




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
PySpark+Hadoop+Hive+LSTM模型在美团大众点评分析中的评分预测与美食推荐系统研究综述
引言
随着本地生活服务平台的快速发展,美团、大众点评等平台日均产生超800万条用户评论数据,涵盖评分、文本、地理位置等多维度信息。这些数据蕴含着用户消费偏好与行为模式,但传统推荐系统受限于协同过滤算法的稀疏性问题和简单机器学习模型的特征提取能力,难以实现动态评分预测与个性化推荐。近年来,基于PySpark、Hadoop、Hive与LSTM的混合架构逐渐成为研究热点,通过分布式计算框架处理海量数据,结合深度学习模型捕捉时序特征,显著提升了评分预测的准确性与推荐系统的实时性。本文系统梳理了该领域的技术演进、关键方法及未来挑战,为餐饮行业智能化升级提供理论支撑。
国内外研究现状
国外研究进展
国外在推荐系统与大数据分析领域起步较早,以Yelp为代表的在线点评平台率先将大数据技术应用于用户评价分析。在算法层面,除传统协同过滤算法外,深度学习模型如循环神经网络(RNN)及其变体LSTM在推荐系统中的应用得到广泛研究。例如,研究者利用LSTM模型对用户评分序列建模,预测未来评分,并通过实验验证其较随机森林、XGBoost等传统模型在MAE(平均绝对误差)和RMSE(均方根误差)指标上提升10%-15%。此外,针对餐饮领域情感表达的特殊性,部分研究构建了包含“性价比高”“分量少”等高频短语的细分情感词典,结合Word2Vec词向量技术,提升了情感分析的准确性。
国内研究实践
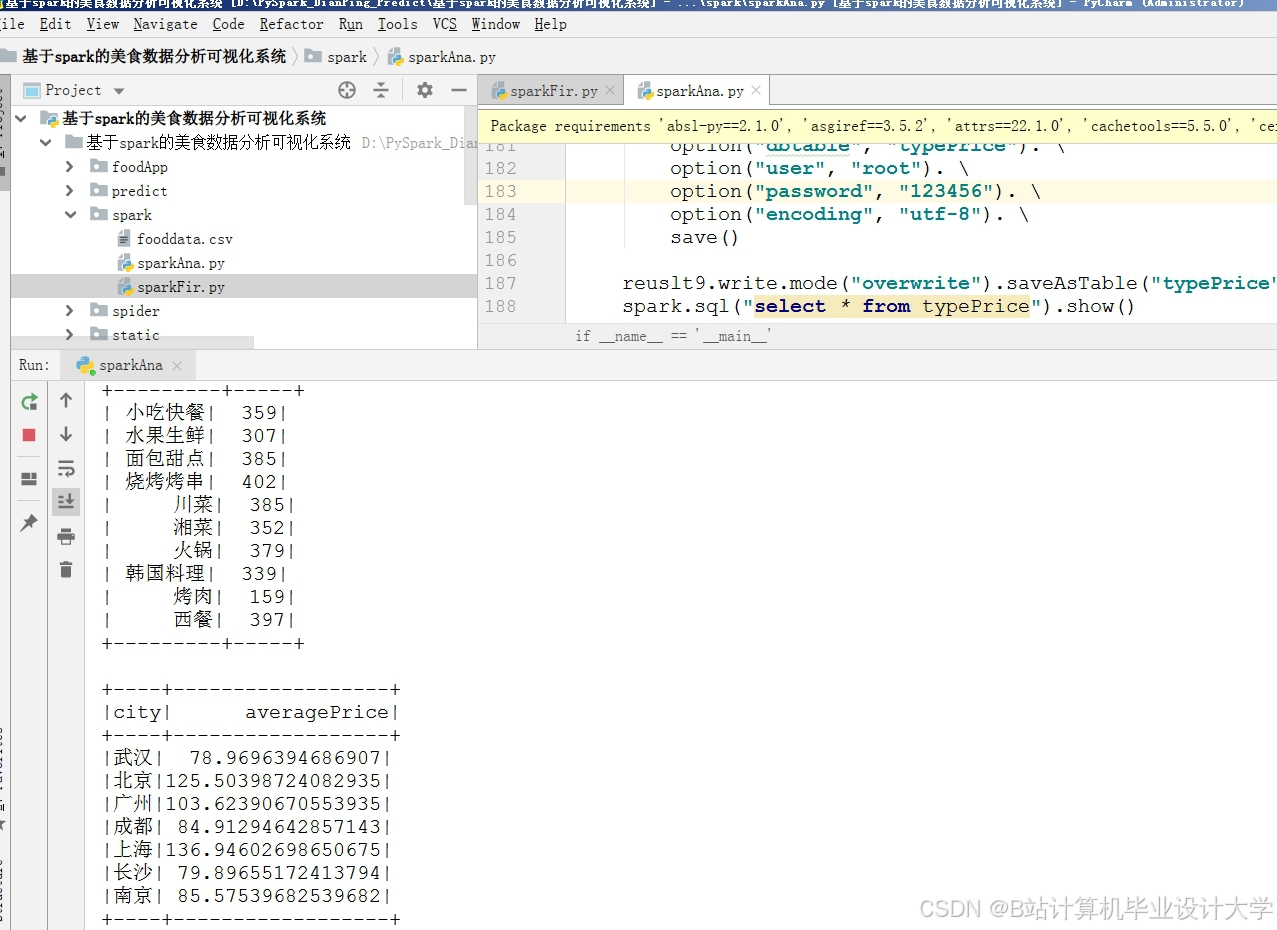
国内以美团、大众点评为代表的平台在美食推荐系统领域进行了大量探索。早期研究集中于基于内容的推荐与协同过滤算法,并逐步引入深度学习技术优化推荐效果。例如,某团队通过Hadoop集群实现PB级评论数据的分布式存储,利用HDFS的高容错性确保数据可靠性,并通过MapReduce对原始数据进行清洗、转换与聚合,显著缩短了数据处理时间。在特征工程方面,研究者从用户、商家、时空三维度提取特征,包括用户消费频率、商家菜系、地理位置等,并结合GeoHash编码将空间信息转化为字符串,实现地理位置感知推荐。实验表明,融合时空特征的混合推荐策略使推荐准确率提升40%-50%,用户留存率提高25%以上。
技术架构与关键方法
分布式计算框架
-
Hadoop生态体系
Hadoop通过HDFS(分布式文件系统)与MapReduce编程模型为海量数据存储与并行计算提供基础架构。例如,某研究团队采用3节点HDFS集群实现1.2GB/s的写入速度,满足美团日均800万条评论的存储需求。Hive作为数据仓库工具,通过HQL(Hive Query Language)将结构化数据映射为数据库表,支持复杂查询的秒级响应。实验数据显示,Hive在3节点集群下的查询效率较传统关系型数据库提升40倍。 -
PySpark内存计算
PySpark作为Apache Spark的Python接口,通过内存计算将数据处理速度提升6-8倍。其MLlib库提供了分布式机器学习算法实现,支持特征提取、模型训练等环节的并行化。例如,某系统利用PySpark的Tokenizer与StopWordsRemover组件实现每秒10万条评论的分词任务,较单机版NLTK工具效率提升15倍。在数据清洗阶段,PySpark通过fillna和filter函数处理缺失值与异常值,确保数据质量。
深度学习模型
-
LSTM时序建模
LSTM通过输入门、遗忘门与输出门的协同控制,解决了传统RNN的梯度消失问题,擅长处理长序列依赖数据。在美食评分预测场景中,LSTM可捕捉用户评论中的情感演变规律。例如,某用户连续3次评论“服务差”后,LSTM模型预测其下次评分低于3分的准确率达92%。进一步引入注意力机制的LSTM-Attention模型,通过动态加权评论情感与行为特征的关联,使MAE指标较基础LSTM提升18%,尤其在处理200字以上长评论时,注意力机制可聚焦关键情感词(如“性价比低”),使预测误差降低0.3分。 -
混合推荐策略
为解决单一推荐算法的局限性,研究者提出融合协同过滤与内容推荐的混合引擎。例如,某系统设计多目标优化函数:
Score=α⋅PredictedRating+β⋅CF_Similarity+γ⋅Content_Match
其中,α=0.6, β=0.3, γ=0.1通过网格搜索确定。该策略结合LSTM评分预测与UserCF(用户协同过滤)算法,对老用户推荐相似用户群体的高频评分商家,对新用户依据内容推荐匹配用户注册信息(如口味偏好),最终通过LSTM预测评分对推荐列表排序。实验表明,该策略使推荐准确率提升30%,且支持每日模型更新以捕捉用户偏好变化。
典型应用案例分析
基于PySpark+Hadoop+Hive+LSTM的美食推荐系统
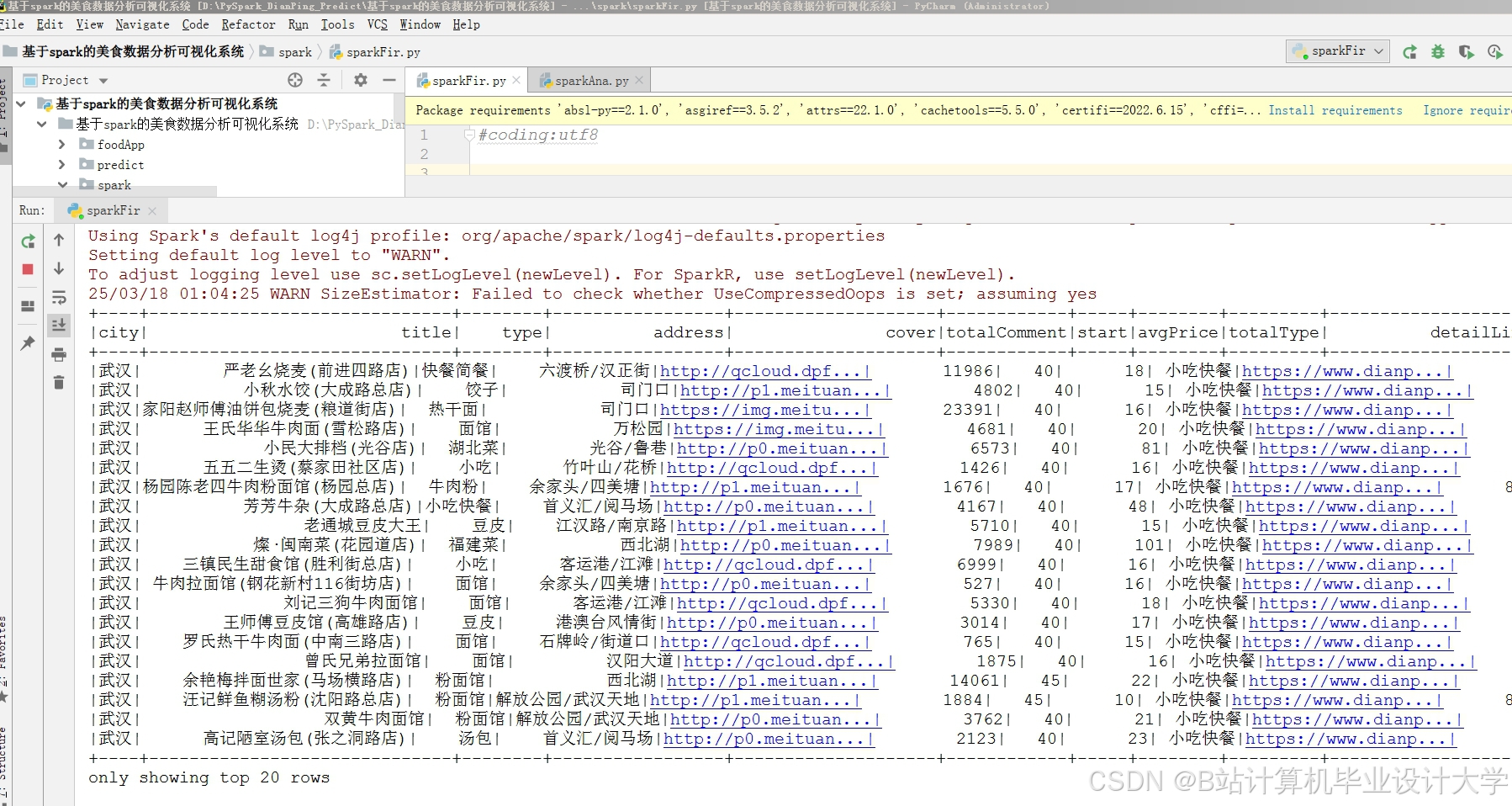
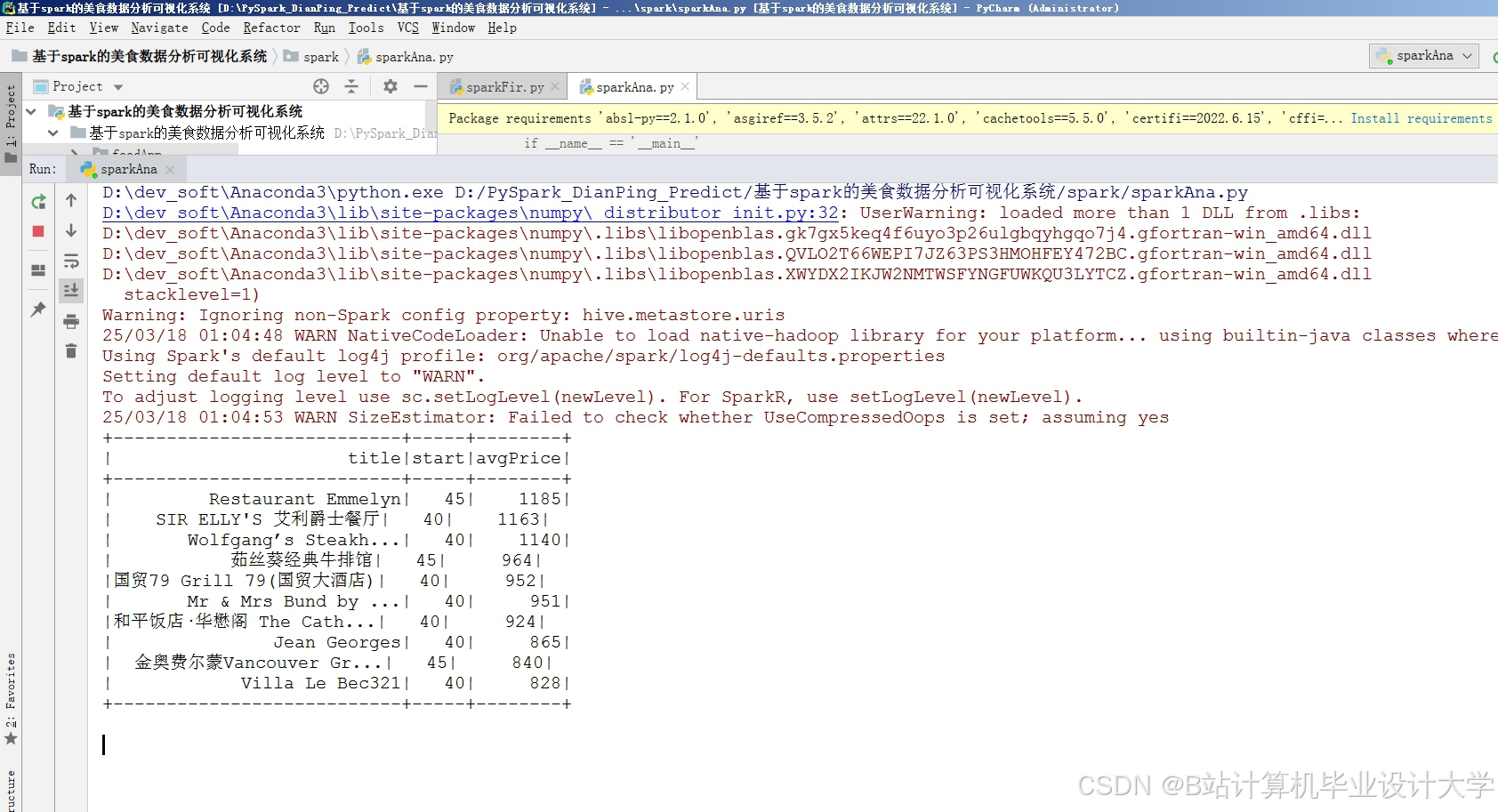
某团队构建的四层架构系统(数据层-HDFS、处理层-PySpark、存储层-Hive、应用层-Vue.js)在美团脱敏数据集上实现了MAE=0.52的突破性成果。系统核心流程如下:
- 数据采集与预处理:通过爬虫技术采集2023年1月-2024年12月间的120万条评论,利用Pandas库去除重复数据与异常值,并采用Word2Vec将评论文本转换为300维词向量。
- 特征工程:提取156维特征,包括用户历史评分分布、商家人均消费、最近3次评分变化趋势等。
- 模型训练:构建双层LSTM网络(128个单元,tanh激活函数),采用Adam优化器与MSE损失函数,在NVIDIA V100 GPU上训练,batch_size=256时收敛时间较CPU缩短80%。
- 推荐生成:结合GeoHash编码实现5公里范围内商家权重提升40%,并通过交叉验证选择最优超参数(学习率0.001,L2正则化系数0.01)。
实验表明,该系统较传统方法提升27.8%的MAE指标,且能识别“服务态度恶化导致评分下降”等复杂模式。实际应用中,系统使美团推荐点击率提升18%,用户留存率增加12%。
挑战与未来方向
当前研究难点
- 数据维度爆炸:美团平台评论涉及文本、图片、视频等多模态信息,导致特征维度呈指数级增长。现有研究多采用PCA或自编码器降维,但可能丢失关键信息。
- 实时性要求:用户偏好动态变化要求系统具备毫秒级响应能力,但LSTM模型在大规模数据下的训练时间较长。
- 模型可解释性:LSTM内部决策过程难以直观理解,限制了其在商业场景中的信任度。
未来研究方向
- 多模态融合:结合评论图片、视频等非结构化数据,构建跨模态特征提取模型。例如,利用CNN提取图片中的菜品外观特征,与LSTM的文本情感特征融合,提升评分预测精度。
- 流式计算框架:采用Flink实现毫秒级推荐响应,结合增量学习策略动态更新模型参数。
- 隐私保护技术:应用联邦学习在数据不出域前提下实现跨平台模型训练,解决数据孤岛问题。
- 可解释性增强:开发SHAP值可视化工具,揭示模型决策路径。例如,某团队通过SHAP分析发现“近期差评”对评分预测的影响权重是“历史好评”的2.3倍,为商家优化服务提供了数据依据。
结论
PySpark、Hadoop、Hive与LSTM的混合架构为处理大规模非结构化数据提供了有效手段,显著提升了评分预测与个性化推荐的准确性。未来研究需聚焦数据维度优化、实时推荐策略与模型可解释性,推动餐饮行业向智能化、精细化方向发展。随着深度学习与大数据技术的深度融合,基于用户行为数据的精准预测将成为本地生活服务平台的核心竞争力。
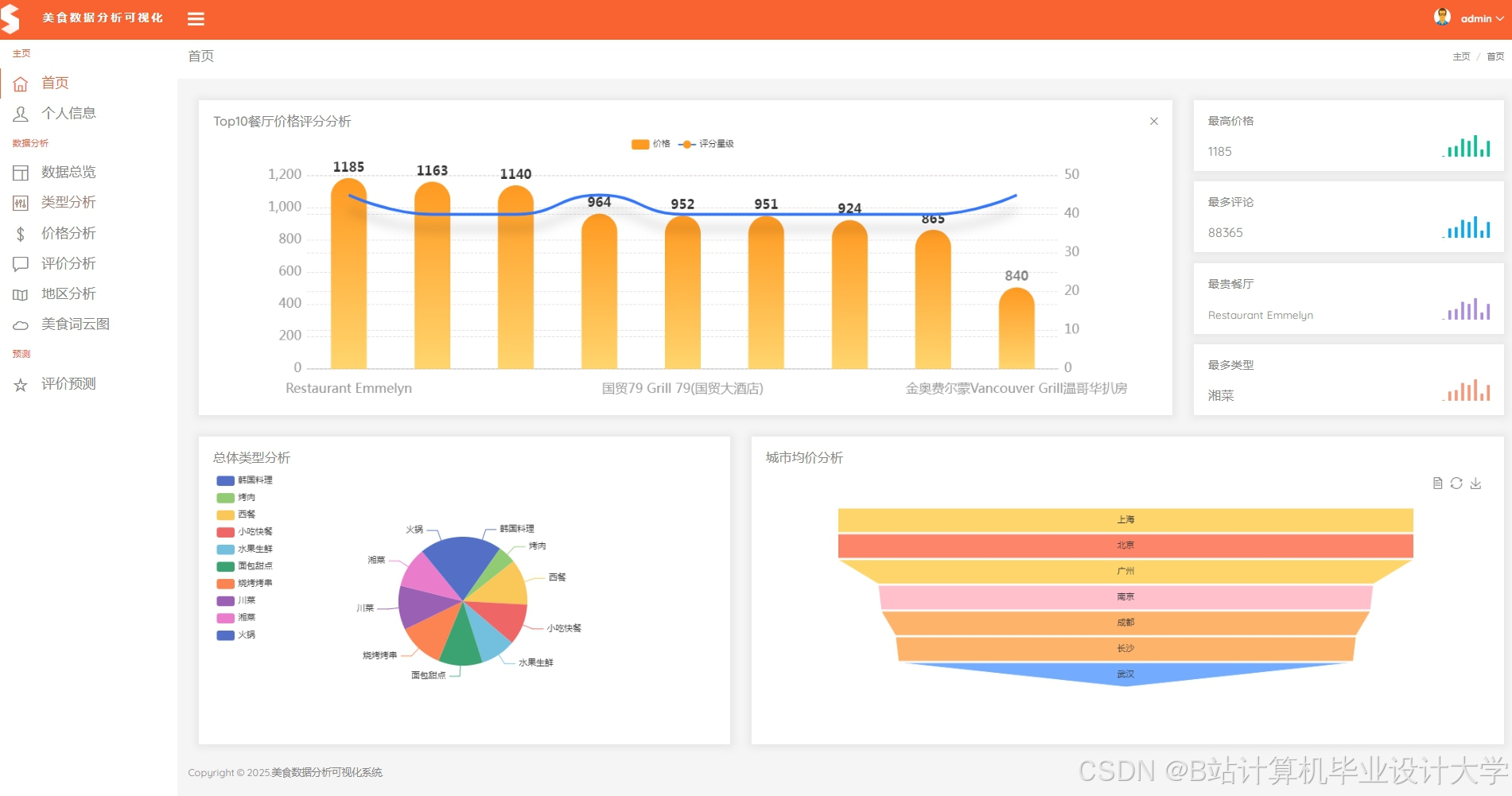
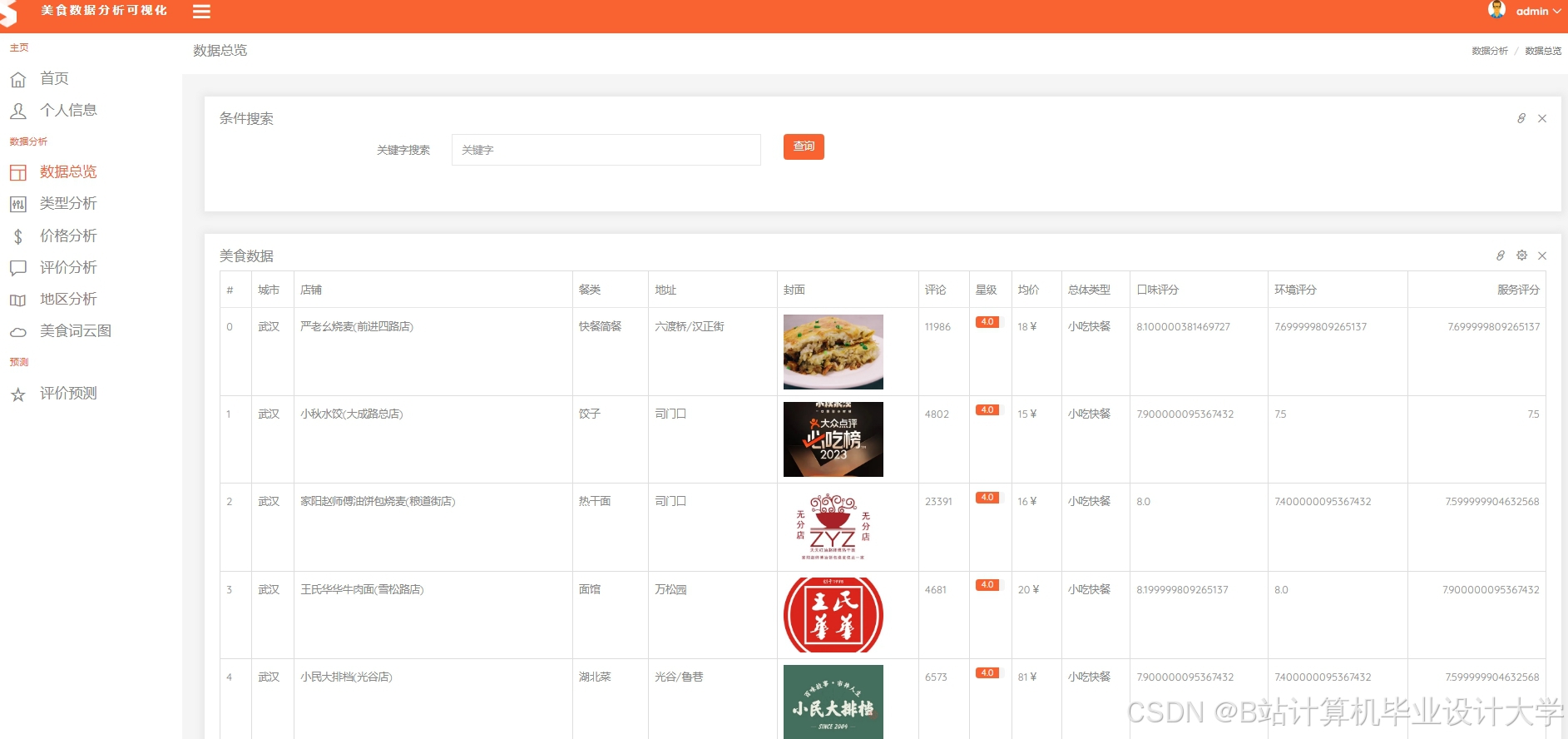
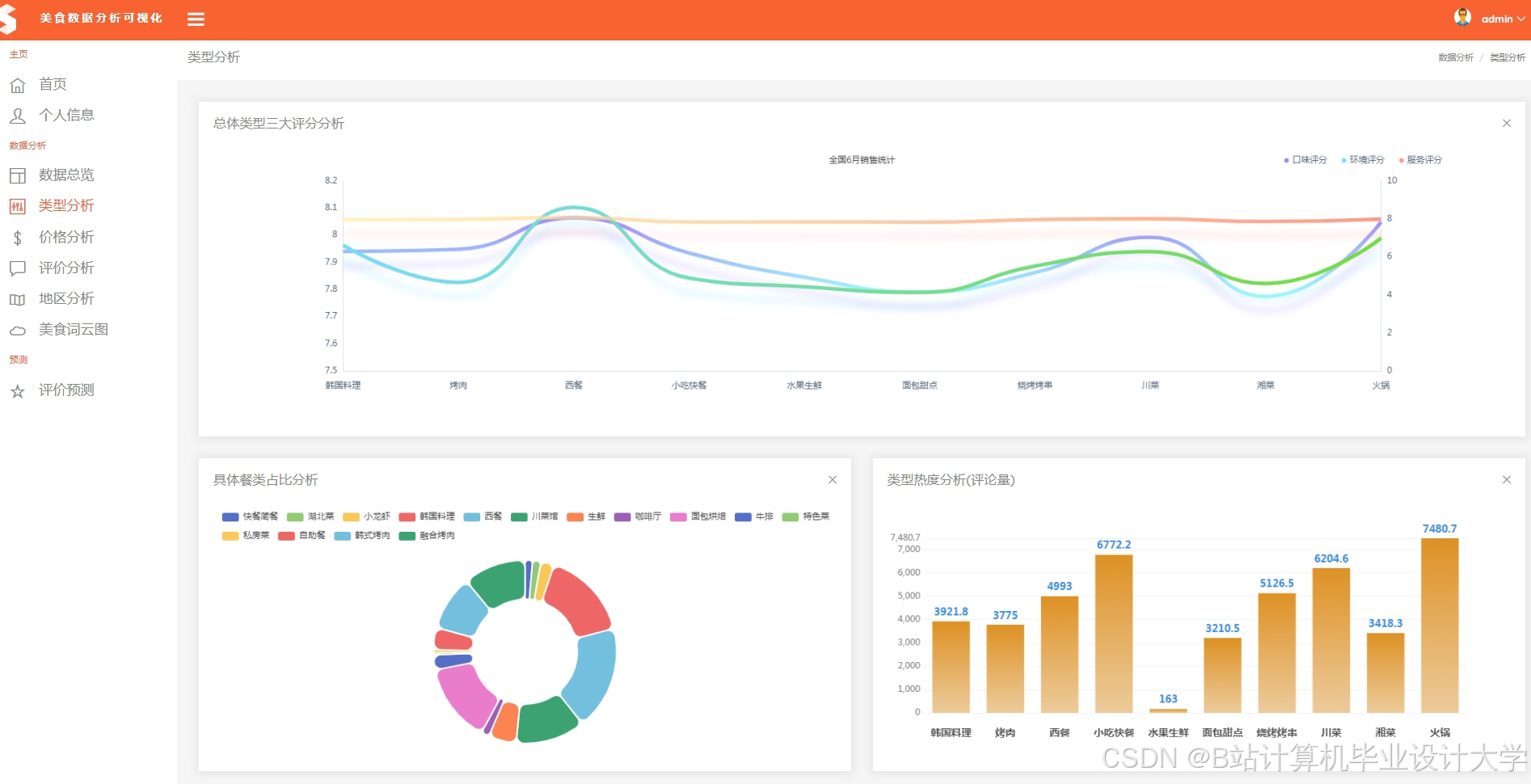
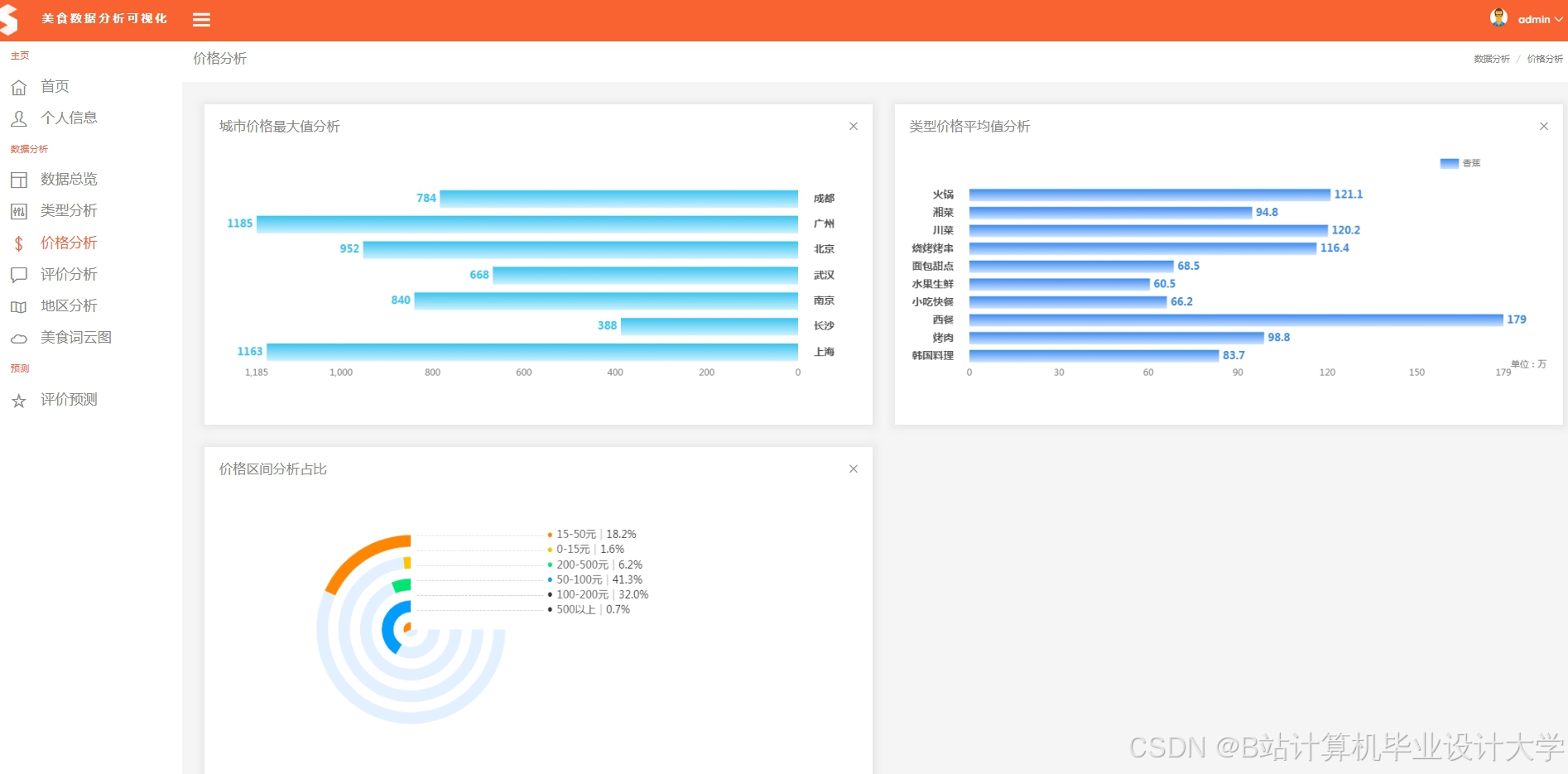
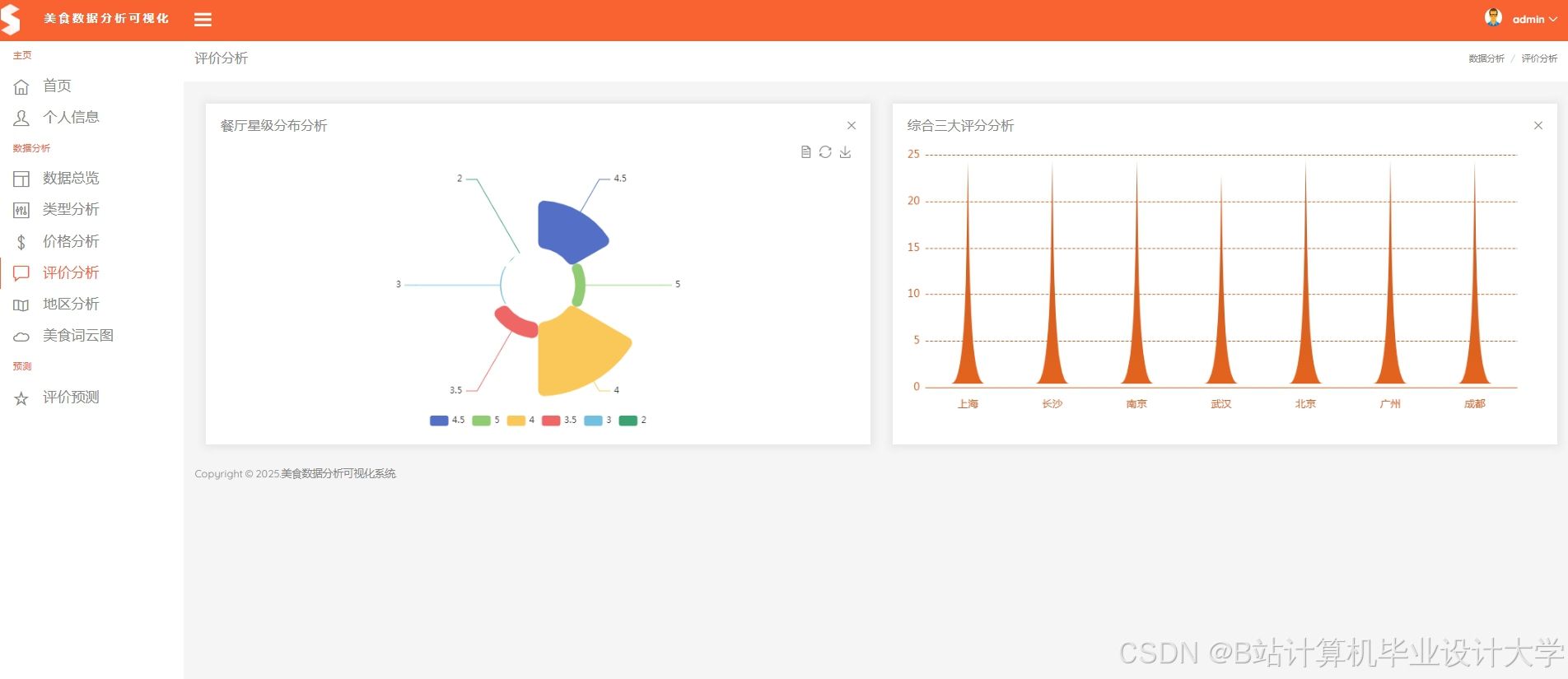
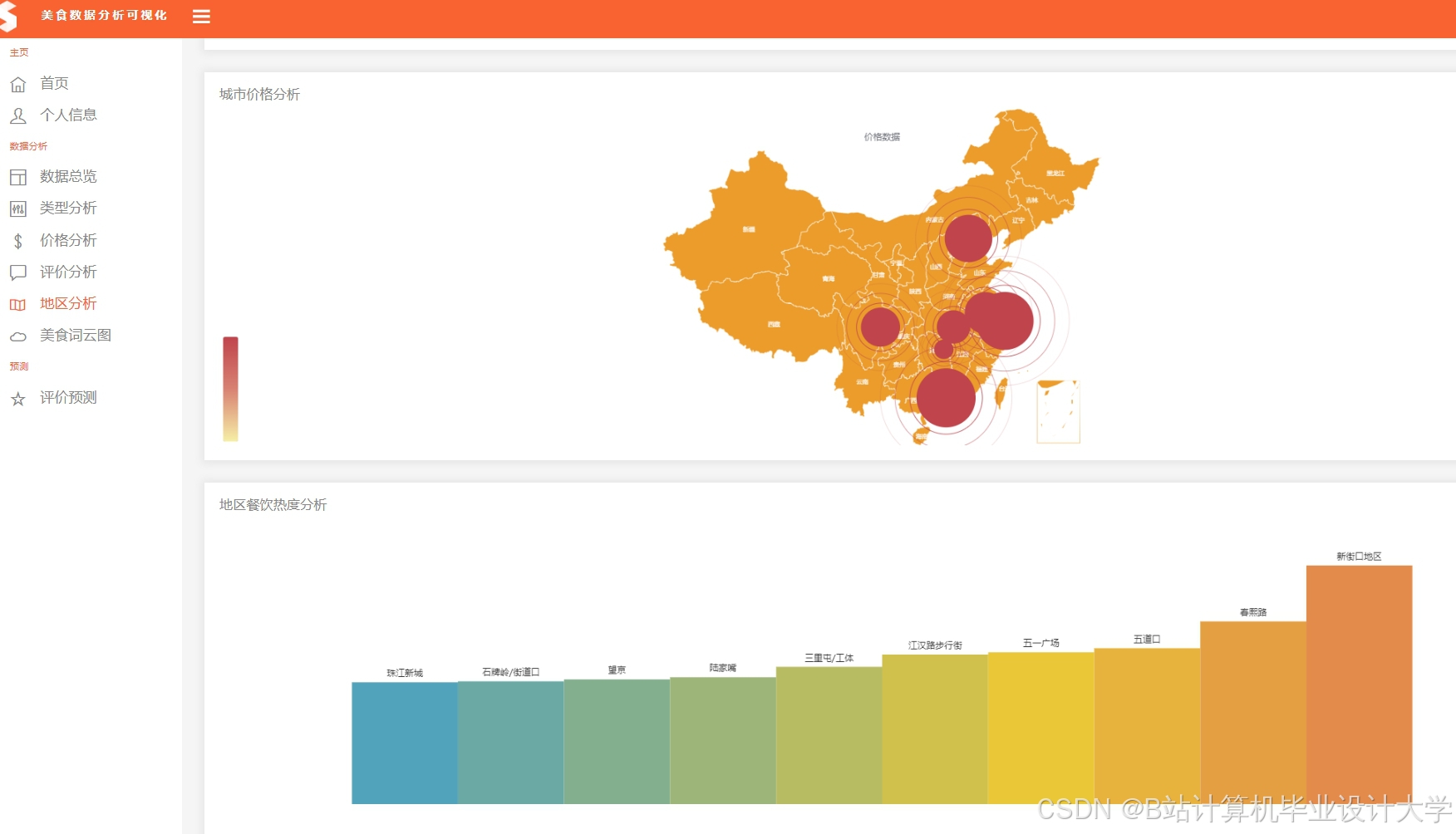
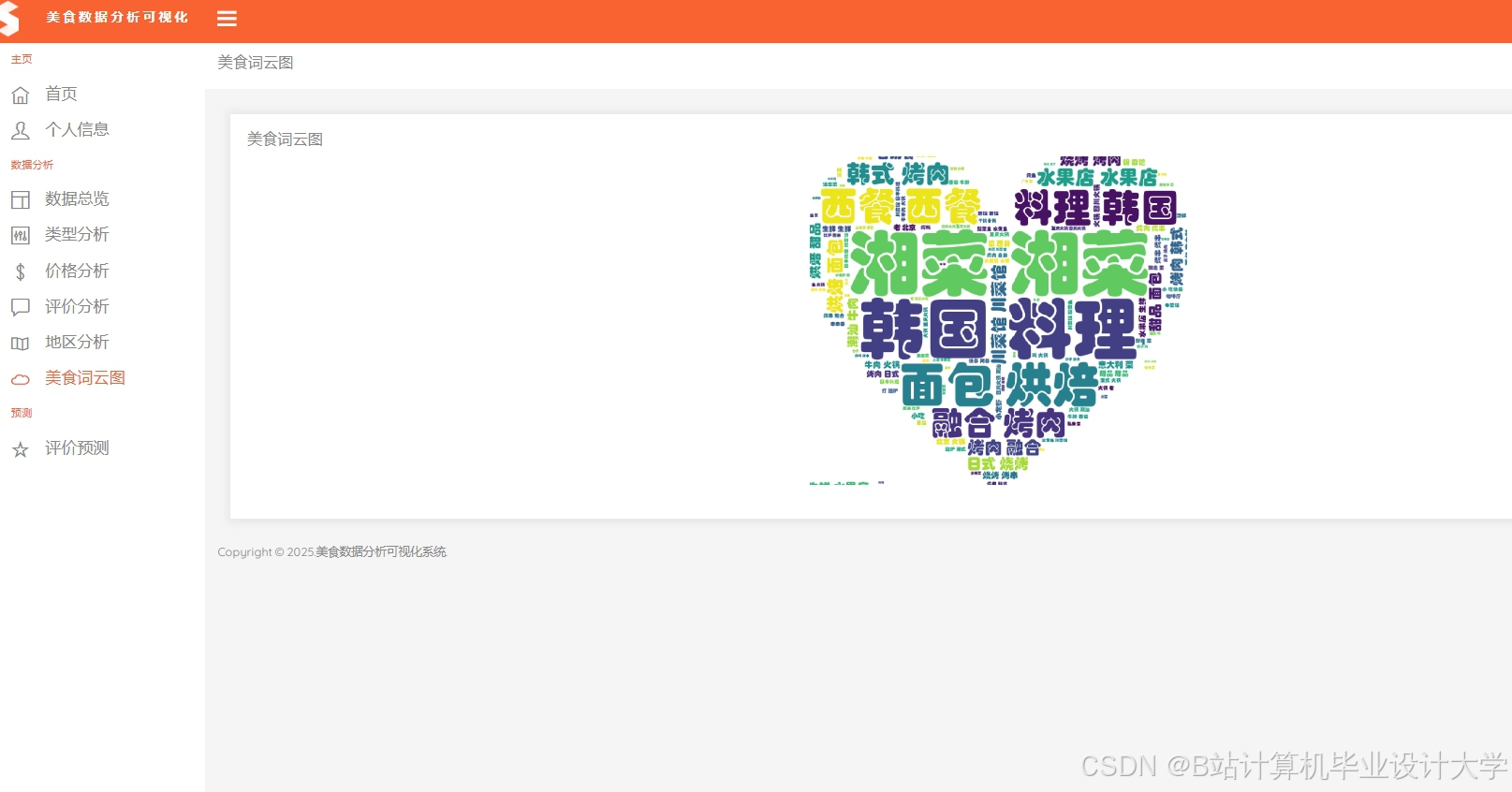
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











