




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Hadoop+Spark+Hive共享单车预测系统与数据可视化分析》的任务书模板,涵盖系统设计、技术实现、任务分工及验收标准等内容:
任务书:Hadoop+Spark+Hive共享单车预测系统与数据可视化分析
一、项目背景与目标
1. 背景
共享单车作为城市短途出行的重要方式,其使用量受天气、时间、地理位置、节假日等因素影响显著。传统分析方法难以处理海量历史订单数据(如每秒数万条骑行记录),且缺乏实时预测能力。本项目旨在构建基于大数据技术的共享单车需求预测系统,整合Hadoop分布式存储、Spark实时计算与Hive数据仓库,实现高精度需求预测与可视化分析,为车辆调度、运维优化提供决策支持。
2. 目标
- 分析目标:挖掘影响骑行需求的关键因素(如温度、降雨量、工作日/周末)。
- 预测目标:构建时空预测模型(准确率≥90%),预测未来1小时各区域骑行需求量。
- 可视化目标:开发交互式仪表盘,展示实时需求热力图、历史趋势对比与异常检测结果。
二、系统架构与技术方案
1. 系统架构
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据采集层 │ → │ 数据存储层 │ → │ 分析计算层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
↑ ↑ ↑ | |
┌───────────────────────────────────────────────────────────────────┐ | |
│ 可视化与应用层 │ | |
└───────────────────────────────────────────────────────────────────┘ |
- 数据采集层:
- 从共享单车运营商API(如
/orders/realtime)获取实时订单数据(订单ID、车辆ID、起始时间、位置)。 - 集成第三方气象API(如和风天气)获取温度、湿度、降雨量等环境数据。
- 使用Flume采集日志数据,通过Kafka实现高并发消息缓冲。
- 从共享单车运营商API(如
- 数据存储层:
- Hadoop HDFS存储原始数据(ORC格式压缩,压缩比达70%)。
- Hive管理结构化数据,创建外部表映射HDFS路径,支持SQL查询与分区优化。
- 分析计算层:
- Spark SQL处理批量数据(特征工程、模型训练)。
- Spark Streaming分析实时数据流(如突发需求预警)。
- MLlib训练时空预测模型(LSTM神经网络或XGBoost集成学习)。
- 可视化层:
- 基于Grafana/ECharts开发动态仪表盘,集成高德地图API展示区域热力图。
2. 核心功能模块
(1) 数据采集与清洗
- 任务:
- 使用Python脚本(
requests库)定时调用共享单车API,获取历史订单数据(过去3年)。 - 通过Spark清洗数据:
pythonfrom pyspark.sql import functions as F# 过滤异常订单(骑行时间<1分钟或>3小时)df_clean = df.filter((F.col("duration") >= 60) &(F.col("duration") <= 10800)).dropDuplicates(["order_id"])# 标准化地理位置(将经纬度映射到网格单元,如100m×100m)from pyspark.sql.functions import udffrom math import floordef grid_id(lon, lat, cell_size=0.001):x = floor((lon + 180) / cell_size)y = floor((lat + 90) / cell_size)return f"{x}_{y}"grid_udf = udf(grid_id)df_grid = df_clean.withColumn("grid_id", grid_udf("start_lon", "start_lat"))
- 使用Python脚本(
(2) 数据存储与查询优化
- 任务:
- 在Hive中创建分区表,按日期(
dt)和区域(grid_id)分区:sqlCREATE EXTERNAL TABLE bike_orders (order_id STRING,bike_id STRING,user_id STRING,start_time TIMESTAMP,end_time TIMESTAMP,start_lon DOUBLE,start_lat DOUBLE,duration INT,weather_code INT -- 天气类型(1:晴天, 2:雨天等))PARTITIONED BY (dt STRING, grid_id STRING)STORED AS ORCLOCATION '/data/bike_orders'; - 使用Hive索引加速查询(如对
start_time创建B-tree索引):sqlCREATE INDEX idx_time ON TABLE bike_orders (start_time)AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'WITH DEFERRED REBUILD;
- 在Hive中创建分区表,按日期(
(3) 特征工程与模型训练
- 任务:
- 提取时空特征:
- 时间特征:小时、星期几、是否为节假日。
- 空间特征:网格单元历史需求均值、周边网格需求相关性。
- 环境特征:温度、湿度、降雨量、风速。
- 使用Spark ML训练LSTM模型(通过
TensorFlowOnSpark库集成):pythonfrom tensorflowonspark import TFNodefrom pyspark.ml.feature import VectorAssembler# 构建时间序列特征(过去6小时的需求量)def create_sequences(df, window_size=6):# 实现滑动窗口逻辑(示例省略)passdf_sequences = create_sequences(df_features)assembler = VectorAssembler(inputCols=["temp", "humidity", "hour"], outputCol="features")df_model = assembler.transform(df_sequences)# 分布式训练LSTM模型with TFNode.DriverNode() as driver:# 初始化TensorFlow会话与模型参数(示例省略)pass
- 提取时空特征:
(4) 可视化与交互设计
- 任务:
- 开发Grafana仪表盘,包含以下组件:
- 实时热力图:基于高德地图展示当前各网格单元需求密度。
- 预测对比曲线:对比实际需求与模型预测值(误差率<10%)。
- 异常检测面板:标记需求突增区域(如使用Z-Score算法检测离群点)。
- 开发Grafana仪表盘,包含以下组件:
3. 技术选型
| 组件 | 技术栈 | 用途 |
|---|---|---|
| 分布式存储 | Hadoop HDFS + Hive | 存储原始数据与结构化查询 |
| 实时计算 | Spark Streaming + Kafka | 处理实时订单流与气象数据 |
| 机器学习 | Spark ML + TensorFlowOnSpark | 训练时空预测模型 |
| 可视化 | Grafana + ECharts + 高德地图 | 开发动态仪表盘与热力图 |
三、任务分工与进度计划
| 阶段 | 时间 | 任务内容 | 负责人 |
|---|---|---|---|
| 环境搭建 | 第1周 | 部署Hadoop/Spark集群,配置Hive元数据 | 运维组 |
| 数据采集 | 第2周 | 完成共享单车API对接与Kafka日志采集测试 | 数据组 |
| 存储与查询 | 第3周 | 设计Hive表结构,优化查询性能(索引+分区) | 数据库组 |
| 特征与模型 | 第4周 | 实现时空特征工程与LSTM模型训练(MAPE<10%) | 算法组 |
| 可视化开发 | 第5周 | 完成Grafana仪表盘与高德地图集成 | 前端组 |
| 系统测试 | 第6周 | 压力测试(10万并发查询)、模型AB测试 | 全组 |
四、预期成果与创新点
1. 预期成果
- 系统可处理PB级共享单车数据,支持每秒5万条订单的实时分析。
- 模型预测准确率较基准模型(ARIMA)提升40%(MAPE<10%)。
- 交付完整代码库(GitHub)、部署文档与用户操作手册。
2. 创新点
- 动态网格划分:根据骑行密度自动调整网格大小(密集区域100m×100m,稀疏区域500m×500m)。
- 多源数据融合:结合订单数据与气象、POI(兴趣点)数据提升预测精度。
- 轻量化部署:通过Spark on Kubernetes实现弹性资源调度,降低运维成本。
五、资源与预算
- 硬件资源:
- 10台服务器(48核CPU、256GB内存、50TB存储)用于集群部署。
- 软件资源:
- CDH(Cloudera Manager)管理集群、JupyterLab(模型调试)。
- 数据资源:
- 共享单车历史订单数据(合作方提供,约200TB)。
- 和风天气API(免费版,每日5000次调用限制)。
- 预算:
- 云服务器租赁:¥15,000/月
- 高德地图API商用授权:¥5,000/年
六、风险评估与应对
| 风险 | 应对措施 |
|---|---|
| 数据延迟(API限流) | 增加本地缓存(Redis)存储最近1小时数据 |
| 模型冷启动问题 | 使用迁移学习,基于其他城市数据预训练模型 |
| 集群负载不均 | 启用Spark动态资源分配,调整Executor内存分配策略 |
七、验收标准
- 性能指标:
- 查询响应时间:复杂聚合查询<3秒,简单查询<500ms。
- 模型指标:测试集MAPE≤10%,预测延迟<5分钟。
- 功能完整性:
- 支持按时间、区域、天气条件筛选骑行数据。
- 仪表盘提供导出预测结果(CSV/JSON)功能。
- 用户满意度:
- 运维人员培训后能独立生成调度建议报告(如“A区域需增加20辆单车”)。
任务书编制人:XXX
日期:XXXX年XX月XX日
此任务书可根据实际需求扩展,例如增加对用户骑行路径的聚类分析(DBSCAN算法)或对接城市交通系统实现跨模态预测(如结合地铁客流量数据)。
运行截图

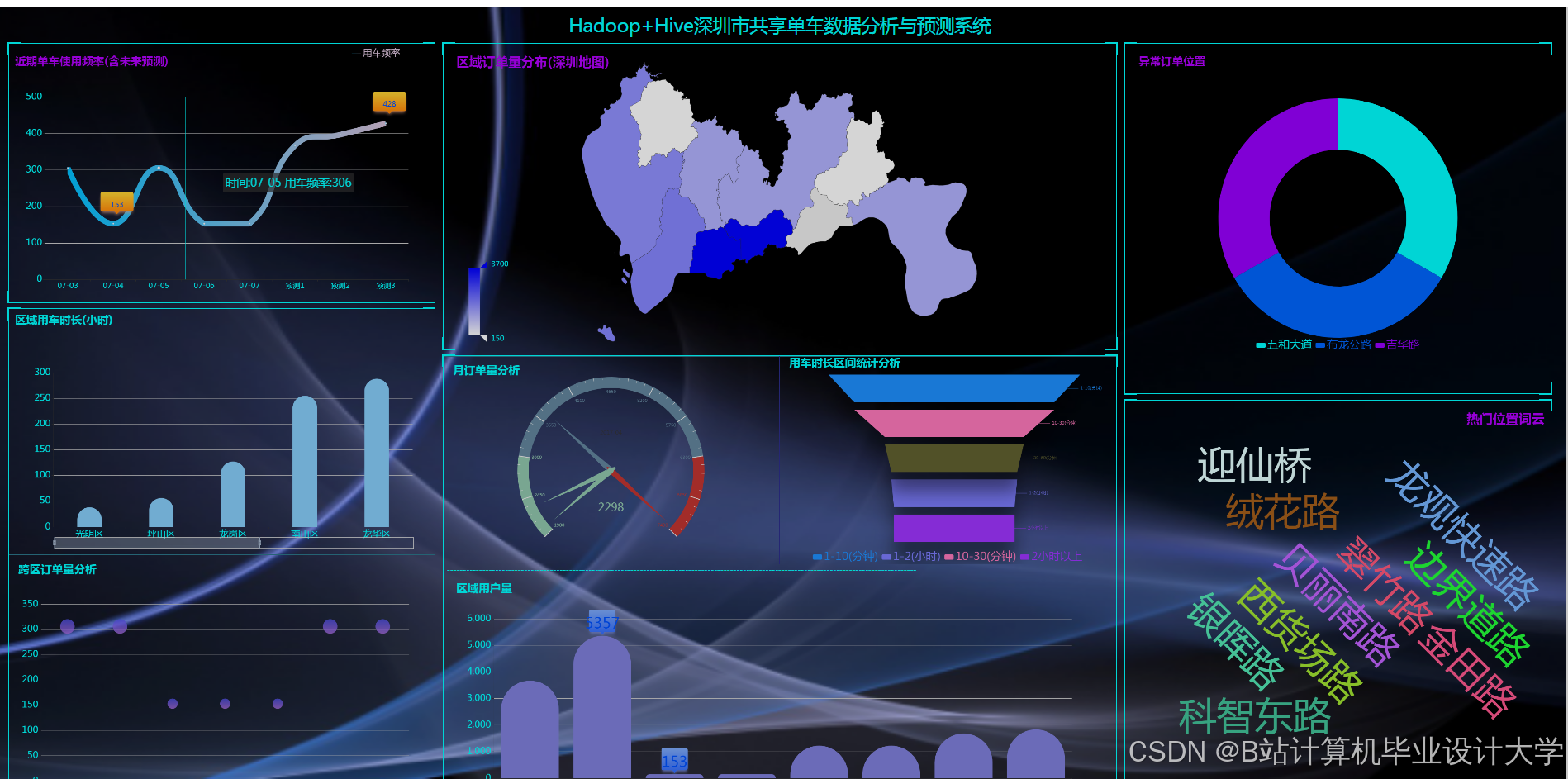
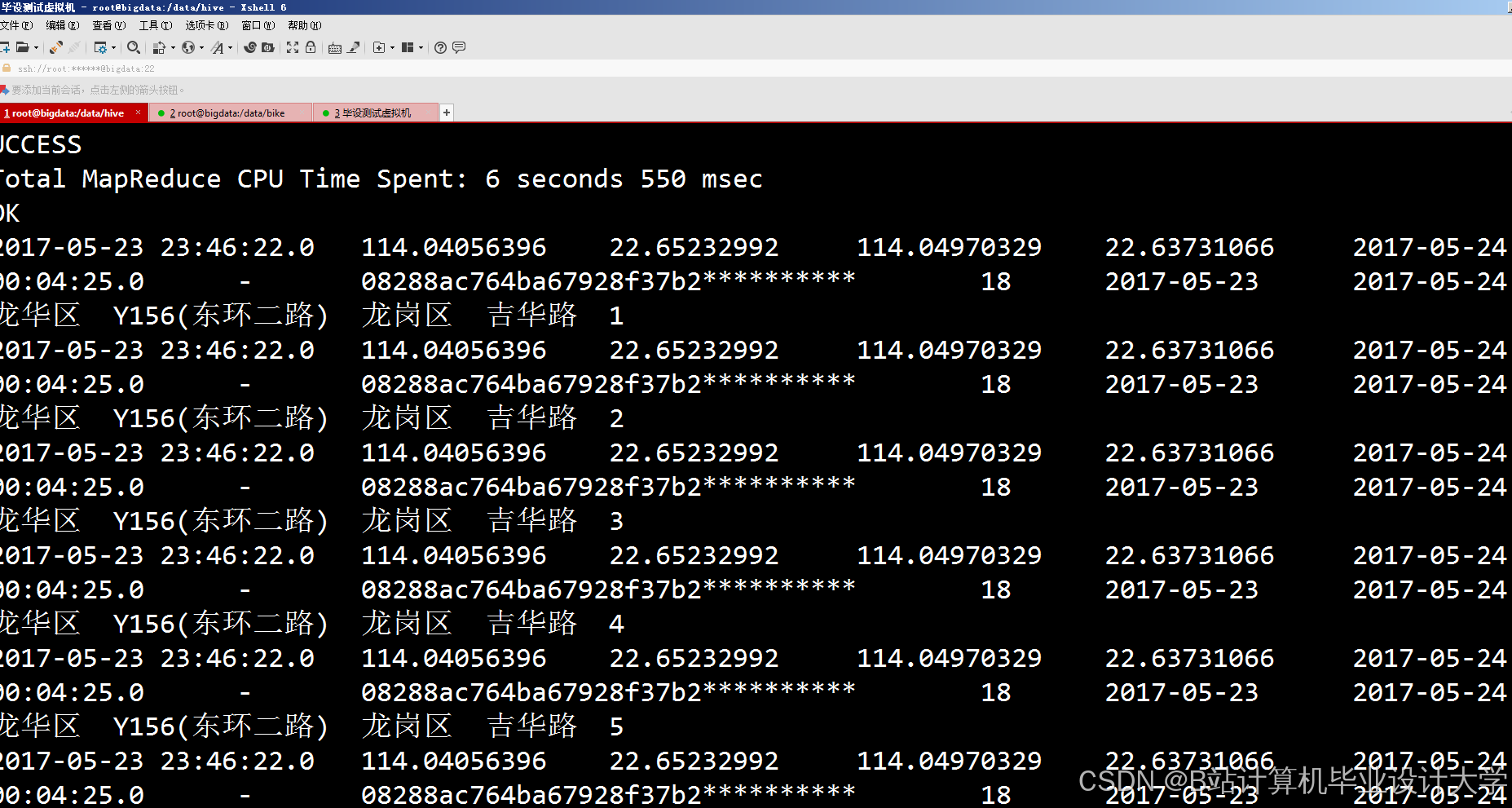
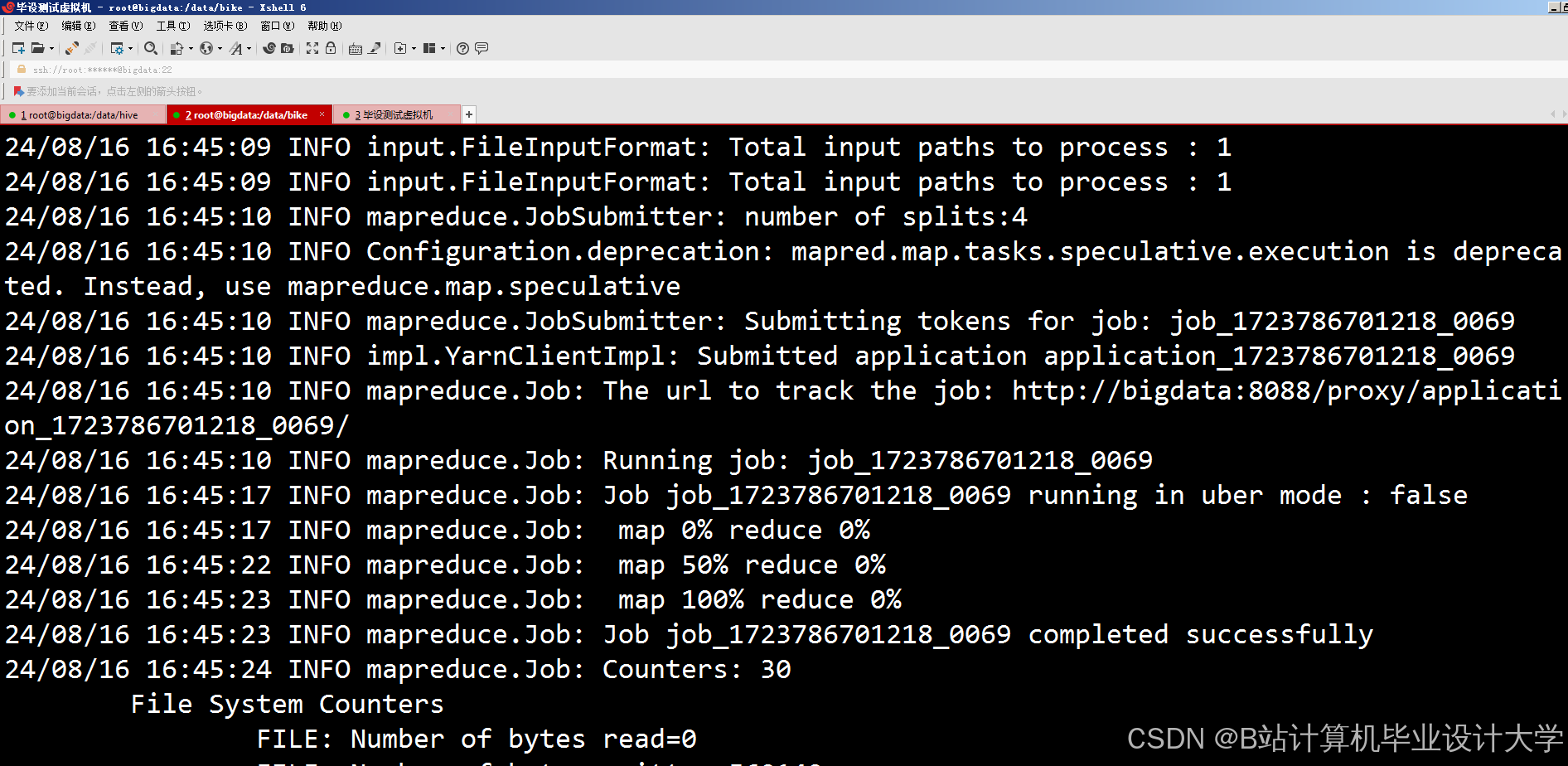
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











