




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Hadoop+Spark+Kafka电影推荐系统》的任务书模板,涵盖系统架构设计、技术选型、模块开发与部署计划:
任务书
项目名称:基于Hadoop+Spark+Kafka的分布式电影推荐系统
项目周期:16周
项目负责人:XXX
团队成员:XXX、XXX、XXX
一、项目背景与目标
1. 背景
- 传统推荐系统痛点:
- 单机处理能力不足:电影数据量庞大(如百万级用户-电影评分矩阵),单机算法(如协同过滤)无法高效处理。
- 实时性差:用户行为(如评分、点击)需实时反馈至推荐模型,传统批处理模式延迟高。
- 系统扩展性弱:新增数据源(如社交网络评论)或算法(如深度学习模型)需重构整个系统。
- 技术选型依据:
- Hadoop:提供分布式存储(HDFS)与资源调度(YARN),支撑海量数据存储与离线计算。
- Spark:基于内存的分布式计算框架,加速迭代算法(如ALS协同过滤),比MapReduce快10-100倍。
- Kafka:高吞吐量消息队列,实现用户行为数据的实时采集与流式处理。
2. 目标
- 功能目标:
- 构建离线+实时混合推荐系统,支持:
- 离线推荐:基于历史数据生成全局推荐模型(每日更新)。
- 实时推荐:根据用户最新行为(如刚评分一部电影)动态调整推荐列表(延迟≤5秒)。
- 提供可视化推荐结果(如Top 10电影列表)与模型评估指标(如RMSE、Precision@K)。
- 构建离线+实时混合推荐系统,支持:
- 性能目标:
- 支持百万级用户与电影数据,推荐响应时间≤1秒(离线)与≤5秒(实时)。
- 系统水平扩展:通过增加节点(如从3台扩展至10台)线性提升吞吐量。
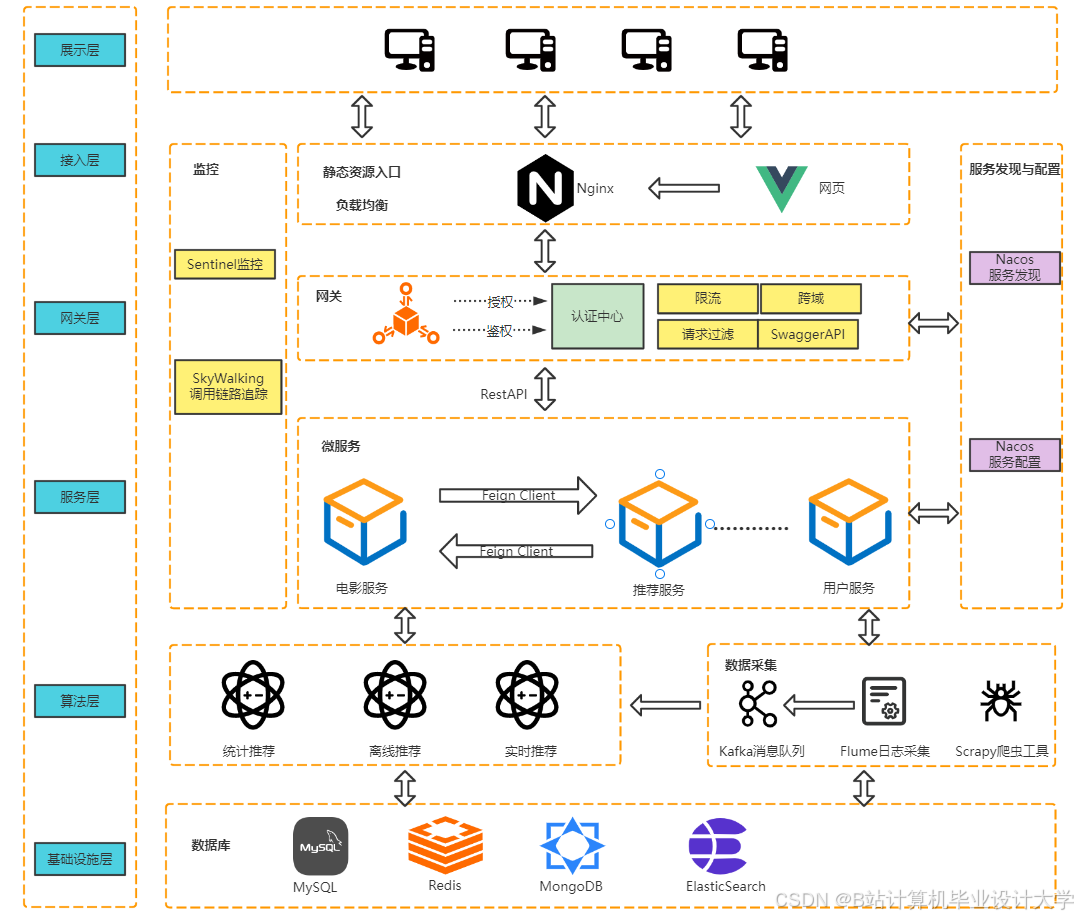
二、系统架构设计
1. 整体架构
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ | |
│ Data │ │ Kafka │ │ Spark │ │ Recommend │ | |
│ Sources │───▶│ Cluster │───▶│ Streaming │───▶│ Results │ | |
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ | |
▲ │ | |
│ ▼ | |
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ | |
│ MySQL │ │ HDFS │ │ Spark MLlib│ │ Redis │ | |
│ (Metadata) │ │ (Raw Data) │ │ (ALS Model) │ │ (Cache) │ | |
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ |
2. 模块说明
- 数据采集层:
- 批数据源:电影元数据(标题、类型、导演)存储于MySQL,用户历史评分数据存储于HDFS(CSV/Parquet格式)。
- 实时数据源:用户实时行为(如评分、点击)通过Kafka生产者(如Flask API)发送至Topic(如
user_actions)。
- 流处理层:
- Spark Streaming消费Kafka消息,更新用户近期行为特征(如最近评分电影列表),触发实时推荐计算。
- 离线计算层:
- Spark on YARN读取HDFS数据,使用ALS算法训练离线推荐模型,保存至HDFS。
- 推荐服务层:
- 离线结果存入Redis缓存,实时推荐通过Spark Streaming直接返回结果,前端通过REST API(如Flask)调用。
三、项目任务分解
模块1:环境搭建与数据准备(Hadoop+Spark+Kafka集群)
- 任务内容
- 集群部署:
- 使用3台虚拟机(或云服务器)搭建Hadoop集群(1 NameNode + 2 DataNodes)。
- 部署Spark on YARN(1 Master + 2 Workers),配置与Hadoop集成。
- 部署Kafka集群(1 Broker + Zookeeper),创建Topic(如
user_actions,分区数=3)。
- 数据准备:
- 从MovieLens数据集(如
ml-latest-small)加载以下数据至HDFS:movies.csv:电影ID、标题、类型。ratings.csv:用户ID、电影ID、评分、时间戳。
- 初始化MySQL数据库,存储电影元数据(便于快速查询电影详情)。
- 从MovieLens数据集(如
- 集群部署:
- 技术工具
- 集群管理:Ambari/Cloudera Manager(可选)
- 数据加载:
hdfs dfs -put、spark-submit
模块2:离线推荐模型开发(Spark MLlib + ALS算法)
- 任务内容
- 数据预处理:
- 使用Spark SQL过滤异常评分(如评分<1或>5),按用户分组统计评分次数(剔除冷启动用户)。
- 将评分数据转换为Spark RDD格式:
(user_id, (movie_id, rating))。
- ALS模型训练:
- 设置参数:
rank=10(潜在因子数)、maxIter=10(迭代次数)、regParam=0.01(正则化系数)。 - 训练模型并保存至HDFS:
scalaimport org.apache.spark.mllib.recommendation.ALSval model = ALS.train(ratingsRDD, rank, numIterations, lambda)model.save(sc, "hdfs://namenode:8020/models/als_model")
- 设置参数:
- 离线推荐生成:
- 对每个用户预测其对所有未评分电影的评分,取Top 10生成推荐列表,存储至Redis:
scalaval userRecs = model.recommendProductsForUsers(10) // 每个用户推荐10部电影userRecs.foreach { case (userId, recs) =>redis.rpush(s"user:$userId:recommendations", recs.map(_.product).mkString(","))}
- 对每个用户预测其对所有未评分电影的评分,取Top 10生成推荐列表,存储至Redis:
- 数据预处理:
- 技术工具
- 机器学习库:Spark MLlib(ALS算法)
- 缓存:Redis(存储推荐结果)
模块3:实时推荐系统开发(Spark Streaming + Kafka)
- 任务内容
- Kafka消息消费:
- 配置Spark Streaming消费
user_actionsTopic,解析JSON格式消息:json{"user_id": 123, "movie_id": 456, "rating": 5, "timestamp": 1630000000}
- 配置Spark Streaming消费
- 实时特征更新:
- 维护用户近期行为窗口(如最近5部评分电影),存储于Spark的
map结构中。
- 维护用户近期行为窗口(如最近5部评分电影),存储于Spark的
- 实时推荐计算:
- 结合离线模型与实时特征,调整推荐权重(如用户刚评分一部科幻电影,临时提升科幻类电影推荐优先级)。
- 返回实时推荐结果至前端API:
scalaval realTimeRecs = ... // 结合离线+实时特征计算realTimeRecs.foreach { case (userId, recs) =>HTTP.post("http://api.example.com/recommend", recs)}
- Kafka消息消费:
- 技术工具
- 流处理:Spark Streaming(DStream API)
- 消息队列:Kafka(高吞吐量消息传递)
模块4:推荐结果可视化与API服务(Flask + ECharts)
- 任务内容
- 后端API:
- 使用Flask提供REST接口:
GET /recommend/<user_id>:返回用户推荐列表(JSON格式)。GET /movie/<movie_id>:返回电影详情(从MySQL查询)。
- 使用Flask提供REST接口:
- 前端可视化:
- 使用ECharts展示推荐电影的评分分布(柱状图)、类型占比(饼图)。
- 示例代码:
javascript// 展示推荐电影评分分布const chart = echarts.init(document.getElementById('chart'));chart.setOption({xAxis: { type: 'category', data: ['1星', '2星', '3星', '4星', '5星'] },yAxis: { type: 'value' },series: [{ data: [5, 10, 20, 30, 35], type: 'bar' }]});
- 后端API:
- 技术工具
- Web框架:Flask(轻量级API服务)
- 可视化库:ECharts(交互式图表)
模块5:系统测试与优化
- 任务内容
- 功能测试:
- 验证离线推荐是否覆盖所有用户,实时推荐是否响应最新行为。
- 性能测试:
- 使用JMeter模拟1000并发用户请求,测试推荐API的QPS(Queries Per Second)与延迟。
- 优化方案:
- 数据倾斜:对热门电影评分数据单独分区(如使用
repartition())。 - 缓存优化:将电影元数据缓存至Spark内存(
broadcast variables)。
- 数据倾斜:对热门电影评分数据单独分区(如使用
- 功能测试:
- 技术工具
- 性能测试:JMeter、Spark UI(监控任务执行情况)
四、时间计划
| 阶段 | 时间 | 任务 |
|---|---|---|
| 环境搭建 | 第1-2周 | 部署Hadoop/Spark/Kafka集群,加载初始数据至HDFS与MySQL |
| 离线推荐开发 | 第3-6周 | 实现ALS模型训练与离线推荐生成,评估RMSE指标(目标≤0.85) |
| 实时推荐开发 | 第7-9周 | 开发Spark Streaming消费Kafka消息,实现实时特征更新与推荐计算 |
| API与可视化开发 | 第10-11周 | 开发Flask API与ECharts前端,集成离线+实时推荐结果 |
| 测试与优化 | 第12-14周 | 进行全链路压力测试,优化数据倾斜与缓存策略 |
| 文档撰写与部署 | 第15-16周 | 编写技术文档(架构图、API说明、部署指南),部署至生产环境(可选云服务) |
五、预期成果
- 完成分布式电影推荐系统,支持离线(每日更新)与实时(≤5秒延迟)推荐模式。
- 推荐准确率:离线模型RMSE≤0.85,实时推荐Precision@10≥30%(基于MovieLens测试集)。
- 提交项目文档(技术报告、用户手册、测试报告、GitHub代码仓库链接)。
六、风险评估与应对
- Kafka消息丢失:
- 应对:设置
acks=all(生产者等待所有副本确认)与replication.factor=3(副本数)。
- 应对:设置
- Spark内存溢出:
- 应对:调整
spark.executor.memory(如从2G增至4G),优化RDD缓存策略(MEMORY_ONLY_SER)。
- 应对:调整
- 数据冷启动:
- 应对:对新用户默认推荐热门电影(基于全局评分排序),积累行为数据后切换至个性化推荐。
项目负责人签字:________________
日期:________________
此任务书可根据实际数据规模(如千万级用户)调整集群规模与算法参数,建议优先实现离线推荐核心功能,再逐步扩展实时模块与可视化界面。
运行截图
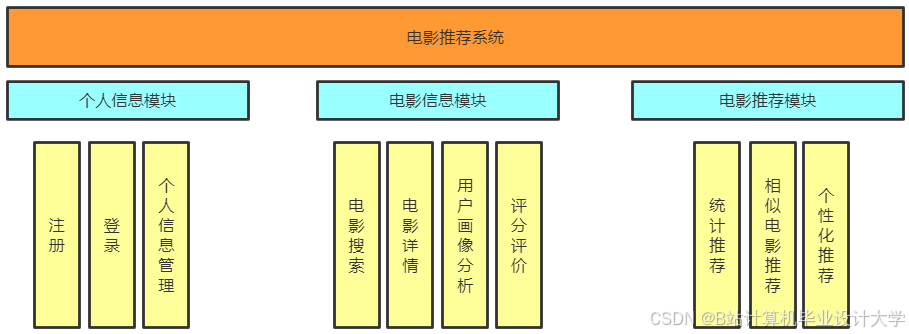
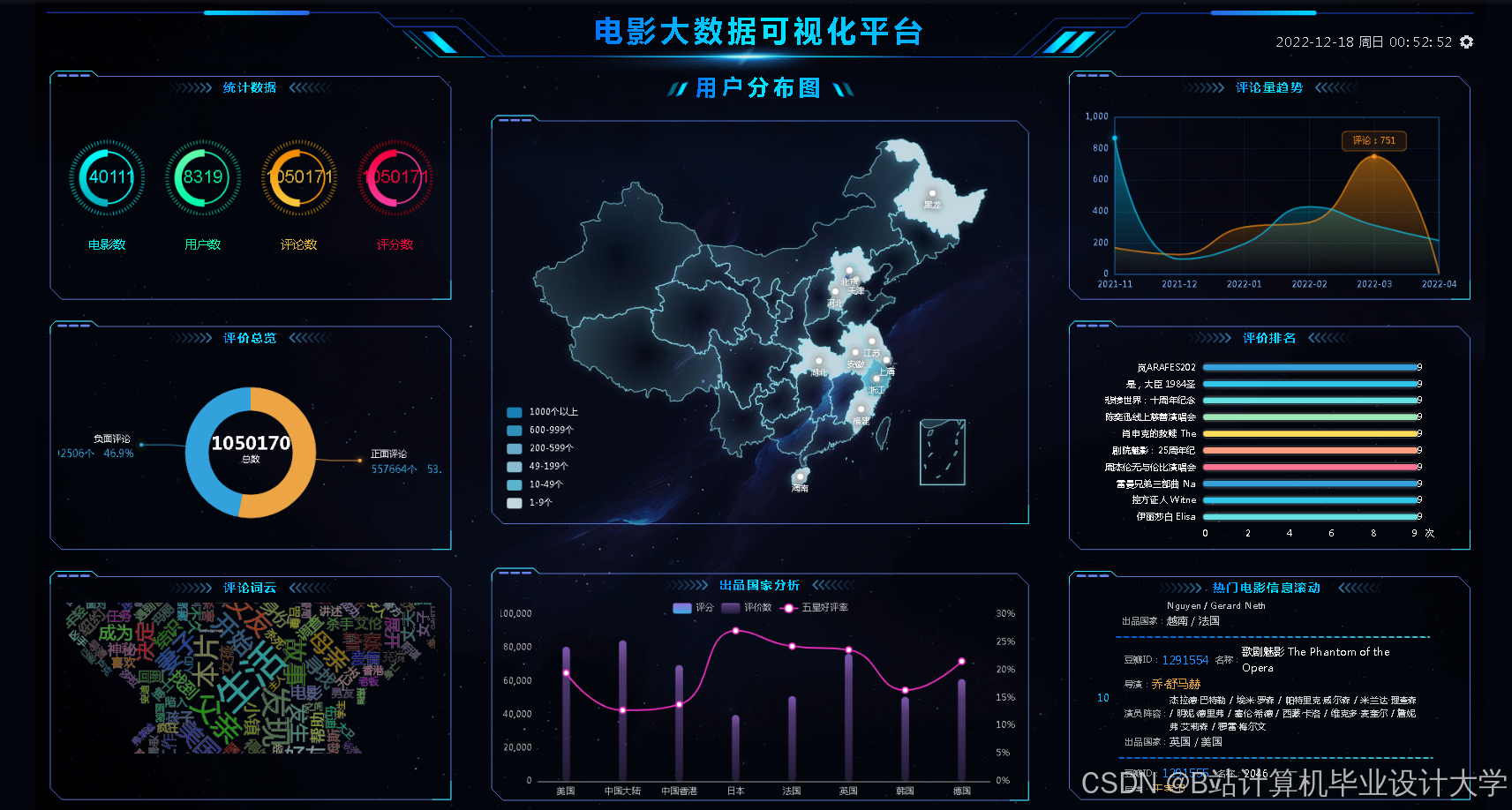
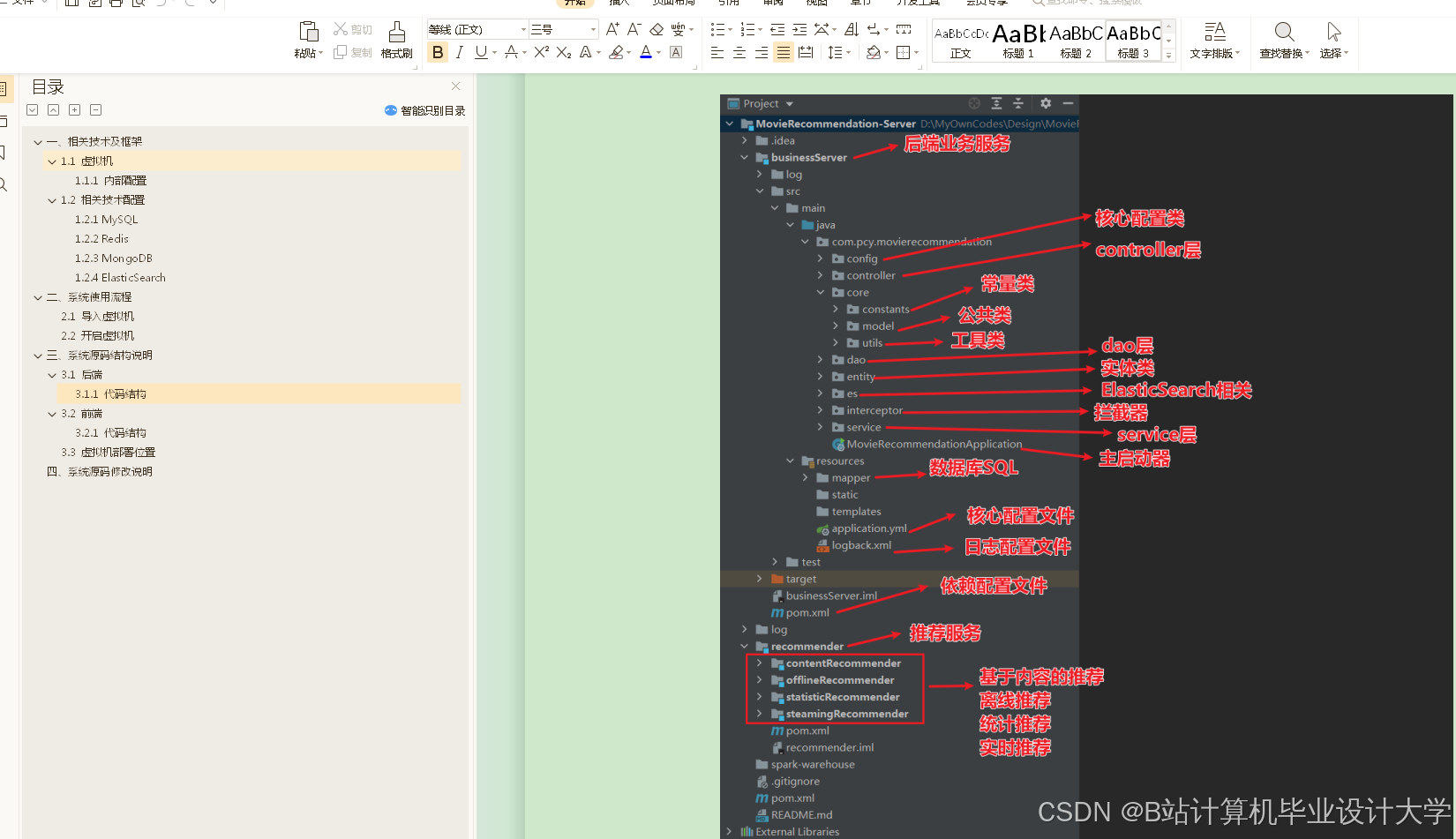
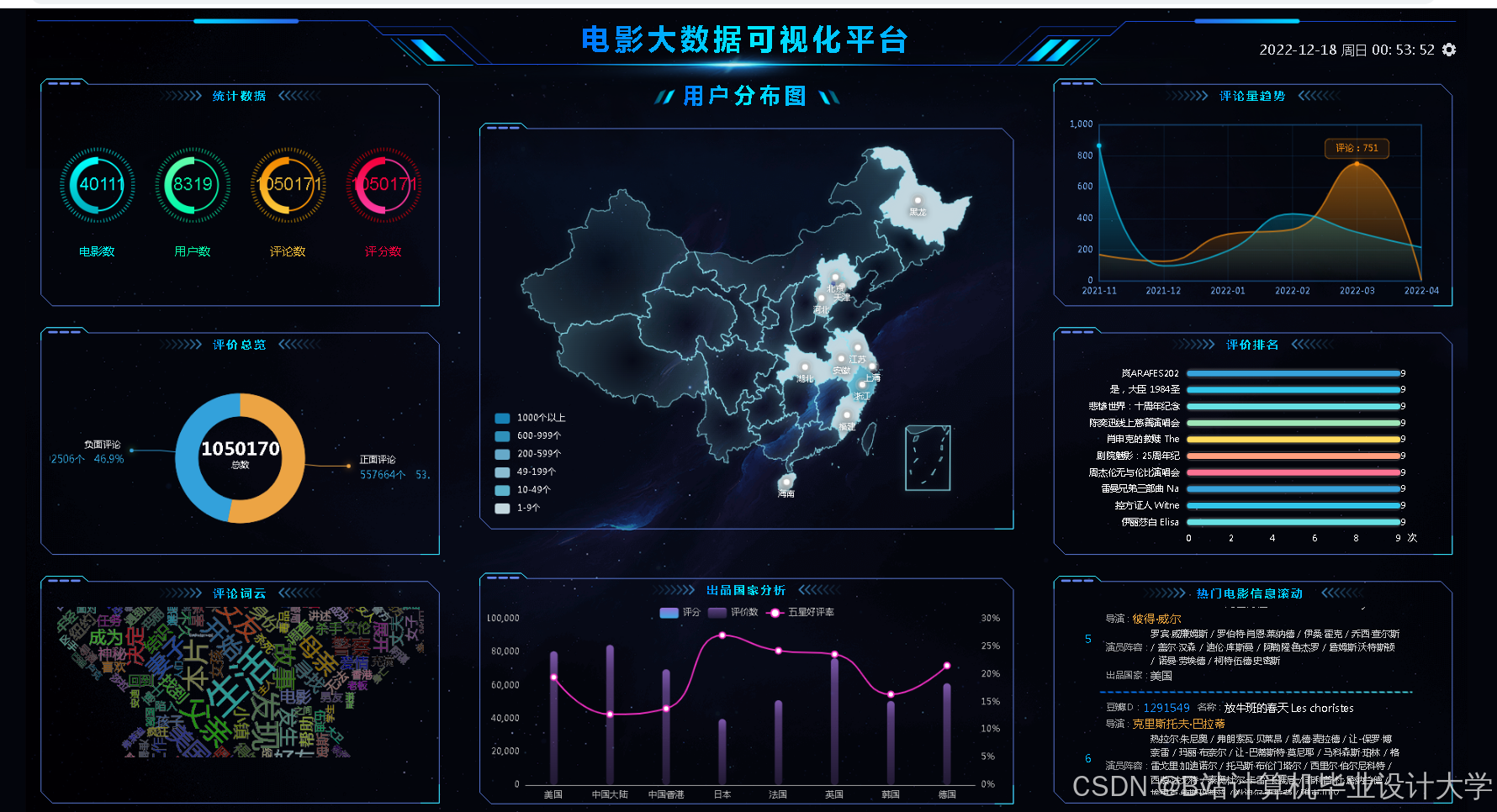


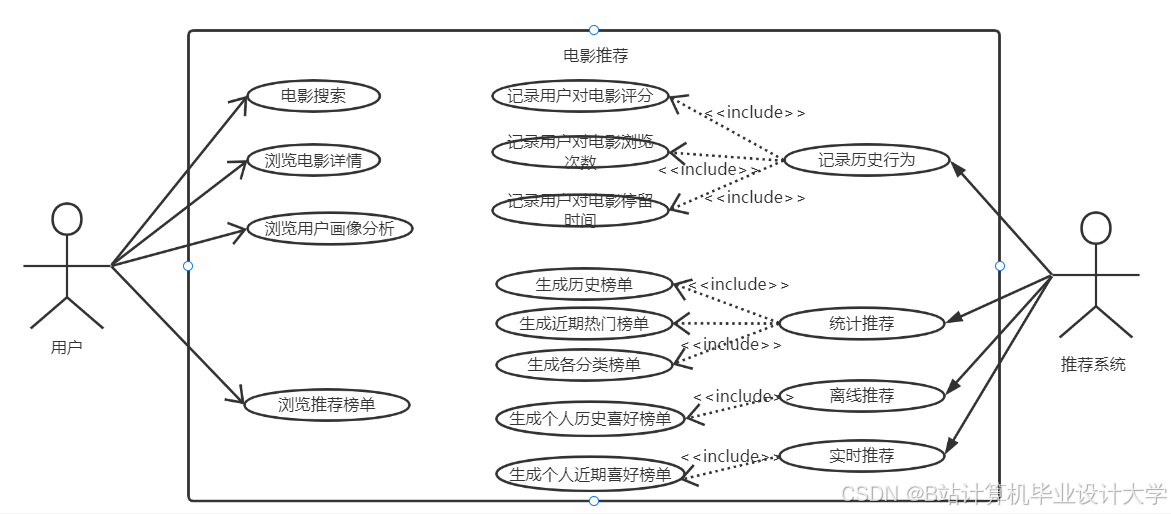
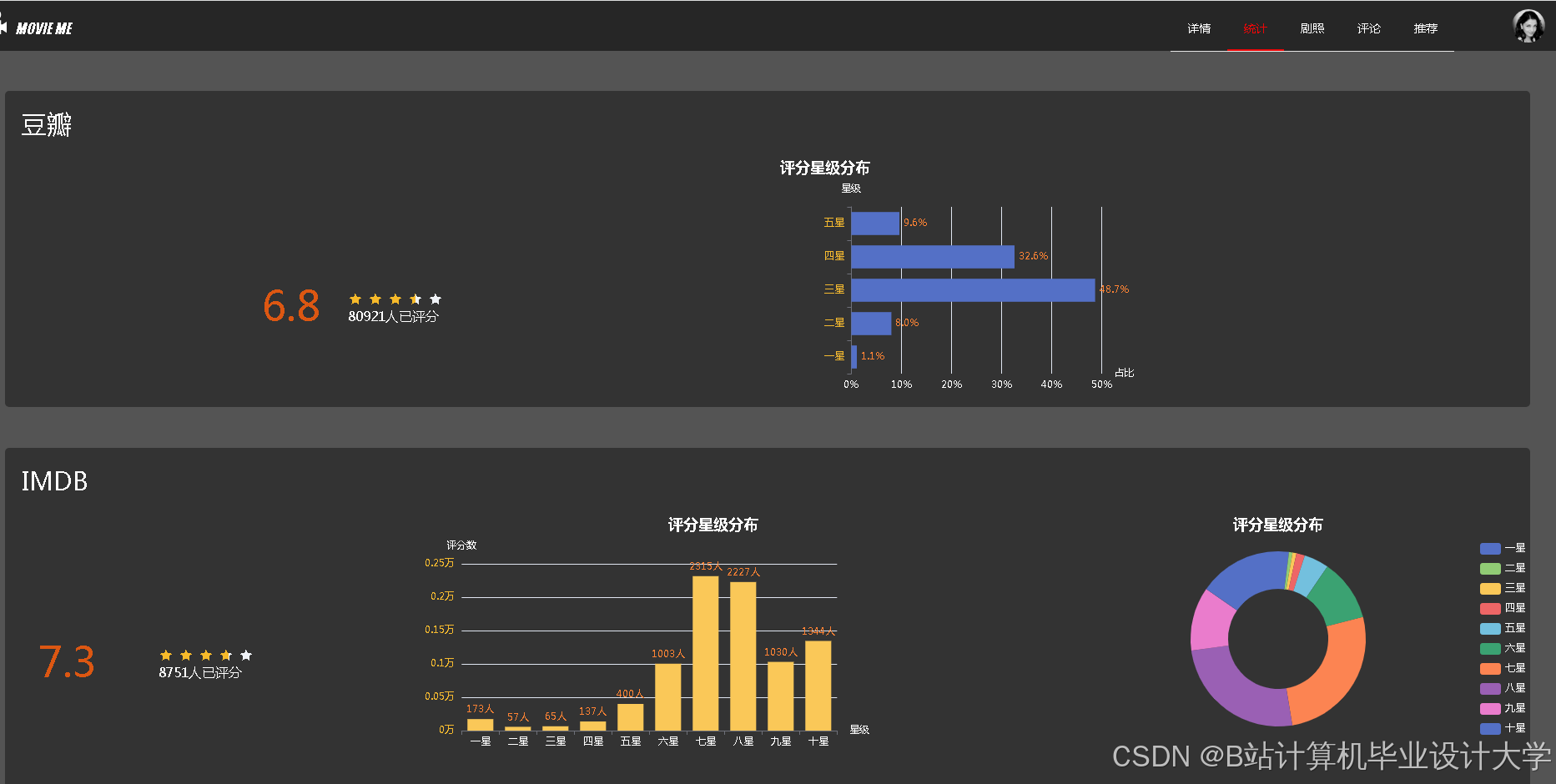
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











