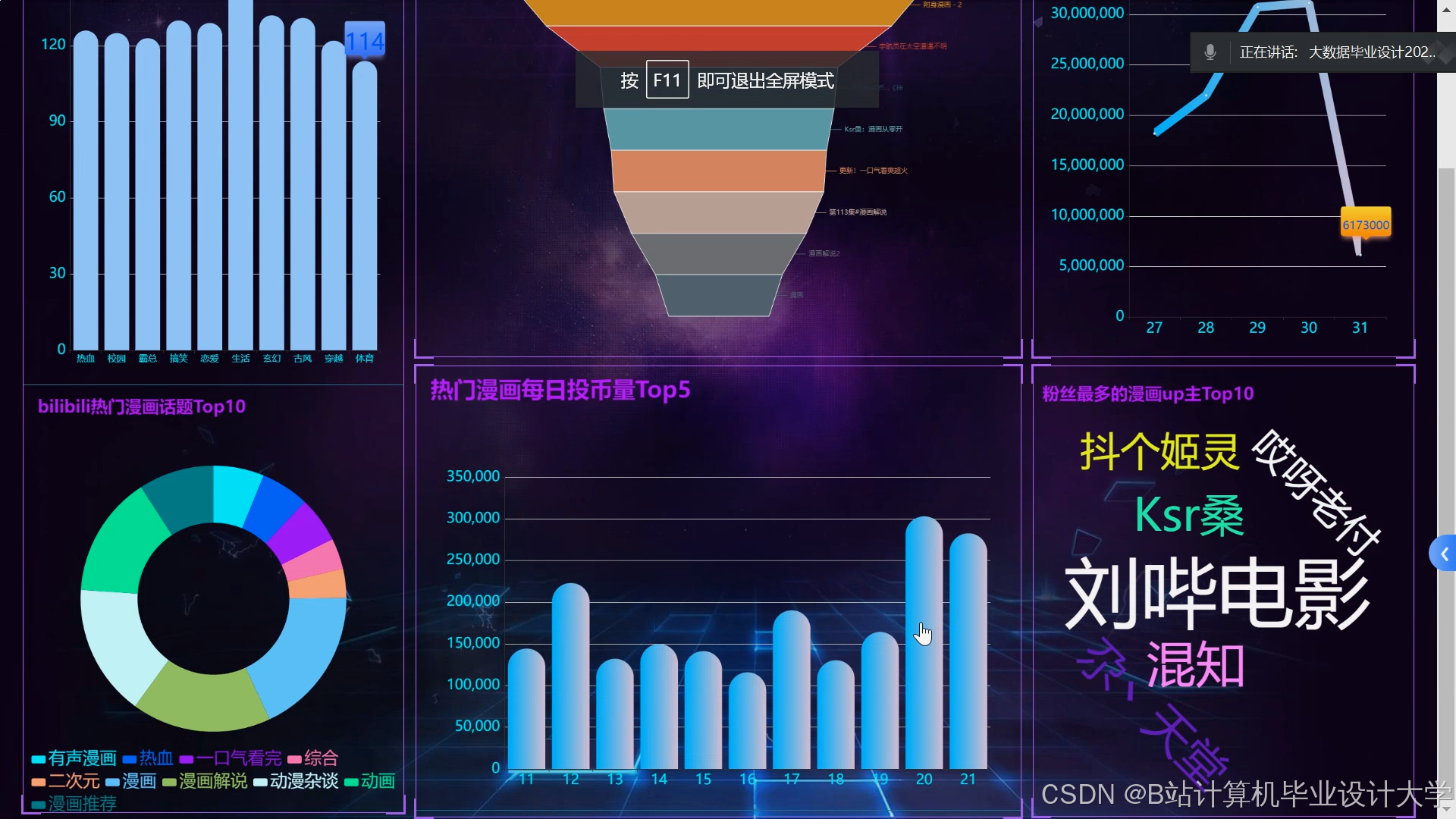
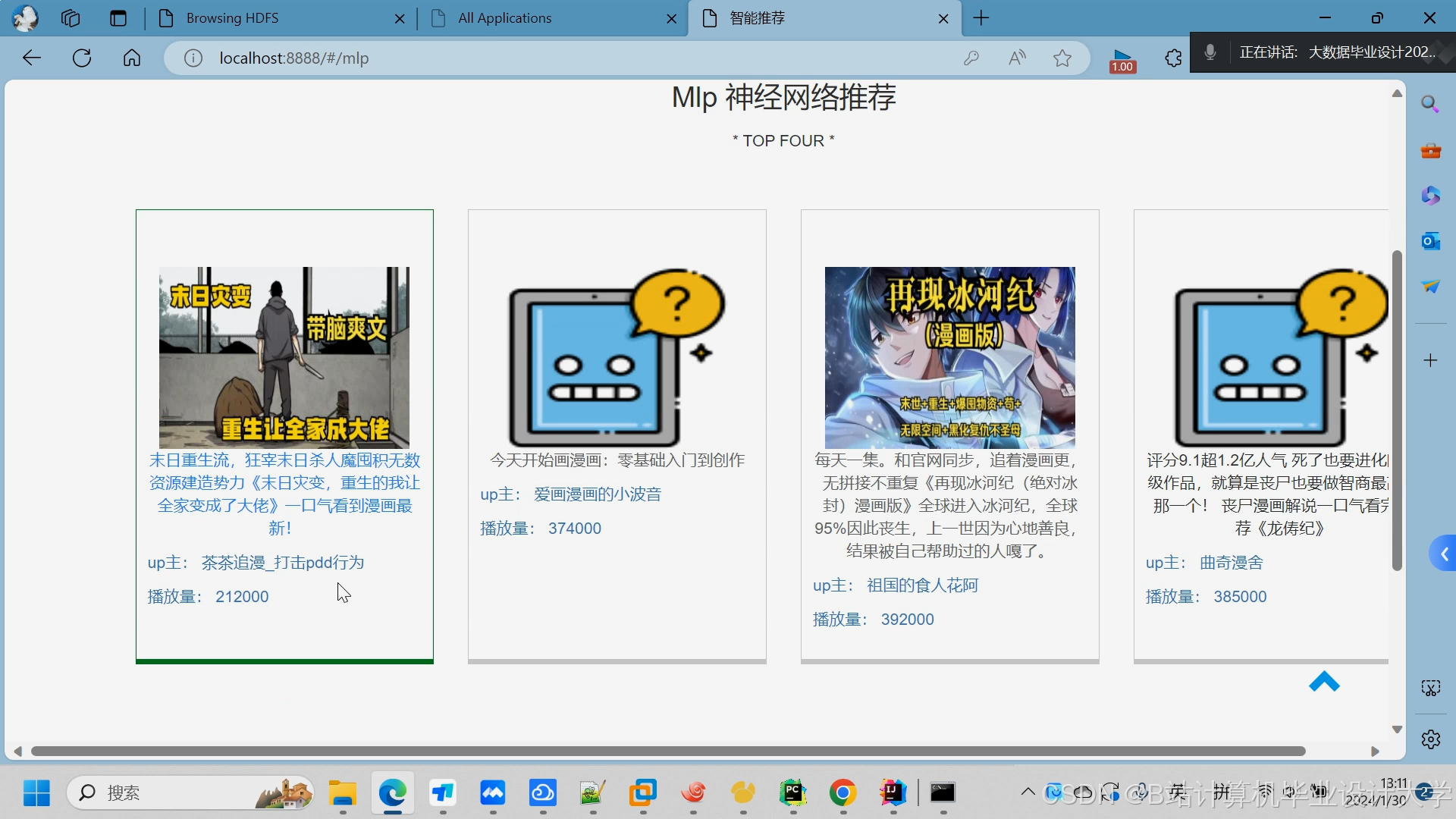
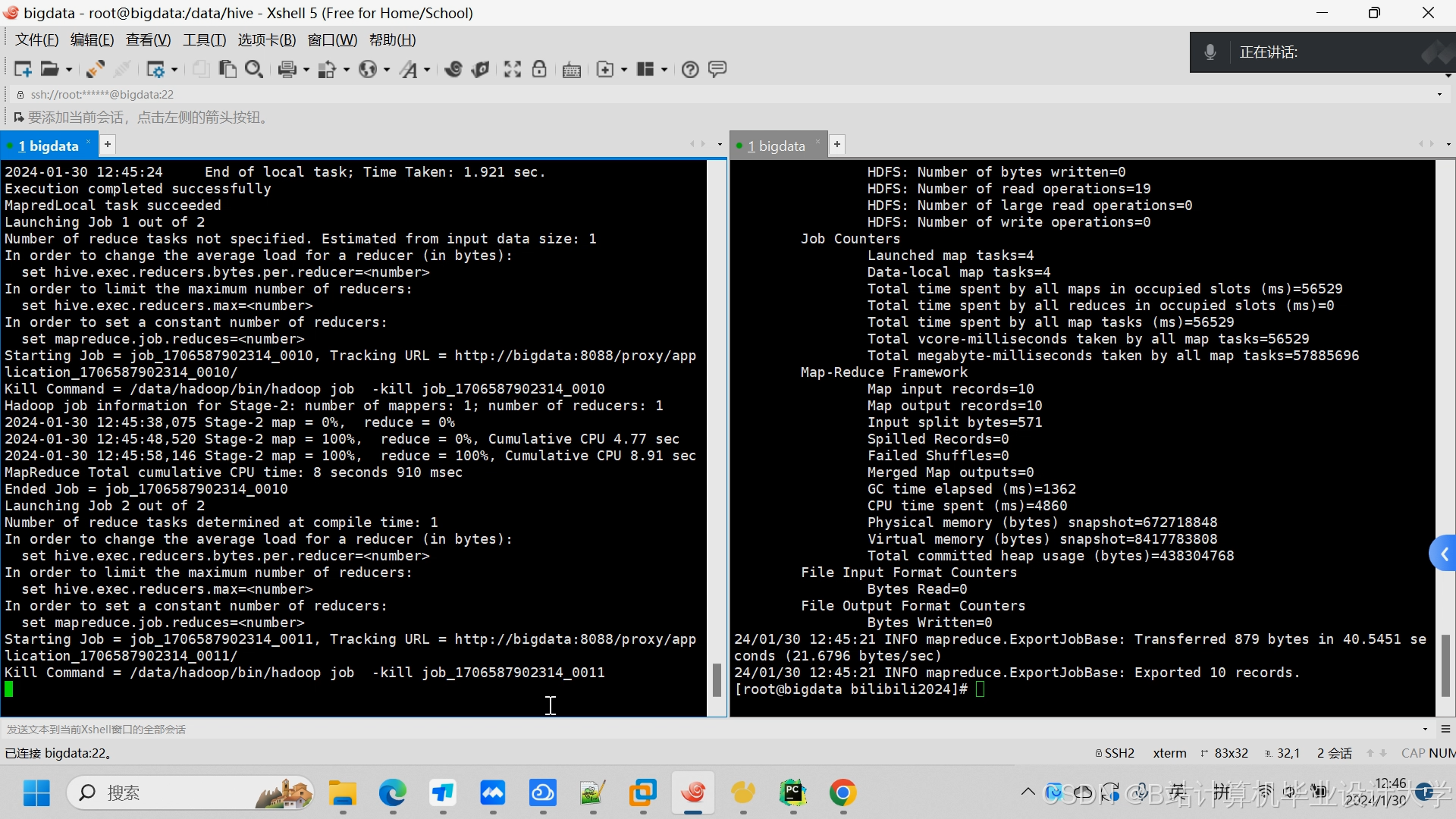
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











