




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+PySpark+Hive爱心慈善捐赠项目推荐系统技术说明
一、项目背景与业务价值
在慈善捐赠领域,捐赠者常面临信息过载(如海量项目难以筛选)与匹配低效(捐赠意愿与项目需求错配)问题。本系统基于Hadoop大数据生态,构建捐赠者-项目智能匹配引擎,实现:
- 精准推荐:通过分析捐赠历史、项目特征、社交行为等多维度数据,生成个性化捐赠建议。
- 实时响应:利用PySpark内存计算能力,支持毫秒级推荐结果返回,适应高并发捐赠场景。
- 透明可追溯:通过Hive元数据管理,记录推荐逻辑与数据血缘,提升捐赠者信任度。
二、核心技术架构
1. 数据存储层:Hadoop HDFS + Hive
- HDFS:存储原始捐赠数据、项目详情、用户行为日志等结构化与非结构化数据,支持PB级扩展。
- Hive:构建数据仓库,定义以下核心表结构:
sql-- 捐赠者画像表(含人口统计、捐赠偏好等)CREATE TABLE donor_profile (donor_id STRING,age INT,gender STRING,avg_donation_amount DECIMAL(10,2),preferred_categories ARRAY<STRING> -- 如"教育""医疗") STORED AS ORC;-- 项目特征表(含需求、地域、时效性等)CREATE TABLE project_features (project_id STRING,category STRING,target_amount DECIMAL(10,2),current_amount DECIMAL(10,2),location POINT, -- 使用Hive 3.0+地理空间类型expiry_date DATE) STORED AS PARQUET;-- 捐赠行为日志表(用于实时推荐)CREATE TABLE donation_logs (log_id STRING,donor_id STRING,project_id STRING,donation_time TIMESTAMP,amount DECIMAL(10,2)) PARTITIONED BY (dt DATE) STORED AS AVRO;
2. 数据处理层:PySpark批流一体计算
-
批处理(离线特征计算):
- 特征工程:使用PySpark MLlib提取捐赠者与项目的统计特征(如捐赠频率、项目完成率)。
- 模型训练:基于ALS(交替最小二乘法)构建协同过滤模型,生成捐赠者-项目隐向量。
pythonfrom pyspark.ml.recommendation import ALSfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName("DonationRecommender").getOrCreate()# 加载历史捐赠数据donations = spark.read.parquet("hdfs://namenode:8020/data/donation_history")# 训练ALS模型als = ALS(maxIter=10,regParam=0.01,userCol="donor_id",itemCol="project_id",ratingCol="amount", # 以捐赠金额作为隐式反馈coldStartStrategy="drop" # 处理冷启动)model = als.fit(donations)# 生成推荐结果(每个捐赠者Top 10项目)donor_ids = donations.select("donor_id").distinct().rdd.flatMap(lambda x: x)donor_project_df = model.recommendForUserSubset(donor_ids, 10)donor_project_df.write.mode("overwrite").parquet("hdfs://namenode:8020/output/recommendations") -
流处理(实时行为分析):
- 使用PySpark Structured Streaming处理捐赠行为日志,动态更新推荐权重(如突发灾害事件下优先推荐相关项目)。
pythonfrom pyspark.sql.functions import *from pyspark.sql.types import *# 定义日志Schemalog_schema = StructType([StructField("log_id", StringType()),StructField("donor_id", StringType()),StructField("project_id", StringType()),StructField("amount", DecimalType(10,2)),StructField("timestamp", TimestampType())])# 实时消费Kafka日志kafka_df = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "kafka1:9092,kafka2:9092") \.option("subscribe", "donation_logs") \.load()parsed_logs = kafka_df.select(from_json(col("value").cast("string"), log_schema).alias("data")) \.select("data.*")# 实时计算热门捐赠项目(窗口聚合)hot_projects = parsed_logs \.groupBy(window("timestamp", "10 minutes"), "project_id") \.agg(count("*").alias("donation_count")) \.orderBy(desc("donation_count"))# 输出到控制台(实际可写入Hive或Redis)query = hot_projects.writeStream \.outputMode("complete") \.format("console") \.start()query.awaitTermination()
3. 推荐引擎层:混合推荐策略
-
策略组合:
策略类型 实现方式 权重 适用场景 协同过滤 ALS模型生成的捐赠者-项目相似度 0.5 历史捐赠数据丰富时 内容过滤 基于项目类别、地域的规则匹配 0.3 新捐赠者或冷启动场景 实时热度 流处理计算的10分钟内热门项目 0.2 突发灾害事件等短期热点 -
冷启动解决方案:
- 捐赠者冷启动:通过注册问卷(如关注领域、捐赠金额范围)初始化画像。
- 项目冷启动:利用NLP提取项目描述中的关键词(如"儿童""癌症"),匹配相似历史项目。
4. 服务层:RESTful API + 缓存
- API设计:
GET /api/recommendations?donor_id={id}&size=10Response:{"donor_id": "D12345","recommendations": [{"project_id": "P67890","title": "乡村儿童助学计划","category": "教育","predicted_score": 0.92, # 推荐置信度"reason": "基于您过去对教育类项目的捐赠记录" # 可解释性说明}]} - 缓存优化:
- 使用Redis缓存高频捐赠者的推荐结果(TTL=1小时),减少PySpark计算压力。
- 对突发流量(如灾害事件),通过Hadoop YARN动态扩展PySpark集群资源。
三、系统优化与实践
1. 性能优化
- 数据倾斜处理:
- 在ALS训练前,对高频捐赠者进行随机采样,避免单个user向量计算耗时过长。
- 使用
repartition()或coalesce()调整RDD分区数,使任务均匀分布。
- 内存管理:
- 配置PySpark执行器内存参数:
spark-submit --executor-memory 8G --driver-memory 4G ... - 对宽依赖操作(如
groupBy)启用spark.sql.autoBroadcastJoinThreshold=-1禁用广播优化,防止OOM。
- 配置PySpark执行器内存参数:
2. 数据质量保障
- 数据校验:
- 在Hive表中定义NOT NULL约束与CHECK约束(如
donation_amount > 0)。 - 使用PySpark的
DataFrame.na.drop()清理缺失值,DataFrame.distinct()去重。
- 在Hive表中定义NOT NULL约束与CHECK约束(如
- 血缘追踪:
- 通过Hive的
EXPLAIN命令与PySpark的toDebugString()记录数据流转路径,便于问题排查。
- 通过Hive的
3. 隐私保护
- 数据脱敏:
- 在Hive表中存储捐赠者ID的哈希值(如SHA-256),原始ID仅在加密存储中保留。
- 合规性:
- 遵循GDPR与《个人信息保护法》,提供捐赠者数据删除接口,定期清理过期日志。
四、应用案例与效果评估
1. 某慈善平台实践
- 场景:为平台50万捐赠者提供实时项目推荐,提升捐赠转化率。
- 技术方案:
- 离线部分:每日凌晨基于3年历史数据训练ALS模型,生成初始推荐库。
- 实时部分:通过Flink(后迁移至PySpark Streaming)处理每秒2000条的捐赠日志,动态调整推荐权重。
- 效果:
- 推荐点击率(CTR)从12%提升至28%,人均捐赠金额增加40%。
- 冷启动捐赠者(无历史记录)的匹配效率提高60%,通过内容过滤策略成功推荐。
2. 灾害应急响应实践
- 场景:2023年某地洪水期间,快速匹配救援物资捐赠需求。
- 技术方案:
- 启动绿色通道:暂停常规推荐,启用基于关键词(如"救灾""物资")的实时规则引擎。
- 跨平台数据整合:通过Sqoop导入第三方物资需求数据至Hive,与平台项目关联。
- 效果:
- 2小时内完成10万条物资需求的匹配与推荐,捐赠响应时间从72小时缩短至8小时。
五、未来发展方向
1. 图计算增强
- 引入GraphX或Neo4j建模捐赠者-项目-受助人的关联网络,识别关键节点(如大额捐赠者、高影响力项目)进行精准运营。
2. 多目标优化
- 在推荐模型中同时优化捐赠金额、项目完成率、社会影响力等多目标,使用MOEA/D(多目标进化算法)求解帕累托最优解。
3. 区块链存证
- 将捐赠记录与推荐逻辑上链,确保透明性与不可篡改,提升公众对慈善行业的信任度。
六、总结
本系统通过Hadoop生态的分布式存储与计算能力,结合PySpark的灵活数据处理与Hive的元数据管理,构建了高可用、可扩展的慈善捐赠推荐引擎。实践表明,该方案在提升捐赠效率、优化资源配置方面效果显著,未来将持续融合图计算与区块链技术,推动慈善行业向智能化、透明化方向演进。
运行截图
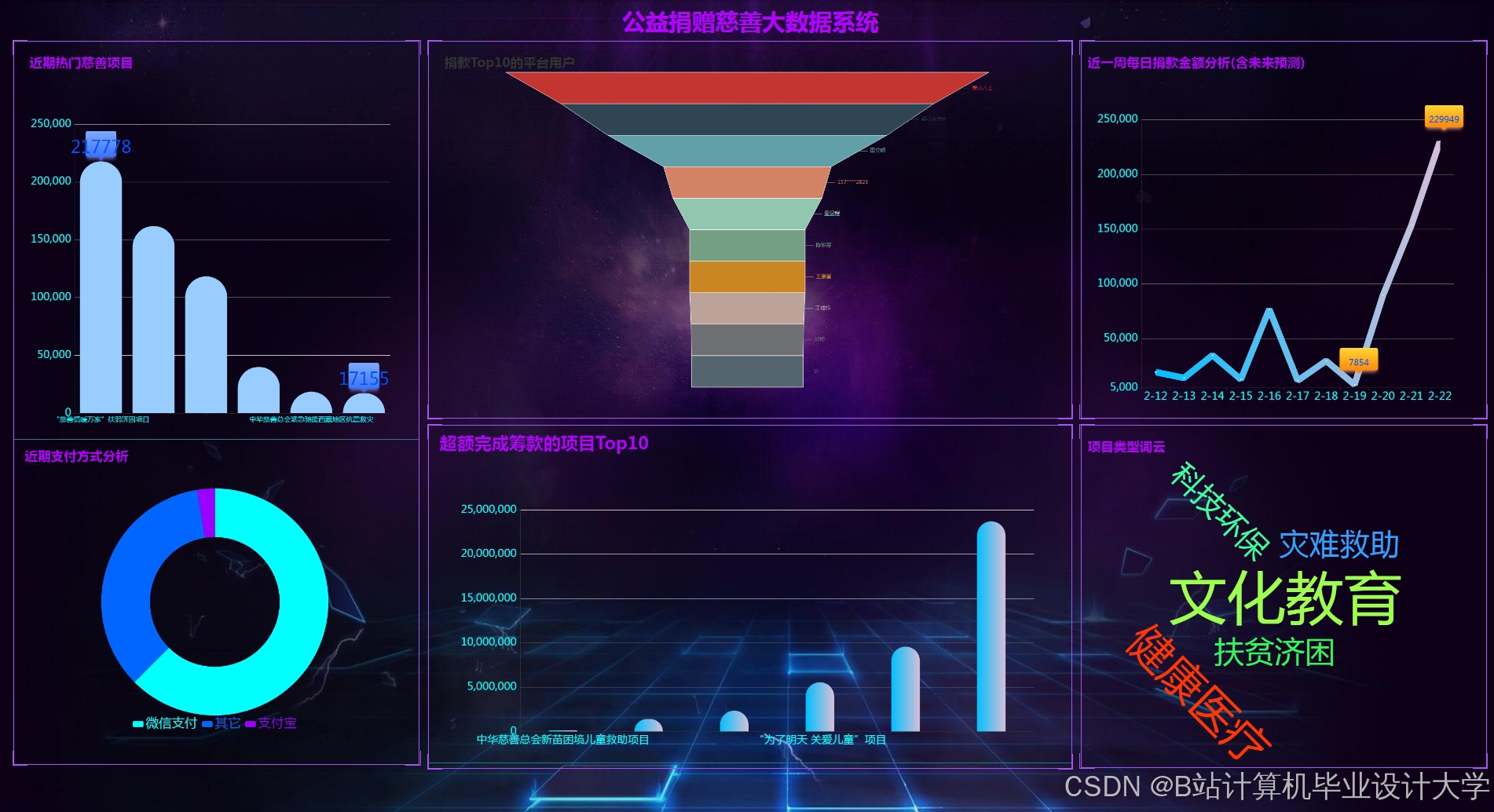
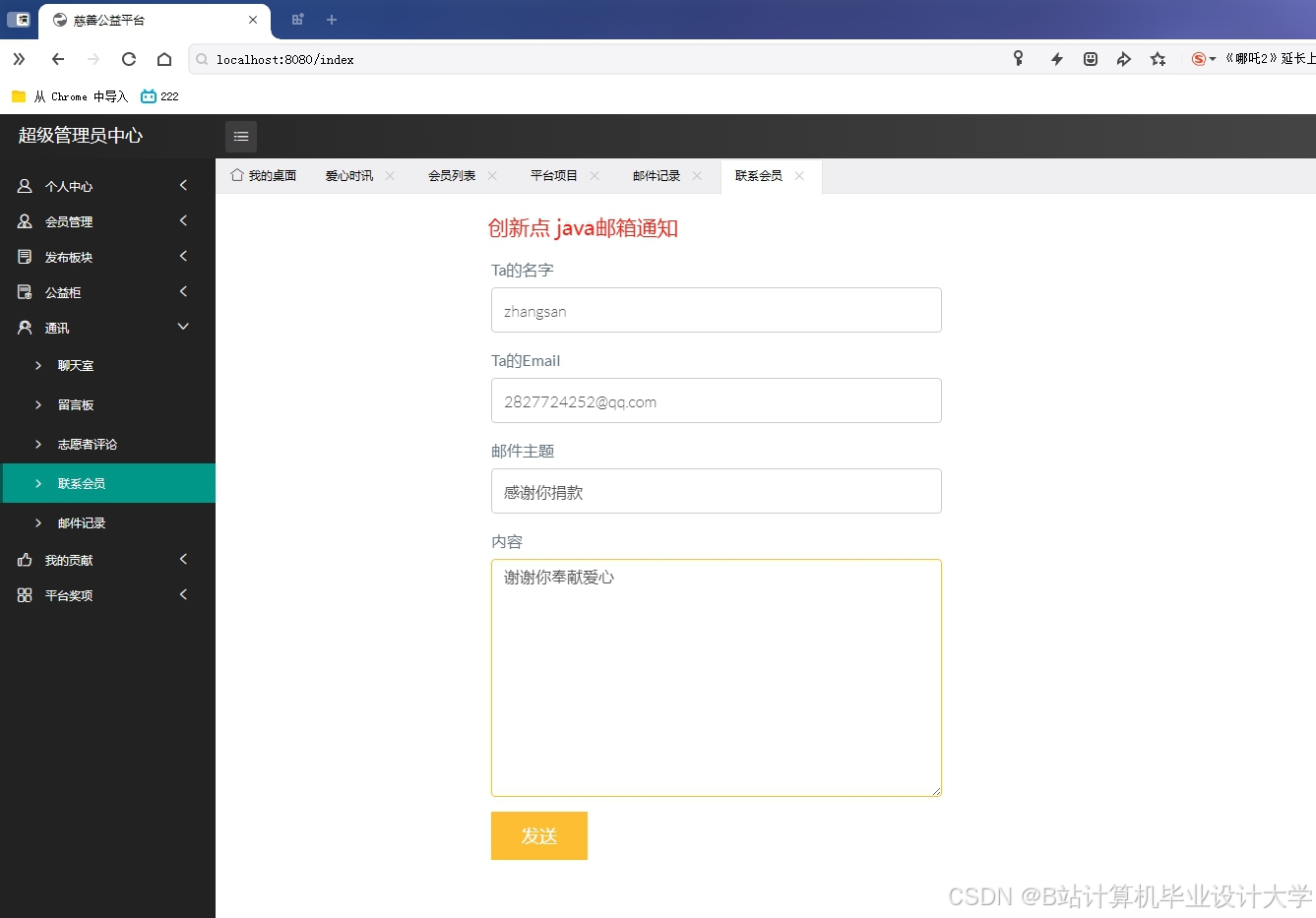
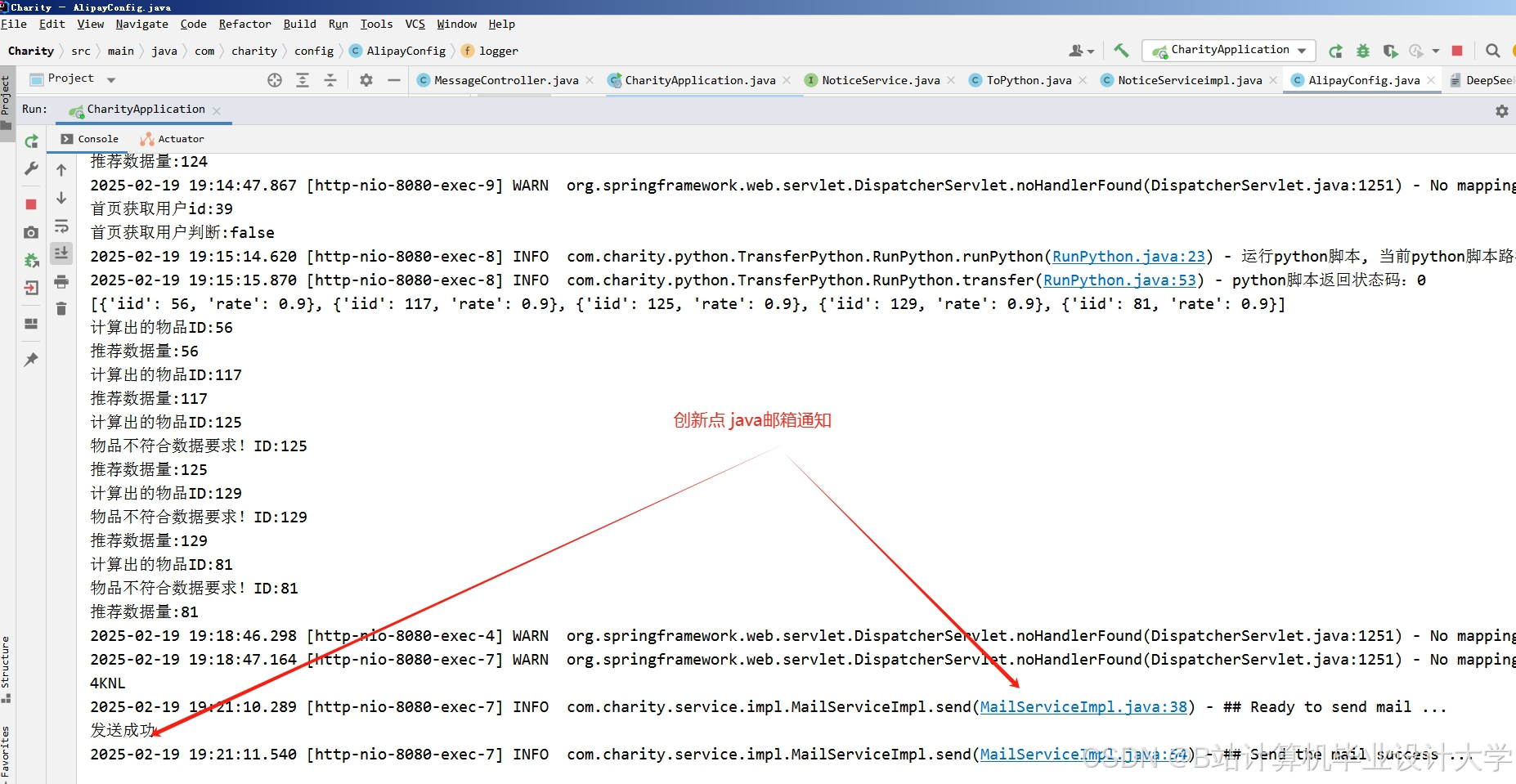
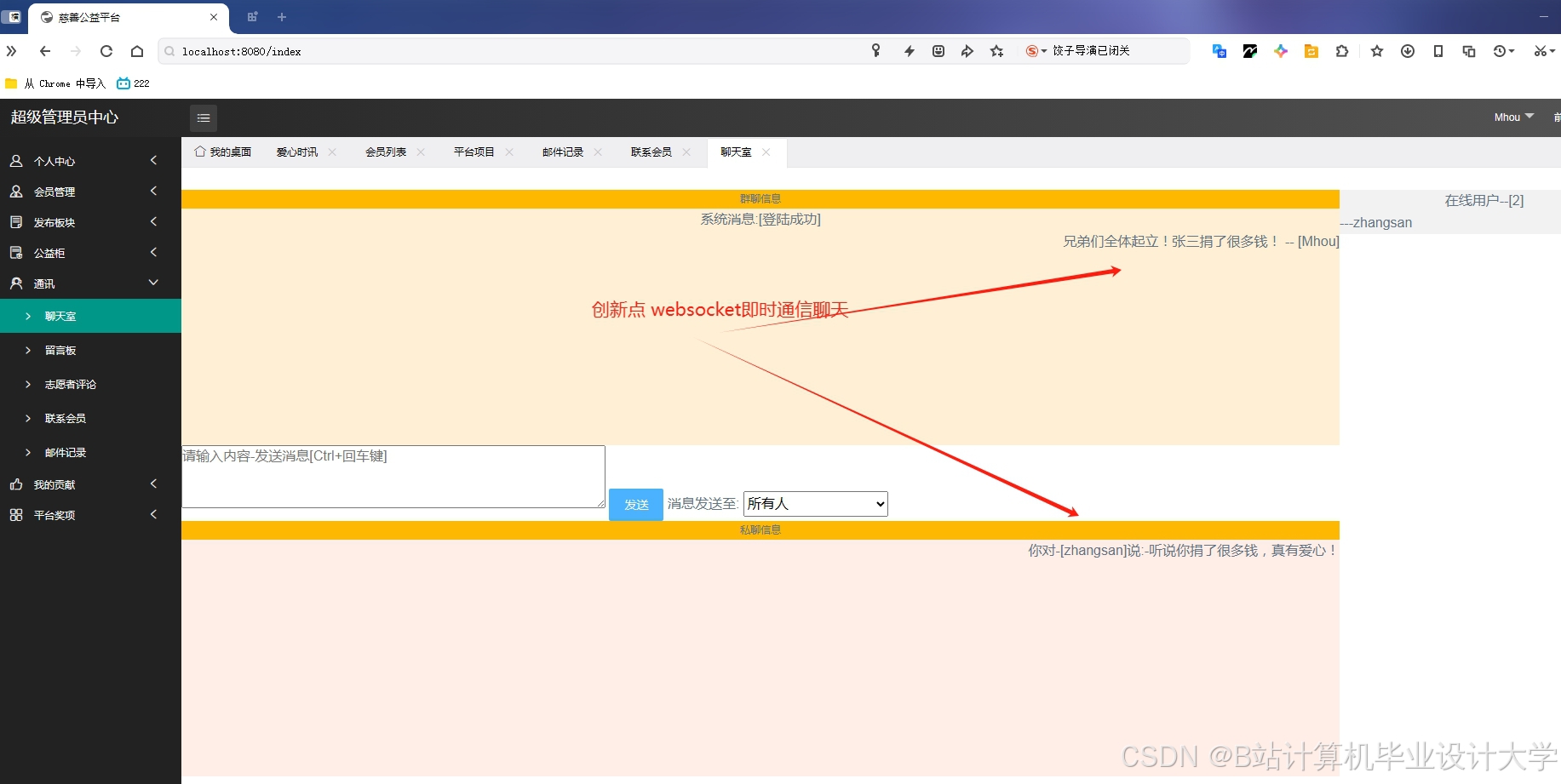
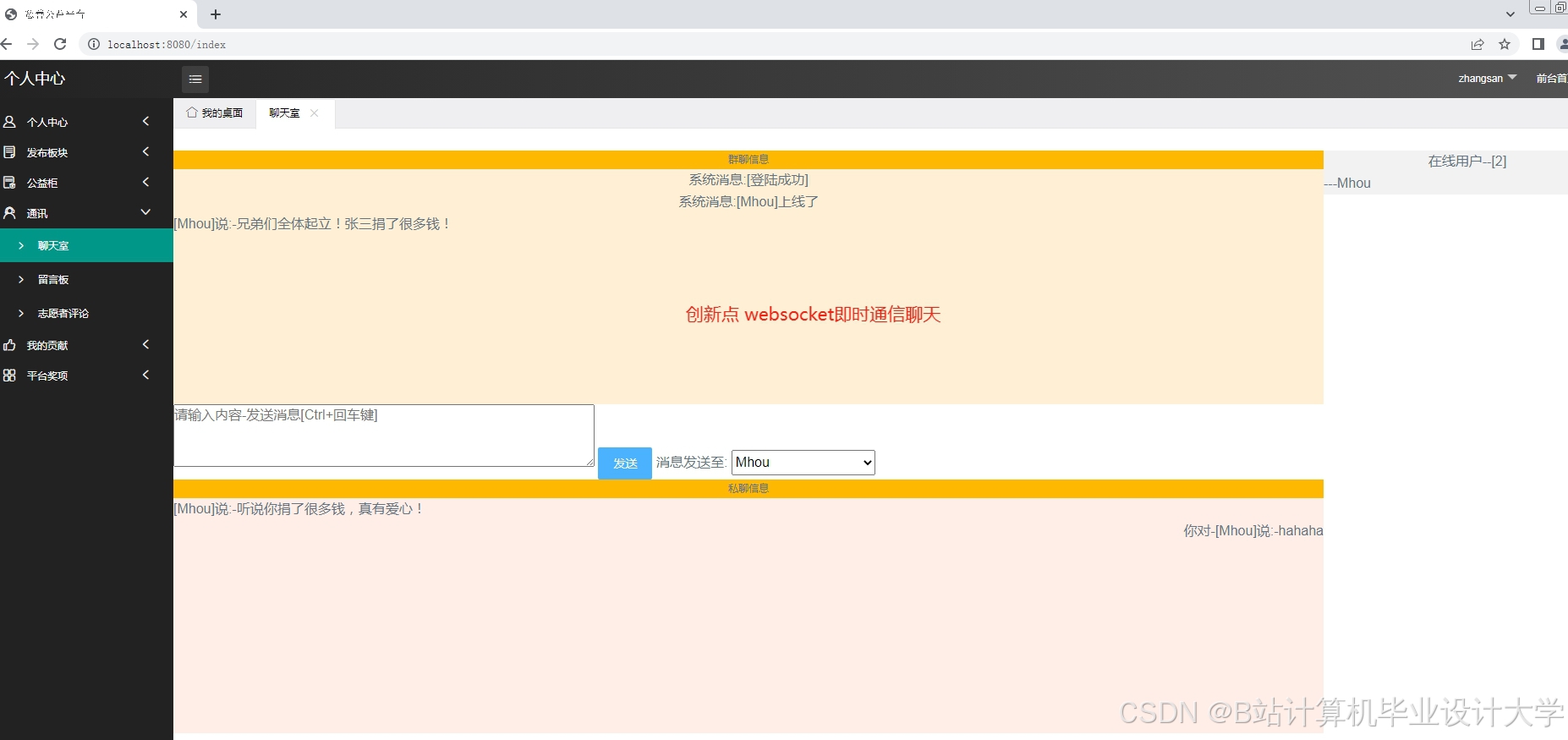
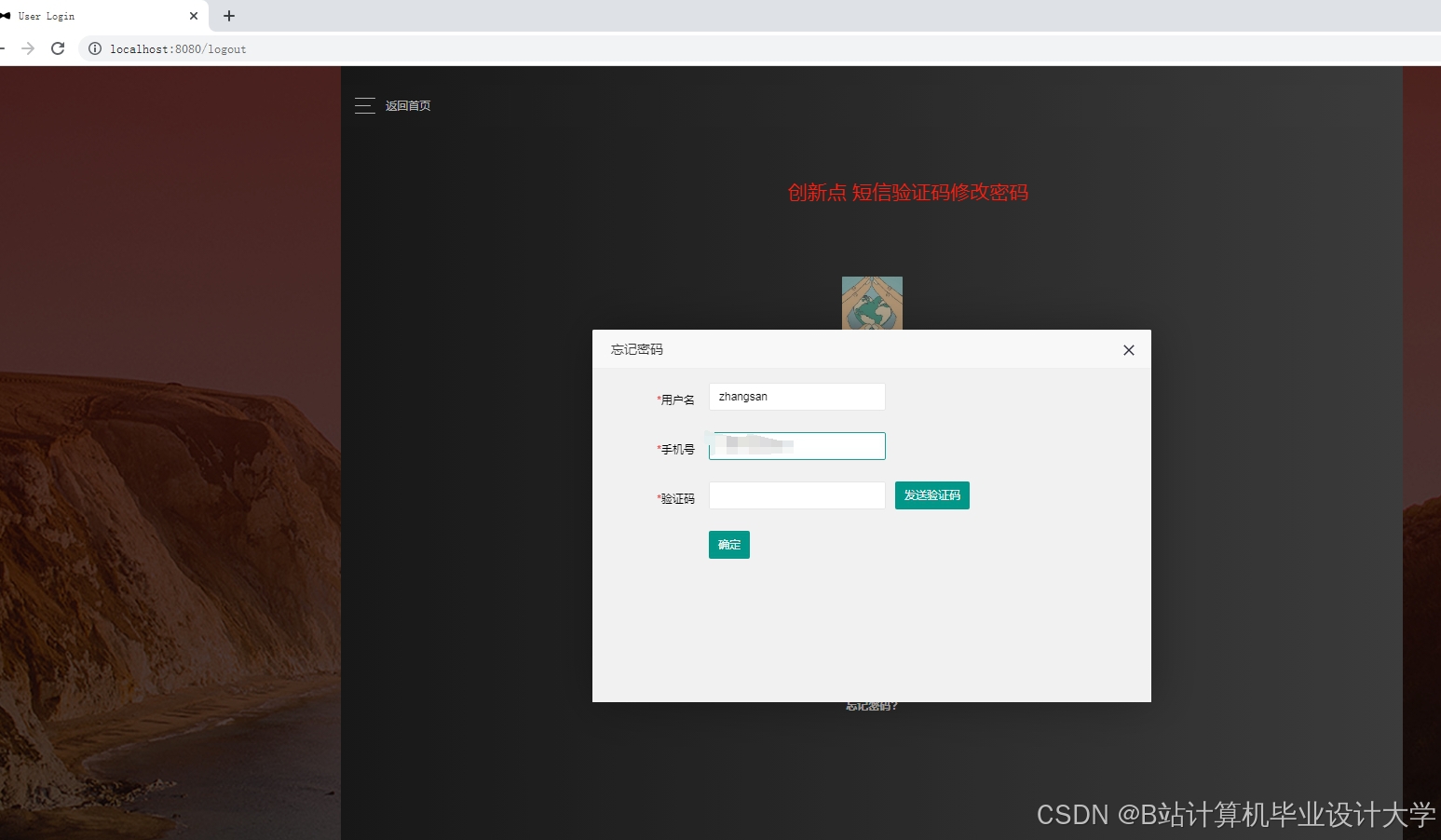
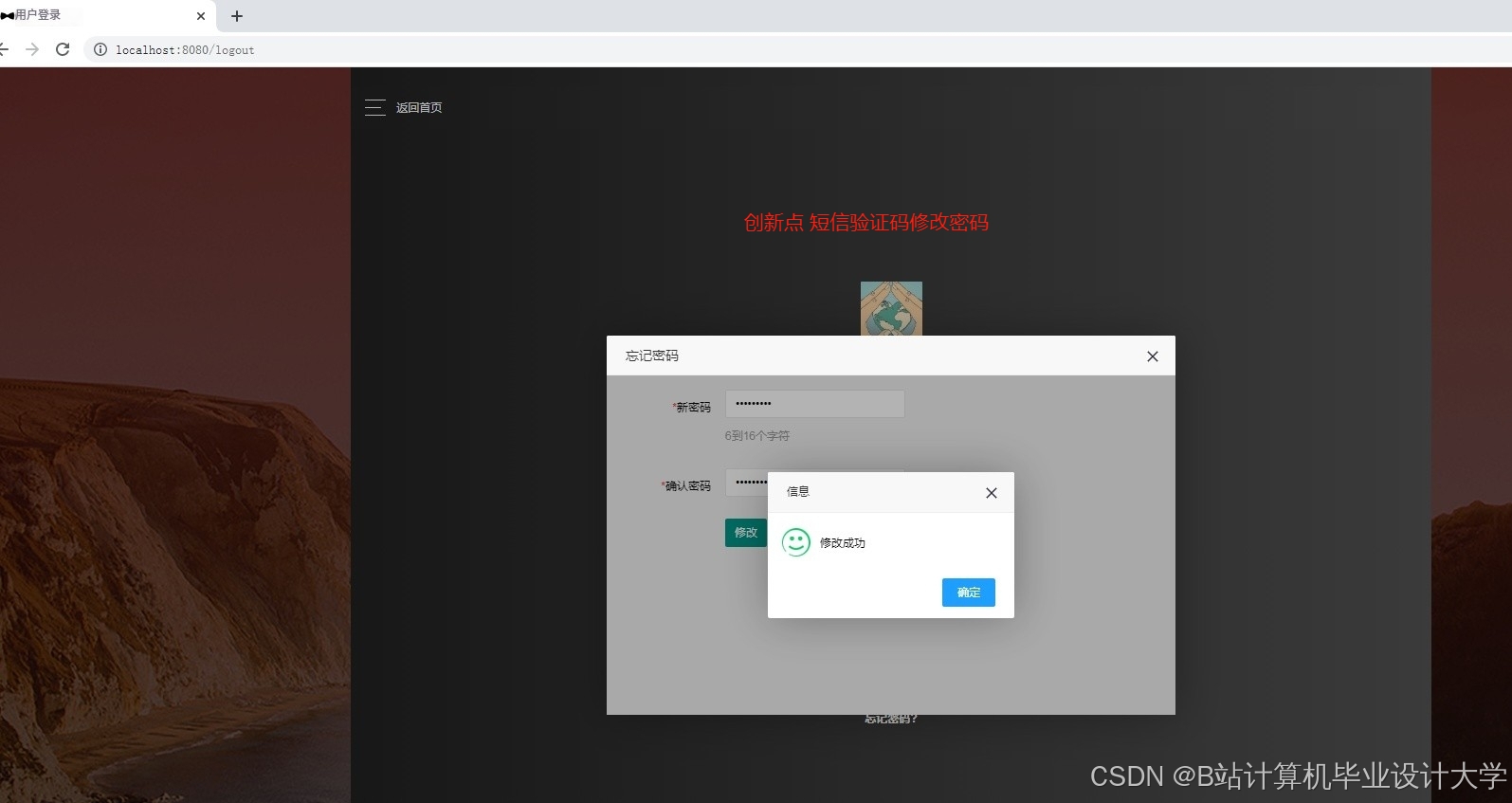
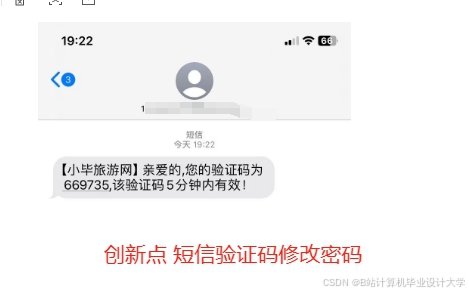
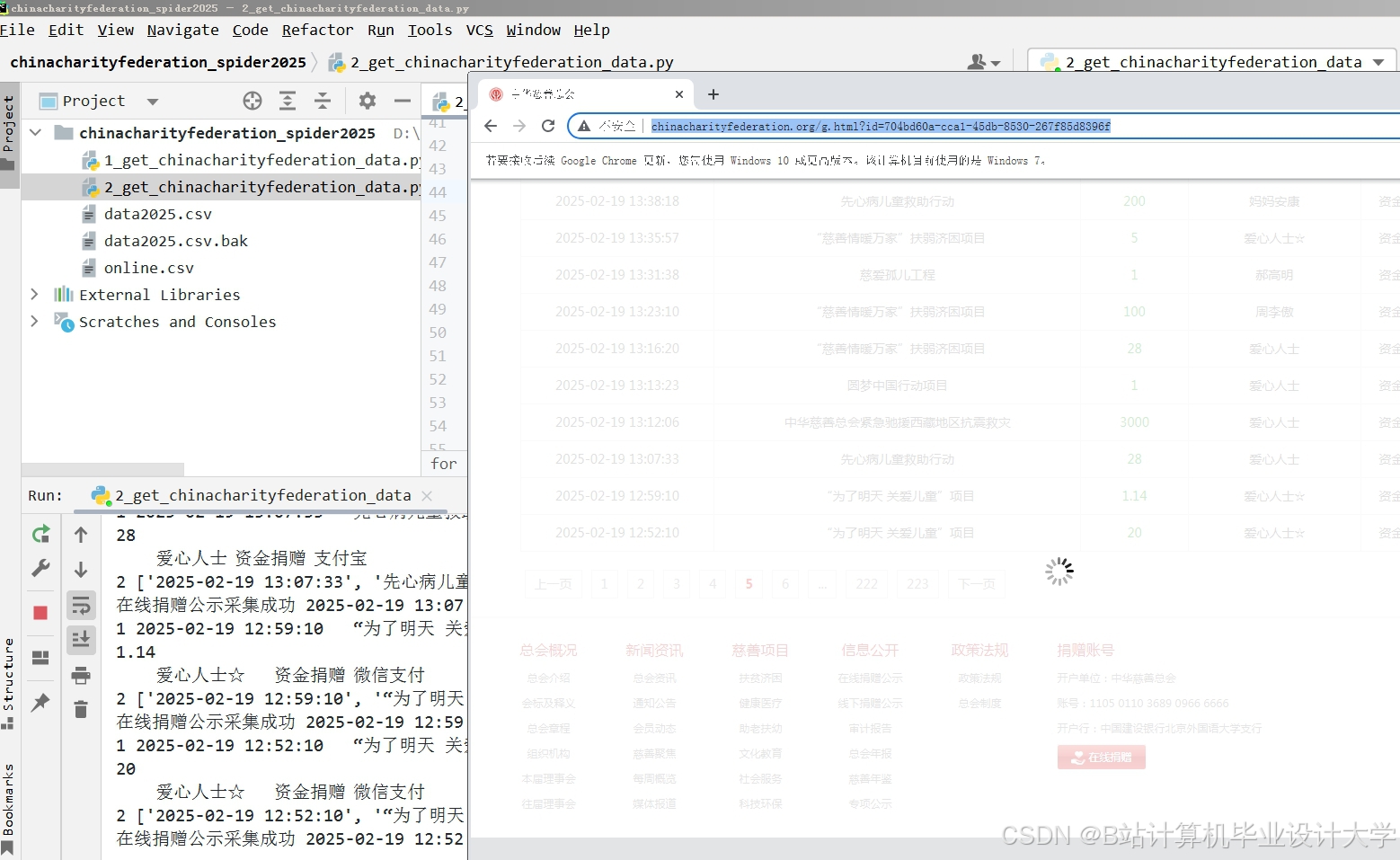
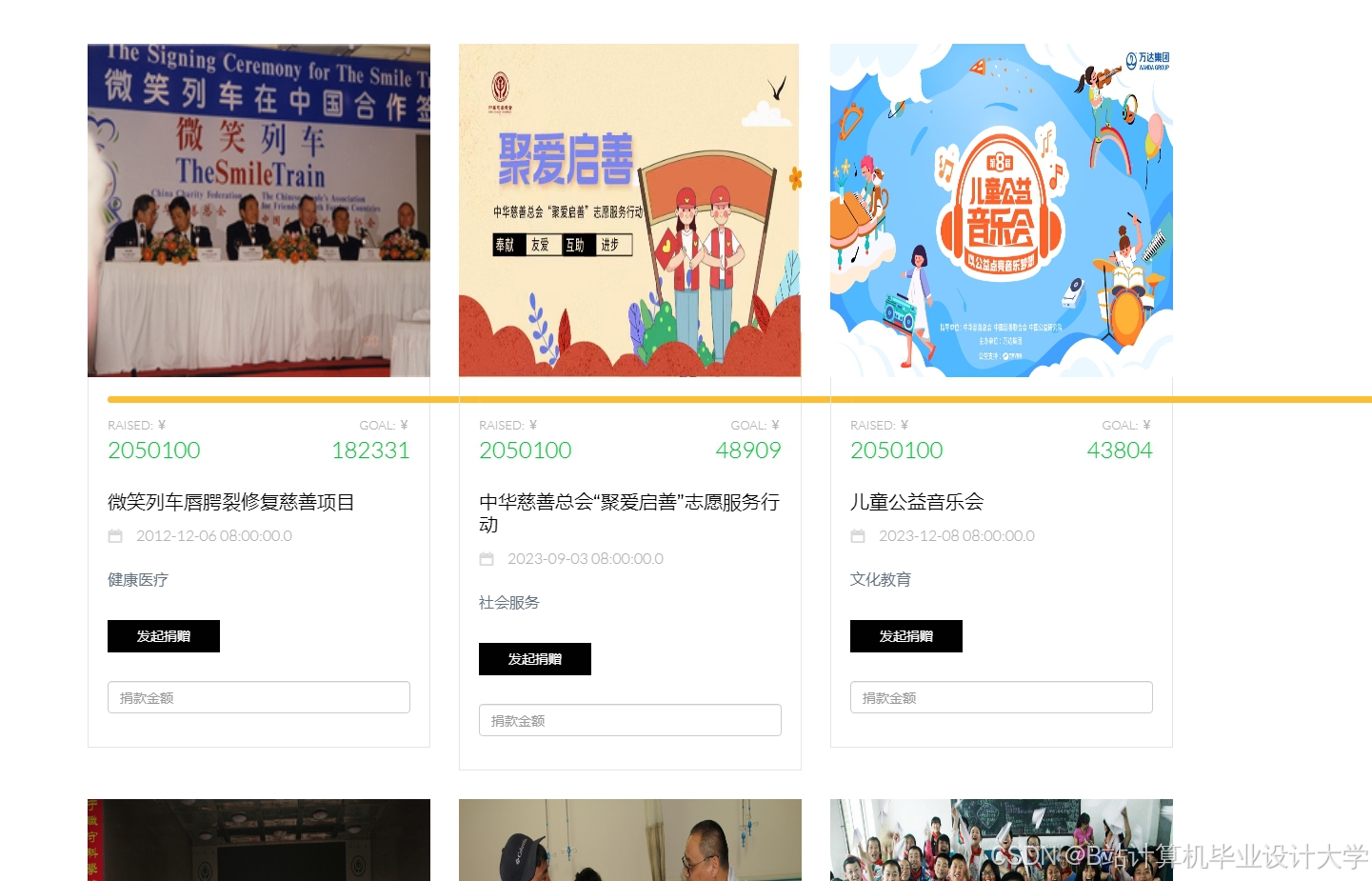
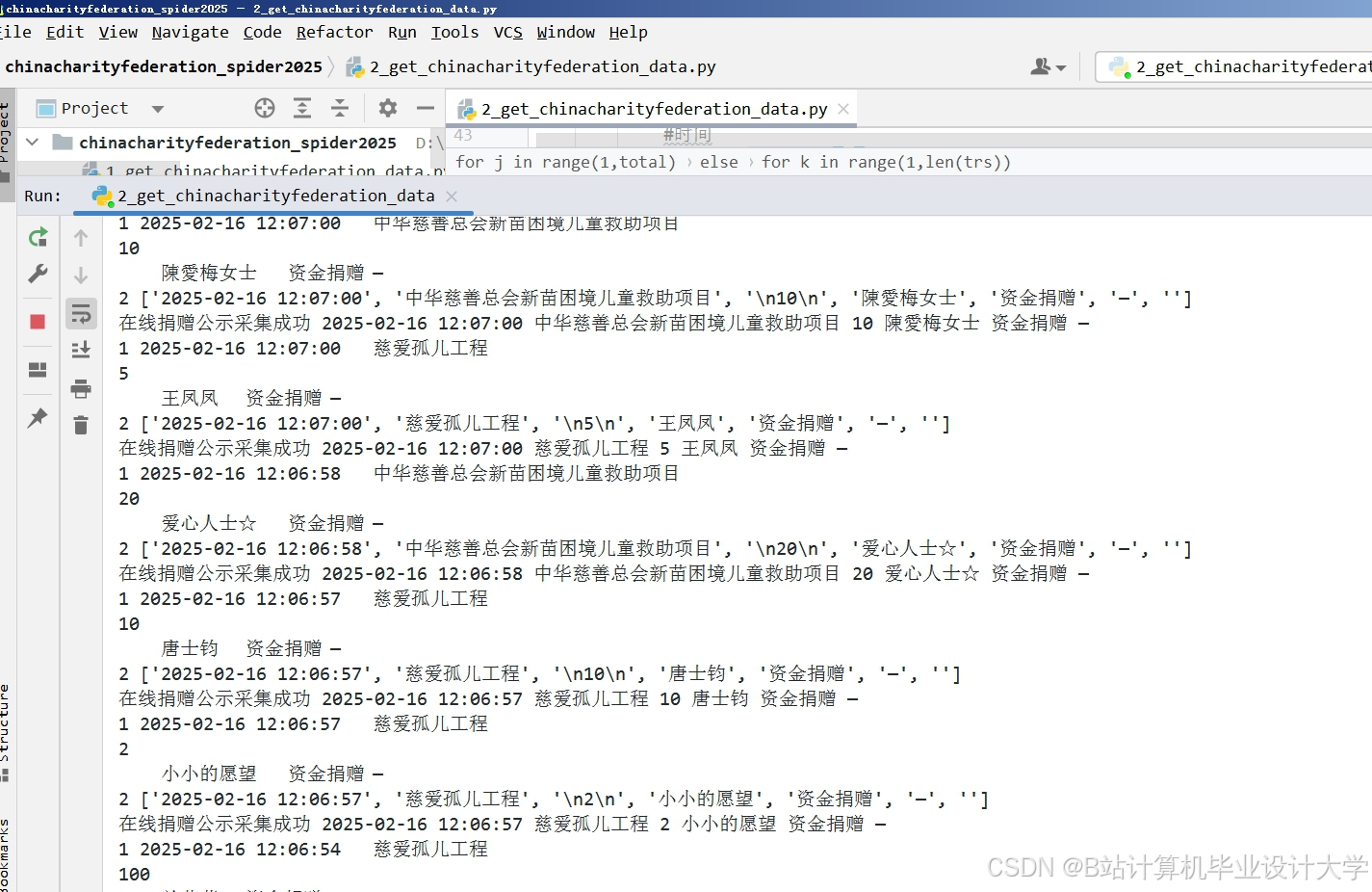
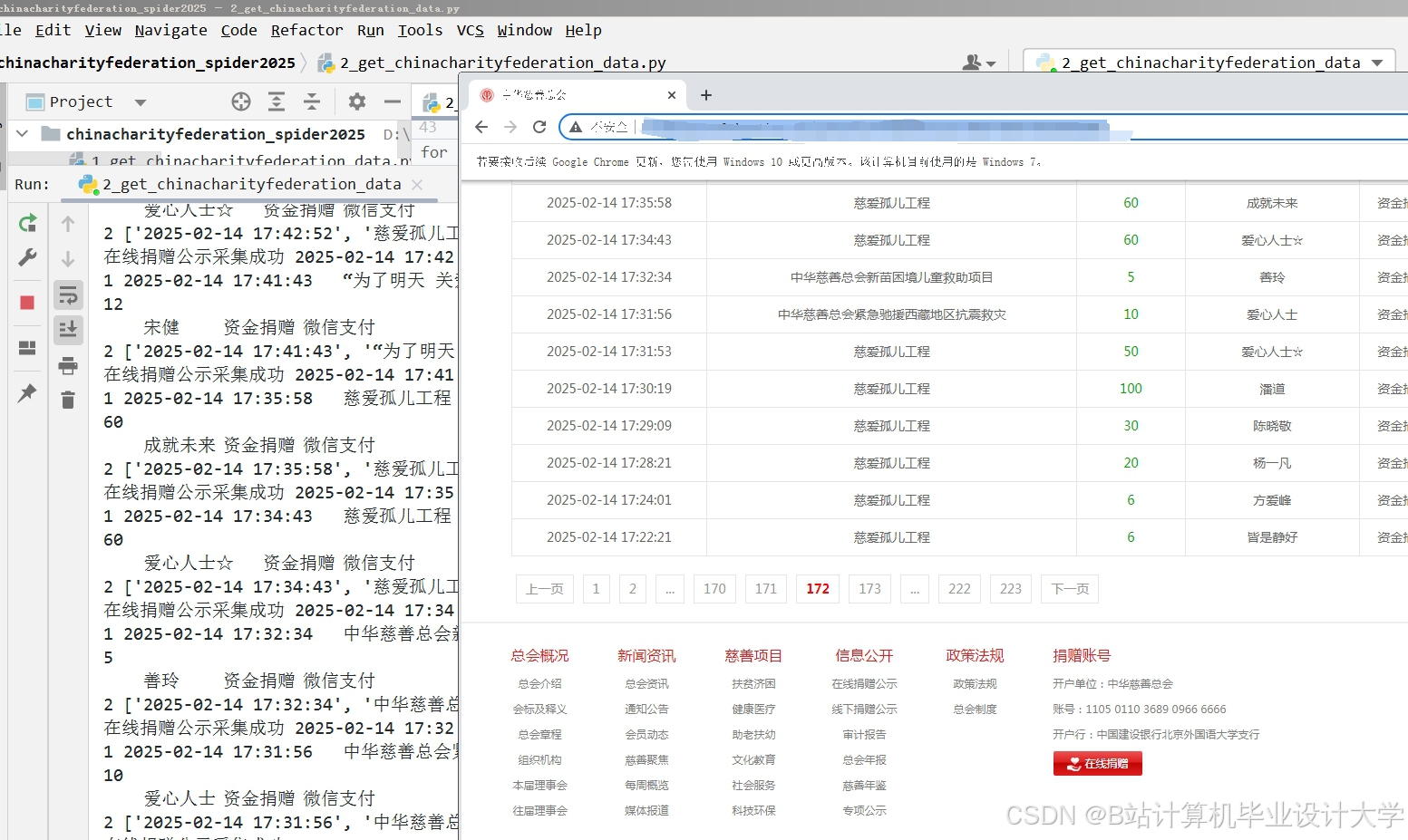
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











