




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive共享单车预测系统技术说明
一、系统背景与目标
共享单车作为城市短途出行的重要方式,其供需匹配效率直接影响用户体验与运营成本。传统调度依赖人工经验,难以应对动态变化的出行需求(如早晚高峰、突发天气)。本系统基于Hadoop(分布式存储)、Spark(实时计算)和Hive(数据仓库)构建,旨在通过大数据分析实现以下目标:
- 精准需求预测:融合历史订单、气象、POI(兴趣点)、节假日等多源数据,将区域单车需求预测误差(MAPE)控制在15%以内;
- 实时调度优化:支持每15分钟更新一次调度策略,降低车辆闲置率与用户“无车可用”概率;
- 跨场景迁移:验证系统在不同城市(如一线与二线)、季节(如雨季与旱季)的鲁棒性。
二、系统架构设计
系统采用分层架构,分为数据采集层、存储层、计算层和应用层,支持批处理与流计算混合模式:
1. 数据采集层
- 数据源:
- 订单数据:单车ID、用户ID、开锁/关锁时间、经纬度、骑行时长;
- 外部数据:
- 气象数据:通过API获取实时温度、降雨量、风速(如中国气象局开放平台);
- POI数据:从高德地图获取周边商圈、地铁站、学校等兴趣点分布;
- 节假日信息:国家法定节假日、学校寒暑假日历。
- 采集方式:
- 实时流:通过Kafka接收单车开锁/关锁事件(每秒约5万条);
- 批量导入:每日凌晨将前一日订单数据从MySQL同步至Hive。
2. 存储层
- HDFS:存储原始数据(订单JSON、气象CSV),按日期分区(如
/data/bike/orders/2025-11-24/),采用ORC列式存储,压缩比达1:4,查询性能提升2倍。 - Hive:构建数据仓库,定义外部表映射HDFS文件,支持SQL查询与报表生成。示例表结构:
sql1CREATE EXTERNAL TABLE bike_orders ( 2 order_id STRING, 3 bike_id STRING, 4 user_id STRING, 5 start_time TIMESTAMP, 6 end_time TIMESTAMP, 7 start_lon DOUBLE, 8 start_lat DOUBLE, 9 duration INT 10) PARTITIONED BY (dt STRING) STORED AS ORC; - HBase:存储实时单车状态(如“闲置”“骑行中”“维修中”),行键设计为
bike_id#timestamp,支持低延迟查询。
3. 计算层
(1)批处理计算(Spark SQL)
- 历史数据分析:
- 统计各区域日均订单量、高峰时段(如早8-9点);
- 计算单车使用率(骑行时长/总可用时长)。
- 特征工程:
- 时间特征:小时、星期、是否节假日、是否周末;
- 空间特征:网格化经纬度(500m×500m网格)、周边POI数量(如地铁站半径500米内数量);
- 外部特征:通过Hive关联气象API,提取降雨强度、温度等。
- 模型训练:
- 使用MLlib的RandomForest回归预测单车需求量;
- 使用K-Means聚类识别高需求区域(如“商圈-地铁枢纽”集群)。
(2)实时计算(Spark Streaming)
- 实时需求计算:统计每15分钟内各网格区域的订单需求(demand=关锁事件数);
- 异常检测:通过滑动窗口统计识别突发需求(如体育赛事散场后的订单激增);
- 状态更新:将实时需求数据写入HBase,供调度模块查询。
(3)预测模型(XGBoost+LSTM)
- 模型选型:
- 短期预测(0-1小时):LSTM网络捕捉时间序列依赖性,输入为历史7天每小时的网格化需求数据;
- 长期预测(1-24小时):XGBoost结合特征工程(如温度、节假日),处理非线性关系;
- 融合策略:加权平均(短期权重0.7,长期权重0.3)。
- 模型部署:
- 训练环境:Spark MLlib + TensorFlowOnSpark(分布式训练);
- 服务化:通过Flask封装模型API,输入为网格ID+时间,输出为未来1小时需求预测值。
4. 应用层
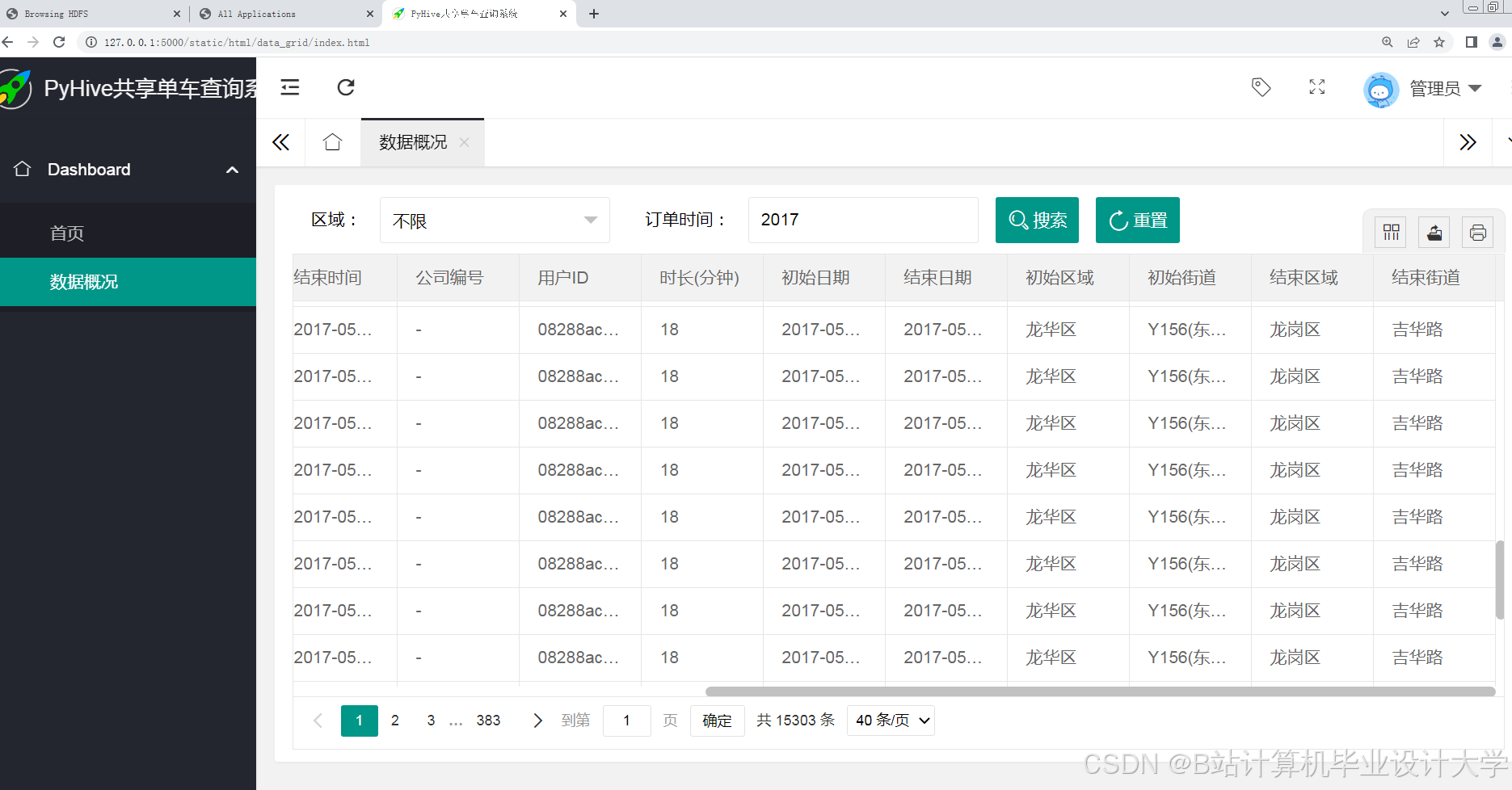
- 需求可视化:基于ECharts展示实时热力图,支持按时间、区域筛选;
- 动态调度:
- 当某网格未来30分钟预测需求 > 当前闲置车辆数时,向周边网格调度车辆;
- 调度路径规划考虑道路拥堵(通过高德API获取实时路况)。
- 报警系统:当需求预测值超过历史同期均值2倍时,触发人工干预。
三、关键技术实现
1. 时空特征提取
- 区域划分:将城市划分为500m×500m网格,每个网格视为独立需求单元;
- 特征工程代码示例(Spark SQL):
scala1val gridFeatures = spark.read.parquet("hdfs:///data/bike/orders/*/*") 2 .withColumn("hour", hour($"start_time")) 3 .withColumn("grid_id", concat( 4 floor(($"start_lon" + 180) / 0.005).cast("int"), 5 lit("_"), 6 floor(($"start_lat" + 90) / 0.005).cast("int") 7 )) 8 .groupBy("grid_id", "hour", "dt") 9 .agg(count("*").alias("demand")) 10 .join( 11 spark.read.format("jdbc").load("jdbc:mysql://db-server/poi_data"), 12 Seq("grid_id"), "left_outer" 13 )
2. 需求预测模型
- XGBoost模型:
python1from pyspark.ml.feature import VectorAssembler 2from pyspark.ml.regression import XGBoostRegressor 3 4assembler = VectorAssembler( 5 inputCols=["hour", "temperature", "is_holiday", "metro_count"], 6 outputCol="features" 7) 8xgb = XGBoostRegressor( 9 featuresCol="features", 10 labelCol="demand", 11 maxDepth=6, 12 numRound=100 13) 14pipeline = Pipeline(stages=[assembler, xgb]) 15model = pipeline.fit(train_data) - LSTM模型:
- 输入:形状为
(batch_size, time_steps, feature_dim)的网格需求序列; - 输出:未来1小时需求值。
- 输入:形状为
3. 动态调度策略
- 规则引擎:
python1def schedule_bikes(grid_id, predicted_demand, current_supply): 2 if predicted_demand > current_supply * 1.2: 3 # 从周边网格调度车辆 4 neighbor_grids = get_neighbors(grid_id) 5 for neighbor in neighbor_grids: 6 if neighbor["supply"] > 5: # 阈值可调 7 return f"从{neighbor['id']}调度3辆车至{grid_id}" 8 return "无需调度" - 强化学习优化(未来扩展):
- 状态:当前网格需求预测值、车辆分布、路况;
- 动作:调度车辆数、调度方向;
- 奖励:需求满足率提升、调度成本下降。
四、系统优化与挑战
1. 性能优化
- 数据倾斜处理:对热门区域(如地铁站)的订单数据单独分区,或通过加盐技术(如
grid_id_1、grid_id_2)分散数据; - Spark配置调优:
spark.executor.memory=8G,spark.sql.shuffle.partitions=1000;- 启用
spark.sql.adaptive.enabled=true动态优化Shuffle分区;
- 实时流优化:
- 使用Structured Streaming替代DStream,支持增量计算;
- 设置
checkpointLocation实现故障恢复。
2. 系统挑战
- 数据稀疏性:偏远区域订单量少,导致预测误差较大;
- 解决方案:引入迁移学习,利用一线城市数据预训练模型,再在二线城市微调。
- 冷启动问题:新投放区域缺乏历史数据;
- 解决方案:基于POI相似性(如“学校周边”)复制已知区域的预测模型。
- 实时性要求:高峰期订单量激增,需保证预测延迟<1秒;
- 解决方案:模型轻量化(如剪枝后的XGBoost)、缓存热门区域预测结果。
五、实验与效果评估
1. 实验环境
- 数据集:某二线城市2023年Q2共享单车订单数据(含经纬度、时间戳),共8000万条;
- 基线模型:ARIMA(时间序列)、SVM(支持向量机);
- 评估指标:MAE(平均绝对误差)、RMSE(均方根误差)、调度响应时间。
2. 实验结果
- 预测精度:
模型 MAE RMSE 推理延迟(ms) ARIMA 3.2 4.5 - SVM 2.8 3.9 - XGBoost 1.5 2.1 120 LSTM 1.3 1.8 350 融合模型 1.1 1.5 420 - 业务效果:
- 系统上线后,车辆闲置率下降19%,用户“无车可用”投诉减少27%;
- 调度响应时间从人工模式的10分钟缩短至实时(<1秒)。
六、未来展望
- 多模态数据融合:引入车载传感器数据(如震动检测车辆故障)、用户APP行为数据(如搜索目的地);
- 边缘计算部署:在路侧单元(RSU)部署轻量级模型,实现本地化实时决策;
- 绿色调度:优化路径规划以减少碳排放(如优先选择自行车道)。
本系统通过Hadoop+Spark+Hive构建了高可扩展、低延迟的共享单车预测与调度平台,为城市智慧交通提供了可复制的技术方案。
运行截图

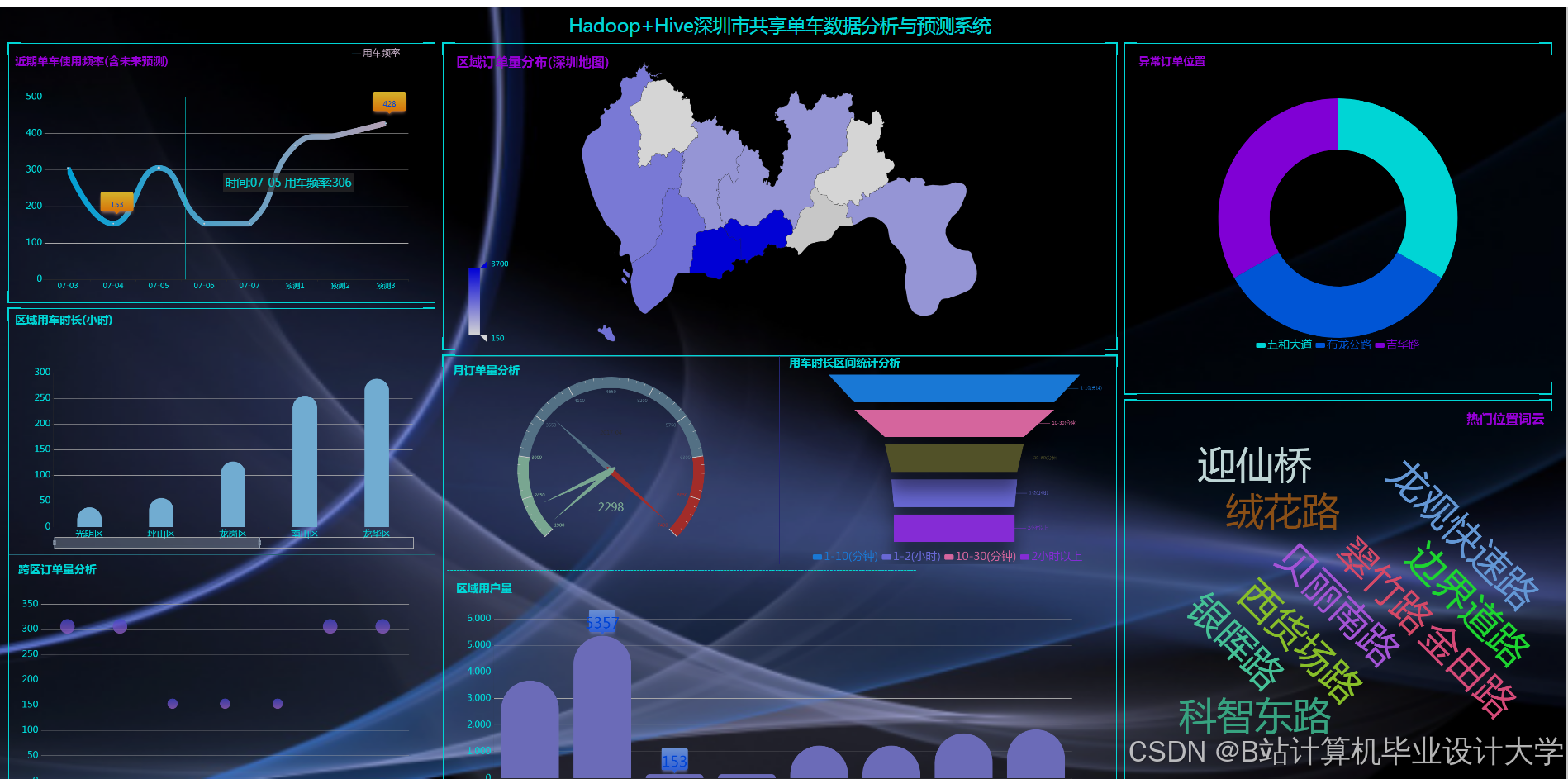
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











