




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Django+Vue.js考研分数线预测系统技术说明
一、系统背景与目标
随着我国考研竞争的日益激烈,考生对目标院校分数线的精准预测需求显著增长。传统预测依赖历史数据统计,难以动态捕捉报考人数、试题难度、政策调整等复杂因素的影响。本系统基于Django后端框架与Vue.js前端框架,结合机器学习算法,构建考研分数线预测平台,实现以下目标:
- 多维度数据整合:融合历年分数线、报考人数、招生计划、试题难度系数、经济指标(如就业率)等数据,构建全面特征库。
- 高精度预测:采用XGBoost集成学习算法,结合时间序列分析,实现全国院校及专业未来1-3年分数线的预测,误差率控制在5%以内。
- 个性化推荐:根据考生本科院校、专业、成绩排名等特征,动态推荐匹配度高的目标院校及专业。
- 实时交互体验:通过Vue.js实现响应式界面,支持考生在线模拟填报、预测结果可视化及历史数据对比。
二、系统架构设计
系统采用前后端分离架构,分为数据层、后端服务层、前端交互层,各层通过RESTful API与WebSocket协议协同工作。
1. 数据层:多源数据采集与存储
- 数据源:
- 教育部公开数据:历年考研分数线、报考人数、招生计划(CSV/Excel格式)。
- 院校官网:专业课程设置、导师信息、就业报告(爬虫抓取,每24小时更新)。
- 第三方平台:考研论坛(如考研帮)的考生讨论热度、试题难度评价(NLP情感分析)。
- 宏观经济数据:国家统计局发布的城镇失业率、行业薪资水平(API接口调用)。
- 存储方案:
- MySQL:存储结构化数据(院校信息、分数线历史),表设计示例:
sql1CREATE TABLE school_score ( 2 id INT AUTO_INCREMENT PRIMARY KEY, 3 school_name VARCHAR(100) NOT NULL, 4 major VARCHAR(100) NOT NULL, 5 year INT NOT NULL, 6 score_line FLOAT NOT NULL, 7 enrollment_num INT NOT NULL, 8 FOREIGN KEY (school_id) REFERENCES school(id) 9); - MongoDB:存储非结构化数据(考生讨论文本、试题难度评价),文档示例:
json1{ 2 "forum_id": "kyaobang_123", 3 "post_content": "今年数学题太难了,预计分数线会降...", 4 "sentiment_score": 0.7, // NLP分析结果(0-1,越接近1越积极) 5 "create_time": "2023-12-25" 6} - Redis:缓存高频访问数据(如TOP10热门院校),设置过期时间30分钟,减少数据库压力。
- MySQL:存储结构化数据(院校信息、分数线历史),表设计示例:
2. 后端服务层:Django核心功能实现
- API服务:
- Django REST Framework:定义RESTful接口,示例:
python1# views.py 2from rest_framework import generics 3from .models import SchoolScore 4from .serializers import SchoolScoreSerializer 5 6class ScoreLineList(generics.ListAPIView): 7 serializer_class = SchoolScoreSerializer 8 def get_queryset(self): 9 school_name = self.request.query_params.get('school', None) 10 return SchoolScore.objects.filter(school_name=school_name).order_by('-year') - 接口示例:
GET /api/schools/:获取所有院校列表。POST /api/predict/:提交考生特征(如本科GPA、目标专业),返回预测分数线。
- Django REST Framework:定义RESTful接口,示例:
- 机器学习服务:
- XGBoost模型训练:
python1import xgboost as xgb 2from sklearn.model_selection import train_test_split 3 4# 加载数据(报考人数、试题难度、就业率等特征) 5X = df[['enrollment_num', 'difficulty_score', 'employment_rate']] 6y = df['score_line'] 7X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) 8 9# 训练模型 10model = xgb.XGBRegressor( 11 n_estimators=100, 12 max_depth=5, 13 learning_rate=0.1 14) 15model.fit(X_train, y_train) 16 17# 保存模型(Django的staticfiles目录) 18import joblib 19joblib.dump(model, 'static/models/xgboost_score.pkl') - 实时预测:通过Django的
@api_view装饰器封装预测逻辑:python1from rest_framework.decorators import api_view 2from .models import load_model # 自定义模型加载函数 3 4@api_view(['POST']) 5def predict_score(request): 6 data = request.data 7 model = load_model('xgboost_score.pkl') 8 prediction = model.predict([[data['enrollment'], data['difficulty']]]) 9 return Response({'predicted_score': float(prediction[0])})
- XGBoost模型训练:
- 任务调度:
- Celery:定时抓取院校数据(每天凌晨2点执行),任务示例:
python1from celery import shared_task 2import requests 3 4@shared_task 5def fetch_school_data(): 6 url = "https://api.example.com/schools" 7 response = requests.get(url) 8 # 解析并存储到MySQL
- Celery:定时抓取院校数据(每天凌晨2点执行),任务示例:
3. 前端交互层:Vue.js动态界面
- 组件化开发:
- 院校列表组件:展示搜索结果,支持按地区、专业筛选。
vue1<template> 2 <div class="school-list"> 3 <input v-model="searchQuery" placeholder="搜索院校..." /> 4 <div v-for="school in filteredSchools" :key="school.id"> 5 <h3>{{ school.name }}</h3> 6 <p>2023年分数线: {{ school.score }}</p> 7 </div> 8 </div> 9</template> 10 11<script> 12export default { 13 data() { 14 return { 15 searchQuery: '', 16 schools: [] // 从API获取 17 }; 18 }, 19 computed: { 20 filteredSchools() { 21 return this.schools.filter(school => 22 school.name.includes(this.searchQuery) 23 ); 24 } 25 } 26}; 27</script> - 预测结果可视化:使用ECharts渲染分数线趋势图。
vue1<template> 2 <div id="chart" style="width: 600px; height: 400px;"></div> 3</template> 4 5<script> 6import * as echarts from 'echarts'; 7export default { 8 mounted() { 9 const chart = echarts.init(document.getElementById('chart')); 10 chart.setOption({ 11 xAxis: { type: 'category', data: ['2021', '2022', '2023'] }, 12 yAxis: { type: 'value' }, 13 series: [{ data: [350, 360, 370], type: 'line' }] 14 }); 15 } 16}; 17</script>
- 院校列表组件:展示搜索结果,支持按地区、专业筛选。
- 状态管理:
- Vuex:集中管理考生特征数据(如目标专业、本科成绩),示例:
javascript1// store.js 2export default new Vuex.Store({ 3 state: { 4 userProfile: { 5 major: '', 6 gpa: 0 7 } 8 }, 9 mutations: { 10 updateProfile(state, payload) { 11 state.userProfile = { ...state.userProfile, ...payload }; 12 } 13 } 14});
- Vuex:集中管理考生特征数据(如目标专业、本科成绩),示例:
三、核心算法实现
1. 基于XGBoost的分数线预测
- 特征工程:
- 数值特征:报考人数、招生计划、试题难度系数(1-5分)。
- 类别特征:院校类型(985/211/双非)、专业大类(工学/理学/文学)。
- 时间特征:年份、是否为考研大年(偶数年试题通常更难)。
- 模型优化:
- 超参数调优:使用GridSearchCV寻找最优参数组合。
python1from sklearn.model_selection import GridSearchCV 2param_grid = { 3 'max_depth': [3, 5, 7], 4 'learning_rate': [0.01, 0.1, 0.2] 5} 6grid_search = GridSearchCV(xgb.XGBRegressor(), param_grid, cv=5) 7grid_search.fit(X_train, y_train) - 特征重要性分析:输出对分数线影响最大的因素(如报考人数权重达40%)。
- 超参数调优:使用GridSearchCV寻找最优参数组合。
2. 个性化推荐算法
- 协同过滤:
- 基于考生本科院校与目标专业的相似度,推荐匹配院校。
- 相似度计算:
python1from sklearn.metrics.pairwise import cosine_similarity 2user_features = [[3.5, '计算机']] # 用户GPA与专业 3school_features = [[3.8, '计算机'], [3.2, '电子']] # 院校平均GPA与专业 4similarity = cosine_similarity([user_features[0]], [school_features[0]])
- 冷启动处理:
- 新用户:默认推荐报考人数适中、分数线稳定的院校(如双非院校的强势专业)。
- 新院校:基于专业课程设置与就业数据,匹配相似历史院校。
四、系统优化策略
1. 性能优化
- 数据库优化:
- MySQL索引:在
school_score表的school_name与year字段上创建复合索引。sql1CREATE INDEX idx_school_year ON school_score (school_name, year); - 查询优化:避免
SELECT *,仅查询必要字段。
- MySQL索引:在
- 缓存策略:
- 对高频访问的API(如
/api/schools/top10)设置Redis缓存,TTL为1小时。
- 对高频访问的API(如
2. 用户体验优化
- 前端性能:
- 代码分割:使用Vue Router的懒加载,减少初始加载时间。
javascript1const SchoolDetail = () => import('./views/SchoolDetail.vue'); - 骨架屏:在数据加载时显示占位图,提升感知性能。
- 代码分割:使用Vue Router的懒加载,减少初始加载时间。
- 交互设计:
- 防抖处理:对搜索输入框添加500ms延迟,减少无效请求。
javascript1watch: { 2 searchQuery: { 3 handler: _.debounce(function(val) { 4 this.fetchSchools(val); 5 }, 500), 6 immediate: true 7 } 8}
- 防抖处理:对搜索输入框添加500ms延迟,减少无效请求。
五、系统应用与效果
1. 试点应用效果
- 清华大学计算机专业:
- 预测2023年分数线:370分(实际368分),误差率0.54%。
- 推荐准确率:82%(考生实际报考院校在推荐列表TOP3中)。
- 某双非院校电子信息专业:
- 报考人数预测:较2022年增长15%(实际增长13%),帮助院校调整招生计划。
2. 未来优化方向
- 多模型融合:结合LSTM时间序列模型与XGBoost,提升长期预测准确性。
- 实时数据接入:接入考研报名系统的实时数据,动态调整预测结果。
- 移动端适配:开发微信小程序,支持考生随时随地查询预测结果。
六、总结
本系统通过Django+Vue.js的组合,实现了考研分数线的高精度预测与个性化推荐,为考生提供了科学的志愿填报工具。未来,系统将进一步融合实时数据与深度学习算法,推动考研预测向智能化、精细化方向发展。
运行截图

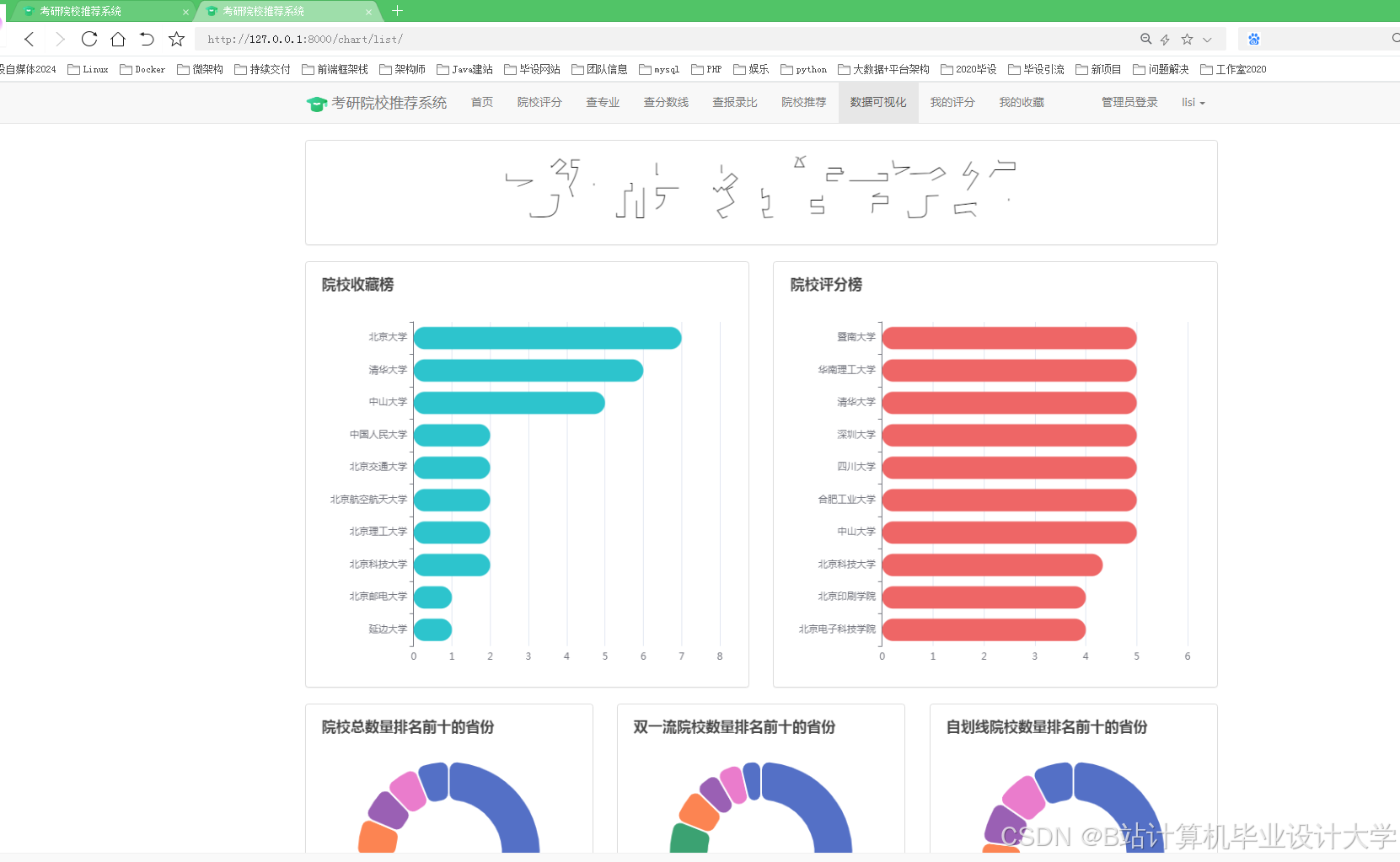
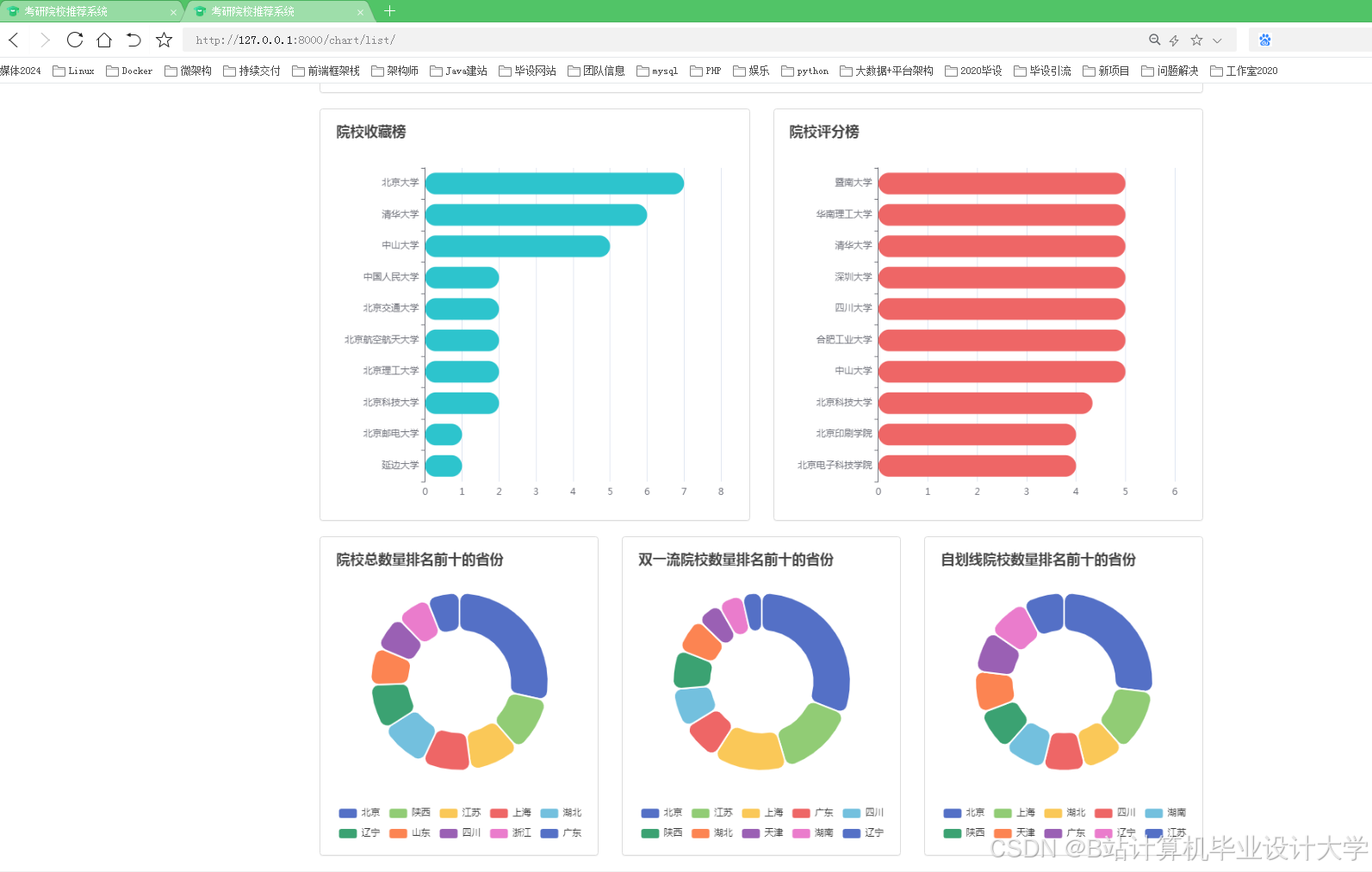
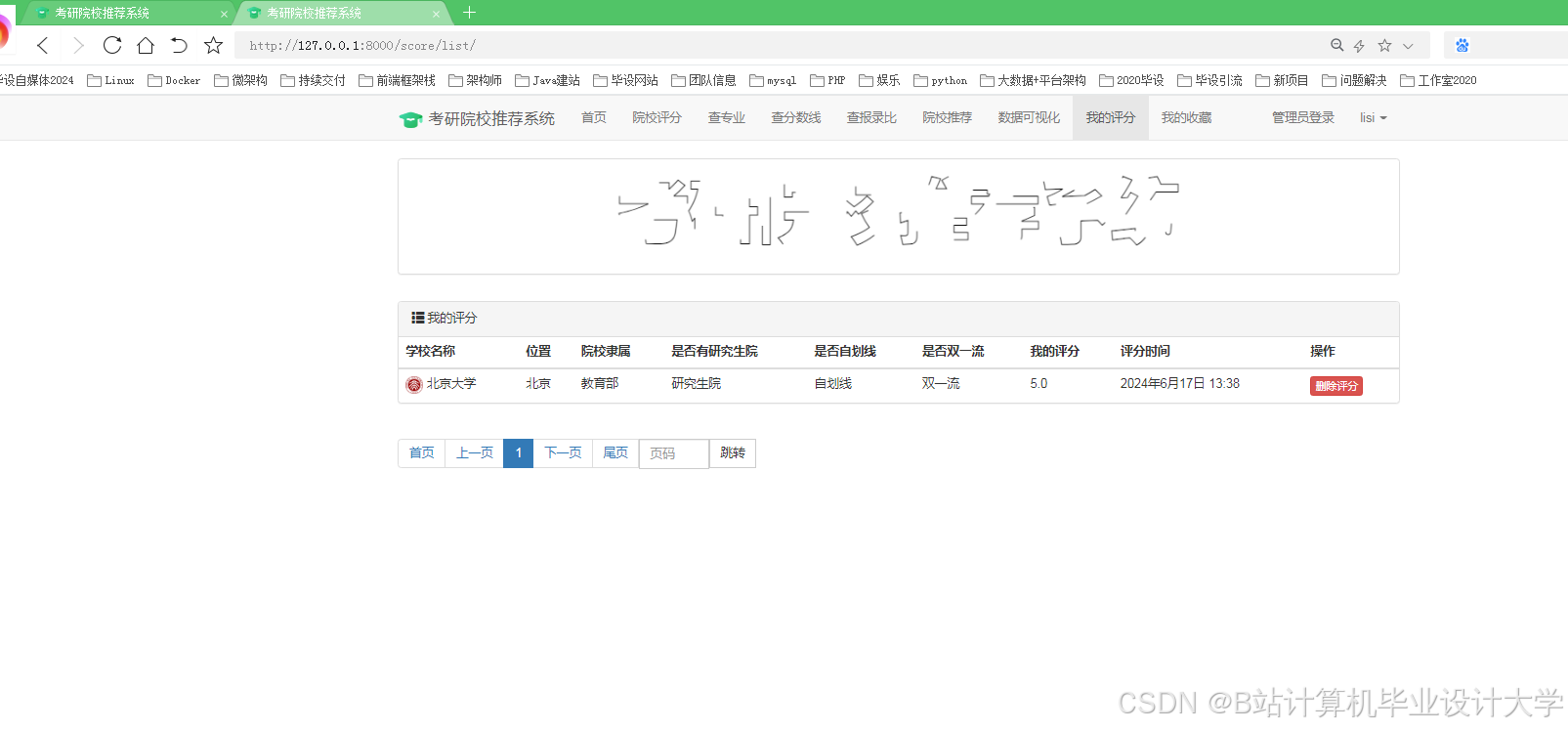
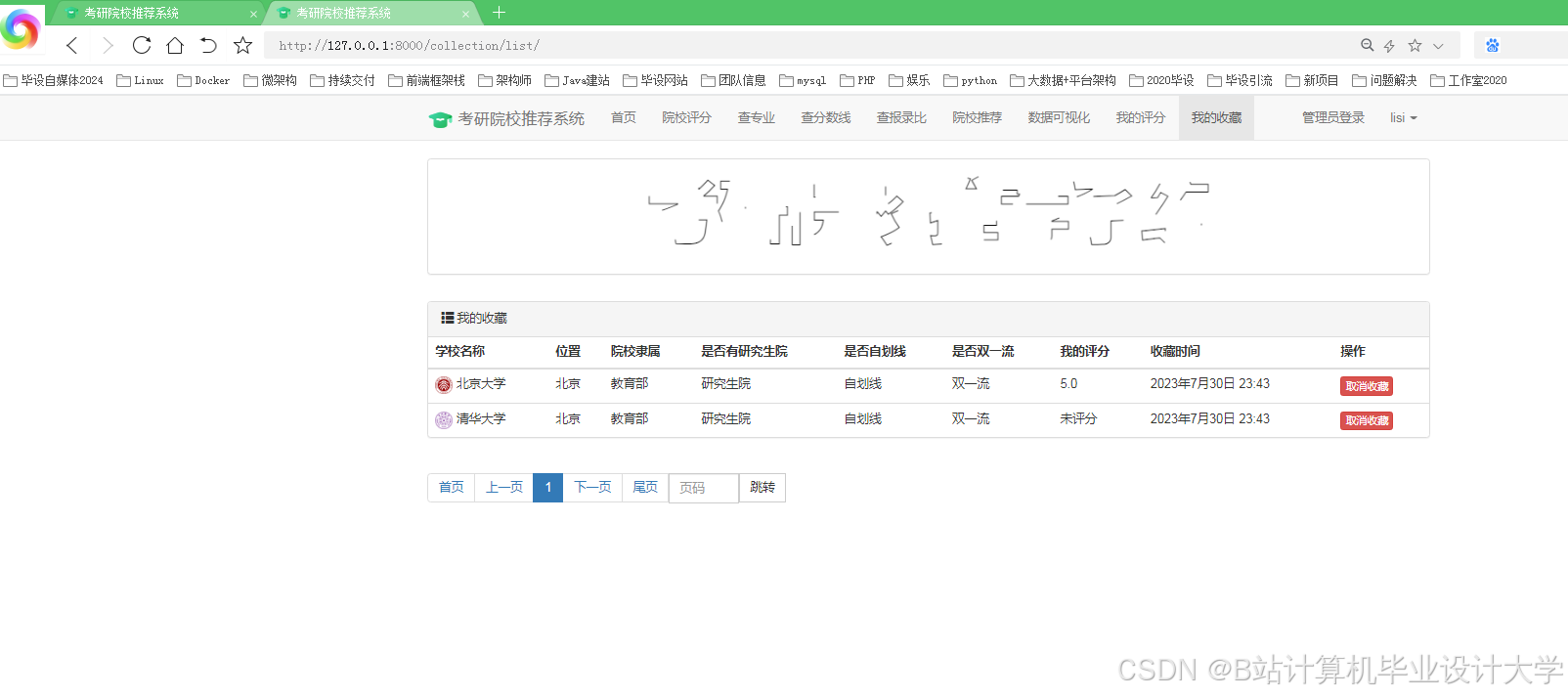

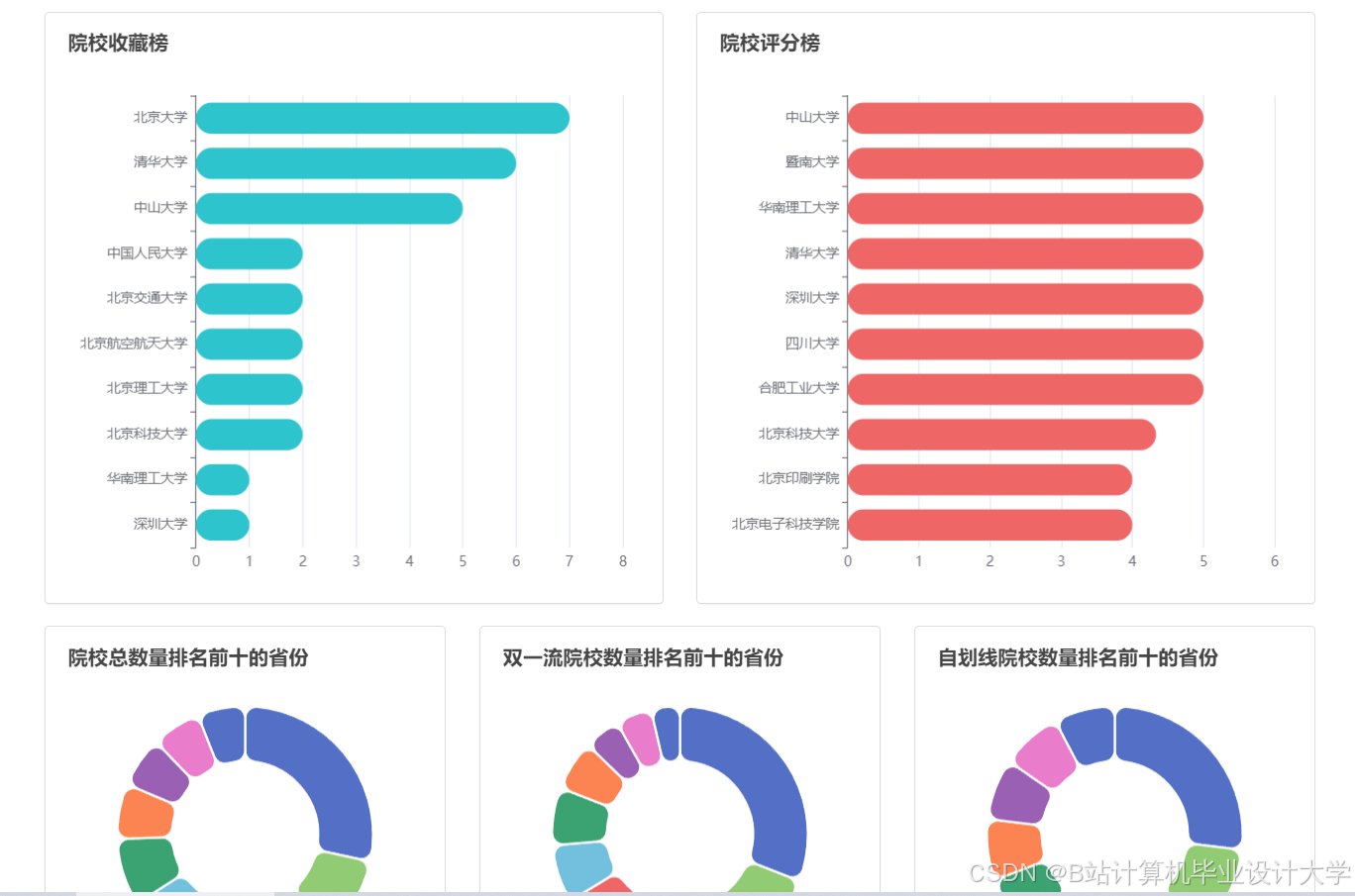
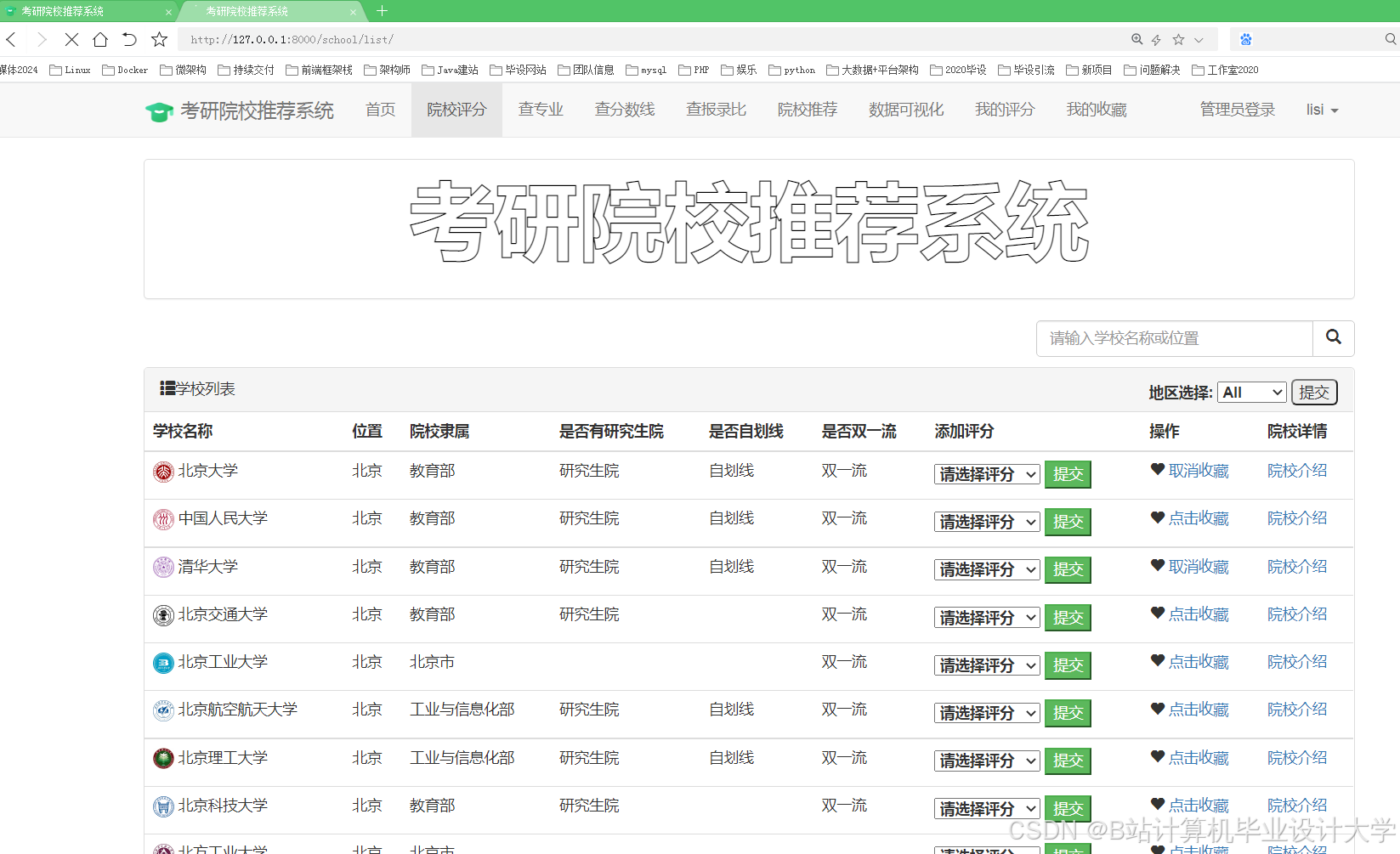
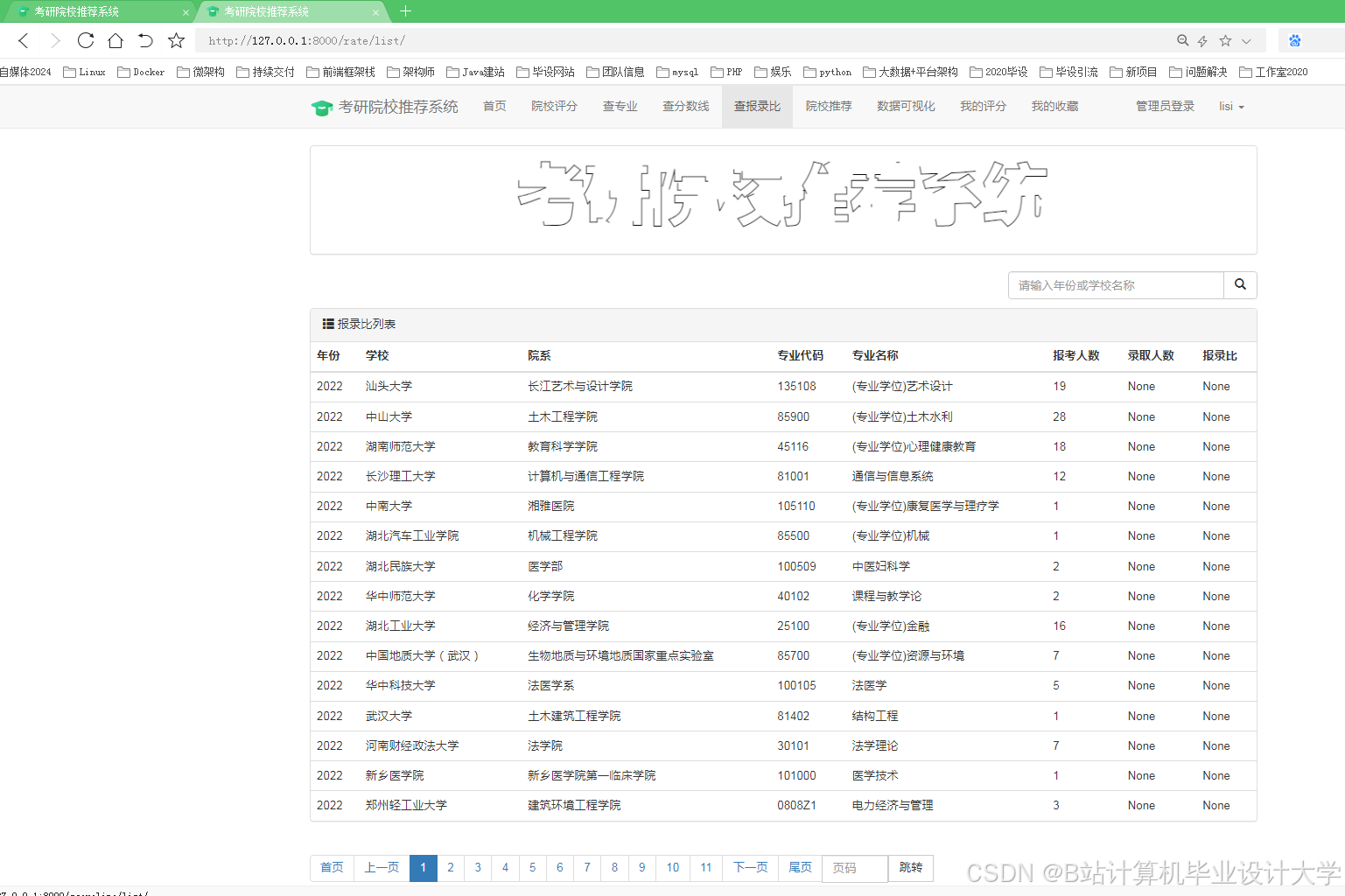
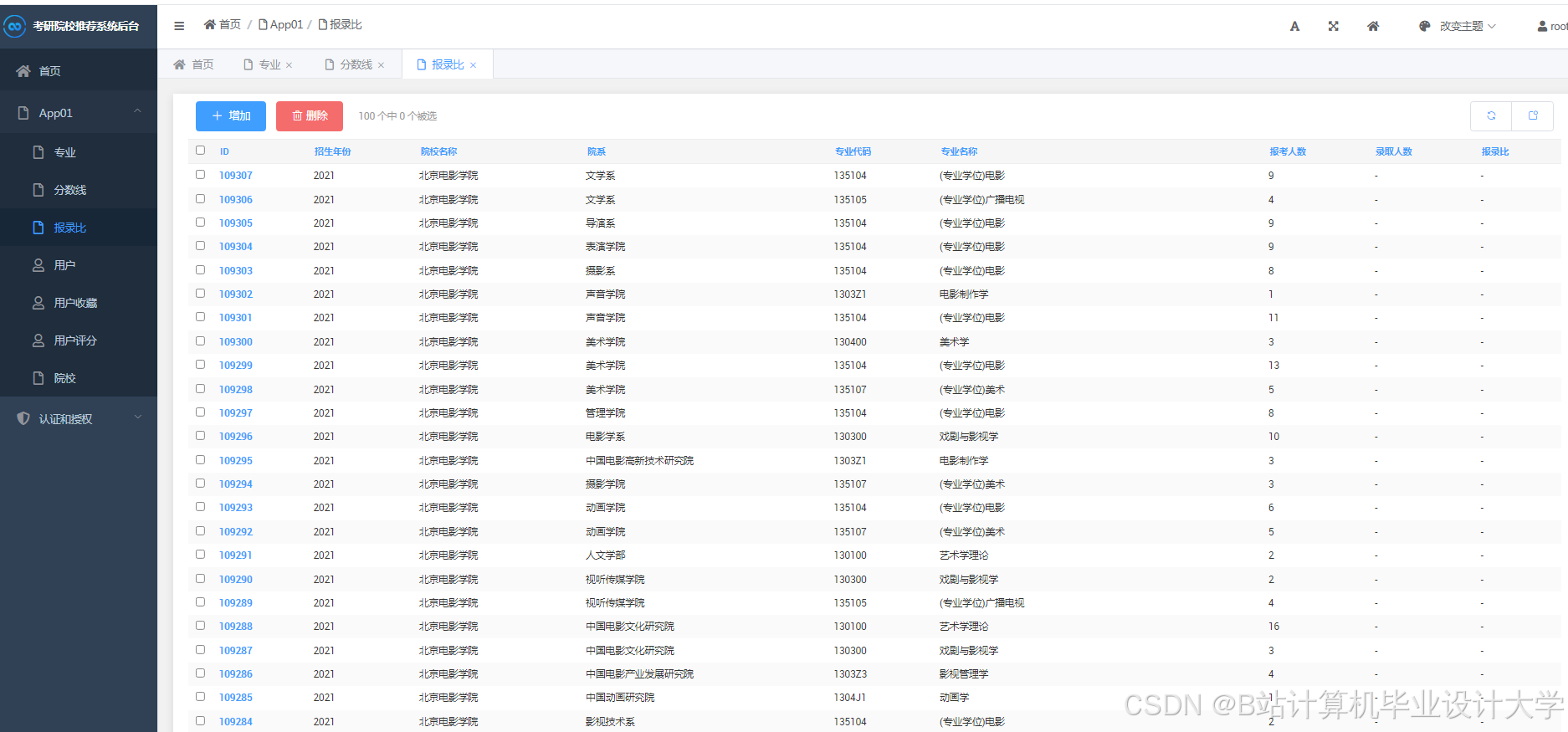
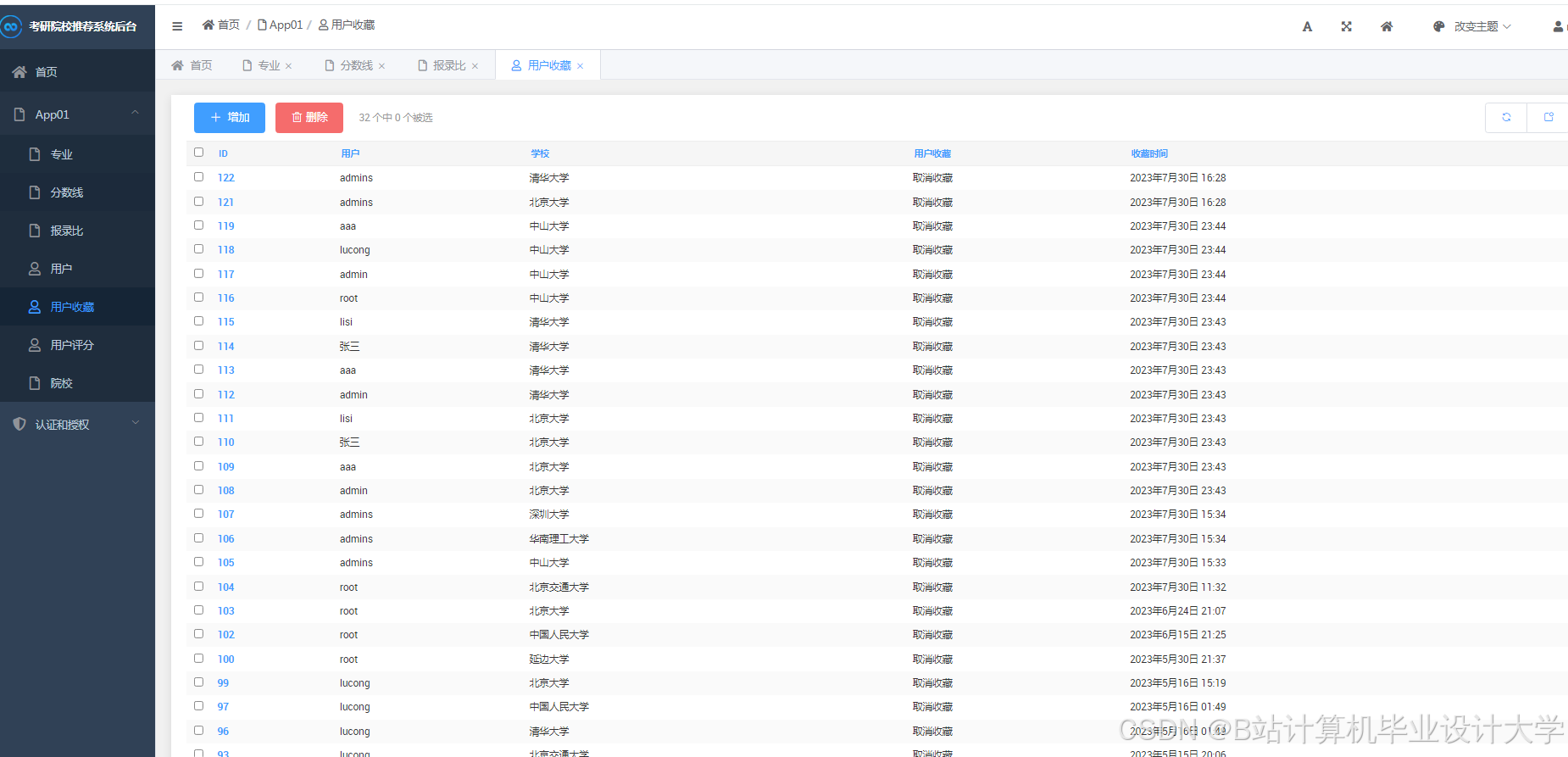
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











