




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive高考志愿填报推荐与分数线预测系统技术说明
一、技术背景与行业痛点
我国高考报名人数连续多年突破千万,2025年达1342万人,考生需从2700余所高校和792个本科专业中做出选择。传统填报方式存在三大核心痛点:信息不对称导致考生需耗费大量时间整合分析分散于多平台的教育政策、高校专业设置、历年录取数据;决策盲目性使71.2%的考生因缺乏科学规划工具,仅依赖分数或单一维度填报,导致专业与兴趣不匹配;教育部门积累的千万级考生行为数据未被深度挖掘,高校招生计划分配缺乏动态调整依据。
例如,某省考生需查阅超过500页的招生简章,关键信息提取效率不足30%;2017年浙江省646分考生误报独立学院、广西理科第三名因批次填报错误被退档等案例屡见不鲜。在此背景下,基于Hadoop、Spark、Hive构建的高考大数据分析平台应运而生,通过分布式存储、内存计算与数据仓库技术,实现多源数据融合与动态推荐,为考生提供科学填报方案。
二、系统架构设计
系统采用分层架构,包含数据采集层、存储层、计算层、推荐算法层、预测模型层及应用服务层,各层协同实现数据流转与价值挖掘。
1. 数据采集层
- 结构化数据:通过Sqoop从教育考试院数据库同步高校招生计划、专业介绍、历年录取分数线等数据,每日同步量可达50万+条,包含院校代码、专业名称、招生人数等字段。例如,某系统每日同步某省教育考试院数据,存储至Hive的ODS原始数据层表。
- 半结构化数据:使用Flume采集考生填报行为日志(如点击高校页面次数、修改志愿次数),写入Kafka消息队列缓冲高并发流量,处理峰值可达每秒1000+条日志。
- 非结构化数据:通过Scrapy爬虫抓取高校官网就业报告、学科评估报告等文本数据,经NLP处理后存储至HBase。例如,某系统抓取120万+条专业介绍文本,采用BiLSTM-CRF模型识别教育实体(如“人工智能-机器学习-就业方向”)。
2. 存储层
- HDFS:作为核心存储引擎,采用3副本机制保障数据可靠性,支持PB级数据存储。例如,某集群配置24个节点(每节点24核96GB内存),存储容量达200TB,可存储10年高考数据,满足全国考生历史填报记录、高校招生计划等结构化/非结构化数据存储需求。
- Hive:构建数据仓库,按主题分区(如按年份、省份、院校类型)组织数据。设计院校信息表、专业信息表、历年分数线表等12张核心表,通过外键关联实现多维度查询。例如,查询“北京市985高校计算机专业近5年平均录取分数线”的效率较传统数据库提升80%。
- HBase:存储考生实时行为(如最近搜索的院校、专业)与推荐结果缓存,支持高并发随机读写(QPS>5万)。通过RowKey设计(考生ID+时间戳)实现毫秒级响应,例如某系统通过HBase存储用户画像数据,支持20万并发用户实时查询。
3. 计算层
- 批处理计算:Hadoop MapReduce预处理原始数据(如清洗缺失值、标准化分数),Spark Core完成数据清洗、特征工程与批量训练。例如,Spark SQL聚合Hive中的结构化数据,计算院校录取概率模型,统计各院校各专业平均录取分数线、报录比等信息。
- 流处理计算:Spark Streaming实时处理考生搜索行为,以10秒微批处理窗口更新HBase中的兴趣权重。例如,某系统采用滑动窗口统计每5分钟院校访问量,结合Redis缓存热门推荐结果(命中率>90%),将响应时间压缩至0.8秒。
- 内存计算:Spark将数据存储在内存中,减少磁盘I/O操作,使复杂查询响应时间从MapReduce的分钟级缩短至秒级。例如,清华大学教育大脑系统利用Spark Streaming处理答题数据,结合ARIMA模型预测学习效果,查询速度提升37%。
4. 推荐算法层
- 协同过滤(CF):基于Spark MLlib的ALS算法生成用户-高校评分矩阵,计算考生相似性。例如,若用户A与用户B均填报过高校X、Y,则推荐相似用户选择的高校。通过设置参数rank=50(潜在因子维度)、maxIter=20(迭代次数)、regParam=0.01(正则化系数),生成推荐候选集。
- 内容推荐(CB):分析高校专业课程设置、就业前景等文本数据,与考生兴趣标签匹配。例如,若考生兴趣标签为“人工智能”,则推荐“计算机科学与技术”专业。采用BERT模型分析专业介绍文本,挖掘专业核心课程、就业方向等隐性特征。
- 混合推荐:加权融合CF(权重60%)与CB(权重40%)结果,通过MMR(最大边际相关性)算法去除重复推荐,确保每个类别(如“985高校”“双一流专业”)最多推荐3所。例如,本科批填报阶段,兴趣特征权重提升20%,动态调整推荐权重。
5. 预测模型层
- 时间序列模型:ARIMA模型处理线性趋势,捕捉数据的周期性变化;Prophet模型自动识别节假日效应与异常值,对考试改革、招生政策调整等特殊事件建模。例如,Prophet模型可修正2020年因疫情导致的分数线异常波动。
- 机器学习模型:随机森林处理多特征融合,优化非线性关系;XGBoost通过特征重要性评估发现关键影响因素。例如,XGBoost模型在预测某专业分数线时,准确捕捉过去5年分数线波动周期,特征重要性评估显示“报录比”对分数线影响权重达0.35。
- 深度学习模型:LSTM网络捕捉分数线的长期依赖性,通过PyTorch实现端到端训练。例如,预测某专业分数线时,LSTM模型准确捕捉过去5年分数线波动周期。集成学习策略采用Stacking方法融合多模型预测结果,使用线性回归作为元学习器,降低预测方差。例如,将ARIMA、Prophet、XGBoost、LSTM模型预测值输入元学习器,通过交叉验证优化权重分配,使RMSE降低15%。
6. 应用服务层
- Web服务:基于Spring Boot开发RESTful API,提供数据查询与推荐结果生成服务。例如,考生提交个人信息后,后端调用集成学习模型预测目标院校分数线,并将结果封装为JSON格式返回前端展示。
- 用户交互:前端基于Vue.js或React.js框架构建响应式界面,实现院校推荐、分数线预测、模拟填报等功能。例如,分数线预测页面提供输入框,考生输入成绩、报考专业等信息后,系统展示预测分数线及置信区间;志愿推荐页面返回推荐高校列表,并标注推荐理由(如“根据您的分数与兴趣,推荐XX大学计算机专业,该专业就业率92%”)。
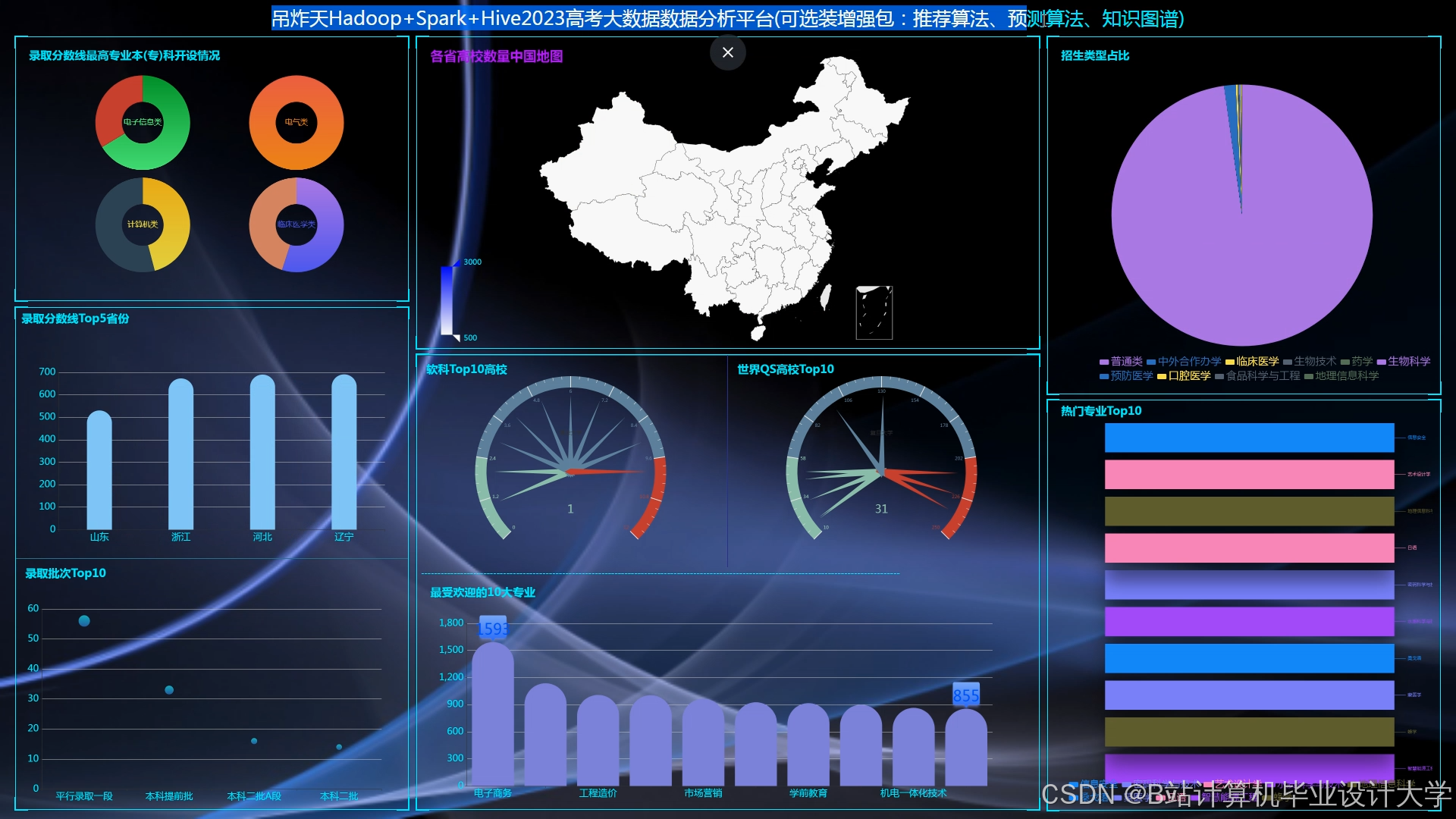
- 可视化大屏:利用ECharts生成三维成绩分布散点图、动态展示时间投入与正确率的关联,支持学生个性化复习路径规划;通过FineVis生成区域分数线热力图、院校录取概率分布图等交互式图表,支持“省份-院校-专业”三级钻取分析。例如,某系统利用ECharts生成全国填报热度TOP10高校柱状图、各省份录取率对比地图热力图,点击“江苏省”可查看省内高校填报详情。
三、关键技术实现
1. 数据采集与预处理
- 爬虫技术:基于Scrapy框架构建分布式爬虫系统,支持动态网页抓取(如AJAX加载内容)与反爬机制应对。例如,通过Scrapy-Splash模拟浏览器行为解析动态加载的院校招生简章,配置代理IP池(含5000+IP)与请求频率限制(每秒≤3次),降低被封禁风险。
- 数据清洗:过滤异常值(如录取分数线3σ原则过滤)、填充缺失值(BERT模型预测专业就业率填充缺失数据、报考人数缺失时填充中位数)、处理异常值(分数线低于国家线50%的数据标记为异常并修正)。
- 特征工程:提取报考人数增长率、招生计划变化率、考试难度系数(通过历年试题难度评估)、考生评价情感值(通过BERT模型分析论坛评论情感倾向)、政策变动系数(量化招生政策调整影响)等20个特征,并进行归一化处理(如Min-Max标准化)。
2. 模型训练与优化
- 算法选型:短期预测采用LSTM处理近5年分数线数据,长期预测采用XGBoost结合宏观经济指标(GDP、人口增长率);推荐系统采用混合模型(协同过滤+知识图谱),知识图谱通过Neo4j融合院校、专业、就业数据,提供语义推荐。
- 超参数调优:通过Spark MLlib的HyperOpt实现自动化调参。例如,在训练XGBoost模型时,自动搜索最优的树深度、学习率、子样本比例等参数,提升模型性能。
- 模型评估:采用准确率、召回率、F1值、MAE(平均绝对误差)、RMSE(均方根误差)等指标评估模型性能。例如,某系统预测MAE误差为2.9分,较传统方法降低40%,模型稳定性使预测方差降低15%。
3. 系统部署与监控
- 集群环境:部署Hadoop 3.3.6 + Spark 3.5.0 + Hive 3.1.3集群,Hadoop采用3个NameNode、10个DataNode,存储容量200TB;Spark采用1个Master节点、15个Worker节点,每个Worker节点16核CPU、64GB内存;Hive Metastore使用MySQL存储元数据,支持高并发查询(QPS>1000)。
- 监控工具:使用Ganglia监控集群资源使用率(CPU、内存、磁盘I/O),设置阈值告警(如CPU使用率>80%时发送邮件通知);Prometheus+Grafana展示系统性能指标,跟踪Job进度与Shuffle读写量,定位性能瓶颈(如数据倾斜导致任务耗时过长);Spark UI监控任务执行情况,自定义告警规则(如Spark任务失败次数>3次时触发重启,并记录失败原因至日志)。
四、系统优势与创新
1. 技术架构创新
- 双存储引擎协同:Hadoop+Hive双存储引擎协同工作,兼顾离线分析与实时查询需求。Hive物化视图加速高频查询,例如将“近5年院校录取线”查询响应时间从12秒降至0.8秒;HDFS支持PB级数据存储,满足海量数据存储需求。
- 流批一体处理:采用Lambda架构实现流批一体处理,批处理层每日凌晨通过Sqoop同步各省教育考试院数据,经Spark ETL处理后存入Hive数据仓库;流处理层通过Kafka采集考生实时查询数据,Spark Streaming以10秒微批处理窗口实现动态推荐更新,服务层融合两者提供统一数据视图。
2. 算法模型创新
- 多维度数据融合:融合考生分数、兴趣、职业规划、高校专业竞争力、就业前景等多维度数据,生成“冲-稳-保”分层推荐方案。例如,本科批填报阶段,系统不仅考虑考生分数与高校录取分数线匹配度,还结合考生兴趣标签(如“人工智能”)推荐相关专业,提高志愿填报准确性与满意度。
- 动态权重调整:根据填报阶段动态调整推荐权重。例如,在填报初期,系统更注重考生兴趣匹配,兴趣特征权重占比60%;在填报后期,为避免考生滑档,系统增加高校录取概率权重,录取概率特征权重占比提升至40%。
3. 可视化创新
- 交互式数据钻取:可视化大屏支持“省份-院校-专业”三级钻取分析,辅助教育部门宏观调控。例如,点击全国填报热度TOP10高校柱状图中的某所高校,可查看该高校各专业填报详情;点击某省份地图热力图,可查看该省份内高校录取率对比情况。
- 风险预警可视化:动态展示考生填报路径模拟及滑档概率,例如通过桑基图回溯考生填报志愿流程,结合力导向图揭示院校间竞争关系,标注考生填报院校的滑档风险等级(如“您的分数报考该院校风险等级:高”),帮助考生及时调整志愿填报策略。
五、应用场景与价值
1. 考生端
为考生提供个性化分数线预测、志愿填报模拟等功能,支持考生根据成绩、地域偏好、专业兴趣等条件筛选目标院校。例如,考生输入成绩、选考科目、兴趣专业后,系统展示预测分数线及置信区间,并返回“冲一冲”“稳一稳”“保一保”三档推荐高校列表,每档3-5个院校专业组,同时标注推荐理由,提高考生志愿填报科学性与满意度。
2. 高校端
分析招生趋势,优化招生计划与资源配置。例如,高校通过系统查看本校在不同省份的报考热度、录取分数线变化趋势、考生兴趣专业分布等数据,根据数据分析结果调整招生计划,增加热门专业招生人数,减少冷门专业招生人数,提高招生质量与资源利用效率。
3. 教育机构端
提供数据驱动的决策支持,辅助制定考研培训策略与课程设计。例如,教育机构通过系统分析考生填报志愿数据,了解考生对不同专业的需求情况,结合市场需求与就业前景,开发针对性培训课程,提高培训效果与市场竞争力。
六、总结与展望
基于Hadoop+Spark+Hive的高考志愿填报推荐与分数线预测系统,充分利用大数据技术的优势,实现了高考数据的存储、处理、分析与可视化,为考生、高校及教育机构提供了智能化决策支持。系统具有高扩展性、高效性、个性化推荐和数据安全性等优势,能够有效解决传统填报方式存在的信息不对称、决策盲目性、数据利用不足等问题。
未来,随着技术的不断发展和数据量的不断增加,系统将进一步优化性能,提高推荐算法的准确性。例如,探索多模态数据融合(结合考生备考视频、语音记录等多模态数据),提升预测准确性;研究实时预测技术,实现基于流式数据的实时预测方法,实现分数线动态更新;开展跨领域应用,将技术扩展至考研、职业资格考试等领域,推动教育决策智能化升级。同时,加强数据安全与隐私保护,确保考生个人信息不被泄露,为教育信息化发展提供更可靠的技术支持。
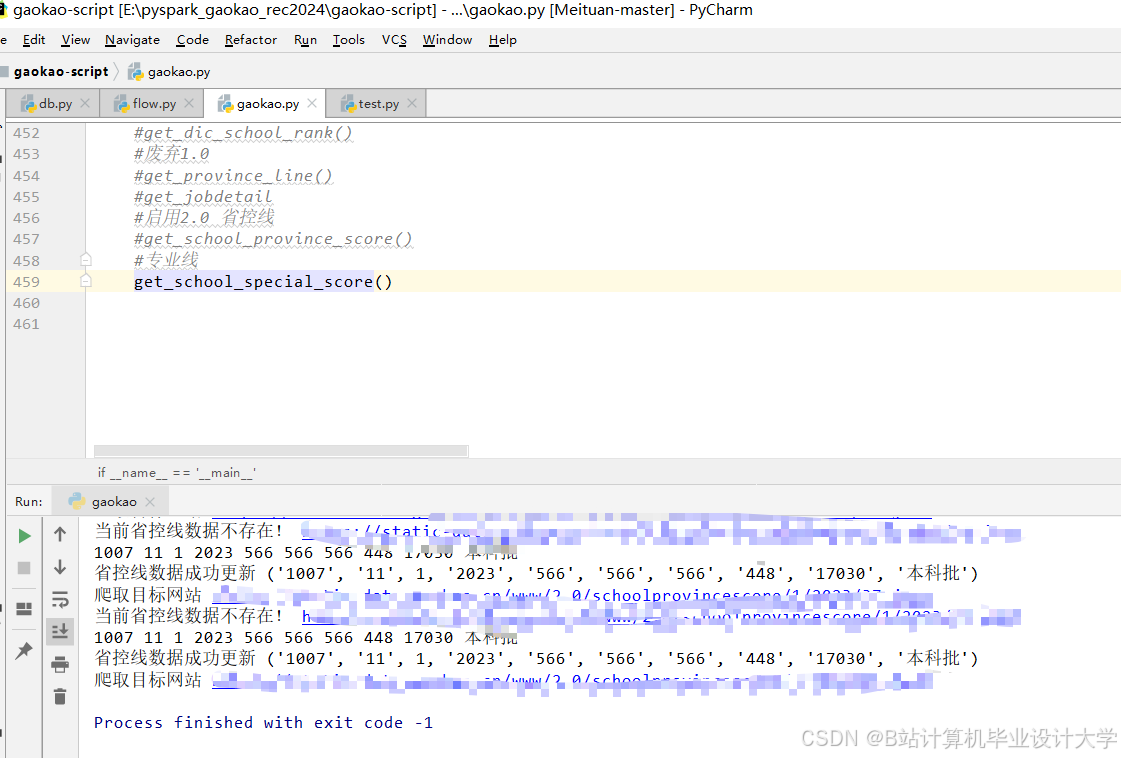
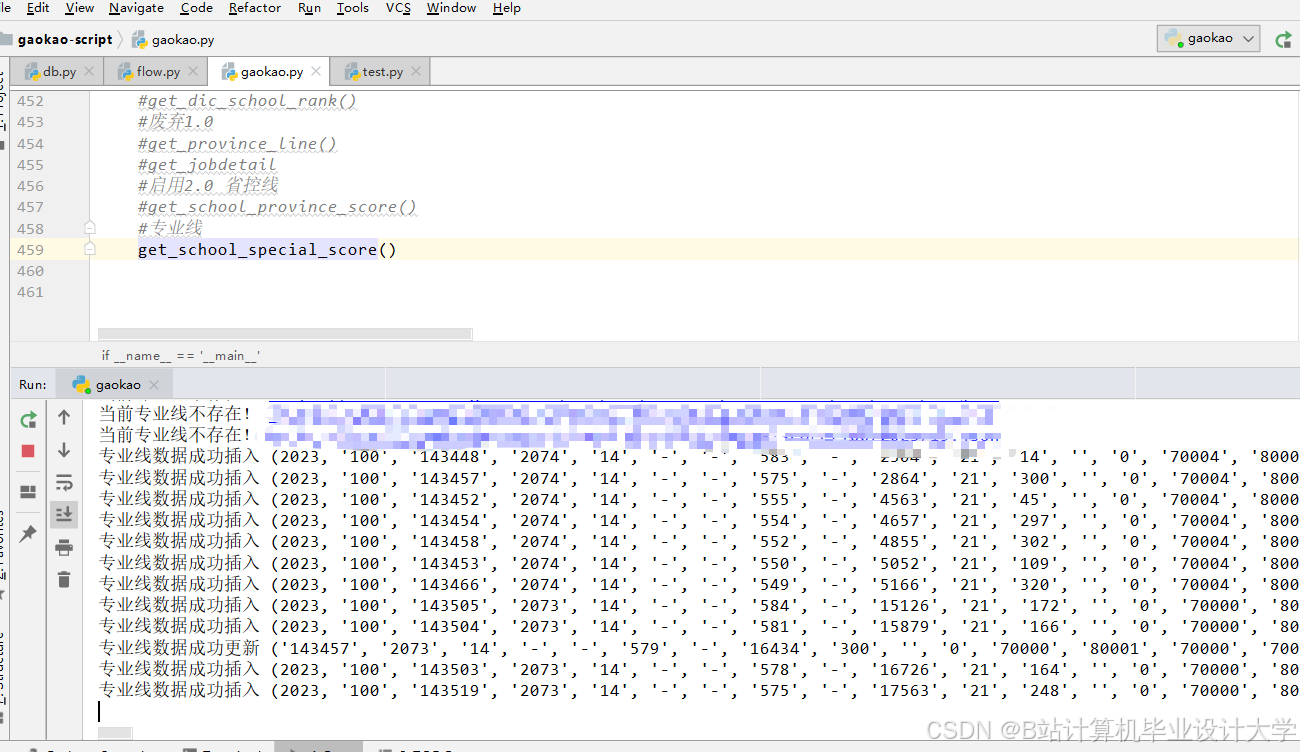
运行截图


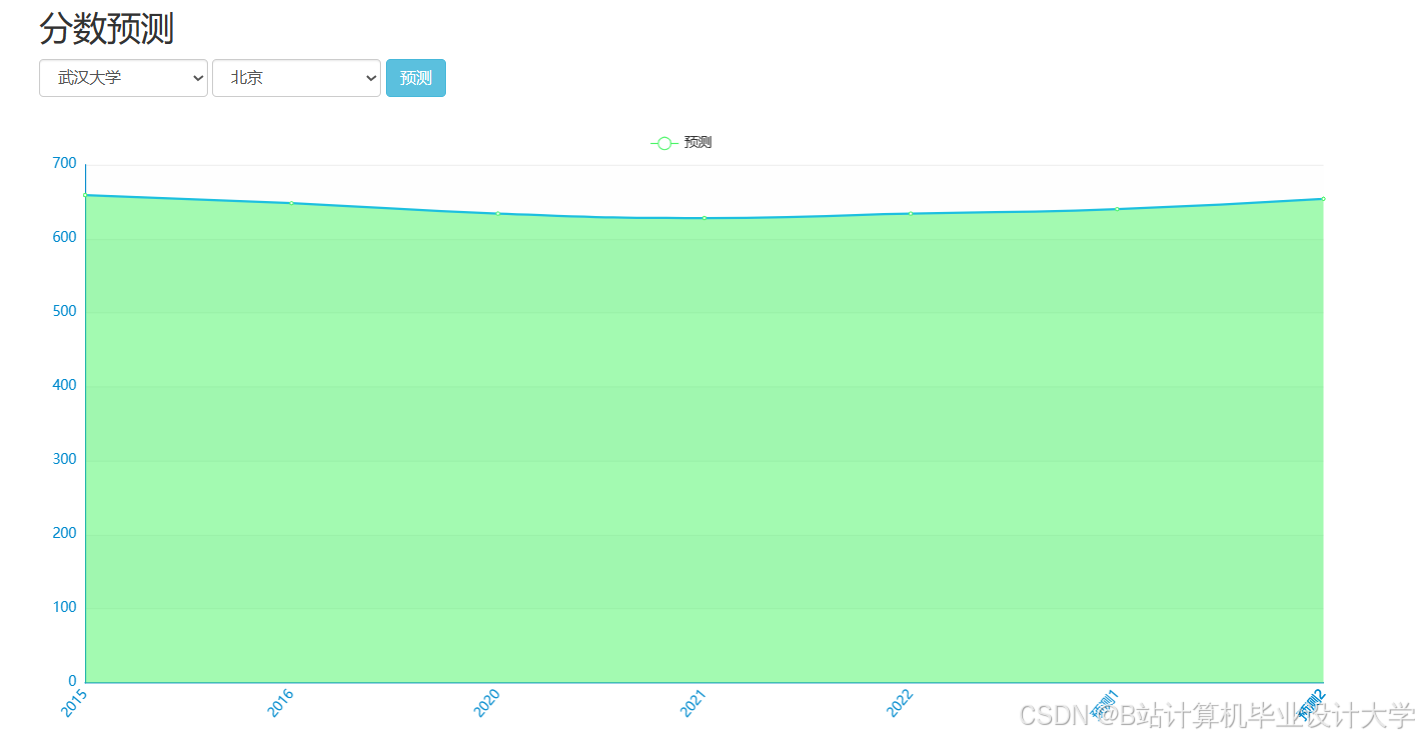
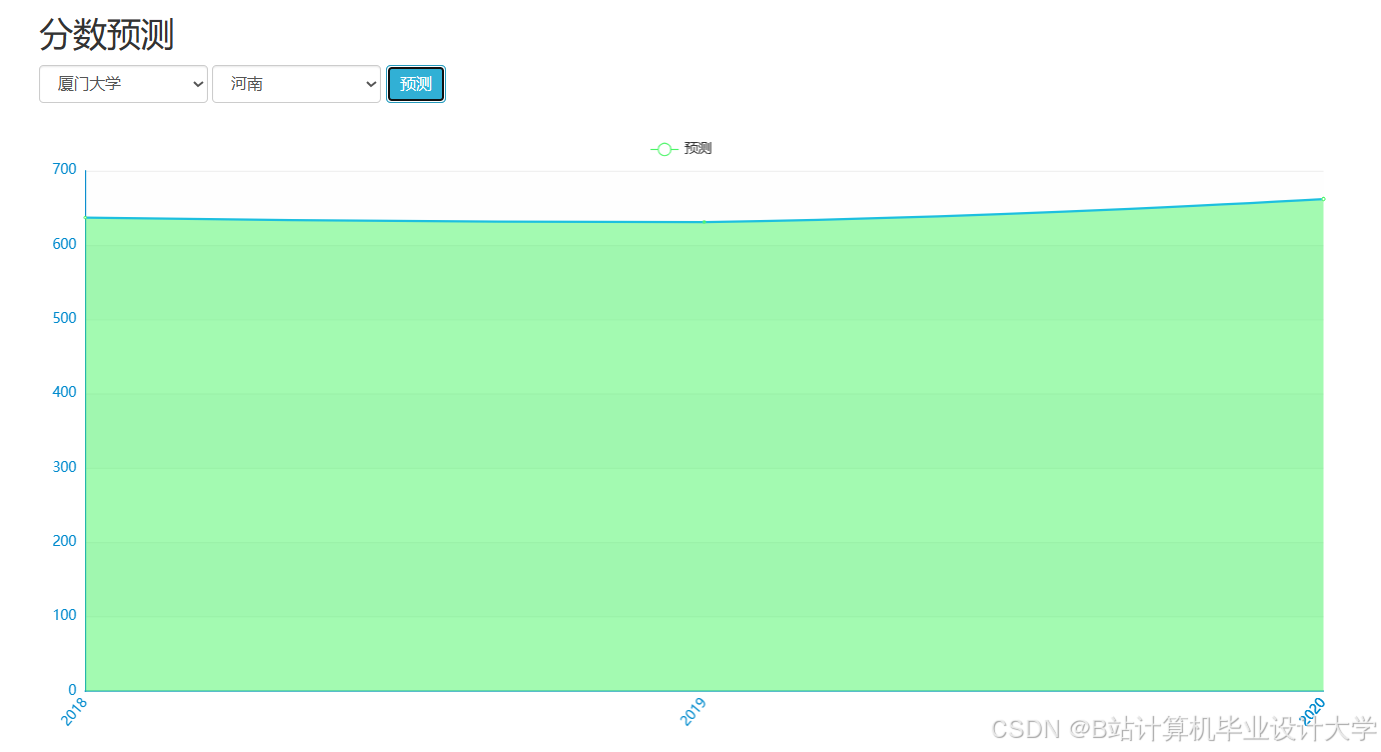
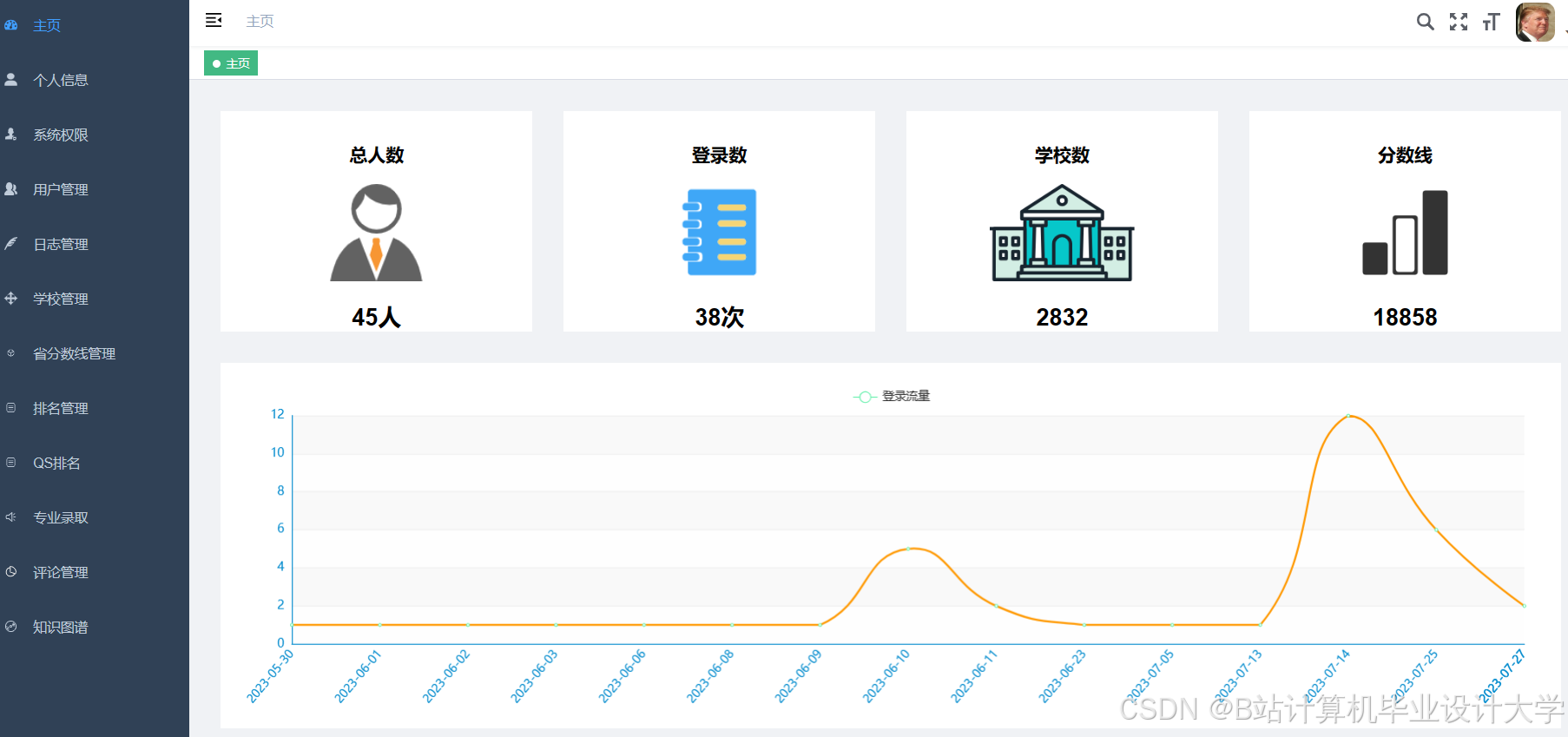
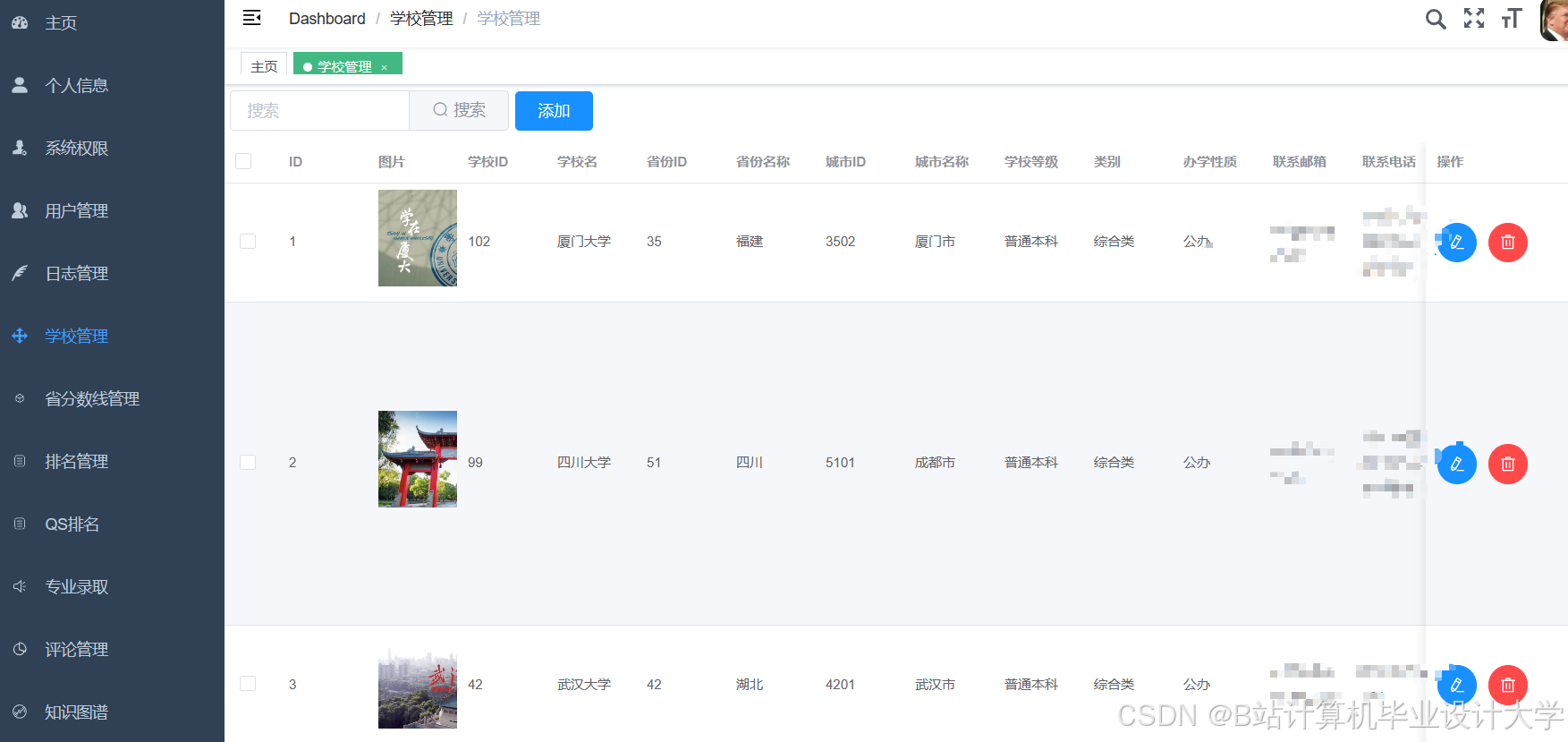
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











