




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《PySpark+Hive+Django小红书评论情感分析、笔记可视化及舆情分析预测系统》的技术说明文档,涵盖系统架构、关键技术实现及功能模块设计:
技术说明:基于PySpark+Hive+Django的小红书舆情分析系统
1. 系统概述
本系统针对小红书社交电商平台的用户评论和笔记数据,构建一个集情感分析、数据可视化与舆情预测于一体的分布式分析平台。系统采用PySpark处理海量文本数据,Hive存储结构化分析结果,Django提供Web交互界面,实现从数据采集到预测预警的全流程自动化。
核心目标
- 实时分析用户评论情感倾向(积极/消极/中性)。
- 可视化展示热点话题、情感分布及地域分布。
- 预测舆情趋势并生成预警报告。
2. 系统架构设计
系统采用分层架构,分为数据层、计算层、应用层和展示层,各层技术选型如下:
mermaid
graph LR | |
A[数据层] -->|爬取数据| B[计算层] | |
B -->|分析结果| C[应用层] | |
C -->|可视化| D[展示层] | |
subgraph 数据层 | |
A1[小红书API/爬虫] --> A2[原始数据存储(HDFS)] | |
end | |
subgraph 计算层 | |
B1[PySpark数据清洗] --> B2[情感分析模型] | |
B2 --> B3[Hive结果存储] | |
end | |
subgraph 应用层 | |
C1[舆情预测算法] --> C2[预警规则引擎] | |
end | |
subgraph 展示层 | |
D1[Django后端] --> D2[ECharts前端] | |
end |
2.1 数据层
- 数据采集:通过小红书官方API或Scrapy框架爬取评论和笔记数据,包含字段:
- 文本内容、发布时间、用户ID、点赞数、话题标签、地理位置。
- 数据存储:原始数据存入HDFS,结构化结果存入Hive表(如
comments_sentiment、trending_topics)。
2.2 计算层
- PySpark处理:
- 数据清洗:去除重复、空值、广告等噪声数据。
- 特征工程:
- 文本分词(Jieba中文分词库)。
- 特征提取:TF-IDF、Word2Vec(结合表情符号、话题标签)。
- 情感分析模型:
- 传统机器学习:SVM、随机森林(基于Scikit-learn)。
- 深度学习:LSTM、BERT(通过PySpark的
pandas_udf调用TensorFlow/PyTorch)。
- 分布式训练:利用Spark的
MLlib或Horovod加速模型训练。
- Hive优化:
- 创建分区表(按日期、情感类别分区)。
- 使用ORC格式压缩存储,提升查询效率。
2.3 应用层
- 舆情预测:
- 时间序列模型:Prophet(Facebook开源库)预测情感趋势。
- 突发舆情检测:基于滑动窗口统计负面评论占比,触发阈值预警。
- 规则引擎:
- 定义预警规则(如“负面评论占比>30%且持续2小时”)。
2.4 展示层
- Django后端:
- 提供RESTful API供前端调用(如
/api/sentiment_trend)。 - 集成Celery实现异步任务(如定时预测)。
- 提供RESTful API供前端调用(如
- ECharts前端:
- 情感分布饼图、热点话题词云、地域热力图。
- 动态折线图展示预测趋势。
3. 关键技术实现
3.1 情感分析模型(PySpark示例)
python
from pyspark.sql import SparkSession | |
from pyspark.ml.feature import HashingTF, IDF, Tokenizer | |
from pyspark.ml.classification import LogisticRegression | |
# 初始化Spark | |
spark = SparkSession.builder.appName("SentimentAnalysis").getOrCreate() | |
# 加载数据(Hive表) | |
data = spark.sql("SELECT text, label FROM comments_sentiment") | |
# 文本分词与特征提取 | |
tokenizer = Tokenizer(inputCol="text", outputCol="words") | |
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=1000) | |
idf = IDF(inputCol="rawFeatures", outputCol="features") | |
# 构建Pipeline | |
from pyspark.ml import Pipeline | |
pipeline = Pipeline(stages=[tokenizer, hashingTF, idf, LogisticRegression()]) | |
model = pipeline.fit(data) | |
# 预测并存储结果 | |
predictions = model.transform(data) | |
predictions.select("text", "prediction").write.saveAsTable("sentiment_results") |
3.2 Hive查询优化
sql
-- 创建分区表 | |
CREATE TABLE comments_sentiment ( | |
id STRING, | |
text STRING, | |
label INT, | |
create_time TIMESTAMP | |
) PARTITIONED BY (dt STRING) | |
STORED AS ORC; | |
-- 查询负面评论占比 | |
SELECT | |
dt, | |
COUNT(CASE WHEN label = 0 THEN 1 END) * 100.0 / COUNT(*) AS negative_rate | |
FROM comments_sentiment | |
GROUP BY dt; |
3.3 Django可视化接口
python
# views.py | |
from django.http import JsonResponse | |
from pyspark.sql import SparkSession | |
def get_sentiment_trend(request): | |
spark = SparkSession.builder.appName("DjangoSpark").getOrCreate() | |
data = spark.sql("SELECT dt, negative_rate FROM sentiment_trend") | |
result = [{"date": row.dt, "rate": row.negative_rate} for row in data.collect()] | |
return JsonResponse({"data": result}) |
4. 系统功能模块
4.1 情感分析看板
- 功能:实时展示评论情感分布(积极/消极/中性比例)。
- 技术:PySpark分类模型 + ECharts饼图。
4.2 热点话题挖掘
- 功能:基于TF-IDF或LDA提取高频话题词云。
- 技术:PySpark的
CountVectorizer+ Jieba关键词提取。
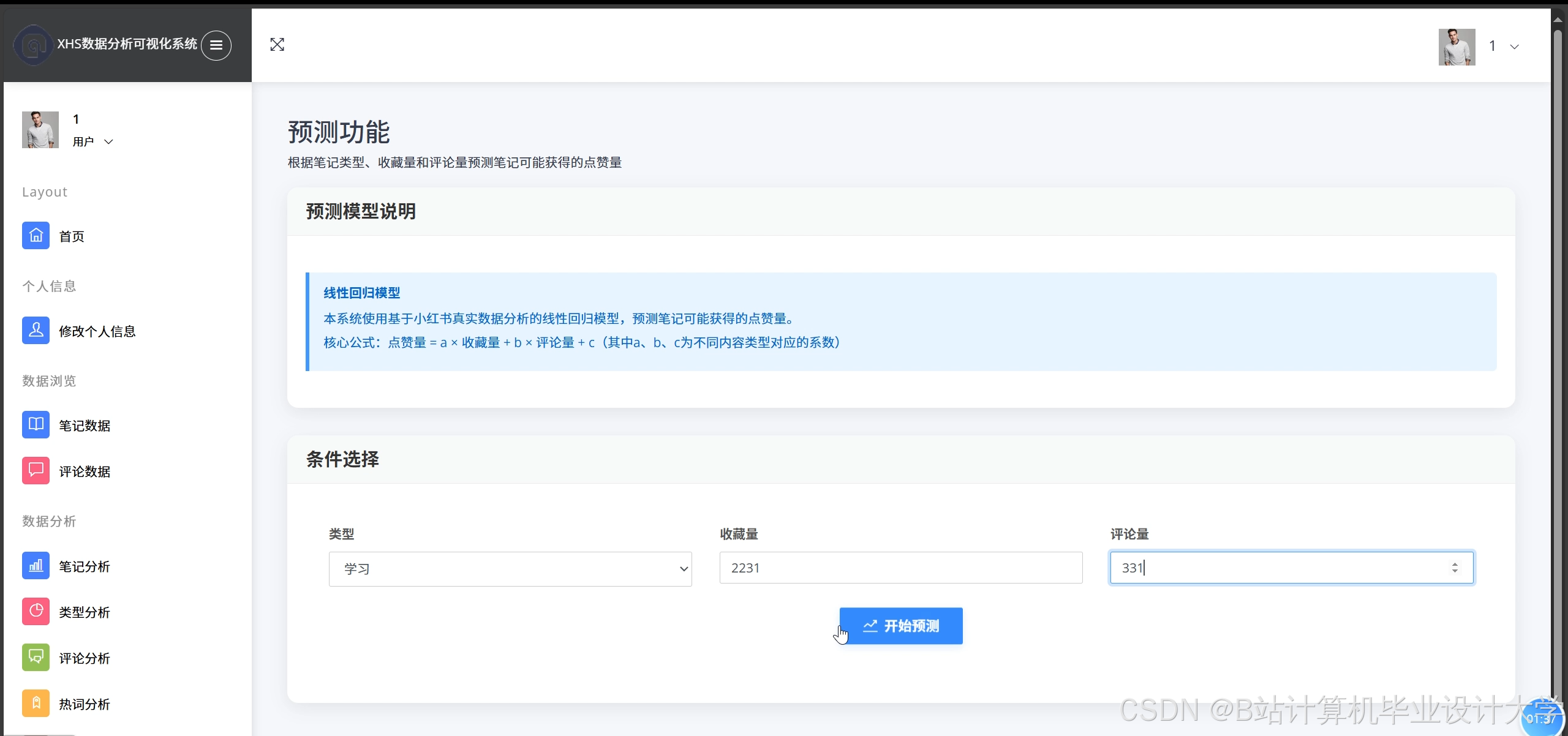
4.3 舆情预测与预警
- 功能:预测未来24小时情感趋势,触发邮件/短信预警。
- 技术:Prophet模型 + Django Celery定时任务。
4.4 用户行为分析
- 功能:分析高赞评论的用户画像(地域、兴趣标签)。
- 技术:Hive聚合查询 + 地理编码(高德API)。
5. 性能优化与挑战
5.1 优化策略
- PySpark调优:
- 调整
spark.executor.memory和spark.sql.shuffle.partitions。 - 使用广播变量(
Broadcast)加速小表JOIN。
- 调整
- Hive优化:
- 开启矢量化查询(
hive.vectorized.execution.enabled=true)。
- 开启矢量化查询(
5.2 面临挑战
- 数据倾斜:热门话题评论量过大导致Shuffle阶段卡顿。
- 解决方案:对热门话题ID进行随机前缀加盐(Salting)。
- 模型准确性:小红书短文本含大量网络用语和表情符号。
- 解决方案:构建领域词典(如“绝绝子”→积极)。
6. 部署与扩展性
6.1 部署方案
- 集群环境:
- Hadoop + Spark集群(3台节点,每台8核32GB)。
- Hive Metastore使用MySQL存储元数据。
- Web服务:
- Django部署于Nginx + Gunicorn,通过Supervisor管理进程。
6.2 扩展性设计
- 水平扩展:增加Spark Worker节点应对数据量增长。
- 模块解耦:情感分析、预测、可视化模块独立部署,通过Kafka消息队列通信。
7. 总结
本系统通过PySpark实现高效分布式计算,Hive保障数据可靠性,Django提供友好交互界面,形成了一套完整的社交电商舆情分析解决方案。未来可集成更先进的NLP模型(如GPT-4微调)进一步提升分析精度。
附录:
- 系统源码仓库:GitHub链接(待补充)
- 测试数据集:小红书评论样本(脱敏后)
备注:
- 实际开发需遵守小红书数据使用规范,避免爬虫被封禁。
- 可增加用户认证模块(如JWT)保护系统接口安全。
此文档可作为开发团队的技术参考或项目验收材料。
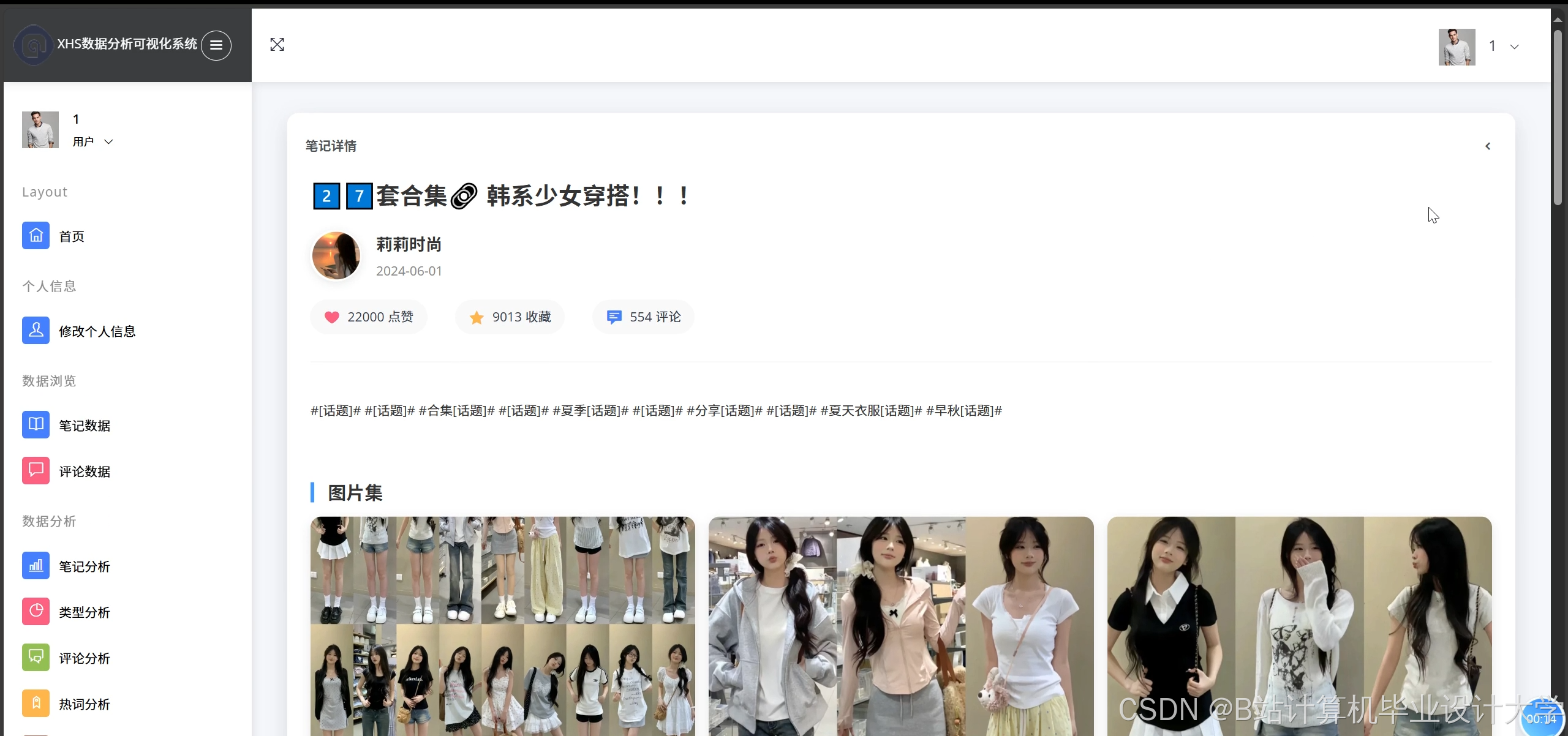
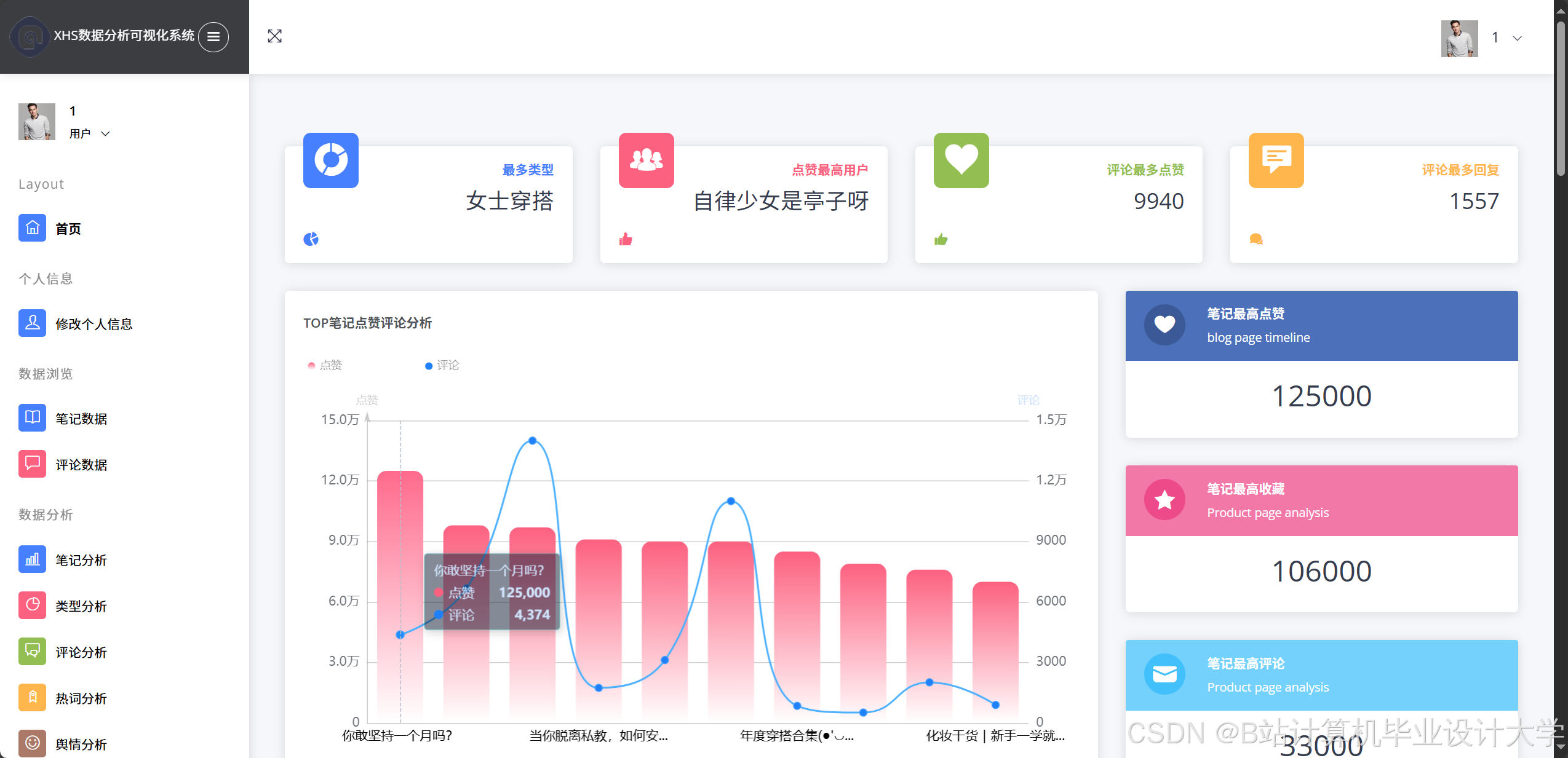
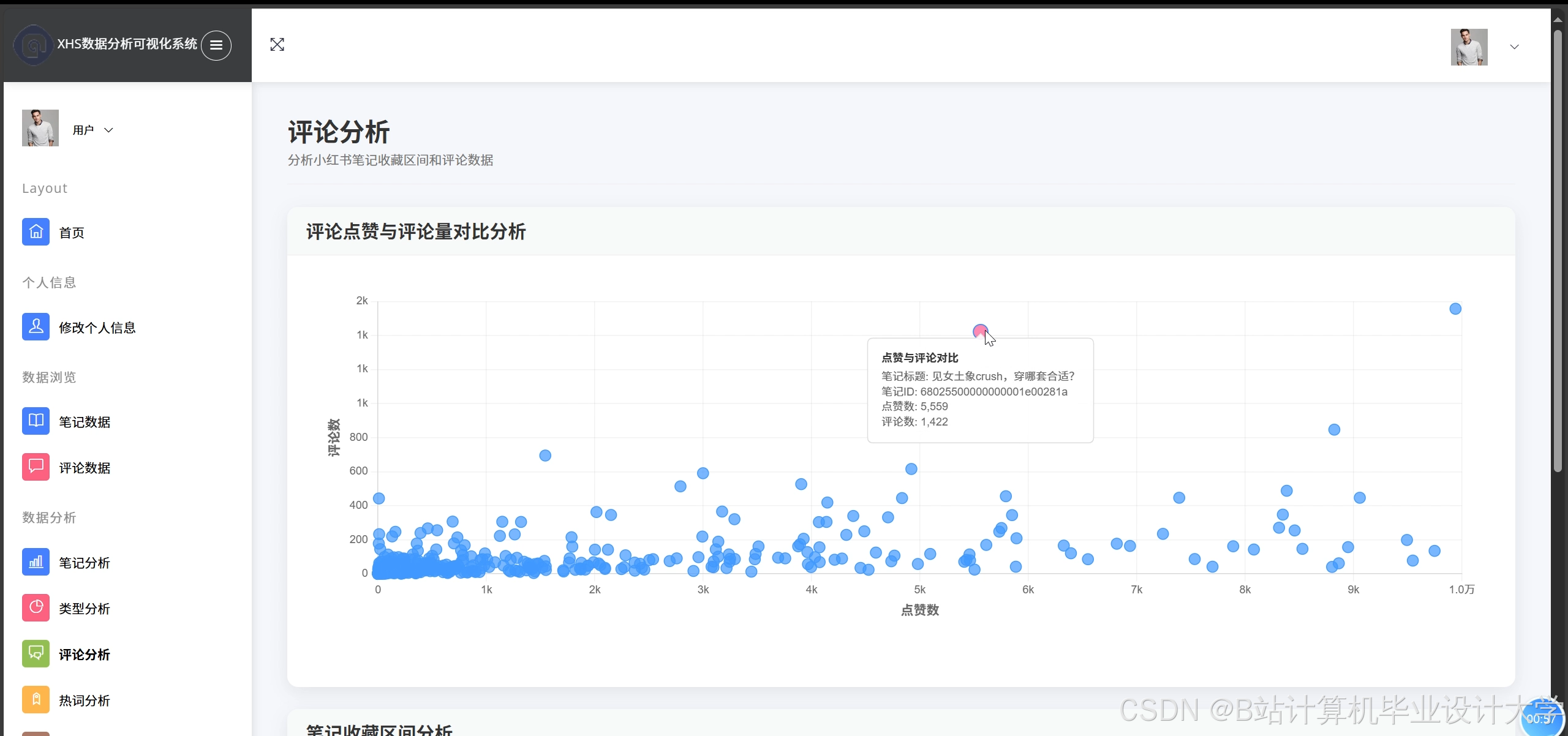
运行截图
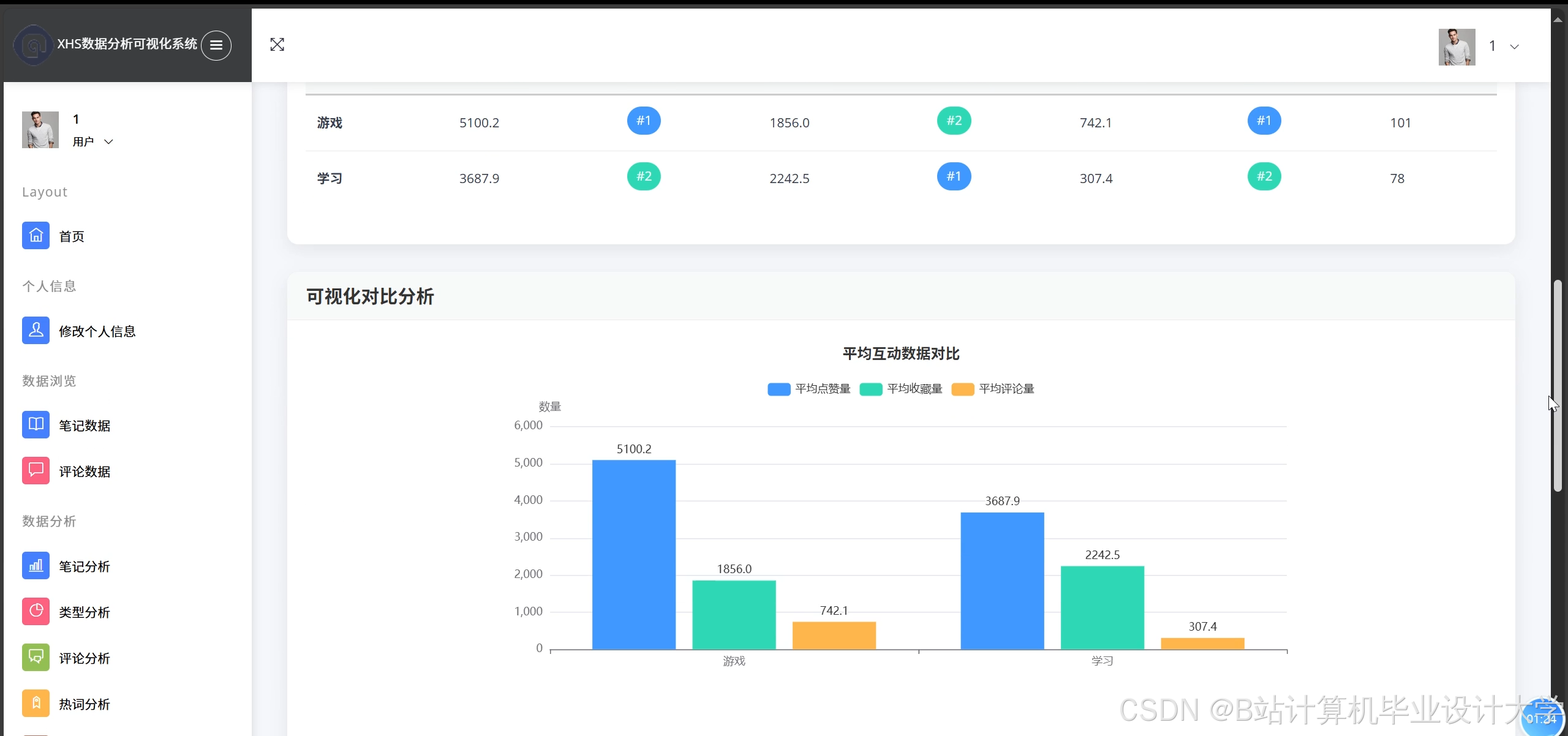
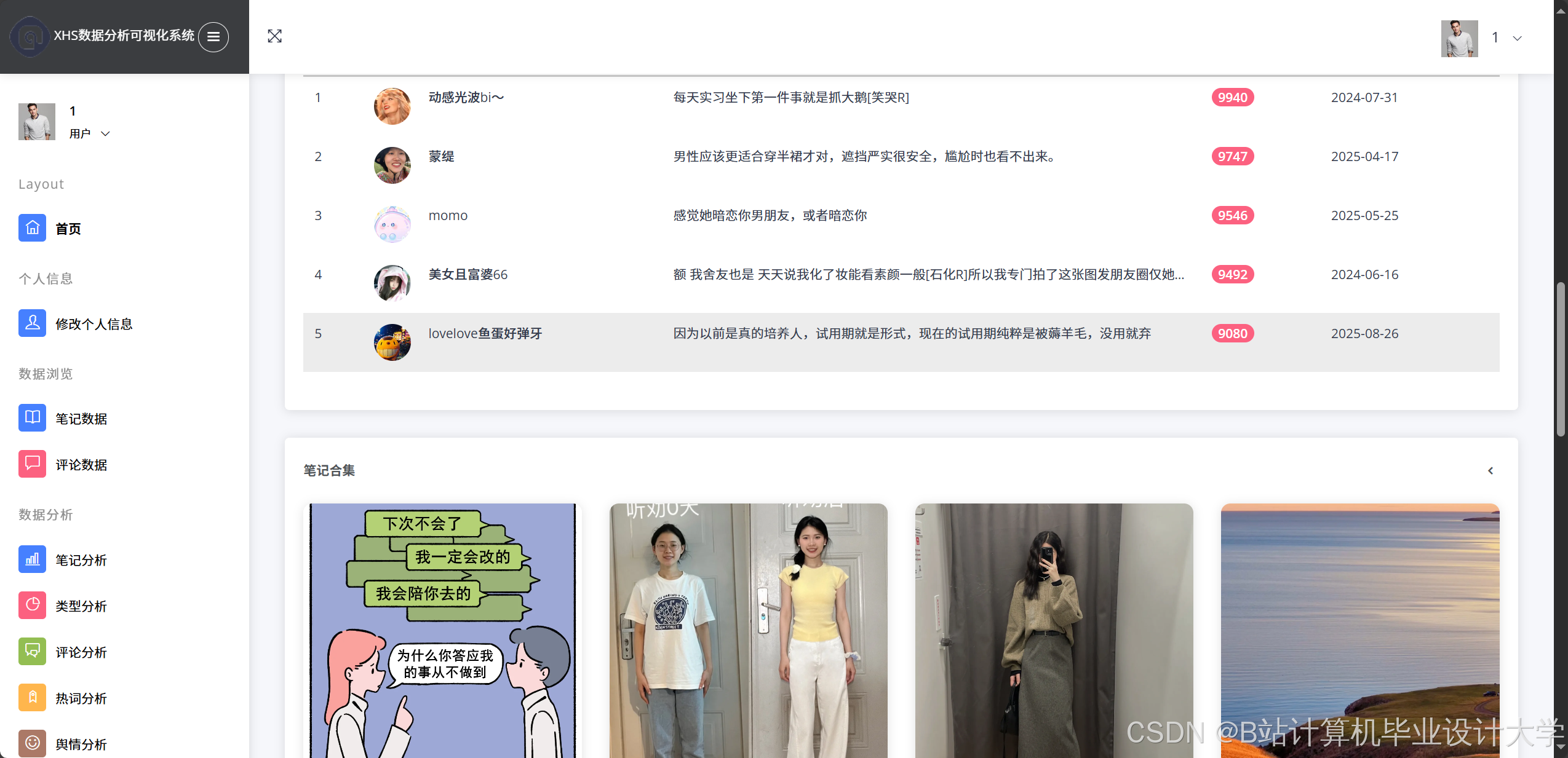
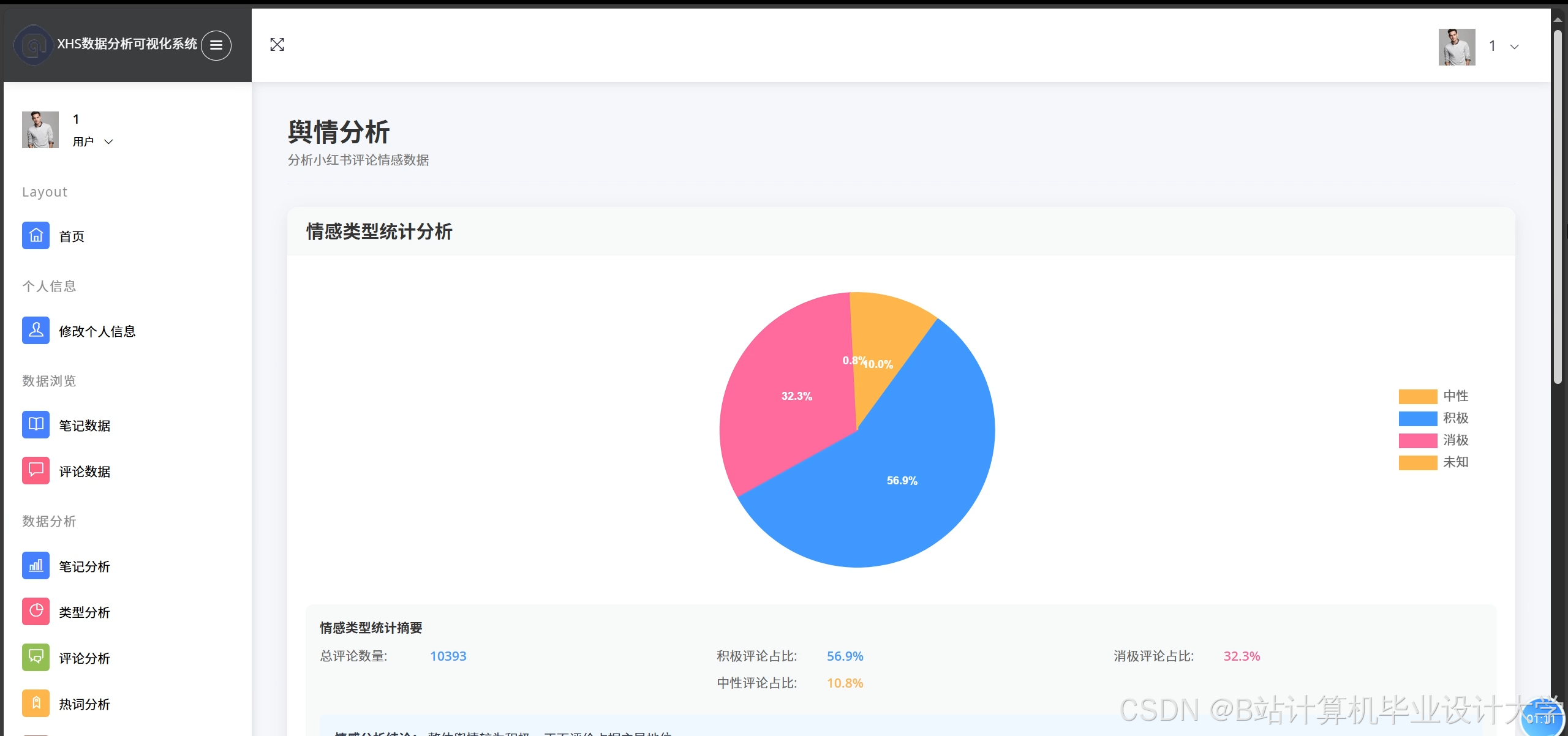
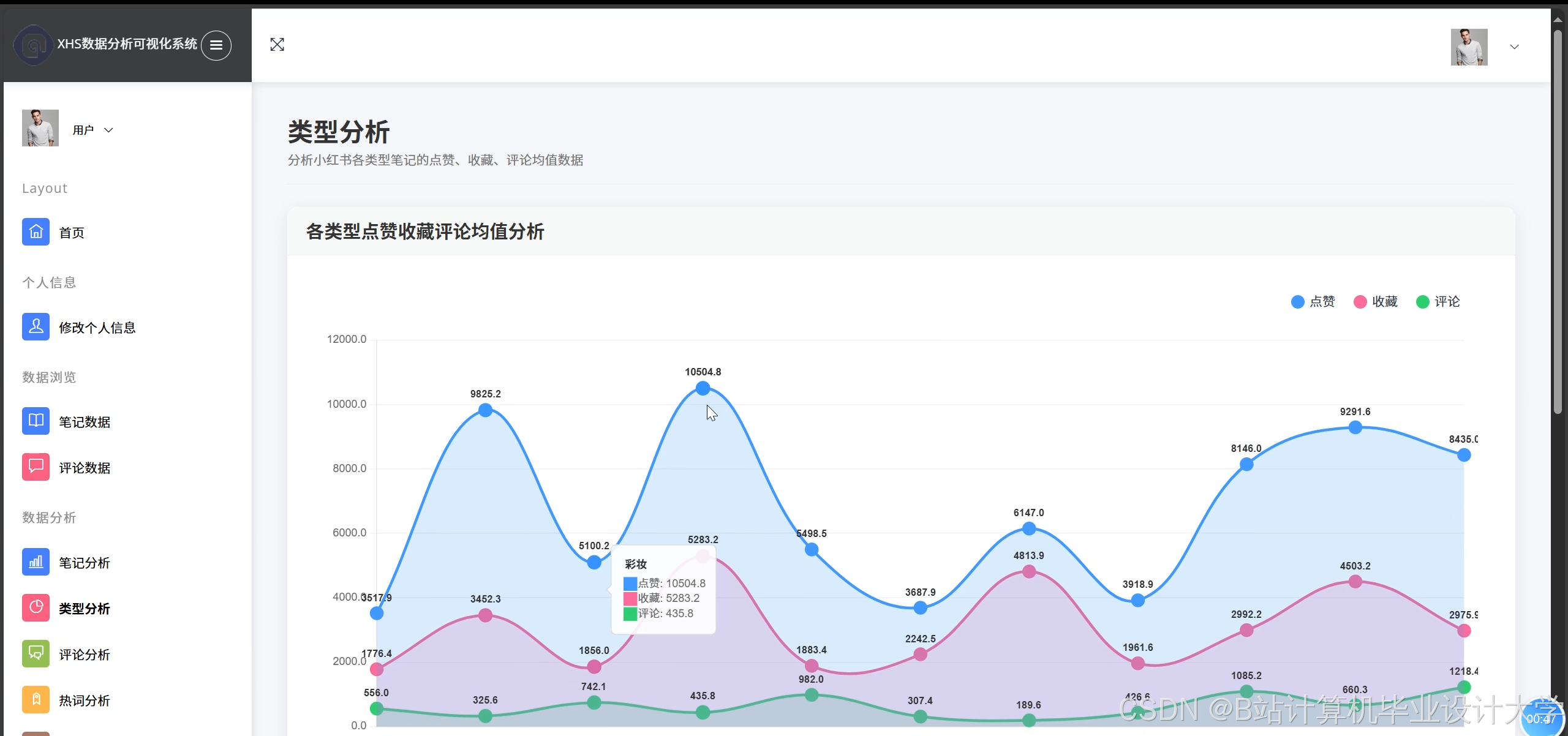
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











