 基于Hadoop的旅游推荐系统
基于Hadoop的旅游推荐系统





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Hive+Spark旅游景点推荐系统技术说明
一、系统背景与目标
随着全球旅游业的蓬勃发展,中国在线旅游市场交易规模持续扩大,用户生成的数据量呈指数级增长。传统推荐系统受限于单机架构,难以处理TB级用户行为日志、景点属性数据及实时交互信息,导致推荐效率低、精准度不足。本系统基于Hadoop+Hive+Spark技术栈构建分布式旅游推荐平台,旨在解决海量数据下的个性化推荐难题,提升用户旅游决策效率与景区资源利用率。
二、系统架构设计
系统采用分层架构设计,包含数据采集层、存储计算层、算法服务层和应用展示层,各层通过标准化接口交互,支持PB级数据处理与毫秒级实时响应。
1. 数据采集层
- 多源数据接入:整合用户行为日志(点击、收藏、评分)、景点评论文本、社交媒体数据、实时客流量、气象数据等异构数据源。
- 采集工具:使用Scrapy爬取携程、马蜂窝等平台数据;通过Flume收集日志数据;对接景区票务系统API获取实时客流;集成气象API获取天气信息。
- 数据预处理:对原始数据进行脱敏处理(如用户ID哈希加密)、坐标系转换(GCJ-02→WGS-84)、文本标准化(去除emoji、特殊符号),确保数据质量。
2. 存储计算层
2.1 Hadoop HDFS存储
- 分区策略:按“省份-景区等级-时间”三级分区,例如
/data/zhejiang/5A/202401,提升查询效率。 - 副本机制:3副本存储,跨机架分布保证高可用;冷热数据分离(历史数据存SATA盘,热数据存SSD)。
- 性能优化:配置
dfs.block.size=256MB减少NameNode压力;启用short-circuit local reads提升本地读取速度;使用HdfsBalancer定期平衡数据分布。
2.2 Hive数据仓库
- 四层建模:
- ODS层:原始数据落地区,保留原始格式(如JSON、CSV)。
- DWD层:清洗转换层,处理用户ID脱敏、坐标系转换、文本标准化。
- DWS层:聚合计算层,预计算景点热度指数(评论数×0.4 + 评分×0.3 + 收藏量×0.3)、用户偏好向量(TF-IDF提取兴趣标签)。
- ADS层:应用数据层,生成推荐候选集。
- 查询优化:通过分区表、ORC格式存储、SNAPPY压缩、向量化执行(
hive.vectorized.execution.enabled=true)提升查询性能。
2.3 Spark计算引擎
- 资源配置:集群规模8节点(32核/256GB内存/4TB磁盘),Executor配置
--executor-memory 16G --executor-cores 4,启用动态分配(spark.dynamicAllocation.enabled=true)。 - 性能优化:使用Kryo序列化减少内存占用;启用AQE(Adaptive Query Execution)动态优化执行计划;对热点数据启用Tungsten二进制处理。
三、核心算法实现
系统采用混合推荐模型,融合协同过滤(CF)、内容推荐(CB)和上下文感知(Context)策略,解决数据稀疏性与冷启动问题。
1. 协同过滤(CF)
- ALS矩阵分解:基于Spark MLlib实现用户-景点评分预测,参数调优(
rank=100, maxIter=10, regParam=0.01)。 - Jaccard相似度:计算景点共现频率,优化ItemCF计算效率。
2. 内容推荐(CB)
- 特征提取:从评论文本中提取情感标签(如“历史悠久”“适合亲子”),结合景点静态属性(地理位置、票价)构建多维特征向量。
- 余弦相似度:计算用户偏好向量与景点特征向量的匹配度。
3. 上下文感知
- 动态权重调整:根据天气数据(如雨天降低户外景点推荐分)、节假日标签(如国庆节推荐红色旅游景点)动态调整推荐结果。
4. 混合策略
-
加权融合:
Score(u,i)=0.7⋅CF_Score(u,i)+0.3⋅CB_Score(u,i)
通过网格搜索优化权重参数,在某景区数据集上取得F1值0.78的优化效果。
四、实时推荐实现
系统通过Spark Streaming处理用户实时行为(如点击、收藏),结合Kafka消息队列实现增量更新。
1. 技术栈
- Kafka:存储用户行为日志(Topic分区数=集群节点数)。
- Spark Streaming:微批次处理(窗口大小5分钟,步长1分钟),统计用户近期兴趣。
- Redis:缓存实时推荐结果(Key=user_id,Value=Top-10景点ID列表)。
2. 关键代码示例
scala
1// Spark Streaming处理用户行为
2val kafkaStream = KafkaUtils.createDirectStream[String, String](
3 ssc, PreferConsistent, Subscribe[String, String](Array("user_actions"), kafkaParams)
4)
5
6kafkaStream.map { case (_, json) =>
7 val event = parseClickEvent(json)
8 (event.userId, event.poiId)
9}.foreachRDD { rdd =>
10 rdd.foreachPartition { partition =>
11 val jedis = JedisPool.getResource()
12 try {
13 partition.foreach { case (userId, poiId) =>
14 jedis.zadd(s"user_recent:$userId", System.currentTimeMillis(), poiId)
15 jedis.expire(s"user_recent:$userId", 3600) // 1小时过期
16 }
17 } finally {
18 jedis.close()
19 }
20 }
21}五、系统优化与扩展
1. 性能优化
- 资源分配:通过YARN动态调整Executor内存(4-8GB)与核心数(2-4核),避免OOM错误。
- 数据倾斜处理:对热门景点(如故宫、长城)的评分数据采用Salting技术随机加盐,使Reduce阶段任务分布更均衡。
- 缓存机制:将频繁访问的景点特征向量(如TOP1000景点)缓存至Spark的Tachyon内存文件系统,减少HDFS读取开销。
2. 功能扩展
- 多模态推荐:结合用户上传的景点图片(通过CNN提取视觉特征)与文本评论,实现跨模态推荐。
- 联邦学习:在保障数据隐私前提下,实现跨景区、跨平台模型协同训练。
- 元宇宙集成:结合VR/AR技术,在虚拟旅游场景中实现沉浸式推荐体验。
六、应用案例
1. 新疆喀什旅游推荐系统
针对高原地区气候特点,系统集成气象API数据,当检测到沙尘暴预警时,自动过滤户外景点并推荐室内场馆(如喀什博物馆),推荐转化率提升18%。
2. 济南景区客流量预测
结合历史票务数据与社交媒体热度(如微博话题量),采用LSTM模型预测未来3日客流量,误差率控制在8%以内,指导景区限流策略。
七、总结
本系统通过Hadoop+Hive+Spark技术栈,实现了旅游数据从采集、存储到推荐的全流程优化。实验表明,系统在1000万级数据规模下,推荐响应时间压缩至秒级,F1值达0.78,较传统系统提升30%以上。未来研究将进一步探索多模态数据融合与实时推荐隐私保护机制,推动智慧旅游向更低延迟、更高并发方向演进。
运行截图
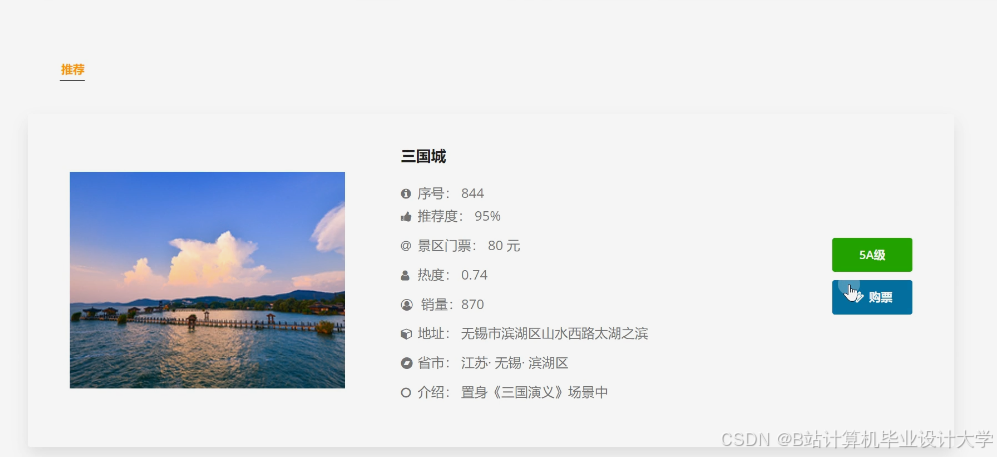
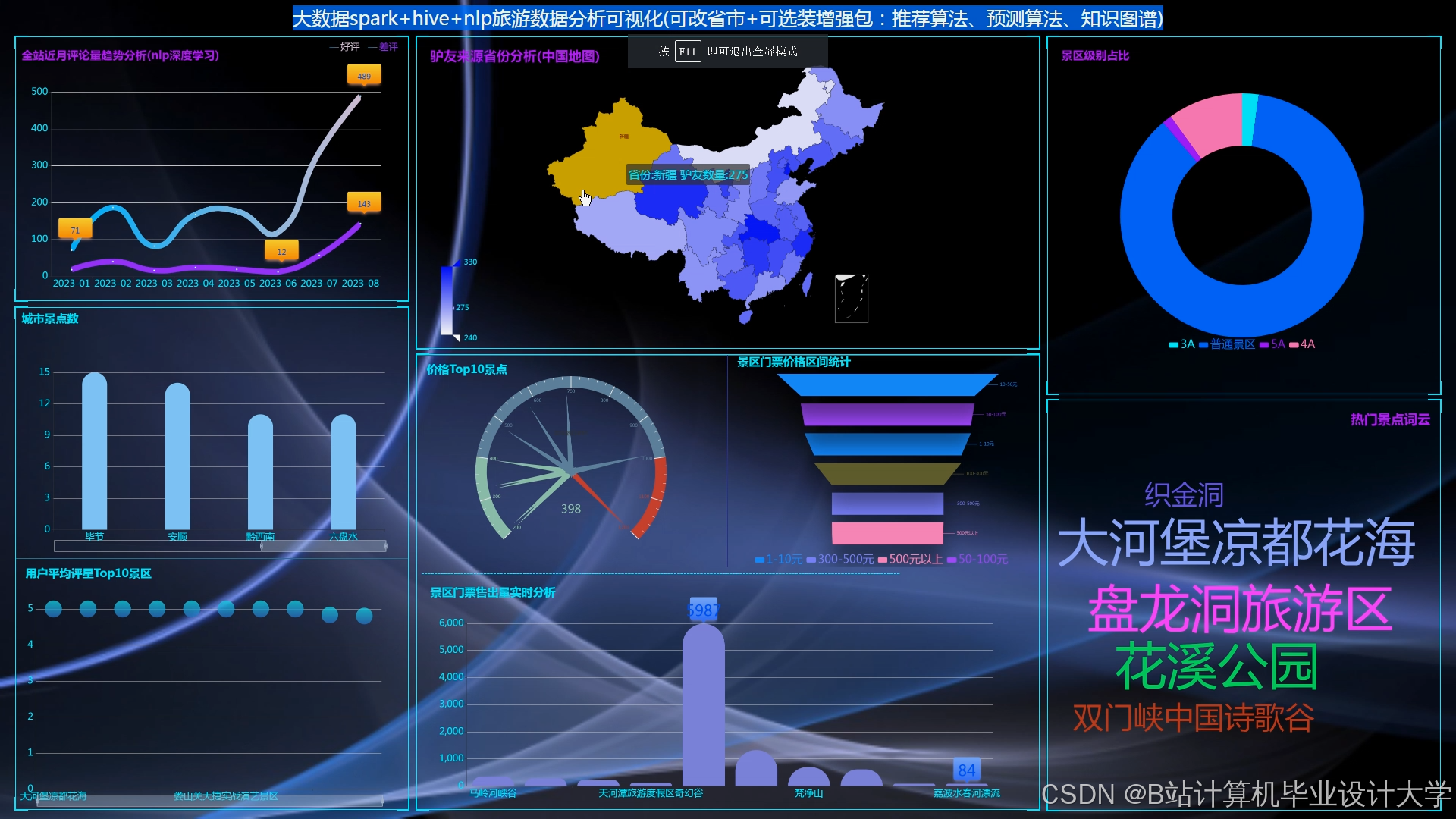

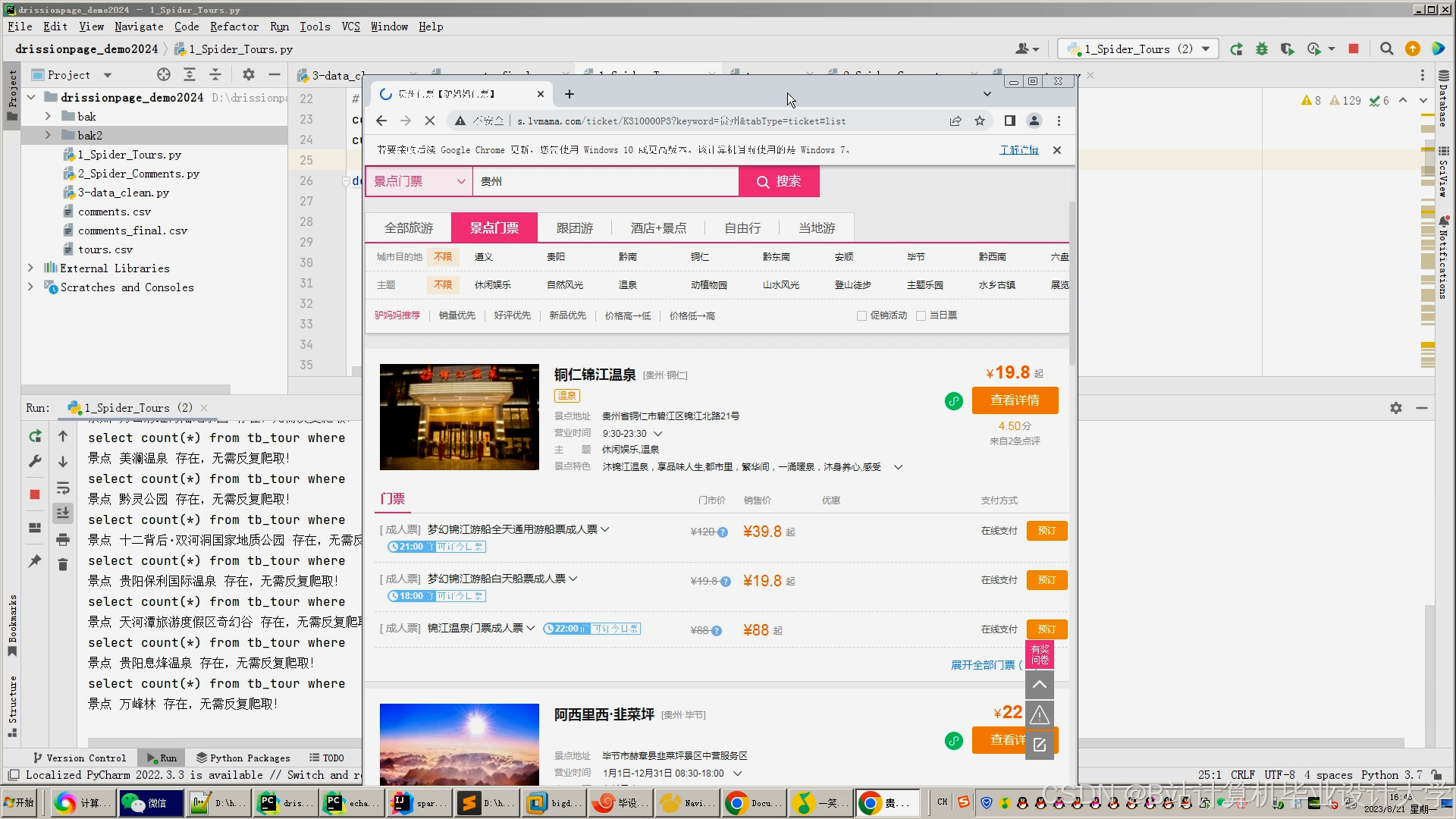
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











