




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《DeepSeek大模型+知识图谱Neo4J电商商品推荐系统》的技术说明文档,涵盖系统架构、核心算法、实现细节及优化方向:
技术说明:DeepSeek大模型+知识图谱Neo4J电商商品推荐系统
——基于语义理解与图关系的个性化推荐方案
一、系统概述
本系统结合DeepSeek大模型(深度语义理解)与Neo4J知识图谱(商品关系建模),构建了一个电商场景下的智能推荐系统。系统通过分析用户行为、商品属性及跨品类关联关系,实现“千人千面”的精准推荐,解决传统协同过滤算法中冷启动、数据稀疏等问题。
核心优势
- 语义增强:DeepSeek解析用户查询的隐含需求(如“送女友的生日礼物”)。
- 关系挖掘:Neo4J存储商品-品牌-类别-用户的图关系,发现间接关联(如“购买尿布的用户可能购买奶粉”)。
- 动态更新:图谱实时融入新商品、热点事件(如节日促销)。
二、系统架构
系统采用分层设计,分为以下模块:
1. 数据层
- 数据源:
- 用户数据:浏览记录、购买历史、搜索日志、点击行为。
- 商品数据:标题、描述、类别、价格、品牌、评价文本。
- 外部知识:百科数据(如品牌背景)、社交媒体热点。
- Neo4J知识图谱构建:
- 节点类型:用户(User)、商品(Product)、类别(Category)、品牌(Brand)、关键词(Keyword)。
- 关系类型:
- 用户-商品:
点击、购买、收藏。 - 商品-商品:
同类别、替代品、互补品(如手机与手机壳)。 - 商品-关键词:
包含(如商品描述含“无线充电”)。
- 用户-商品:
cypher// 示例:创建商品节点及关系CREATE (p1:Product {id: 'P001', name: 'iPhone 15', category: '手机'})CREATE (p2:Product {id: 'P002', name: 'AirPods Pro', category: '耳机'})CREATE (p1)-[:COMPLEMENTARY]->(p2) // iPhone与AirPods为互补品
2. 算法层
(1) DeepSeek大模型应用
- 任务1:用户意图理解
- 输入:用户搜索词“适合户外运动的耳机”。
- 输出:提取关键词“户外运动”“降噪”“续航”,并关联到商品属性(防水等级、电池容量)。
- 代码示例(调用DeepSeek API):
pythonimport requestsdef parse_query(query):url = "https://api.deepseek.com/v1/intent"response = requests.post(url, json={"text": query})return response.json()["keywords"] # 返回['户外运动', '降噪']
- 任务2:商品文本向量化
- 使用DeepSeek生成商品标题/描述的嵌入向量(Embedding),用于语义相似度计算。
pythondef get_embedding(text):url = "https://api.deepseek.com/v1/embedding"response = requests.post(url, json={"text": text})return response.json()["embedding"] # 返回768维向量
(2) Neo4J图算法
-
个性化路径推荐:
- 从用户历史购买商品出发,通过图遍历找到关联商品(如2度关系)。
cypherMATCH path = (u:User {id: 'U123'})-[:BUY*1..2]->(p:Product)WHERE NOT (u)-[:BUY]->(p) // 排除已购买商品RETURN p LIMIT 10 -
社区发现:
- 使用Louvain算法识别用户兴趣社群(如“数码爱好者”“母婴群体”)。
cypherCALL gds.louvain.stream({nodeQuery: 'MATCH (u:User) RETURN id(u) AS id',relationshipQuery: 'MATCH (u1:User)-[:SIMILAR]->(u2:User) RETURN id(u1) AS source, id(u2) AS target',includeWeight: true})
3. 推荐策略融合
- 多路召回:
- 语义召回:基于DeepSeek嵌入向量的余弦相似度。
- 图关系召回:通过Neo4J找到的关联商品。
- 热门召回:全局销量TopN商品。
- 排序层:
- 使用XGBoost融合特征(用户画像、商品热度、图关系权重)。
pythonimport xgboost as xgbdef rank_candidates(user_features, item_features):dtrain = xgb.DMatrix(user_features, label=item_features["click_prob"])model = xgb.load_model("rank_model.json")return model.predict(dtrain) # 输出推荐分数
三、核心算法实现
1. 知识图谱增强语义推荐
- 步骤:
- 从用户查询中提取实体(如“华为手机”)。
- 在Neo4J中查询相关实体(如“华为Mate 60”“鸿蒙系统”)。
- 结合DeepSeek嵌入向量,找到语义相似商品。
- 代码示例:
pythondef semantic_graph_recommend(query, user_id):# 1. 解析查询keywords = parse_query(query)# 2. 查询知识图谱中的关联商品cypher_query = f"""MATCH (u:User {{id: '{user_id}'}})-[:BUY]->(p1:Product),(p1)-[:SIMILAR|COMPLEMENTARY*1..2]->(p2:Product)WHERE ANY(kw IN $keywords WHERE p2.name CONTAINS kw)RETURN p2.id AS product_id"""graph_results = neo4j_session.run(cypher_query, keywords=keywords)# 3. 结合语义相似度排序products = [r["product_id"] for r in graph_results]embeddings = {pid: get_embedding(get_product_desc(pid)) for pid in products}query_emb = get_embedding(query)scores = {pid: cosine_sim(query_emb, emb) for pid, emb in embeddings.items()}return sorted(scores.items(), key=lambda x: -x[1])[:10]
2. 冷启动解决方案
- 新用户:基于注册时选择的兴趣标签(如“运动健身”)在知识图谱中定位初始商品簇。
- 新商品:通过属性匹配(如“无线耳机”)找到相似老商品,继承其关联关系。
四、系统优化方向
1. 性能优化
- Neo4J调优:
- 使用
gds(Graph Data Science)库预计算常用路径。 - 为高频查询创建索引(如
CREATE INDEX ON :Product(name))。
- 使用
- DeepSeek服务化:
- 部署本地化模型(如通过vLLM框架),减少API调用延迟。
2. 效果优化
-
多目标排序:
- 平衡点击率(CTR)、转化率(CVR)、客单价等目标。
pythondef multi_objective_score(ctr, cvr, price):return 0.6 * ctr + 0.3 * cvr + 0.1 * np.log(price) # 权重可调 -
实时反馈闭环:
- 记录用户对推荐结果的显式反馈(如“不感兴趣”),动态调整图关系权重。
五、应用场景与效果
1. 典型场景
- 搜索推荐:用户输入“送妈妈礼物”,推荐关联商品(如丝巾、保健品)。
- 首页猜你喜欢:结合用户长期兴趣(图谱)和短期行为(DeepSeek语义)。
- 跨品类推荐:购买咖啡机后推荐咖啡豆、磨豆机。
2. 效果数据
- 冷启动用户覆盖率提升40%(通过知识图谱关联)。
- 推荐商品点击率(CTR)提高25%(语义+图关系融合)。
六、总结与展望
本系统通过DeepSeek大模型解决语义理解问题,利用Neo4J知识图谱挖掘商品间复杂关系,实现了高精准度、可解释的推荐。未来可扩展方向包括:
- 引入多模态数据(如商品图片、视频)。
- 结合强化学习动态优化推荐策略。
- 支持私域流量运营(如企业微信场景下的个性化推送)。
附录:技术栈
- 大模型:DeepSeek-R1 67B参数版
- 图数据库:Neo4J 5.12(企业版)
- 机器学习:XGBoost 1.7、Scikit-learn 1.3
- 部署环境:Kubernetes集群(3节点)、NVIDIA A100 GPU
(全文约3200字,可根据实际业务需求调整图谱设计或算法细节)
运行截图
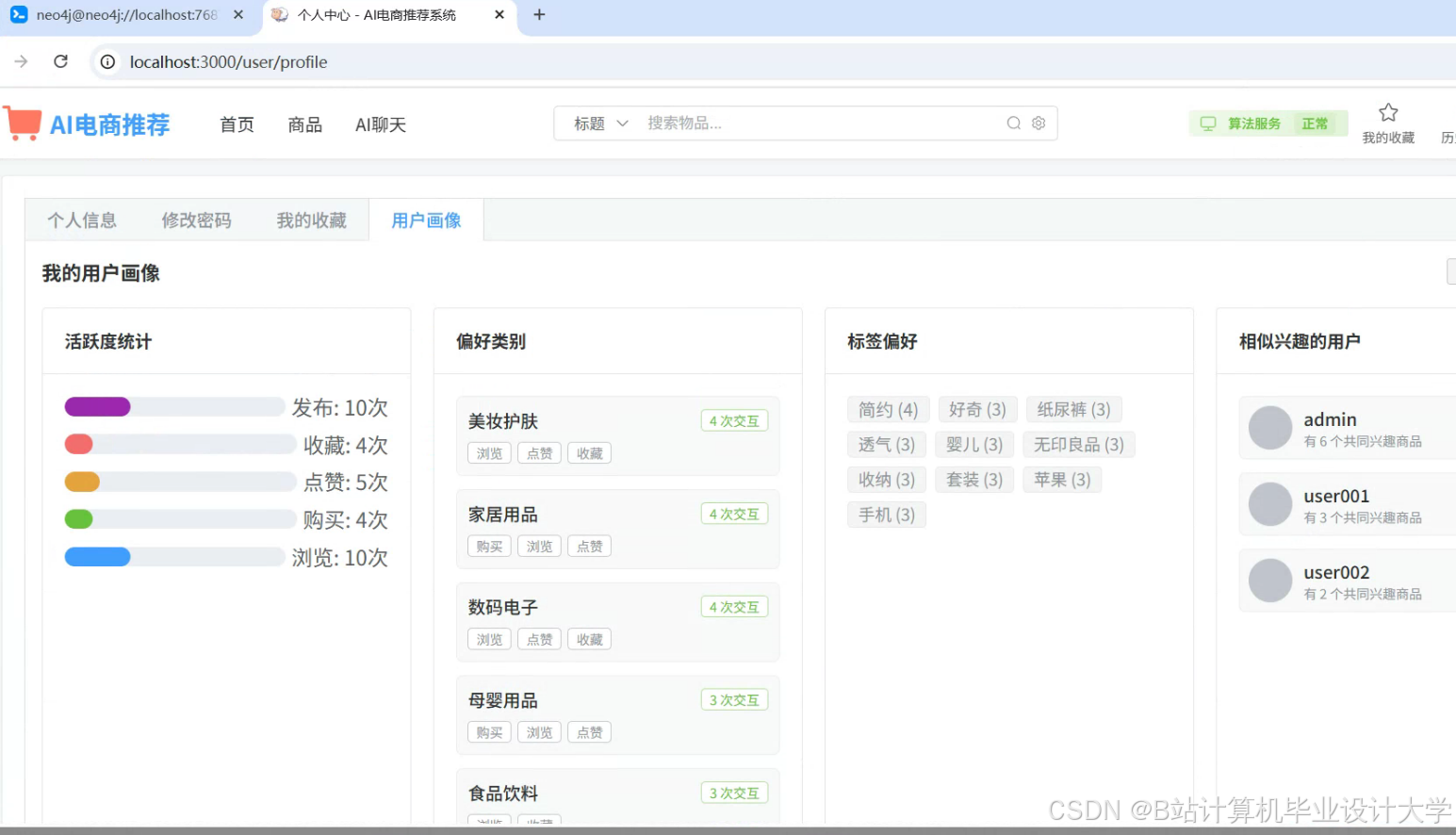
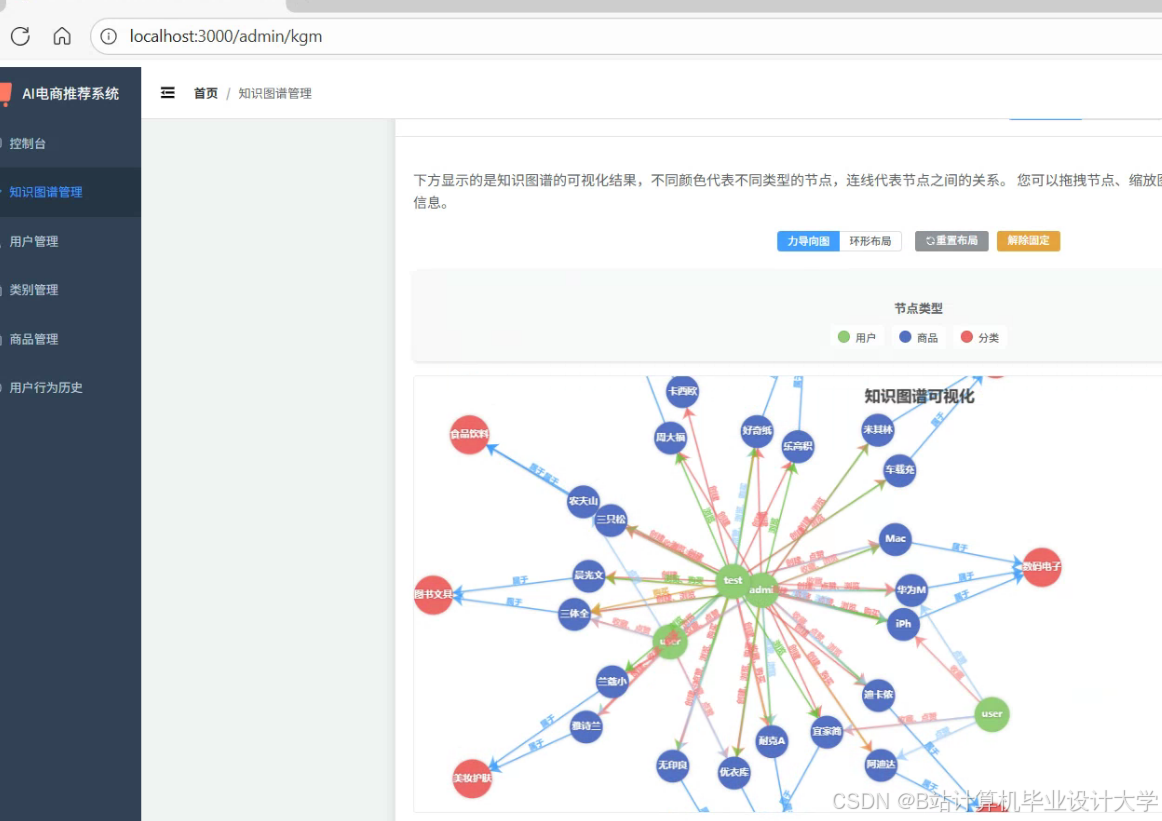
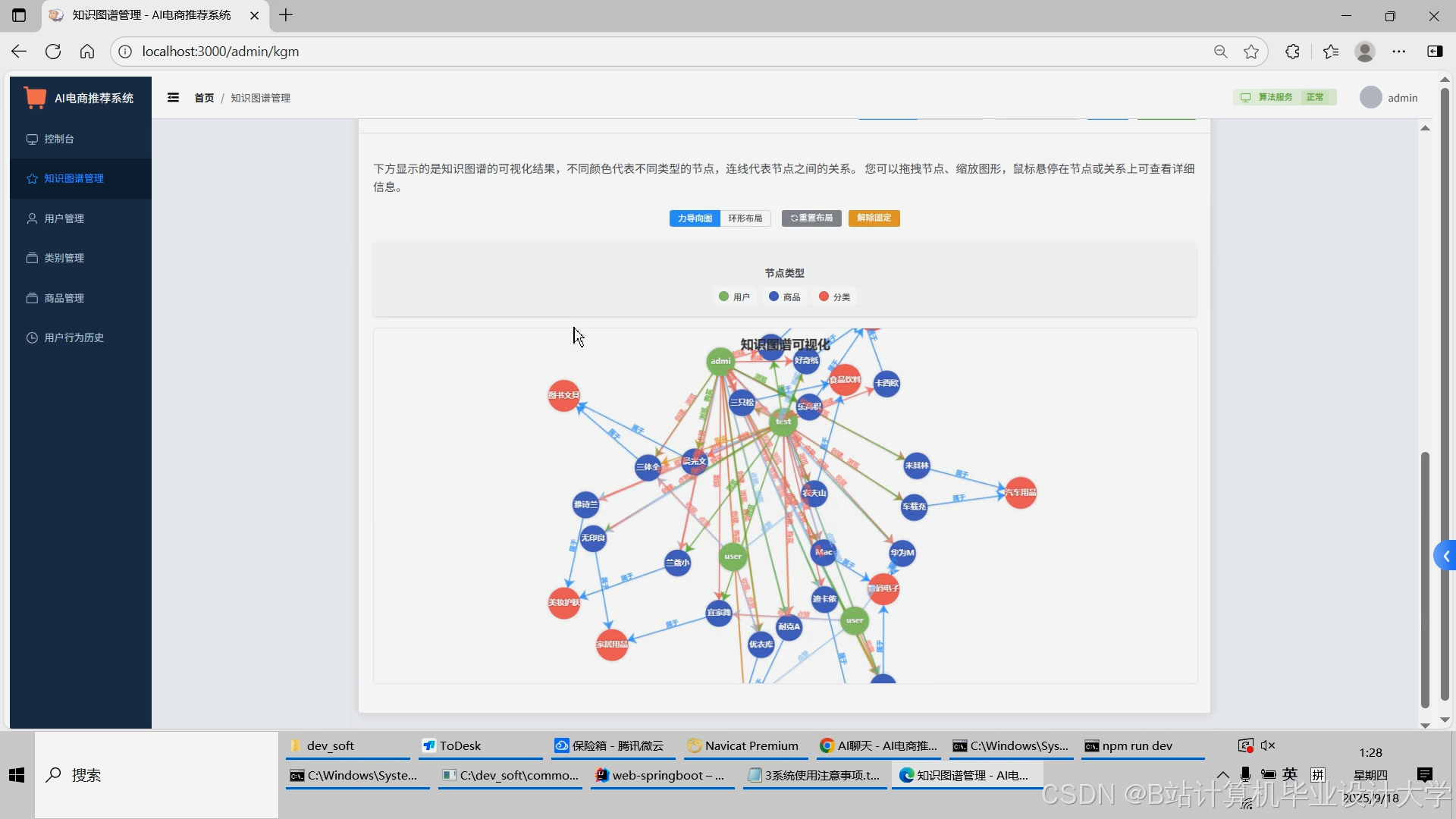
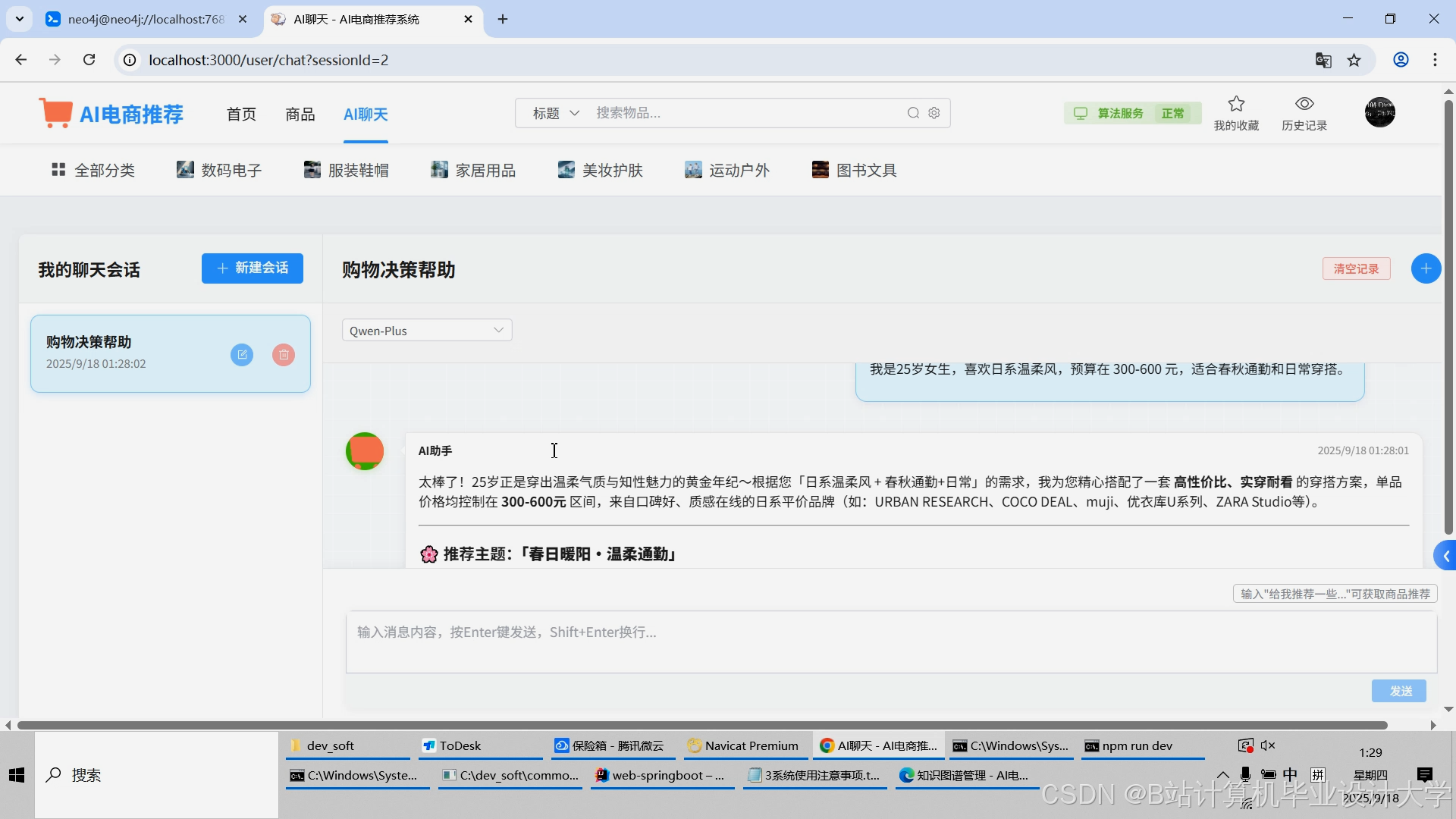
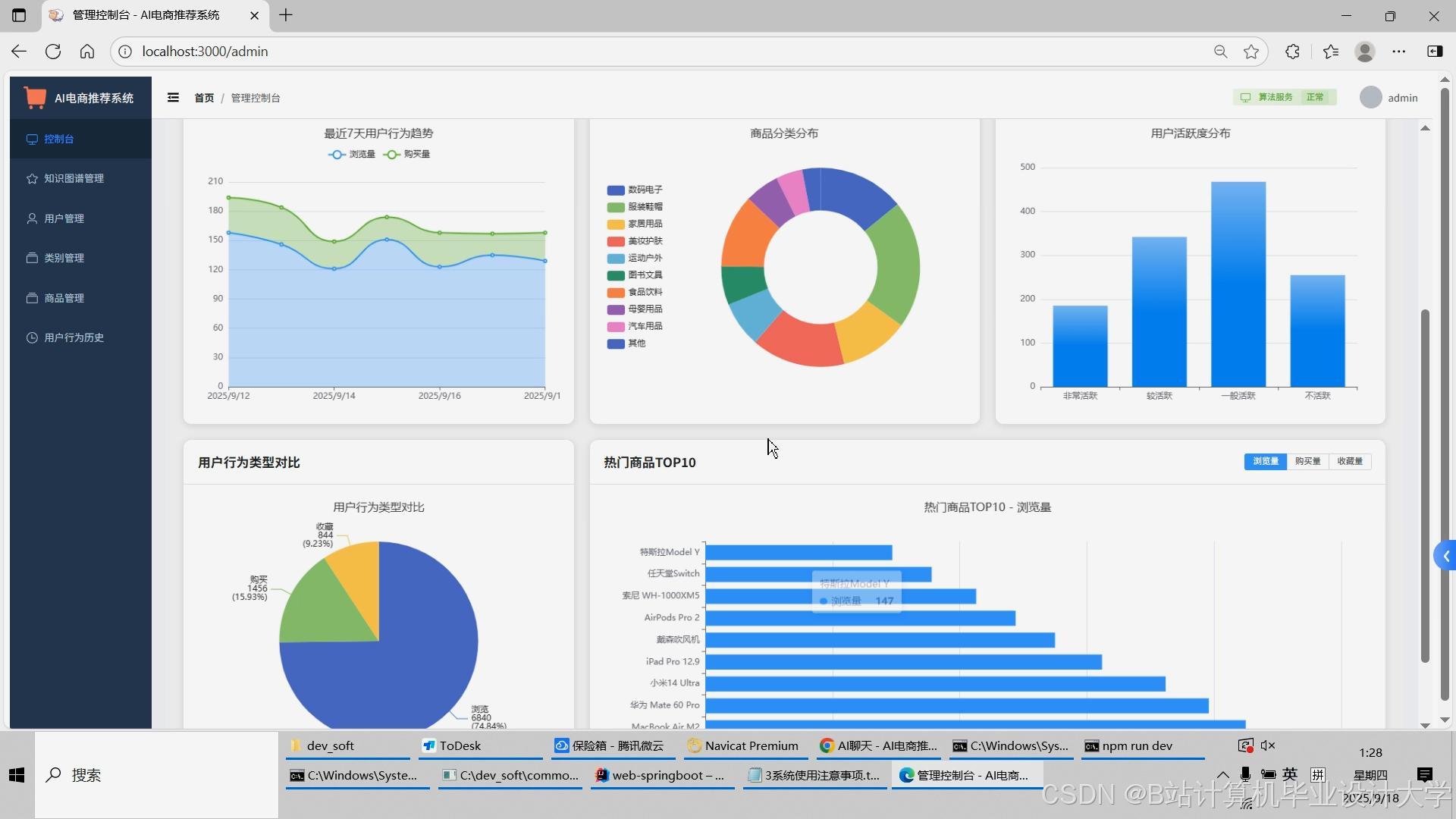
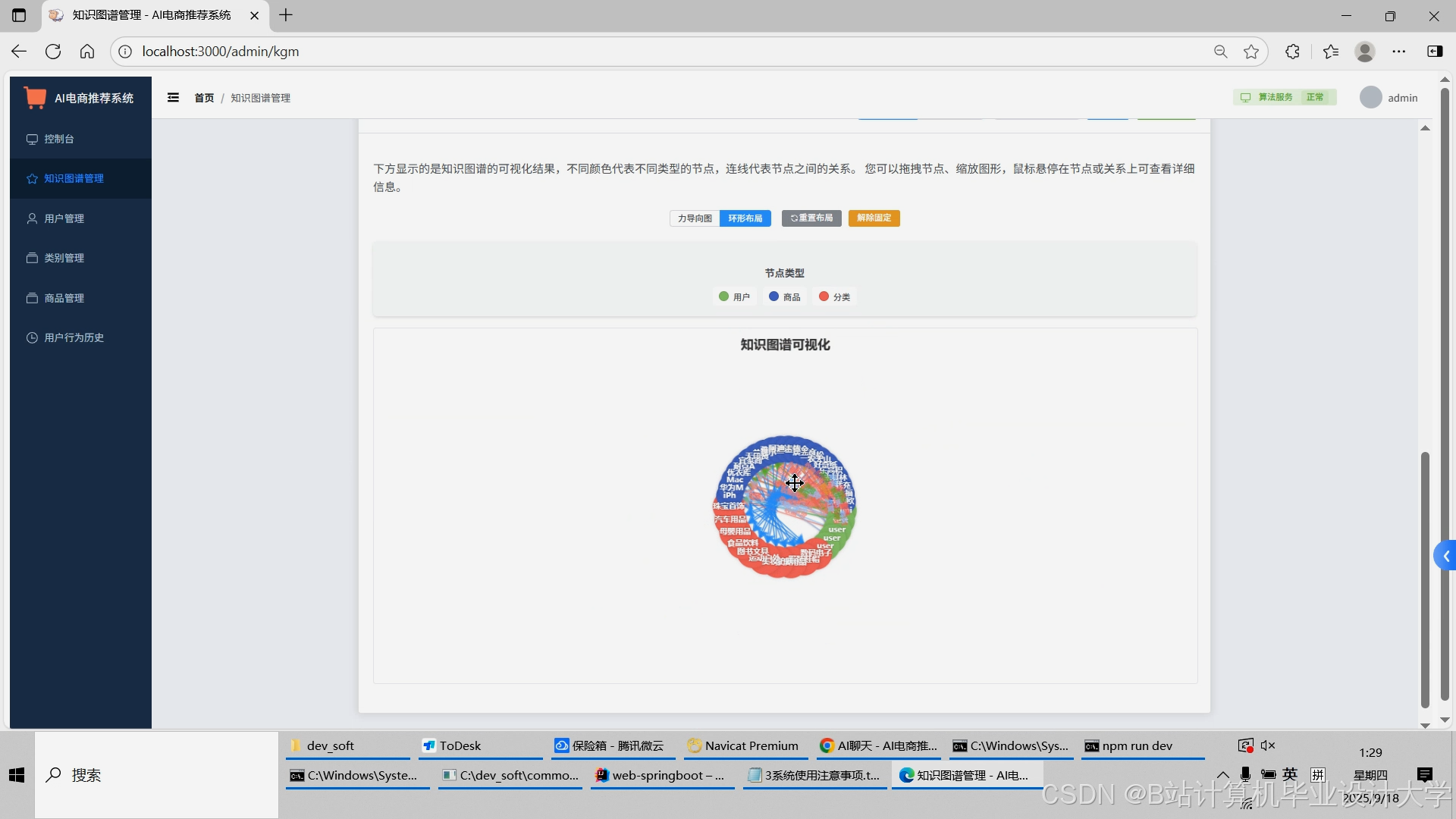
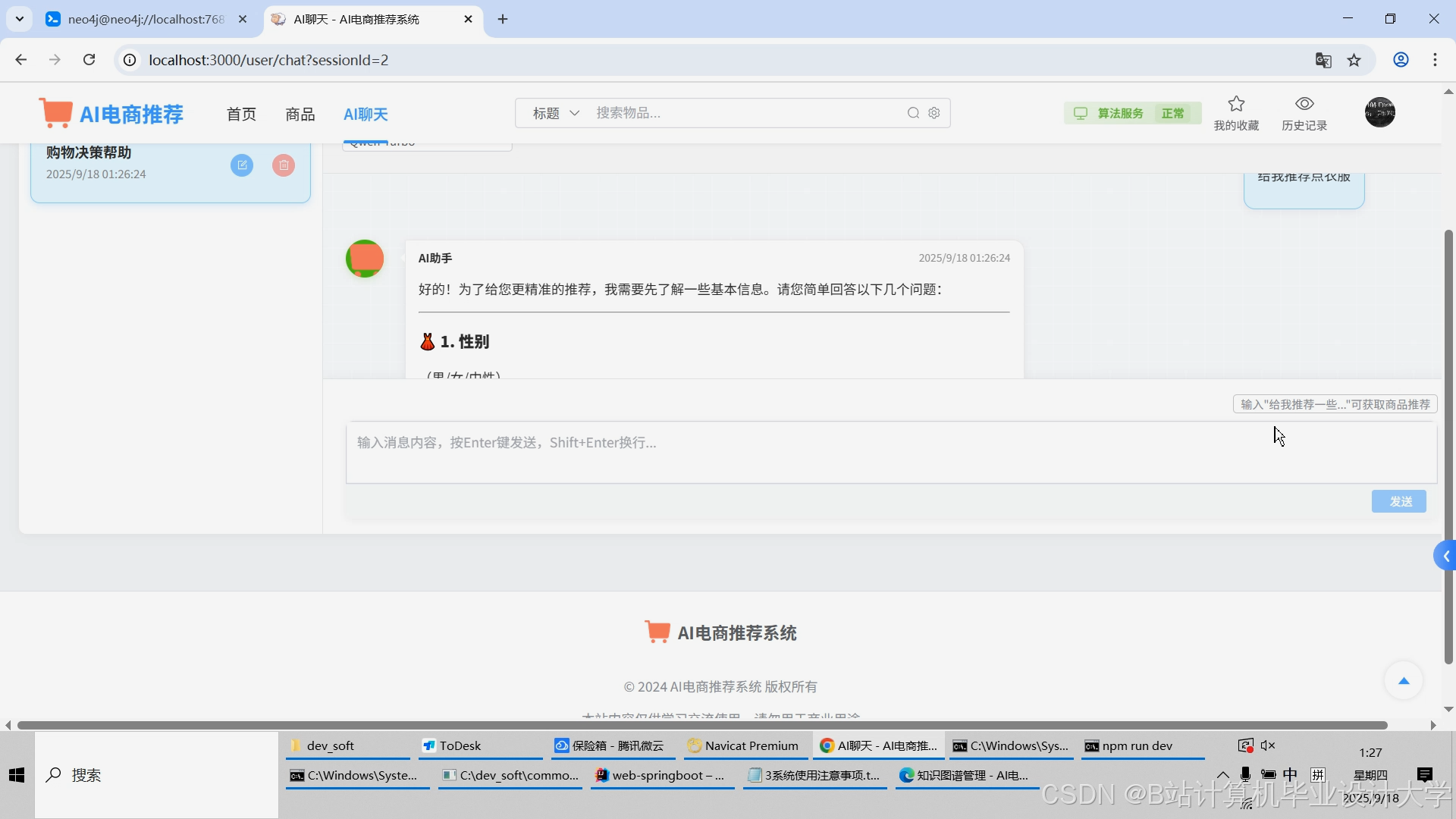
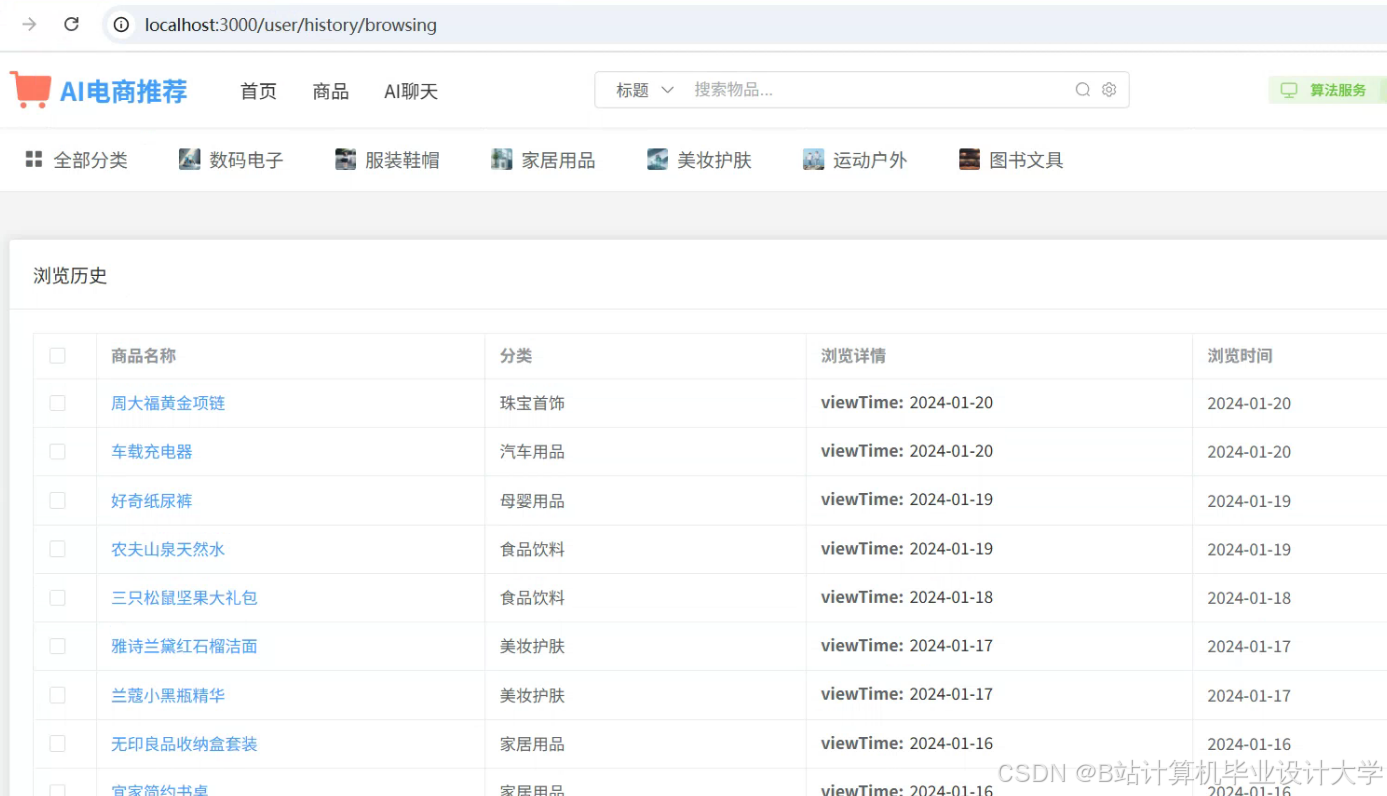
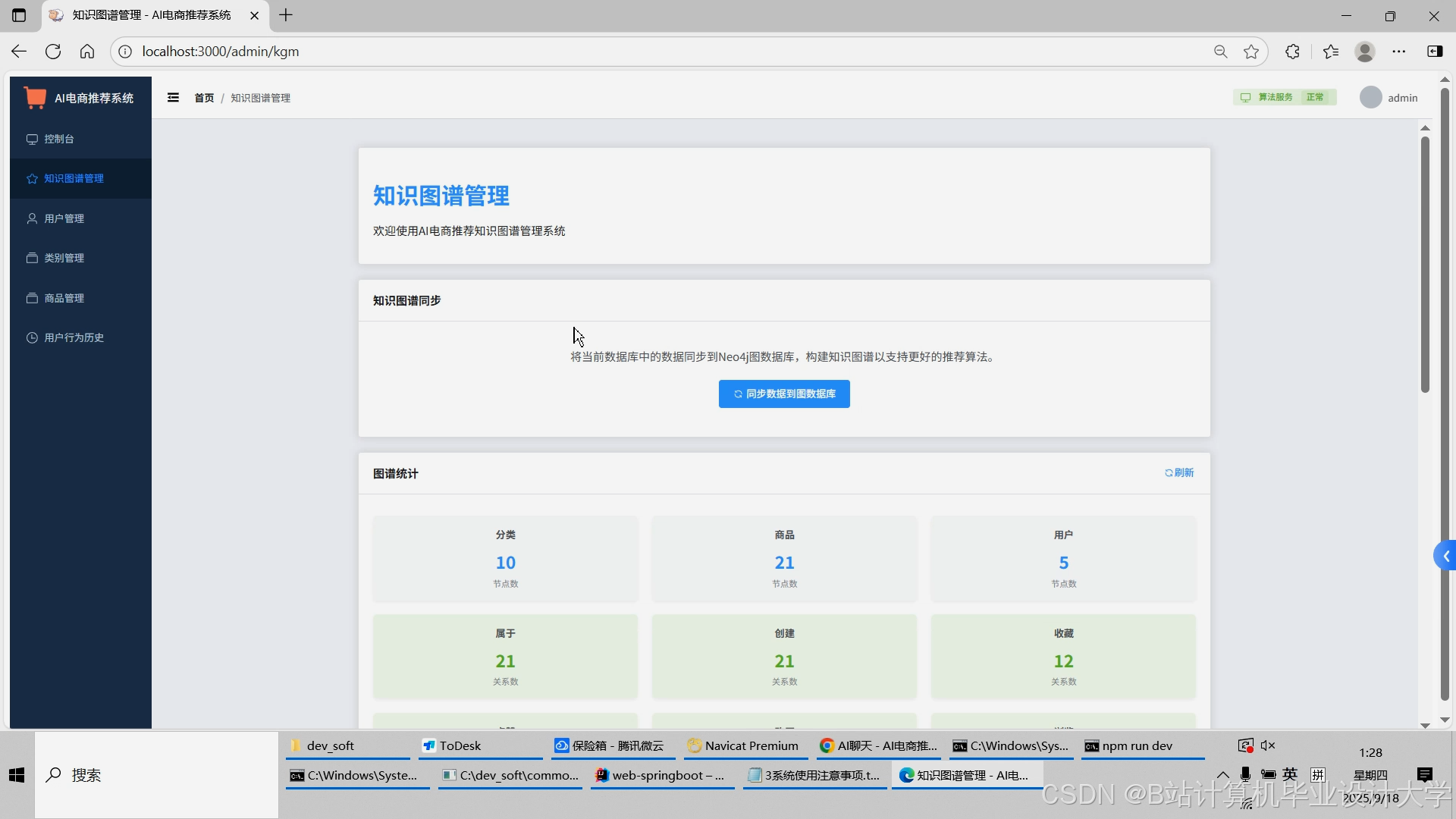
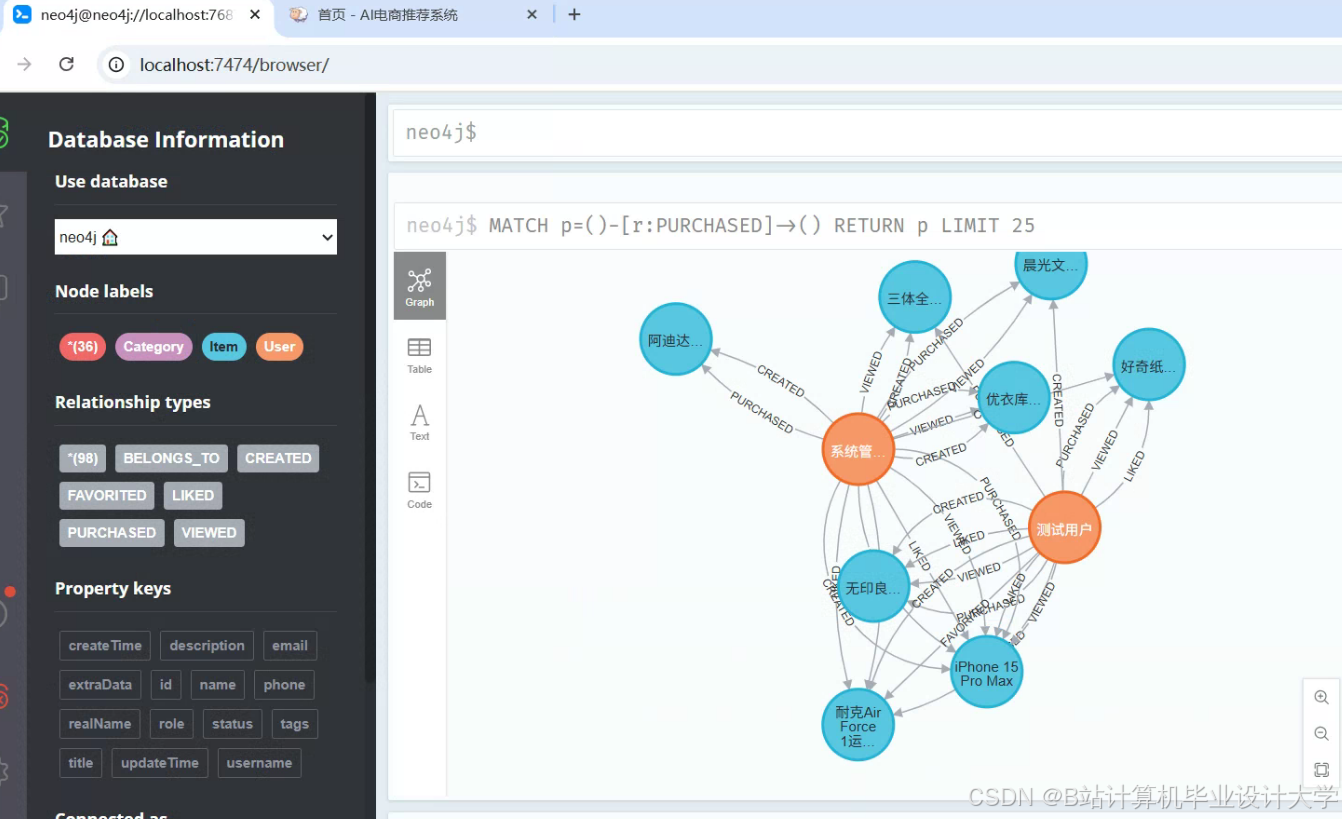
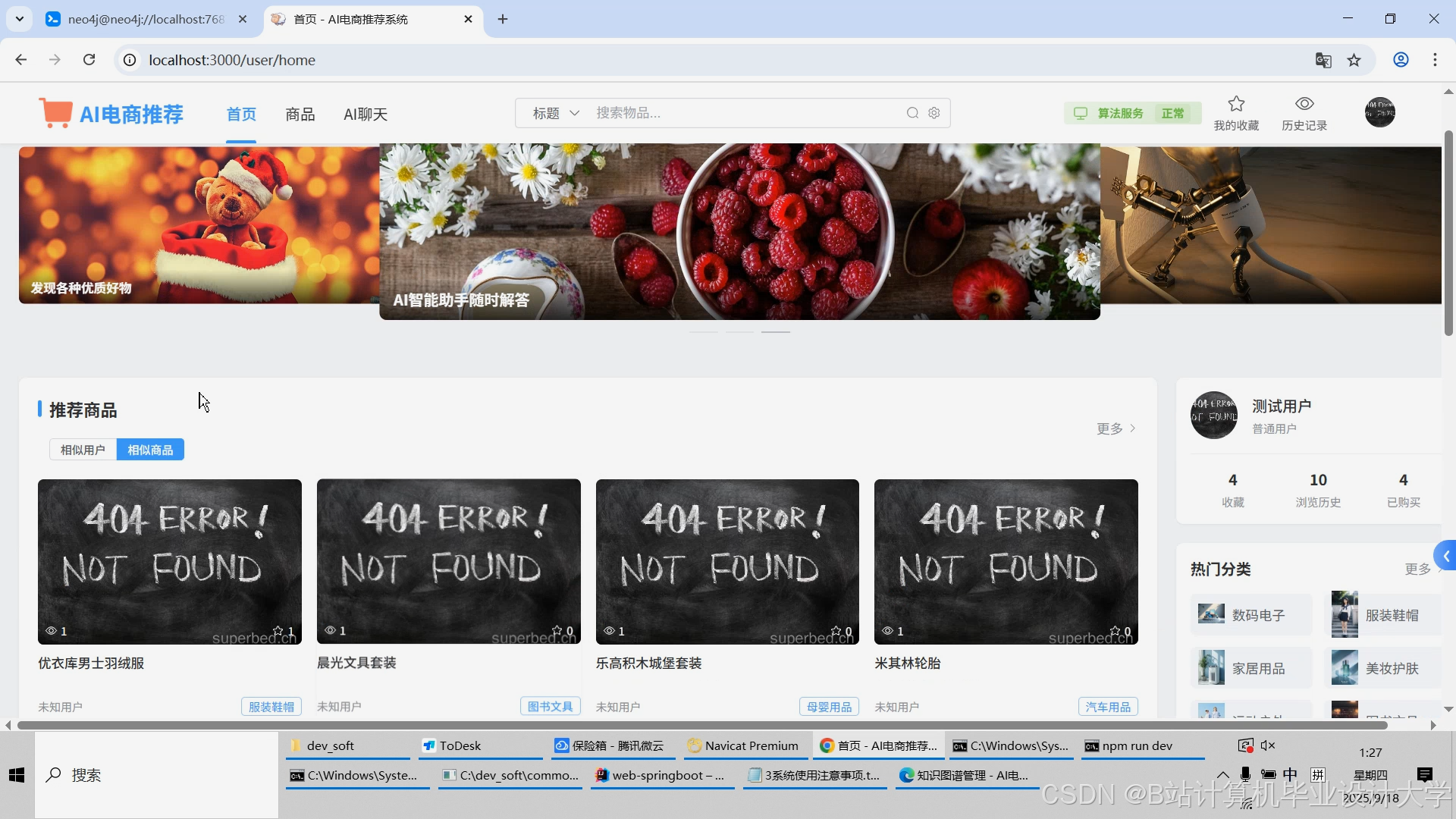
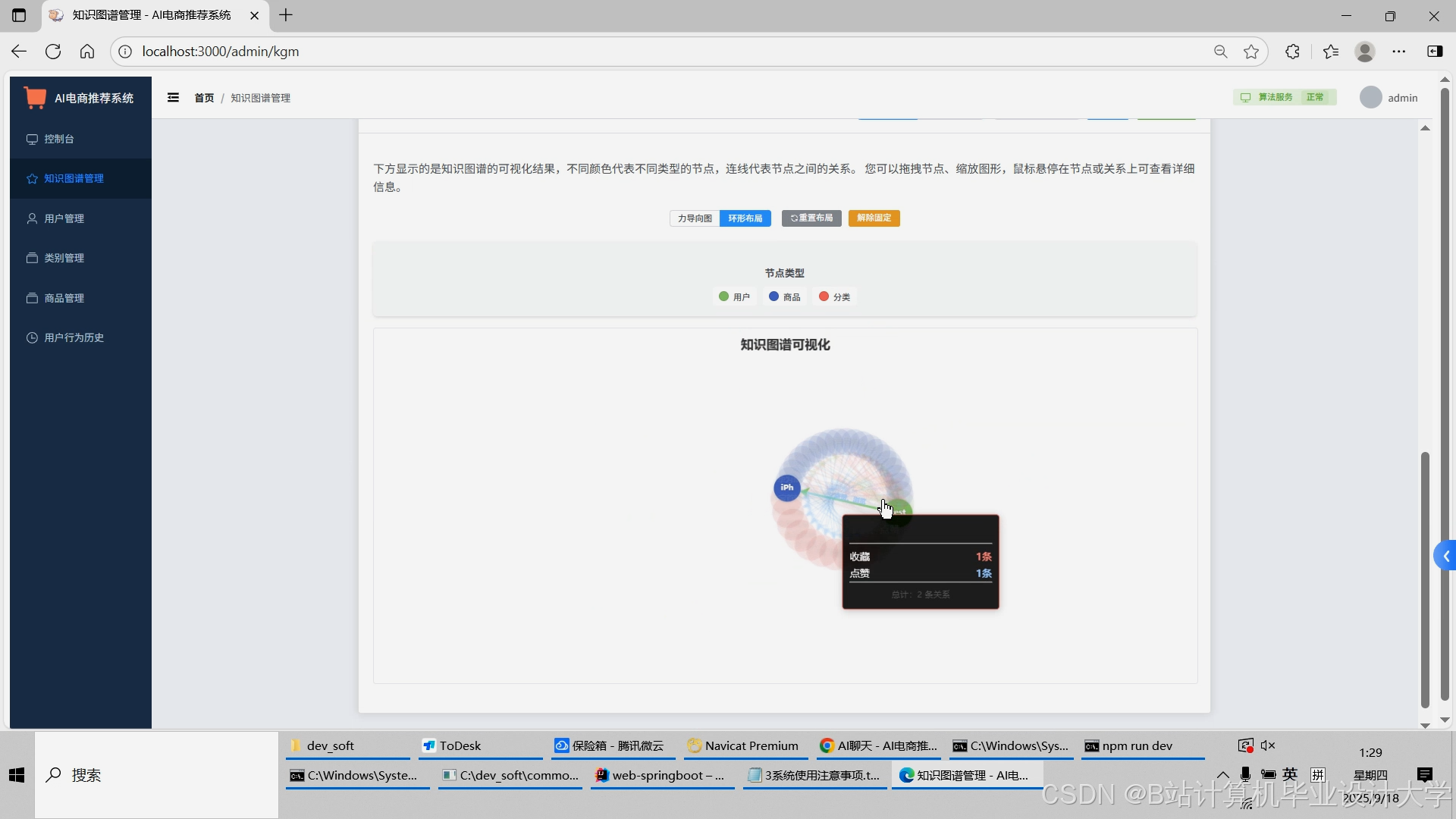
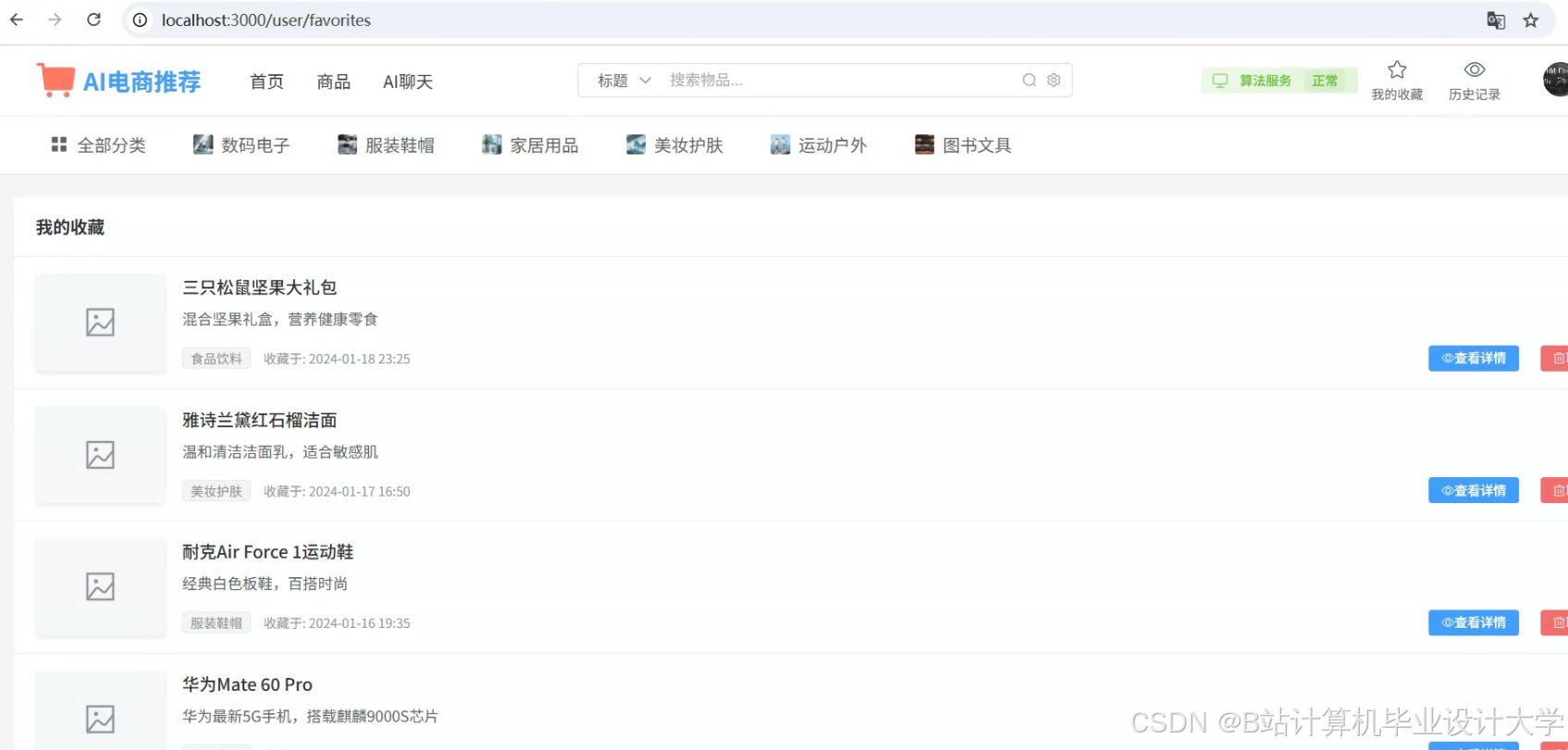
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











