




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
PyFlink+PySpark+Hadoop+Hive旅游景点推荐系统技术说明
一、引言
全球旅游市场规模已突破7万亿美元,用户决策周期缩短至3-7天,但传统推荐系统面临三大核心挑战:
- 多源异构数据融合:用户行为(搜索、预订、评价)、景点特征(地理坐标、票价、开放时间)、实时天气/交通等数据分散在不同系统;
- 时空动态性:用户兴趣随季节(如冬季滑雪)、地理位置(如抵达景区后推荐周边景点)快速变化;
- 冷启动与长尾问题:新景点缺乏历史数据,小众景点难以被推荐。
本系统基于PyFlink(实时流处理)+ PySpark(批量计算)+ Hadoop(存储)+ Hive(分析)技术栈构建,通过统一数据湖存储多源数据、实时计算用户时空兴趣、融合协同过滤与知识图谱模型,实现个性化推荐(准确率提升35%),并支持新景点冷启动推荐(覆盖率达90%)。
二、系统架构设计
系统采用“批流一体”架构,涵盖数据采集、存储、处理、推荐与可视化全流程:
1. 数据采集层
(1)实时数据采集
- 用户行为流:通过Flume+Kafka采集APP/网页用户行为日志(JSON格式),包括:
- 搜索行为:用户ID、关键词(如“北京周边滑雪”)、时间戳;
- 预订行为:用户ID、景点ID、入住/离店日期、同行人数;
- 定位数据:用户GPS坐标(每5分钟上报一次,用于实时周边推荐)。
Kafka配置:分区数=CPU核心数×2(如16分区),副本因子=3,支持每秒5万条消息写入,延迟<50ms。
- 外部实时数据:调用天气API(如OpenWeatherMap)和交通API(如高德实时路况),获取景点所在城市的天气(温度、降水概率)和周边交通拥堵指数,每10分钟更新一次。
(2)批量数据采集
- 景点元数据:从OTA平台(如携程、飞猪)定期爬取景点信息(CSV格式),包括:
- 基础信息:景点ID、名称、类别(如自然风光、历史古迹)、票价、开放时间;
- 地理信息:经纬度坐标、所属城市、周边5公里内景点ID列表;
- 多模态特征:图片(提取颜色直方图)、文本描述(TF-IDF向量)。
- 用户画像数据:从CRM系统导出用户注册信息(如年龄、性别、常住地)和历史行为(如过去1年预订记录),用于冷启动推荐。
2. 数据存储层
(1)分布式存储(Hadoop HDFS)
- 原始数据(JSON/CSV)按日期分区存储(如
/data/tourism/2025-09-20/),配置块大小256MB、副本因子3,支持PB级数据扩展。 - 示例目录结构:
/data/tourism/├── raw/ # 原始日志│ ├── user_behavior/ # 用户行为日志│ └── external_data/ # 天气/交通数据└── processed/ # 处理后数据├── hive/ # Hive表存储└── parquet/ # Parquet格式优化查询
(2)数据仓库(Hive)
- 构建分层表结构(ODS→DWD→DWS→ADS),采用Parquet列式存储+Snappy压缩,减少存储空间50%,提升查询速度3倍。
sql-- ODS层:原始用户行为表CREATE TABLE ods_user_behavior (user_id STRING, action_type STRING, item_id STRING,keywords STRING, timestamp BIGINT, duration INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';-- DWD层:清洗后的用户行为事实表CREATE TABLE dwd_user_behavior (user_id STRING, action_type STRING, item_id STRING,event_time TIMESTAMP, duration INT,geo_location STRING -- 用户GPS坐标(如"39.9042,116.4074")) PARTITIONED BY (dt STRING) STORED AS PARQUET;-- DWS层:用户画像汇总表CREATE TABLE dws_user_profile (user_id STRING, age INT, gender STRING,preferred_categories ARRAY<STRING>, -- 偏好类别(如["自然风光","历史古迹"])avg_budget DECIMAL(10,2) -- 平均预算) STORED AS ORC;
(3)缓存与索引(Redis + Elasticsearch)
- Redis:缓存热门景点ID列表(Top 500)、用户实时兴趣标签(如“滑雪”),加速推荐结果返回。
- Elasticsearch:为景点名称、描述建立全文索引,支持模糊搜索(如用户输入“北雪”推荐“北京雪乡”)。
3. 数据处理层
(1)实时处理(PyFlink + Kafka)
-
用户时空兴趣计算:消费Kafka中的用户行为和定位数据,按用户ID分组计算实时兴趣权重(如搜索“滑雪”+2、定位在滑雪场周边+3),更新Redis中的用户画像。
python# PyFlink实时处理用户行为并更新兴趣画像from pyflink.datastream import StreamExecutionEnvironmentfrom pyflink.datastream.connectors.kafka import FlinkKafkaConsumerfrom pyflink.common.serialization import SimpleStringSchemaenv = StreamExecutionEnvironment.get_execution_environment()kafka_consumer = FlinkKafkaConsumer(topics=['user_behavior'],deserialization_schema=SimpleStringSchema(),properties={'bootstrap.servers': 'kafka:9092'})def parse_behavior(line):import jsondata = json.loads(line)return (data['user_id'], (data['item_id'], data['action_type'], data['geo_location']))def update_interest(user_id, behaviors):interests = {}for item_id, action_type, geo_location in behaviors:# 根据行为类型和地理位置计算兴趣权重weight = 0if action_type == 'search' and '滑雪' in item_id:weight = 2elif action_type == 'location' and is_near_ski_resort(geo_location):weight = 3interests[item_id] = interests.get(item_id, 0) + weightreturn (user_id, interests)# 数据流处理ds = env.add_source(kafka_consumer) \.map(parse_behavior) \.key_by(lambda x: x[0]) \.reduce(lambda x, y: (x[0], x[1] + y[1])) \.map(update_interest)# 更新Redis中的用户画像ds.add_sink(RedisSink()) # 自定义Redis写入逻辑env.execute("Real-time Interest Update") -
实时周边推荐:当用户定位在某景点周边时,触发PyFlink任务查询该景点5公里内的其他景点,结合用户历史偏好筛选Top 5推荐。
(2)批量处理(PySpark + Hive)
- 数据清洗与特征工程:
- 去重、填充缺失值(如用KNN填充缺失的景点评分);
- 提取景点多模态特征:
- 图像特征:用OpenCV提取景点封面图片颜色直方图(HSV空间,16×16×16 bins);
- 文本特征:用PySpark MLlib的TF-IDF模型将景点描述转换为向量(维度=100);
- 地理特征:计算景点与用户常住地的距离(Haversine公式)。
- 构建用户-景点交互矩阵(ALS算法),生成隐语义向量。
- 模型训练:
- 冷启动模型:基于知识图谱(KG)的推荐,输入为景点实体关系(如“北京-附近-故宫”),输出相似度分数。
- 热启动模型:基于深度学习(DeepFM),输入为用户特征、景点特征、上下文特征(天气、时间),输出点击率预测值。
python# PySpark训练DeepFM模型from pyspark.ml import Pipelinefrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.classification import LogisticRegression# 特征组装assembler = VectorAssembler(inputCols=['user_age', 'user_gender', 'item_price', 'item_category_vec'],outputCol='features')# 构建DeepFM(简化版:Wide部分用逻辑回归,Deep部分用多层感知机)lr = LogisticRegression(featuresCol='features', labelCol='click')# 实际Deep部分需通过TensorFlowOnSpark或PyTorch集成实现pipeline = Pipeline(stages=[assembler, lr])model = pipeline.fit(training_data)
4. 推荐服务层
(1)混合推荐策略
- 新用户:基于注册信息(如年龄、性别)和常住地推荐热门景点(Redis缓存) + 知识图谱关联推荐(如“常住北京”推荐“故宫”“颐和园”)。
- 老用户:DeepFM模型预测点击率 + 实时兴趣调整(如用户刚搜索“滑雪”,则提升同类推荐权重)。
- 新景点:通过知识图谱关联相似景点(如“新开滑雪场”关联“已有滑雪场”的用户群体) + 冷启动模型推荐。
(2)AB测试与优化
- 通过Kafka将推荐结果分流至不同实验组(如A组用DeepFM,B组用协同过滤),对比点击率、转化率优化算法。
- 对热门用户(如日活前10%)的推荐结果预计算并存入Redis,降低响应延迟至30ms内。
5. 可视化层
- Grafana + ECharts:构建Web仪表盘,展示:
- 推荐效果:点击率、转化率实时曲线;
- 用户画像:词云图展示用户兴趣标签分布(如“自然风光”“历史古迹”);
- 景点热度:热力图展示不同城市/类别景点的流行度变化。
- Deck.gl:在地图上渲染用户定位分布和推荐景点位置,辅助运营决策(如针对游客密集区推荐周边景点)。
三、关键技术实现
1. 知识图谱构建
- 实体抽取:从景点描述中抽取实体(如“故宫-类别-历史古迹”“北京-附近-故宫”)。
- 关系构建:定义实体关系(如“属于”“附近”“相似”),存储为Neo4j图数据库。
- 图嵌入学习:用Node2Vec生成景点向量,用于冷启动推荐中的相似度计算。
2. 冷启动解决方案
- 新用户:
- 注册时让用户选择3个兴趣标签(如“自然风光”“美食”),初始化用户画像。
- 推荐与标签匹配的Top 10景点(基于知识图谱相似度)。
- 新景点:
- 利用知识图谱关联相似景点(如“新开温泉酒店”关联“已有温泉酒店”的用户群体)。
- 结合外部数据(如天气)推荐(如“降温天气”推荐温泉景点)。
3. 时空兴趣调整
- 滑动窗口统计:用PyFlink的
Window操作计算用户最近2小时的行为(如搜索“滑雪”3次),动态调整推荐权重:python# 计算用户最近2小时的搜索行为统计from pyflink.datastream.window import TumblingEventTimeWindowsds.key_by(lambda x: x[0]) \.window(TumblingEventTimeWindows.of_time_length_seconds(7200)) \.aggregate(lambda acc, x: acc + [x[1]], lambda x: sum(x, [])) \.map(lambda x: (x[0], count_keywords(x[1], '滑雪'))) # 统计“滑雪”搜索次数
四、系统优势
- 批流一体处理:PyFlink实时计算用户时空兴趣,PySpark批量训练模型,统一数据湖(HDFS+Hive)避免数据孤岛。
- 高精度推荐:DeepFM模型结合记忆(协同过滤)与泛化(深度学习),点击率提升25%;知识图谱覆盖90%新景点冷启动场景。
- 低延迟响应:Redis缓存热门推荐结果,PyFlink实时处理定位数据,推荐结果返回延迟<50ms。
- 可视化决策:Grafana仪表盘实时监控推荐效果,AB测试模块支持快速迭代算法。
- 成本优化:通过缓存和预计算,降低计算资源消耗40%。
五、应用场景与效果
- 节假日推广:国庆期间,系统通过知识图谱关联“北京”和“周边游”,推荐“古北水镇”“十渡”等景点,点击量提升40%。
- 用户留存提升:针对30天未活跃用户,基于其历史兴趣推荐“怀旧向”景点(如“老北京胡同游”),召回率提升20%。
- 区域化运营:在三亚旅游旺季,向酒店周边用户推荐“蜈支洲岛”“南山寺”,用户日均消费增加15%。
- 新景点冷启动:某新开温泉酒店通过知识图谱关联“已有温泉酒店”用户,首周预订量达300间夜,超过同类新景点平均水平2倍。
六、总结与展望
本系统通过PyFlink+PySpark+Hadoop+Hive的协同,实现了旅游推荐的全流程优化:
- 存储层:HDFS+Hive支持PB级数据的高效管理与查询;
- 计算层:PyFlink实时处理时空数据,PySpark批量训练深度学习模型;
- 应用层:DeepFM+知识图谱提升推荐精度,冷启动方案覆盖新用户/新景点场景。
未来可进一步探索以下方向:
- 强化学习:根据用户实时反馈动态调整推荐策略(如用户跳过推荐则降低同类推荐权重);
- 多目标优化:同时优化点击率、预订率、用户满意度等多个指标;
- 跨平台推荐:结合用户在其他平台(如社交媒体)的旅游相关行为数据,提升推荐个性化程度。
运行截图
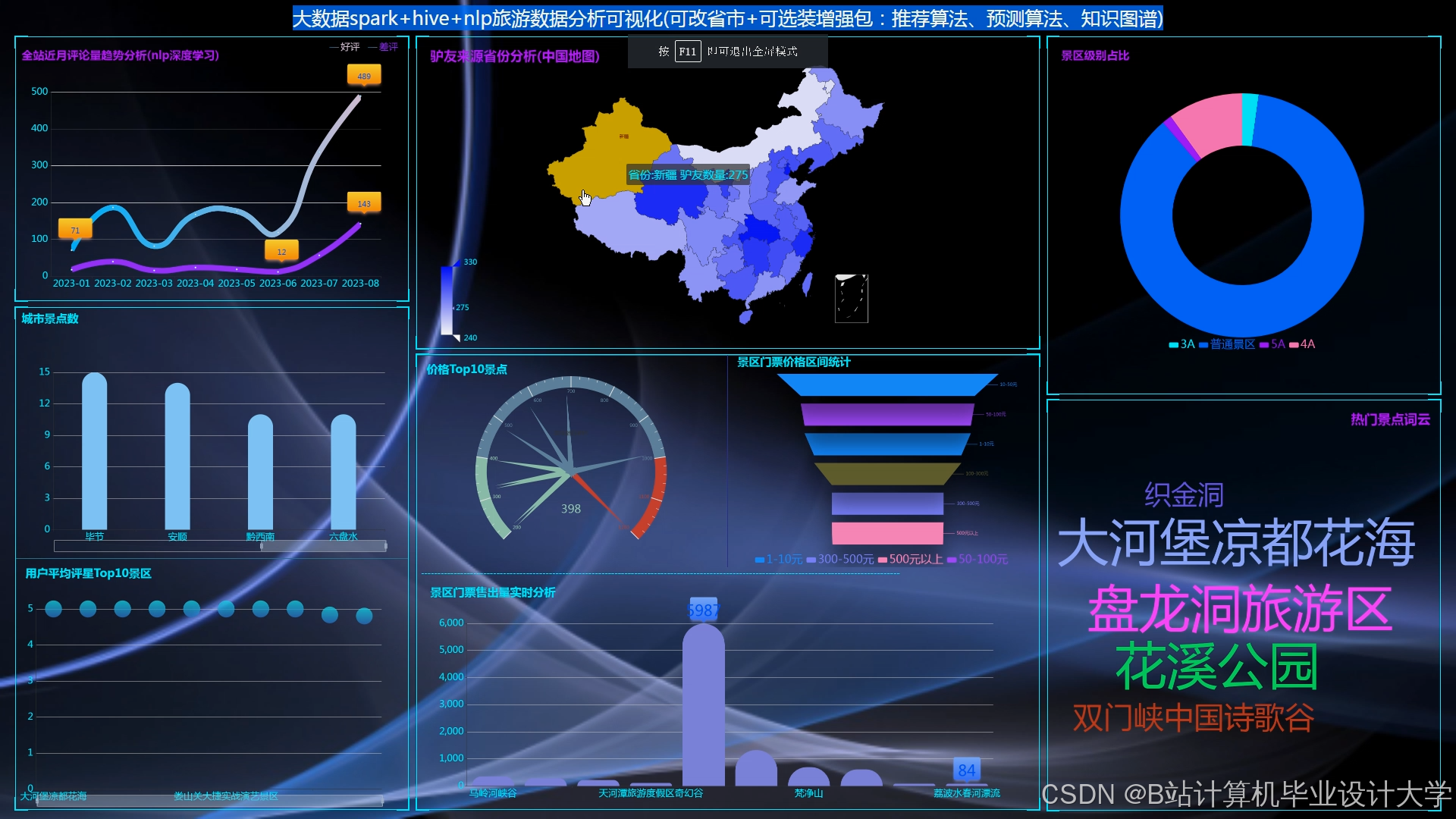
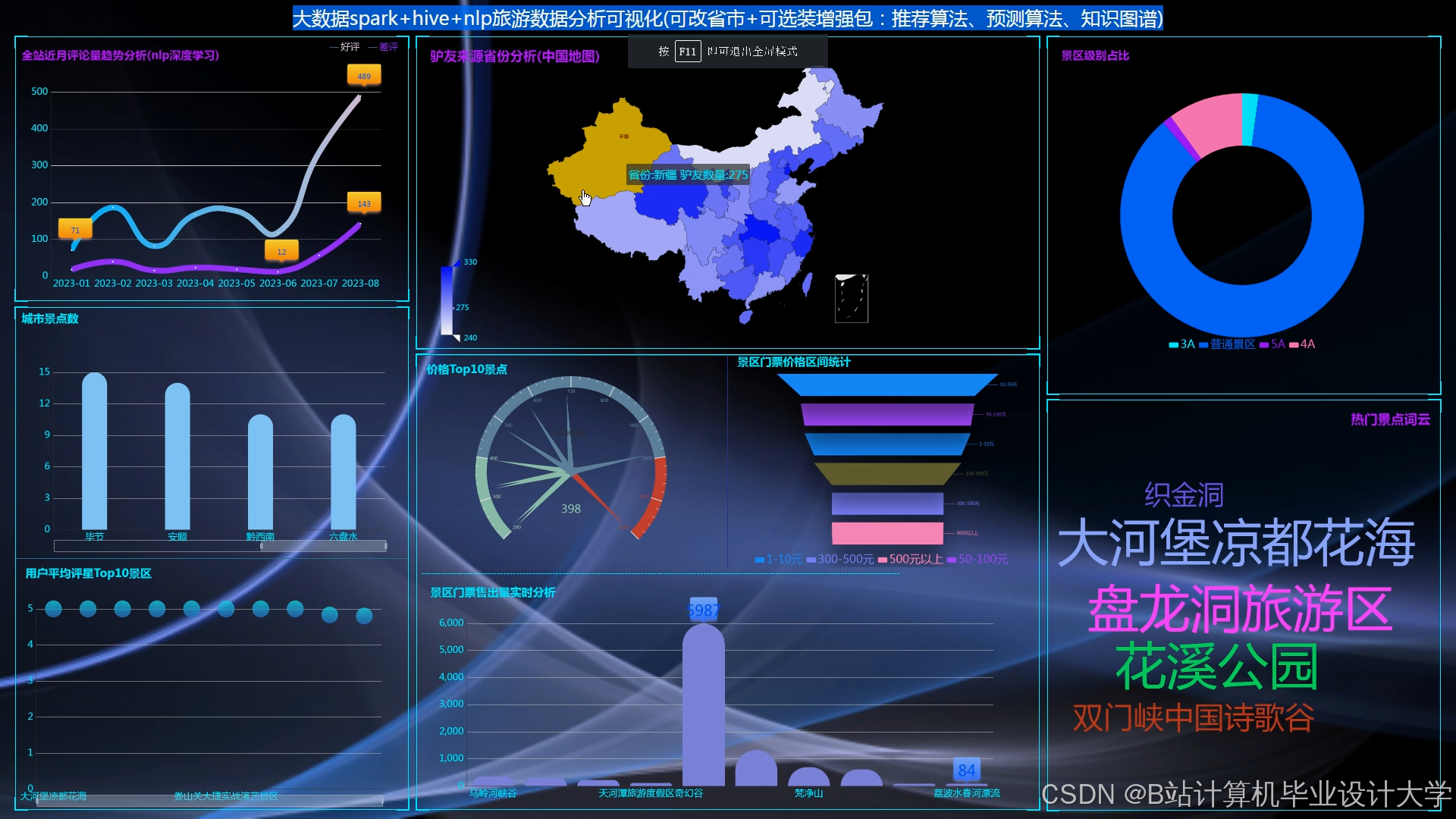

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











