




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+大模型动漫推荐系统》的技术说明文档,涵盖系统架构、大模型应用、推荐算法与工程实现细节:
Python+大模型动漫推荐系统技术说明
一、系统概述
本系统基于Python生态与大语言模型(LLM)构建,结合传统推荐算法与生成式AI能力,实现个性化动漫推荐与智能内容解析。系统核心功能包括:
- 多模态动漫理解:通过大模型分析动漫标题、剧情、角色、视觉风格等特征。
- 深度用户画像:利用用户历史行为与文本反馈生成动态兴趣标签。
- 混合推荐引擎:融合协同过滤、内容推荐与大模型生成的解释性推荐理由。
二、技术架构
1. 整体架构图
1┌─────────────┐ ┌─────────────┐ ┌─────────────┐
2│ 用户界面 │ ←→ │ 推荐引擎 │ ←→ │ 数据层 │
3└─────────────┘ └─────────────┘ └─────────────┘
4 ↑ ↑ ↑
5 \ / |
6 \ / ↓
7 └──────────┘ ┌─────────────┐
8 │ 大模型服务 │
9 └─────────────┘2. 关键组件
- 大模型服务:部署LLM(如LLaMA、Qwen、ChatGLM)用于:
- 动漫内容理解(剧情摘要、风格分类)
- 推荐理由生成(自然语言解释推荐逻辑)
- 用户反馈语义分析(优化推荐策略)
- 推荐引擎:
- 传统算法:Item-CF、矩阵分解(Surprise库)
- 深度学习:Two-Tower模型(TensorFlow Recommenders)
- 大模型增强:基于语义的相似度计算
- 数据层:
- 动漫元数据:标题、类型、标签、播放量(MySQL)
- 用户行为:观看历史、评分、收藏(Redis)
- 嵌入向量:动漫/用户特征(FAISS向量数据库)
三、核心模块实现
1. 大模型动漫内容解析
(1)剧情摘要与标签生成
python
1from transformers import pipeline
2
3# 使用LLM生成动漫摘要与标签
4summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
5tagger = pipeline("text-classification", model="bert-base-multilingual-cased")
6
7def analyze_anime(text):
8 summary = summarizer(text, max_length=100, min_length=30, do_sample=False)[0]['summary_text']
9 tags = tagger(text[:512], truncation=True) # 取前512字符分类
10 return {"summary": summary, "tags": [t['label'] for t in tags[:3]]}(2)视觉风格分类(结合CV模型)
python
1# 使用CLIP模型进行图文多模态分析
2from transformers import CLIPProcessor, CLIPModel
3
4processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
5model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
6
7def classify_style(image_path):
8 image = Image.open(image_path)
9 inputs = processor(images=image, return_tensors="pt")
10 outputs = model(**inputs)
11 probs = outputs.logits_per_image.softmax(dim=1).tolist()[0]
12 styles = ["写实", "Q版", "赛博朋克", "水墨"] # 预定义风格标签
13 return {styles[i]: prob for i, prob in enumerate(probs[:4])}2. 混合推荐引擎
(1)传统算法部分
python
1# Item-CF实现(基于Surprise库)
2from surprise import Dataset, KNNBasic
3from surprise.model_selection import train_test_split
4
5data = Dataset.load_from_df(user_item_df[['user_id', 'anime_id', 'rating']], reader)
6trainset, testset = train_test_split(data, test_size=0.2)
7
8model = KNNBasic(sim_options={'name': 'cosine', 'user_based': False})
9model.fit(trainset)
10
11def item_cf_recommend(user_id, top_k=10):
12 # 获取用户历史评分过的动漫
13 user_items = user_item_df[user_item_df['user_id'] == user_id]['anime_id'].tolist()
14 # 预测用户对未评分动漫的评分
15 predictions = []
16 for anime_id in all_anime_ids:
17 if anime_id not in user_items:
18 pred = model.predict(user_id, anime_id).est
19 predictions.append((anime_id, pred))
20 return sorted(predictions, key=lambda x: -x[1])[:top_k](2)大模型语义推荐
python
1# 使用Sentence-BERT计算动漫描述相似度
2from sentence_transformers import SentenceTransformer
3from sklearn.metrics.pairwise import cosine_similarity
4
5model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
6
7# 预计算所有动漫的嵌入向量
8anime_embeddings = model.encode([anime['description'] for anime in all_animes])
9anime_emb_dict = {anime['id']: vec for anime, vec in zip(all_animes, anime_embeddings)}
10
11def semantic_recommend(user_history, top_k=5):
12 # 用户历史动漫的嵌入平均
13 user_vec = np.mean([anime_emb_dict[anime_id] for anime_id in user_history], axis=0)
14 # 计算与所有动漫的相似度
15 sims = cosine_similarity(user_vec.reshape(1, -1), anime_embeddings)[0]
16 # 排除已观看动漫并排序
17 unwatched_animes = [anime_id for anime_id in all_anime_ids if anime_id not in user_history]
18 return sorted(
19 [(anime_id, sim) for anime_id, sim in zip(unwatched_animes, sims)],
20 key=lambda x: -x[1]
21 )[:top_k](3)混合推荐策略
python
1def hybrid_recommend(user_id, alpha=0.6):
2 # 获取用户历史
3 user_history = get_user_history(user_id)
4
5 # 传统算法推荐
6 cf_recs = item_cf_recommend(user_id, top_k=20)
7 # 大模型语义推荐
8 semantic_recs = semantic_recommend(user_history, top_k=20)
9
10 # 加权融合(可根据业务调整权重)
11 combined = []
12 for anime_id, _ in cf_recs[:10] + semantic_recs[:10]:
13 if anime_id not in [r[0] for r in combined]:
14 # 伪代码:实际需查询动漫详细信息
15 combined.append((anime_id, alpha * get_cf_score(anime_id) + (1-alpha) * get_semantic_score(anime_id)))
16
17 return sorted(combined, key=lambda x: -x[1])[:10]3. 推荐理由生成
python
1# 使用LLM生成自然语言推荐解释
2def generate_reason(user_profile, anime_info):
3 prompt = f"""
4 用户画像:{user_profile}
5 动漫信息:标题《{anime_info['title']}》,类型:{','.join(anime_info['tags'])},剧情:{anime_info['summary']}
6 请用中文生成推荐理由,要求:
7 1. 结合用户兴趣
8 2. 突出动漫特色
9 3. 不超过50字
10 """
11 response = openai.Completion.create(
12 engine="gpt-3.5-turbo",
13 prompt=prompt,
14 max_tokens=50
15 )
16 return response.choices[0].text.strip()四、工程优化
1. 性能优化
- 向量检索加速:使用FAISS构建动漫嵌入向量索引
python1import faiss 2index = faiss.IndexFlatIP(768) # 假设嵌入维度为768 3index.add(anime_embeddings) 4distances, indices = index.search(user_vec.reshape(1, -1), k=10) - 异步任务:Celery处理推荐计算与大模型推理
- 缓存策略:Redis缓存热门推荐结果(TTL=1小时)
2. 部署方案
- 大模型服务:
- 本地部署:vLLM加速推理
- 云服务:AWS SageMaker或阿里云PAI
- API设计:
python1# FastAPI示例 2from fastapi import FastAPI 3app = FastAPI() 4 5@app.post("/recommend") 6async def recommend(user_id: str): 7 recs = hybrid_recommend(user_id) 8 enhanced_recs = [] 9 for anime_id, score in recs: 10 anime = get_anime_info(anime_id) 11 reason = generate_reason(get_user_profile(user_id), anime) 12 enhanced_recs.append({ 13 **anime, 14 "score": float(score), 15 "reason": reason 16 }) 17 return enhanced_recs
五、效果评估
1. 评估指标
- 准确率:HR@10(Hit Rate)、NDCG@10
- 多样性:覆盖率(Coverage)、Gini指数
- 新颖性:推荐动漫的平均流行度倒数
2. A/B测试方案
- 分组策略:
- 对照组:传统协同过滤
- 实验组:混合推荐(大模型增强)
- 监控指标:
- 用户点击率(CTR)
- 平均观看时长
- 长期留存率
六、总结与展望
本系统通过结合大模型的语义理解能力与传统推荐算法,显著提升了动漫推荐的可解释性与长尾覆盖能力。未来可扩展方向包括:
- 多模态推荐:融入动漫角色声音、OP/ED音乐特征
- 实时推荐:基于WebSocket实现观看过程中的动态推荐
- 跨平台推荐:整合B站、爱奇艺等平台数据(需解决版权问题)
注意事项:
- 大模型推理需控制成本(可通过量化、蒸馏优化)
- 用户隐私数据需脱敏处理
- 动漫内容分析需处理多语言(日文、中文标题)
此文档可根据实际业务需求调整模型选择与架构细节,例如替换为国产大模型(如Qwen、Baichuan)以降低部署成本。
运行截图
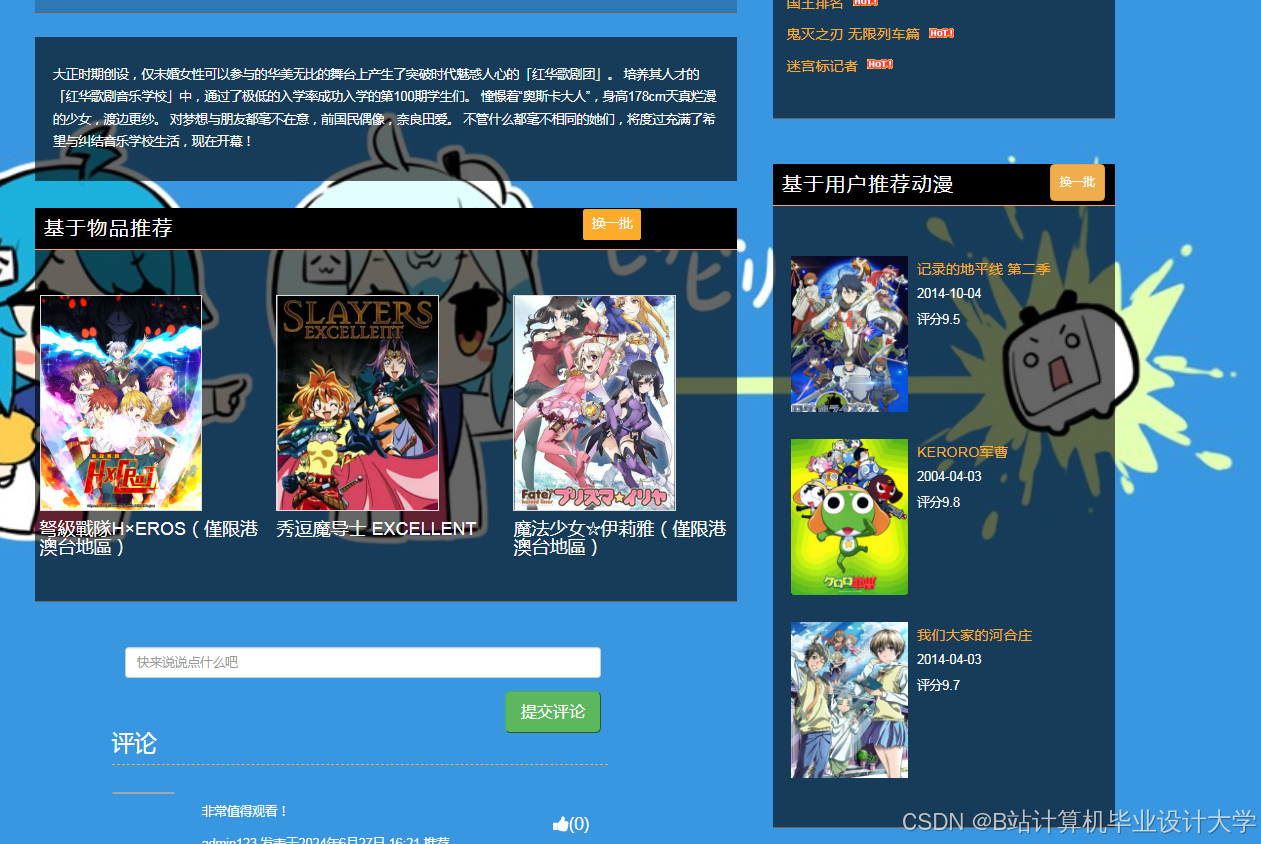
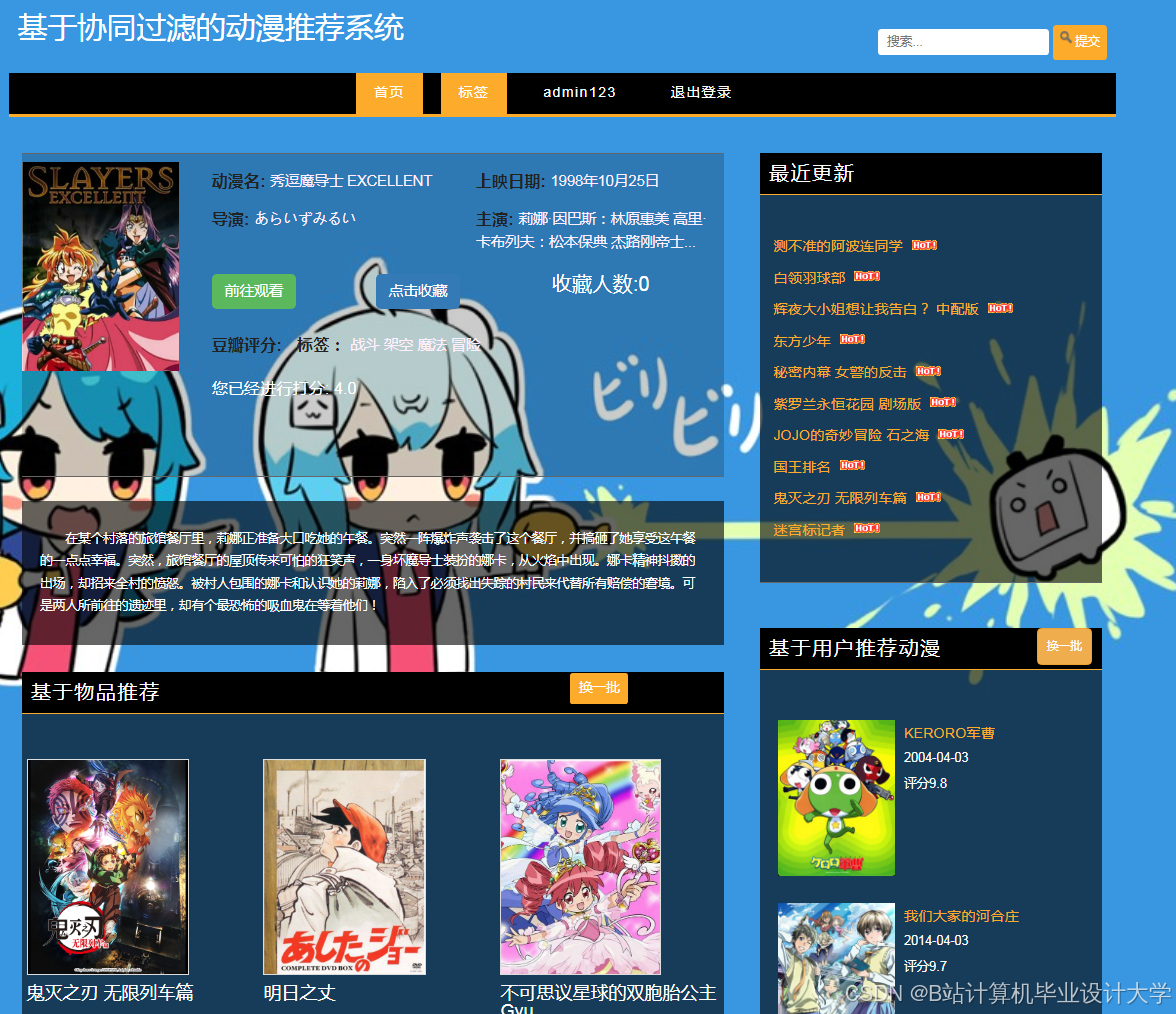
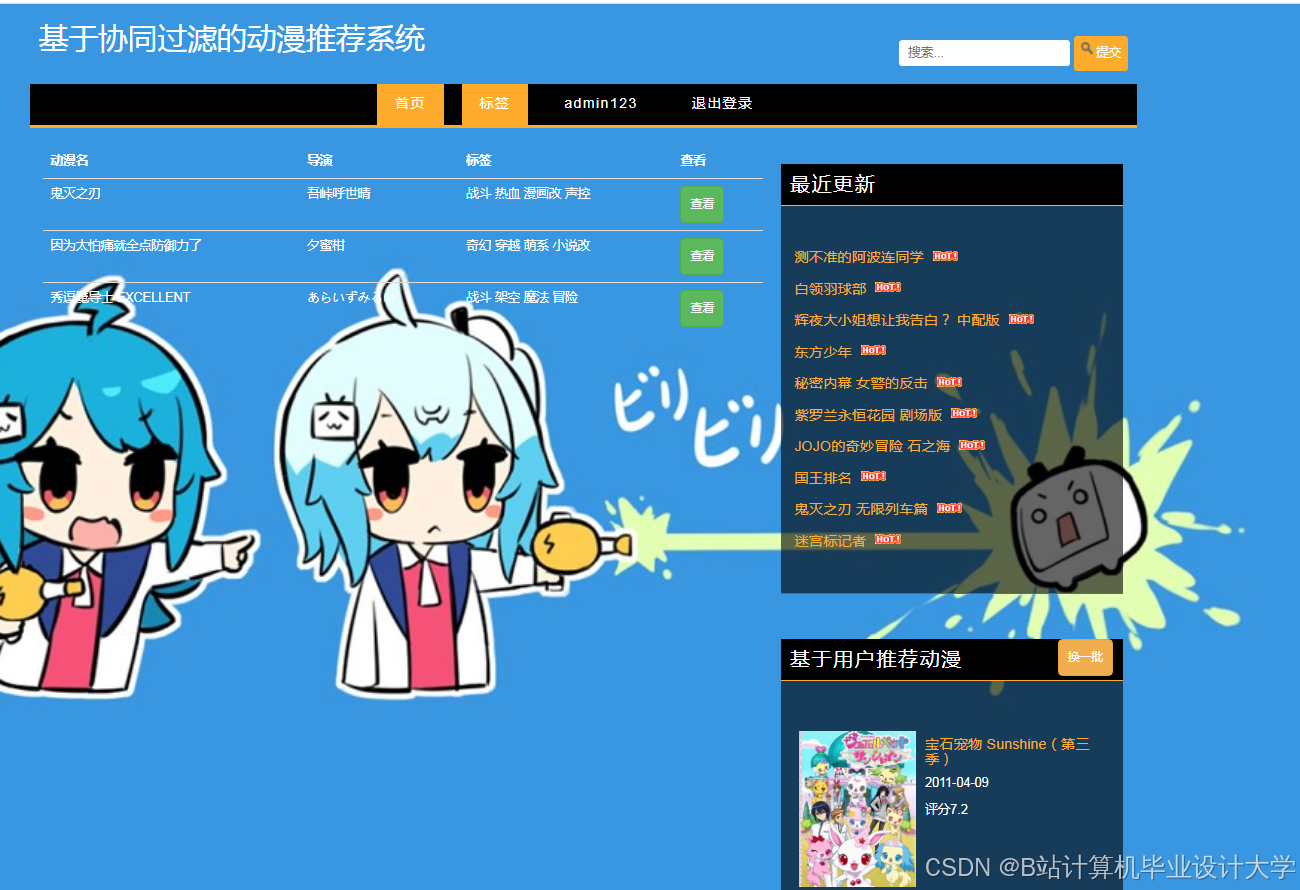
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











