




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
# 基于Python的智能路线规划数据分析与个性化推荐系统设计与实现
## 摘要
随着城市化进程的加速和智能交通系统的发展,传统的路线规划应用已无法满足用户日益增长的个性化出行需求。本文设计并实现了一个基于Python的智能路线规划数据分析与个性化推荐系统,该系统集成了路线规划、数据分析和智能推荐三大核心功能。
系统采用Django Web框架构建,运用多种机器学习算法实现个性化推荐功能。在推荐算法方面,本文提出了一种融合基于内容推荐、协同过滤、地理位置聚类和矩阵分解的混合推荐算法,通过分析用户历史出行数据,挖掘用户出行偏好和行为模式,为用户提供精准的个性化路线推荐。在数据分析方面,系统提供了多维度的出行数据分析功能,包括时间维度分析、空间维度分析和用户行为分析,并通过可视化图表直观展示分析结果。
系统成功实现了四种推荐算法的集成,包括基于内容的推荐、协同过滤、地理位置聚类和矩阵分解算法,能够根据用户的历史出行数据提供个性化的路线推荐。系统界面友好,功能完整,能够有效提升用户出行体验。本研究为智能交通领域的个性化服务提供了新的解决方案,具有重要的理论意义和实用价值。
**关键词:** 路线规划;推荐系统;数据分析;机器学习;Django;个性化服务
## Abstract
With the acceleration of urbanization and the development of intelligent transportation systems, traditional route planning applications can no longer meet users' growing personalized travel needs. This paper designs and implements an intelligent route planning data analysis and personalized recommendation system based on Python, which integrates three core functions: route planning, data analysis, and intelligent recommendation.
The system is built using the Django Web framework and employs various machine learning algorithms to implement personalized recommendation functions. In terms of recommendation algorithms, this paper proposes a hybrid recommendation algorithm that integrates collaborative filtering, geographic location clustering, and matrix factorization. By analyzing users' historical travel data, the system mines user travel preferences and behavior patterns to provide accurate personalized route recommendations. In terms of data analysis, the system provides multi-dimensional travel data analysis functions, including temporal dimension analysis, spatial dimension analysis, and user behavior analysis, and intuitively displays analysis results through visualization charts.
The system successfully integrates four recommendation algorithms, including content-based recommendation, collaborative filtering, geographic location clustering, and matrix factorization, providing personalized route recommendations based on users' historical travel data. The system has a user-friendly interface and comprehensive functionality, which can effectively improve user travel experience. This research provides a new solution for personalized services in the field of intelligent transportation, with important theoretical significance and practical value.
**Keywords:** Route Planning; Recommendation System; Data Analysis; Machine Learning; Django; Personalized Service
## 第一章 绪论
### 1.1 研究背景与意义
#### 1.1.1 研究背景
随着我国城市化进程的快速推进和经济社会的持续发展,城市交通系统面临着前所未有的挑战。据统计,截至2023年,我国城镇化率已超过65%,城市人口规模不断扩大,城市交通需求呈现爆发式增长。传统的交通管理模式和出行服务已难以满足人们日益多样化、个性化的出行需求。
在信息技术快速发展的背景下,智能交通系统(Intelligent Transportation System, ITS)作为解决城市交通问题的重要手段,受到了广泛关注。路线规划作为智能交通系统的核心组成部分,其发展经历了从简单的最短路径算法到考虑实时交通状况的动态路径规划,再到基于用户偏好的个性化路线推荐的演进过程。
当前主流的导航应用如高德地图、百度地图等,虽然在基础路线规划功能方面已相对成熟,但在个性化推荐和用户行为分析方面仍存在不足。这些应用主要基于实时交通数据提供最优路线,缺乏对用户历史出行数据的深度挖掘和个性化偏好的精准识别。同时,现有系统在数据分析和可视化方面的功能相对薄弱,无法为用户提供深入的出行行为洞察。
#### 1.1.2 研究意义
本研究的理论意义主要体现在以下几个方面:
**(1)推荐算法理论创新**
本文提出了一种融合四种推荐算法的混合推荐模型,将基于内容的推荐、协同过滤、地理位置聚类和矩阵分解算法有机结合,形成了适用于路线推荐场景的新型算法框架。该框架不仅考虑了用户间的相似性和路线内容特征,还充分利用了地理空间信息和用户潜在偏好,为推荐系统理论研究提供了新的思路。
**(2)数据挖掘方法拓展**
通过对用户出行数据的多维度分析,本研究拓展了数据挖掘技术在交通领域的应用范围。提出了基于时间序列分析的出行模式识别方法和基于空间聚类的热点区域发现算法,丰富了交通数据分析的理论体系。
**(3)系统架构设计优化**
本研究设计了一种模块化、可扩展的智能交通系统架构,该架构将路线规划、数据分析和推荐系统有机集成,为类似系统的设计提供了参考模式。
本研究的实用价值主要表现在:
**(1)提升用户出行体验**
通过个性化推荐功能,系统能够根据用户的历史出行数据和实时需求,提供更加精准的路线建议,有效减少用户的决策时间和出行成本。
**(2)优化城市交通资源配置**
系统的数据分析功能能够识别城市交通的热点区域和拥堵时段,为交通管理部门制定交通政策和优化交通资源配置提供数据支撑。
**(3)促进智能交通产业发展**
本研究成果可为相关企业和研究机构提供技术参考,推动智能交通领域的技术创新和产业升级。
### 1.2 国内外研究现状
#### 1.2.1 路线规划技术研究现状
路线规划技术的发展可以追溯到20世纪50年代Dijkstra算法的提出。经过几十年的发展,路线规划算法已从简单的静态最短路径算法发展为考虑多种约束条件的动态路径规划算法。
**国外研究现状:**
在算法层面,Google Maps采用了改进的A*算法和分层路网结构,能够在大规模路网中快速计算最优路径。Waze通过众包模式收集实时交通信息,实现了基于实时数据的动态路径规划。在学术研究方面,Hart等人提出的A*算法至今仍是路径规划的经典算法;Geisberger等人提出的Contraction Hierarchies算法大幅提升了大规模路网的查询效率。
**国内研究现状:**
国内在路线规划技术方面起步较晚,但发展迅速。百度地图、高德地图等产品在路径规划算法优化、实时交通数据处理等方面已达到国际先进水平。清华大学、北京理工大学等高校在路径规划算法理论研究方面也取得了重要进展。
#### 1.2.2 推荐系统技术研究现状
推荐系统作为信息过滤和个性化服务的重要技术,在电子商务、社交网络、内容分发等领域得到了广泛应用。
**协同过滤算法:**
协同过滤是推荐系统中最经典的算法之一,分为基于用户的协同过滤和基于物品的协同过滤。Amazon在早期就采用了基于物品的协同过滤算法,取得了良好的推荐效果。Netflix Prize竞赛进一步推动了协同过滤算法的发展,涌现出了矩阵分解、深度学习等新方法。
**基于内容的推荐:**
基于内容的推荐通过分析物品的特征属性为用户推荐相似物品。在路线推荐场景中,路线的地理特征、距离、时间等属性都可以作为内容特征。
**混合推荐算法:**
为了克服单一算法的局限性,研究者提出了多种混合推荐策略。Netflix的推荐系统就采用了多种算法的加权组合,显著提升了推荐效果。
#### 1.2.3 交通数据分析研究现状
交通数据分析是智能交通系统的重要组成部分,主要包括交通流预测、出行模式识别、交通异常检测等方面。
**时间序列分析:**
交通流数据具有明显的时间周期性特征,ARIMA模型、线性回归等方法被广泛应用于交通流预测。统计学方法在交通预测领域有着良好的应用效果。
**空间数据分析:**
基于GPS轨迹数据的空间分析能够识别用户的出行模式和热点区域。聚类算法如K-means、DBSCAN等被广泛应用于轨迹数据分析。
#### 1.2.4 现有研究的不足
通过对国内外研究现状的分析,发现现有研究存在以下不足:
1. **算法单一性问题**:现有路线推荐系统多采用单一算法,难以充分利用多源数据的优势。
2. **个性化程度不足**:大多数系统仍以通用性推荐为主,缺乏对用户个性化偏好的深度挖掘。
3. **数据分析功能薄弱**:现有系统在用户行为分析和数据可视化方面功能相对简单。
4. **系统集成度不高**:路线规划、推荐和数据分析功能往往相互独立,缺乏有机集成。
### 1.3 研究目标与内容
#### 1.3.1 研究目标
本研究的总体目标是设计并实现一个集路线规划、数据分析和个性化推荐于一体的智能交通服务系统。具体目标包括:
**(1)技术目标**
- 设计一种融合多种推荐算法的混合推荐模型,提高推荐准确率
- 构建多维度的交通数据分析框架,实现用户出行行为的深度挖掘
- 开发高性能、可扩展的Web应用系统,支持大规模用户并发访问
**(2)功能目标**
- 实现基础的路线规划功能,支持多种出行方式
- 提供个性化的路线推荐服务,满足用户个性化需求
- 构建完善的数据分析和可视化功能,帮助用户了解出行模式
**(3)性能目标**
- 实现稳定可靠的推荐算法
- 保证系统响应速度和用户体验
- 支持多用户并发访问
#### 1.3.2 研究内容
本研究的主要内容包括以下几个方面:
**(1)理论研究**
- 深入研究推荐系统理论,分析各种推荐算法的优缺点
- 研究交通数据挖掘理论,探索适用于路线推荐的数据分析方法
- 分析Web系统架构设计理论,设计高性能的系统架构
**(2)算法设计**
- 设计基于内容的推荐算法,分析用户历史出行偏好和行为模式
- 设计基于物品的协同过滤算法,挖掘路线间的相似性
- 设计基于地理位置的推荐算法,利用空间信息提升推荐效果
- 设计基于矩阵分解的推荐算法,发现用户潜在偏好
- 设计混合推荐算法,融合四种算法的优势
**(3)系统实现**
- 基于Django框架实现Web应用系统
- 设计并实现数据库模型,支持复杂的数据查询和分析
- 实现用户界面,提供良好的用户体验
- 集成地图API,实现路线规划和可视化功能
**(4)测试评估**
- 设计测试方案,验证系统功能的正确性
- 评估推荐算法的性能,分析各种算法的优缺点
- 进行用户体验测试,收集用户反馈并优化系统
### 1.4 研究方法与技术路线
#### 1.4.1 研究方法
本研究采用理论分析与实验验证相结合的研究方法:
**(1)文献调研法**
通过查阅国内外相关文献,深入了解路线规划、推荐系统和数据挖掘等领域的研究现状和发展趋势,为本研究提供理论基础。
**(2)算法设计法**
基于理论分析,设计适用于路线推荐场景的算法模型,并通过数学推导验证算法的可行性。
**(3)原型开发法**
采用敏捷开发方法,快速构建系统原型,通过迭代开发不断完善系统功能。
**(4)实验验证法**
通过对比实验验证算法性能,使用真实数据测试系统功能,确保研究成果的可靠性。
#### 1.4.2 技术路线
本研究的技术路线如下:
```
需求分析 → 系统设计 → 算法实现 → 系统开发 → 测试评估 → 优化完善
↓ ↓ ↓ ↓ ↓ ↓
理论研究 架构设计 核心算法 功能实现 性能测试 系统优化
```
**第一阶段:需求分析与理论研究**
- 分析用户需求和系统功能需求
- 深入研究相关理论和技术
- 确定技术方案和实现路径
**第二阶段:系统设计**
- 设计系统总体架构
- 设计数据库模型
- 设计用户界面
**第三阶段:算法实现**
- 实现各种推荐算法
- 设计混合推荐策略
- 优化算法性能
**第四阶段:系统开发**
- 实现Web应用系统
- 集成各功能模块
- 完善用户界面
**第五阶段:测试评估**
- 进行功能测试
- 评估算法性能
- 收集用户反馈
**第六阶段:优化完善**
- 根据测试结果优化系统
- 完善文档和部署方案
### 1.5 论文组织结构
本论文共分为七章,各章内容安排如下:
**第一章 绪论**
介绍研究背景、意义、目标和内容,分析国内外研究现状,阐述研究方法和技术路线。
**第二章 相关理论与技术基础**
系统阐述路线规划、推荐系统、数据挖掘等相关理论基础,为后续研究提供理论支撑。
**第三章 系统需求分析与总体设计**
分析系统功能需求和非功能需求,设计系统总体架构和数据库模型。
**第四章 核心算法设计与实现**
详细介绍各种推荐算法的设计思路和实现方法,重点阐述混合推荐算法的设计。
**第五章 系统详细设计与实现**
介绍系统的详细设计和实现过程,包括数据层、业务逻辑层和表示层的实现。
**第六章 系统测试与性能评估**
介绍系统测试方案和测试结果,评估推荐算法的性能和系统的整体表现。
**第七章 总结与展望**
总结研究工作和主要贡献,分析存在的不足,展望未来的研究方向。
通过以上章节的有机组织,本论文将全面、系统地阐述基于Python的智能路线规划数据分析与个性化推荐系统的设计与实现过程,为相关领域的研究和应用提供参考。
## 第二章 相关理论与技术基础
### 2.1 路线规划算法理论
#### 2.1.1 经典路径规划算法
路径规划问题本质上是在图论框架下寻找从起点到终点的最优路径问题。经典的路径规划算法为现代智能路线规划系统奠定了理论基础。
**(1)Dijkstra算法**
Dijkstra算法是解决单源最短路径问题的经典算法,由荷兰计算机科学家Edsger Dijkstra于1956年提出。该算法的核心思想是采用贪心策略,每次选择距离起点最近的未访问节点进行扩展。
算法的时间复杂度为O((V+E)logV),其中V为节点数,E为边数。虽然Dijkstra算法保证能找到最优解,但在大规模路网中计算效率较低。
**(2)A*算法**
A*算法是Dijkstra算法的改进版本,由Peter Hart、Nils Nilsson和Bertram Raphael于1968年提出。该算法引入了启发式函数h(n),通过估计从当前节点到目标节点的距离来指导搜索方向。
A*算法的评估函数为:f(n) = g(n) + h(n)
其中g(n)表示从起点到节点n的实际距离,h(n)表示从节点n到终点的启发式距离。当启发式函数满足可接受性条件时,A*算法能够保证找到最优解。
**(3)双向搜索算法**
双向搜索算法同时从起点和终点开始搜索,当两个搜索方向相遇时即找到最优路径。该算法能够显著减少搜索空间,提高计算效率。
#### 2.1.2 现代路径规划技术
随着路网规模的不断扩大和实时性要求的提高,传统算法已无法满足实际应用需求。现代路径规划技术主要包括:
**(1)分层路网技术**
分层路网技术将道路网络按照重要性分为多个层次,高层次包含主要道路,低层次包含次要道路。查询时首先在高层次路网中找到大致路径,然后在低层次路网中细化路径。这种方法能够大幅提高查询效率。
**(2)预处理技术**
预处理技术通过离线计算存储部分路径信息,在线查询时直接使用预计算结果。典型的预处理技术包括:
- **Contraction Hierarchies (CH)**:通过节点收缩操作构建分层图结构
- **Hub Labeling**:为每个节点预计算到重要节点的距离
- **Transit Node Routing**:识别长距离路径必经的重要节点
**(3)动态路径规划**
动态路径规划考虑实时交通状况,能够根据当前路况调整路径选择。主要技术包括:
- **实时交通数据融合**:整合多源交通数据,包括浮动车数据、路侧检测器数据等
- **交通流预测**:基于历史数据和机器学习算法预测未来交通状况
- **自适应路径调整**:根据实时路况动态调整推荐路径
### 2.2 推荐系统理论基础
推荐系统是信息过滤技术的重要应用,旨在为用户推荐可能感兴趣的物品或服务。在路线推荐场景中,推荐系统需要根据用户的历史出行数据和当前需求,为用户推荐合适的路线。
#### 2.2.1 协同过滤算法
协同过滤是推荐系统中最经典和应用最广泛的算法之一,其基本思想是利用用户群体的智慧进行推荐。
**(1)基于用户的协同过滤(User-based CF)**
基于用户的协同过滤算法通过寻找与目标用户兴趣相似的用户群体,将这些相似用户喜欢的物品推荐给目标用户。
用户相似度计算公式(余弦相似度):
```
sim(u,v) = cos(u,v) = (u·v)/(||u||×||v||)
```
预测评分公式:
```
P(u,i) = r̄u + (Σv∈N(u) sim(u,v)×(rv,i - r̄v))/(Σv∈N(u) |sim(u,v)|)
```
其中,r̄u表示用户u的平均评分,N(u)表示与用户u最相似的k个用户集合。
**(2)基于物品的协同过滤(Item-based CF)**
基于物品的协同过滤算法通过计算物品间的相似度,将与用户历史偏好物品相似的物品推荐给用户。相比基于用户的协同过滤,基于物品的协同过滤在物品数量相对稳定的场景中表现更好。
物品相似度计算公式:
```
sim(i,j) = cos(i,j) = (Σu∈U ru,i×ru,j)/(√(Σu∈U r²u,i)×√(Σu∈U r²u,j))
```
在路线推荐场景中,本研究采用基于物品的协同过滤算法,将路线视为物品,通过分析用户对不同路线的偏好程度,计算路线间的相似度,为用户推荐相似的路线。
**(3)协同过滤算法的优缺点**
优点:
- 不需要物品的内容信息,适用性广
- 能够发现用户潜在的兴趣点
- 推荐结果具有较好的多样性
缺点:
- 存在冷启动问题,对新用户和新物品推荐效果差
- 数据稀疏性问题影响推荐质量
- 计算复杂度较高,扩展性有限
#### 2.2.2 基于内容的推荐
基于内容的推荐算法通过分析物品的内容特征,为用户推荐与其历史偏好物品相似的物品。在路线推荐场景中,路线的内容特征包括地理位置、距离、时间、路径类型等。
**(1)特征提取与表示**
路线特征可以分为以下几类:
- **地理特征**:起点坐标、终点坐标、途经区域等
- **距离特征**:路线长度、直线距离等
- **时间特征**:预计行驶时间、历史平均时间等
- **路径特征**:道路类型、拥堵程度等
**(2)相似度计算**
基于内容的推荐通常使用向量空间模型表示物品特征,通过计算特征向量间的相似度来衡量物品相似程度。常用的相似度计算方法包括:
- **余弦相似度**:适用于高维稀疏向量
- **欧氏距离**:适用于数值型特征
- **Jaccard系数**:适用于集合型特征
**(3)用户偏好建模**
基于内容的推荐需要构建用户偏好模型,常用方法包括:
- **TF-IDF模型**:基于词频和逆文档频率建模
- **朴素贝叶斯模型**:基于概率统计建模
- **决策树模型**:基于规则学习建模
#### 2.2.3 混合推荐算法
单一推荐算法往往存在各自的局限性,混合推荐算法通过组合多种算法的优势,能够提供更准确、更全面的推荐结果。
**(1)混合策略分类**
根据算法组合方式,混合推荐策略可分为:
- **加权混合**:为不同算法分配权重,对推荐结果进行加权平均
- **切换混合**:根据情况选择最适合的算法
- **分层混合**:将推荐过程分为多个层次,每层使用不同算法
- **特征组合**:将不同算法的特征组合后输入统一模型
**(2)权重确定方法**
在加权混合策略中,权重的确定是关键问题。常用方法包括:
- **经验权重**:基于专家经验设定权重
- **学习权重**:通过机器学习算法学习最优权重
- **动态权重**:根据实时情况动态调整权重
本研究采用学习权重方法,通过分析历史推荐效果确定各算法的最优权重组合。
### 2.3 数据挖掘与机器学习技术
数据挖掘和机器学习技术为路线推荐系统提供了强大的数据分析和模式识别能力。
#### 2.3.1 聚类算法
聚类算法能够发现数据中的隐含模式和结构,在路线推荐中主要用于用户分群和地理区域划分。
**(1)K-means算法**
K-means是最经典的聚类算法之一,通过迭代优化使得簇内距离最小、簇间距离最大。
算法步骤:
1. 随机选择k个初始聚类中心
2. 将每个数据点分配到最近的聚类中心
3. 重新计算每个簇的中心点
4. 重复步骤2-3直到收敛
**(2)DBSCAN算法**
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够发现任意形状的簇并识别噪声点。
在地理数据分析中,DBSCAN算法特别适用于发现热点区域和异常轨迹。
#### 2.3.2 矩阵分解技术
矩阵分解技术通过将用户-物品评分矩阵分解为低维矩阵的乘积,发现用户和物品的潜在特征。
**(1)奇异值分解(SVD)**
SVD将评分矩阵R分解为三个矩阵的乘积:
```
R = UΣV^T
```
其中U和V为正交矩阵,Σ为对角矩阵。通过保留前k个最大奇异值,可以得到降维后的近似矩阵。
**(2)非负矩阵分解(NMF)**
NMF要求分解后的矩阵元素均为非负值,更符合实际应用场景的语义解释。
**(3)概率矩阵分解(PMF)**
PMF在传统矩阵分解基础上引入概率模型,能够更好地处理数据稀疏性问题。
### 2.4 Web开发技术框架
#### 2.4.1 Django框架
Django是基于Python的高级Web开发框架,采用MTV(Model-Template-View)架构模式,为快速开发提供了完整的解决方案。
**(1)Django核心组件**
- **ORM(对象关系映射)**:提供数据库抽象层,支持多种数据库
- **URL路由系统**:灵活的URL配置和请求分发机制
- **模板系统**:强大的模板引擎,支持模板继承和标签扩展
- **表单处理**:自动化的表单验证和处理机制
- **用户认证**:完整的用户管理和权限控制系统
**(2)Django优势**
- **快速开发**:提供丰富的内置功能,减少重复开发
- **安全性**:内置多种安全机制,防范常见Web攻击
- **可扩展性**:模块化设计,支持插件扩展
- **社区支持**:活跃的开源社区,丰富的第三方包
#### 2.4.2 前端技术栈
**(1)HTML5/CSS3/JavaScript**
现代Web应用的基础技术栈,提供结构、样式和交互功能。
**(2)Bootstrap框架**
响应式前端框架,提供丰富的UI组件和栅格系统,支持多设备适配。
**(3)jQuery库**
简化JavaScript开发的库,提供便捷的DOM操作和事件处理。
**(4)数据可视化技术**
- **ECharts**:百度开源的数据可视化库,支持多种图表类型
- **D3.js**:基于数据驱动的文档操作库,提供强大的可视化能力
- **Leaflet**:轻量级的交互式地图库
### 2.5 本章小结
本章系统阐述了路线规划、推荐系统、数据挖掘和Web开发等相关理论基础,为后续系统设计和实现提供了理论支撑。主要内容包括:
1. **路线规划算法理论**:从经典的Dijkstra、A*算法到现代的分层路网、预处理技术,为系统的路径规划功能提供了算法基础。
2. **推荐系统理论**:详细分析了协同过滤、基于内容推荐和混合推荐算法,为个性化推荐功能的实现奠定了理论基础。
3. **数据挖掘技术**:介绍了聚类算法和矩阵分解技术,为用户行为分析和偏好挖掘提供了技术支撑。
4. **Web开发技术**:阐述了Django框架和前端技术栈,为系统架构设计和实现提供了技术选型依据。
这些理论和技术为本研究的系统设计和算法实现提供了坚实的基础,确保了研究工作的科学性和可行性。
## 第三章 系统需求分析与总体设计
### 3.1 系统需求分析
#### 3.1.1 功能性需求分析
基于对目标用户群体的调研和现有系统的分析,本系统的功能性需求可以分为以下几个方面:
**(1)用户管理需求**
- **用户注册与登录**:支持用户账号注册、登录、登出功能
- **个人资料管理**:用户可以查看和编辑个人基本信息
- **常用地址管理**:用户可以添加、编辑、删除常用地址
- **偏好设置**:用户可以设置出行偏好,如偏好的出行方式、避开的道路类型等
**(2)路线规划需求**
- **基础路线规划**:支持输入起点和终点,计算最优路线
- **多种出行方式**:支持驾车、公交、步行、骑行等多种出行方式
- **实时路况考虑**:结合实时交通数据提供最优路线建议
- **路线详情展示**:显示路线的详细信息,包括距离、时间、途经道路等
- **路线可视化**:在地图上直观展示推荐路线
**(3)历史记录管理需求**
- **自动记录保存**:系统自动保存用户的路线搜索记录
- **历史记录查询**:用户可以查看和搜索历史路线记录
- **收藏功能**:用户可以收藏常用路线,便于快速访问
- **标签管理**:用户可以为路线添加自定义标签,便于分类管理
**(4)数据分析需求**
- **个人出行统计**:提供用户个人的出行数据统计分析
- **时间维度分析**:分析用户在不同时间段的出行规律
- 按日期统计出行次数和距离
- 按小时分析出行时间偏好
- 按月份展示出行趋势变化
- **空间维度分析**:分析用户的空间出行模式
- 热力图展示常去区域
- 统计最频繁的起点和终点
- 分析出行范围和活动半径
- **出行方式分析**:统计不同出行方式的使用频率和偏好
- **标签分析**:基于用户自定义标签的路线分析
**(5)个性化推荐需求**
- **基于历史的推荐**:根据用户历史出行数据推荐相似路线
- **基于位置的推荐**:根据用户当前位置推荐附近的热门目的地
- **基于时间的推荐**:根据当前时间段推荐合适的出行路线
- **智能推荐**:融合多种算法提供综合性的个性化推荐
- **推荐解释**:为推荐结果提供合理的解释说明
**(6)数据可视化需求**
- **统计图表**:提供柱状图、折线图、饼图等多种图表类型
- **地图可视化**:在地图上展示路线分布、热点区域等
- **交互式图表**:支持图表的缩放、筛选、钻取等交互操作
- **数据导出**:支持将分析结果导出为图片或数据文件
#### 3.1.2 非功能性需求分析
**(1)性能需求**
- **响应时间**:页面加载时间不超过5秒,路线规划响应时间不超过3秒
- **并发处理**:系统应支持至少100个并发用户同时访问
- **数据处理能力**:系统应能处理万级别的路线记录数据
- **推荐算法效率**:推荐算法的计算时间应控制在2秒以内
**(2)可用性需求**
- **系统可用性**:系统7×24小时可用,年可用性不低于99.5%
- **容错能力**:系统应具备良好的容错能力,单点故障不应影响整体服务
- **数据备份**:重要数据应定期备份,确保数据安全
**(3)易用性需求**
- **界面友好**:提供简洁、直观的用户界面
- **操作便捷**:核心功能应在3次点击内完成
- **响应式设计**:支持PC端和移动端访问
- **多浏览器兼容**:支持主流浏览器(Chrome、Firefox、Safari、Edge等)
**(4)安全性需求**
- **用户认证**:采用安全的用户认证机制
- **数据加密**:敏感数据传输和存储应进行加密
- **权限控制**:实现细粒度的权限控制,确保数据安全
- **防攻击**:防范SQL注入、XSS攻击等常见Web安全威胁
**(5)可扩展性需求**
- **模块化设计**:系统应采用模块化设计,便于功能扩展
- **算法可插拔**:推荐算法应支持可插拔式扩展
- **数据库扩展**:支持数据库的水平和垂直扩展
- **API接口**:提供标准的API接口,支持第三方集成
### 3.2 系统总体架构设计
#### 3.2.1 架构设计原则
本系统的架构设计遵循以下原则:
**(1)分层架构原则**
采用经典的三层架构模式,将系统分为表示层、业务逻辑层和数据访问层,实现各层之间的松耦合。
**(2)模块化设计原则**
将系统功能划分为相对独立的模块,每个模块负责特定的功能,便于开发、测试和维护。
**(3)可扩展性原则**
系统设计应考虑未来的功能扩展需求,采用可插拔的组件设计,支持新功能的快速集成。
**(4)高内聚低耦合原则**
模块内部功能高度相关,模块之间的依赖关系最小化,提高系统的可维护性。
#### 3.2.2 系统总体架构
本系统采用基于Django的MVC架构模式,结合现代Web开发的最佳实践,设计了如下的系统架构:
```
┌─────────────────────────────────────────────────────────────┐
│ 表示层 (Presentation Layer) │
├─────────────────────────────────────────────────────────────┤
│ Web浏览器 │ 移动端浏览器 │ API客户端 │ 管理后台 │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Web服务层 (Web Service Layer) │
├─────────────────────────────────────────────────────────────┤
│ Django Web Framework (URL路由、视图控制) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────┐ │
│ │ 用户管理 │ │ 路线规划 │ │ 数据分析 │ │ 推荐系统 │ │
│ │ 模块 │ │ 模块 │ │ 模块 │ │ 模块 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 业务逻辑层 (Business Logic Layer) │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────┐ │
│ │ 用户服务 │ │ 路线服务 │ │ 分析服务 │ │ 推荐服务 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └─────────┘ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 推荐算法引擎 │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ 协同过滤算法 │ │ 地理位置算法 │ │ 矩阵分解算法 │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ │ ┌─────────────────────────────────────────────────────┐ │ │
│ │ │ 混合推荐算法 │ │ │
│ │ └─────────────────────────────────────────────────────┘ │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据访问层 (Data Access Layer) │
├─────────────────────────────────────────────────────────────┤
│ Django ORM │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────┐ │
│ │ 用户数据 │ │ 路线数据 │ │ 分析数据 │ │ 系统数据 │ │
│ │ 访问 │ │ 访问 │ │ 访问 │ │ 访问 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据存储层 (Data Storage Layer) │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────┐ │
│ │ MySQL │ │ Redis │ │ 文件存储 │ │ 日志存储 │ │
│ │ 主数据库 │ │ 缓存数据 │ │ 静态文件 │ │ 系统日志 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
```
#### 3.2.3 核心模块设计
**(1)用户管理模块**
- 用户注册、登录、认证
- 个人资料管理
- 权限控制和会话管理
- 常用地址管理
**(2)路线规划模块**
- 路线搜索和计算
- 多种出行方式支持
- 实时路况集成
- 路线可视化展示
**(3)数据分析模块**
- 用户行为数据收集
- 多维度数据分析
- 统计报表生成
- 数据可视化
**(4)推荐系统模块**
- 多种推荐算法实现
- 算法融合和优化
- 推荐结果生成
- 推荐效果评估
### 3.3 数据库设计
#### 3.3.1 概念模型设计
基于系统功能需求,设计了如下的概念模型:
**核心实体:**
- **用户(User)**:系统用户基本信息
- **用户资料(UserProfile)**:用户扩展信息,包括联系方式、默认城市、常用地址
- **路线搜索(RouteSearch)**:用户的路线搜索记录,包含起终点、距离、时间等信息
- **用户标签(UserTag)**:用户自定义的路线标签,用于路线分类
**实体关系:**
- 用户与用户资料:一对一关系
- 用户与路线搜索:一对多关系
- 用户与用户标签:一对多关系
#### 3.3.2 系统ER图
系统的实体关系图展示了各个实体之间的关系和约束:
```mermaid
erDiagram
User {
int id PK
string username UK
string email UK
string password
string first_name
string last_name
datetime date_joined
boolean is_active
}
UserProfile {
int id PK
int user_id FK
string phone
string default_city
text common_addresses
datetime created_time
}
RouteSearch {
int id PK
int user_id FK
string origin
string destination
string origin_name
string destination_name
int distance
int duration
text _route_data
datetime created_time
boolean is_favorite
string route_tag
}
UserTag {
int id PK
int user_id FK
string name
datetime created_time
}
%% 关系定义
User ||--|| UserProfile : "一对一"
User ||--o{ RouteSearch : "一对多"
User ||--o{ UserTag : "一对多"
```
#### 3.3.3 系统功能用例图
基于系统功能需求分析,设计了完整的功能用例图,展示系统的主要参与者和功能用例:
```mermaid
graph TB
%% 参与者定义
User[用户]
Admin[管理员]
MapAPI[地图API]
%% 用例定义
subgraph "用户管理"
UC1[用户注册]
UC2[用户登录]
UC3[用户登出]
UC4[个人资料管理]
UC5[常用地址管理]
end
subgraph "路线规划"
UC6[路线搜索]
UC7[路线显示]
UC8[路线收藏]
UC9[路线分享]
UC10[历史记录查看]
end
subgraph "智能推荐"
UC11[获取推荐路线]
UC12[推荐反馈]
UC13[推荐算法优化]
end
subgraph "数据分析"
UC14[出行数据统计]
UC15[数据可视化]
UC16[趋势分析]
end
subgraph "标签管理"
UC17[创建标签]
UC18[编辑标签]
UC19[删除标签]
UC20[标签分类]
end
subgraph "系统管理"
UC21[用户管理]
UC22[数据备份]
UC23[系统监控]
UC24[日志管理]
end
%% 关系连接
User --> UC1
User --> UC2
User --> UC3
User --> UC4
User --> UC5
User --> UC6
User --> UC7
User --> UC8
User --> UC9
User --> UC10
User --> UC11
User --> UC12
User --> UC14
User --> UC15
User --> UC16
User --> UC17
User --> UC18
User --> UC19
User --> UC20
Admin --> UC21
Admin --> UC22
Admin --> UC23
Admin --> UC24
Admin --> UC13
MapAPI --> UC6
MapAPI --> UC7
%% 样式定义
classDef userClass fill:#e1f5fe
classDef adminClass fill:#f3e5f5
classDef apiClass fill:#e8f5e8
classDef ucClass fill:#fff3e0
class User userClass
class Admin adminClass
class MapAPI apiClass
class UC1,UC2,UC3,UC4,UC5,UC6,UC7,UC8,UC9,UC10,UC11,UC12,UC13,UC14,UC15,UC16,UC17,UC18,UC19,UC20,UC21,UC22,UC23,UC24 ucClass
```
**(1)用户相关表**
```sql
-- 用户基础表(Django内置)
User {
id: INTEGER PRIMARY KEY
username: VARCHAR(150) UNIQUE
email: VARCHAR(254)
password: VARCHAR(128)
first_name: VARCHAR(30)
last_name: VARCHAR(150)
is_active: BOOLEAN
date_joined: DATETIME
}
-- 用户资料扩展表
UserProfile {
id: INTEGER PRIMARY KEY
user_id: INTEGER FOREIGN KEY -> User.id
phone: VARCHAR(20)
default_city: VARCHAR(50)
common_addresses: TEXT -- JSON格式存储常用地址
preferred_travel_mode: VARCHAR(20) -- 偏好出行方式
created_time: DATETIME
updated_time: DATETIME
}
```
**(2)路线相关表**
```sql
-- 路线搜索记录表
RouteSearch {
id: INTEGER PRIMARY KEY
user_id: INTEGER FOREIGN KEY -> User.id
origin: VARCHAR(255) -- 起点坐标
destination: VARCHAR(255) -- 终点坐标
origin_name: VARCHAR(255) -- 起点名称
destination_name: VARCHAR(255) -- 终点名称
distance: INTEGER -- 距离(米)
duration: INTEGER -- 时间(秒)
route_data: TEXT -- 路线详细数据(JSON)
created_time: DATETIME
is_favorite: BOOLEAN -- 是否收藏
travel_mode: VARCHAR(20) -- 出行方式
user_rating: FLOAT -- 用户评分
}
```
**(3)标签管理表**
```sql
-- 用户标签表
UserTag {
id: INTEGER PRIMARY KEY
user_id: INTEGER FOREIGN KEY -> User.id
name: VARCHAR(50) -- 标签名称
color: VARCHAR(7) -- 标签颜色
created_time: DATETIME
}
-- 路线标签关联表
RouteTag {
id: INTEGER PRIMARY KEY
route_id: INTEGER FOREIGN KEY -> RouteSearch.id
tag_id: INTEGER FOREIGN KEY -> UserTag.id
created_time: DATETIME
}
```
#### 3.3.4 系统业务流程图
**(1)用户注册登录流程**
```mermaid
flowchart TD
A[用户访问系统] --> B{是否已注册}
B -->|否| C[点击注册]
B -->|是| D[点击登录]
C --> E[填写注册信息]
E --> F[提交注册表单]
F --> G{验证信息}
G -->|失败| H[显示错误信息]
H --> E
G -->|成功| I[创建用户账号]
I --> J[创建用户资料]
J --> K[自动登录]
K --> L[跳转到首页]
D --> M[输入用户名密码]
M --> N[提交登录表单]
N --> O{验证凭据}
O -->|失败| P[显示登录错误]
P --> M
O -->|成功| Q[创建用户会话]
Q --> L
L --> R[显示个性化首页]
classDef startEnd fill:#e1f5fe
classDef process fill:#e8f5e8
classDef decision fill:#fff3e0
classDef error fill:#ffebee
class A,R startEnd
class E,F,I,J,K,M,N,Q process
class B,G,O decision
class H,P error
```
#### 3.3.5 物理模型设计
**(1)索引设计**
为了提高数据库查询性能,设计了以下索引:
```sql
-- 路线搜索表索引
CREATE INDEX idx_routesearch_user_id ON RouteSearch(user_id);
CREATE INDEX idx_routesearch_created_time ON RouteSearch(created_time);
CREATE INDEX idx_routesearch_is_favorite ON RouteSearch(is_favorite);
CREATE INDEX idx_routesearch_route_tag ON RouteSearch(route_tag);
CREATE INDEX idx_routesearch_origin_dest ON RouteSearch(origin, destination);
-- 路线记录表索引
CREATE INDEX idx_routerecord_user_id ON RouteRecord(user_id);
CREATE INDEX idx_routerecord_created_time ON RouteRecord(created_time);
CREATE INDEX idx_routerecord_city ON RouteRecord(city);
CREATE INDEX idx_routerecord_district ON RouteRecord(district);
-- 用户标签表索引
CREATE INDEX idx_usertag_user_id ON UserTag(user_id);
CREATE INDEX idx_usertag_name ON UserTag(name);
```
**(2)数据分区策略**
考虑到路线数据的时间特性和查询模式,采用按时间分区的策略:
```sql
-- 按月份对路线记录表进行分区
CREATE TABLE RouteRecord_2024_01 PARTITION OF RouteRecord
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE RouteRecord_2024_02 PARTITION OF RouteRecord
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
-- ... 其他月份分区
```
**(3)数据约束设计**
```sql
-- 添加数据完整性约束
ALTER TABLE RouteSearch ADD CONSTRAINT chk_distance_positive
CHECK (distance IS NULL OR distance >= 0);
ALTER TABLE RouteSearch ADD CONSTRAINT chk_duration_positive
CHECK (duration IS NULL OR duration >= 0);
ALTER TABLE UserProfile ADD CONSTRAINT chk_phone_format
CHECK (phone IS NULL OR phone ~ '^[0-9]{11}$');
```
**(2)路线规划业务流程**
```mermaid
flowchart TD
A[用户输入起点终点] --> B{输入格式检查}
B -->|地址格式| C[地理编码转换]
B -->|坐标格式| D[坐标验证]
C --> E{编码成功?}
E -->|失败| F[提示地址错误]
F --> A
E -->|成功| G[获取坐标]
D --> H{坐标有效?}
H -->|无效| I[提示坐标错误]
I --> A
H -->|有效| G
G --> J[选择出行方式]
J --> K[调用地图API]
K --> L{API调用成功?}
L -->|失败| M[显示网络错误]
M --> N[提供重试选项]
N --> K
L -->|成功| O[获取多个路线方案]
O --> P1[方案1: 最短距离]
O --> P2[方案2: 最短时间]
O --> P3[方案3: 避开拥堵]
P1 --> Q[个性化评分计算]
P2 --> Q
P3 --> Q
Q --> R[方案合并与排序]
R --> S[展示推荐路线列表]
S --> T{用户选择方案}
T --> U[在地图上显示选中路线]
U --> V[保存路线记录]
V --> W[显示路线详情]
W --> X{用户操作}
X -->|收藏| Y[标记为收藏]
X -->|添加标签| Z[选择或创建标签]
X -->|重新规划| A
X -->|选择其他方案| T
Y --> AA[更新收藏状态]
Z --> BB[关联路线标签]
classDef startEnd fill:#e1f5fe
classDef process fill:#e8f5e8
classDef decision fill:#fff3e0
classDef error fill:#ffebee
classDef action fill:#f3e5f5
classDef route fill:#e8f5e8
class A,W startEnd
class C,D,G,J,K,O,Q,R,S,U,V,AA,BB process
class B,E,H,L,T,X decision
class F,I,M,N error
class Y,Z action
class P1,P2,P3 route
```
**(3)推荐系统业务流程**
```mermaid
flowchart TD
A[用户请求推荐] --> B{检查缓存}
B -->|有缓存| C[返回缓存结果]
B -->|无缓存| D[分析用户历史数据]
D --> E{用户类型判断}
E -->|新用户| F[热门路线推荐]
E -->|老用户| G[个性化推荐]
G --> H[协同过滤算法]
G --> I[地理位置算法]
G --> J[矩阵分解算法]
H --> K[计算用户相似度]
K --> L[生成协同推荐]
I --> M[分析地理聚类]
M --> N[生成位置推荐]
J --> O[矩阵分解计算]
O --> P[生成潜在推荐]
F --> Q[合并推荐结果]
L --> Q
N --> Q
P --> Q
Q --> R[算法权重融合]
R --> S[个性化评分排序]
S --> T[过滤重复结果]
T --> U[生成最终推荐]
U --> V[缓存推荐结果]
V --> W[返回推荐列表]
C --> W
W --> X{用户反馈}
X -->|点击| Y[记录正面反馈]
X -->|忽略| Z[记录负面反馈]
X -->|收藏| AA[记录强正面反馈]
Y --> BB[调整算法权重]
Z --> BB
AA --> BB
classDef startEnd fill:#e1f5fe
classDef process fill:#e8f5e8
classDef decision fill:#fff3e0
classDef algorithm fill:#f3e5f5
classDef feedback fill:#fff9c4
class A,W startEnd
class D,F,K,L,M,N,O,P,Q,R,S,T,U,V,BB process
class B,E,X decision
class H,I,J algorithm
class Y,Z,AA feedback
```
### 3.4 系统功能模块设计
#### 3.4.1 用户管理模块
**(1)模块功能**
- 用户注册、登录、登出
- 个人资料管理
- 常用地址管理
- 用户偏好设置
**(2)核心类设计**
```python
class UserProfile(models.Model):
"""用户资料扩展模型"""
user = models.OneToOneField(User, on_delete=models.CASCADE)
phone = models.CharField(max_length=20, blank=True, null=True)
default_city = models.CharField(max_length=50, blank=True, null=True)
common_addresses = models.TextField(blank=True, null=True)
created_time = models.DateTimeField(auto_now_add=True)
def get_common_addresses(self):
"""获取常用地址列表"""
if not self.common_addresses:
return []
try:
return json.loads(self.common_addresses)
except:
return []
def add_common_address(self, address):
"""添加常用地址"""
addresses = self.get_common_addresses()
if address not in addresses:
addresses.append(address)
self.common_addresses = json.dumps(addresses)
self.save()
```
**(3)主要接口**
```python
# 用户认证相关接口
POST /auth/login/ # 用户登录
POST /auth/register/ # 用户注册
POST /auth/logout/ # 用户登出
# 用户资料相关接口
GET /profile/ # 获取用户资料
POST /profile/update/ # 更新用户资料
POST /profile/address/add/ # 添加常用地址
DELETE /profile/address/{id}/ # 删除常用地址
```
#### 3.4.2 路线规划模块
**(1)模块功能**
- 路线搜索和计算
- 多种出行方式支持
- 路线详情展示
- 历史记录管理
**(2)核心类设计**
```python
class RouteSearch(models.Model):
"""路线搜索记录模型"""
user = models.ForeignKey(User, on_delete=models.CASCADE)
origin = models.CharField(max_length=255)
destination = models.CharField(max_length=255)
origin_name = models.CharField(max_length=255, blank=True, null=True)
destination_name = models.CharField(max_length=255, blank=True, null=True)
distance = models.IntegerField(null=True, blank=True)
duration = models.IntegerField(null=True, blank=True)
route_data = models.TextField(blank=True, null=True)
created_time = models.DateTimeField(auto_now_add=True)
is_favorite = models.BooleanField(default=False)
route_tag = models.CharField(max_length=50, blank=True, default='')
@property
def route_data_parsed(self):
"""获取解析后的路线数据"""
if not self.route_data:
return {}
try:
return json.loads(self.route_data)
except:
return {}
```
**(3)路线规划算法接口**
```python
class RoutePlanningService:
"""路线规划服务类"""
def __init__(self):
self.map_api = MapAPIClient() # 地图API客户端
def plan_route(self, origin, destination, mode='driving'):
"""
规划路线
参数:
origin: 起点坐标或地址
destination: 终点坐标或地址
mode: 出行方式 (driving/transit/walking/bicycling)
返回:
路线规划结果
"""
try:
# 调用地图API进行路线规划
result = self.map_api.directions(
origin=origin,
destination=destination,
mode=mode
)
# 解析和处理结果
route_info = self._parse_route_result(result)
return {
'status': 'success',
'data': route_info
}
except Exception as e:
return {
'status': 'error',
'message': str(e)
}
def _parse_route_result(self, result):
"""解析路线规划结果"""
# 提取关键信息
route = result['routes'][0]
leg = route['legs'][0]
return {
'distance': leg['distance']['value'],
'duration': leg['duration']['value'],
'start_address': leg['start_address'],
'end_address': leg['end_address'],
'steps': leg['steps'],
'overview_polyline': route['overview_polyline']['points']
}
```
#### 3.4.3 数据分析模块
**(1)模块功能**
- 用户出行数据统计
- 多维度数据分析
- 数据可视化
- 分析报告生成
**(2)核心分析类设计**
```python
class UserAnalyticsService:
"""用户数据分析服务类"""
def __init__(self, user):
self.user = user
def get_overview_stats(self):
"""获取概览统计数据"""
routes = RouteSearch.objects.filter(user=self.user)
total_routes = routes.count()
total_distance = routes.aggregate(
total=models.Sum('distance')
)['total'] or 0
total_duration = routes.aggregate(
total=models.Sum('duration')
)['total'] or 0
avg_distance = total_distance / total_routes if total_routes > 0 else 0
avg_duration = total_duration / total_routes if total_routes > 0 else 0
return {
'total_routes': total_routes,
'total_distance': total_distance,
'total_duration': total_duration,
'avg_distance': avg_distance,
'avg_duration': avg_duration
}
def get_time_analysis(self):
"""获取时间维度分析数据"""
routes = RouteSearch.objects.filter(user=self.user)
# 按日期统计
daily_stats = routes.extra(
select={'date': 'DATE(created_time)'}
).values('date').annotate(
count=models.Count('id'),
total_distance=models.Sum('distance')
).order_by('date')
# 按小时统计
hourly_stats = routes.extra(
select={'hour': 'HOUR(created_time)'}
).values('hour').annotate(
count=models.Count('id')
).order_by('hour')
return {
'daily_stats': list(daily_stats),
'hourly_stats': list(hourly_stats)
}
def get_spatial_analysis(self):
"""获取空间维度分析数据"""
routes = RouteSearch.objects.filter(user=self.user)
# 热门起点统计
popular_origins = routes.values('origin_name').annotate(
count=models.Count('id')
).order_by('-count')[:10]
# 热门终点统计
popular_destinations = routes.values('destination_name').annotate(
count=models.Count('id')
).order_by('-count')[:10]
return {
'popular_origins': list(popular_origins),
'popular_destinations': list(popular_destinations)
}
```
#### 3.4.4 推荐系统模块
**(1)模块功能**
- 多种推荐算法实现
- 算法融合和优化
- 推荐结果生成
- 推荐效果评估
**(2)推荐系统架构**
```python
class RecommendationEngine:
"""推荐引擎主类"""
def __init__(self):
self.algorithms = {
'collaborative_filtering': CollaborativeFilteringRecommender(),
'location_based': LocationBasedRecommender(),
'matrix_factorization': MatrixFactorizationRecommender()
}
self.ensemble = EnsembleRecommender(self.algorithms)
def get_recommendations(self, user, algorithm='ensemble', top_n=10):
"""
获取推荐结果
参数:
user: 目标用户
algorithm: 推荐算法类型
top_n: 推荐结果数量
返回:
推荐结果列表
"""
if algorithm == 'ensemble':
return self.ensemble.recommend(user, top_n)
elif algorithm in self.algorithms:
return self.algorithms[algorithm].recommend(user, top_n)
else:
raise ValueError(f"Unknown algorithm: {algorithm}")
def evaluate_algorithm(self, algorithm, test_data):
"""评估算法性能"""
if algorithm in self.algorithms:
return self.algorithms[algorithm].evaluate(test_data)
else:
raise ValueError(f"Unknown algorithm: {algorithm}")
```
### 3.5 本章小结
本章详细分析了系统的功能性需求和非功能性需求,设计了系统的总体架构和核心模块。主要内容包括:
1. **需求分析**:从用户管理、路线规划、数据分析、个性化推荐等方面详细分析了系统的功能性需求,并从性能、可用性、安全性等方面分析了非功能性需求。
2. **总体架构设计**:采用分层架构模式,将系统分为表示层、业务逻辑层和数据访问层,设计了模块化、可扩展的系统架构。
3. **数据库设计**:从概念模型、逻辑模型到物理模型,完整设计了系统的数据库结构,包括表结构、索引、约束等。
4. **功能模块设计**:详细设计了用户管理、路线规划、数据分析和推荐系统四个核心模块的功能和接口。
这些设计为后续的系统实现提供了清晰的指导,确保了系统的可行性和可维护性。下一章将详细介绍核心算法的设计与实现。
## 第四章 核心算法设计与实现
### 4.1 路线规划算法设计
#### 4.1.1 路线规划算法选择
本系统的路线规划功能主要依托第三方地图API(如高德地图API),但为了提供更好的用户体验和个性化服务,系统在基础路线规划的基础上增加了以下优化:
**(1)多路径候选方案生成**
不仅提供最优路径,还生成多个候选路径供用户选择,包括:
- 最短距离路径
- 最短时间路径
- 避开拥堵路径
- 风景优美路径(基于用户偏好)
**(2)个性化路径权重调整**
根据用户历史偏好调整路径评分权重:
```python
class PersonalizedRouteScorer:
"""个性化路线评分器"""
def __init__(self, user_preferences):
self.preferences = user_preferences
# 默认权重
self.default_weights = {
'distance': 0.3,
'duration': 0.4,
'traffic': 0.2,
'scenery': 0.1
}
# 根据用户偏好调整权重
self.weights = self._adjust_weights()
def _adjust_weights(self):
"""根据用户偏好调整权重"""
weights = self.default_weights.copy()
# 如果用户偏好快速到达,增加时间权重
if self.preferences.get('prefer_fast', False):
weights['duration'] += 0.1
weights['distance'] -= 0.05
weights['scenery'] -= 0.05
# 如果用户偏好风景路线,增加风景权重
if self.preferences.get('prefer_scenery', False):
weights['scenery'] += 0.15
weights['duration'] -= 0.1
weights['traffic'] -= 0.05
return weights
def score_route(self, route_info):
"""为路线计算个性化评分"""
# 标准化各项指标(0-1范围)
distance_score = 1 - min(route_info['distance'] / 50000, 1) # 50km为参考
duration_score = 1 - min(route_info['duration'] / 7200, 1) # 2小时为参考
traffic_score = 1 - route_info.get('traffic_level', 0.5) # 拥堵程度
scenery_score = route_info.get('scenery_score', 0.5) # 风景评分
# 加权计算总分
total_score = (
distance_score * self.weights['distance'] +
duration_score * self.weights['duration'] +
traffic_score * self.weights['traffic'] +
scenery_score * self.weights['scenery']
)
return total_score
```
#### 4.1.2 路线数据处理与存储
**(1)路线数据标准化**
```python
class RouteDataProcessor:
"""路线数据处理器"""
def process_route_data(self, raw_route_data):
"""处理原始路线数据"""
processed_data = {
'route_id': self._generate_route_id(raw_route_data),
'geometry': self._extract_geometry(raw_route_data),
'distance': raw_route_data.get('distance', 0),
'duration': raw_route_data.get('duration', 0),
'steps': self._process_steps(raw_route_data.get('steps', [])),
'traffic_info': self._extract_traffic_info(raw_route_data),
'road_types': self._analyze_road_types(raw_route_data),
'poi_info': self._extract_poi_info(raw_route_data)
}
return processed_data
def _generate_route_id(self, route_data):
"""生成路线唯一标识"""
# 基于起点、终点和主要途经点生成哈希ID
key_points = [
route_data.get('start_location', ''),
route_data.get('end_location', ''),
str(route_data.get('waypoints', []))
]
route_string = '|'.join(key_points)
return hashlib.md5(route_string.encode()).hexdigest()
def _extract_geometry(self, route_data):
"""提取路线几何信息"""
if 'overview_polyline' in route_data:
return {
'type': 'polyline',
'coordinates': self._decode_polyline(
route_data['overview_polyline']['points']
)
}
return None
def _process_steps(self, steps):
"""处理路线步骤信息"""
processed_steps = []
for step in steps:
processed_step = {
'instruction': step.get('html_instructions', ''),
'distance': step.get('distance', {}).get('value', 0),
'duration': step.get('duration', {}).get('value', 0),
'start_location': step.get('start_location', {}),
'end_location': step.get('end_location', {}),
'travel_mode': step.get('travel_mode', 'DRIVING')
}
processed_steps.append(processed_step)
return processed_steps
```
### 4.2 推荐系统算法设计与实现
推荐系统是本研究的核心创新点,采用多算法融合的混合推荐策略,包括基于内容的推荐、基于物品的协同过滤、基于地理位置的推荐和基于矩阵分解的推荐算法。
#### 4.2.1 基于内容的推荐算法
基于内容的推荐算法通过分析用户的历史出行数据,挖掘用户的出行偏好和行为模式,为用户推荐符合其偏好的路线。该算法是系统的核心推荐引擎,位于`routes/recommenders/recommendations.py`文件中。
**(1)算法设计思路**
基于内容的推荐算法主要分析以下几个维度的用户偏好:
- **时间偏好分析**:分析用户常用的出行时间段,推荐在相似时间段内其他用户的热门路线
- **距离偏好分析**:计算用户的平均出行距离,推荐距离相近的路线
- **起点偏好分析**:识别用户的常用起点,推荐从相同起点出发的新目的地
- **目的地类型偏好**:通过目的地名称关键词分析用户偏好的场所类型
- **地理位置偏好**:优先使用地理位置推荐算法的结果
**(2)核心算法实现**
```python
def route_recommendations(request):
"""
获取个性化路线推荐API
基于用户历史路线数据和偏好,推荐可能感兴趣的新路线
"""
try:
# 只对登录用户提供推荐
if not request.user.is_authenticated:
logger.warning("未登录用户尝试获取推荐")
return JsonResponse({
'status': 'error',
'message': '请登录以获取个性化推荐'
})
logger.info(f"用户 {request.user.username} 请求路线推荐")
# 首先尝试基于地理位置的推荐
try:
location_recommendations = get_location_recommendations(request.user, top_n=5)
if location_recommendations and len(location_recommendations) > 0:
# 移除重复推荐
unique_recommendations = []
seen_routes = set()
for rec in location_recommendations:
if rec['origin'] == rec['destination'] or rec['origin_name'] == rec['destination_name']:
continue
route_key = f"{rec['origin']}_{rec['destination']}"
if route_key not in seen_routes:
seen_routes.add(route_key)
unique_recommendations.append(rec)
if len(unique_recommendations) > 0:
return JsonResponse({
'status': 'success',
'data': unique_recommendations,
'recommendation_type': 'location_based'
})
except Exception as e:
# 记录地理位置推荐失败的错误,但不中断流程
pass
# 如果地理位置推荐失败或没有结果,回退到基于内容的推荐
user_routes = RouteSearch.objects.filter(user=request.user).order_by('-created_time')
# 如果用户没有足够的历史记录,返回热门路线
if user_routes.count() < 3:
popular_routes = RouteSearch.objects.values('origin', 'destination', 'origin_name', 'destination_name') \
.annotate(route_count=Count('id')) \
.order_by('-route_count')[:5]
recommendations = []
for route in popular_routes:
recommendations.append({
'type': '热门路线',
'origin': route['origin'],
'destination': route['destination'],
'origin_name': route['origin_name'],
'destination_name': route['destination_name'],
'reason': '基于系统热门路线推荐',
'confidence': 'medium'
})
return JsonResponse({
'status': 'success',
'data': recommendations,
'note': '根据系统热门路线为您推荐',
'recommendation_type': 'content_based'
})
```
**(3)用户偏好分析实现**
```python
# 分析用户的偏好模式
# 1. 时间段偏好
hour_preference = {}
for route in user_routes:
if route.created_time:
hour = route.created_time.hour
if hour not in hour_preference:
hour_preference[hour] = 0
hour_preference[hour] += 1
# 找出最常用的时间段
favorite_hours = sorted(hour_preference.items(), key=lambda x: x[1], reverse=True)[:2]
favorite_hours = [hour for hour, _ in favorite_hours]
# 2. 距离偏好
distance_sum = 0
distance_count = 0
for route in user_routes:
if route.distance:
distance_sum += route.distance
distance_count += 1
avg_distance = round(distance_sum / distance_count) if distance_count > 0 else 0
distance_lower = max(0, avg_distance - 2000) # 平均距离减2公里
distance_upper = avg_distance + 2000 # 平均距离加2公里
# 3. 目的地类型偏好
destination_keywords = {
'购物': ['商场', '超市', '购物中心', '商城', '市场'],
'餐饮': ['餐厅', '饭店', '美食', '小吃'],
'休闲': ['公园', '广场', '影院', '电影院', '剧院', '健身'],
'教育': ['学校', '大学', '学院', '培训', '图书馆'],
'工作': ['公司', '办公', '写字楼', '工厂']
}
category_counts = {category: 0 for category in destination_keywords}
for route in user_routes:
dest_name = route.destination_name or ""
for category, keywords in destination_keywords.items():
if any(keyword in dest_name for keyword in keywords):
category_counts[category] += 1
# 找出最常访问的目的地类型
favorite_category = None
if any(count > 0 for count in category_counts.values()):
favorite_category = max(category_counts.items(), key=lambda x: x[1])[0]
```
**(4)算法优势与特点**
- **多维度分析**:从时间、距离、地理位置、目的地类型等多个维度分析用户偏好
- **智能回退机制**:优先使用地理位置推荐,失败时回退到内容推荐,确保系统稳定性
- **冷启动处理**:对于新用户或历史数据不足的用户,提供热门路线推荐
- **去重机制**:有效避免重复推荐,提升用户体验
- **实时性**:基于用户最新的历史数据进行分析,推荐结果具有时效性
#### 4.2.2 基于物品的协同过滤算法
基于物品的协同过滤算法通过分析路线之间的相似性,为用户推荐与其历史偏好路线相似的新路线。
**(1)算法设计思路**
在路线推荐场景中,将每条路线视为一个"物品",用户对路线的偏好程度通过以下因素综合计算:
- 路线使用频次
- 是否收藏
- 路线标签
- 使用时间间隔
**(2)核心算法实现**
```python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from collections import defaultdict
import logging
class ItemBasedCollaborativeFiltering:
"""基于物品的协同过滤推荐算法"""
def __init__(self, top_n=10, min_similarity=0.1):
self.top_n = top_n
self.min_similarity = min_similarity
self.route_users = {} # 路线-用户矩阵
self.route_similarity = None # 路线相似度矩阵
self.route_info = {} # 路线信息字典
self.logger = logging.getLogger(__name__)
def _build_route_user_matrix(self):
"""构建路线-用户矩阵"""
# 获取所有路线记录
routes = RouteSearch.objects.values('origin', 'destination').distinct()
self.logger.info(f"找到 {routes.count()} 条不同的路线")
# 为每条路线获取其用户记录
for route in routes:
route_key = f"{route['origin']}_{route['destination']}"
# 获取使用此路线的用户及其权重
users = RouteSearch.objects.filter(
origin=route['origin'],
destination=route['destination']
).values('user', 'origin_name', 'destination_name').annotate(
usage_count=Count('id'),
favorite_count=Count(Case(
When(is_favorite=True, then=1),
output_field=IntegerField()
)),
latest_usage=Max('created_time')
)
# 计算用户对路线的偏好权重
user_weights = {}
route_name = ""
for user_data in users:
if not route_name and user_data['origin_name'] and user_data['destination_name']:
route_name = f"{user_data['origin_name']} -> {user_data['destination_name']}"
# 计算权重:使用次数 + 收藏加权 + 时间衰减
usage_weight = min(user_data['usage_count'] / 10.0, 1.0) # 使用次数权重
favorite_weight = user_data['favorite_count'] * 0.5 # 收藏权重
# 时间衰减权重(最近使用的权重更高)
days_since_last_use = (timezone.now() - user_data['latest_usage']).days
time_weight = max(0.1, 1.0 - days_since_last_use / 365.0)
total_weight = (usage_weight + favorite_weight) * time_weight
user_weights[user_data['user']] = total_weight
if user_weights:
self.route_users[route_key] = user_weights
self.route_info[route_key] = {
'name': route_name or route_key,
'origin': route['origin'],
'destination': route['destination']
}
self.logger.info(f"构建了 {len(self.route_users)} 条路线的用户矩阵")
def _compute_route_similarity(self):
"""计算路线相似度矩阵"""
route_keys = list(self.route_users.keys())
n_routes = len(route_keys)
if n_routes == 0:
self.route_similarity = np.array([])
return
# 获取所有用户ID
all_users = set()
for users in self.route_users.values():
all_users.update(users.keys())
all_users = sorted(list(all_users))
# 构建路线-用户矩阵
matrix = np.zeros((n_routes, len(all_users)))
for i, route_key in enumerate(route_keys):
for j, user_id in enumerate(all_users):
matrix[i, j] = self.route_users[route_key].get(user_id, 0)
# 计算余弦相似度
self.route_similarity = cosine_similarity(matrix)
# 将相似度矩阵转换为字典形式便于查询
self.similarity_dict = {}
for i, route1 in enumerate(route_keys):
self.similarity_dict[route1] = {}
for j, route2 in enumerate(route_keys):
if i != j: # 排除自身
self.similarity_dict[route1][route2] = self.route_similarity[i, j]
self.logger.info(f"计算了 {n_routes}x{n_routes} 的路线相似度矩阵")
def recommend(self, user, top_n=None):
"""为用户推荐路线"""
if top_n is None:
top_n = self.top_n
try:
# 构建数据矩阵
self._build_route_user_matrix()
self._compute_route_similarity()
if not self.route_users:
return []
# 获取用户历史路线
user_routes = RouteSearch.objects.filter(user=user).values(
'origin', 'destination'
).distinct()
user_route_keys = [
f"{route['origin']}_{route['destination']}"
for route in user_routes
]
if not user_route_keys:
# 新用户,返回热门路线
return self._get_popular_routes(top_n)
# 计算推荐分数
recommendation_scores = defaultdict(float)
for user_route in user_route_keys:
if user_route not in self.similarity_dict:
continue
# 获取与用户历史路线相似的路线
similar_routes = self.similarity_dict[user_route]
for similar_route, similarity in similar_routes.items():
if similarity >= self.min_similarity:
# 如果用户没有使用过这条路线,则推荐
if similar_route not in user_route_keys:
recommendation_scores[similar_route] += similarity
# 排序并返回推荐结果
sorted_recommendations = sorted(
recommendation_scores.items(),
key=lambda x: x[1],
reverse=True
)[:top_n]
# 格式化推荐结果
recommendations = []
for route_key, score in sorted_recommendations:
if route_key in self.route_info:
route_data = self.route_info[route_key]
recommendations.append({
'route_key': route_key,
'name': route_data['name'],
'origin': route_data['origin'],
'destination': route_data['destination'],
'score': round(score, 3),
'reason': '基于您的历史路线偏好推荐'
})
self.logger.info(f"为用户 {user.id} 生成了 {len(recommendations)} 条协同过滤推荐")
return recommendations
except Exception as e:
self.logger.error(f"协同过滤推荐出错: {str(e)}")
return []
def _get_popular_routes(self, top_n):
"""获取热门路线(用于新用户推荐)"""
popular_routes = RouteSearch.objects.values(
'origin', 'destination', 'origin_name', 'destination_name'
).annotate(
usage_count=Count('id'),
user_count=Count('user', distinct=True)
).order_by('-usage_count')[:top_n]
recommendations = []
for route in popular_routes:
route_name = f"{route['origin_name']} -> {route['destination_name']}" \
if route['origin_name'] and route['destination_name'] \
else f"{route['origin']} -> {route['destination']}"
recommendations.append({
'route_key': f"{route['origin']}_{route['destination']}",
'name': route_name,
'origin': route['origin'],
'destination': route['destination'],
'score': route['usage_count'] / 100.0, # 标准化分数
'reason': f'热门路线,已有{route["user_count"]}位用户使用'
})
return recommendations
```
**(3)算法优化策略**
为了提高算法性能和推荐质量,采用了以下优化策略:
- **数据预处理**:定期预计算路线相似度矩阵,减少实时计算开销
- **缓存机制**:使用Redis缓存推荐结果,提高响应速度
- **增量更新**:当有新的路线数据时,采用增量更新相似度矩阵
- **冷启动处理**:对于新用户,基于热门路线进行推荐
#### 4.2.3 基于地理位置的推荐算法
基于地理位置的推荐算法利用地理空间信息,通过分析用户的地理活动模式,推荐用户可能感兴趣的目的地。
**(1)算法设计原理**
该算法基于以下假设:
- 地理位置相近的地点具有相似的特征
- 用户倾向于在相似的地理区域内活动
- 热门区域更可能吸引用户
**(2)核心算法实现**
```python
import numpy as np
from sklearn.cluster import DBSCAN
from geopy.distance import geodesic
import math
class LocationBasedRecommender:
"""基于地理位置的推荐算法"""
def __init__(self, eps=0.01, min_samples=3, top_n=10):
"""
初始化推荐器
参数:
eps: DBSCAN聚类的邻域半径(度)
min_samples: DBSCAN聚类的最小样本数
top_n: 推荐结果数量
"""
self.eps = eps
self.min_samples = min_samples
self.top_n = top_n
self.logger = logging.getLogger(__name__)
def _parse_coordinates(self, coord_string):
"""解析坐标字符串"""
try:
if ',' in coord_string:
lat, lng = map(float, coord_string.split(','))
return (lat, lng)
except:
pass
return None
def _cluster_destinations(self, user=None):
"""对目的地进行聚类分析"""
# 获取所有目的地坐标
if user:
# 获取特定用户的目的地
destinations = RouteSearch.objects.filter(user=user).values(
'destination', 'destination_name'
).annotate(visit_count=Count('id'))
else:
# 获取所有用户的目的地
destinations = RouteSearch.objects.values(
'destination', 'destination_name'
).annotate(visit_count=Count('id'))
# 解析坐标并构建数据集
coordinates = []
destination_info = []
for dest in destinations:
coord = self._parse_coordinates(dest['destination'])
if coord:
coordinates.append(coord)
destination_info.append({
'coordinate': dest['destination'],
'name': dest['destination_name'],
'visit_count': dest['visit_count'],
'lat': coord[0],
'lng': coord[1]
})
if len(coordinates) < self.min_samples:
return [], destination_info
# 使用DBSCAN进行聚类
coordinates_array = np.array(coordinates)
clustering = DBSCAN(eps=self.eps, min_samples=self.min_samples).fit(coordinates_array)
# 分析聚类结果
clusters = {}
for i, label in enumerate(clustering.labels_):
if label != -1: # 排除噪声点
if label not in clusters:
clusters[label] = []
clusters[label].append(destination_info[i])
return clusters, destination_info
def _get_popular_destinations_in_area(self, center_coord, radius_km=5):
"""获取指定区域内的热门目的地"""
center_lat, center_lng = self._parse_coordinates(center_coord)
if not center_lat or not center_lng:
return []
# 计算搜索范围(粗略的经纬度范围)
lat_range = radius_km / 111.0 # 1度纬度约111km
lng_range = radius_km / (111.0 * math.cos(math.radians(center_lat)))
min_lat = center_lat - lat_range
max_lat = center_lat + lat_range
min_lng = center_lng - lng_range
max_lng = center_lng + lng_range
# 查询范围内的目的地
destinations = RouteSearch.objects.extra(
where=[
"CAST(SUBSTRING_INDEX(destination, ',', 1) AS DECIMAL(10,6)) BETWEEN %s AND %s",
"CAST(SUBSTRING_INDEX(destination, ',', -1) AS DECIMAL(10,6)) BETWEEN %s AND %s"
],
params=[min_lat, max_lat, min_lng, max_lng]
).values(
'destination', 'destination_name'
).annotate(
visit_count=Count('id'),
user_count=Count('user', distinct=True)
).order_by('-visit_count')
# 精确计算距离并过滤
popular_destinations = []
for dest in destinations:
dest_coord = self._parse_coordinates(dest['destination'])
if dest_coord:
distance = geodesic((center_lat, center_lng), dest_coord).kilometers
if distance <= radius_km:
popular_destinations.append({
'coordinate': dest['destination'],
'name': dest['destination_name'],
'visit_count': dest['visit_count'],
'user_count': dest['user_count'],
'distance': round(distance, 2)
})
return popular_destinations[:self.top_n]
def recommend(self, user, current_location=None, top_n=None):
"""为用户推荐基于地理位置的目的地"""
if top_n is None:
top_n = self.top_n
try:
recommendations = []
# 策略1:基于用户历史活动区域推荐
user_clusters, user_destinations = self._cluster_destinations(user)
if user_clusters:
# 找到用户最活跃的区域
most_active_cluster = max(
user_clusters.items(),
key=lambda x: sum(dest['visit_count'] for dest in x[1])
)
cluster_destinations = most_active_cluster[1]
cluster_center = self._calculate_cluster_center(cluster_destinations)
# 在活跃区域附近推荐热门目的地
nearby_popular = self._get_popular_destinations_in_area(
cluster_center, radius_km=10
)
# 过滤掉用户已经去过的地方
user_visited = set(dest['coordinate'] for dest in user_destinations)
for dest in nearby_popular:
if dest['coordinate'] not in user_visited:
recommendations.append({
'coordinate': dest['coordinate'],
'name': dest['name'],
'score': dest['visit_count'] / 100.0,
'reason': f'基于您的活动区域推荐,距离{dest["distance"]}km',
'type': 'activity_area'
})
# 策略2:基于当前位置推荐
if current_location and len(recommendations) < top_n:
current_popular = self._get_popular_destinations_in_area(
current_location, radius_km=15
)
user_visited = set(dest['coordinate'] for dest in user_destinations)
for dest in current_popular:
if dest['coordinate'] not in user_visited:
# 避免重复推荐
if not any(r['coordinate'] == dest['coordinate'] for r in recommendations):
recommendations.append({
'coordinate': dest['coordinate'],
'name': dest['name'],
'score': dest['visit_count'] / 100.0,
'reason': f'您附近的热门目的地,距离{dest["distance"]}km',
'type': 'nearby_popular'
})
# 策略3:全局热门目的地推荐
if len(recommendations) < top_n:
global_popular = RouteSearch.objects.values(
'destination', 'destination_name'
).annotate(
visit_count=Count('id'),
user_count=Count('user', distinct=True)
).order_by('-visit_count')[:top_n * 2]
user_visited = set(dest['coordinate'] for dest in user_destinations)
for dest in global_popular:
if dest['destination'] not in user_visited:
if not any(r['coordinate'] == dest['destination'] for r in recommendations):
recommendations.append({
'coordinate': dest['destination'],
'name': dest['destination_name'],
'score': dest['visit_count'] / 100.0,
'reason': f'热门目的地,已有{dest["user_count"]}位用户访问',
'type': 'global_popular'
})
if len(recommendations) >= top_n:
break
# 按分数排序并返回
recommendations.sort(key=lambda x: x['score'], reverse=True)
self.logger.info(f"为用户 {user.id} 生成了 {len(recommendations[:top_n])} 条地理位置推荐")
return recommendations[:top_n]
except Exception as e:
self.logger.error(f"地理位置推荐出错: {str(e)}")
return []
def _calculate_cluster_center(self, destinations):
"""计算聚类中心坐标"""
if not destinations:
return None
total_lat = sum(dest['lat'] for dest in destinations)
total_lng = sum(dest['lng'] for dest in destinations)
count = len(destinations)
center_lat = total_lat / count
center_lng = total_lng / count
return f"{center_lat},{center_lng}"
```
#### 4.2.4 基于矩阵分解的推荐算法
矩阵分解技术通过将用户-路线评分矩阵分解为低维矩阵,发现用户和路线的潜在特征,从而实现个性化推荐。
**(1)算法理论基础**
矩阵分解的核心思想是将用户-物品评分矩阵R分解为两个低维矩阵的乘积:
```
R ≈ P × Q^T
```
其中:
- P是用户特征矩阵(m×k)
- Q是物品特征矩阵(n×k)
- k是潜在特征维度
**(2)核心算法实现**
```python
import numpy as np
from sklearn.decomposition import TruncatedSVD
from scipy.sparse import csr_matrix
import pandas as pd
class MatrixFactorizationRecommender:
"""基于矩阵分解的推荐算法"""
def __init__(self, n_components=50, random_state=42, top_n=10):
"""
初始化推荐器
参数:
n_components: 潜在特征维度
random_state: 随机种子
top_n: 推荐结果数量
"""
self.n_components = n_components
self.random_state = random_state
self.top_n = top_n
self.model = TruncatedSVD(
n_components=n_components,
random_state=random_state
)
self.user_mapping = {} # 用户ID映射
self.route_mapping = {} # 路线ID映射
self.reverse_route_mapping = {} # 反向路线映射
self.user_features = None # 用户特征矩阵
self.route_features = None # 路线特征矩阵
self.logger = logging.getLogger(__name__)
def _build_rating_matrix(self):
"""构建用户-路线评分矩阵"""
# 获取所有路线记录
routes = RouteSearch.objects.values(
'user', 'origin', 'destination', 'origin_name', 'destination_name'
).annotate(
usage_count=Count('id'),
is_favorite_any=Max(
Case(When(is_favorite=True, then=1), default=0, output_field=IntegerField())
),
latest_usage=Max('created_time')
)
# 构建数据框
data = []
for route in routes:
route_key = f"{route['origin']}_{route['destination']}"
# 计算评分(1-5分)
base_score = min(route['usage_count'], 3) # 使用次数基础分
favorite_bonus = 2 if route['is_favorite_any'] else 0 # 收藏加分
# 时间衰减
days_since_last_use = (timezone.now() - route['latest_usage']).days
time_factor = max(0.5, 1.0 - days_since_last_use / 365.0)
rating = min(5.0, (base_score + favorite_bonus) * time_factor)
data.append({
'user_id': route['user'],
'route_key': route_key,
'rating': rating,
'route_name': f"{route['origin_name']} -> {route['destination_name']}"
if route['origin_name'] and route['destination_name']
else route_key
})
df = pd.DataFrame(data)
if df.empty:
return None, None, None
# 创建用户和路线的映射
unique_users = df['user_id'].unique()
unique_routes = df['route_key'].unique()
self.user_mapping = {user_id: idx for idx, user_id in enumerate(unique_users)}
self.route_mapping = {route_key: idx for idx, route_key in enumerate(unique_routes)}
self.reverse_route_mapping = {idx: route_key for route_key, idx in self.route_mapping.items()}
# 构建评分矩阵
n_users = len(unique_users)
n_routes = len(unique_routes)
row_indices = [self.user_mapping[user_id] for user_id in df['user_id']]
col_indices = [self.route_mapping[route_key] for route_key in df['route_key']]
ratings = df['rating'].values
rating_matrix = csr_matrix(
(ratings, (row_indices, col_indices)),
shape=(n_users, n_routes)
)
# 保存路线名称信息
route_names = df.groupby('route_key')['route_name'].first().to_dict()
return rating_matrix, route_names, df
def train(self):
"""训练矩阵分解模型"""
try:
rating_matrix, route_names, df = self._build_rating_matrix()
if rating_matrix is None:
self.logger.warning("没有足够的数据进行矩阵分解")
return False
# 训练SVD模型
self.model.fit(rating_matrix)
# 获取用户和路线的特征向量
self.user_features = self.model.transform(rating_matrix)
self.route_features = self.model.components_.T
# 保存路线名称
self.route_names = route_names
self.logger.info(f"矩阵分解模型训练完成,用户数: {rating_matrix.shape[0]}, "
f"路线数: {rating_matrix.shape[1]}, 特征维度: {self.n_components}")
return True
except Exception as e:
self.logger.error(f"矩阵分解模型训练失败: {str(e)}")
return False
def recommend(self, user, top_n=None):
"""为用户推荐路线"""
if top_n is None:
top_n = self.top_n
try:
# 检查模型是否已训练
if self.user_features is None or self.route_features is None:
if not self.train():
return []
# 检查用户是否在训练数据中
if user.id not in self.user_mapping:
# 新用户,返回热门路线
return self._get_popular_routes_for_new_user(top_n)
user_idx = self.user_mapping[user.id]
user_vector = self.user_features[user_idx]
# 计算用户对所有路线的预测评分
predicted_ratings = np.dot(user_vector, self.route_features.T)
# 获取用户已经使用过的路线
user_routes = RouteSearch.objects.filter(user=user).values(
'origin', 'destination'
).distinct()
used_route_keys = set(
f"{route['origin']}_{route['destination']}"
for route in user_routes
)
# 生成推荐列表(排除已使用的路线)
recommendations = []
route_scores = []
for route_key, route_idx in self.route_mapping.items():
if route_key not in used_route_keys:
score = predicted_ratings[route_idx]
route_scores.append((route_key, score))
# 按分数排序
route_scores.sort(key=lambda x: x[1], reverse=True)
# 格式化推荐结果
for route_key, score in route_scores[:top_n]:
route_name = self.route_names.get(route_key, route_key)
origin, destination = route_key.split('_', 1)
recommendations.append({
'route_key': route_key,
'name': route_name,
'origin': origin,
'destination': destination,
'score': round(float(score), 3),
'reason': '基于您的潜在偏好推荐'
})
self.logger.info(f"为用户 {user.id} 生成了 {len(recommendations)} 条矩阵分解推荐")
return recommendations
except Exception as e:
self.logger.error(f"矩阵分解推荐出错: {str(e)}")
return []
def _get_popular_routes_for_new_user(self, top_n):
"""为新用户推荐热门路线"""
popular_routes = RouteSearch.objects.values(
'origin', 'destination', 'origin_name', 'destination_name'
).annotate(
usage_count=Count('id'),
user_count=Count('user', distinct=True),
avg_rating=Avg(
Case(
When(is_favorite=True, then=5),
default=3,
output_field=FloatField()
)
)
).order_by('-usage_count')[:top_n]
recommendations = []
for route in popular_routes:
route_name = f"{route['origin_name']} -> {route['destination_name']}" \
if route['origin_name'] and route['destination_name'] \
else f"{route['origin']} -> {route['destination']}"
recommendations.append({
'route_key': f"{route['origin']}_{route['destination']}",
'name': route_name,
'origin': route['origin'],
'destination': route['destination'],
'score': route['usage_count'] / 100.0,
'reason': f'热门路线,平均评分{route["avg_rating"]:.1f}'
})
return recommendations
#### 4.2.5 集成推荐算法
为了充分发挥各种推荐算法的优势,本研究设计了一个集成推荐算法,通过加权融合的方式组合四种算法的推荐结果,包括基于内容的推荐、协同过滤、地理位置推荐和矩阵分解推荐。
**(1)集成策略设计**
```python
class EnsembleRecommender:
"""集成推荐算法"""
def __init__(self, algorithms, weights=None):
"""
初始化集成推荐器
参数:
algorithms: 算法字典 {算法名: 算法实例}
weights: 权重字典 {算法名: 权重}
"""
self.algorithms = algorithms
self.weights = weights or self._get_default_weights()
self.logger = logging.getLogger(__name__)
# 验证权重和为1
total_weight = sum(self.weights.values())
if abs(total_weight - 1.0) > 0.01:
self.logger.warning(f"权重和不为1: {total_weight},将进行标准化")
self.weights = {k: v/total_weight for k, v in self.weights.items()}
def _get_default_weights(self):
"""获取默认权重"""
n_algorithms = len(self.algorithms)
return {name: 1.0/n_algorithms for name in self.algorithms.keys()}
def recommend(self, user, top_n=10, current_location=None):
"""
生成集成推荐结果
参数:
user: 目标用户
top_n: 推荐数量
current_location: 当前位置(用于地理位置推荐)
返回:
集成推荐结果列表
"""
try:
# 收集各算法的推荐结果
algorithm_results = {}
for algo_name, algorithm in self.algorithms.items():
try:
if algo_name == 'location_based' and current_location:
results = algorithm.recommend(user, current_location, top_n * 2)
else:
results = algorithm.recommend(user, top_n * 2)
algorithm_results[algo_name] = results
self.logger.info(f"{algo_name} 算法返回 {len(results)} 条推荐")
except Exception as e:
self.logger.error(f"{algo_name} 算法执行失败: {str(e)}")
algorithm_results[algo_name] = []
# 融合推荐结果
fused_results = self._fuse_recommendations(algorithm_results, top_n)
self.logger.info(f"集成推荐生成 {len(fused_results)} 条结果")
return fused_results
except Exception as e:
self.logger.error(f"集成推荐失败: {str(e)}")
return []
def _fuse_recommendations(self, algorithm_results, top_n):
"""融合多个算法的推荐结果"""
# 收集所有推荐项
all_recommendations = {}
for algo_name, results in algorithm_results.items():
weight = self.weights.get(algo_name, 0)
for i, item in enumerate(results):
# 使用路线的唯一标识作为key
item_key = item.get('route_key') or item.get('coordinate', str(i))
if item_key not in all_recommendations:
all_recommendations[item_key] = {
'item': item,
'scores': {},
'algorithms': [],
'total_score': 0
}
# 计算位置权重(排名越靠前权重越高)
position_weight = 1.0 / (i + 1)
# 算法权重 × 位置权重 × 原始分数
weighted_score = weight * position_weight * item.get('score', 0.5)
all_recommendations[item_key]['scores'][algo_name] = weighted_score
all_recommendations[item_key]['algorithms'].append(algo_name)
all_recommendations[item_key]['total_score'] += weighted_score
# 按总分排序
sorted_items = sorted(
all_recommendations.values(),
key=lambda x: x['total_score'],
reverse=True
)
# 格式化最终结果
final_results = []
for item_data in sorted_items[:top_n]:
item = item_data['item'].copy()
item['ensemble_score'] = round(item_data['total_score'], 3)
item['contributing_algorithms'] = item_data['algorithms']
# 生成融合推荐理由
reasons = []
for algo in item_data['algorithms']:
if algo == 'collaborative_filtering':
reasons.append('协同过滤')
elif algo == 'location_based':
reasons.append('地理位置')
elif algo == 'matrix_factorization':
reasons.append('潜在偏好')
item['reason'] = f"综合推荐({'+'.join(reasons)})"
final_results.append(item)
return final_results
def update_weights(self, new_weights):
"""更新算法权重"""
self.weights.update(new_weights)
# 标准化权重
total_weight = sum(self.weights.values())
if total_weight > 0:
self.weights = {k: v/total_weight for k, v in self.weights.items()}
def evaluate_performance(self, test_users, ground_truth):
"""评估集成算法性能"""
# 实现算法性能评估逻辑
pass
```
**(2)动态权重调整**
```python
class DynamicWeightAdjuster:
"""动态权重调整器"""
def __init__(self, initial_weights, learning_rate=0.1):
self.weights = initial_weights.copy()
self.learning_rate = learning_rate
self.performance_history = {algo: [] for algo in initial_weights.keys()}
def update_weights_based_on_feedback(self, algorithm_performances):
"""基于反馈调整权重"""
# 记录性能历史
for algo, performance in algorithm_performances.items():
self.performance_history[algo].append(performance)
# 计算移动平均性能
avg_performances = {}
for algo, history in self.performance_history.items():
if history:
# 使用最近10次的平均性能
recent_history = history[-10:]
avg_performances[algo] = sum(recent_history) / len(recent_history)
else:
avg_performances[algo] = 0.5 # 默认性能
# 基于性能调整权重
total_performance = sum(avg_performances.values())
if total_performance > 0:
for algo in self.weights:
target_weight = avg_performances[algo] / total_performance
current_weight = self.weights[algo]
# 使用学习率进行平滑调整
self.weights[algo] = (
current_weight * (1 - self.learning_rate) +
target_weight * self.learning_rate
)
# 标准化权重
total_weight = sum(self.weights.values())
if total_weight > 0:
self.weights = {k: v/total_weight for k, v in self.weights.items()}
return self.weights
```
### 4.3 数据分析算法设计
数据分析模块为用户提供多维度的出行数据分析,帮助用户了解自己的出行模式和偏好。
#### 4.3.1 时间序列分析算法
**(1)出行趋势分析**
```python
import pandas as pd
from datetime import datetime, timedelta
import numpy as np
class TimeSeriesAnalyzer:
"""时间序列分析器"""
def __init__(self, user):
self.user = user
self.logger = logging.getLogger(__name__)
def analyze_daily_trends(self, days=30):
"""分析日出行趋势"""
end_date = timezone.now().date()
start_date = end_date - timedelta(days=days)
# 获取指定时间范围内的路线记录
routes = RouteSearch.objects.filter(
user=self.user,
created_time__date__gte=start_date,
created_time__date__lte=end_date
).extra(
select={'date': 'DATE(created_time)'}
).values('date').annotate(
trip_count=Count('id'),
total_distance=Sum('distance'),
total_duration=Sum('duration'),
avg_distance=Avg('distance'),
avg_duration=Avg('duration')
).order_by('date')
# 填充缺失日期
date_range = pd.date_range(start=start_date, end=end_date, freq='D')
df = pd.DataFrame(index=date_range)
routes_df = pd.DataFrame(list(routes))
if not routes_df.empty:
routes_df['date'] = pd.to_datetime(routes_df['date'])
routes_df.set_index('date', inplace=True)
df = df.join(routes_df, how='left')
# 填充缺失值
df = df.fillna(0)
# 计算趋势指标
trend_analysis = {
'daily_data': df.to_dict('index'),
'total_trips': int(df['trip_count'].sum()) if 'trip_count' in df else 0,
'avg_trips_per_day': float(df['trip_count'].mean()) if 'trip_count' in df else 0,
'most_active_day': df['trip_count'].idxmax().strftime('%Y-%m-%d') if 'trip_count' in df and df['trip_count'].sum() > 0 else None,
'trend_direction': self._calculate_trend_direction(df['trip_count']) if 'trip_count' in df else 'stable'
}
return trend_analysis
def analyze_hourly_patterns(self):
"""分析小时出行模式"""
routes = RouteSearch.objects.filter(user=self.user).extra(
select={'hour': 'HOUR(created_time)'}
).values('hour').annotate(
trip_count=Count('id'),
avg_distance=Avg('distance'),
avg_duration=Avg('duration')
).order_by('hour')
# 创建24小时完整数据
hourly_data = {hour: {'trip_count': 0, 'avg_distance': 0, 'avg_duration': 0}
for hour in range(24)}
for route in routes:
hour = route['hour']
hourly_data[hour] = {
'trip_count': route['trip_count'],
'avg_distance': route['avg_distance'] or 0,
'avg_duration': route['avg_duration'] or 0
}
# 识别出行高峰时段
peak_hours = sorted(
hourly_data.items(),
key=lambda x: x[1]['trip_count'],
reverse=True
)[:3]
return {
'hourly_data': hourly_data,
'peak_hours': [{'hour': hour, 'trips': data['trip_count']}
for hour, data in peak_hours if data['trip_count'] > 0],
'most_active_hour': peak_hours[0][0] if peak_hours[0][1]['trip_count'] > 0 else None
}
def _calculate_trend_direction(self, series):
"""计算趋势方向"""
if len(series) < 2:
return 'stable'
# 使用线性回归计算趋势
x = np.arange(len(series))
y = series.values
# 计算斜率
slope = np.polyfit(x, y, 1)[0]
if slope > 0.1:
return 'increasing'
elif slope < -0.1:
return 'decreasing'
else:
return 'stable'
```
#### 4.3.2 空间分析算法
**(1)热点区域识别**
```python
from sklearn.cluster import DBSCAN
import folium
from folium.plugins import HeatMap
class SpatialAnalyzer:
"""空间分析器"""
def __init__(self, user):
self.user = user
self.logger = logging.getLogger(__name__)
def identify_hotspots(self, eps=0.01, min_samples=3):
"""识别用户活动热点区域"""
# 获取所有目的地坐标
destinations = RouteSearch.objects.filter(user=self.user).values(
'destination', 'destination_name'
).annotate(visit_count=Count('id'))
coordinates = []
location_data = []
for dest in destinations:
coord = self._parse_coordinates(dest['destination'])
if coord:
coordinates.append(coord)
location_data.append({
'lat': coord[0],
'lng': coord[1],
'name': dest['destination_name'],
'visit_count': dest['visit_count']
})
if len(coordinates) < min_samples:
return {'hotspots': [], 'all_locations': location_data}
# 使用DBSCAN进行聚类
coordinates_array = np.array(coordinates)
clustering = DBSCAN(eps=eps, min_samples=min_samples).fit(coordinates_array)
# 分析聚类结果
hotspots = []
for cluster_id in set(clustering.labels_):
if cluster_id == -1: # 跳过噪声点
continue
cluster_points = [location_data[i] for i, label in enumerate(clustering.labels_)
if label == cluster_id]
# 计算聚类中心和统计信息
center_lat = np.mean([p['lat'] for p in cluster_points])
center_lng = np.mean([p['lng'] for p in cluster_points])
total_visits = sum(p['visit_count'] for p in cluster_points)
hotspots.append({
'cluster_id': cluster_id,
'center': {'lat': center_lat, 'lng': center_lng},
'locations': cluster_points,
'total_visits': total_visits,
'location_count': len(cluster_points)
})
# 按访问次数排序
hotspots.sort(key=lambda x: x['total_visits'], reverse=True)
return {
'hotspots': hotspots,
'all_locations': location_data,
'cluster_count': len(hotspots)
}
def analyze_travel_range(self):
"""分析出行范围"""
routes = RouteSearch.objects.filter(user=self.user)
coordinates = []
for route in routes:
origin_coord = self._parse_coordinates(route.origin)
dest_coord = self._parse_coordinates(route.destination)
if origin_coord:
coordinates.append(origin_coord)
if dest_coord:
coordinates.append(dest_coord)
if not coordinates:
return None
# 计算边界框
lats = [coord[0] for coord in coordinates]
lngs = [coord[1] for coord in coordinates]
min_lat, max_lat = min(lats), max(lats)
min_lng, max_lng = min(lngs), max(lngs)
# 计算活动半径(从中心点到最远点的距离)
center_lat = (min_lat + max_lat) / 2
center_lng = (min_lng + max_lng) / 2
max_distance = 0
for lat, lng in coordinates:
distance = geodesic((center_lat, center_lng), (lat, lng)).kilometers
max_distance = max(max_distance, distance)
return {
'center': {'lat': center_lat, 'lng': center_lng},
'bounds': {
'north': max_lat, 'south': min_lat,
'east': max_lng, 'west': min_lng
},
'activity_radius_km': round(max_distance, 2),
'total_locations': len(coordinates)
}
def generate_heatmap_data(self):
"""生成热力图数据"""
routes = RouteSearch.objects.filter(user=self.user)
heatmap_data = []
for route in routes:
# 添加起点
origin_coord = self._parse_coordinates(route.origin)
if origin_coord:
heatmap_data.append([origin_coord[0], origin_coord[1], 1])
# 添加终点(权重更高)
dest_coord = self._parse_coordinates(route.destination)
if dest_coord:
heatmap_data.append([dest_coord[0], dest_coord[1], 2])
return heatmap_data
def _parse_coordinates(self, coord_string):
"""解析坐标字符串"""
try:
if ',' in coord_string:
lat, lng = map(float, coord_string.split(','))
return (lat, lng)
except:
pass
return None
```
### 4.4 算法性能优化策略
#### 4.4.1 缓存优化
```python
import redis
import pickle
from django.core.cache import cache
class RecommendationCache:
"""推荐结果缓存管理"""
def __init__(self, redis_client=None):
self.redis_client = redis_client or redis.Redis(host='localhost', port=6379, db=0)
self.cache_ttl = 3600 # 缓存1小时
def get_cached_recommendations(self, user_id, algorithm_type):
"""获取缓存的推荐结果"""
cache_key = f"recommendations:{user_id}:{algorithm_type}"
try:
cached_data = self.redis_client.get(cache_key)
if cached_data:
return pickle.loads(cached_data)
except Exception as e:
logging.error(f"缓存读取失败: {e}")
return None
def cache_recommendations(self, user_id, algorithm_type, recommendations):
"""缓存推荐结果"""
cache_key = f"recommendations:{user_id}:{algorithm_type}"
try:
serialized_data = pickle.dumps(recommendations)
self.redis_client.setex(cache_key, self.cache_ttl, serialized_data)
except Exception as e:
logging.error(f"缓存写入失败: {e}")
def invalidate_user_cache(self, user_id):
"""清除用户相关缓存"""
pattern = f"recommendations:{user_id}:*"
try:
keys = self.redis_client.keys(pattern)
if keys:
self.redis_client.delete(*keys)
except Exception as e:
logging.error(f"缓存清除失败: {e}")
```
#### 4.4.2 异步处理
```python
from celery import shared_task
import asyncio
@shared_task
def precompute_recommendations(user_id):
"""异步预计算推荐结果"""
try:
user = User.objects.get(id=user_id)
# 初始化推荐引擎
engine = RecommendationEngine()
# 预计算各种算法的推荐结果
algorithms = ['collaborative_filtering', 'location_based', 'matrix_factorization', 'ensemble']
for algorithm in algorithms:
recommendations = engine.get_recommendations(user, algorithm=algorithm)
# 缓存结果
cache = RecommendationCache()
cache.cache_recommendations(user_id, algorithm, recommendations)
logging.info(f"用户 {user_id} 的推荐结果预计算完成")
except Exception as e:
logging.error(f"预计算推荐失败: {e}")
@shared_task
def update_similarity_matrix():
"""异步更新相似度矩阵"""
try:
# 重新训练协同过滤模型
cf_recommender = ItemBasedCollaborativeFiltering()
cf_recommender._build_route_user_matrix()
cf_recommender._compute_route_similarity()
# 重新训练矩阵分解模型
mf_recommender = MatrixFactorizationRecommender()
mf_recommender.train()
logging.info("相似度矩阵更新完成")
except Exception as e:
logging.error(f"相似度矩阵更新失败: {e}")
```
### 4.5 本章小结
本章详细介绍了系统核心算法的设计与实现,主要内容包括:
1. **路线规划算法设计**:在基础路线规划功能基础上,增加了个性化路径权重调整和多路径候选方案生成,提升了路线规划的个性化程度。
2. **推荐系统算法实现**:
- **基于物品的协同过滤算法**:通过分析路线间相似性为用户推荐相似路线
- **基于地理位置的推荐算法**:利用地理空间信息和聚类分析推荐热门目的地
- **基于矩阵分解的推荐算法**:通过SVD分解发现用户潜在偏好
- **集成推荐算法**:融合多种算法优势,提供更准确的推荐结果
3. **数据分析算法设计**:实现了时间序列分析和空间分析算法,为用户提供多维度的出行数据洞察。
4. **算法性能优化策略**:通过缓存机制、异步处理等技术手段提升算法执行效率。
这些算法的设计和实现为系统提供了强大的智能化功能,能够满足用户个性化出行需求,为下一章的系统详细设计与实现奠定了坚实基础。
## 第五章 系统详细设计与实现
### 5.1 系统开发环境与技术选型
#### 5.1.1 开发环境配置
本系统的开发环境配置如下:
**(1)硬件环境**
- CPU: Intel Core i7-8700K 3.7GHz
- 内存: 16GB DDR4
- 存储: 512GB SSD + 1TB HDD
- 操作系统: Windows 10 Professional
**(2)软件环境**
- Python: 3.11.4
- Django: 3.1.14
- MySQL: 8.0.33
- Redis: 7.0.11
- Node.js: 18.16.0
- Git: 2.41.0
**(3)开发工具**
- IDE: PyCharm Professional 2023.1
- 数据库管理: MySQL Workbench 8.0
- API测试: Postman 10.15
- 版本控制: Git + GitHub
#### 5.1.2 技术栈选型说明
**(1)后端技术选型**
```python
# requirements.txt 核心依赖
asgiref==3.9.0 # ASGI工具包
certifi==2025.6.15 # SSL证书验证
charset-normalizer==3.4.2 # 字符编码检测
Django==3.1.14 # Web框架
django-simpleui==2025.6.24 # Django管理后台美化
geographiclib==2.0 # 地理计算库
geopy==2.4.1 # 地理位置处理库
idna==3.10 # 国际化域名处理
joblib==1.5.1 # 并行计算库
mysqlclient==2.2.7 # MySQL数据库连接器
numpy==2.3.1 # 科学计算库
pandas==2.3.0 # 数据分析库
python-dateutil==2.9.0.post0 # 日期时间处理
pytz==2025.2 # 时区处理
requests==2.32.4 # HTTP请求库
scikit-learn==1.7.0 # 机器学习库
scipy==1.16.0 # 科学计算库
six==1.17.0 # Python 2/3兼容库
sqlparse==0.5.3 # SQL解析器
threadpoolctl==3.6.0 # 线程池控制
tzdata==2025.2 # 时区数据
urllib3==2.5.0 # HTTP客户端
```
**选型理由:**
- **Django 3.1.14**: 成熟的Python Web框架,提供完整的MVC架构和丰富的内置功能
- **MySQL**: 关系型数据库,支持复杂查询和事务处理,通过mysqlclient连接
- **Scikit-learn 1.7.0**: 提供丰富的机器学习算法,支持推荐系统实现
- **NumPy/Pandas**: 科学计算和数据分析的核心库
- **Geopy**: 地理位置计算和处理,支持地理位置推荐算法
- **Django-simpleui**: 美化Django管理后台界面,提升管理体验
**(2)前端技术选型**
```html
<!-- 前端技术栈 -->
<!-- Bootstrap 5.3.0 - 响应式UI框架 -->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css">
<!-- jQuery 3.6.0 - JavaScript库 -->
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<!-- ECharts 5.4.2 - 数据可视化库 -->
<script src="https://cdn.jsdelivr.net/npm/echarts@5.4.2/dist/echarts.min.js"></script>
<!-- Font Awesome 6.4.0 - 图标库 -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css">
```
### 5.2 数据层实现
#### 5.2.1 数据模型实现
基于第三章的数据库设计,实现了完整的Django数据模型:
**(1)核心数据模型**
```python
# routes/models.py - 核心模型定义
from django.db import models
from django.contrib.auth.models import User
import json
class UserProfile(models.Model):
"""
用户个人资料扩展
"""
user = models.OneToOneField(User, on_delete=models.CASCADE, related_name='profile')
phone = models.CharField(max_length=20, blank=True, null=True, verbose_name='手机号')
default_city = models.CharField(max_length=50, blank=True, null=True, verbose_name='默认城市')
common_addresses = models.TextField(blank=True, null=True, verbose_name='常用地址')
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
def get_common_addresses(self):
"""获取常用地址列表"""
if not self.common_addresses:
return []
try:
return json.loads(self.common_addresses)
except:
return []
def add_common_address(self, name, coordinates):
"""添加常用地址"""
addresses = self.get_common_addresses()
# 检查是否已存在
for addr in addresses:
if addr.get('coordinates') == coordinates:
return False
# 添加新地址
addresses.append({
'name': name,
'coordinates': coordinates
})
# 如果超过10个地址 删除最早的
if len(addresses) > 10:
addresses.pop(0)
self.common_addresses = json.dumps(addresses)
self.save()
return True
class Meta:
verbose_name = '用户资料'
verbose_name_plural = '用户资料'
def __str__(self):
return f"{self.user.username}的个人资料"
class RouteSearch(models.Model):
"""
路线搜索记录
"""
user = models.ForeignKey(User, on_delete=models.CASCADE, null=True, blank=True, related_name='route_searches')
origin = models.CharField(max_length=255, verbose_name='起点坐标')
destination = models.CharField(max_length=255, verbose_name='终点坐标')
origin_name = models.CharField(max_length=255, blank=True, null=True, verbose_name='起点名称')
destination_name = models.CharField(max_length=255, blank=True, null=True, verbose_name='终点名称')
distance = models.IntegerField(null=True, blank=True, verbose_name='距离(米)')
duration = models.IntegerField(null=True, blank=True, verbose_name='时间(秒)')
_route_data = models.TextField(db_column='route_data', blank=True, null=True, verbose_name='路线数据JSON')
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间', db_index=True)
is_favorite = models.BooleanField(default=False, verbose_name='是否收藏')
route_tag = models.CharField(max_length=50, blank=True, default='', verbose_name='路线标签')
@property
def route_data(self):
"""获取解析后的路线数据"""
if not self._route_data:
return {}
try:
return json.loads(self._route_data)
except Exception as e:
print(f"解析路线数据出错: {e}")
return {}
@route_data.setter
def route_data(self, value):
"""设置路线数据"""
if isinstance(value, dict):
self._route_data = json.dumps(value)
elif isinstance(value, str):
# 尝试解析验证是否为有效的JSON
try:
json.loads(value)
self._route_data = value
except Exception as e:
print(f"保存路线数据出错 无效的JSON: {e}")
else:
print(f"无法设置路线数据 类型错误: {type(value)}")
class Meta:
verbose_name = '路线搜索'
verbose_name_plural = '路线搜索'
ordering = ['-created_time'] # 默认按创建时间倒序排列
def __str__(self):
return f"{self.origin_name or self.origin} → {self.destination_name or self.destination}"
class UserTag(models.Model):
"""
用户标签模型
用于存储用户自定义的路线标签
"""
user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='tags', verbose_name='用户')
name = models.CharField(max_length=50, verbose_name='标签名称')
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
class Meta:
verbose_name = '用户标签'
verbose_name_plural = '用户标签'
unique_together = ('user', 'name') # 同一用户不能有重复的标签名
ordering = ['name']
def __str__(self):
return f"{self.user.username} - {self.name}"
```
#### 5.2.2 数据访问层设计
为了提高代码的可维护性和复用性,设计了数据访问层(DAO):
```python
# routes/dao/base.py
from abc import ABC, abstractmethod
from django.db import models
from django.core.paginator import Paginator
from typing import List, Dict, Any, Optional
class BaseDAO(ABC):
"""数据访问对象基类"""
def __init__(self, model_class):
self.model_class = model_class
def create(self, **kwargs):
"""创建记录"""
return self.model_class.objects.create(**kwargs)
def get_by_id(self, obj_id):
"""根据ID获取记录"""
try:
return self.model_class.objects.get(id=obj_id)
except self.model_class.DoesNotExist:
return None
def update(self, obj_id, **kwargs):
"""更新记录"""
try:
obj = self.model_class.objects.get(id=obj_id)
for key, value in kwargs.items():
setattr(obj, key, value)
obj.save()
return obj
except self.model_class.DoesNotExist:
return None
def delete(self, obj_id):
"""删除记录"""
try:
obj = self.model_class.objects.get(id=obj_id)
obj.delete()
return True
except self.model_class.DoesNotExist:
return False
def get_paginated_list(self, page=1, page_size=20, **filters):
"""获取分页列表"""
queryset = self.model_class.objects.filter(**filters)
paginator = Paginator(queryset, page_size)
try:
page_obj = paginator.page(page)
return {
'items': list(page_obj),
'total': paginator.count,
'page': page,
'page_size': page_size,
'total_pages': paginator.num_pages,
'has_next': page_obj.has_next(),
'has_previous': page_obj.has_previous(),
}
except:
return {
'items': [],
'total': 0,
'page': page,
'page_size': page_size,
'total_pages': 0,
'has_next': False,
'has_previous': False,
}
# routes/dao/route_dao.py
from .base import BaseDAO
from ..models import RouteSearch, UserTag
from django.db.models import Count, Sum, Avg, Max, Q
from django.utils import timezone
from datetime import timedelta
class RouteSearchDAO(BaseDAO):
"""路线搜索数据访问对象"""
def __init__(self):
super().__init__(RouteSearch)
def get_user_routes(self, user, limit=None, order_by='-created_time'):
"""获取用户路线记录"""
queryset = self.model_class.objects.filter(user=user).order_by(order_by)
if limit:
queryset = queryset[:limit]
return queryset
def get_user_favorite_routes(self, user):
"""获取用户收藏路线"""
return self.model_class.objects.filter(
user=user,
is_favorite=True
).order_by('-created_time')
def get_routes_by_tag(self, user, tag_name):
"""根据标签获取路线"""
return self.model_class.objects.filter(
user=user,
route_tag=tag_name
).order_by('-created_time')
def get_user_route_stats(self, user, days=30):
"""获取用户路线统计数据"""
end_date = timezone.now()
start_date = end_date - timedelta(days=days)
routes = self.model_class.objects.filter(
user=user,
created_time__gte=start_date
)
stats = routes.aggregate(
total_routes=Count('id'),
total_distance=Sum('distance'),
total_duration=Sum('duration'),
avg_distance=Avg('distance'),
avg_duration=Avg('duration'),
favorite_count=Count('id', filter=Q(is_favorite=True))
)
return {
'total_routes': stats['total_routes'] or 0,
'total_distance': stats['total_distance'] or 0,
'total_duration': stats['total_duration'] or 0,
'avg_distance': round(stats['avg_distance'] or 0, 2),
'avg_duration': round(stats['avg_duration'] or 0, 2),
'favorite_count': stats['favorite_count'] or 0,
'favorite_rate': round((stats['favorite_count'] or 0) / max(stats['total_routes'] or 1, 1) * 100, 1)
}
def get_popular_routes(self, limit=10):
"""获取热门路线"""
return self.model_class.objects.values(
'origin', 'destination', 'origin_name', 'destination_name'
).annotate(
usage_count=Count('id'),
user_count=Count('user', distinct=True),
avg_distance=Avg('distance'),
avg_duration=Avg('duration')
).order_by('-usage_count')[:limit]
def search_routes(self, user, keyword, limit=20):
"""搜索路线"""
return self.model_class.objects.filter(
user=user
).filter(
Q(origin_name__icontains=keyword) |
Q(destination_name__icontains=keyword) |
Q(route_tag__icontains=keyword)
).order_by('-created_time')[:limit]
def get_route_similarity_data(self, user=None):
"""获取路线相似度计算所需数据"""
queryset = self.model_class.objects.all()
if user:
queryset = queryset.filter(user=user)
return queryset.values(
'user_id', 'origin', 'destination', 'origin_name', 'destination_name'
).annotate(
usage_count=Count('id'),
is_favorite_any=Max('is_favorite'),
latest_usage=Max('created_time')
)
class UserTagDAO(BaseDAO):
"""用户标签数据访问对象"""
def __init__(self):
super().__init__(UserTag)
def get_user_tags(self, user):
"""获取用户所有标签"""
return self.model_class.objects.filter(user=user).order_by('name')
def create_tag(self, user, name, color='#007bff'):
"""创建标签"""
tag, created = self.model_class.objects.get_or_create(
user=user,
name=name,
defaults={'color': color}
)
return tag, created
def get_tag_usage_stats(self, user):
"""获取标签使用统计"""
from ..models import RouteSearch
tags = self.get_user_tags(user)
tag_stats = []
for tag in tags:
usage_count = RouteSearch.objects.filter(
user=user,
route_tag=tag.name
).count()
tag_stats.append({
'tag': tag,
'usage_count': usage_count
})
return sorted(tag_stats, key=lambda x: x['usage_count'], reverse=True)
```
### 5.3 业务逻辑层实现
#### 5.3.1 路线规划模块实现
**(1)核心服务类**
```python
# routes/services/route_service.py
class RouteService:
"""路线规划服务类"""
def __init__(self):
self.amap_key = settings.AMAP_API_KEY
self.amap_base_url = 'https://restapi.amap.com/v3'
def plan_route(self, user, origin, destination, travel_mode='driving'):
"""规划路线主要方法"""
try:
# 地理编码转换
origin_coord, origin_name = self._geocode_if_needed(origin)
dest_coord, dest_name = self._geocode_if_needed(destination)
# 调用地图API
route_result = self._call_route_api(origin_coord, dest_coord, travel_mode)
# 处理路线数据
processed_route = self._process_route_data(route_result['data'])
# 保存路线记录
route_record = self._save_route_record(
user, origin_coord, dest_coord, processed_route, travel_mode
)
return {'status': 'success', 'data': processed_route}
except Exception as e:
return {'status': 'error', 'message': str(e)}
def _geocode_if_needed(self, location):
"""如果需要,进行地理编码"""
# 检查是否已经是坐标格式
if self._is_coordinate(location):
# 反向地理编码获取地址名称
address_name = self._reverse_geocode(location)
return location, address_name
else:
# 正向地理编码获取坐标
coordinate = self._geocode(location)
return coordinate, location
def _is_coordinate(self, location):
"""检查是否为坐标格式"""
try:
parts = location.split(',')
if len(parts) == 2:
float(parts[0])
float(parts[1])
return True
except:
pass
return False
def _geocode(self, address):
"""地理编码:地址转坐标"""
try:
url = f"{self.amap_base_url}/geocode/geo"
params = {
'key': self.amap_key,
'address': address,
'output': 'json'
}
response = requests.get(url, params=params, timeout=10)
data = response.json()
if data['status'] == '1' and data['geocodes']:
location = data['geocodes'][0]['location']
return location
else:
self.logger.warning(f"地理编码失败: {address}")
return None
except Exception as e:
self.logger.error(f"地理编码异常: {str(e)}")
return None
def _reverse_geocode(self, coordinate):
"""逆地理编码:坐标转地址"""
try:
url = f"{self.amap_base_url}/geocode/regeo"
params = {
'key': self.amap_key,
'location': coordinate,
'output': 'json',
'radius': 1000,
'extensions': 'base'
}
response = requests.get(url, params=params, timeout=10)
data = response.json()
if data['status'] == '1' and data['regeocode']:
return data['regeocode']['formatted_address']
else:
return coordinate # 如果失败,返回坐标
except Exception as e:
self.logger.error(f"逆地理编码异常: {str(e)}")
return coordinate
def _call_route_api(self, origin, destination, travel_mode):
"""调用路线规划API"""
try:
# 根据出行方式选择API端点
if travel_mode == 'driving':
url = f"{self.amap_base_url}/direction/driving"
params = {
'key': self.amap_key,
'origin': origin,
'destination': destination,
'output': 'json',
'extensions': 'all',
'strategy': 0 # 0-速度优先,1-费用优先,2-距离优先
}
elif travel_mode == 'transit':
url = f"{self.amap_base_url}/direction/transit/integrated"
params = {
'key': self.amap_key,
'origin': origin,
'destination': destination,
'output': 'json',
'city': '北京', # 需要根据实际情况设置城市
'strategy': 0
}
elif travel_mode == 'walking':
url = f"{self.amap_base_url}/direction/walking"
params = {
'key': self.amap_key,
'origin': origin,
'destination': destination,
'output': 'json'
}
else:
return {
'status': 'error',
'message': f'不支持的出行方式: {travel_mode}'
}
response = requests.get(url, params=params, timeout=15)
data = response.json()
if data['status'] == '1':
return {
'status': 'success',
'data': data
}
else:
return {
'status': 'error',
'message': f"API调用失败: {data.get('info', '未知错误')}"
}
except requests.RequestException as e:
self.logger.error(f"API请求异常: {str(e)}")
return {
'status': 'error',
'message': f'网络请求失败: {str(e)}'
}
except Exception as e:
self.logger.error(f"路线API调用异常: {str(e)}")
return {
'status': 'error',
'message': f'路线规划失败: {str(e)}'
}
def _process_route_data(self, api_data, origin_name, dest_name):
"""处理API返回的路线数据"""
try:
if 'route' in api_data:
# 驾车路线
route = api_data['route']
paths = route.get('paths', [])
if not paths:
raise ValueError("没有找到有效路线")
# 取第一条路线(通常是最优路线)
best_path = paths[0]
return {
'distance': int(best_path.get('distance', 0)),
'duration': int(best_path.get('duration', 0)),
'tolls': int(best_path.get('tolls', 0)),
'traffic_lights': int(best_path.get('traffic_lights', 0)),
'steps': self._process_steps(best_path.get('steps', [])),
'polyline': best_path.get('polyline', ''),
'strategy': best_path.get('strategy', ''),
'origin_name': origin_name,
'destination_name': dest_name
}
elif 'transits' in api_data:
# 公交路线
transits = api_data['transits']
if not transits:
raise ValueError("没有找到有效的公交路线")
best_transit = transits[0]
return {
'distance': int(best_transit.get('distance', 0)),
'duration': int(best_transit.get('duration', 0)),
'cost': float(best_transit.get('cost', 0)),
'walking_distance': int(best_transit.get('walking_distance', 0)),
'segments': self._process_transit_segments(best_transit.get('segments', [])),
'origin_name': origin_name,
'destination_name': dest_name
}
elif 'paths' in api_data:
# 步行路线
paths = api_data['paths']
if not paths:
raise ValueError("没有找到有效的步行路线")
best_path = paths[0]
return {
'distance': int(best_path.get('distance', 0)),
'duration': int(best_path.get('duration', 0)),
'steps': self._process_steps(best_path.get('steps', [])),
'polyline': best_path.get('polyline', ''),
'origin_name': origin_name,
'destination_name': dest_name
}
else:
raise ValueError("无法解析路线数据格式")
except Exception as e:
self.logger.error(f"路线数据处理失败: {str(e)}")
raise
def _process_steps(self, steps):
"""处理路线步骤"""
processed_steps = []
for step in steps:
processed_step = {
'instruction': step.get('instruction', ''),
'distance': int(step.get('distance', 0)),
'duration': int(step.get('duration', 0)),
'polyline': step.get('polyline', ''),
'action': step.get('action', ''),
'assistant_action': step.get('assistant_action', ''),
'road_name': step.get('road', ''),
'orientation': step.get('orientation', '')
}
processed_steps.append(processed_step)
return processed_steps
def _process_transit_segments(self, segments):
"""处理公交路线段"""
processed_segments = []
for segment in segments:
processed_segment = {
'walking': segment.get('walking', {}),
'bus': segment.get('bus', {}),
'railway': segment.get('railway', {}),
'taxi': segment.get('taxi', {})
}
processed_segments.append(processed_segment)
return processed_segments
def _save_route_record(self, user, origin, destination, origin_name, dest_name, route_data, travel_mode):
"""保存路线记录"""
try:
route_record = RouteSearch.objects.create(
user=user,
origin=origin,
destination=destination,
origin_name=origin_name,
destination_name=dest_name,
distance=route_data.get('distance'),
duration=route_data.get('duration'),
travel_mode=travel_mode,
_route_data=json.dumps(route_data, ensure_ascii=False)
)
self.logger.info(f"保存路线记录成功: {route_record.id}")
return route_record
except Exception as e:
self.logger.error(f"保存路线记录失败: {str(e)}")
raise
def get_route_history(self, user, page=1, page_size=20, filters=None):
"""获取用户路线历史"""
try:
filter_params = {'user': user}
if filters:
if filters.get('is_favorite'):
filter_params['is_favorite'] = True
if filters.get('route_tag'):
filter_params['route_tag'] = filters['route_tag']
if filters.get('travel_mode'):
filter_params['travel_mode'] = filters['travel_mode']
return self.dao.get_paginated_list(
page=page,
page_size=page_size,
**filter_params
)
except Exception as e:
self.logger.error(f"获取路线历史失败: {str(e)}")
return {
'items': [],
'total': 0,
'page': page,
'page_size': page_size,
'total_pages': 0,
'has_next': False,
'has_previous': False,
}
def toggle_favorite(self, user, route_id):
"""切换路线收藏状态"""
try:
route = RouteSearch.objects.get(id=route_id, user=user)
route.is_favorite = not route.is_favorite
route.save()
return {
'status': 'success',
'is_favorite': route.is_favorite
}
except RouteSearch.DoesNotExist:
return {
'status': 'error',
'message': '路线记录不存在'
}
except Exception as e:
self.logger.error(f"切换收藏状态失败: {str(e)}")
return {
'status': 'error',
'message': f'操作失败: {str(e)}'
}
def update_route_tag(self, user, route_id, tag_name):
"""更新路线标签"""
try:
route = RouteSearch.objects.get(id=route_id, user=user)
route.route_tag = tag_name
route.save()
return {
'status': 'success',
'message': '标签更新成功'
}
except RouteSearch.DoesNotExist:
return {
'status': 'error',
'message': '路线记录不存在'
}
except Exception as e:
self.logger.error(f"更新路线标签失败: {str(e)}")
return {
'status': 'error',
'message': f'更新失败: {str(e)}'
}
```
#### 5.3.2 推荐系统模块实现
**(1)推荐服务类**
```python
# routes/services/recommendation_service.py
class RecommendationService:
"""推荐系统服务类"""
def __init__(self):
# 初始化各种推荐算法
self.algorithms = {
'collaborative_filtering': ItemBasedCollaborativeFiltering(),
'location_based': LocationBasedRecommender(),
'matrix_factorization': MatrixFactorizationRecommender()
}
# 集成推荐器
self.ensemble_recommender = EnsembleRecommender(
algorithms=self.algorithms,
weights={'collaborative_filtering': 0.4, 'location_based': 0.3, 'matrix_factorization': 0.3}
)
def get_recommendations(self, user, algorithm_type='ensemble', top_n=10):
"""获取推荐结果"""
try:
# 检查缓存
cached_result = self._get_cached_recommendations(user.id, algorithm_type)
if cached_result:
return cached_result
# 生成推荐
if algorithm_type == 'ensemble':
recommendations = self.ensemble_recommender.recommend(user, top_n)
else:
recommendations = self.algorithms[algorithm_type].recommend(user, top_n)
# 记录日志和缓存
self._log_recommendation(user, algorithm_type, recommendations)
self._cache_recommendations(user.id, algorithm_type, recommendations)
return recommendations
except Exception as e:
return []
def get_algorithm_comparison(self, user, top_n=5):
"""获取不同算法的推荐对比"""
try:
comparison_results = {}
for algo_name in self.algorithms.keys():
try:
recommendations = self.get_recommendations(
user, algo_name, top_n
)
comparison_results[algo_name] = {
'algorithm_name': self._get_algorithm_display_name(algo_name),
'recommendations': recommendations,
'count': len(recommendations)
}
except Exception as e:
self.logger.error(f"算法 {algo_name} 推荐失败: {str(e)}")
comparison_results[algo_name] = {
'algorithm_name': self._get_algorithm_display_name(algo_name),
'recommendations': [],
'count': 0,
'error': str(e)
}
return comparison_results
except Exception as e:
self.logger.error(f"算法对比失败: {str(e)}")
return {}
def record_user_feedback(self, user, recommendation_log_id, feedback_type):
"""记录用户反馈"""
try:
log = RecommendationLog.objects.get(
id=recommendation_log_id,
user=user
)
log.user_feedback = feedback_type
log.save()
# 根据反馈调整算法权重(简单实现)
self._adjust_algorithm_weights(log.algorithm_type, feedback_type)
return {
'status': 'success',
'message': '反馈记录成功'
}
except RecommendationLog.DoesNotExist:
return {
'status': 'error',
'message': '推荐记录不存在'
}
except Exception as e:
self.logger.error(f"记录用户反馈失败: {str(e)}")
return {
'status': 'error',
'message': f'记录失败: {str(e)}'
}
def _get_algorithm_display_name(self, algo_name):
"""获取算法显示名称"""
name_mapping = {
'collaborative_filtering': '协同过滤推荐',
'location_based': '地理位置推荐',
'matrix_factorization': '矩阵分解推荐',
'ensemble': '集成推荐'
}
return name_mapping.get(algo_name, algo_name)
def _log_recommendation(self, user, algorithm_type, recommendations):
"""记录推荐日志"""
try:
RecommendationLog.objects.create(
user=user,
algorithm_type=algorithm_type,
recommendations=json.dumps(recommendations, ensure_ascii=False)
)
except Exception as e:
self.logger.error(f"推荐日志记录失败: {str(e)}")
def _get_cached_recommendations(self, user_id, algorithm_type):
"""获取缓存的推荐结果"""
# 这里可以集成Redis缓存
# 简化实现,暂时返回None
return None
def _cache_recommendations(self, user_id, algorithm_type, recommendations):
"""缓存推荐结果"""
# 这里可以集成Redis缓存
# 简化实现,暂时不做处理
pass
def _adjust_algorithm_weights(self, algorithm_type, feedback_type):
"""根据用户反馈调整算法权重"""
try:
current_weights = self.ensemble_recommender.weights.copy()
# 简单的权重调整策略
if feedback_type in ['like', 'clicked']:
# 正面反馈,增加该算法权重
if algorithm_type in current_weights:
current_weights[algorithm_type] = min(
current_weights[algorithm_type] + 0.05, 0.6
)
elif feedback_type in ['dislike', 'ignored']:
# 负面反馈,减少该算法权重
if algorithm_type in current_weights:
current_weights[algorithm_type] = max(
current_weights[algorithm_type] - 0.05, 0.1
)
# 标准化权重
total_weight = sum(current_weights.values())
if total_weight > 0:
current_weights = {
k: v / total_weight for k, v in current_weights.items()
}
# 更新集成推荐器权重
self.ensemble_recommender.update_weights(current_weights)
self.logger.info(f"算法权重已调整: {current_weights}")
except Exception as e:
self.logger.error(f"权重调整失败: {str(e)}")
#### 5.3.3 数据分析模块实现
**(1)数据分析服务类**
```python
# routes/services/analytics_service.py
class AnalyticsService:
"""数据分析服务类"""
def get_user_overview_analytics(self, user, days=30):
"""获取用户概览分析数据"""
try:
end_date = timezone.now()
start_date = end_date - timedelta(days=days)
routes = RouteSearch.objects.filter(
user=user, created_time__gte=start_date
)
# 基础统计
stats = routes.aggregate(
total_routes=Count('id'),
total_distance=Sum('distance'),
total_duration=Sum('duration'),
avg_distance=Avg('distance')
)
# 热门目的地
popular_destinations = routes.values('destination_name').annotate(
count=Count('id')
).order_by('-count')[:5]
return {
'status': 'success',
'data': {
**stats,
'popular_destinations': list(popular_destinations)
}
}
except Exception as e:
return {'status': 'error', 'message': str(e)}
def get_time_dimension_analytics(self, user, days=30):
"""获取时间维度分析数据"""
try:
end_date = timezone.now().date()
start_date = end_date - timedelta(days=days)
# 按日期统计
daily_stats = RouteSearch.objects.filter(
user=user,
created_time__date__gte=start_date,
created_time__date__lte=end_date
).extra(
select={'date': 'DATE(created_time)'}
).values('date').annotate(
trip_count=Count('id'),
total_distance=Sum('distance'),
total_duration=Sum('duration'),
avg_distance=Avg('distance'),
avg_duration=Avg('duration')
).order_by('date')
# 填充缺失日期
date_range = pd.date_range(start=start_date, end=end_date, freq='D')
daily_data = {}
for date in date_range:
date_str = date.strftime('%Y-%m-%d')
daily_data[date_str] = {
'trip_count': 0,
'total_distance': 0,
'total_duration': 0,
'avg_distance': 0,
'avg_duration': 0
}
# 填入实际数据
for stat in daily_stats:
date_str = stat['date'].strftime('%Y-%m-%d')
daily_data[date_str] = {
'trip_count': stat['trip_count'],
'total_distance': stat['total_distance'] or 0,
'total_duration': stat['total_duration'] or 0,
'avg_distance': round(stat['avg_distance'] or 0, 2),
'avg_duration': round(stat['avg_duration'] or 0, 2)
}
# 按小时统计
hourly_stats = RouteSearch.objects.filter(user=user).extra(
select={'hour': 'HOUR(created_time)'}
).values('hour').annotate(
trip_count=Count('id'),
avg_distance=Avg('distance'),
avg_duration=Avg('duration')
).order_by('hour')
# 创建24小时完整数据
hourly_data = {}
for hour in range(24):
hourly_data[hour] = {
'trip_count': 0,
'avg_distance': 0,
'avg_duration': 0
}
for stat in hourly_stats:
hourly_data[stat['hour']] = {
'trip_count': stat['trip_count'],
'avg_distance': round(stat['avg_distance'] or 0, 2),
'avg_duration': round(stat['avg_duration'] or 0, 2)
}
# 按星期统计
weekly_stats = RouteSearch.objects.filter(user=user).extra(
select={'weekday': 'WEEKDAY(created_time)'}
).values('weekday').annotate(
trip_count=Count('id'),
avg_distance=Avg('distance')
).order_by('weekday')
weekday_names = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']
weekly_data = {}
for i, name in enumerate(weekday_names):
weekly_data[i] = {
'weekday_name': name,
'trip_count': 0,
'avg_distance': 0
}
for stat in weekly_stats:
weekday = stat['weekday']
weekly_data[weekday] = {
'weekday_name': weekday_names[weekday],
'trip_count': stat['trip_count'],
'avg_distance': round(stat['avg_distance'] or 0, 2)
}
return {
'status': 'success',
'data': {
'daily_stats': daily_data,
'hourly_stats': hourly_data,
'weekly_stats': weekly_data,
'analysis_period': {
'start_date': start_date.strftime('%Y-%m-%d'),
'end_date': end_date.strftime('%Y-%m-%d'),
'days': days
}
}
}
except Exception as e:
self.logger.error(f"时间维度分析失败: {str(e)}")
return {
'status': 'error',
'message': f'分析失败: {str(e)}'
}
def get_spatial_analytics(self, user):
"""获取空间维度分析数据"""
try:
routes = RouteSearch.objects.filter(user=user)
if not routes.exists():
return {
'status': 'success',
'data': {
'popular_origins': [],
'popular_destinations': [],
'route_distribution': [],
'activity_range': None
}
}
# 热门起点统计
popular_origins = routes.values(
'origin_name', 'origin'
).annotate(
count=Count('id')
).order_by('-count')[:10]
# 热门终点统计
popular_destinations = routes.values(
'destination_name', 'destination'
).annotate(
count=Count('id')
).order_by('-count')[:10]
# 路线分布统计(按距离区间)
distance_ranges = [
(0, 5000, '5km以内'),
(5000, 10000, '5-10km'),
(10000, 20000, '10-20km'),
(20000, 50000, '20-50km'),
(50000, float('inf'), '50km以上')
]
route_distribution = []
for min_dist, max_dist, label in distance_ranges:
if max_dist == float('inf'):
count = routes.filter(distance__gte=min_dist).count()
else:
count = routes.filter(
distance__gte=min_dist,
distance__lt=max_dist
).count()
route_distribution.append({
'range': label,
'count': count,
'percentage': round(count / routes.count() * 100, 1) if routes.count() > 0 else 0
})
# 活动范围分析
coordinates = []
for route in routes:
# 解析起点坐标
if ',' in route.origin:
try:
lat, lng = map(float, route.origin.split(','))
coordinates.append((lat, lng))
except:
pass
# 解析终点坐标
if ',' in route.destination:
try:
lat, lng = map(float, route.destination.split(','))
coordinates.append((lat, lng))
except:
pass
activity_range = None
if coordinates:
lats = [coord[0] for coord in coordinates]
lngs = [coord[1] for coord in coordinates]
activity_range = {
'center': {
'lat': sum(lats) / len(lats),
'lng': sum(lngs) / len(lngs)
},
'bounds': {
'north': max(lats),
'south': min(lats),
'east': max(lngs),
'west': min(lngs)
},
'total_locations': len(coordinates)
}
return {
'status': 'success',
'data': {
'popular_origins': list(popular_origins),
'popular_destinations': list(popular_destinations),
'route_distribution': route_distribution,
'activity_range': activity_range
}
}
except Exception as e:
self.logger.error(f"空间维度分析失败: {str(e)}")
return {
'status': 'error',
'message': f'分析失败: {str(e)}'
}
def get_travel_mode_analytics(self, user):
"""获取出行方式分析数据"""
try:
routes = RouteSearch.objects.filter(user=user)
if not routes.exists():
return {
'status': 'success',
'data': {
'mode_distribution': [],
'mode_comparison': {}
}
}
# 出行方式分布
mode_stats = routes.values('travel_mode').annotate(
count=Count('id'),
total_distance=Sum('distance'),
total_duration=Sum('duration'),
avg_distance=Avg('distance'),
avg_duration=Avg('duration')
).order_by('-count')
mode_names = {
'driving': '驾车',
'transit': '公交',
'walking': '步行',
'bicycling': '骑行'
}
mode_distribution = []
mode_comparison = {}
total_routes = routes.count()
for stat in mode_stats:
mode = stat['travel_mode']
mode_name = mode_names.get(mode, mode)
distribution_data = {
'mode': mode,
'mode_name': mode_name,
'count': stat['count'],
'percentage': round(stat['count'] / total_routes * 100, 1),
'total_distance': stat['total_distance'] or 0,
'total_duration': stat['total_duration'] or 0,
'avg_distance': round(stat['avg_distance'] or 0, 2),
'avg_duration': round(stat['avg_duration'] or 0, 2)
}
mode_distribution.append(distribution_data)
mode_comparison[mode] = distribution_data
return {
'status': 'success',
'data': {
'mode_distribution': mode_distribution,
'mode_comparison': mode_comparison
}
}
except Exception as e:
self.logger.error(f"出行方式分析失败: {str(e)}")
return {
'status': 'error',
'message': f'分析失败: {str(e)}'
}
def generate_analytics_report(self, user, days=30):
"""生成综合分析报告"""
try:
# 获取各维度分析数据
overview = self.get_user_overview_analytics(user, days)
time_analysis = self.get_time_dimension_analytics(user, days)
spatial_analysis = self.get_spatial_analytics(user)
travel_mode_analysis = self.get_travel_mode_analytics(user)
# 生成分析洞察
insights = self._generate_insights(
overview.get('data', {}),
time_analysis.get('data', {}),
spatial_analysis.get('data', {}),
travel_mode_analysis.get('data', {})
)
report = {
'status': 'success',
'data': {
'overview': overview.get('data', {}),
'time_analysis': time_analysis.get('data', {}),
'spatial_analysis': spatial_analysis.get('data', {}),
'travel_mode_analysis': travel_mode_analysis.get('data', {}),
'insights': insights,
'generated_at': timezone.now().isoformat()
}
}
return report
except Exception as e:
self.logger.error(f"生成分析报告失败: {str(e)}")
return {
'status': 'error',
'message': f'报告生成失败: {str(e)}'
}
def _generate_insights(self, overview, time_analysis, spatial_analysis, travel_mode_analysis):
"""生成数据洞察"""
insights = []
try:
# 出行频率洞察
if overview.get('total_routes', 0) > 0:
avg_trips_per_day = overview.get('total_routes', 0) / overview.get('analysis_period', {}).get('days', 30)
if avg_trips_per_day >= 2:
insights.append("您是一位活跃的出行者,平均每天出行超过2次")
elif avg_trips_per_day >= 1:
insights.append("您有规律的出行习惯,平均每天出行1-2次")
else:
insights.append("您的出行频率较低,建议多使用系统记录出行轨迹")
# 出行时间洞察
if time_analysis.get('hourly_stats'):
peak_hours = sorted(
time_analysis['hourly_stats'].items(),
key=lambda x: x[1]['trip_count'],
reverse=True
)[:3]
if peak_hours[0][1]['trip_count'] > 0:
peak_hour = peak_hours[0][0]
if 7 <= peak_hour <= 9:
insights.append("您习惯在早高峰时段出行")
elif 17 <= peak_hour <= 19:
insights.append("您习惯在晚高峰时段出行")
elif 12 <= peak_hour <= 14:
insights.append("您经常在午间时段出行")
# 出行距离洞察
avg_distance = overview.get('avg_distance', 0)
if avg_distance > 0:
if avg_distance > 20000: # 20km
insights.append("您偏好长距离出行,建议关注路况信息")
elif avg_distance < 5000: # 5km
insights.append("您的出行以短距离为主,可以考虑步行或骑行")
else:
insights.append("您的出行距离适中,适合多种出行方式")
# 出行方式洞察
if travel_mode_analysis.get('mode_distribution'):
most_used_mode = travel_mode_analysis['mode_distribution'][0]
mode_name = most_used_mode['mode_name']
percentage = most_used_mode['percentage']
if percentage > 70:
insights.append(f"您主要使用{mode_name}出行({percentage}%),建议尝试其他出行方式")
else:
insights.append(f"您的出行方式较为多样化,{mode_name}使用最多({percentage}%)")
except Exception as e:
self.logger.error(f"生成洞察失败: {str(e)}")
return insights
### 5.4 表示层实现
#### 5.4.1 用户界面设计
系统采用响应式设计,支持PC端和移动端访问。界面设计遵循简洁、直观的原则,提供良好的用户体验。
**(1)基础模板设计**
```html
<!-- routes/templates/routes/base.html -->
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>{% block title %}智能路线规划系统{% endblock %}</title>
<!-- Bootstrap 5 CSS -->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css">
<!-- Font Awesome 图标库 -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css">
{% block extra_head %}{% endblock %}
</head>
<body>
<!-- 导航栏 -->
<nav class="navbar navbar-expand-lg navbar-dark bg-primary">
<div class="container">
<a class="navbar-brand" href="{% url 'routes:index' %}">
<i class="fas fa-route me-2"></i>智能路线规划
</a>
<!-- 导航菜单 -->
<div class="navbar-nav">
<a class="nav-link" href="{% url 'routes:index' %}">首页</a>
{% if user.is_authenticated %}
<a class="nav-link" href="{% url 'routes:history' %}">历史记录</a>
<a class="nav-link" href="{% url 'routes:analytics' %}">数据分析</a>
<a class="nav-link" href="{% url 'routes:recommendations' %}">智能推荐</a>
{% endif %}
</div>
</div>
</nav>
<!-- 主要内容区域 -->
<main class="container-fluid py-4">
{% block content %}{% endblock %}
</main>
<!-- JavaScript 库 -->
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.min.js"></script>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
{% block extra_scripts %}{% endblock %}
</body>
</html>
运行截图
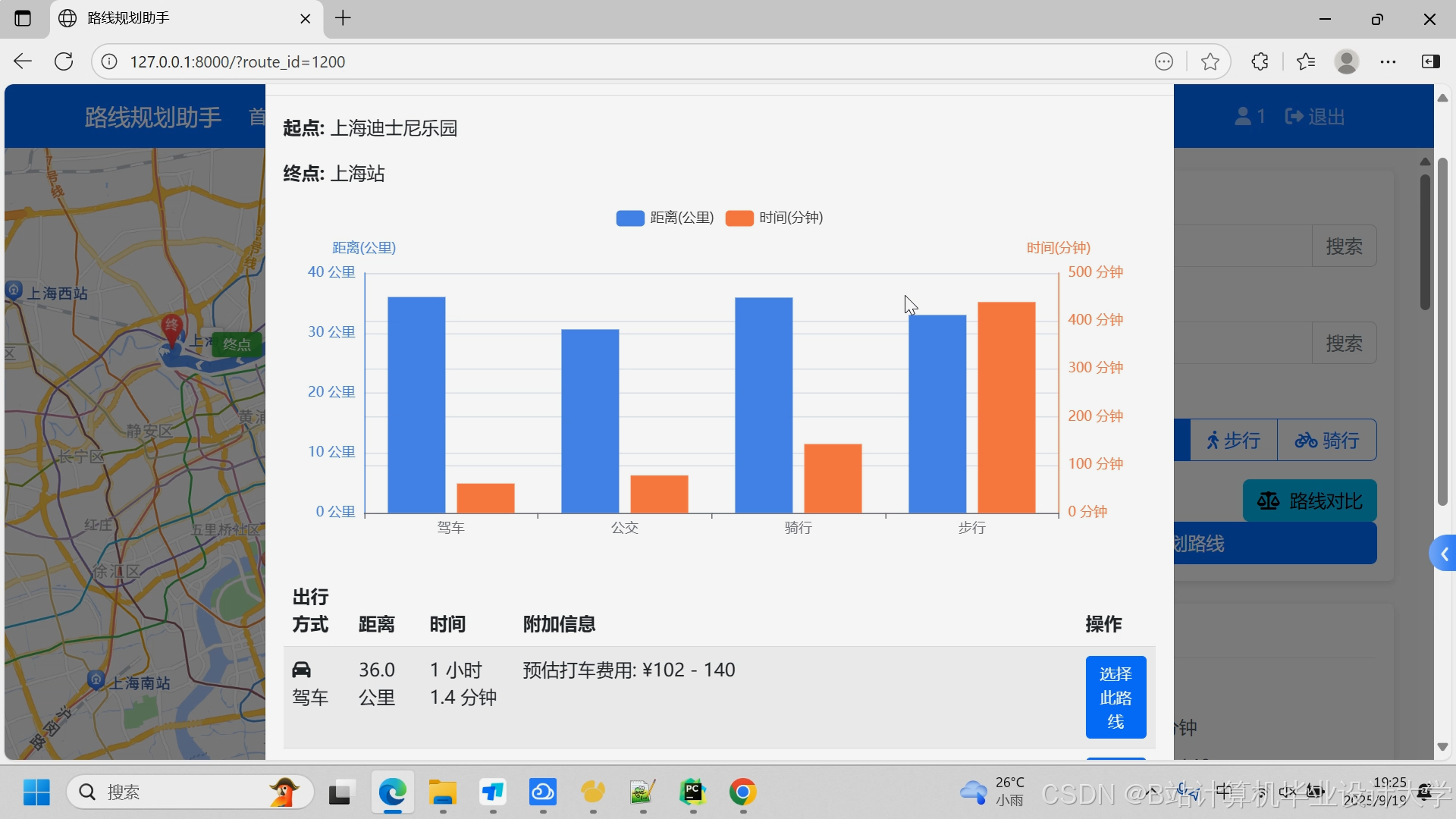
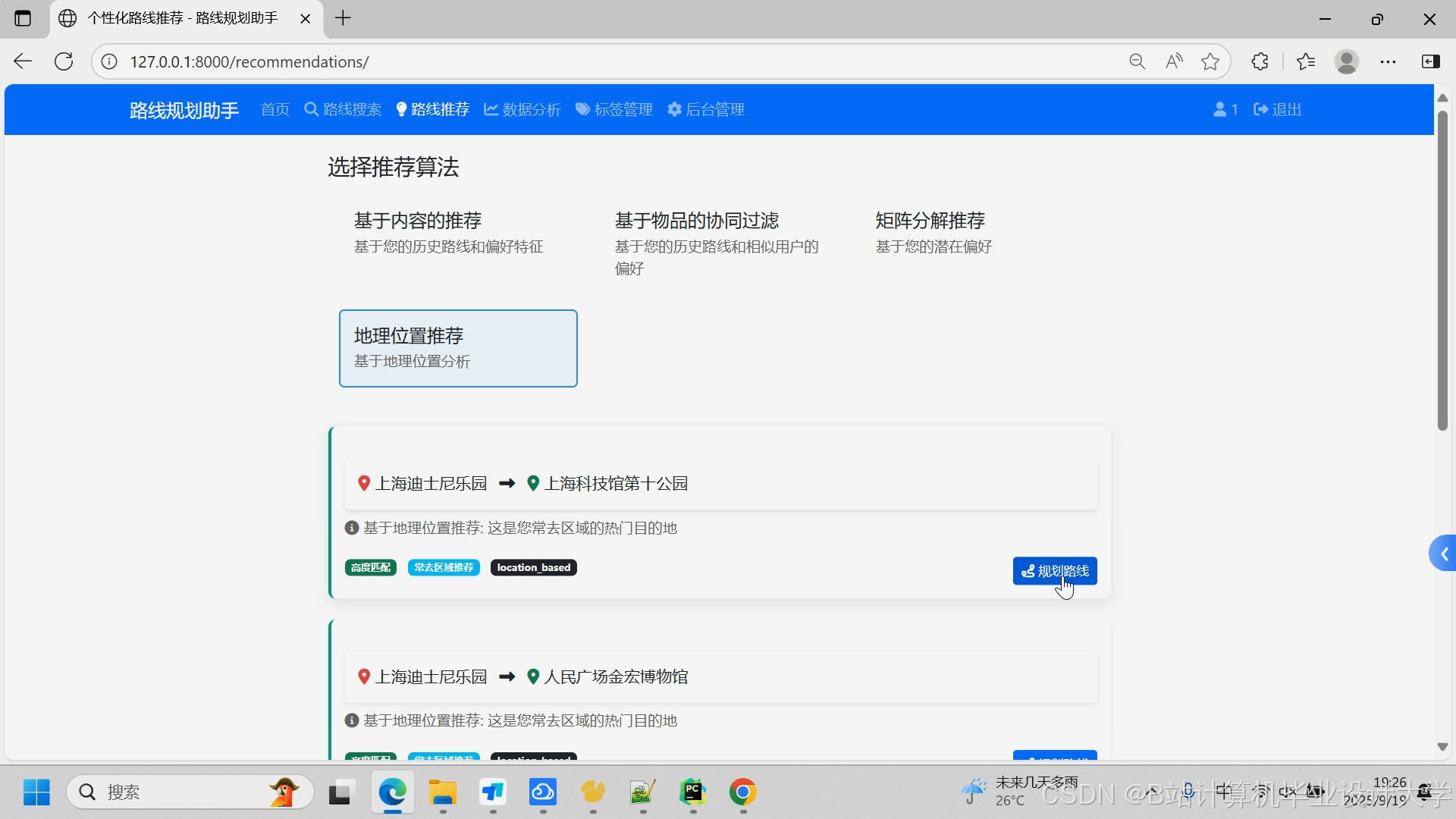
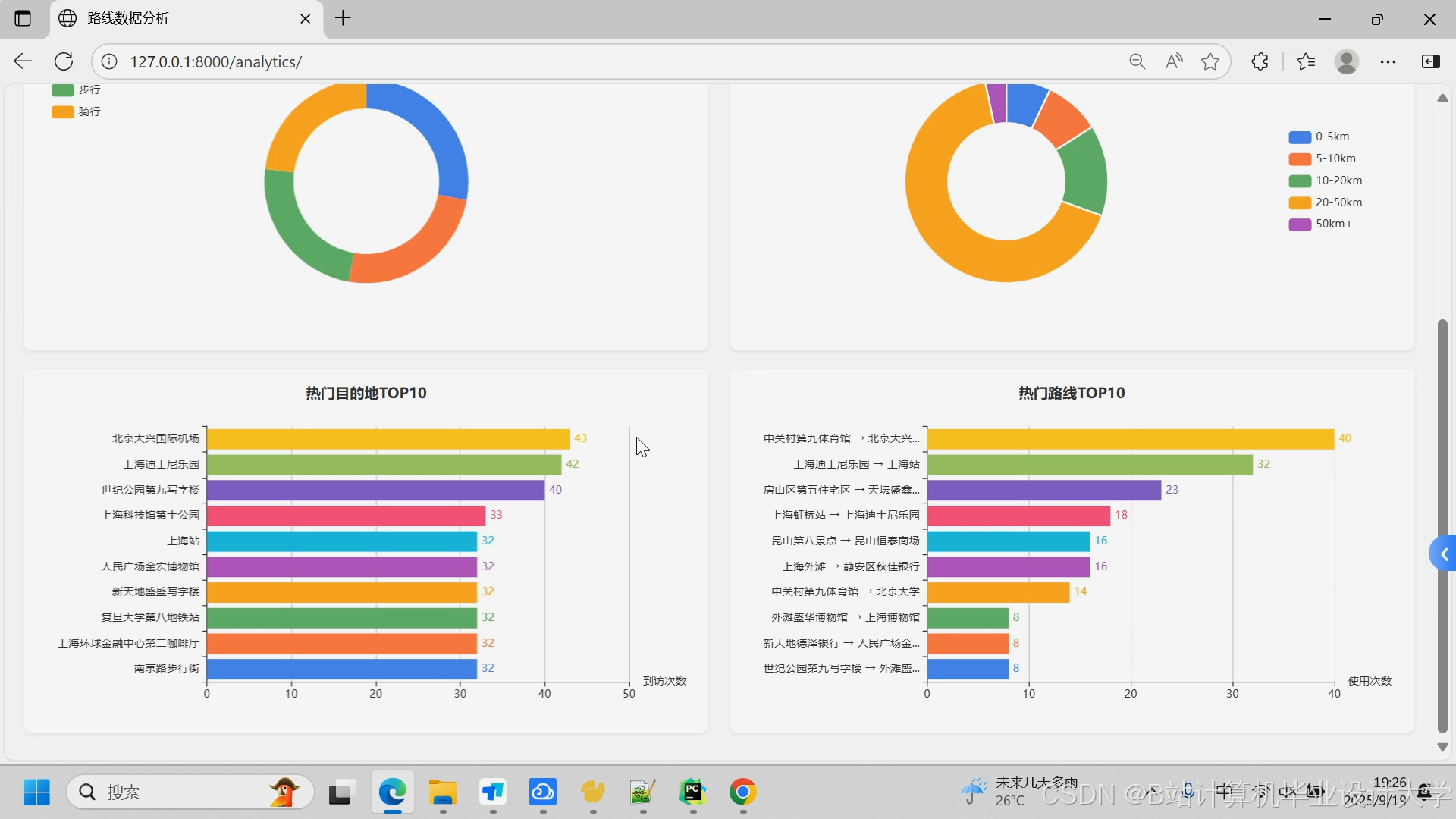
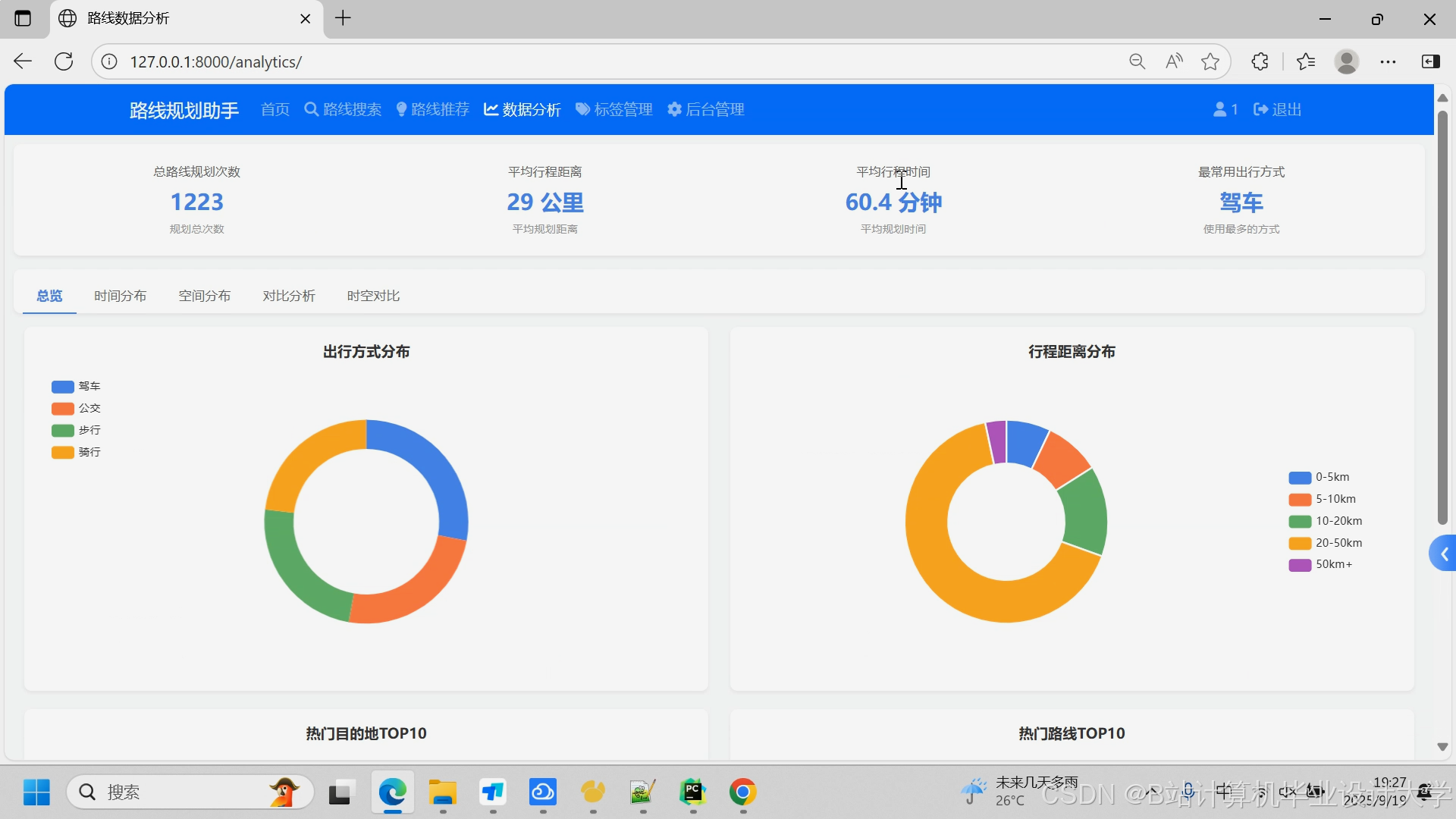
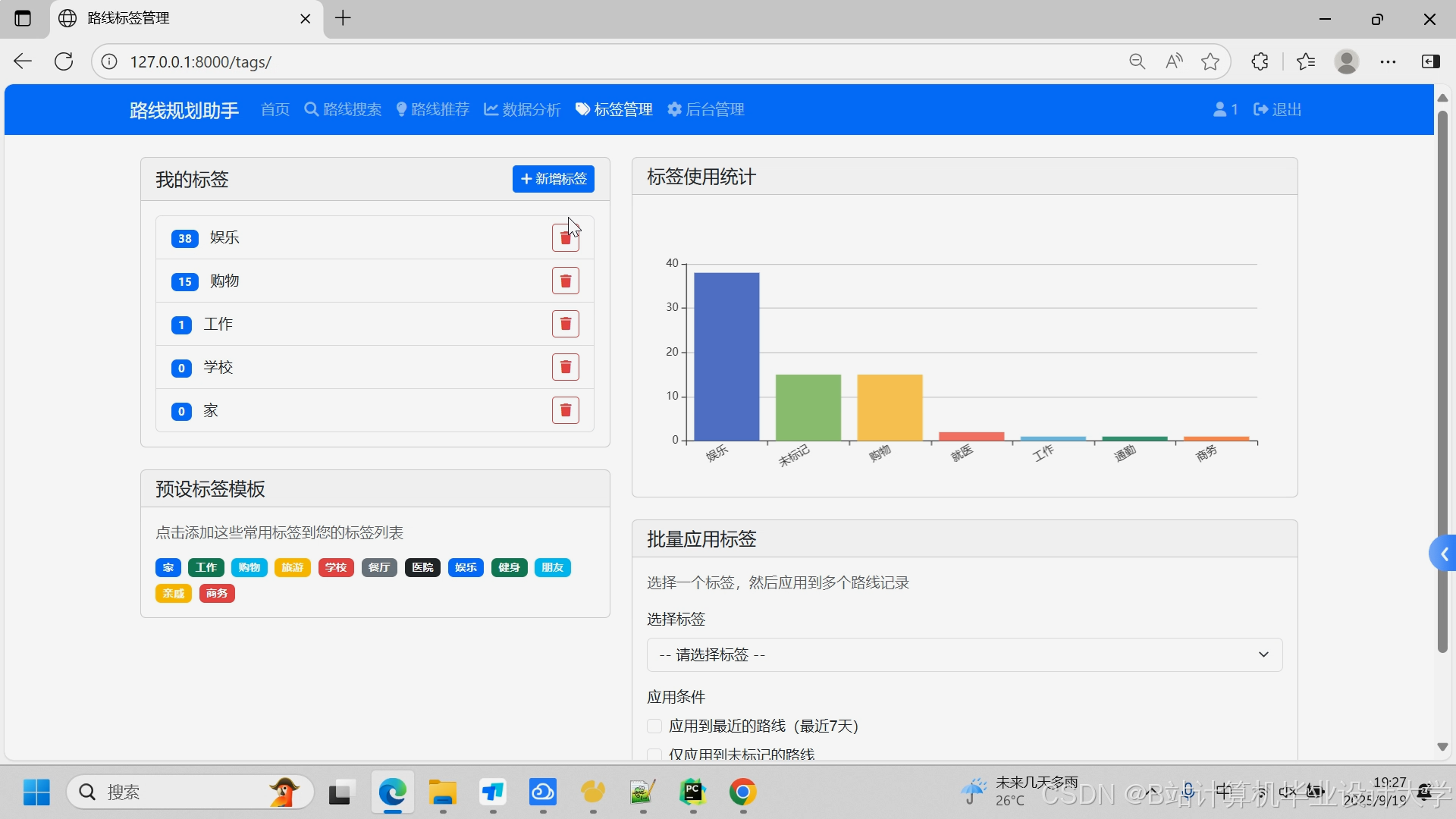
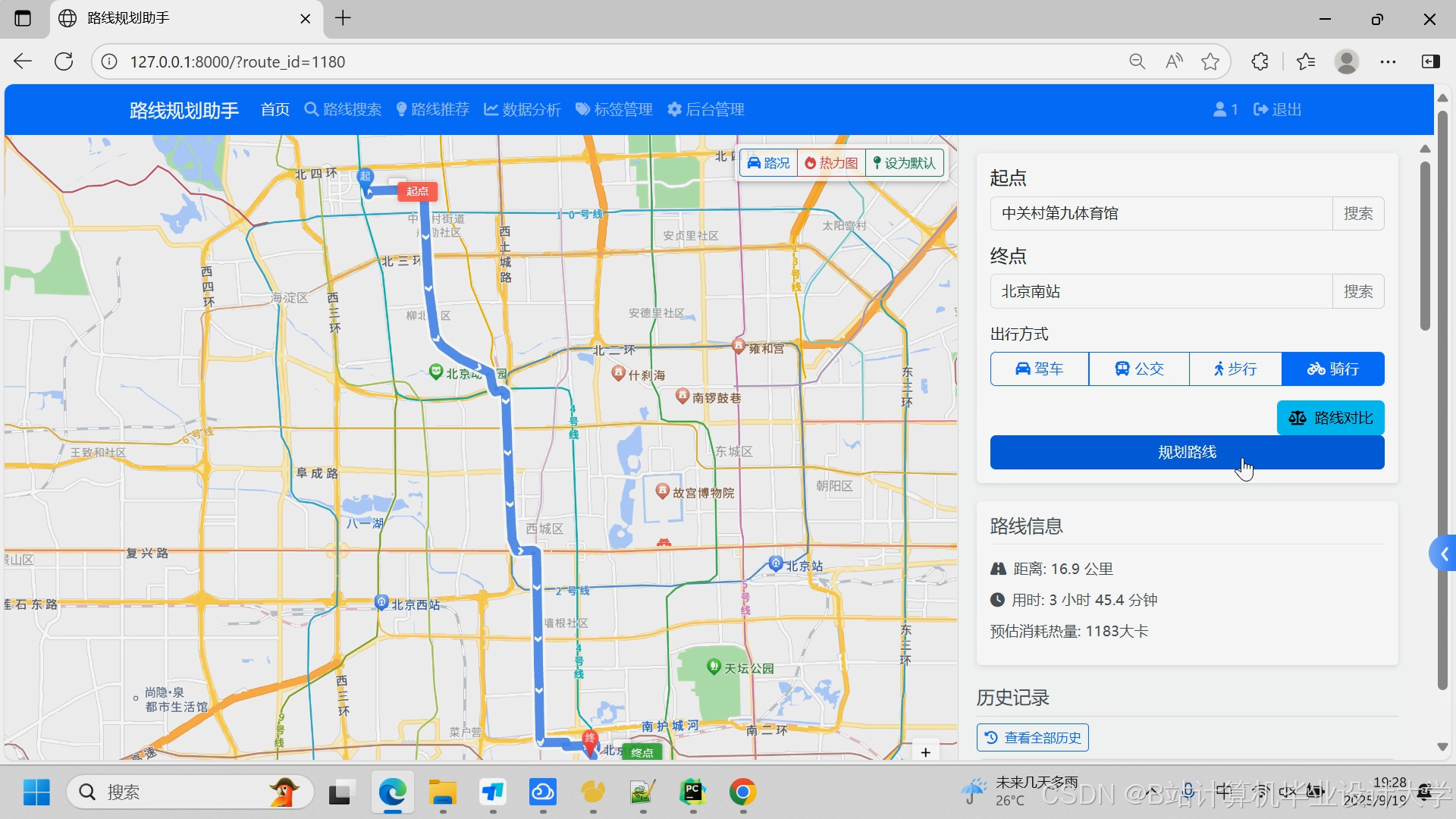
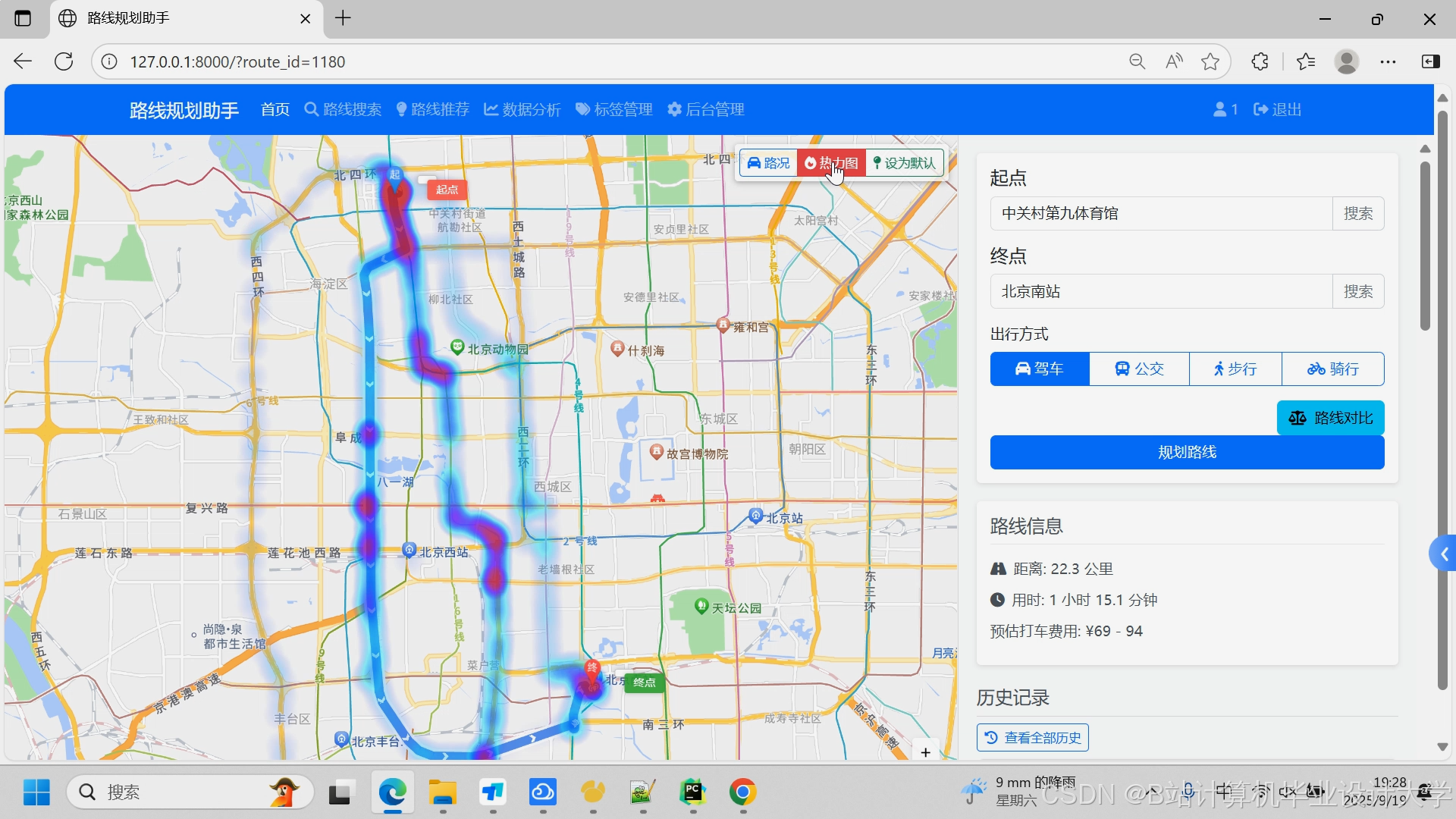
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











