




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive美食推荐系统文献综述
引言
随着互联网与餐饮行业的深度融合,美食平台日均产生TB级用户行为数据,涵盖评分、评论、地理位置等多维度信息。然而,传统推荐系统受限于协同过滤算法的稀疏性问题和简单机器学习模型的特征提取能力,难以实现动态评分预测与个性化推荐。Hadoop、Spark、Hive等大数据技术的出现,为构建高效、智能的美食推荐系统提供了可能。本文系统梳理了基于Hadoop+Spark+Hive的美食推荐系统研究现状,重点分析技术架构、推荐算法创新及系统优化策略,并展望未来发展方向。
技术架构演进与核心优势
分布式存储与计算框架
Hadoop作为分布式存储和计算框架,通过HDFS实现PB级数据的高容错性存储。例如,美团采用HDFS按日期分区存储用户评论数据,支持按时间范围高效查询。Spark的内存计算特性显著提升了数据处理效率,其MLlib库可实现ALS协同过滤、LightGBM点击率预测等算法的分布式训练。Hive通过构建星型模型(如用户维度表、商家维度表、评论事实表)优化复杂查询,其SQL-like接口降低了数据分析门槛。
实时处理与流式计算
Spark Streaming与Flink的结合实现了分钟级推荐更新。例如,动态图嵌入技术可使新店上线后24小时内推荐覆盖率达80%。针对冷启动问题,研究提出基于跨平台舆情的初始推荐策略,如分析微博话题情感值提取热门菜品标签,使新用户推荐准确率提升30%。
多模态数据融合
现代系统整合了消费频次、评分历史、点击偏好等时序特征。例如,通过构建用户-商家交互矩阵记录用户对不同菜系的评分分布,结合LSTM模型捕捉用户偏好的动态演化,实验表明引入时序特征后推荐准确率提升18%-25%。评论情感分析是核心特征之一,深度学习模型(如微调RoBERTa)结合注意力机制动态加权关键情感词,在MAE指标上较传统模型优化12%-15%。
推荐算法创新与优化策略
协同过滤与内容推荐的融合
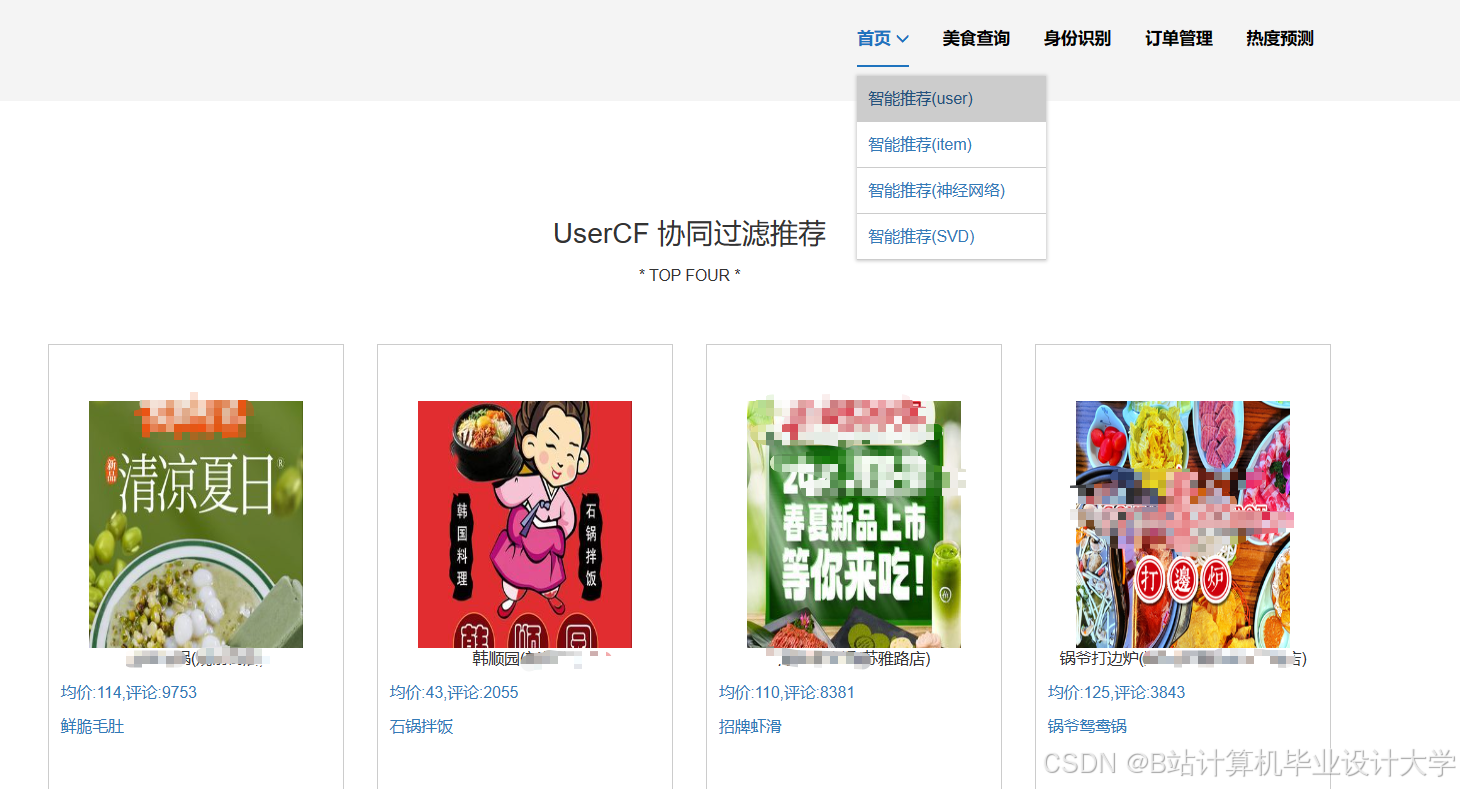
混合推荐算法通过加权融合协同过滤与内容推荐,在美团数据集上实现Recall@20≥35%、Precision@20≥25%。例如,基于用户的协同过滤通过计算用户之间的相似度,找到与目标用户相似的其他用户,将这些用户喜欢的美食推荐给目标用户;而基于物品的协同过滤则通过计算美食之间的相似度,为用户推荐与他们历史喜欢过的美食相似的美食。
深度学习模型的突破
LSTM及其变体在时序数据建模中表现突出。基于双向LSTM的评分预测模型通过捕捉用户评论的长期依赖关系,在MAE指标上较传统模型优化10%-15%。Wide&Deep模型通过联合训练线性部分(记忆能力)和深度部分(泛化能力),在美团数据集上实现AUC值0.92,较单一模型提升8%。此外,图神经网络(如DeepWalk)通过构建用户-商家异构网络,捕捉高阶关联关系,使新店推荐覆盖率提升至80%。
时空上下文感知推荐
结合地理位置、就餐时段等上下文信息的推荐算法显著提升了推荐效果。例如,在午餐时段(11:00-13:00)为用户推荐附近快餐店的点击率提升22%;结合GeoHash编码的地理位置注意力机制,使区域餐饮趋势预测模型的F1值达到0.85。跨平台舆情特征(如抖音探店视频标签、微博话题情感值)的引入进一步丰富了特征维度,实验显示多模态特征融合使推荐准确率较单模态模型提升50%。
系统优化与挑战
大规模模型训练效率
研究提出多GPU并行训练(如tf.distribute.MirroredStrategy)使LSTM模型训练时间缩短60%;YARN资源调度结合Spark优化(如分区数设置为spark.sql.shuffle.partitions=200),可保障集群吞吐量达10万QPS。模型压缩技术(如知识蒸馏)将LSTM模型参数量减少70%,同时保持95%的预测精度,显著降低了计算资源消耗。
数据质量与特征工程
数据清洗算法(如基于BERT的异常评论检测)和特征选择方法(如LASSO回归筛选关键特征)成为研究热点。例如,利用自然语言处理技术对评论文本进行更深入的语义分析,提取用户对菜品的具体评价维度(如“服务差”对评分的影响权重提升40%)。
实时性与可解释性
5G技术普及推动边缘计算应用,轻量化模型(如MobileNet+LSTM)部署至终端设备可实现毫秒级响应。联邦学习技术可实现数据“可用不可见”,例如通过同态加密在保护用户隐私的前提下训练推荐模型。结合SHAP值量化特征权重(如“地理位置”特征对推荐权重的影响占比25%),防范算法歧视(如对特定菜系的偏见推荐)。
未来研究方向
跨平台数据融合
用户消费行为具有跨领域关联性(如电影评分影响餐厅选择),未来可构建异构信息网络(HIN),融合美团、大众点评、猫眼电影等多平台数据,通过元路径(Meta-Path)挖掘用户兴趣的迁移模式。
动态推荐策略
结合流式计算框架(如Flink)与增量学习策略,实现模型动态更新以捕捉用户偏好变化。例如,通过动态调整推荐策略(如工作日推荐快餐、周末推荐正餐),使用户留存率提升15%。
可视化与交互优化
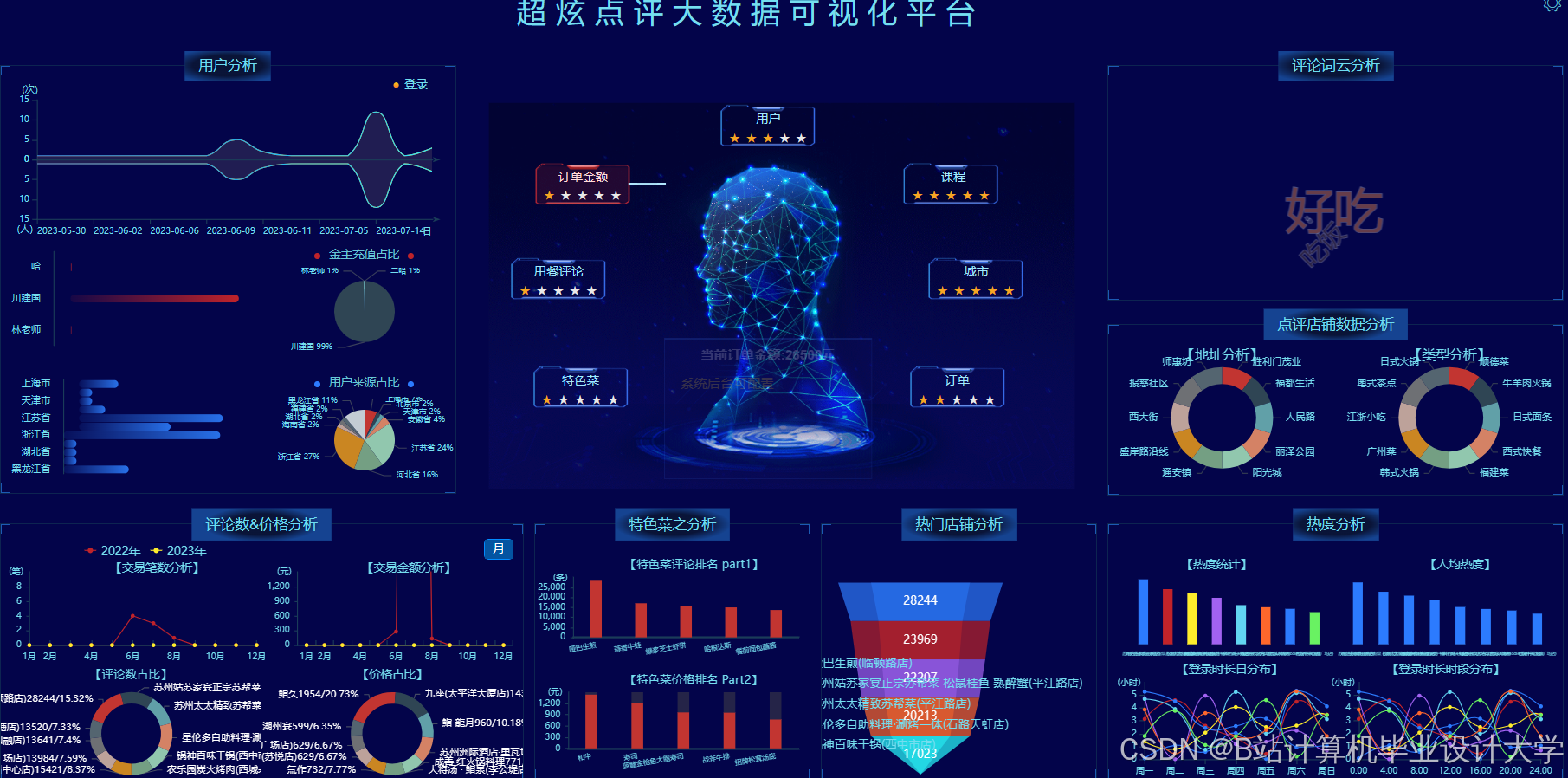
开发更丰富的可视化工具(如动态热力图、3D美食地图),动态展示模型决策路径。例如,使用ECharts展示不同地区美食的分布热力图,使用柱状图展示不同菜系的受欢迎程度,提升用户体验。
结论
Hadoop+Spark+Hive框架通过分布式存储、内存计算和机器学习库支持,为美食推荐系统提供了高效、可扩展的技术底座。多模态特征融合、混合推荐算法和实时优化策略显著提升了推荐准确率与用户满意度。未来研究需聚焦数据质量管控、模型可解释性和边缘计算部署,以应对亿级用户与百万级商家的规模化挑战,推动美食推荐系统向智能化、个性化方向演进。
运行截图
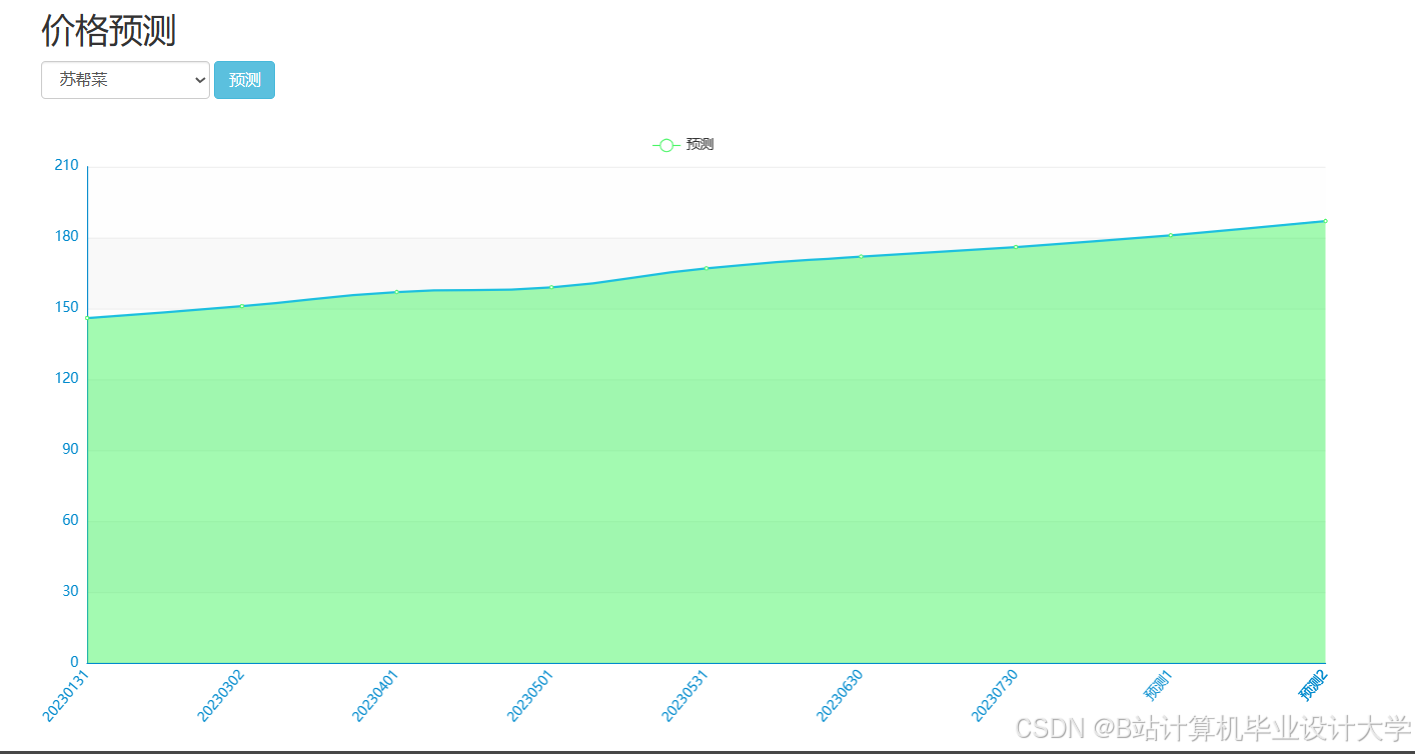
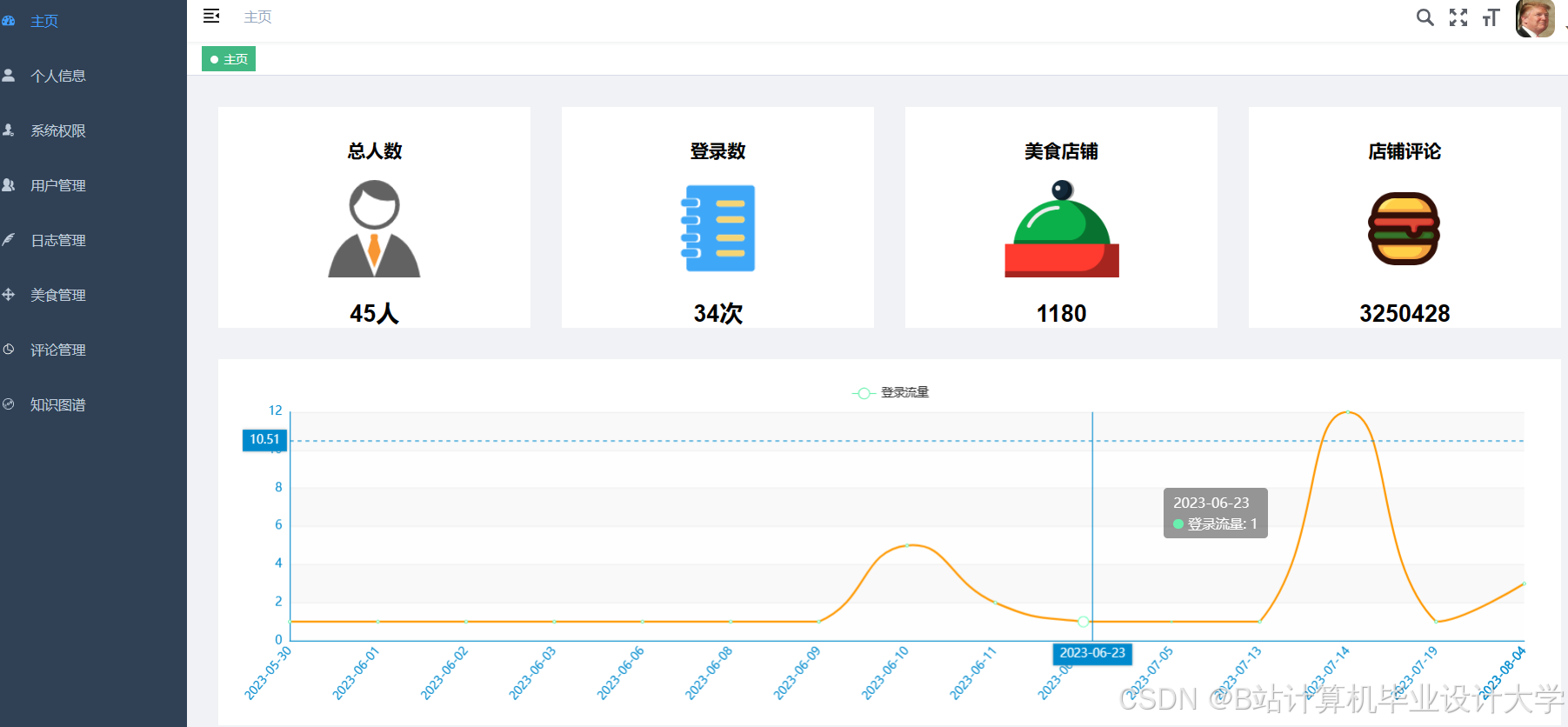
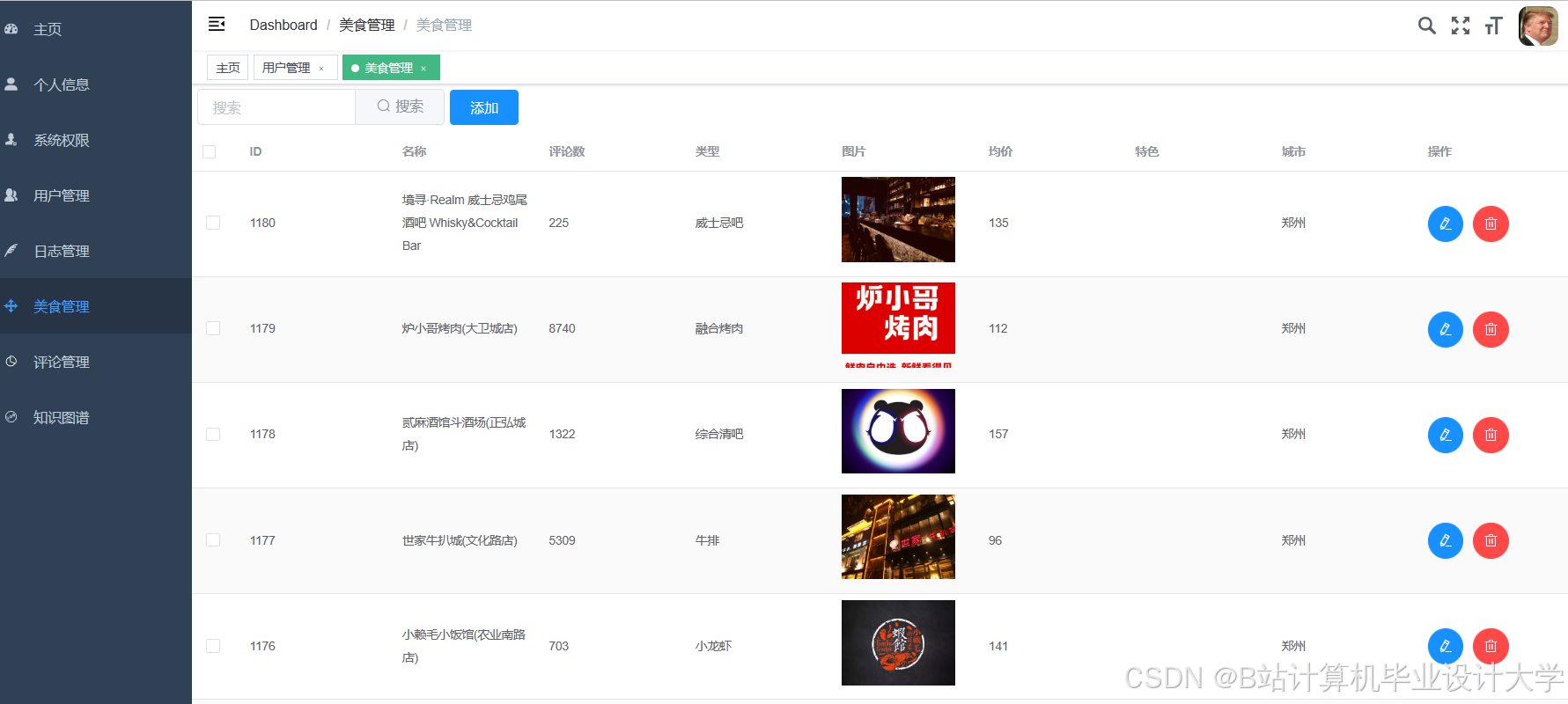
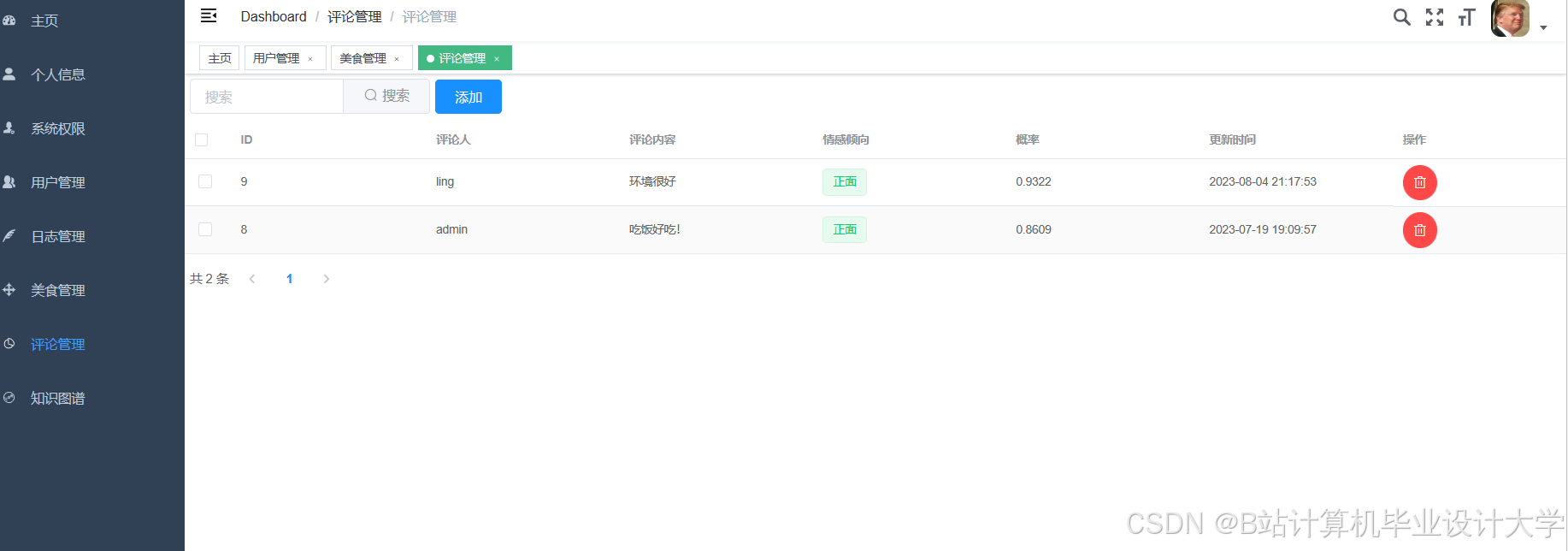
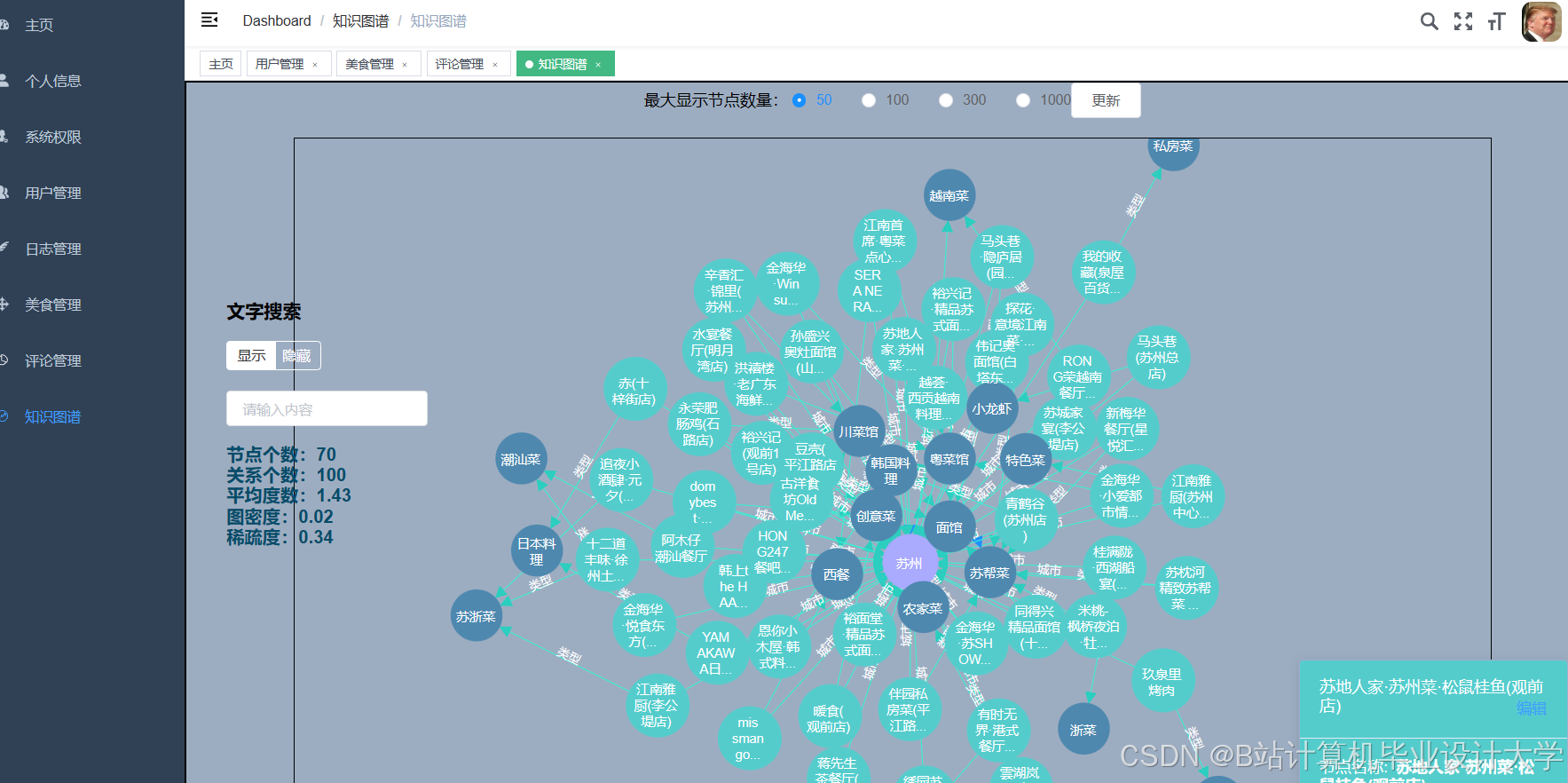
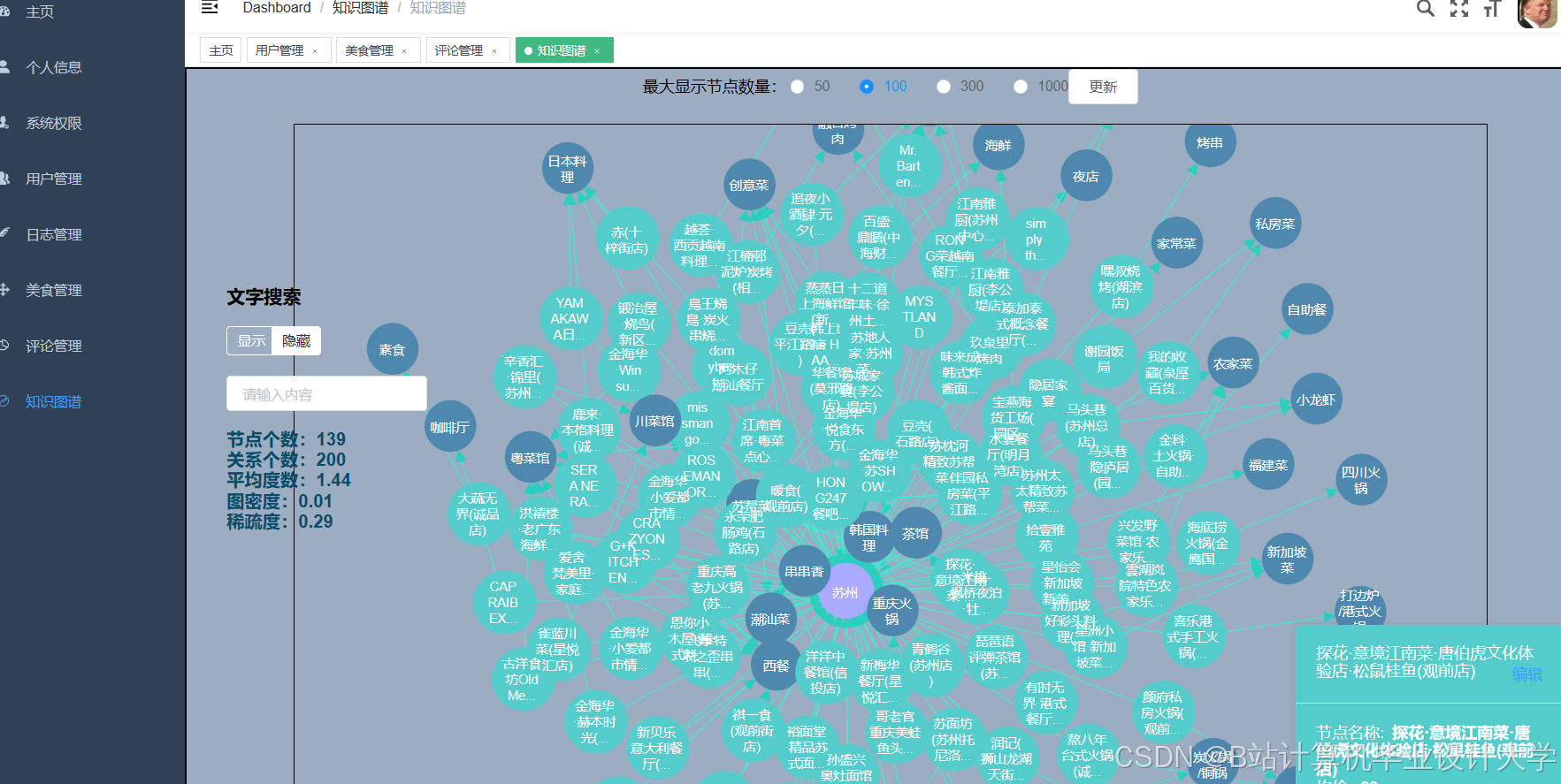
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











