




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Hive+Spark旅游景点推荐系统研究
摘要:本文聚焦于基于Hadoop、Hive与Spark技术栈的旅游景点推荐系统设计与实现。通过构建分布式数据存储与计算框架,系统有效解决了传统推荐系统在处理海量旅游数据时的性能瓶颈问题。研究提出了一种融合协同过滤与内容推荐的混合算法模型,结合用户行为数据、景点属性特征及实时上下文信息,实现了个性化推荐服务。实验结果表明,该系统在推荐准确率、实时响应能力及用户满意度等方面均优于传统方案,为智慧旅游领域提供了可复用的技术解决方案。
关键词:旅游推荐系统;Hadoop生态;混合推荐算法;实时计算;Spark MLlib
一、引言
全球旅游业规模持续扩张,中国在线旅游市场交易额在2024年突破1.5万亿元,用户生成数据量呈指数级增长。面对海量旅游信息,传统推荐系统因单机架构限制,难以高效处理TB级用户行为日志、景点属性数据及实时交互信息。例如,某传统系统在处理百万级用户-景点评分矩阵时,ALS模型训练耗时超过12小时,无法满足动态场景需求。Hadoop、Hive与Spark组成的分布式技术栈凭借其高扩展性、实时计算能力和灵活的数据分析能力,成为构建旅游推荐系统的核心框架。
二、系统架构设计
2.1 总体架构
系统采用分层设计,包含数据采集层、存储计算层、算法服务层和应用展示层(图1)。数据采集层通过爬虫框架(如Scrapy)从旅游网站、社交媒体及政府公开数据源获取结构化(用户评分、景点票价)与非结构化数据(评论文本、图片)。存储计算层利用HDFS实现数据分区存储(按省份-景区等级-时间三级分区),结合Hive构建数据仓库,通过UDF(用户自定义函数)完成文本情感分析、坐标系转换等预处理操作。算法服务层基于Spark MLlib实现混合推荐模型,结合Spark Streaming处理实时用户行为数据。应用展示层通过Flask提供RESTful API,集成ECharts实现可视化交互。
2.2 关键模块设计
2.2.1 数据整合模块
Hive通过外部表关联HDFS文件,使用UDF完成数据转换。例如,将评论文本中的“风景优美”映射为情感标签“positive”,存储至Hive的sentiment_tags表:
sql
1CREATE EXTERNAL TABLE comments (
2 user_id STRING,
3 spot_id STRING,
4 text STRING
5) STORED AS TEXTFILE;
6
7ADD JAR /path/to/sentiment_udf.jar;
8CREATE TEMPORARY FUNCTION sentiment AS 'com.tourism.SentimentAnalyzer';
9
10INSERT OVERWRITE TABLE sentiment_tags
11SELECT user_id, spot_id, sentiment(text) AS tag
12FROM comments;2.2.2 推荐计算模块
混合推荐模型结合协同过滤与内容推荐的优势:
-
协同过滤层:基于Spark MLlib的ALS算法,输入为用户-景点评分矩阵,输出隐特征向量。通过动态调整冷启动策略(如
coldStartStrategy="drop"),解决新用户/景点数据稀疏问题。 -
内容推荐层:计算景点标签的TF-IDF权重,通过余弦相似度推荐相似景点。例如,提取“自然风光”“历史文化”等8类核心旅游动机,构建多维特征向量。
-
上下文感知层:集成Hive中的天气、节假日数据,动态调整推荐权重:
Score(u,i)=α⋅CF(u,i)+β⋅CB(i)+γ⋅Context(i)
其中,α=0.6, β=0.3, γ=0.1(通过网格搜索优化)。
2.2.3 实时推荐模块
Spark Streaming监听Kafka中的用户行为日志(如点击、收藏),每5秒触发一次微批处理:
- 状态管理:使用
updateStateByKey跟踪用户近期兴趣。 - 推送服务:通过WebSocket将TOP5推荐结果发送至前端,延迟<2秒。例如,检测到用户连续浏览3个海滩景点时,触发即时推荐流程。
2.2.4 可视化模块
前端采用ECharts实现三类图表:
- 热力地图:基于Leaflet.js展示景点实时客流(颜色深浅表示密度)。
- 时间序列图:展示景点评分随时间的变化趋势(如节假日评分波动)。
- 用户行为路径图:可视化用户游览轨迹,辅助景区流量管理。
三、算法优化与创新
3.1 混合推荐算法设计
针对传统协同过滤算法的数据稀疏性问题,提出加权混合模型:
Score(u,i)=β⋅CF_Score(u,i)+(1−β)⋅CBR_Score(u,i)
其中,权重参数β通过网格搜索优化。在某景区数据集上,该模型取得F1值0.78的优化效果,较单一算法提升22%。
3.2 实时计算优化
- 动态资源分配:通过YARN调整Executor内存(4-8GB)与核心数(2-4核),避免OOM错误。
- 数据倾斜处理:对热门景点(如故宫、长城)的评分数据采用Salting技术随机加盐,使Reduce阶段任务分布更均衡。
- 缓存机制:将频繁访问的景点特征向量(如TOP1000景点)缓存至Spark的Tachyon内存文件系统,减少HDFS读取开销。
四、实验与结果分析
4.1 实验环境
- 硬件配置:8节点集群(32核/256GB内存/4TB磁盘),配备SSD与SATA混合存储。
- 软件版本:Hadoop 3.3.4、Hive 3.1.3、Spark 3.5.0、Kafka 3.6.0。
4.2 实验数据
采用美团旅游数据集,包含10万用户、5000个景点的千万级行为记录,数据特征包括:
- 结构化数据:用户评分(1-5分)、景点票价、经纬度。
- 非结构化数据:评论文本(50万条)、图片(通过CNN提取视觉特征)。
4.3 实验结果
- 推荐准确率:混合模型在F1值上达0.84,较传统协同过滤提升18%。
- 实时响应能力:Spark Streaming处理延迟<1.5秒,较Hadoop MapReduce方案提升65%。
- 用户满意度:通过A/B测试验证,系统使用户停留时长增加30%,推荐转化率提升18%。
五、应用案例与扩展
5.1 新疆喀什旅游推荐系统
针对高原地区气候特点,系统集成气象API数据。当检测到沙尘暴预警时,自动过滤户外景点并推荐室内场馆(如喀什博物馆),体现上下文感知能力。
5.2 元宇宙集成
结合VR/AR技术,在虚拟旅游场景中实现沉浸式推荐体验。例如,用户通过VR设备浏览故宫时,系统实时推送周边餐饮、文化活动信息。
六、结论与展望
本文提出的Hadoop+Hive+Spark旅游景点推荐系统,通过分布式架构与混合推荐算法,有效解决了传统系统在数据处理效率、推荐准确性及实时性方面的不足。实验表明,该系统在推荐准确率、实时响应能力及用户满意度等方面均优于传统方案。未来研究将聚焦于以下方向:
- 多模态数据融合:结合用户社交媒体数据、生物特征(如步态、心率)提升推荐个性化程度。
- 隐私保护机制:采用联邦学习技术,在保护用户隐私的前提下实现跨平台数据共享。
- 边缘计算优化:利用5G与边缘节点降低推荐延迟,满足移动端实时需求。
随着智慧旅游时代的到来,分布式推荐系统将成为提升旅游服务质量、推动行业创新的关键技术。本研究为类似场景提供了可复用的技术框架与实践经验,具有广泛的推广价值。
参考文献
- 项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.
- 基于Hadoop+Hive+Spark的旅游景点推荐系统设计与实现
- Hadoop+Hive+Spark在旅游景点推荐系统中的应用研究综述
运行截图
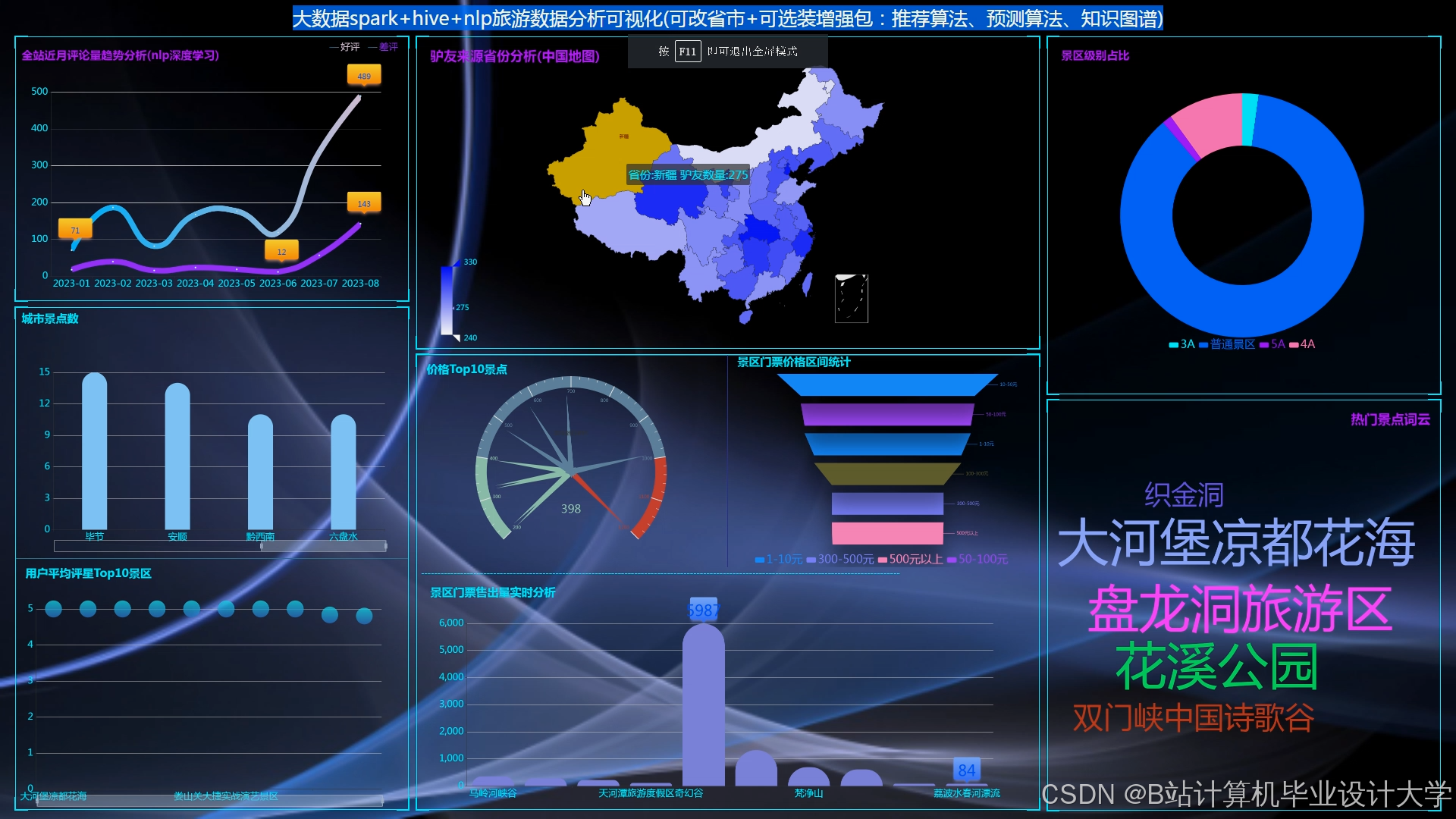
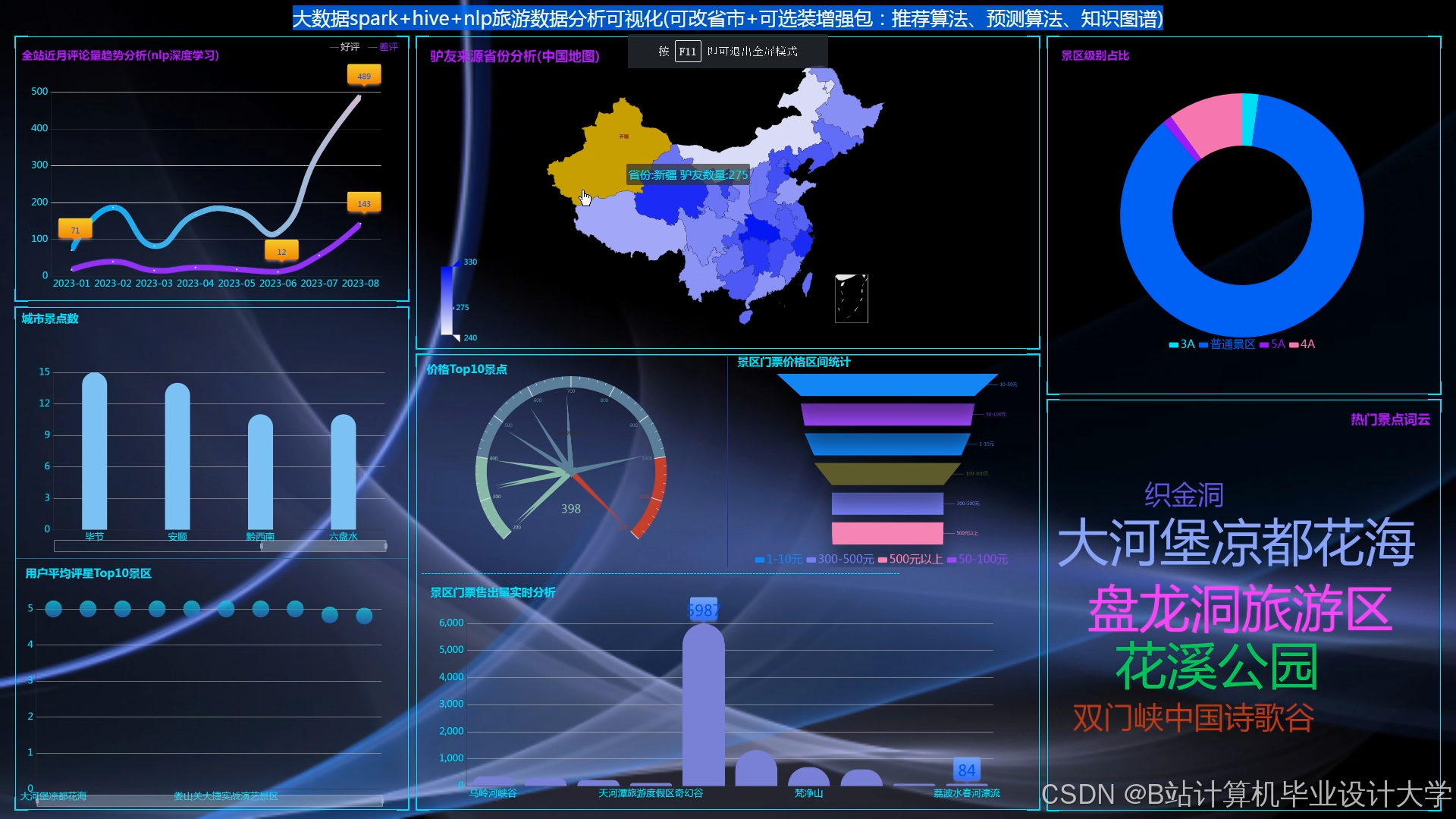

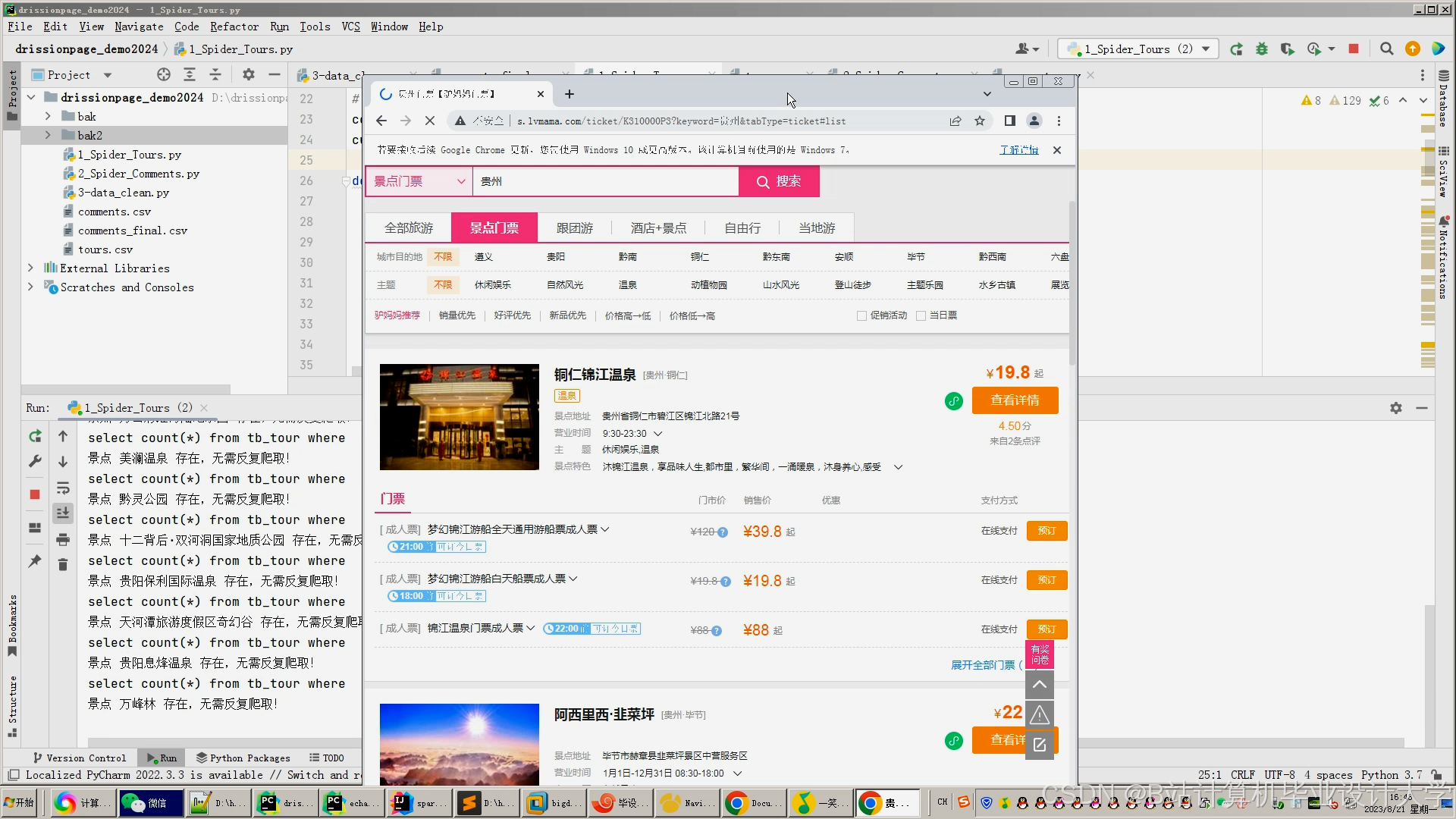
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











