




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份针对《PySpark+Hadoop+Hive+LSTM模型美团大众点评分析+评分预测美食推荐系统》的任务书模板,涵盖数据采集、特征工程、模型构建、推荐系统集成等核心模块,结合美团/大众点评业务场景设计:
任务书:基于PySpark+Hadoop+Hive+LSTM的美团/大众点评美食评分预测与推荐系统
一、项目背景与目标
1. 背景
- 美团/大众点评作为本地生活服务平台,用户评论数据呈现海量、高维、非结构化特征(如文本评论、图片、评分、时间序列行为)。
- 传统推荐系统依赖协同过滤(CF)或浅层模型(如LR、GBDT),难以捕捉用户动态偏好和评论中的情感-评分关联。
- 需结合深度学习(LSTM)与大数据处理框架(PySpark+Hadoop),构建实时评分预测模型,提升美食推荐个性化精度。
2. 目标
- 构建Hadoop+Hive数据仓库,整合用户行为、商家属性、评论文本等多源异构数据。
- 基于PySpark实现LSTM评分预测模型,捕捉用户评论情感随时间变化的动态模式。
- 开发混合推荐系统(评分预测+协同过滤),输出TOP-N美食推荐列表,支持实时与离线场景。
- 部署系统至生产环境,验证模型在美团真实数据集上的MAE(平均绝对误差)≤0.8,推荐点击率提升15%+。
二、项目任务与分工
1. 多源数据采集与存储(Hadoop+Hive)
- 任务内容
- 数据源接入:
- 用户行为数据:浏览记录、点击记录、收藏/分享行为(通过Kafka实时采集)。
- 评论数据:文本内容、评分(1-5分)、图片标签(如“环境优雅”“菜品精致”)、评论时间。
- 商家属性数据:品类(川菜/日料等)、人均消费、地理位置、历史评分分布。
- 外部数据:天气API(影响用餐选择)、节假日日历(如情人节增加“浪漫餐厅”需求)。
- 数据清洗与存储:
- 处理异常数据(如评分=0、重复评论、文本乱码)。
- 分层存储至Hive:
- ODS层:原始数据(保留3年历史评论)。
- DWD层:清洗后数据,按主题分区(用户、商家、评论)。
- DWS层:聚合指标(用户月均评论数、商家周评分趋势)。
- ADS层:模型输入特征表(如“用户A_川菜_近30天评论情感分_商家B历史评分”)。
- 数据源接入:
- 技术工具
- 数据采集:Flume(日志文件)、Kafka(实时流)、Sqoop(批量导入Hive)。
- 存储格式:Hive表(ORC压缩)、HBase(用户实时行为缓存)。
2. 特征工程与LSTM模型开发(PySpark)
- 任务内容
- 特征设计:
- 用户侧特征:
- 静态特征:年龄、性别、注册时长、常驻城市。
- 动态特征:近30天评论情感分(通过BERT预训练模型提取)、消费频次、品类偏好向量(One-Hot编码)。
- 商家侧特征:
- 静态特征:品类、人均消费、地理位置(经纬度离散化为网格)。
- 动态特征:近7天评分趋势、评论数量波动率、热门标签分布(如“性价比高”出现频次)。
- 上下文特征:
- 时间特征:小时级(午餐/晚餐时段)、星期几、是否为节假日。
- 外部特征:天气类型(雨/雪影响外卖需求)、温度。
- 用户侧特征:
- LSTM模型构建:
- 输入:用户历史评论序列(文本情感分+评分)+ 当前上下文特征。
- 输出:预测用户对目标商家的评分(1-5分)。
- 模型结构(PySpark MLlib + Keras示例):
pythonfrom pyspark.ml.feature import VectorAssemblerfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense# 1. PySpark特征组装assembler = VectorAssembler(inputCols=["user_history_sentiment", "context_features"],outputCol="features")df_features = assembler.transform(spark_df)# 2. 定义LSTM模型(需通过Spark UDF调用Keras)def build_lstm_model(input_shape):model = Sequential([LSTM(64, input_shape=input_shape, return_sequences=True),Dense(32, activation='relu'),Dense(1) # 回归任务输出评分])model.compile(optimizer='adam', loss='mse')return model# 3. 训练流程(需将Spark DataFrame转为NumPy数组)X_train, y_train = df_features.select("features", "label").rdd.map(lambda row: (row.features, row.label)).collect()model = build_lstm_model((X_train.shape[1], X_train.shape[2]))model.fit(X_train, y_train, epochs=20, batch_size=32)
- 模型评估:
- 指标:MAE、RMSE、R²(决定系数)。
- 对比基线:XGBoost、传统LSTM(非序列化特征)。
- 特征设计:
- 输出成果
- 特征工程代码库(PySpark SQL/Pandas UDF)。
- LSTM模型权重文件(HDF5格式)、模型评估报告。
3. 混合推荐系统开发
- 任务内容
- 推荐策略设计:
- 评分预测层:
- 对用户-商家候选对(User-Item Pair)调用LSTM模型预测评分。
- 过滤低评分商家(如预测评分<3分)。
- 协同过滤层:
- 基于用户历史行为(点击/收藏)构建Item-CF矩阵,挖掘相似商家。
- 结合LSTM预测评分加权排序(如:最终得分 = 0.7×预测评分 + 0.3×协同过滤相似度)。
- 评分预测层:
- 实时推荐流程(PySpark Structured Streaming示例):
scala// 1. 读取用户实时行为(Kafka)val userActions = spark.readStream.format("kafka").option("subscribe", "user_actions_topic").load()// 2. 关联用户历史特征(从Hive ADS层)val userFeatures = spark.table("user_features_ads")val joinedStream = userActions.join(broadcast(userFeatures), "user_id")// 3. 调用预训练LSTM模型预测评分val predictions = joinedStream.mapPartitions { partition =>val model = loadLSTMModel("/models/lstm_rating.h5")partition.map(row => {val features = extractFeatures(row) // 提取用户-商家特征val predictedScore = model.predict(features)(row.user_id, row.item_id, predictedScore)})}// 4. 生成TOP-N推荐列表val topNRecs = predictions.groupByKey("user_id").mapGroups { (userId, iter) =>val sorted = iter.toList.sortBy(-_._3).take(10) // 按评分降序取TOP10(userId, sorted.map(x => (x._2, x._3))) // (商家ID, 预测评分)}// 5. 写入Redis供前端调用topNRecs.writeStream.format("org.apache.spark.sql.redis").start("recommendations_db") - 离线推荐流程:
- 每日凌晨运行Spark Batch作业,更新全量用户推荐列表至Hive。
- 推荐策略设计:
- 输出成果
- 推荐系统代码库(Scala/Python)、Redis缓存策略文档。
- AB测试方案(对比纯协同过滤与混合推荐效果)。
4. 系统集成与性能优化
- 任务内容
- 部署Hadoop集群(5节点)、Spark Standalone集群(3主2从)、Hive Metastore。
- 优化LSTM模型推理速度:
- 使用ONNX格式导出模型,通过PySpark UDF调用。
- 对高频查询用户特征缓存至Redis(TTL=1小时)。
- 监控系统:
- Prometheus+Grafana监控Spark任务延迟、Hive查询响应时间。
- 设置预警阈值(如单次推荐耗时>500ms触发告警)。
- 输出成果
- 集群部署文档、性能优化报告(含资源占用率对比)。
三、技术栈与开发环境
| 模块 | 技术选型 |
|---|---|
| 大数据框架 | Hadoop 3.3.4, Spark 3.3.2 (PySpark), Hive 3.1.3 |
| 深度学习 | TensorFlow 2.12 (Keras), ONNX Runtime |
| 数据流处理 | Kafka 3.4.0, Spark Structured Streaming |
| 推荐系统缓存 | Redis 7.0 (Sorted Set存储推荐列表) |
| 开发环境 | Linux (Ubuntu 22.04), JupyterLab, PyCharm |
四、项目里程碑计划
| 阶段 | 时间 | 交付物 |
|---|---|---|
| 数据调研与ETL开发 | 第1-2周 | Hive表结构、数据清洗脚本 |
| 特征工程与LSTM训练 | 第3-4周 | 特征重要性分析报告、模型权重文件 |
| 推荐系统开发 | 第5-6周 | 实时推荐Demo、AB测试方案 |
| 系统集成与调优 | 第7周 | 集群部署脚本、性能监控看板 |
| 项目验收 | 第8周 | 用户操作手册、模型迭代计划 |
五、预期成果
- 模型性能:
- LSTM预测评分MAE≤0.8,较XGBoost提升15%+。
- 推荐效果:
- 混合推荐点击率(CTR)较纯协同过滤提升12-18%。
- 系统性能:
- 实时推荐延迟<300ms,支持每秒1万次请求。
六、风险评估与应对
| 风险类型 | 应对措施 |
|---|---|
| LSTM训练资源不足 | 使用分布式TensorFlow(Horovod)加速训练 |
| 评论文本情感提取偏差 | 结合BERT+规则引擎(如识别否定词“不辣”) |
| 冷启动问题 | 对新用户采用基于内容的推荐(商家标签匹配) |
| 数据倾斜 | 对高频用户/商家采样,使用Spark repartition |
项目负责人:__________
日期:__________
此任务书可根据美团实际业务数据规模调整集群规模(如增加Spark Worker节点),并建议优先在单一城市(如北京)验证模型效果,再扩展至全国范围。
运行截图
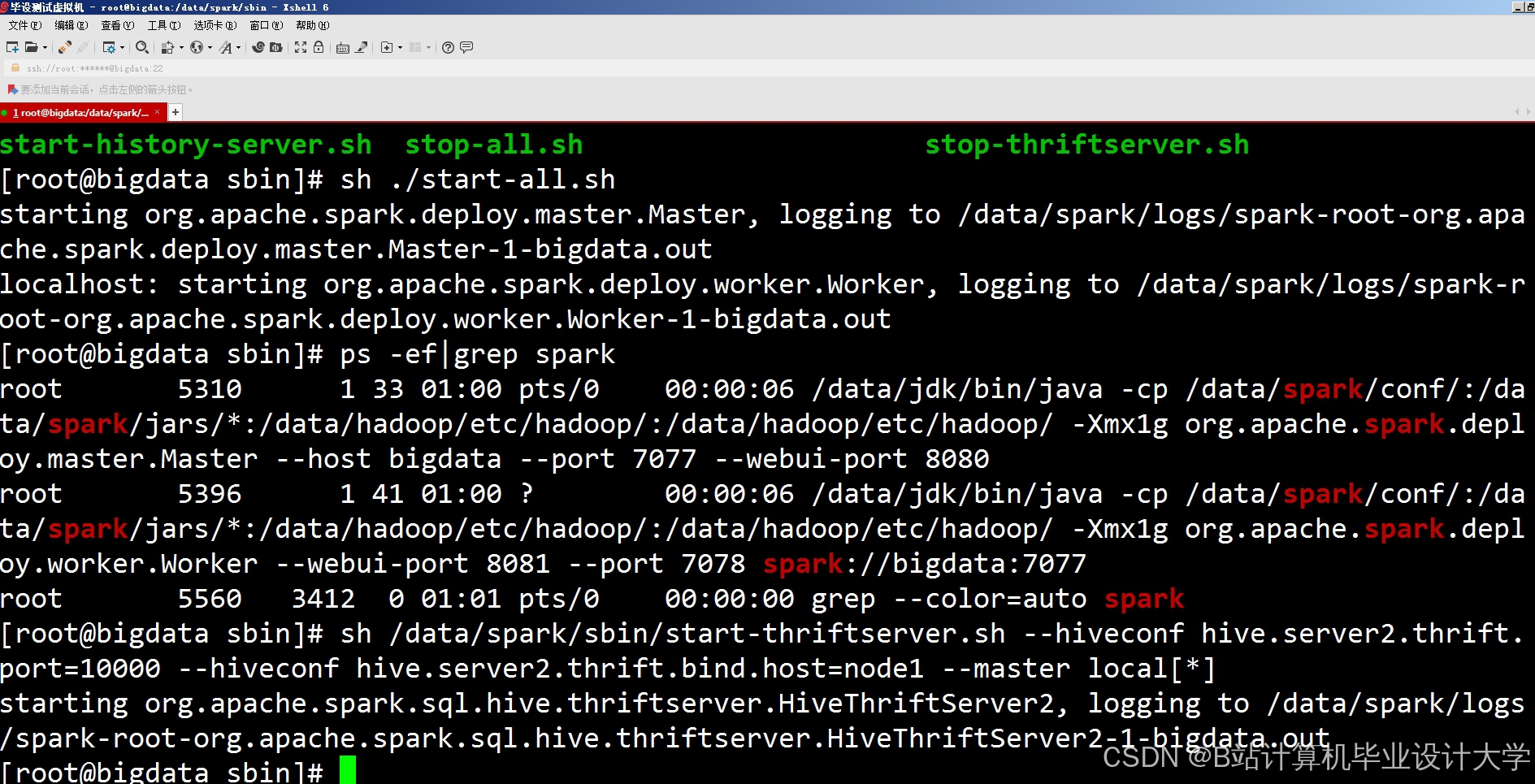
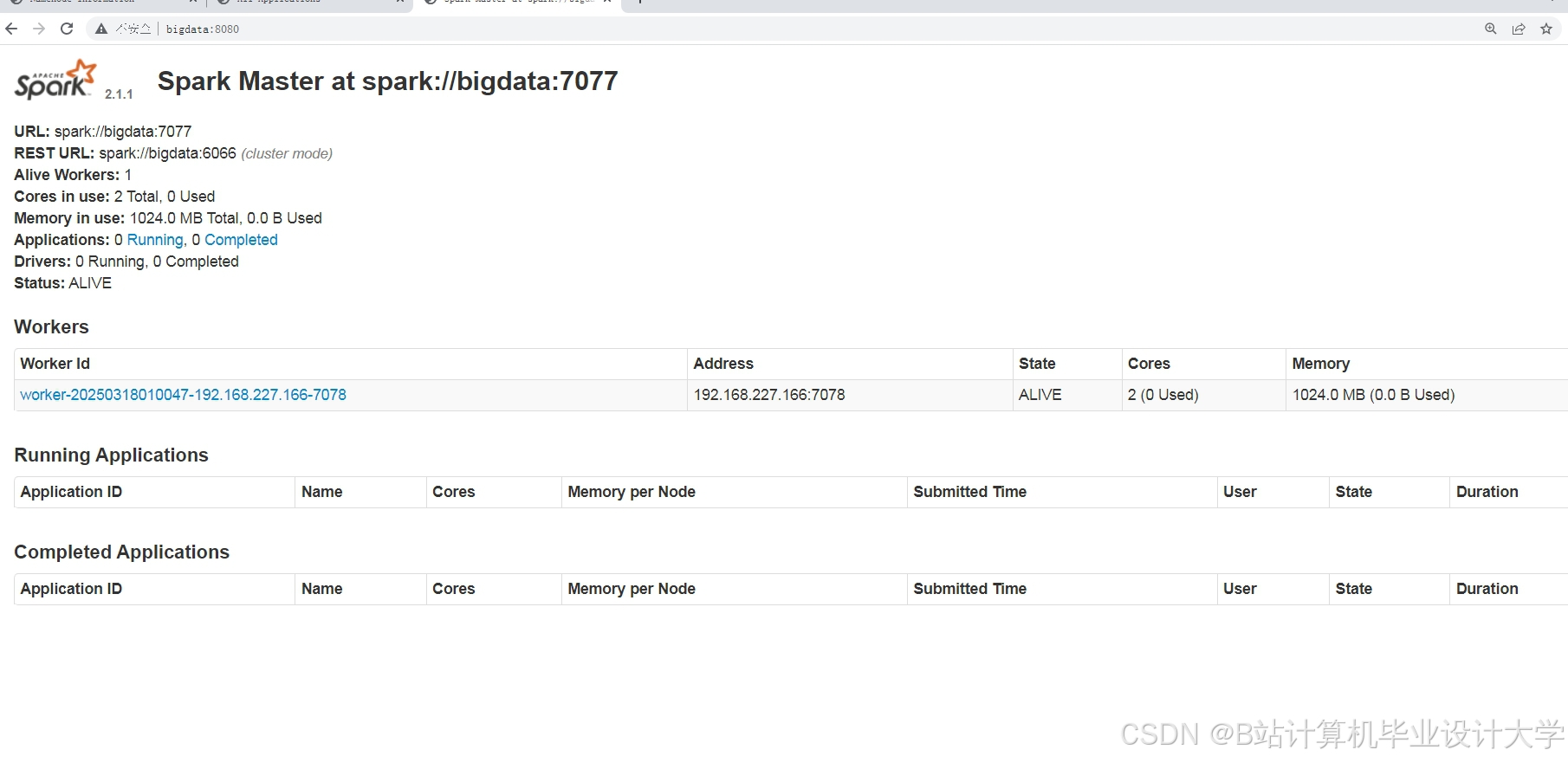
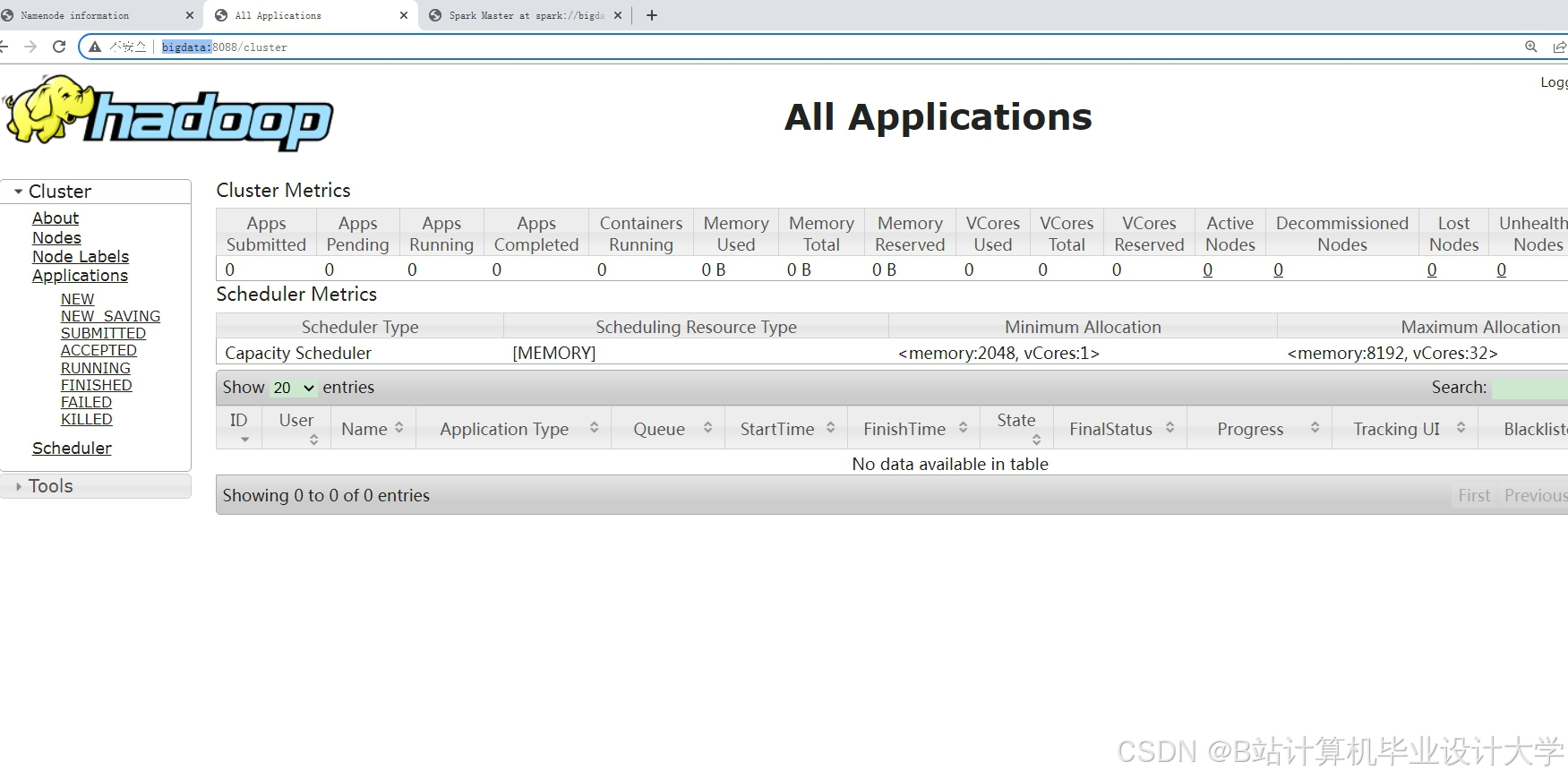
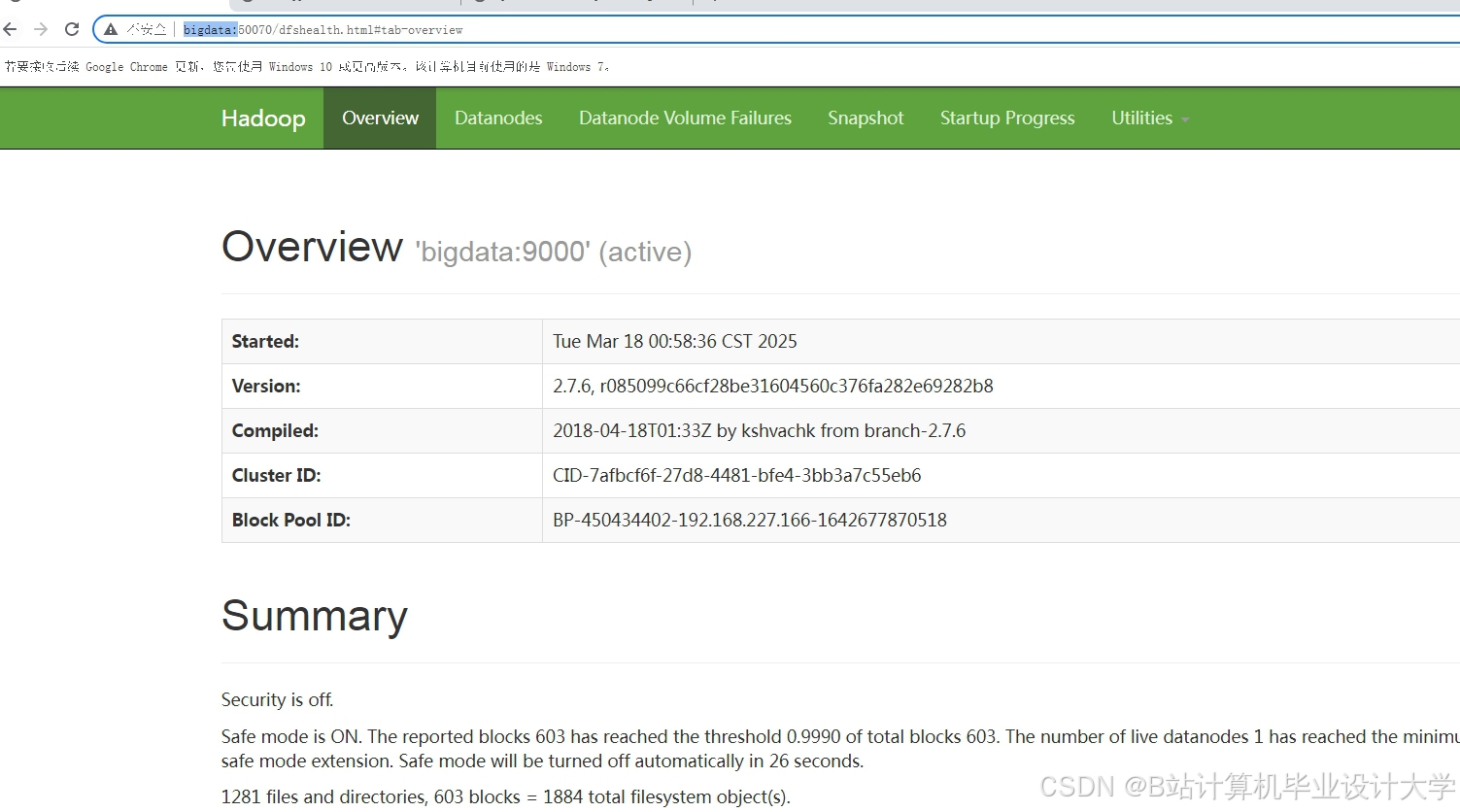
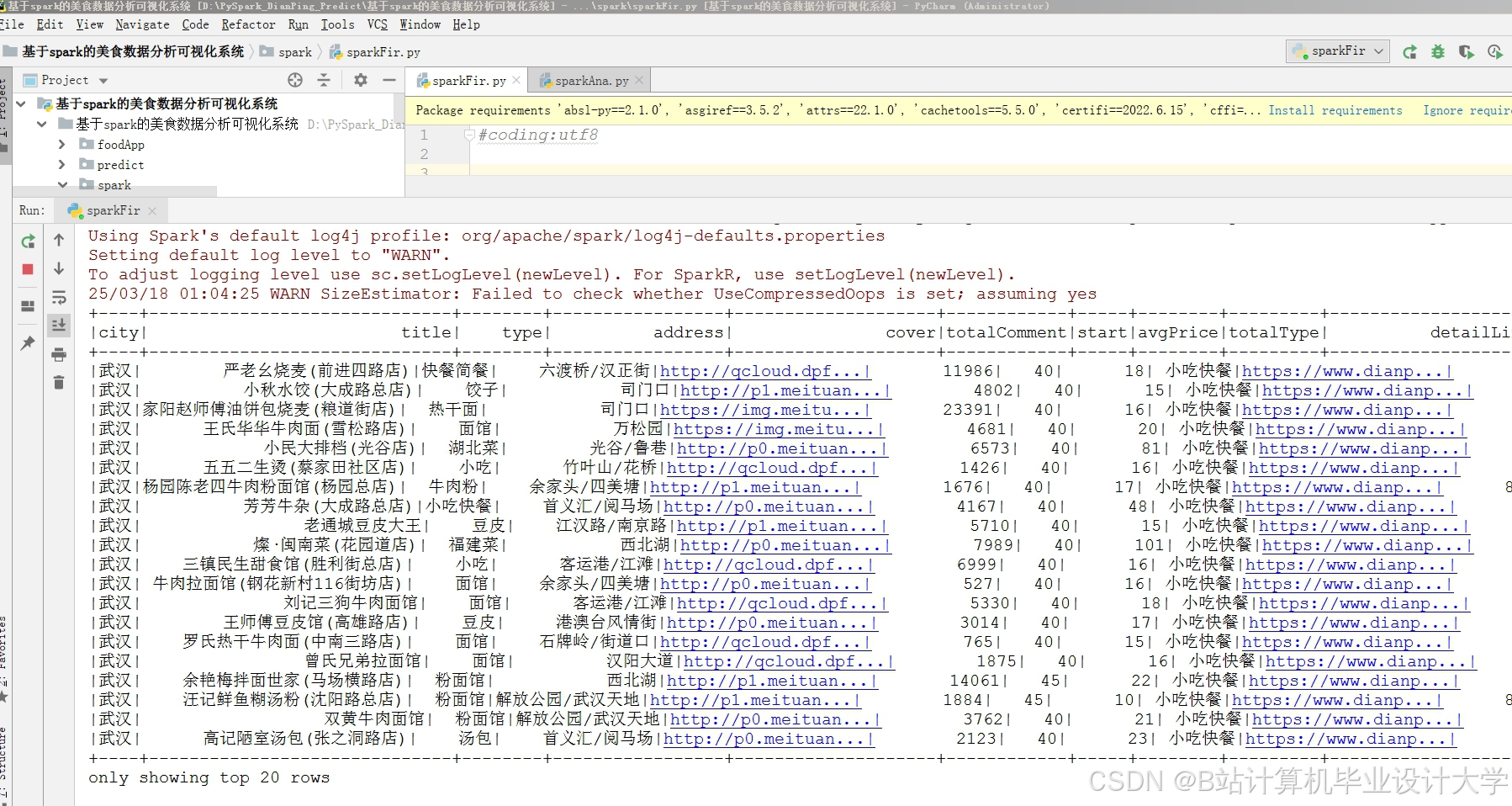
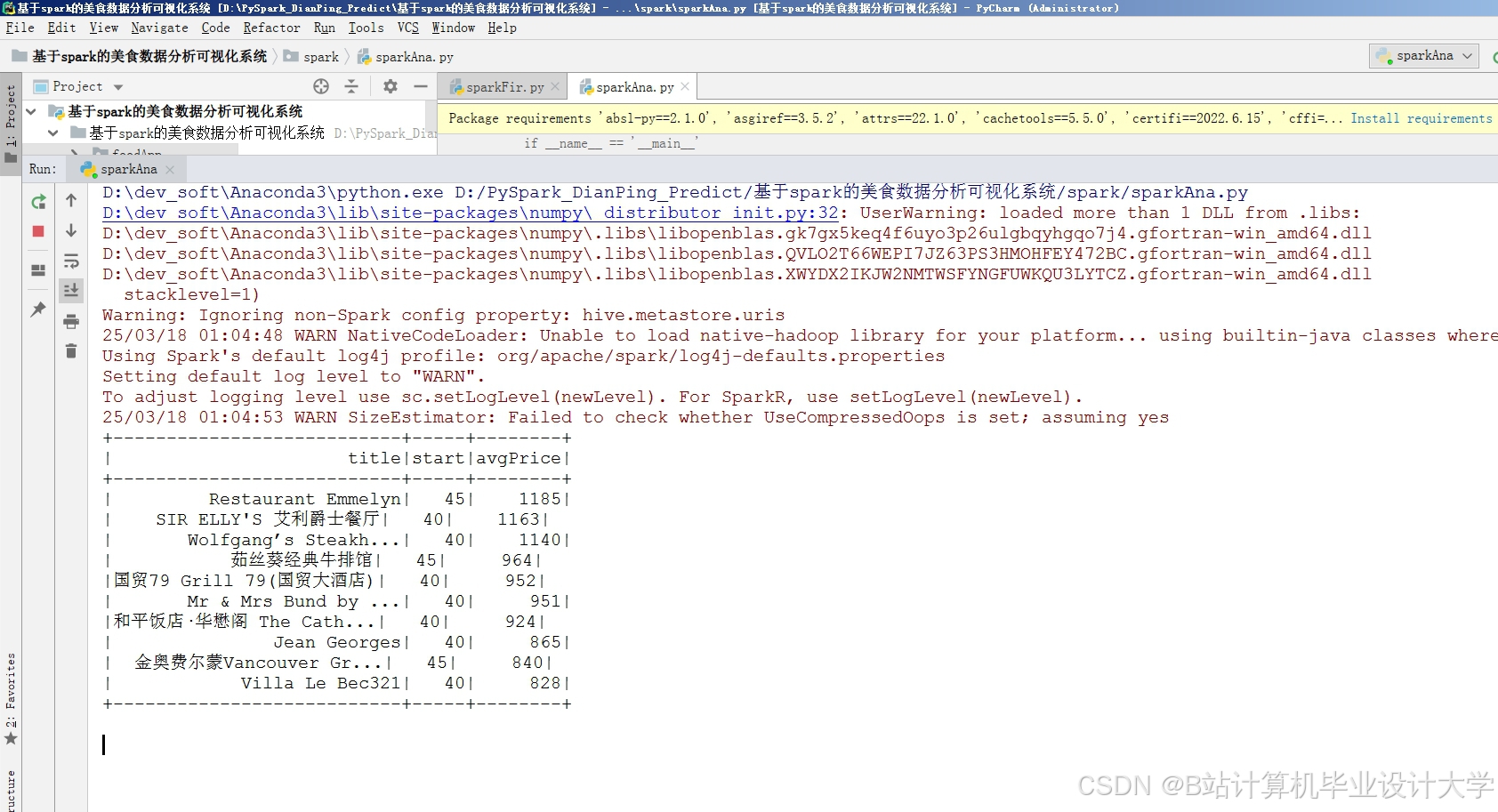
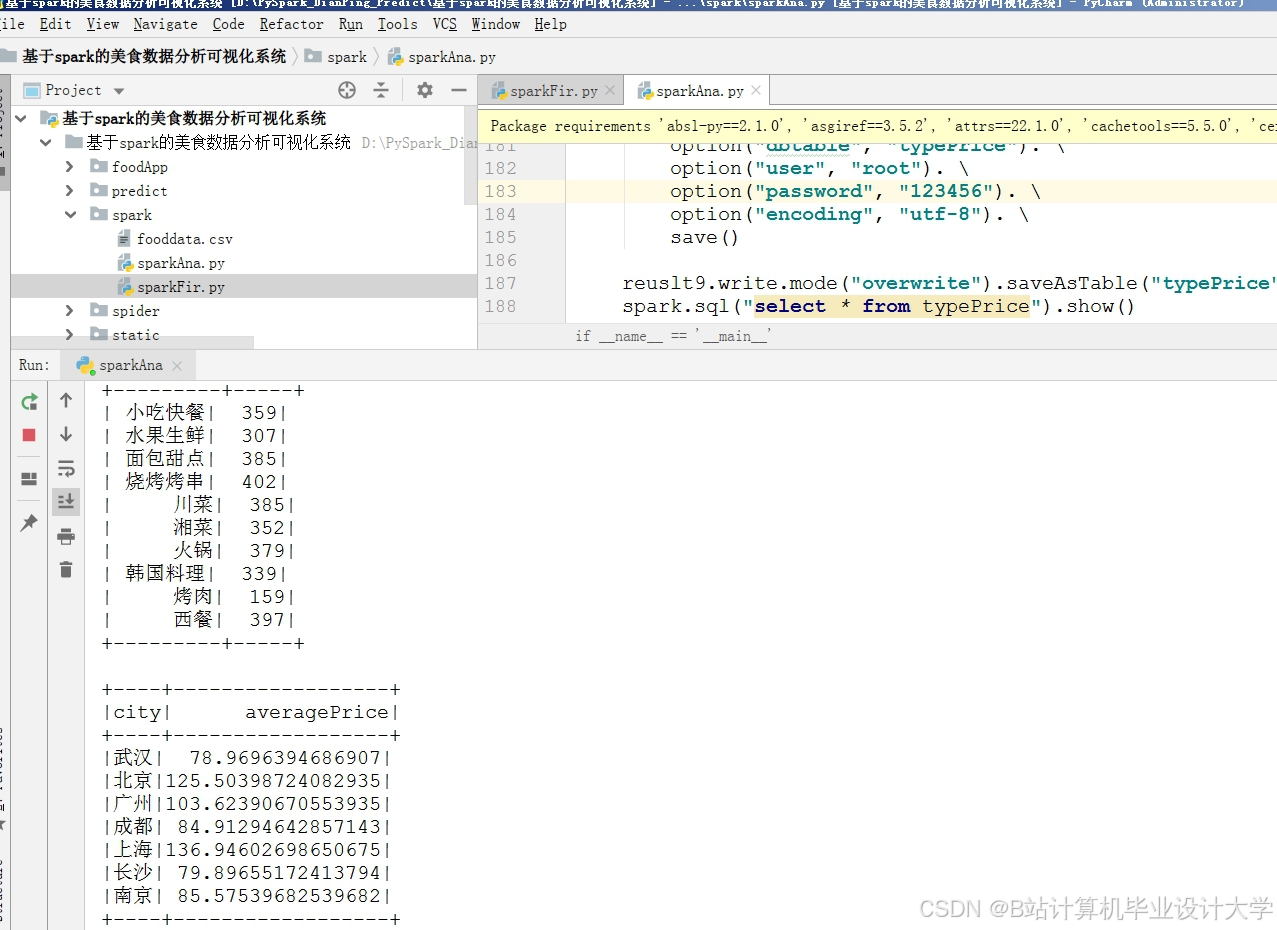
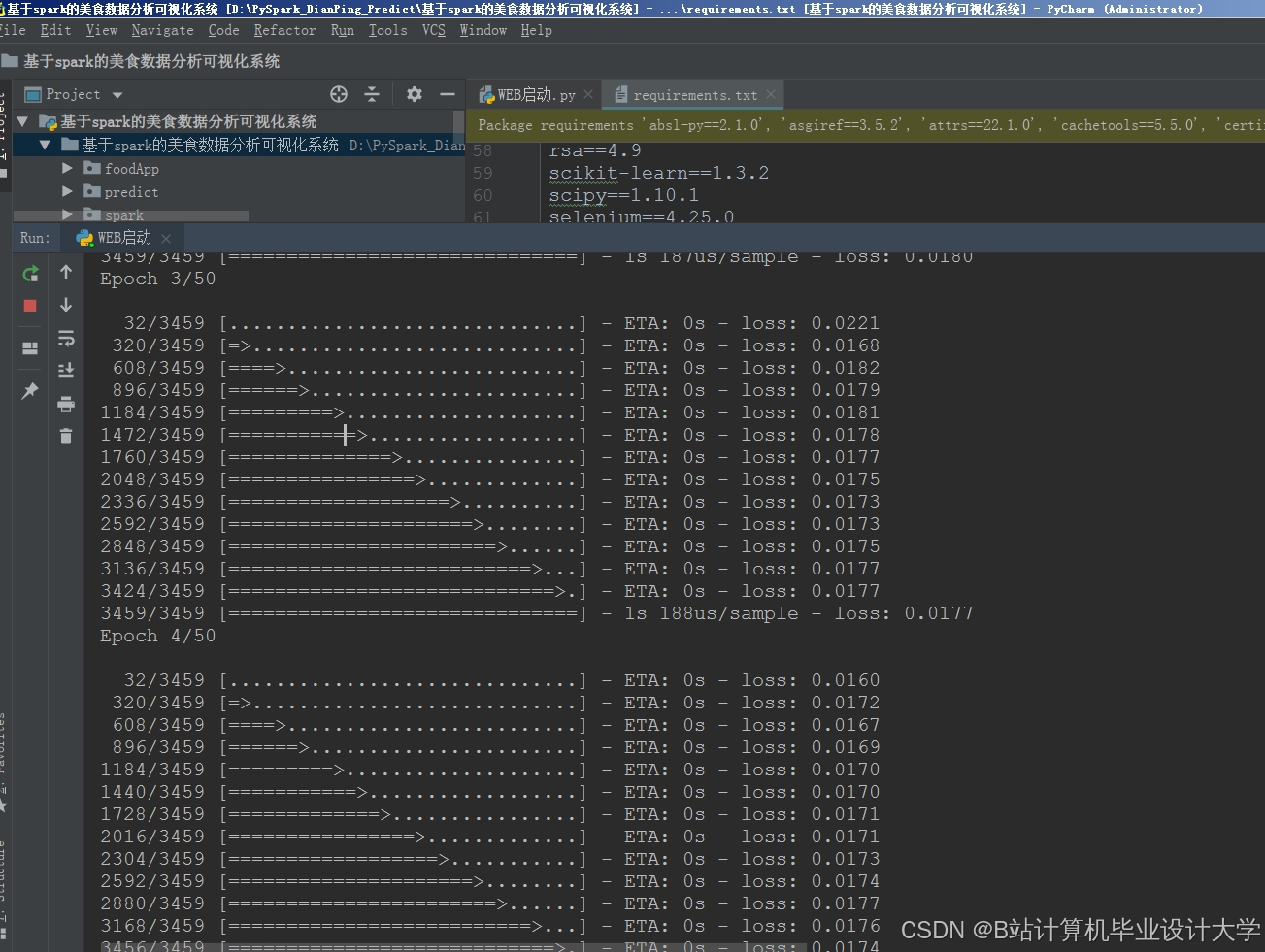
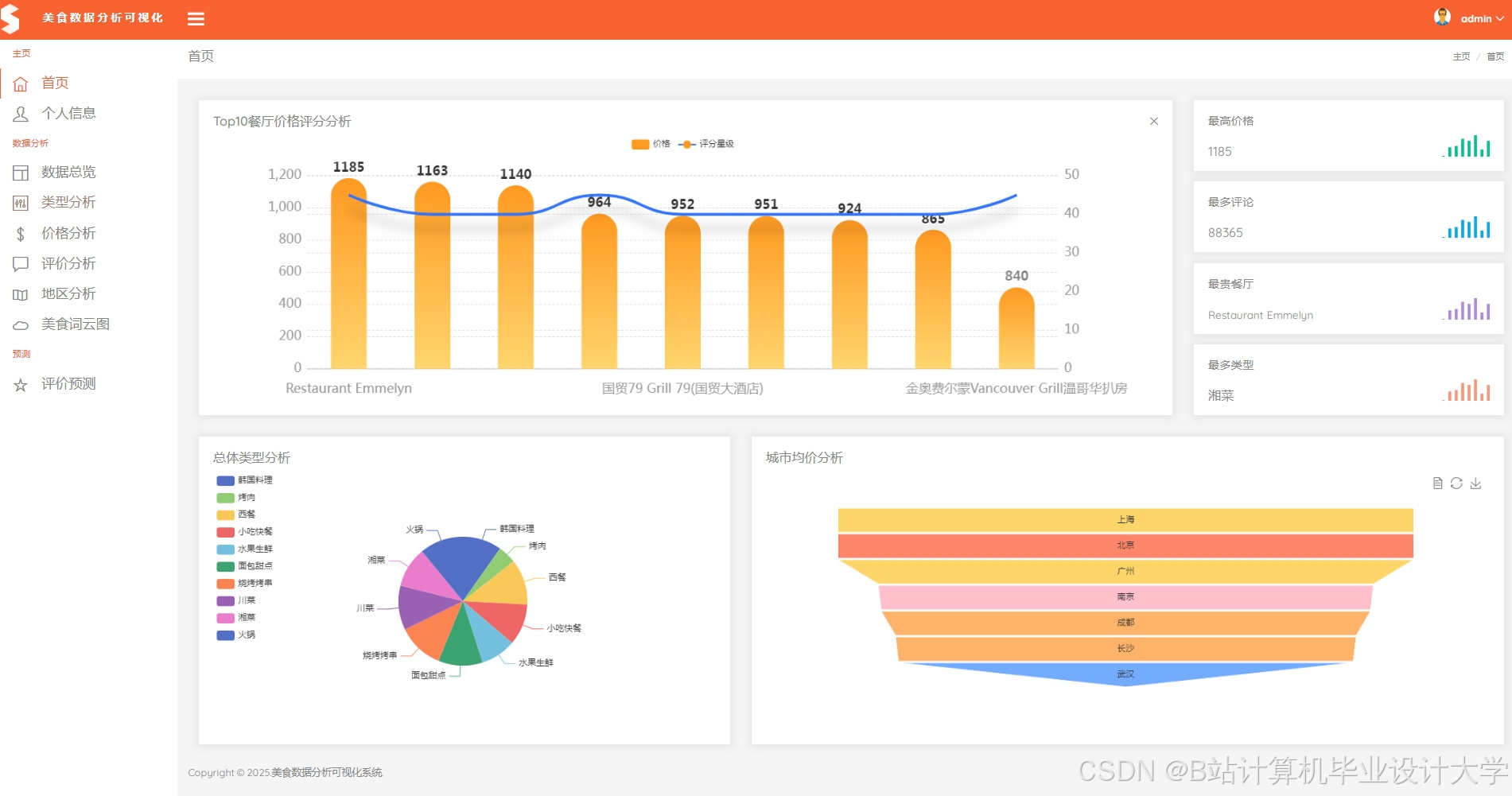
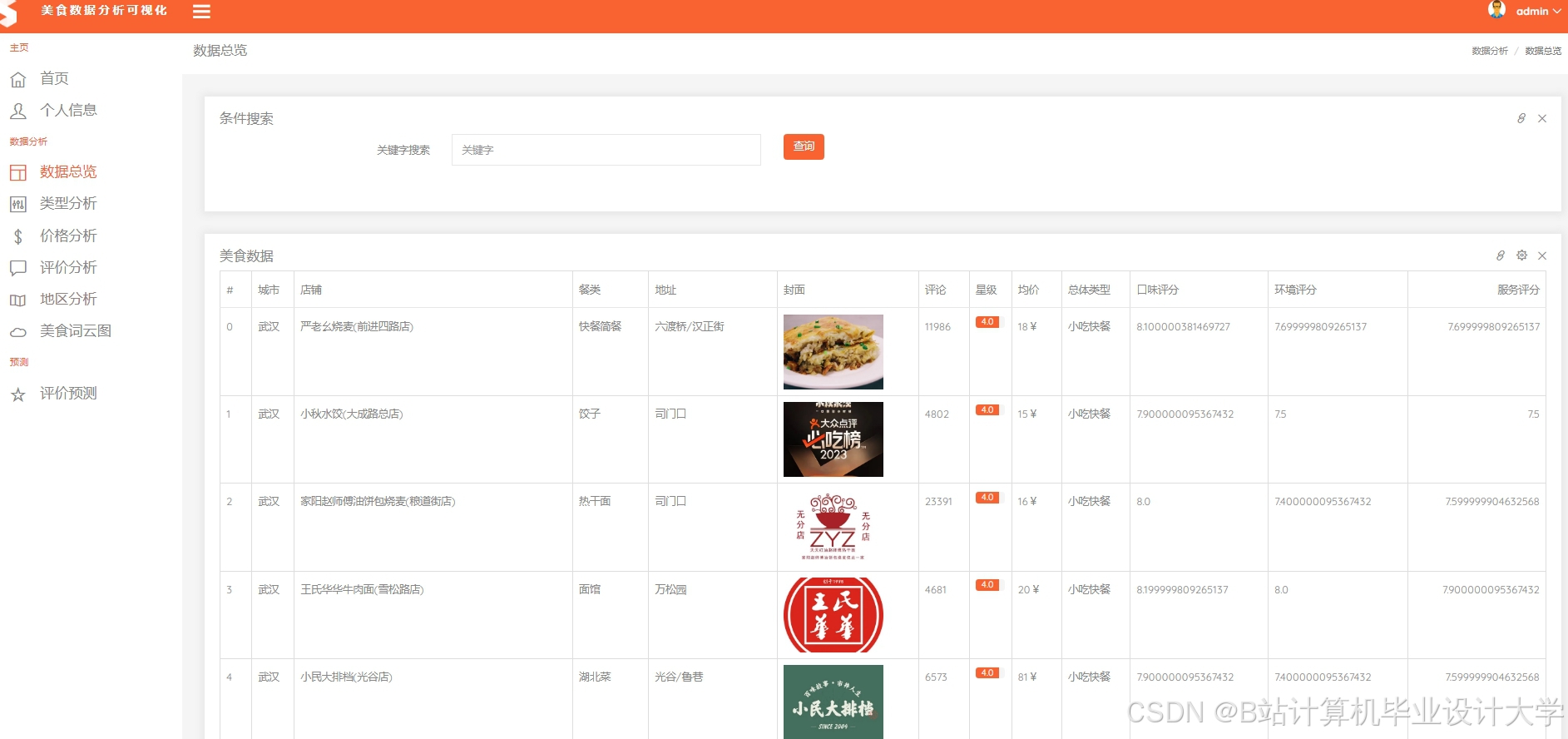
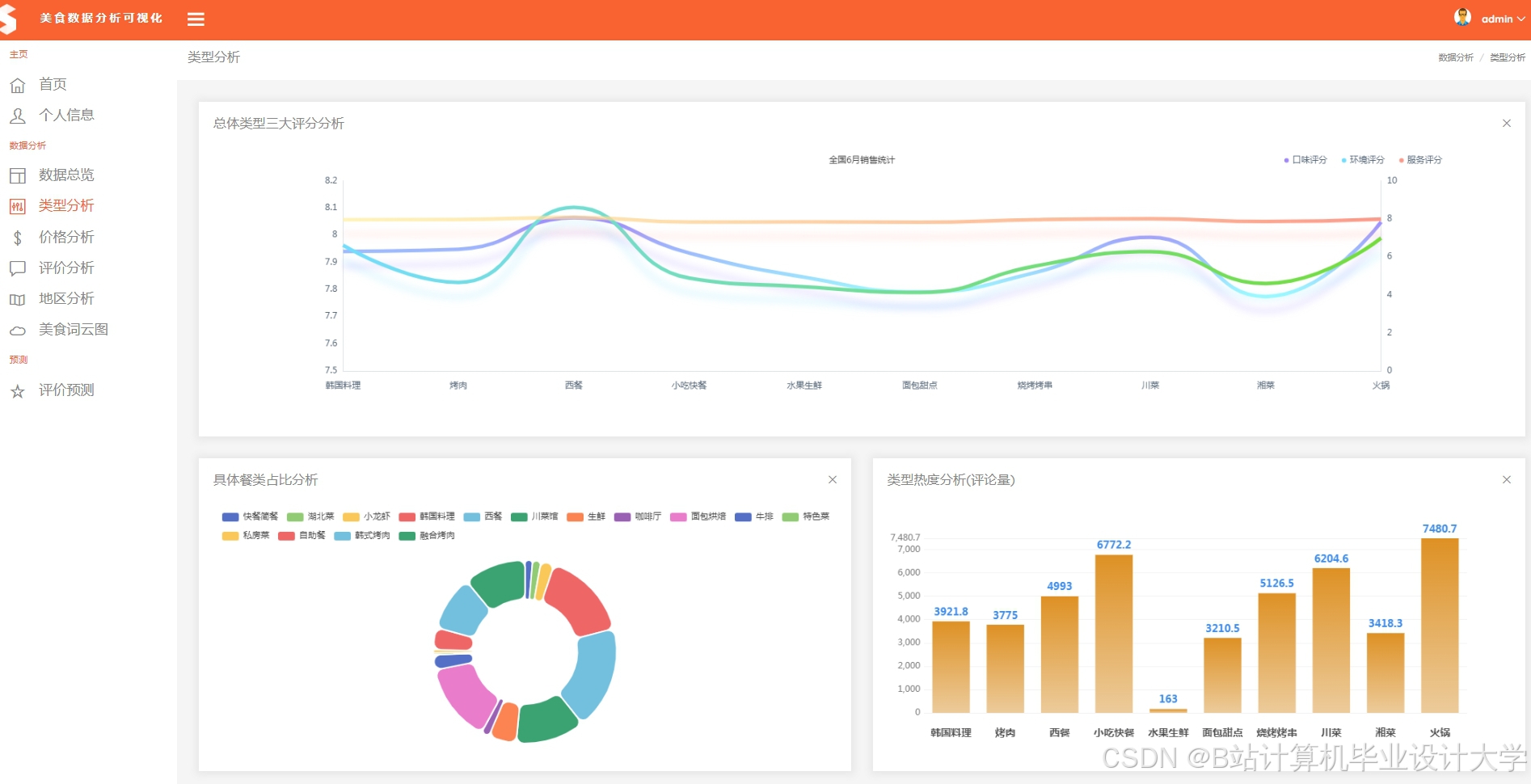
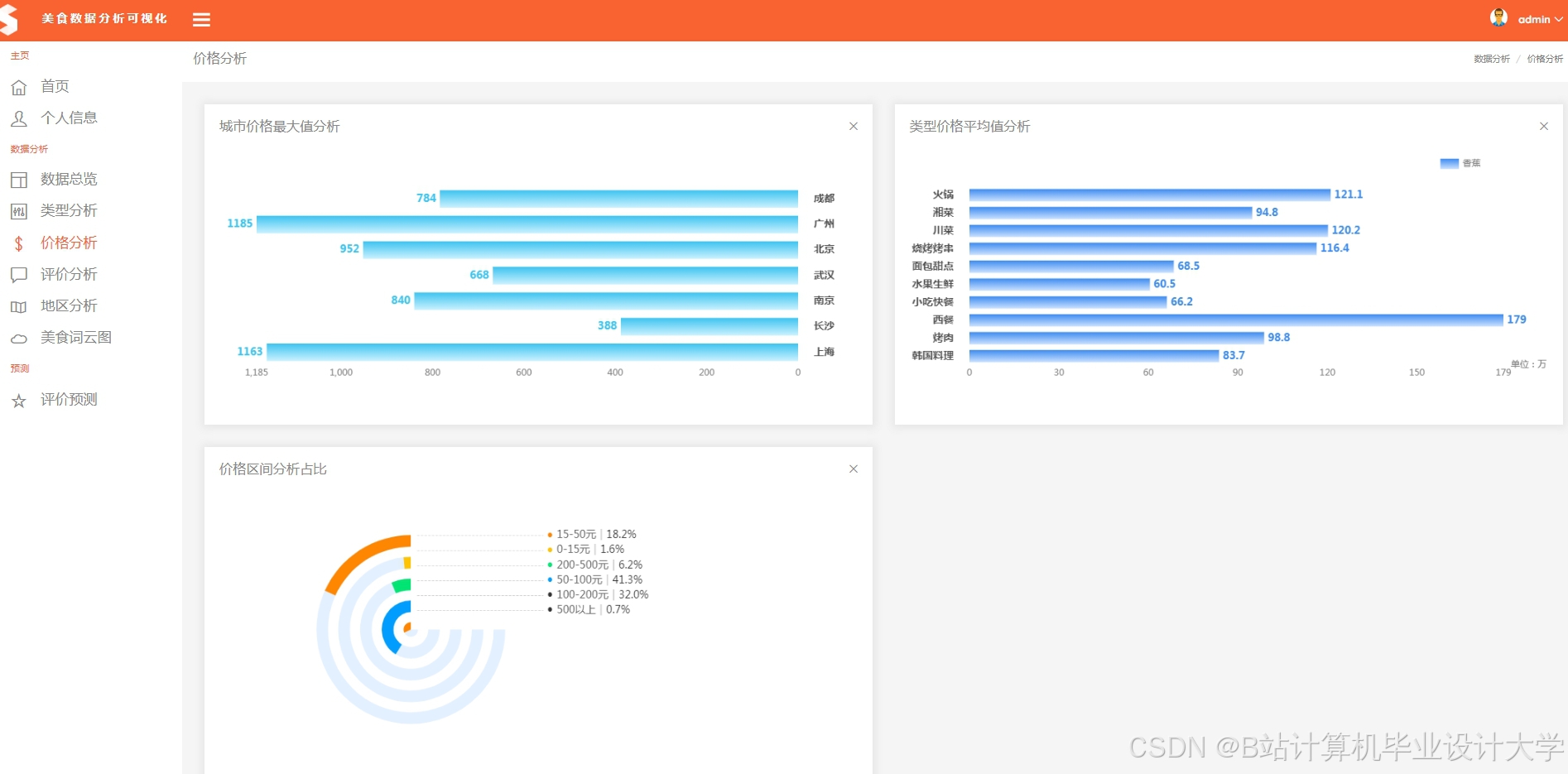
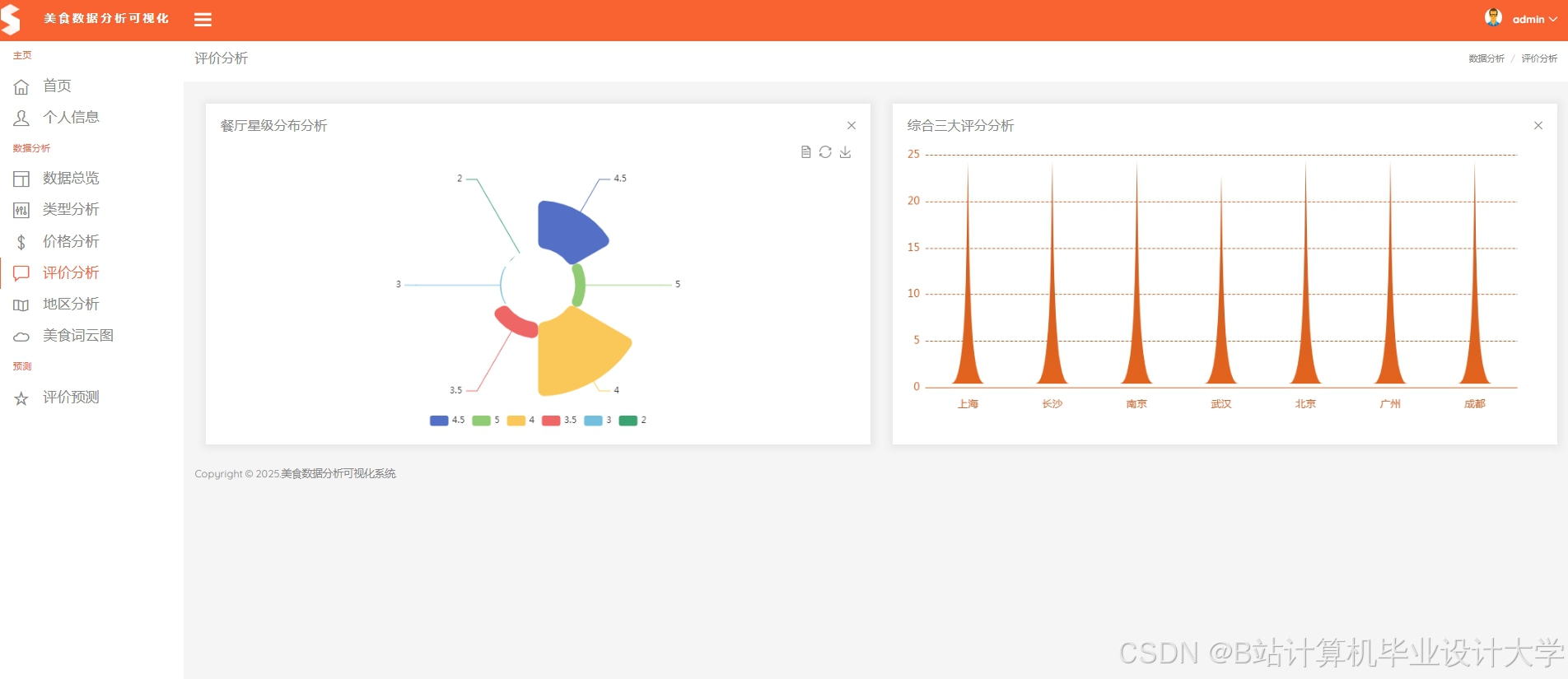
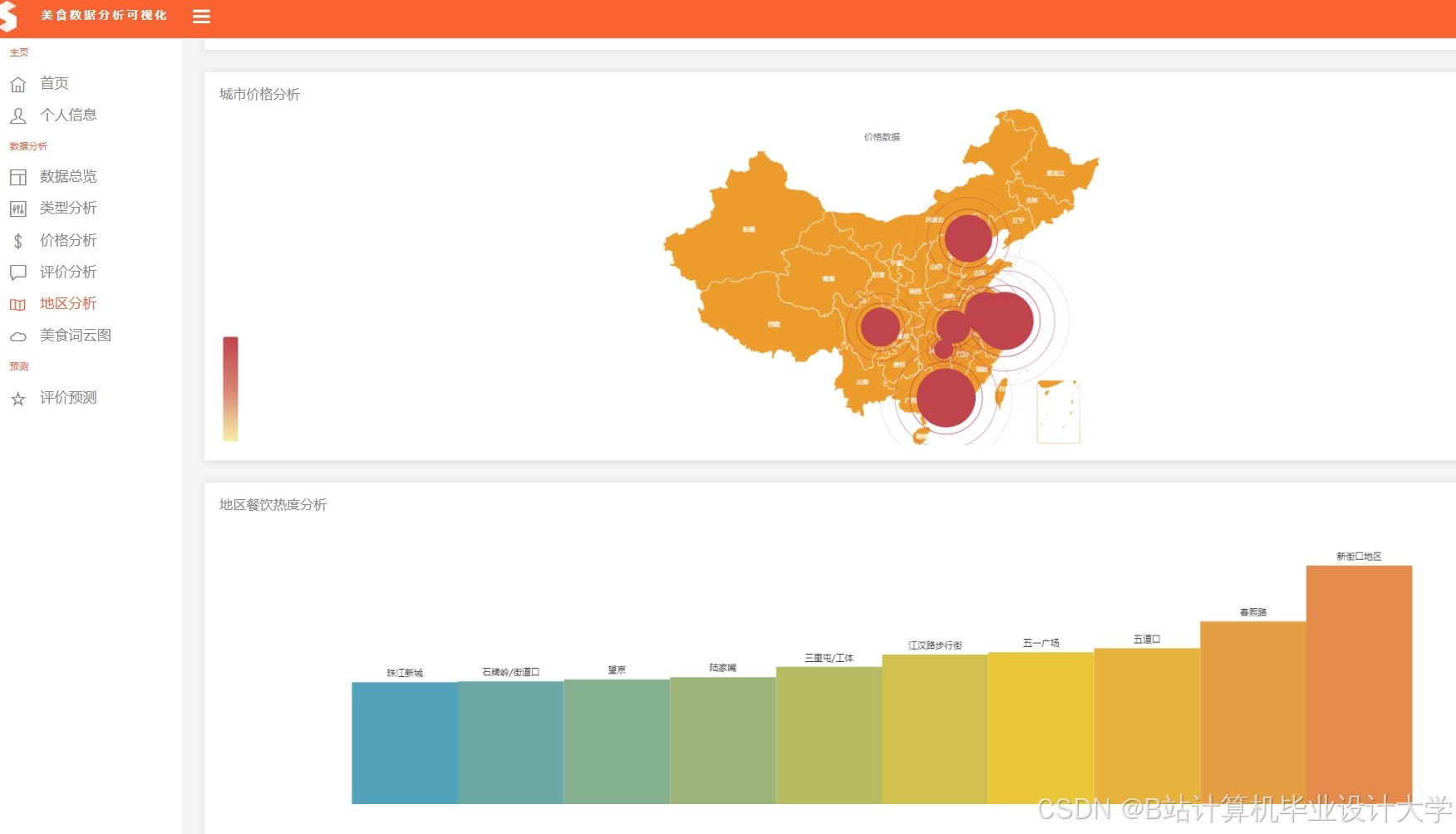
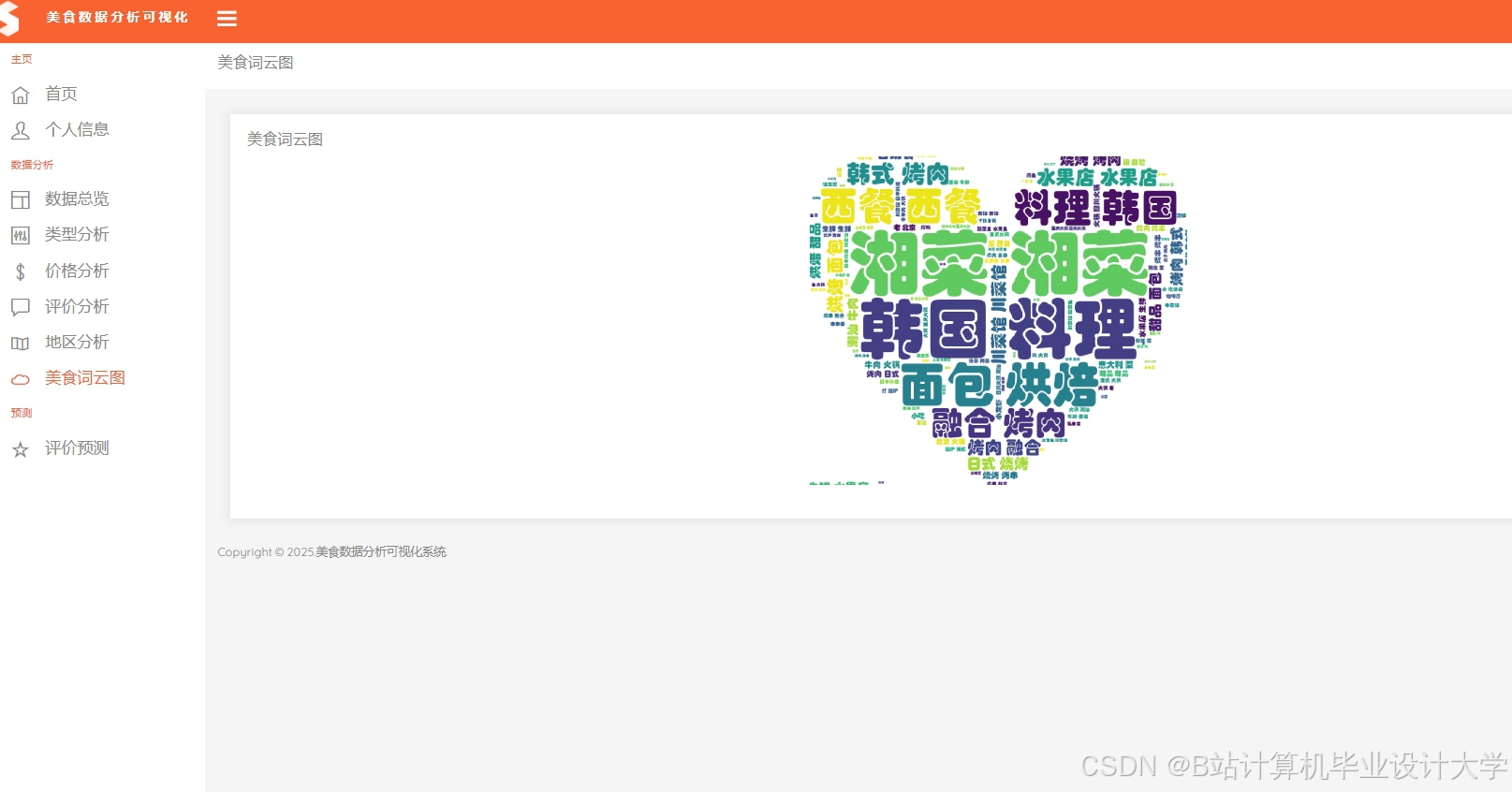
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











