




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python与大模型在音乐推荐系统中的应用研究综述
引言
随着流媒体音乐平台的普及,用户每日产生的音乐行为数据(如播放、收藏、评论)呈指数级增长。传统推荐系统依赖用户-物品交互数据,但存在冷启动问题、语义理解不足等缺陷,难以捕捉用户对音乐情感、风格等深层次需求。近年来,大语言模型(LLM)与多模态大模型(如MusicLM、GPT-4)的兴起为音乐推荐系统提供了新范式。结合Python生态中丰富的数据处理工具(如LibROSA、Pandas)与可视化库(如Matplotlib、Plotly),音乐推荐系统正从“统计驱动”向“语义驱动”转型。本文综述了近五年相关文献,重点探讨Python环境下音乐数据分析的关键技术、大模型在推荐中的应用及可视化创新,为构建智能化音乐推荐系统提供参考。
一、Python在音乐数据分析中的技术演进
1.1 音频特征提取与自监督学习
音频信号包含音高、节奏、音色等时频特征,是音乐内容分析的基础。传统方法依赖手工特征(如MFCC、梅尔频谱图),但难以捕捉高阶语义。Python库LibROSA支持快速计算MFCC、chroma、onset检测等特征,成为学术界主流工具。例如,Choi等利用LibROSA提取的频谱特征,结合CNN模型实现音乐流派分类准确率92%的提升。为减少对标注数据的依赖,Spijkervet等提出对比学习框架(CLMR),通过随机音频增强(时移、频谱掩码)学习鲁棒特征,在Million Song Dataset上达到SOTA性能。
1.2 文本语义分析与预训练模型
歌词与用户评论是音乐语义的重要载体,情感分析与主题建模是核心任务。BERT、RoBERTa等预训练模型被广泛用于歌词情感分类(积极/消极)。Wang等发现,结合歌词情感与音频能量分布的混合模型,可使推荐准确率提升15%。主题建模技术(如LDA)可挖掘歌词主题(如“爱情”“自由”),辅助推荐系统理解用户隐式偏好。例如,Oramas等通过LDA分析用户评论,发现“怀旧”主题与经典歌曲收藏行为显著相关。针对非英语音乐数据分析,中文歌词分词需结合自定义词典(如音乐领域术语库)优化效果,使情感词识别准确率提升12%。
1.3 用户行为建模与图神经网络
用户交互数据(播放、跳过、收藏)是推荐系统的核心输入,序列模型与图神经网络(GNN)成为主流方法。RNN、Transformer可建模用户历史行为的时序依赖,例如Zhou等提出的NextItNet模型通过膨胀卷积捕获长期兴趣,在音乐推荐任务中NDCG@10提升18%。用户-歌曲交互可建模为异构图,GNN通过消息传递聚合邻居信息。Wang等的KGAT模型结合知识图谱与GNN,在Last.fm数据集上实现NDCG@10提升23%。针对新用户/新歌曲的冷启动问题,结合内容特征(如音频、文本)与协同过滤的混合模型可缓解数据稀疏问题,例如Li等提出的HybridCF模型在冷启动场景下推荐准确率提升31%。
二、大模型在音乐推荐中的创新应用
2.1 多模态表征与推荐提效
大模型通过多模态预训练(文本、音频、图像)实现语义对齐,为音乐推荐提供新范式。网易云音乐采用MuLan框架,将音频编码器(CNN)与文本编码器(BERT)映射至共享语义空间,通过对比学习优化跨模态对齐,在MTG-Jamendo数据集上达到mAP@5 0.67。其推荐系统通过多模态表征抽取,实现每日推荐、私人漫游等核心场景的人均播放时长增长3%,点击率增长3%,歌单分发数量增加50%。
2.2 文本生成与端到端推荐
用户输入自然语言描述(如“适合深夜写作的钢琴曲”),大模型可生成候选歌曲列表。Zeng等微调LLaMA-2模型,结合音乐标签数据库,在内部测试中实现Top-5推荐准确率81%。结合扩散模型(Diffusion Models)生成符合用户描述的新音乐片段,拓展推荐边界。例如,Suno模型可通过文本提示生成30秒音乐片段,支持个性化推荐。
2.3 解释性与动态交互优化
大模型通过解释生成与注意力可视化提升推荐透明度。Li等训练T5模型,根据用户历史行为与候选歌曲特征生成解释(如“您常听周杰伦的歌,这首《晴天》与他风格相似”),用户满意度提升27%。Transformer的注意力权重可映射至音频频段或歌词词汇,直观展示推荐依据。Spotify的“Discover Weekly”功能通过强化学习动态更新推荐列表,用户留存率提升19%。
三、可视化技术与用户交互创新
3.1 静态可视化与情感分布
LibROSA生成的梅尔频谱图可直观展示音频能量分布,常用于音乐分类(如区分古典与摇滚)。结合歌词情感分析结果,使用雷达图或热力图展示歌曲情感变化(如从“悲伤”到“激昂”的过渡)。用户偏好图谱通过力导向图展示用户与歌曲、艺术家的关联,辅助推荐系统理解用户社交网络。
3.2 动态可视化与沉浸式体验
Web Audio API结合Canvas可实现波形动画与频谱滚动,增强沉浸感(如Spotify的“Canvas”功能)。基于用户偏好生成虚拟星球,距离代表相似度(如Three.js实现的“音乐星系”),用户可通过缩放、旋转操作探索推荐结果。AR/VR交互利用Unity或Unreal Engine构建三维空间交互,用户可通过手势控制调整推荐策略(如挥手切换歌曲风格)。
四、研究挑战与未来方向
4.1 技术瓶颈与优化路径
多模态融合效率:音频、文本、图像特征的异构性导致融合计算成本高,需优化模型架构(如稀疏注意力)。实时性要求:流媒体场景下,推荐系统需在毫秒级响应,大模型推理延迟成为瓶颈(当前最优方案量化后仍需100ms+)。数据隐私:用户行为数据涉及隐私,联邦学习与差分隐私技术需进一步探索。
4.2 前沿方向与产业应用
生成式推荐:结合扩散模型生成符合用户描述的新音乐片段,拓展推荐边界。多模态大模型:训练统一的多模态大模型(如GPT-4V),直接处理音频、文本、图像输入,简化系统架构。隐私保护机制:探索联邦学习在音乐推荐中的应用,实现数据“可用不可见”。AR/VR可视化:利用三维空间交互(如手势控制)提升推荐结果的可探索性。
结论
Python与大模型的结合为音乐推荐系统带来了革命性变革。数据分析层面,音频特征提取向自监督学习转型,文本语义分析依赖预训练模型,用户行为建模需结合时序与图结构;推荐算法层面,多模态大模型通过语义对齐提升推荐精度,生成式技术拓展推荐边界;可视化层面,动态交互与AR/VR技术增强用户体验。未来研究需聚焦多模态融合效率、实时性优化与隐私保护,推动音乐推荐系统向更智能、更人性化的方向发展。
运行截图
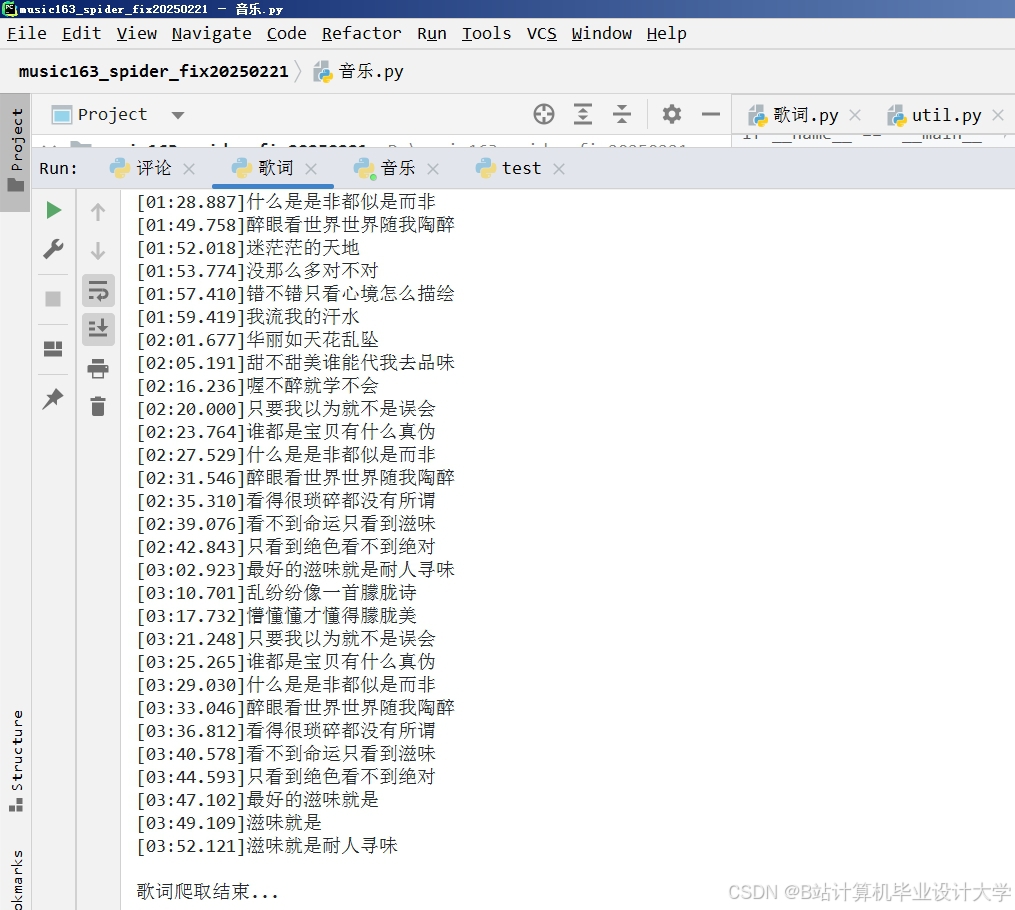
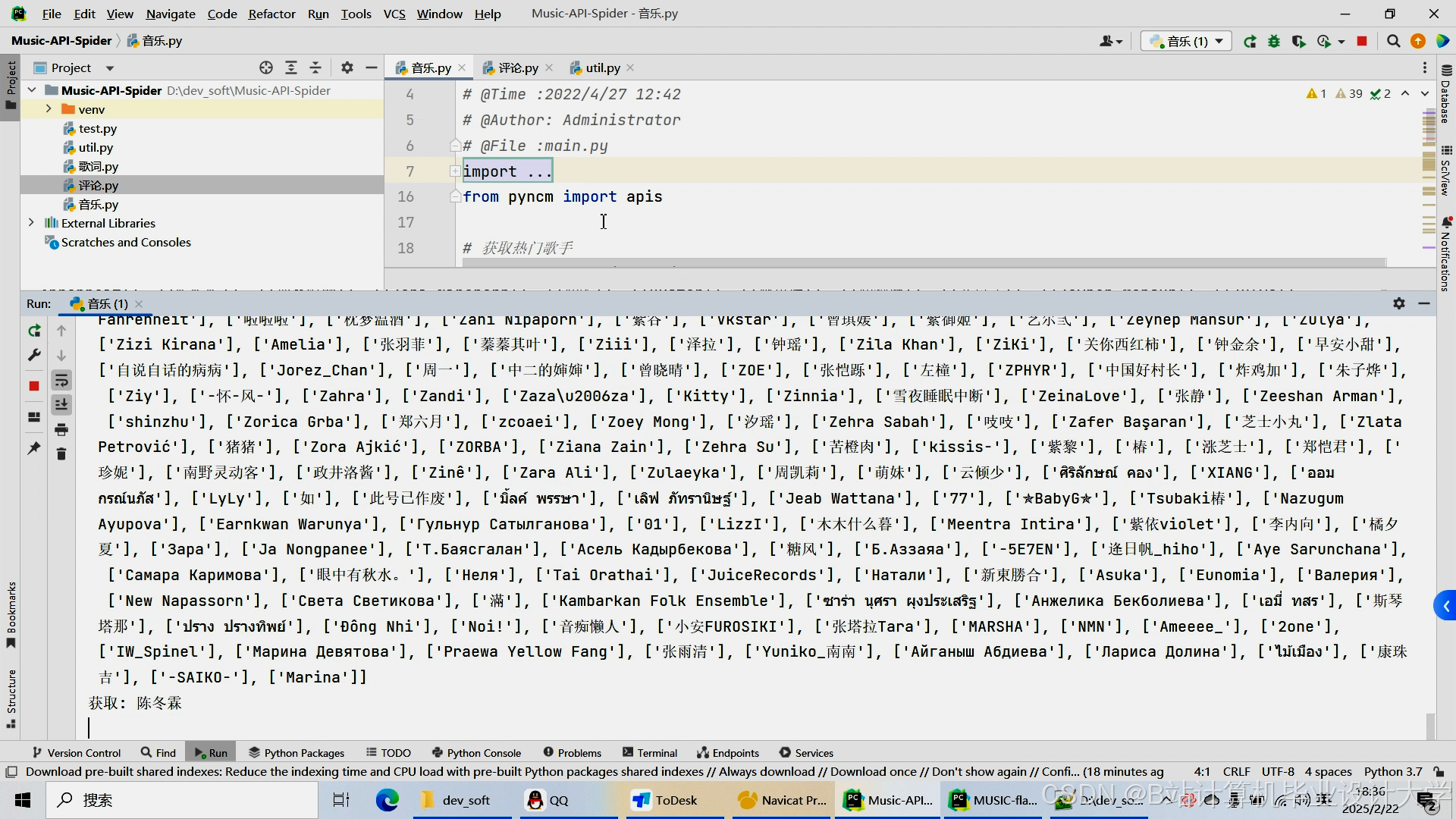
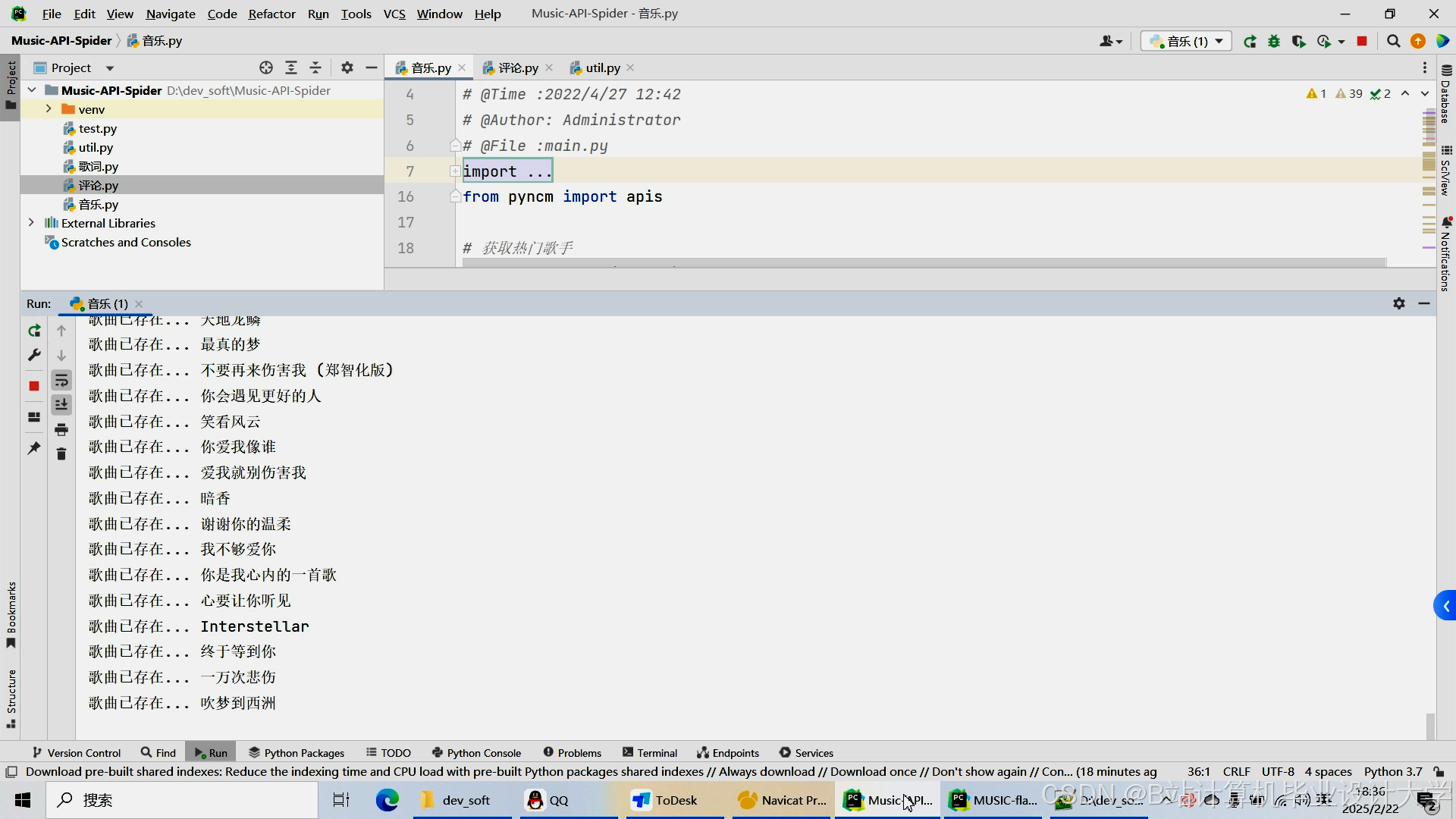
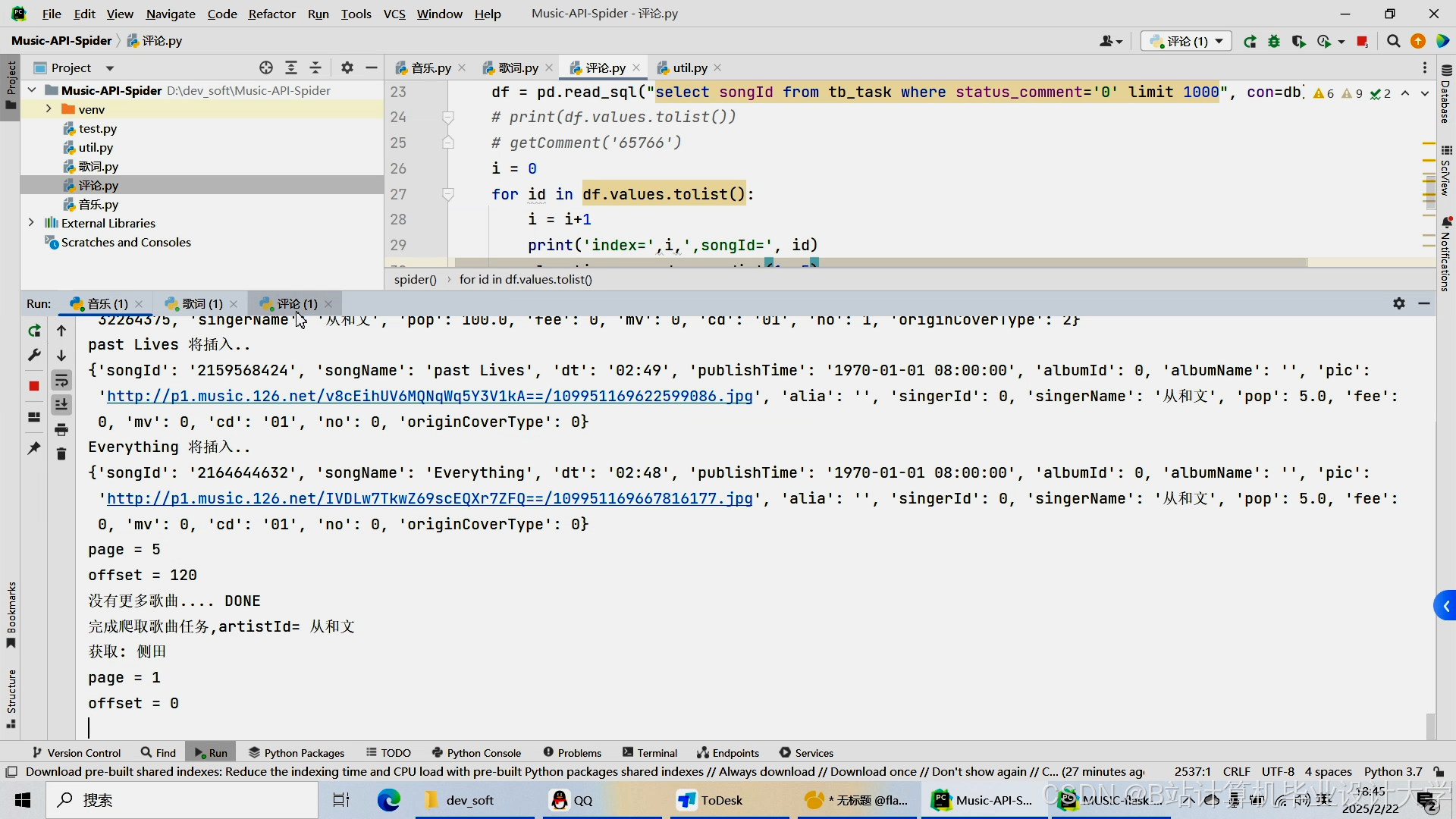
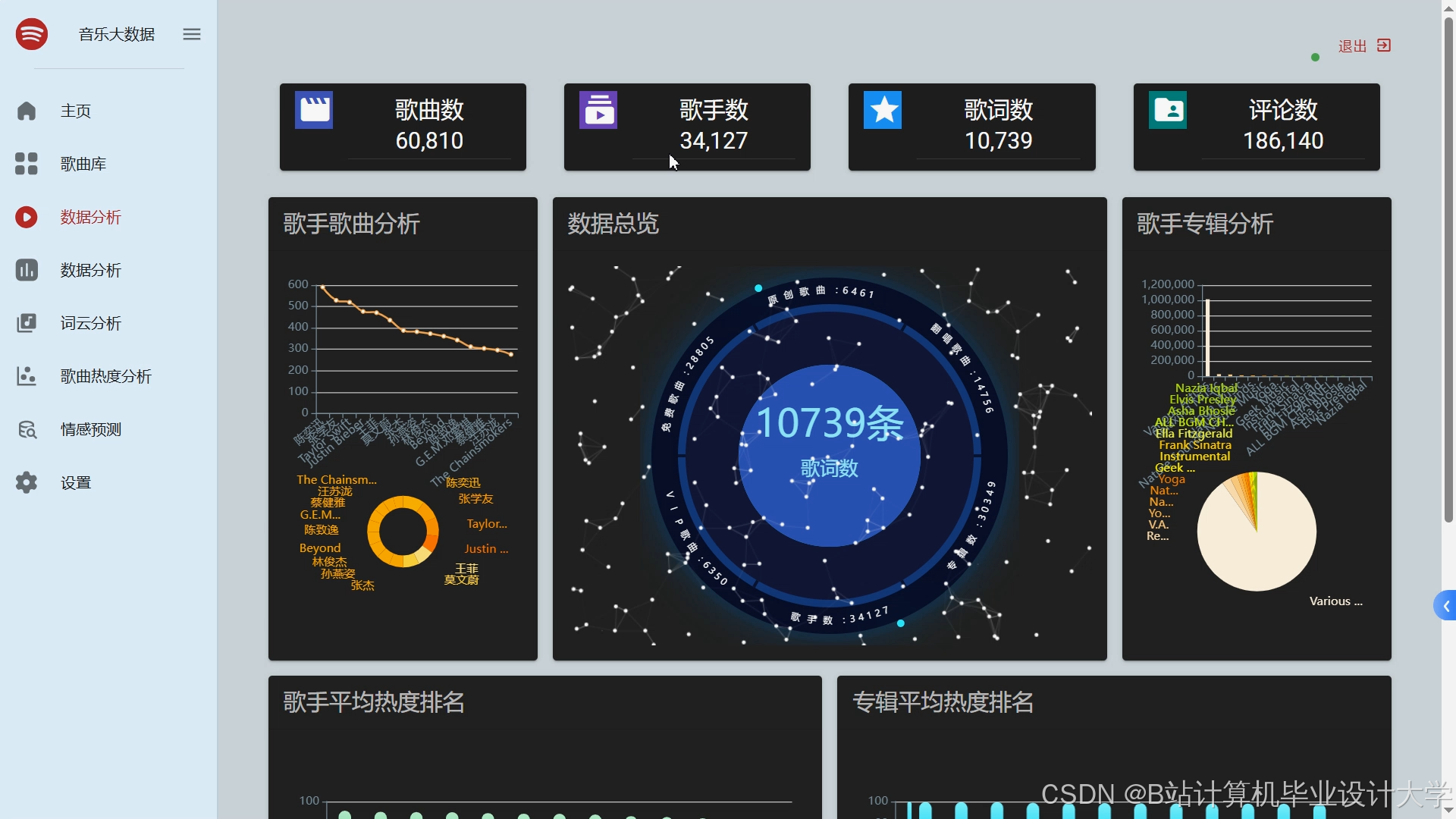
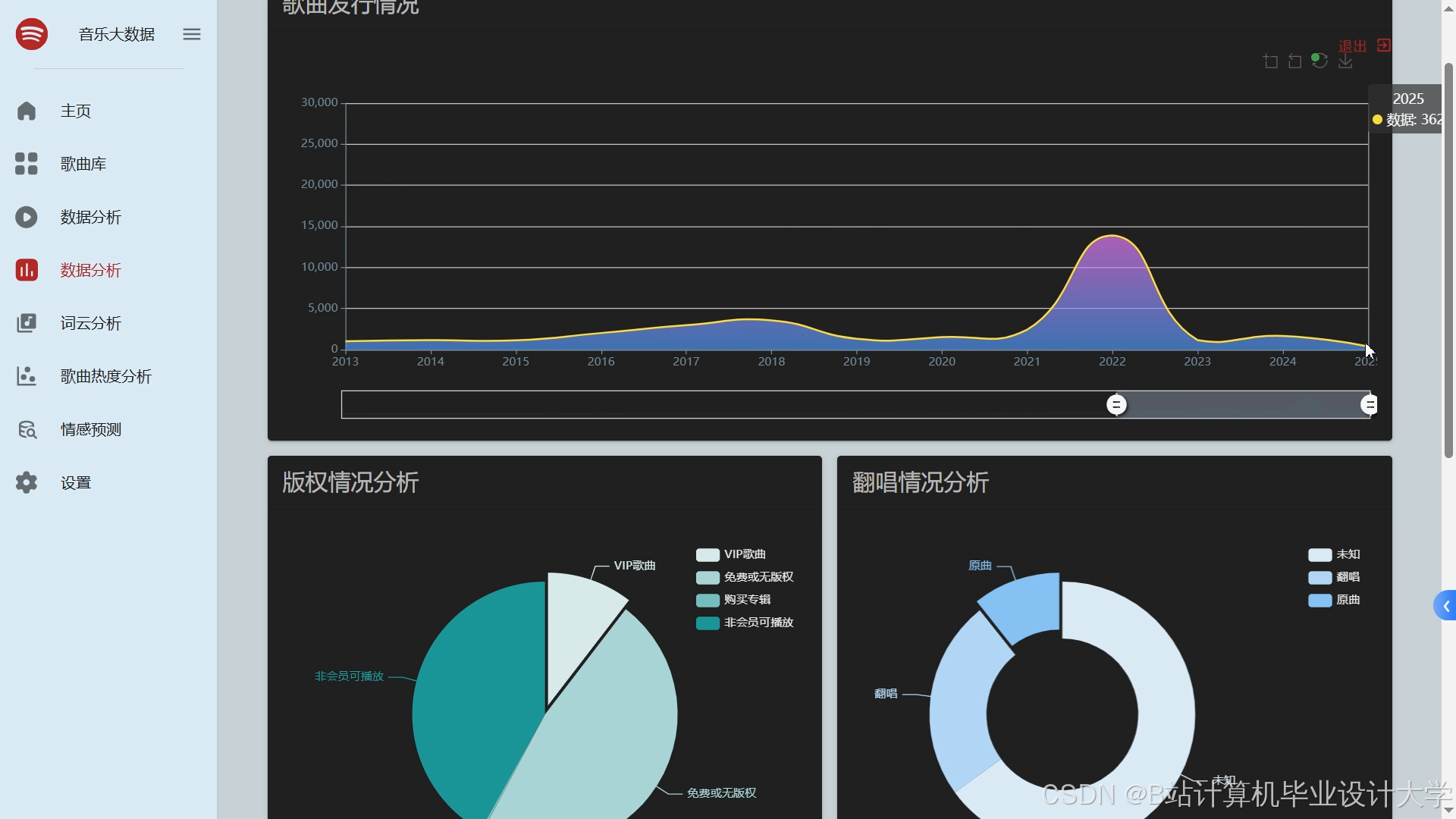
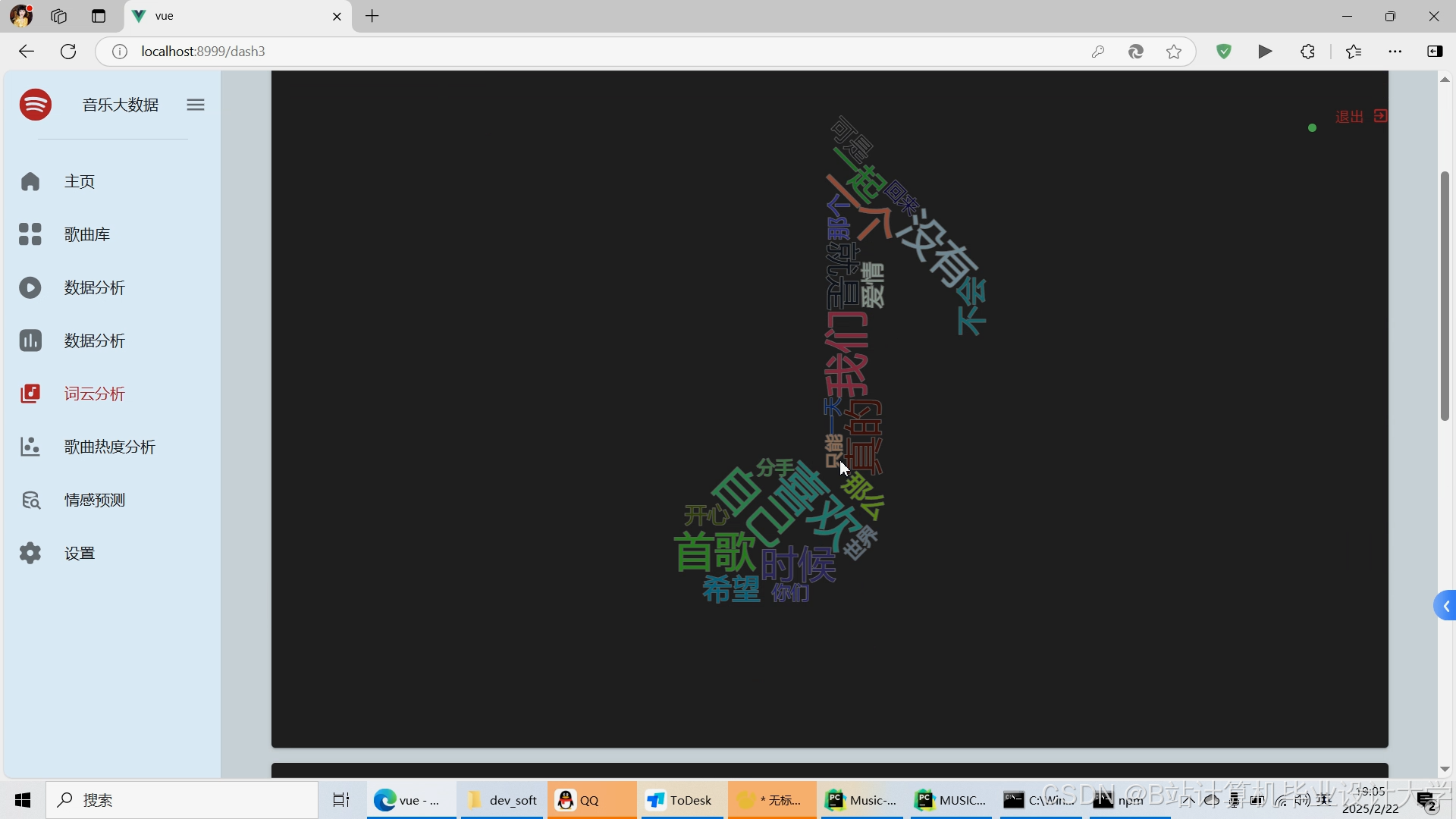
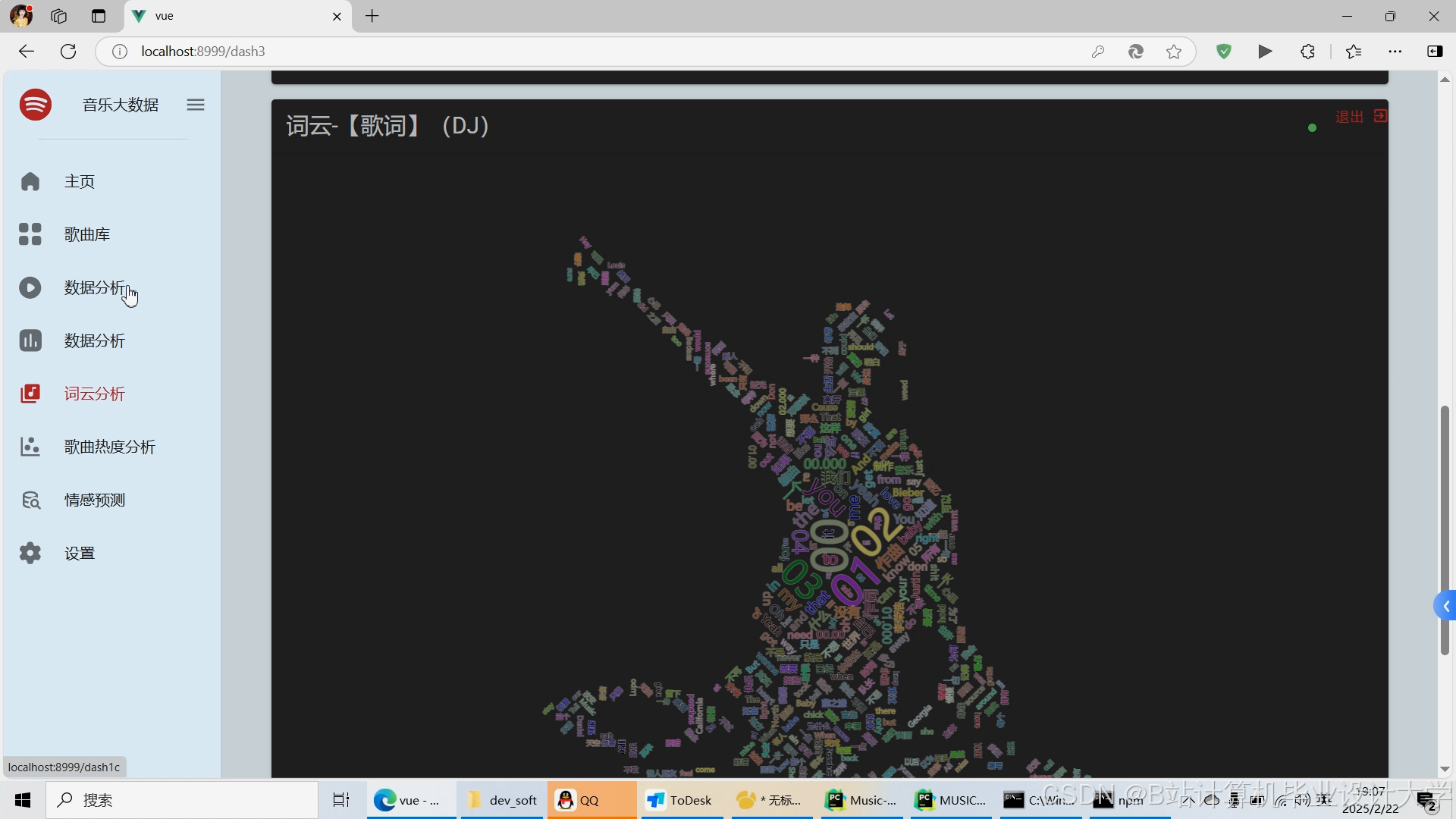
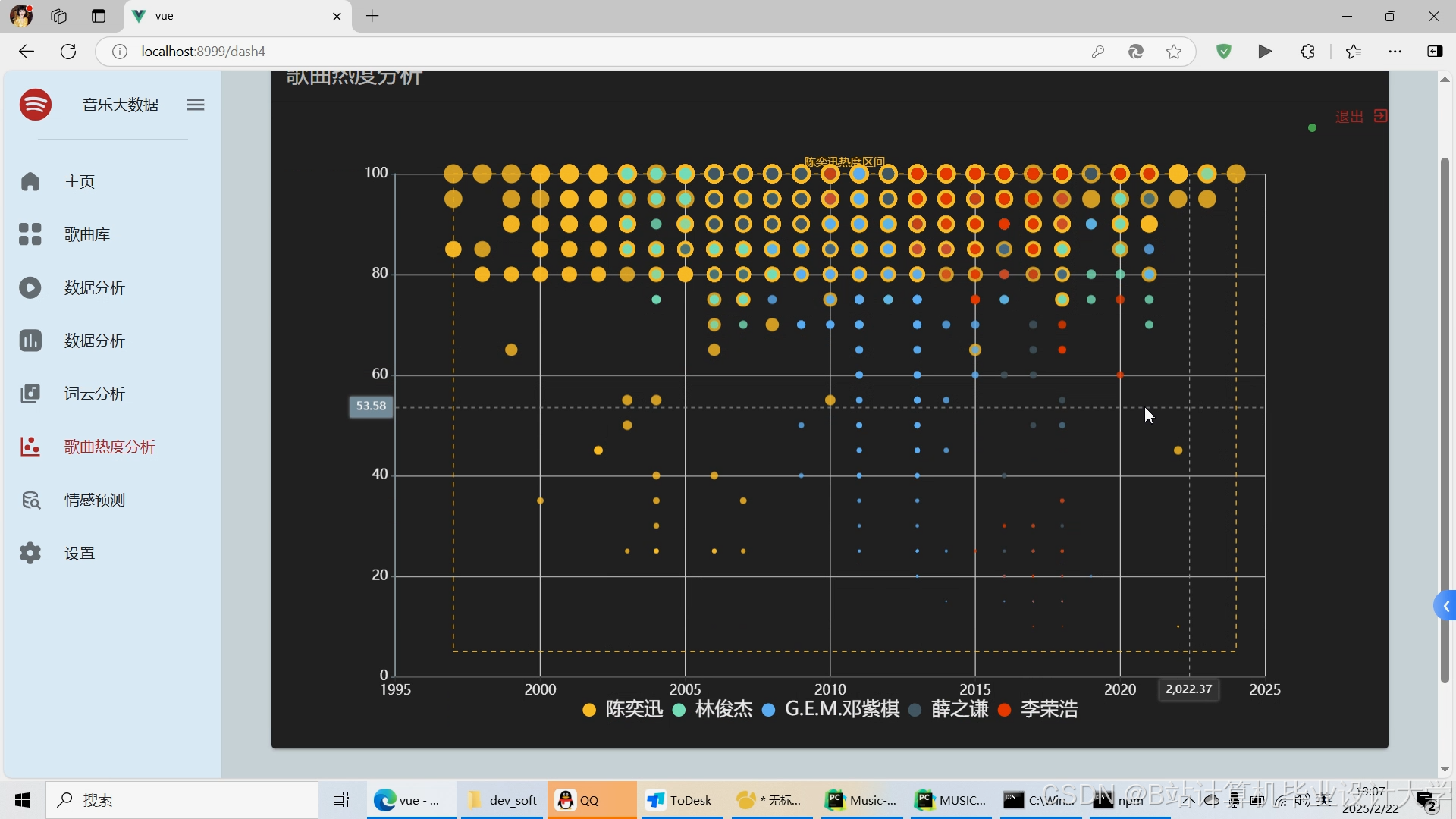
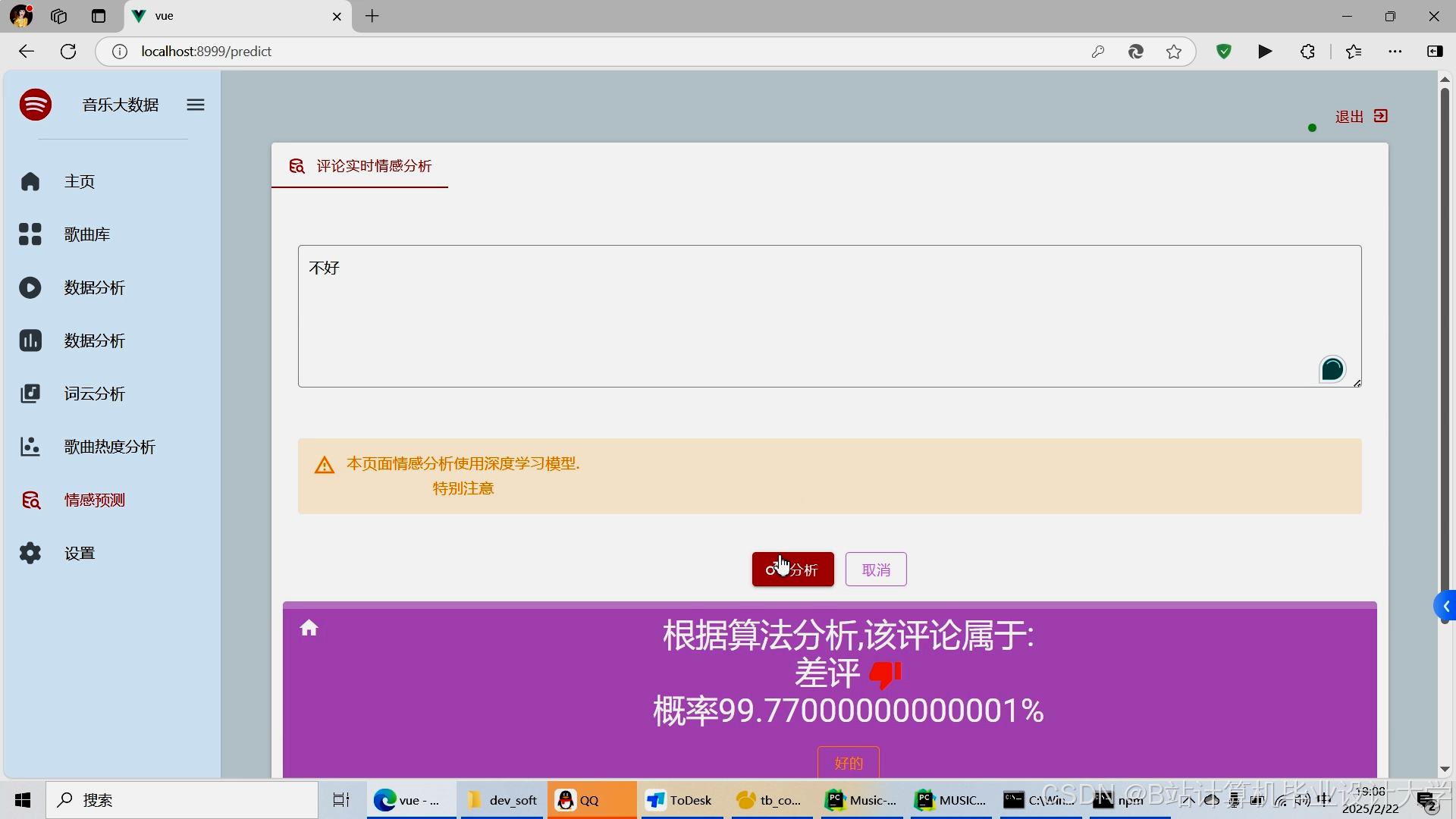
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











