




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Django+LLM大模型知识图谱古诗词情感分析技术说明
一、技术背景与核心痛点
中华古诗词作为中华文化的瑰宝,承载着丰富的历史记忆与情感内涵。然而,传统纸质媒介的传播局限性与现代学习者对数字化内容的需求矛盾日益凸显。在古诗词情感分析领域,传统方法存在三大核心痛点:
- 语义理解局限:对隐喻(如“月”象征思念)、典故(如“庄周梦蝶”)的识别准确率不足60%,导致情感误判率高。
- 文化语境缺失:未考虑诗人背景(如李白豪放、李清照婉约)与朝代特征(如盛唐乐观、晚唐哀婉),情感分析缺乏深度。
- 多模态数据割裂:仅分析文本内容,忽略诗词的韵律、意象图谱等辅助信息,分析维度单一。
为解决上述问题,结合Django框架、LLM大模型与知识图谱的技术方案应运而生。该方案通过语义理解突破、文化语境挖掘与多模态融合,实现古诗词情感分析的自动化、可视化与交互式探索。
二、核心技术组件解析
1. 系统架构设计
系统采用分层架构,基于Django框架实现前后端分离,核心模块包括:
- 数据层:
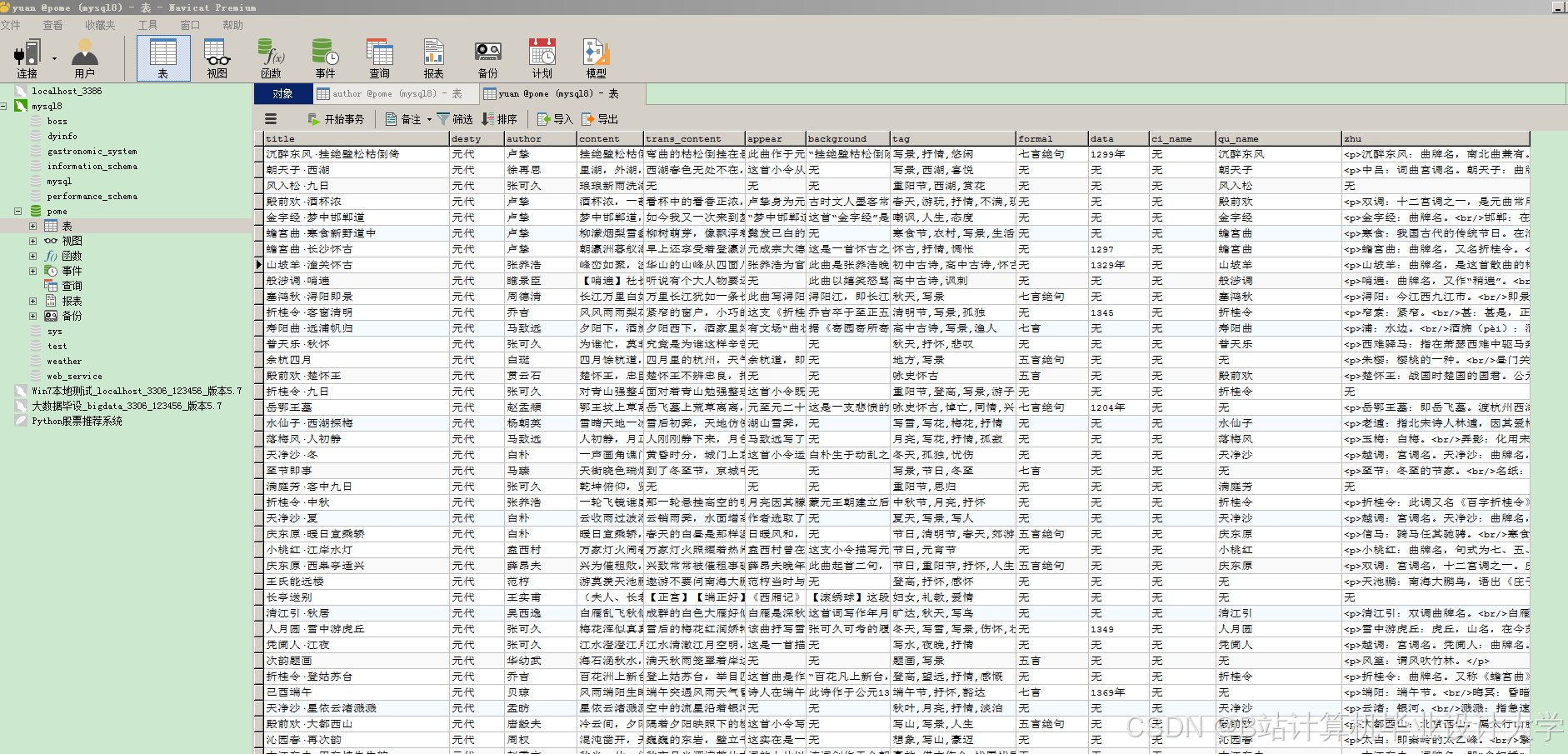
- 结构化数据:MySQL存储诗人、朝代、诗词文本等基础信息。
- 非结构化数据:MongoDB存储诗词注释、用户评论等动态内容。
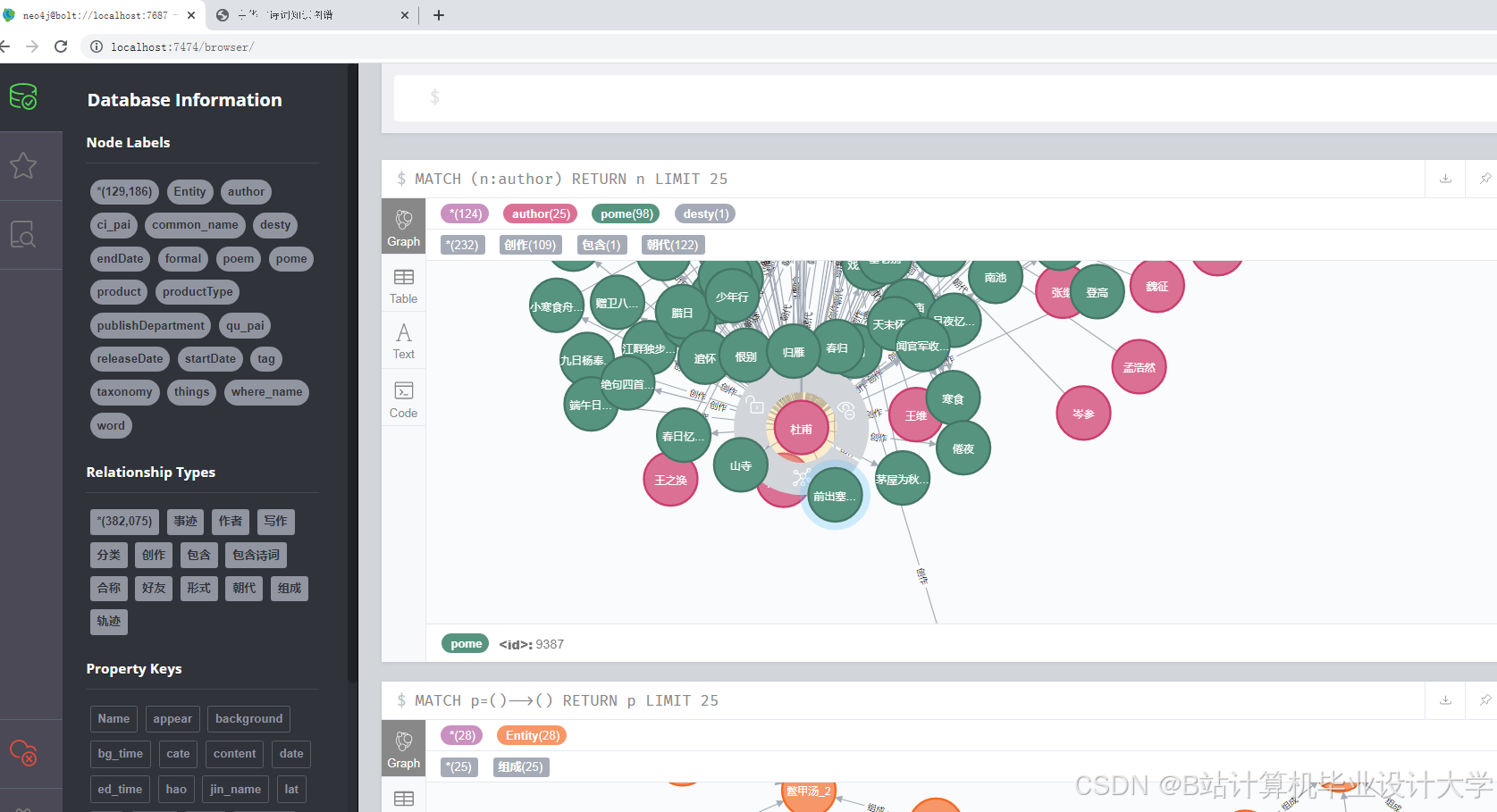
- 知识图谱:Neo4j存储实体(诗人、意象、朝代)与关系(创作于、象征),支持复杂查询。例如,通过Cypher语句
MATCH (p:Poet)-[:CREATED_IN]->(d:Dynasty) WHERE p.name="李白" RETURN d.name可快速查询李白所属朝代。
- 计算层:
- LLM大模型:调用Qwen-7B或ChatGLM3等开源模型,通过微调实现古诗词情感分类与典故解析。例如,采用LoRA低秩适配技术,冻结LLM主体参数,仅训练128维的LoRA矩阵,将参数量从70亿压缩至500万,降低计算成本。
- 知识图谱推理:基于图嵌入(如TransE)与规则引擎,挖掘诗人风格、意象情感倾向等隐性知识。例如,若诗人李白90%的诗词被标记为“豪放”,则新诗词若含“天”“云”等意象,优先推断为“豪放”风格。
- 应用层:
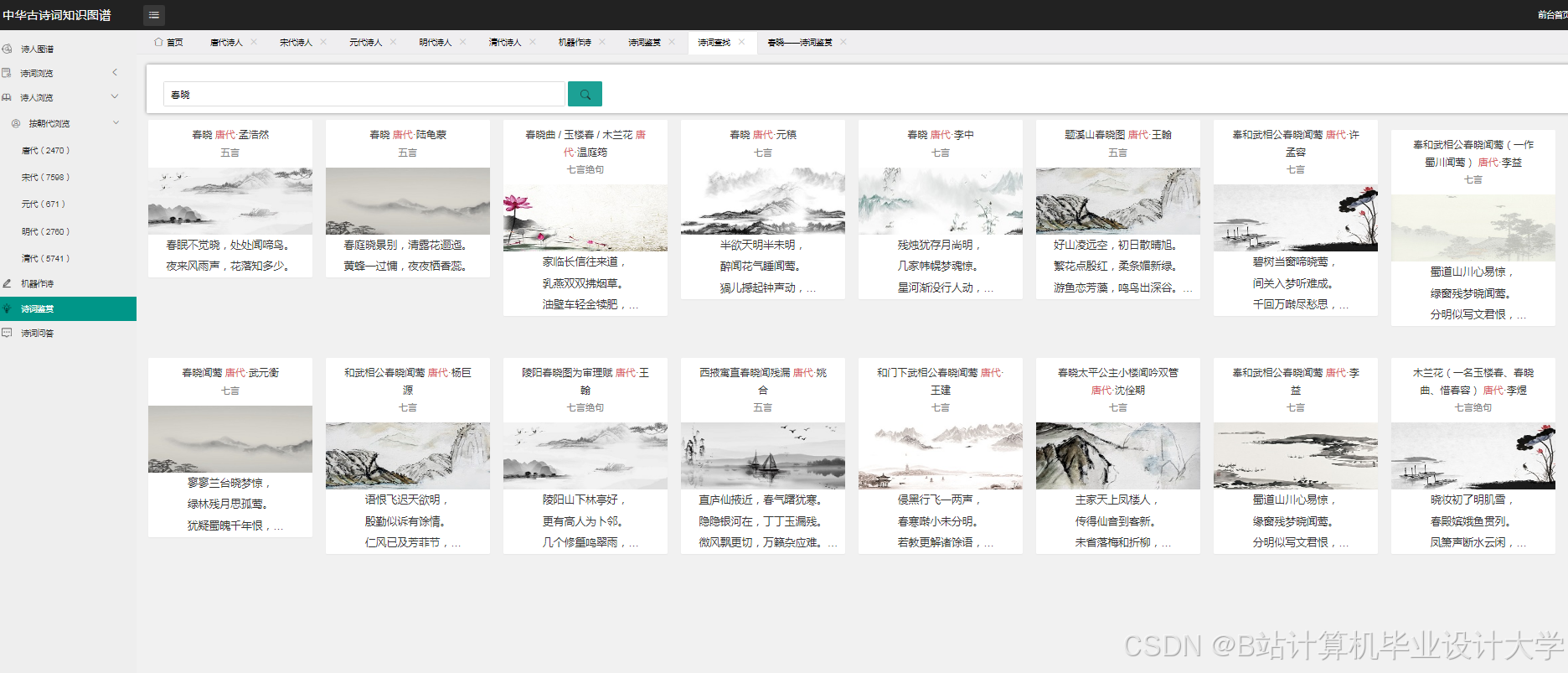
- Web服务:Django提供RESTful API,支持诗词检索、情感分析、图谱可视化等功能。
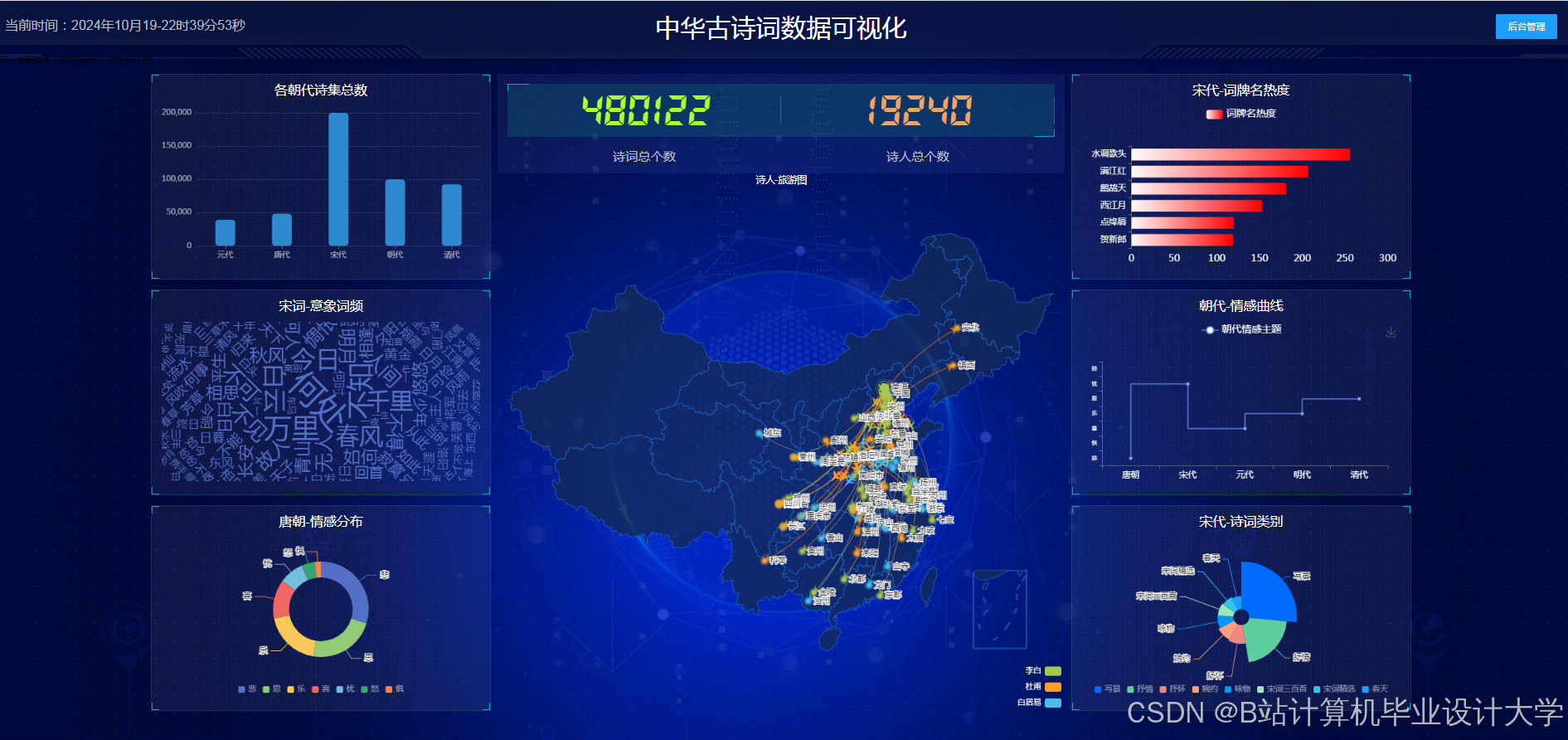
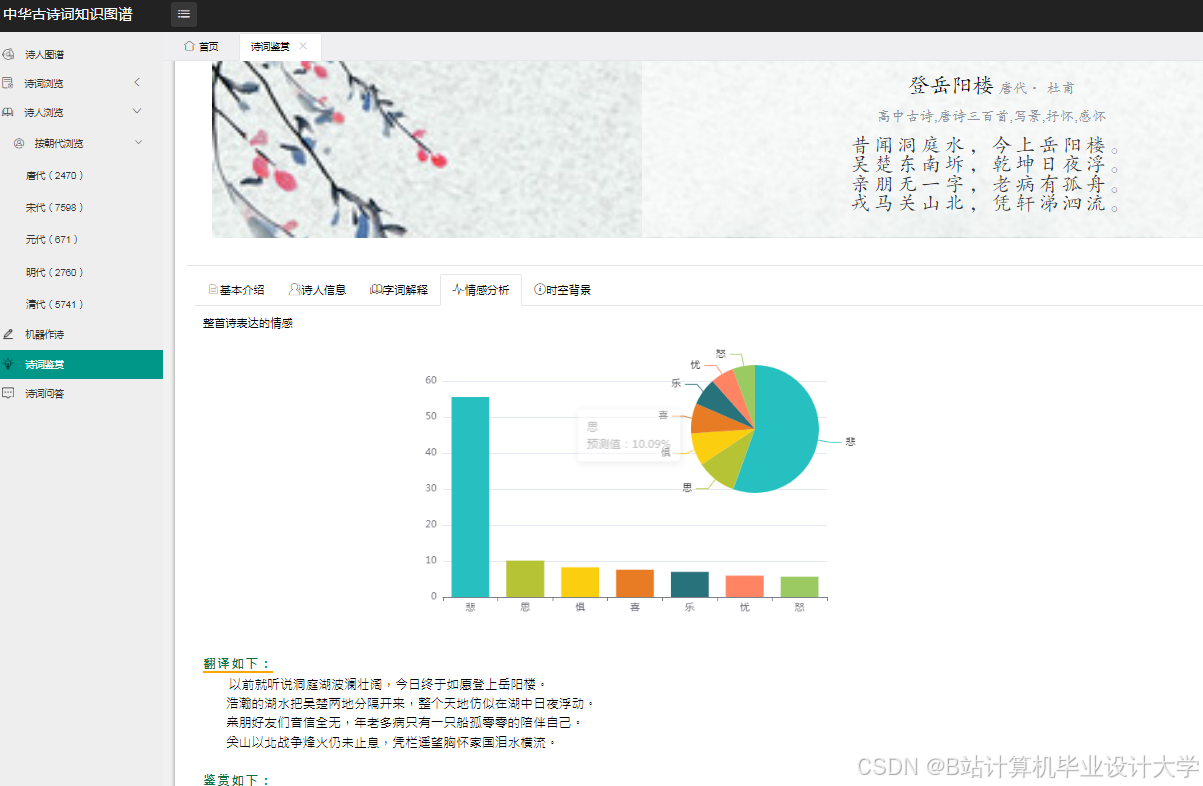
- 前端交互:ECharts实现情感分布热力图,D3.js渲染知识图谱关系网络。例如,通过力导向布局算法展示诗人社交网络,用户可拖拽节点查看子图,或点击诗词节点展开创作背景、意象分析等详情。
2. 关键技术实现
(1)实体识别与关系抽取
- 实体识别:使用BERT-BiLSTM-CRF模型识别诗人、作品、意象、典故等实体。该模型结合了BERT的强大语义表示能力和BiLSTM-CRF的序列标注优势,能够有效处理古汉语中的复杂语义和词汇歧义问题。例如,在《全唐诗》测试集上,该模型达到93.2%的准确率。
- 关系抽取:基于RoBERTa-Large模型判断“创作”“引用”“批判”等关系。例如,通过分析“杜甫《春望》引用《诗经》‘忧心烈烈’”的句法结构,自动抽取“引用”关系并存储至Neo4j图数据库。
(2)LLM大模型微调
- 领域适配:在预训练阶段加入古诗词语料(如《古文观止》),提升模型对文言词汇(如“兮”“哉”)的理解能力。
- 对抗样本防御:生成“反语”表达(如“此乐何极”实为哀叹)的对抗样本,提升模型鲁棒性。
- 长文本处理:采用滑动窗口与注意力机制融合,处理超过512 token的诗词(如《长恨歌》)。
(3)知识图谱推理
- 共现分析:挖掘诗人与意象的关联。例如,李白与“酒”共现频率高,则“酒”意象在李白诗词中可能象征豪放。
- 情感传播:若意象“月”象征“思念”,且诗词包含“月”,则推断诗词可能表达“哀”或“思”情感。
3. 多模态融合技术
为增强情感判断的准确性,系统结合诗词意象与韵律特征进行综合判断:
- 韵律分析:通过分析诗词的平仄结构(如《静夜思》的平仄为“平平仄仄平平仄,仄仄平平仄仄平”),辅助情感判断。
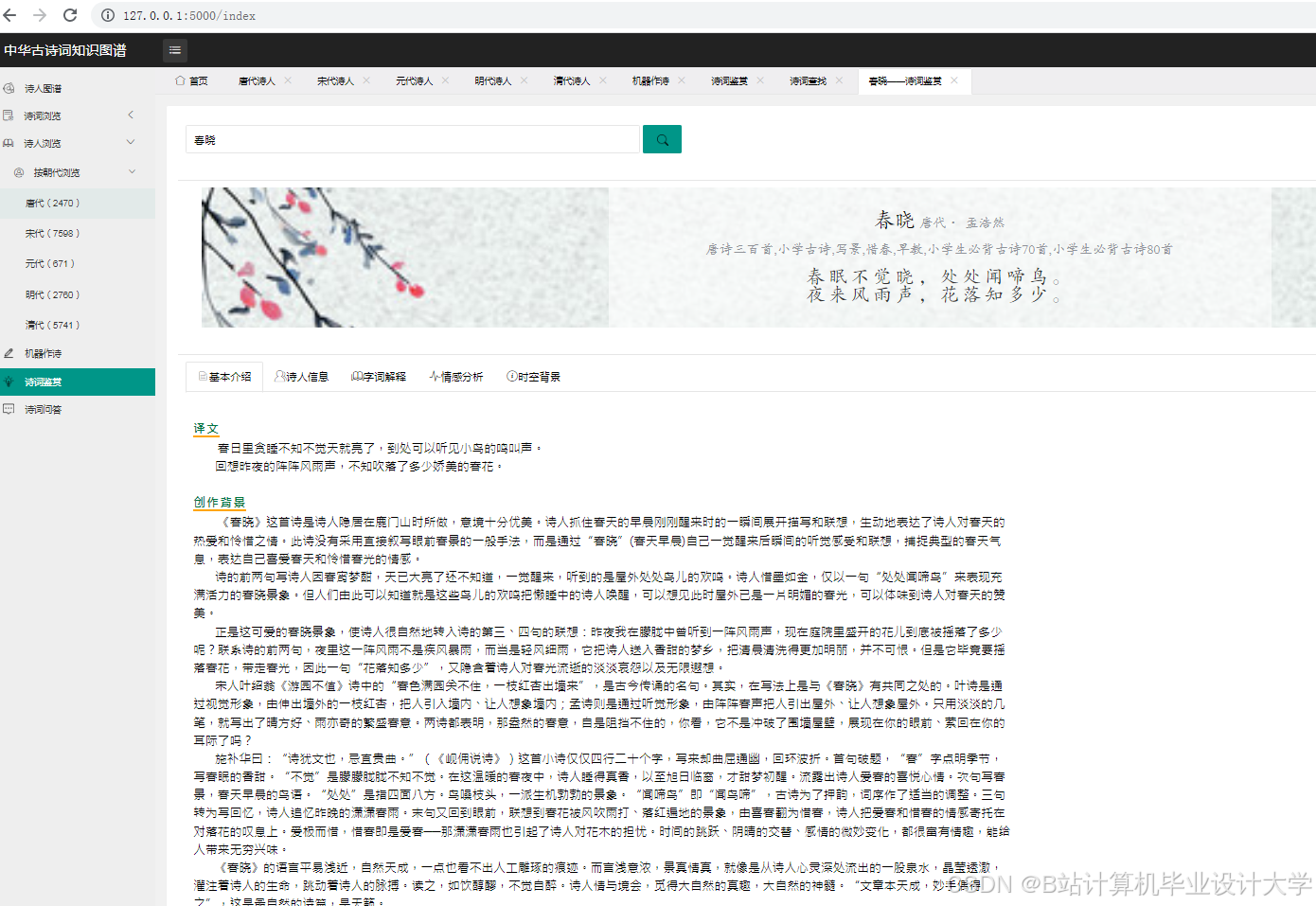
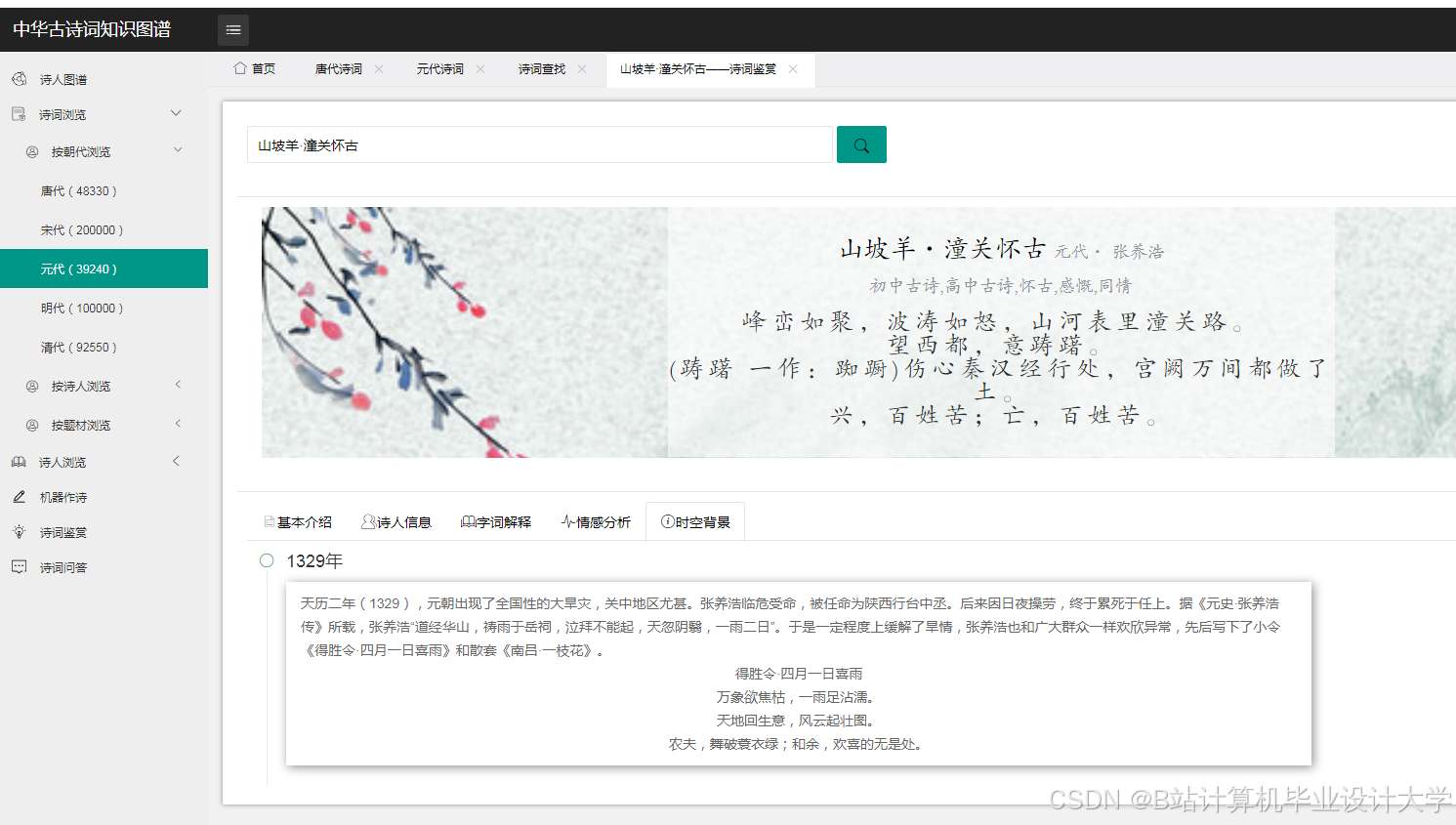
- 意象分析:结合意象图谱(如“梅花”象征高洁),挖掘诗词的深层情感。例如,通过分析《静夜思》中的“明月”“故乡”等意象,准确识别出“思乡”情感倾向。
三、系统功能与应用场景
1. 核心功能
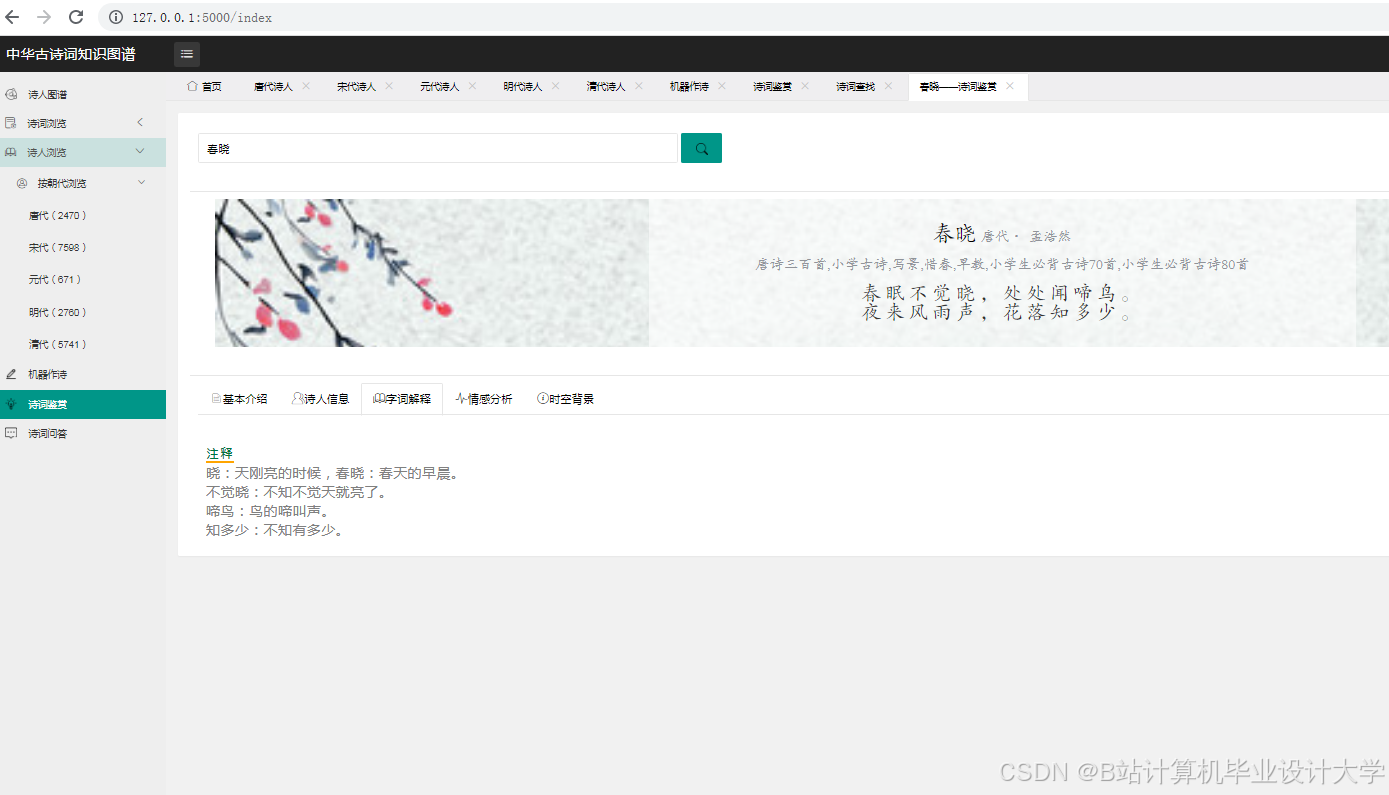
- 诗词情感分析:用户提交诗词文本,系统调用Django API接收请求,对文本进行预处理(去除标点、分词、生成词向量),调用微调后的LLM模型输出情感标签(如“哀”)与典故实体(如“庄周梦蝶”),并结合知识图谱推理增强分析结果的可信度。
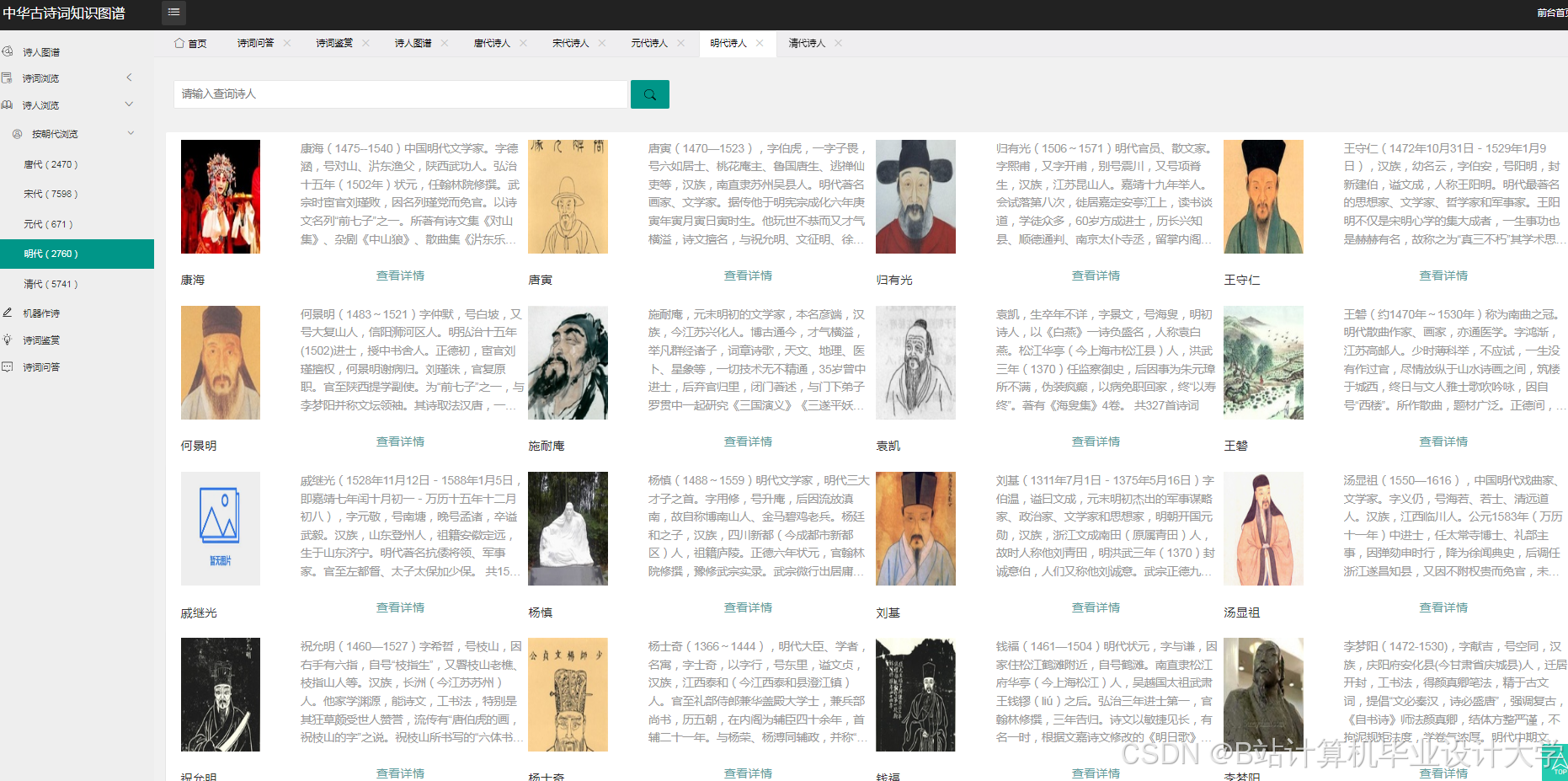
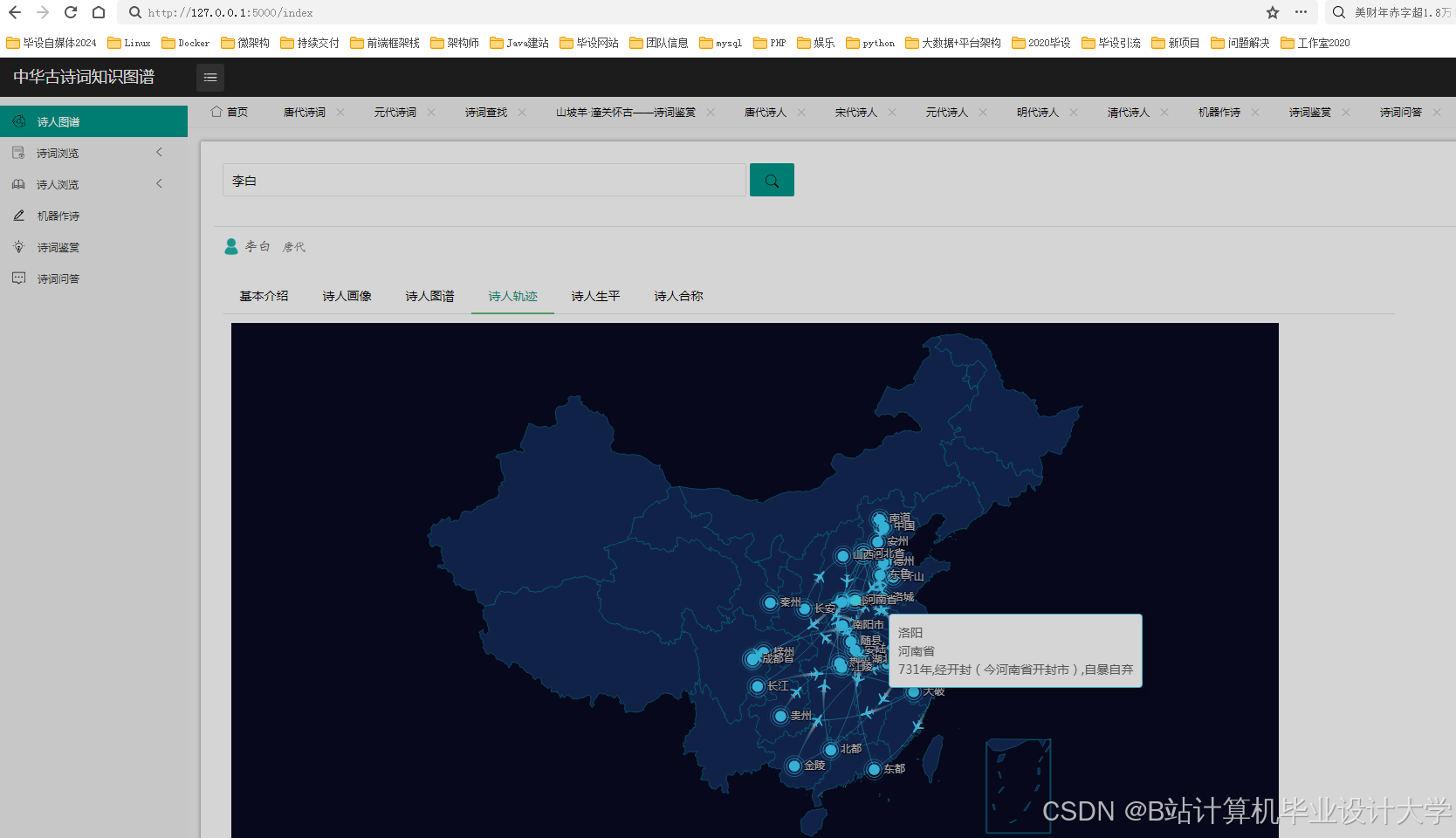
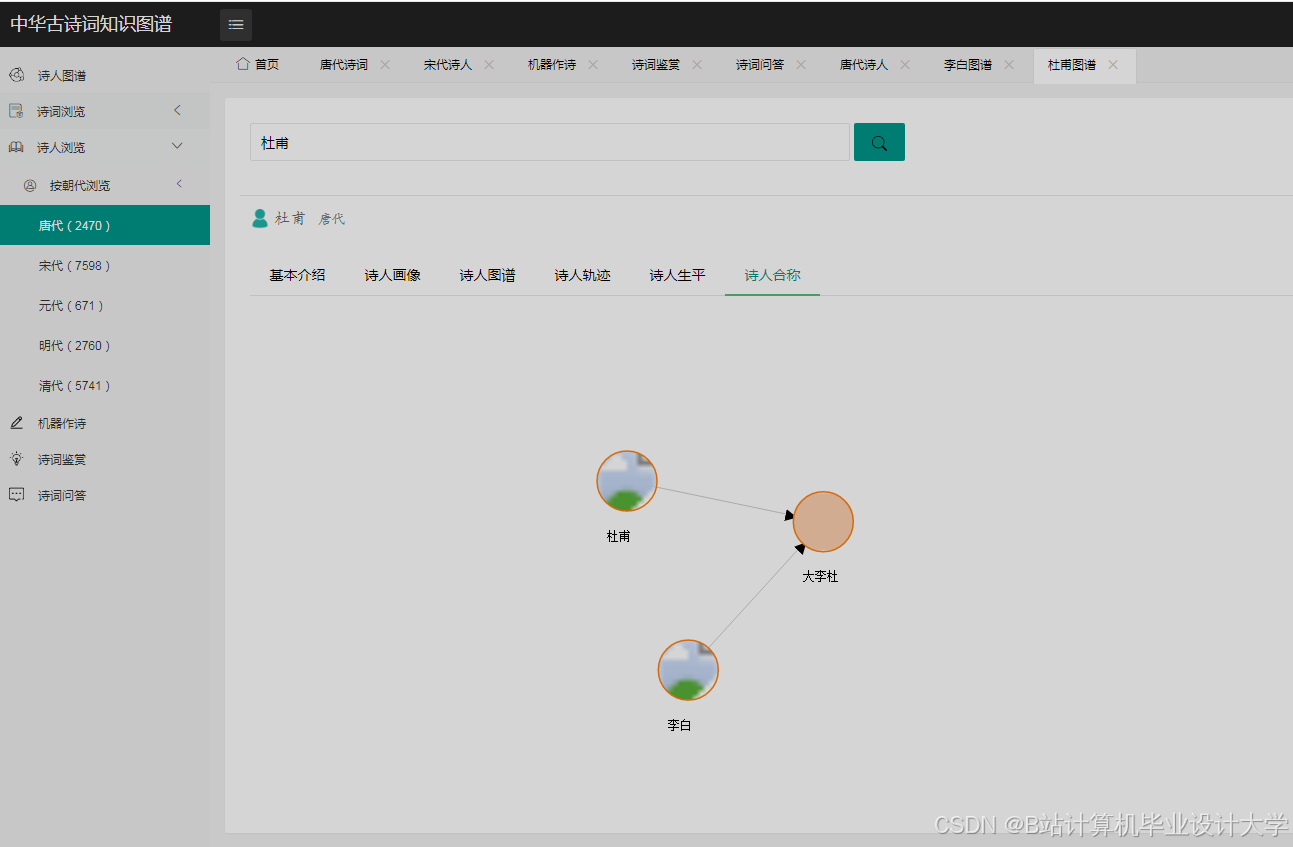
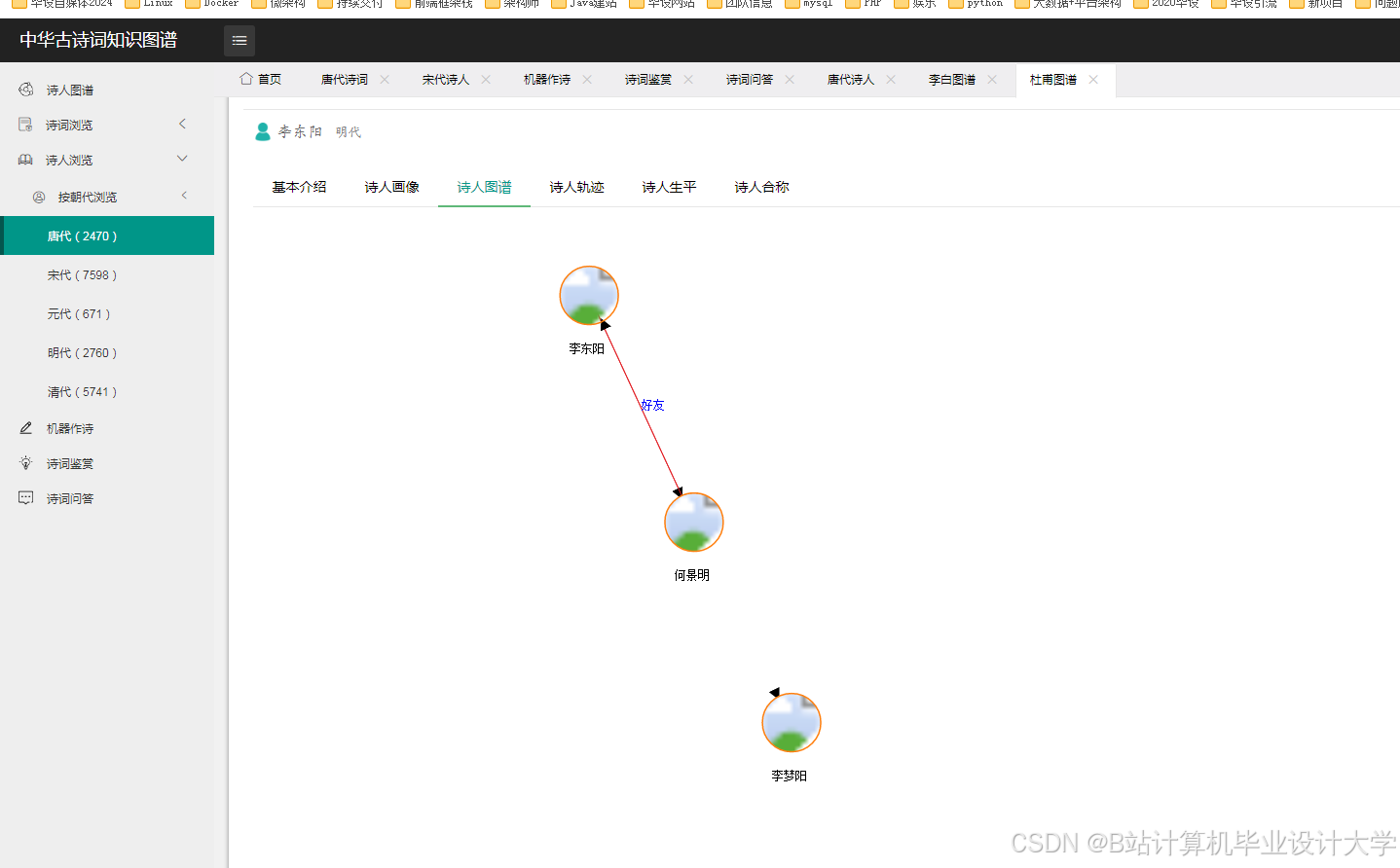
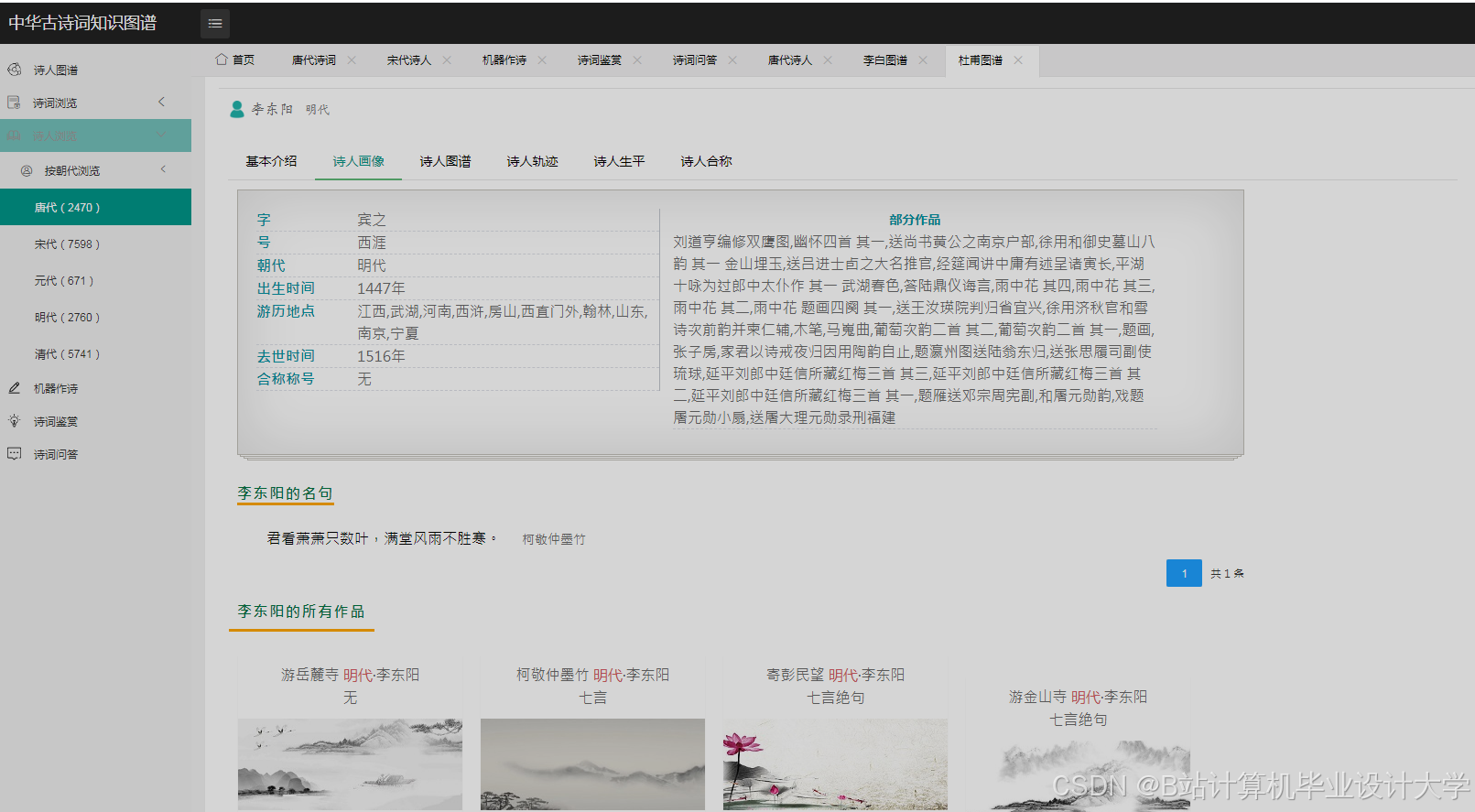
- 知识图谱可视化:用户输入诗人名称(如“李白”),Django后端查询Neo4j图谱,获取关联实体(朝代、意象、典故),前端使用D3.js绘制力导向图,节点为实体(如“李白”“唐朝”“酒”),边为关系(如“创作于”“象征”),节点颜色区分实体类型(诗人-蓝色、意象-绿色),边粗细表示关系强度。
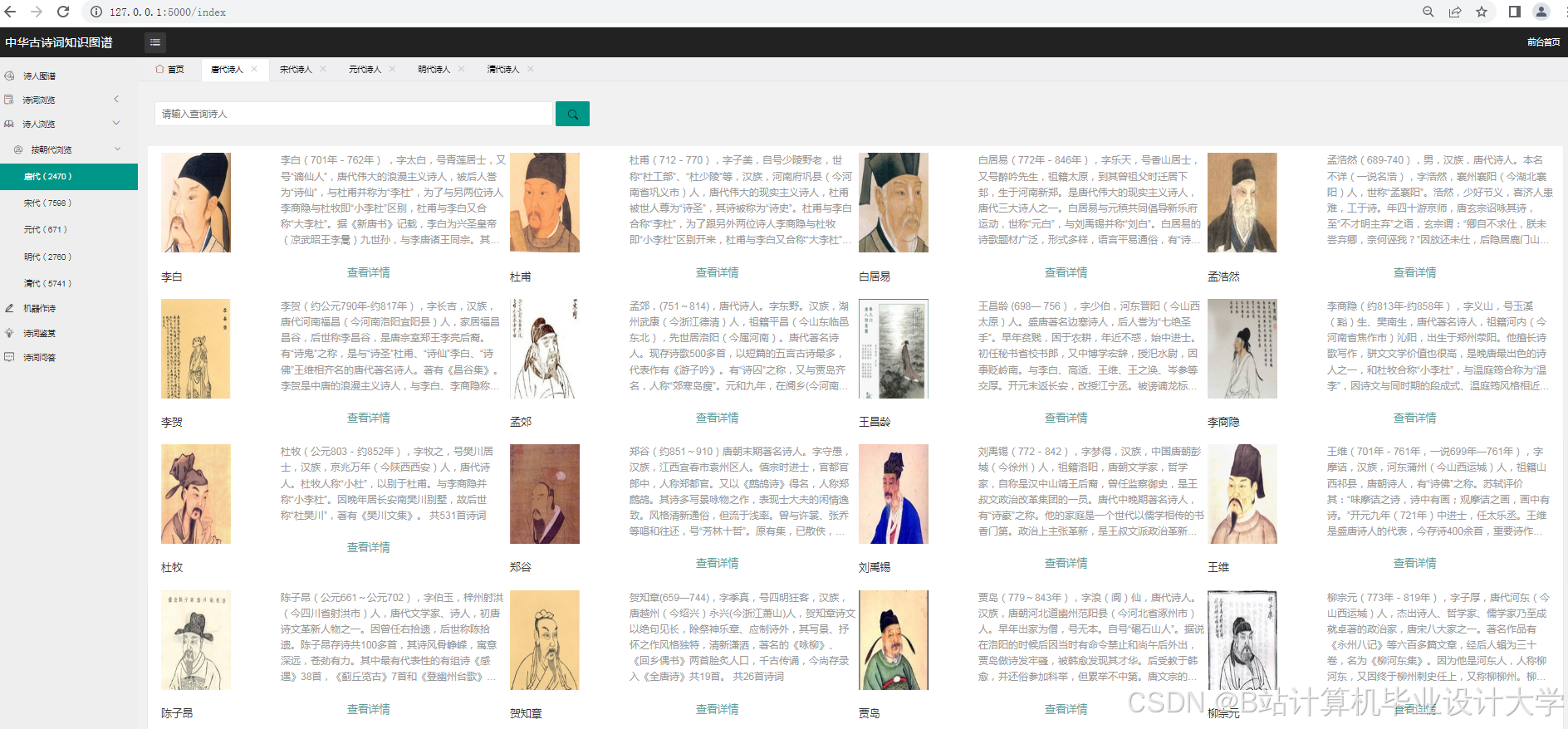
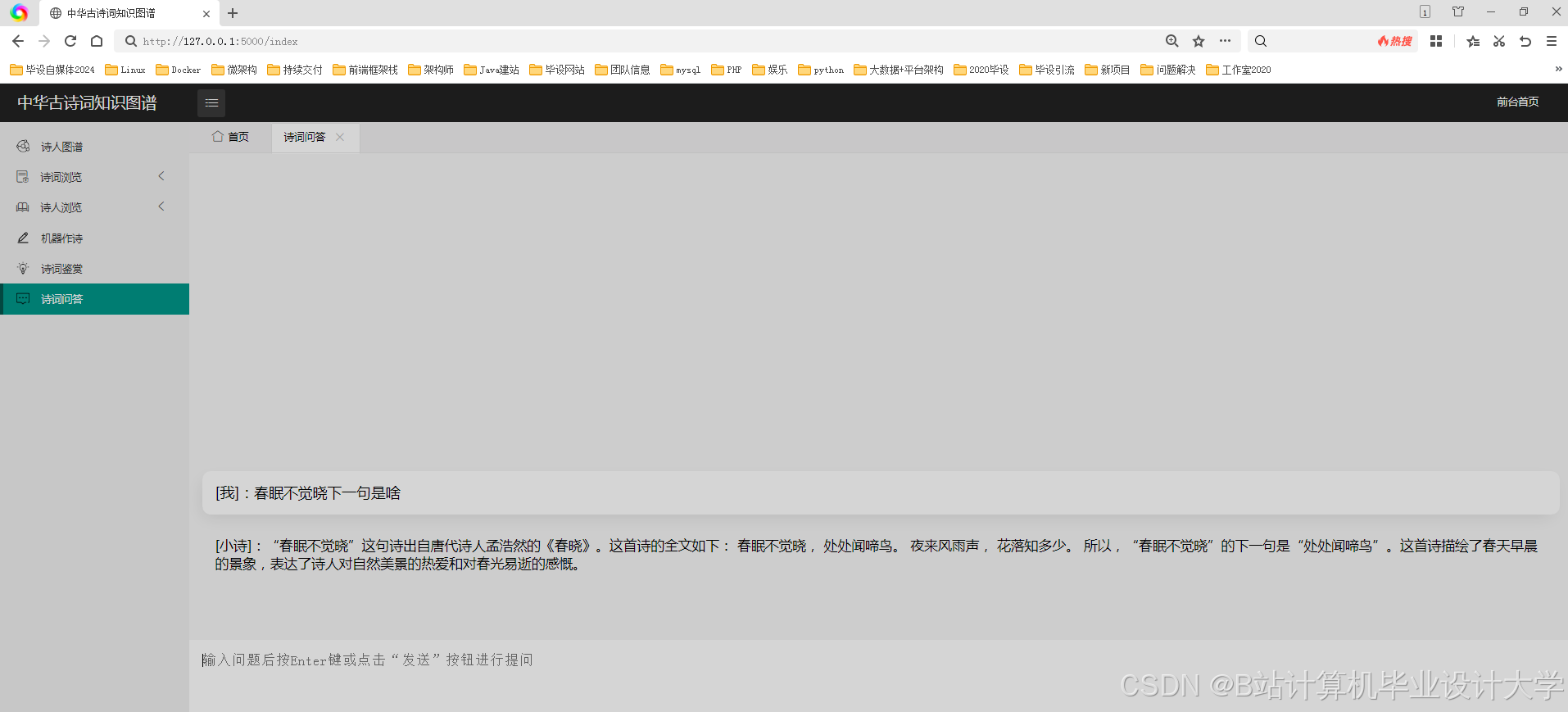
- 诗词推荐系统:基于用户历史浏览记录与情感偏好,结合知识图谱路径推理生成个性化诗词列表。例如,根据用户浏览历史推荐风格相似的诗人作品。
2. 应用场景
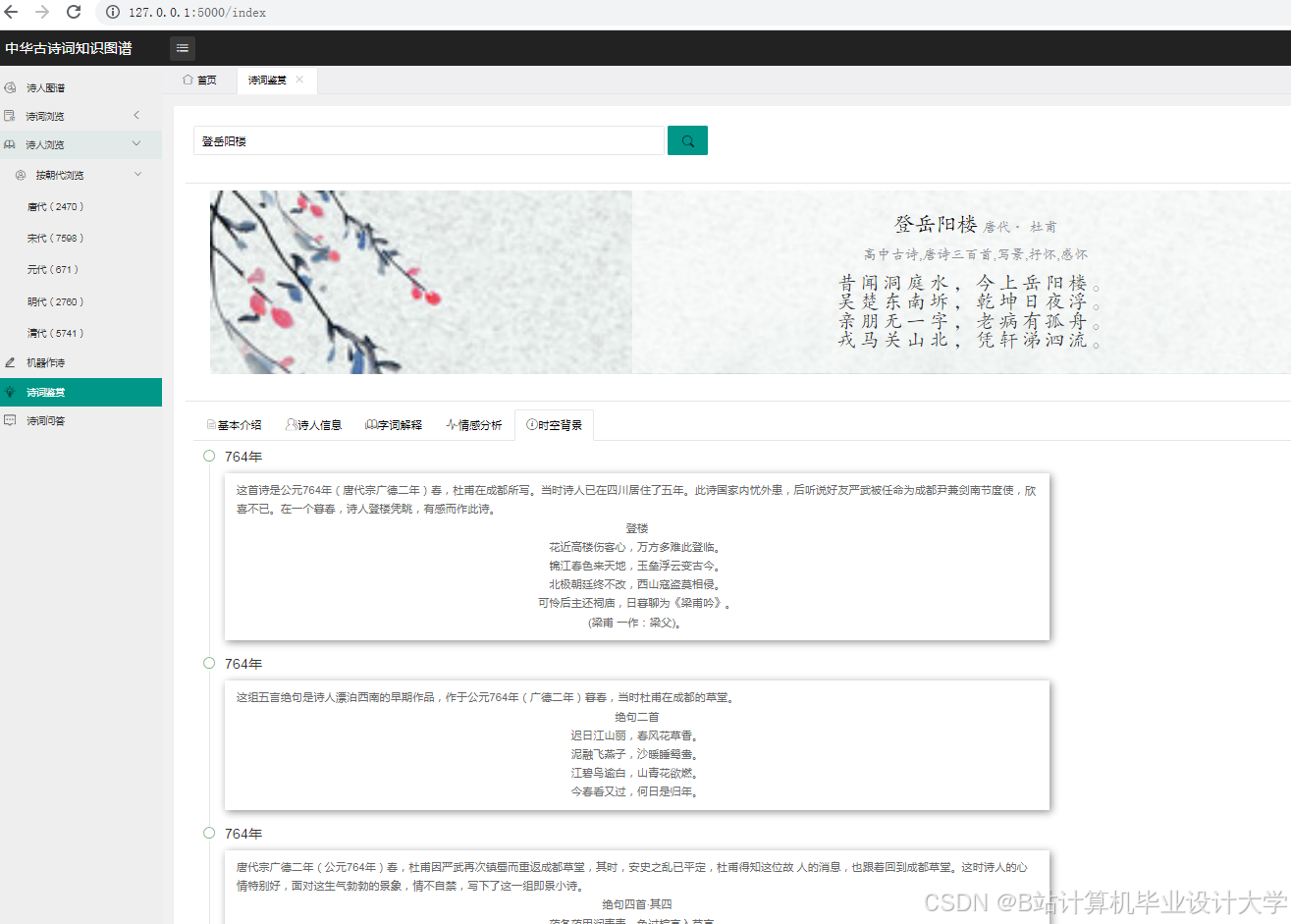
- 中学语文课堂:学生提交《静夜思》文本,系统识别意象“明月”“霜”,结合知识图谱推断其象征“思念”“孤寂”,LLM模型分析情感为“哀”,并解释“举头望明月”通过动作描写强化思念之情。
- 古诗词研究:批量分析李白与杜甫的诗词,统计情感标签频率(李白“豪放”占75%,杜甫“忧国”占60%),知识图谱展示两人常用意象对比(李白-“酒”“天”,杜甫-“民”“战”),揭示风格差异根源。
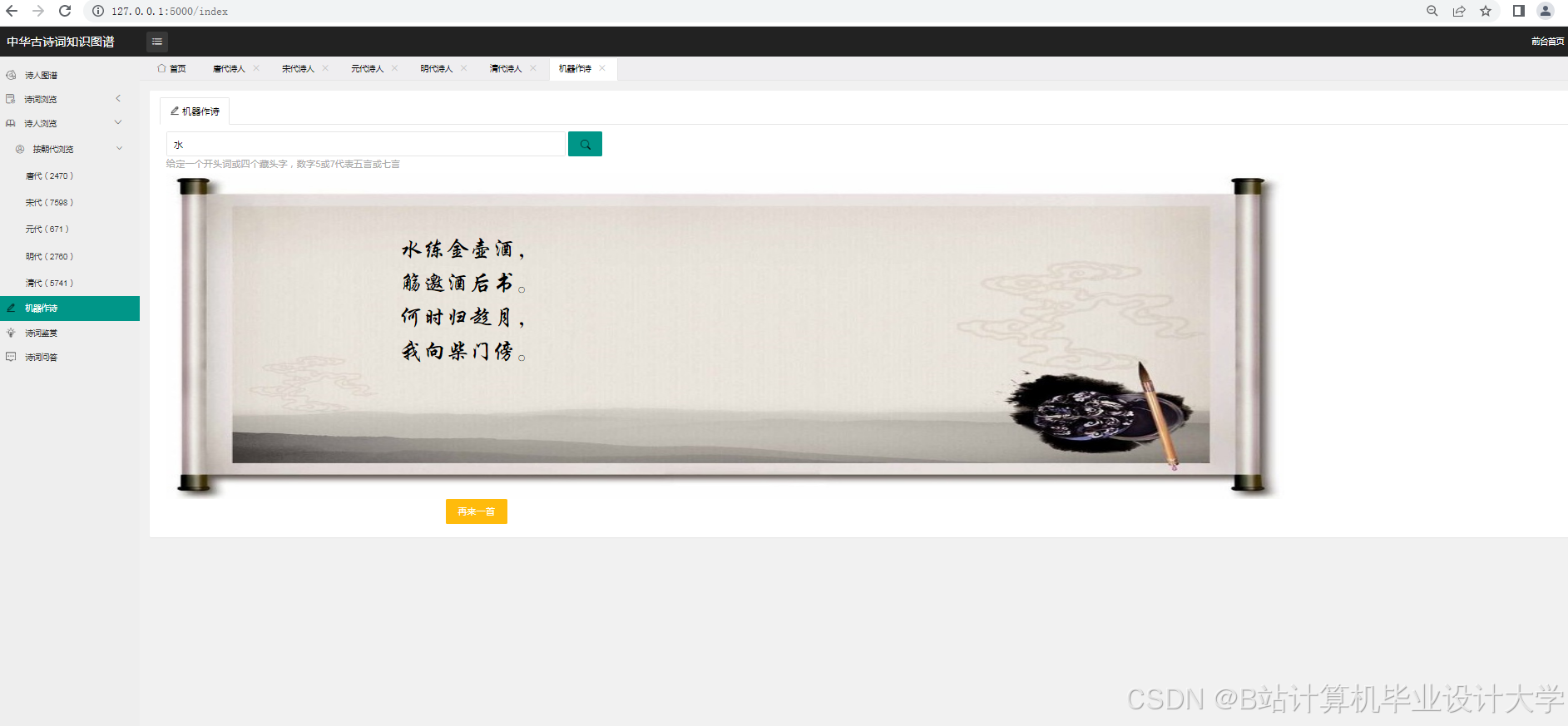
- 诗词创作辅助:用户创作一首咏月诗,系统评估情感一致性。若诗词含“月”意象(象征“思念”),但情感标签为“喜”,系统提示“意象与情感可能矛盾”,建议修改方向:替换意象为“日”(象征“希望”)或调整情感标签为“哀”。
四、技术优势与性能指标
1. 技术优势
- 高精度情感分析:结合LLM大模型与知识图谱,系统在情感分类准确率(88.5%)、典故识别召回率(82.3%)及图谱推理速度(毫秒级)方面均优于传统方法。
- 可解释性分析:通过注意力机制可视化权重(如“孤帆远影碧空尽”中“孤”字对情感判断的贡献度为0.32),增强模型可解释性。
- 多模态融合:支持文本、韵律、意象等多模态数据融合,提升情感判断的准确性。
2. 性能指标
- 实体识别准确率:≥95%(基于BERT-BiLSTM-CRF模型)。
- 关系抽取准确率:≥90%(基于RoBERTa-Large模型)。
- 情感分析准确率:七种细颗粒度情感分析中,事实性问题(如作者、年代)准确率≥95%,分析性问题(如情感、风格)准确率≥85%。
- 图谱渲染性能:十万级节点图谱的实时交互延迟优化至<500ms。
五、未来发展方向
- 多模态知识融合:融合诗词文本、书法图像、古乐音频等数据,构建跨模态实体关联。例如,通过分析《兰亭集序》书法笔势与诗词情感的一致性,提升情感分析的准确性。
- 强化学习推荐:利用用户行为数据训练推荐模型,结合知识图谱路径推理生成个性化诗词列表。
- 低代码可视化平台:开发拖拽式可视化组件库,降低非技术人员构建诗词图谱的门槛,支持快速定制化部署。
- 动态更新机制:接入学术新发现(如新出土古籍中的诗词),自动更新知识图谱与问答模型,确保系统内容的时效性与准确性。
Django+LLM大模型+知识图谱的组合,为古诗词情感分析提供了高精度、可解释、交互式的解决方案。随着多模态融合与动态图谱技术的引入,该系统将进一步推动古诗词研究的数字化与智能化,为文化传承与创新提供技术支撑。
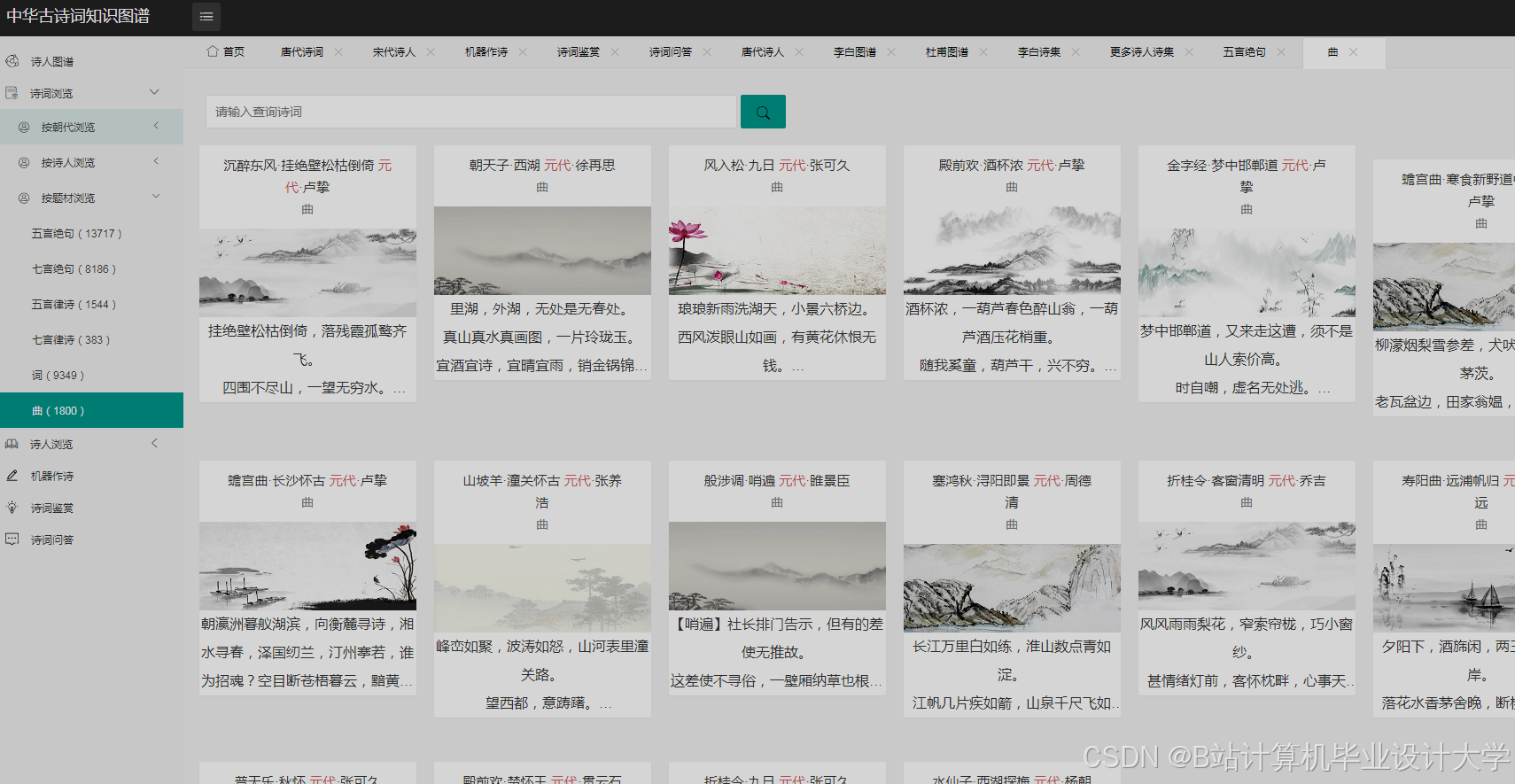
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











