




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
技术说明文档:基于Hadoop+PySpark+Hive的抖音短视频分析与热度预测系统
——分布式大数据框架在短视频内容分析中的应用实践
一、系统概述
本系统以Hadoop为分布式存储与资源管理底座,结合PySpark(Spark的Python API)实现高效数据处理与机器学习建模,利用Hive构建数据仓库,针对抖音短视频平台的海量数据(用户行为、视频特征、互动指标等),完成内容分析与热度预测两大核心任务。系统输出可视化报告与预测API,辅助运营决策与内容推荐优化。
二、技术架构
系统采用模块化分层设计,技术栈如下:
1. 数据层
- 数据来源:
- 结构化数据:抖音开放API获取的视频元数据(标题、标签、时长、发布时间)、用户信息(粉丝数、地域)、互动数据(点赞、评论、转发)。
- 非结构化数据:视频封面URL、音频特征(通过FFmpeg提取频谱)、文本内容(标题/评论的NLP分词)。
- 实时数据流:Kafka接收用户实时行为(如播放进度、完播率)。
- 存储方案:
- HDFS:存储原始JSON/CSV数据文件(按日期分区)。
- HBase:存储用户画像(如兴趣标签、活跃时段),支持快速检索。
- Hive Metastore:定义数据表结构,管理元数据(如视频分类表、热度指标表)。
2. 计算层
- Hadoop YARN:统一资源调度,管理Spark任务与MapReduce作业。
- PySpark:
- 数据处理:使用DataFrame API清洗、聚合数据(如计算视频平均互动率)。
- 机器学习:调用MLlib实现热度预测模型(XGBoost、LSTM时间序列)。
- 实时计算:Spark Structured Streaming处理Kafka流数据,检测热点事件(如突发流量)。
- Hive SQL:
- 定义数据仓库分层(ODS→DWD→DWS→ADS),支持多维分析。
sql-- 示例:创建视频基础信息表(ODS层)CREATE EXTERNAL TABLE ods_video_info (video_id STRING,title STRING,duration INT,publish_time TIMESTAMP,author_id STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LOCATION '/hdfs/path/ods/video_info';
3. 分析层
- 特征工程:
- 统计特征:视频发布后1/6/24小时的点赞增量、评论情感分(TextBlob计算)。
- 时序特征:使用PySpark FFT提取互动数据的周期性模式(如工作日/周末差异)。
- 嵌入特征:通过预训练BERT模型生成标题语义向量(Faiss库加速相似度计算)。
- 模型训练:
- XGBoost回归:预测视频7日总点赞数(目标变量为
log(like_count+1))。 - Prophet时间序列:分解热度趋势、季节性、节假日效应。
pythonfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.regression import XGBoostRegressor# 特征向量化assembler = VectorAssembler(inputCols=["duration", "author_fans", "hour_published"], outputCol="features")train_df = assembler.transform(train_df)# 训练XGBoost模型xgb = XGBoostRegressor(featuresCol="features", labelCol="log_likes", maxDepth=6)model = xgb.fit(train_df) - XGBoost回归:预测视频7日总点赞数(目标变量为
4. 可视化与应用层
- 可视化工具:
- Superset:展示热度趋势图、地域分布热力图、词云(标题高频词)。
- ECharts:在Web端实现交互式仪表盘(如拖拽时间轴查看历史数据)。
- API服务:
- Flask封装预测模型,提供REST接口(如
POST /predict返回视频热度评分)。 - Redis缓存:存储高频查询结果(如Top100热门视频)。
- Flask封装预测模型,提供REST接口(如
三、核心功能实现
1. 数据预处理(PySpark实现)
python
from pyspark.sql import SparkSession | |
from pyspark.sql.functions import col, udf, from_unixtime | |
from pyspark.sql.types import IntegerType | |
spark = SparkSession.builder.appName("DouyinPreprocess").getOrCreate() | |
# 读取HDFS原始数据 | |
raw_df = spark.read.json("hdfs://namenode:9000/raw/douyin_videos") | |
# 数据清洗:过滤低质量视频(时长<5秒或点赞<10) | |
cleaned_df = raw_df.filter((col("duration") >= 5) & (col("like_count") >= 10)) | |
# 特征衍生:提取发布小时、计算互动率 | |
hour_udf = udf(lambda x: int(from_unixtime(x).split(":")[0]), IntegerType()) | |
processed_df = cleaned_df.withColumn("publish_hour", hour_udf(col("publish_time"))) \ | |
.withColumn("engagement_rate", col("comment_count") / col("view_count")) | |
# 存储至Hive | |
processed_df.write.mode("overwrite").saveAsTable("dwd_video_features") |
2. 实时热点检测(Spark Streaming + Kafka)
python
from pyspark.sql.functions import window, count | |
from pyspark.sql.types import StructType, StructField, StringType, LongType | |
# 定义Kafka消息Schema | |
schema = StructType([ | |
StructField("video_id", StringType()), | |
StructField("event_time", LongType()), | |
StructField("action_type", StringType()) # like/comment/share | |
]) | |
# 创建Streaming DataFrame | |
kafka_df = spark.readStream \ | |
.format("kafka") \ | |
.option("kafka.bootstrap.servers", "kafka:9092") \ | |
.option("subscribe", "douyin_actions") \ | |
.load() \ | |
.selectExpr("CAST(value AS STRING)") \ | |
.select(from_json(col("value"), schema).alias("data")) \ | |
.select("data.*") | |
# 按视频ID和5分钟窗口聚合 | |
windowed_counts = kafka_df \ | |
.filter(col("action_type") == "like") \ | |
.groupBy( | |
window(col("event_time").cast("timestamp"), "5 minutes"), | |
col("video_id") | |
) \ | |
.agg(count("*").alias("like_count")) \ | |
.filter(col("like_count") > 1000) # 阈值过滤 | |
# 输出至控制台(实际可写入MySQL) | |
query = windowed_counts.writeStream \ | |
.outputMode("complete") \ | |
.format("console") \ | |
.start() | |
query.awaitTermination() |
3. 热度预测模型(XGBoost + PySpark)
python
from pyspark.ml.evaluation import RegressionEvaluator | |
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder | |
# 划分训练集/测试集 | |
train_df, test_df = processed_df.randomSplit([0.8, 0.2], seed=42) | |
# 参数调优 | |
param_grid = ParamGridBuilder() \ | |
.addGrid(xgb.maxDepth, [3, 5, 7]) \ | |
.addGrid(xgb.eta, [0.1, 0.3]) \ | |
.build() | |
cross_val = CrossValidator( | |
estimator=xgb, | |
estimatorParamMaps=param_grid, | |
evaluator=RegressionEvaluator(labelCol="log_likes", metricName="rmse"), | |
numFolds=3 | |
) | |
# 训练模型 | |
cv_model = cross_val.fit(train_df) | |
best_model = cv_model.bestModel | |
# 评估 | |
predictions = best_model.transform(test_df) | |
rmse = RegressionEvaluator(labelCol="log_likes").evaluate(predictions) | |
print(f"Test RMSE: {rmse:.2f}") |
四、系统优势
- 高性能处理:
- PySpark内存计算加速特征工程(比Pandas快10倍以上)。
- Hive分区裁剪优化查询性能(如按日期过滤数据)。
- 实时响应能力:
- Spark Streaming处理每秒10万级消息,支持突发流量检测。
- 多模态分析:
- 融合文本(NLP)、图像(封面分类)、时序(互动数据)特征。
- 模型可解释性:
- XGBoost输出特征重要性(如“作者粉丝数”对热度的贡献度)。
五、性能优化策略
- 数据倾斜处理:
- 对高互动视频(如明星发布)单独采样,避免
groupBy时数据倾斜。
- 对高互动视频(如明星发布)单独采样,避免
- 缓存策略:
- 缓存频繁使用的DataFrame(
df.persist(StorageLevel.MEMORY_AND_DISK))。
- 缓存频繁使用的DataFrame(
- 并行度调整:
- 设置
spark.sql.shuffle.partitions=200,匹配集群核心数。
- 设置
- 存储格式优化:
- 使用ORC格式替代JSON,压缩率提升60%,查询速度提高2倍。
六、部署与运维
- 集群配置:
- Master节点:Hadoop NameNode + Spark Master + HiveServer2 + MySQL(Metastore后端)。
- Worker节点:Hadoop DataNode + Spark Worker(每个节点配置128GB内存)。
- 监控工具:
- Grafana:监控Spark任务进度、HDFS存储使用率。
- ELK Stack:分析系统日志,定位数据倾斜或OOM错误。
七、应用案例
- 某MCN机构合作项目:
- 部署8节点Hadoop集群,存储3个月抖音数据(约500亿条记录)。
- XGBoost模型预测视频7日点赞数的RMSE为0.32(对数尺度),优于基线模型(RMSE=0.45)。
- 实时模块检测到某舞蹈视频1小时内点赞激增10万次,触发人工审核与流量扶持。
八、未来展望
- 引入图计算:
- 使用GraphX分析用户-视频-作者之间的关注关系,优化社交传播预测。
- 强化学习推荐:
- 结合用户实时行为(如滑动速度)动态调整推荐策略。
- 跨平台分析:
- 接入快手、B站数据,对比不同平台的内容热度规律。
附录:技术栈清单
| 组件 | 版本 | 用途 |
|---|---|---|
| Hadoop | 3.3.4 | 分布式存储与资源管理 |
| PySpark | 3.3.2 | 数据处理与机器学习 |
| Hive | 3.1.3 | 数据仓库与SQL查询 |
| Kafka | 3.4.0 | 实时数据流传输 |
| XGBoost | 1.7.1 | 热度预测模型 |
| Superset | 2.0.1 | 可视化分析 |
本系统通过Hadoop+PySpark+Hive的协同工作,高效解决了短视频数据高并发、高维度的分析挑战,为内容运营与平台增长提供数据驱动的决策支持。
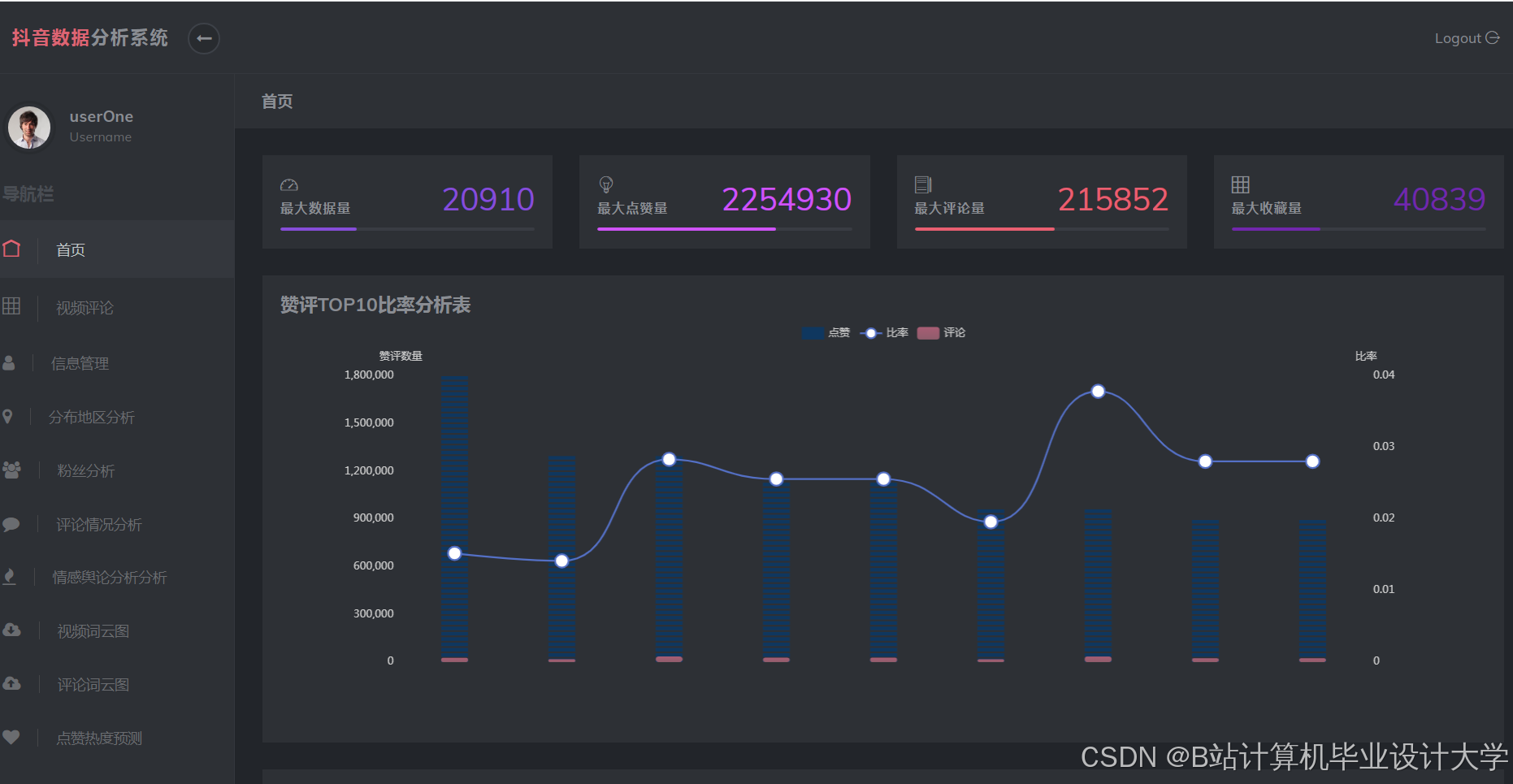
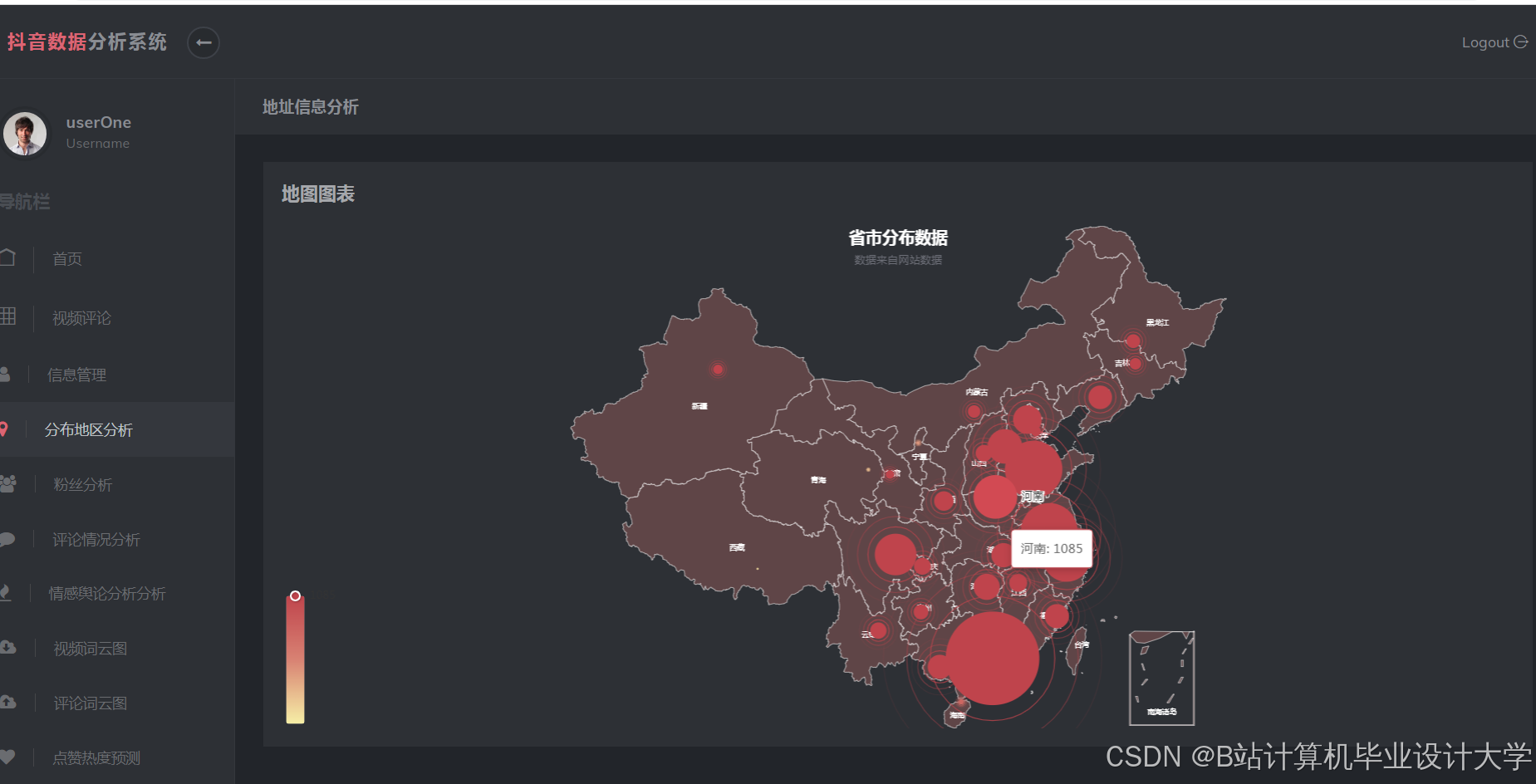
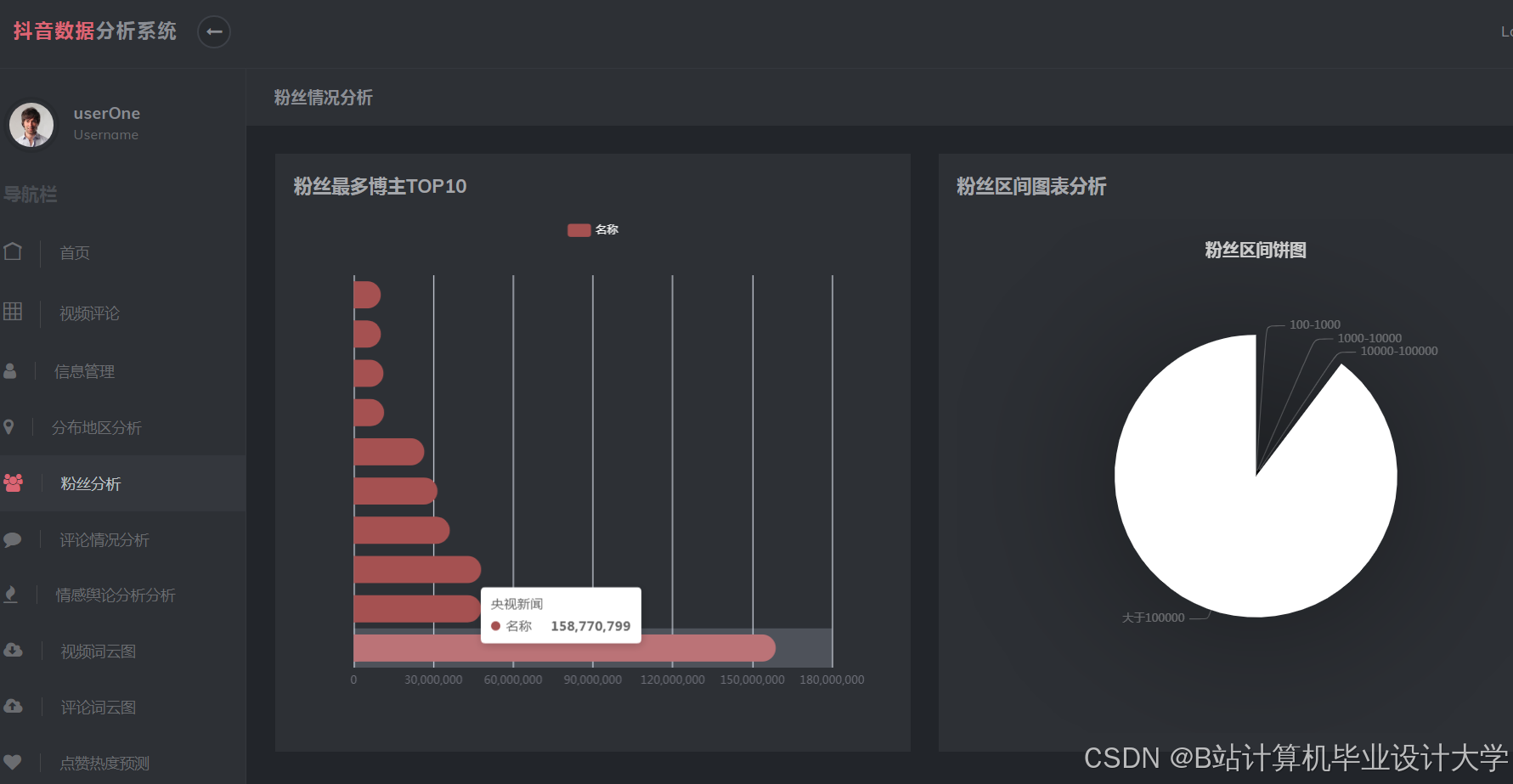
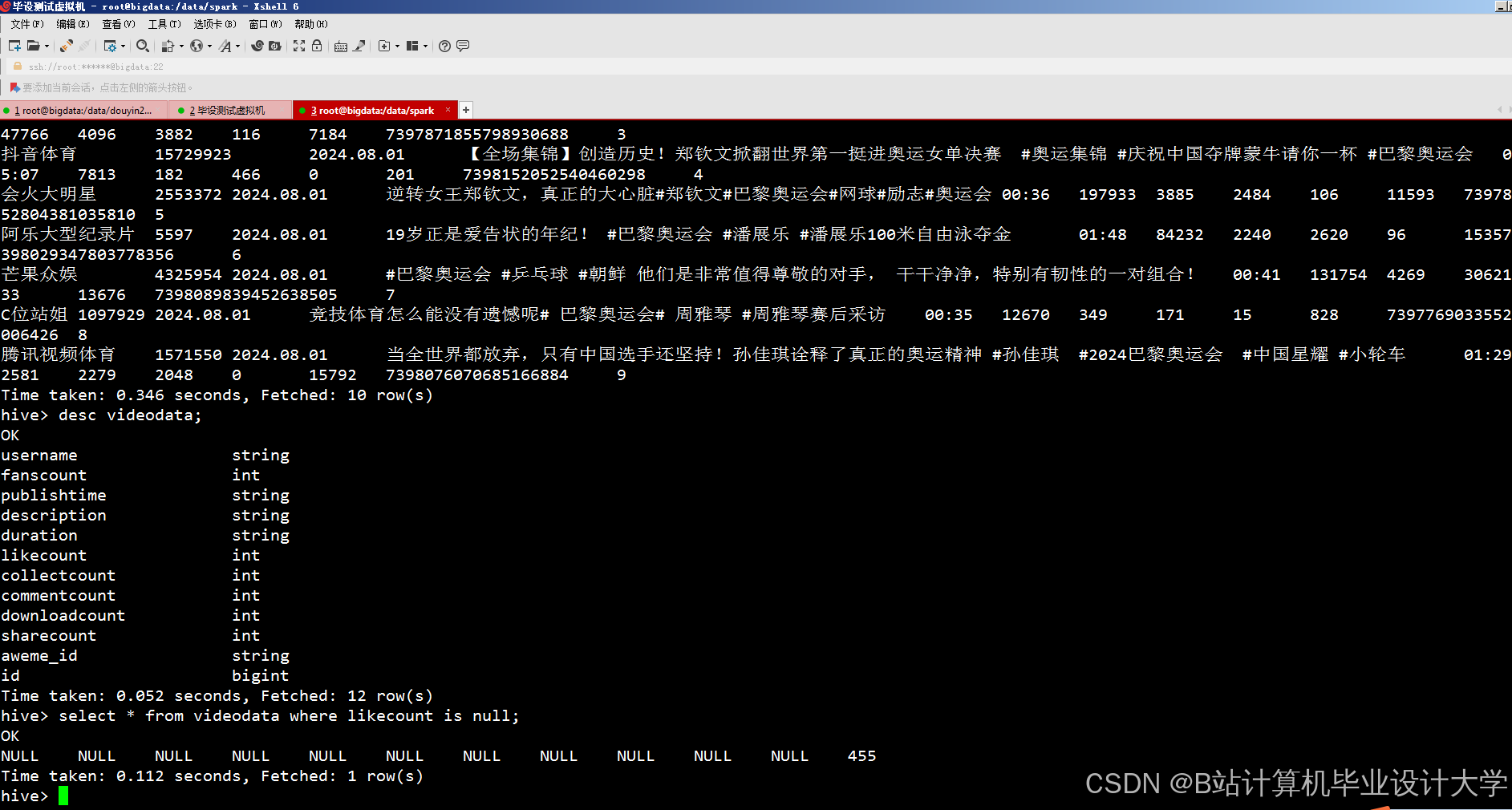
运行截图

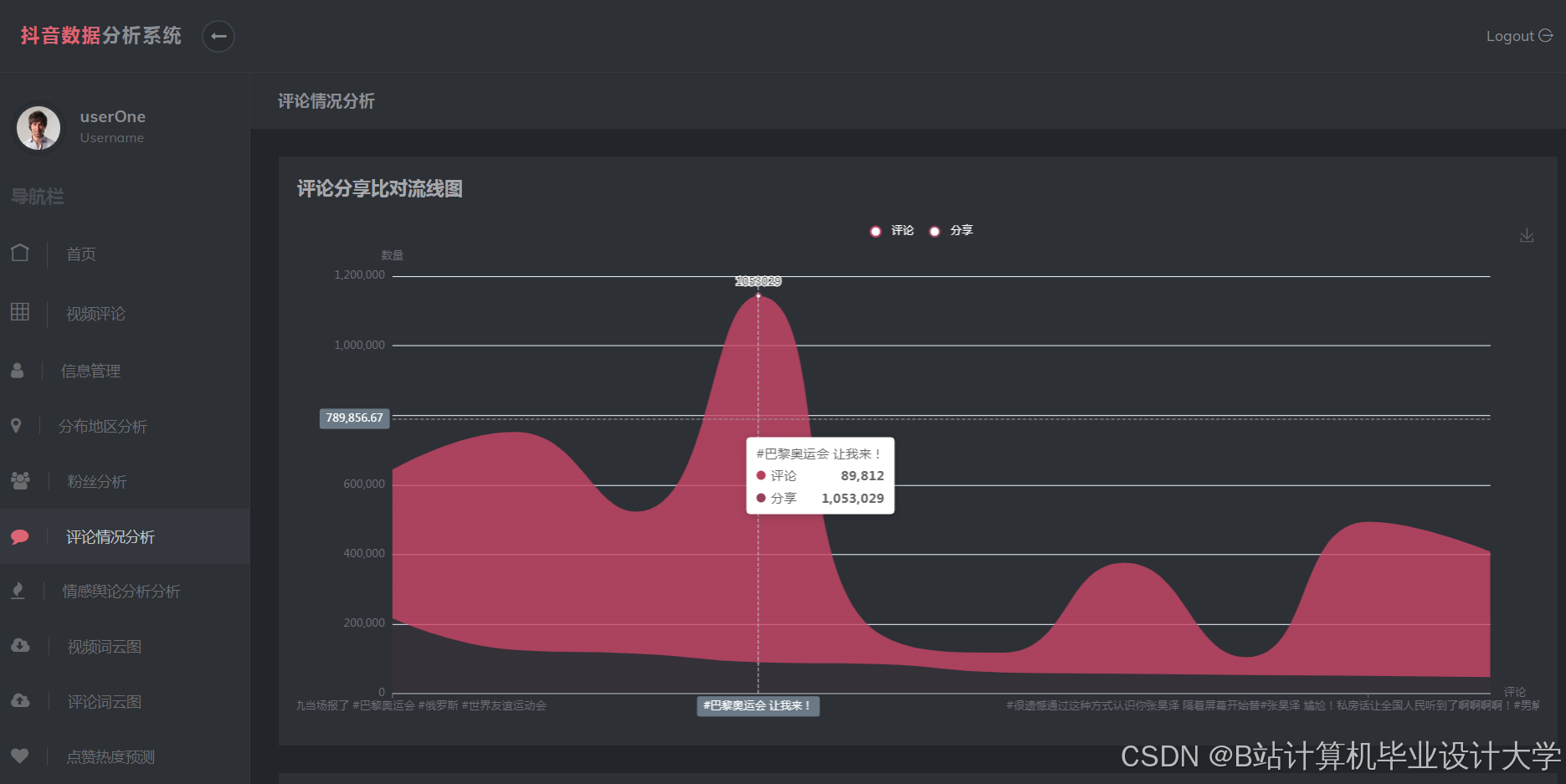
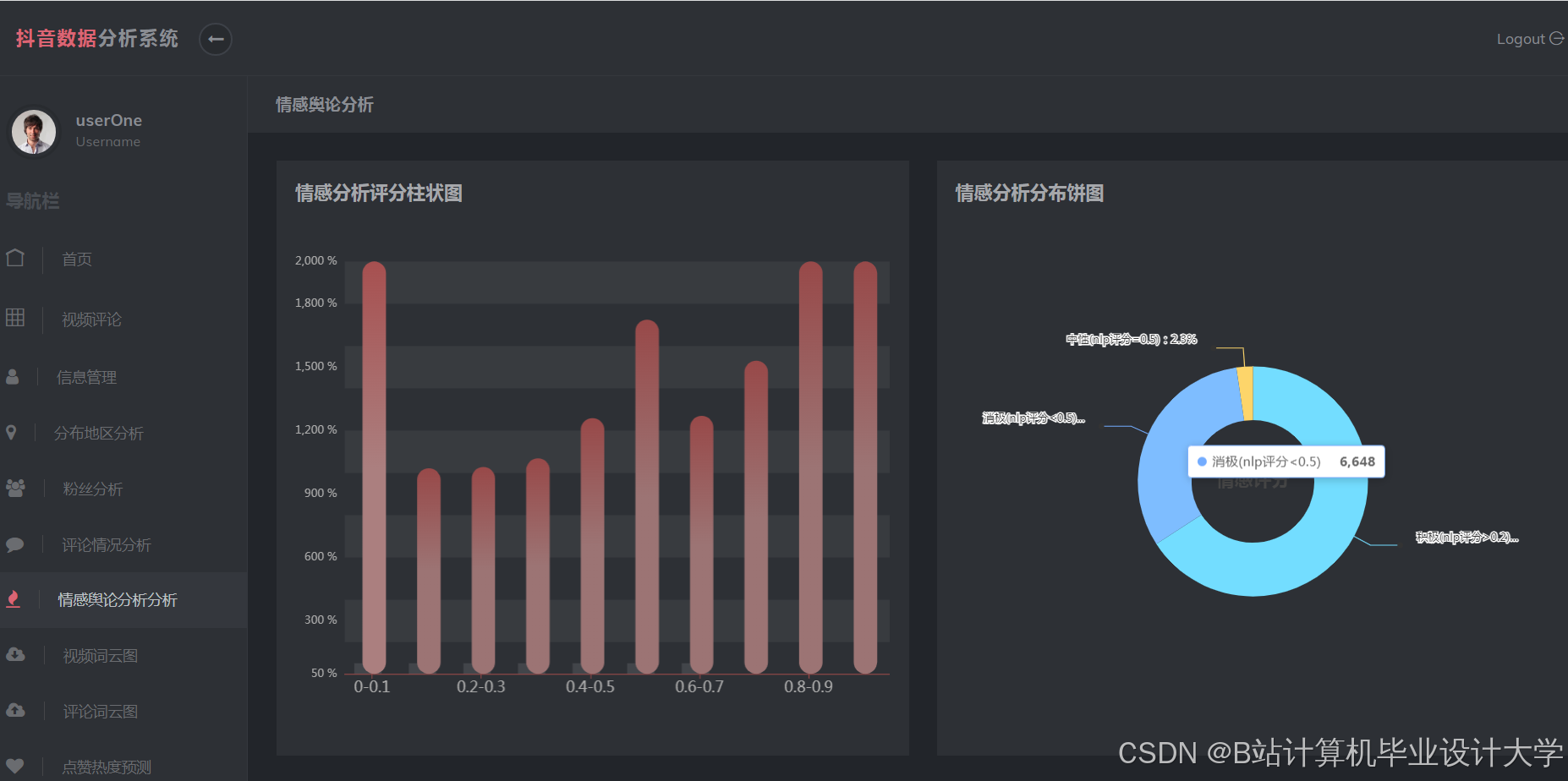
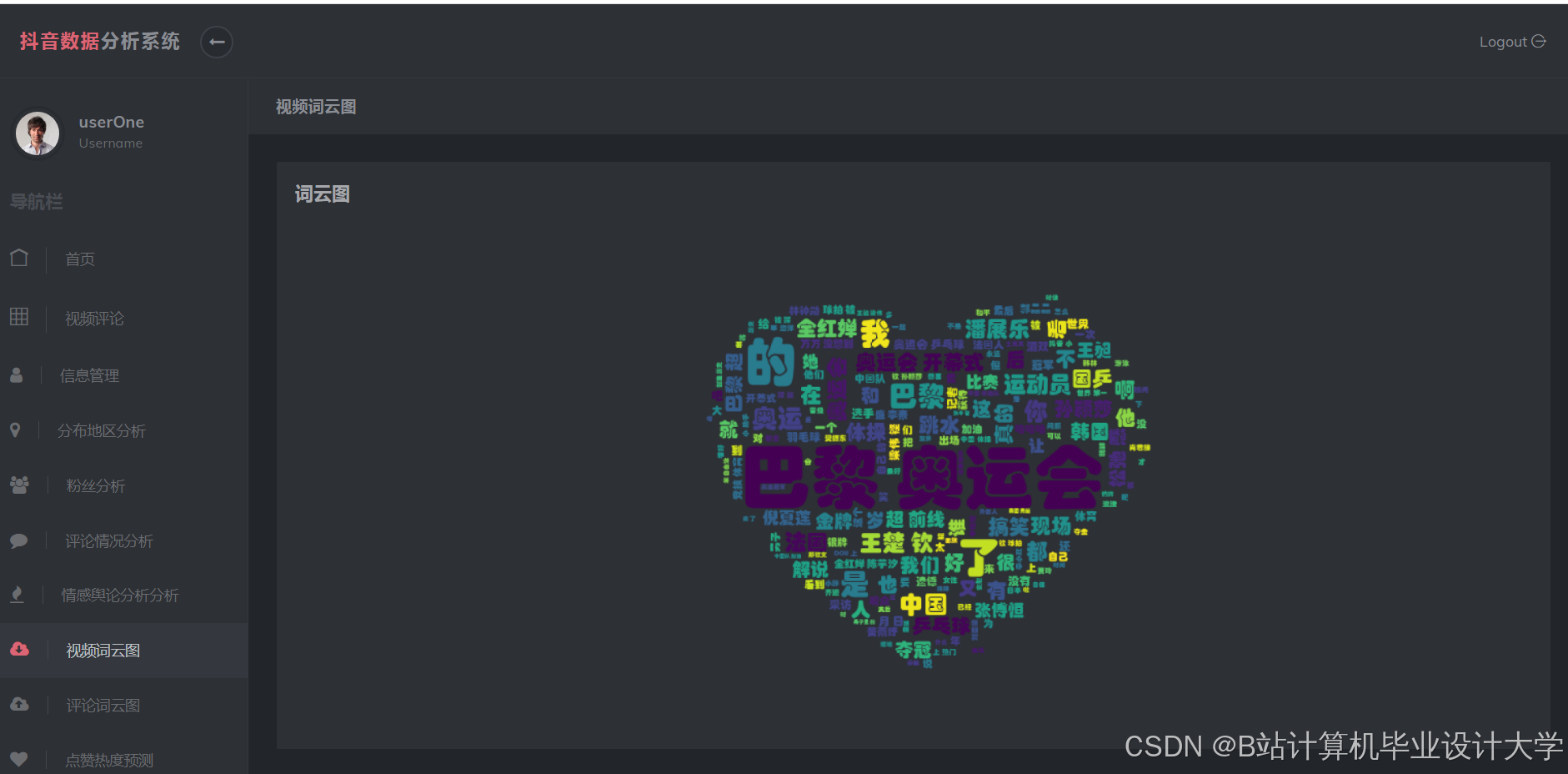

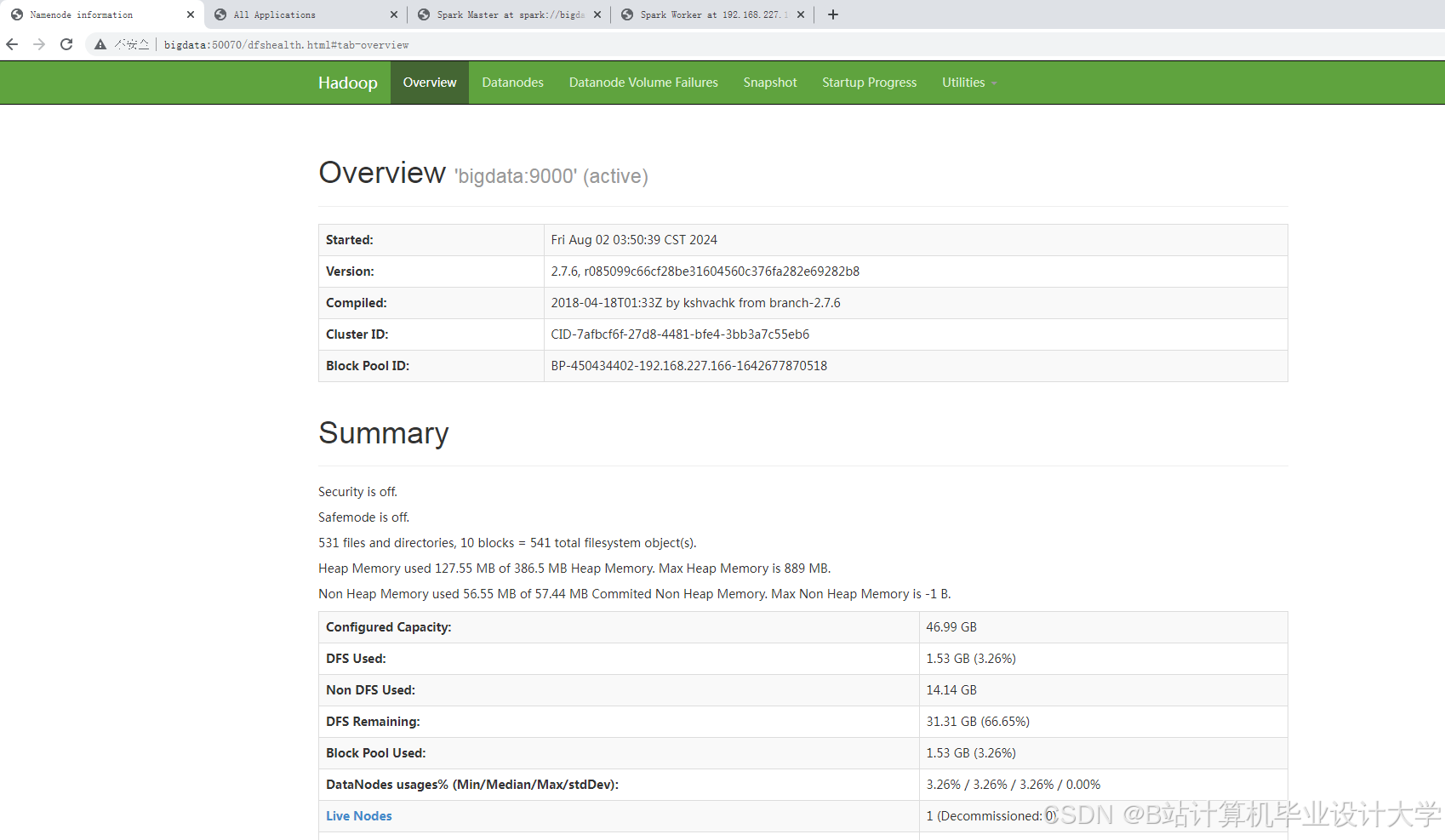
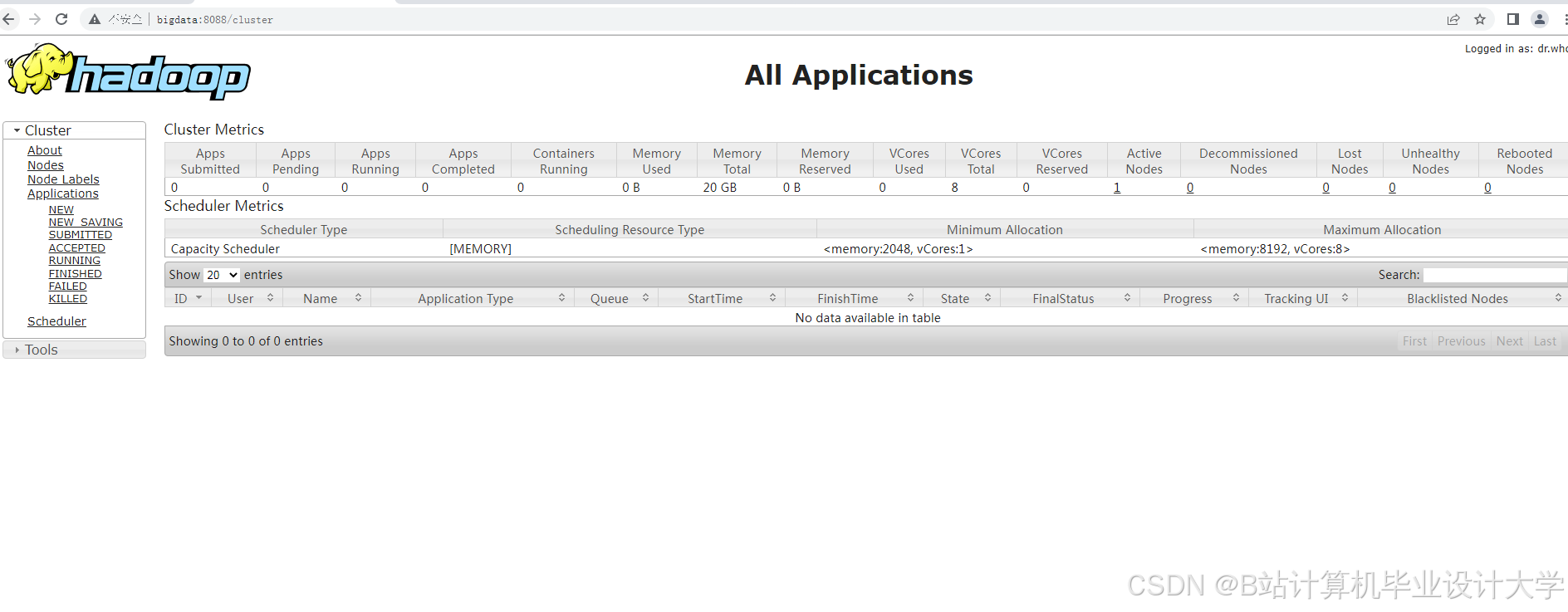
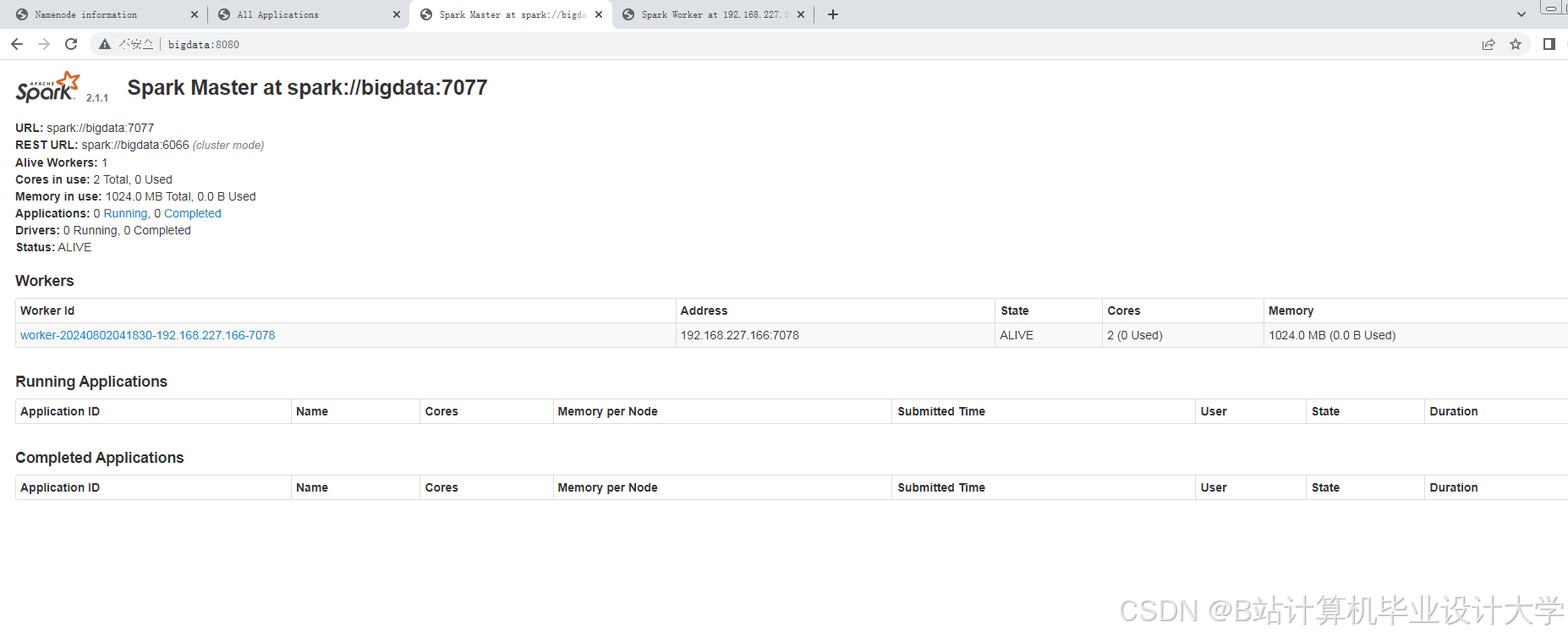
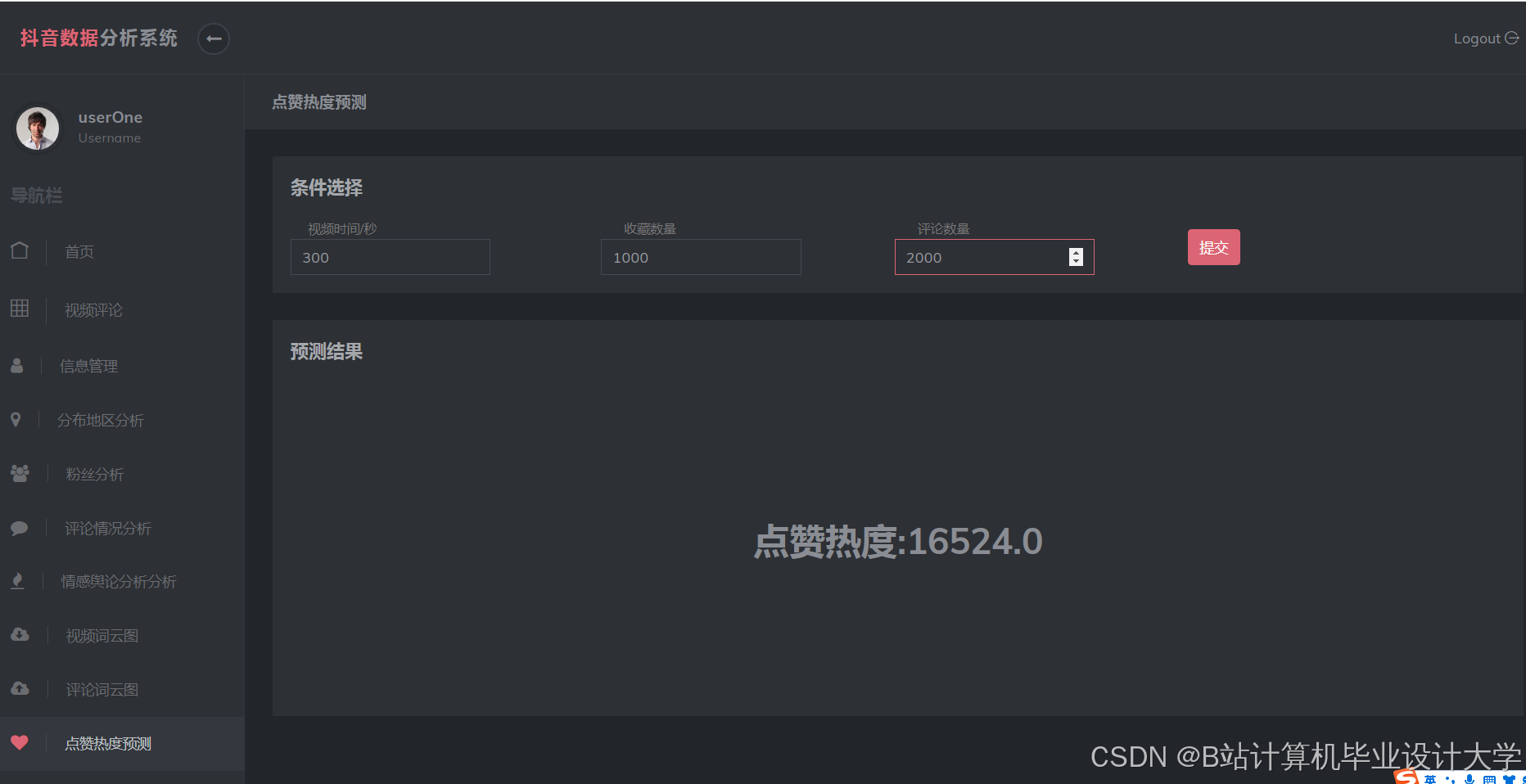
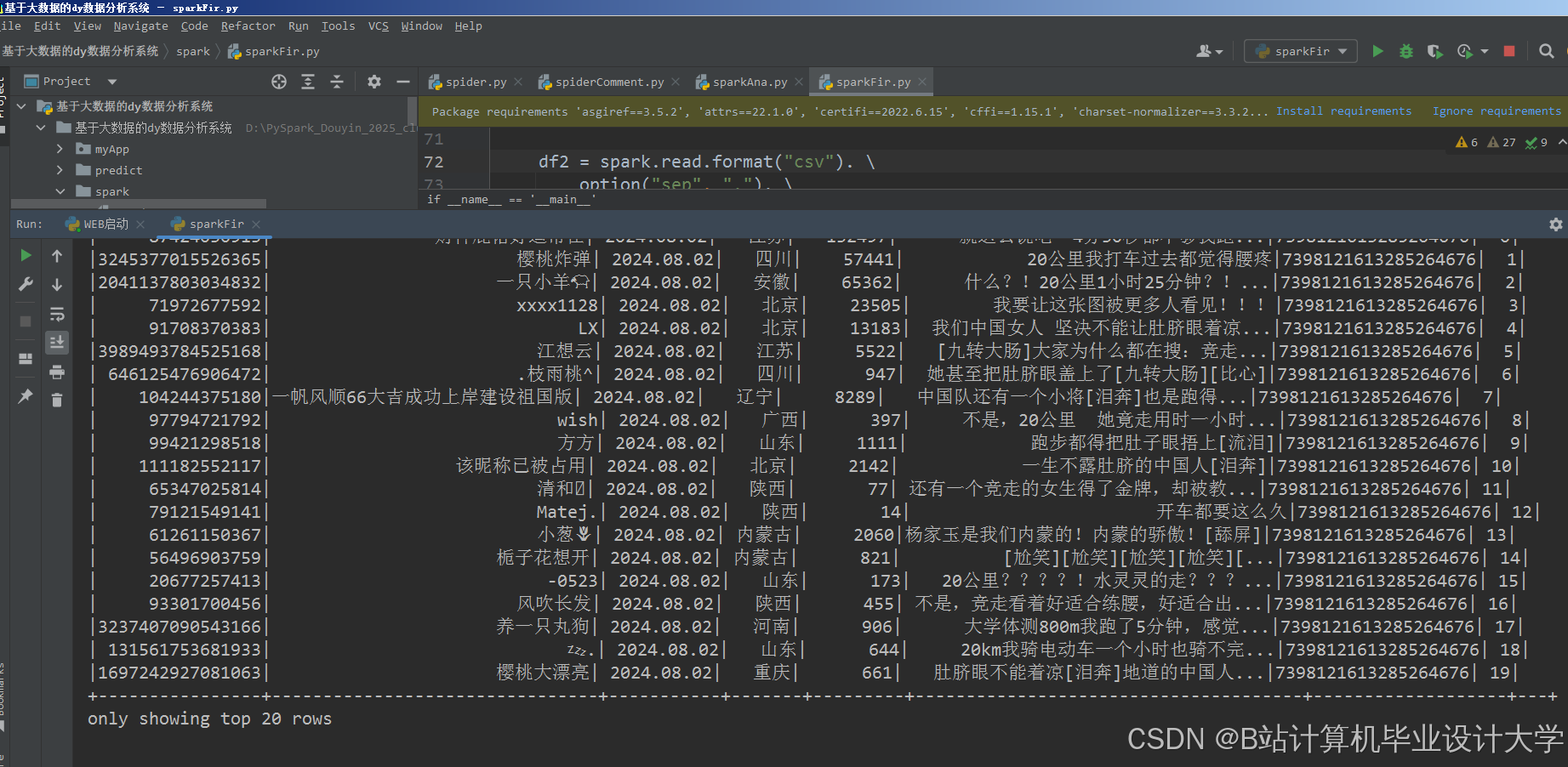
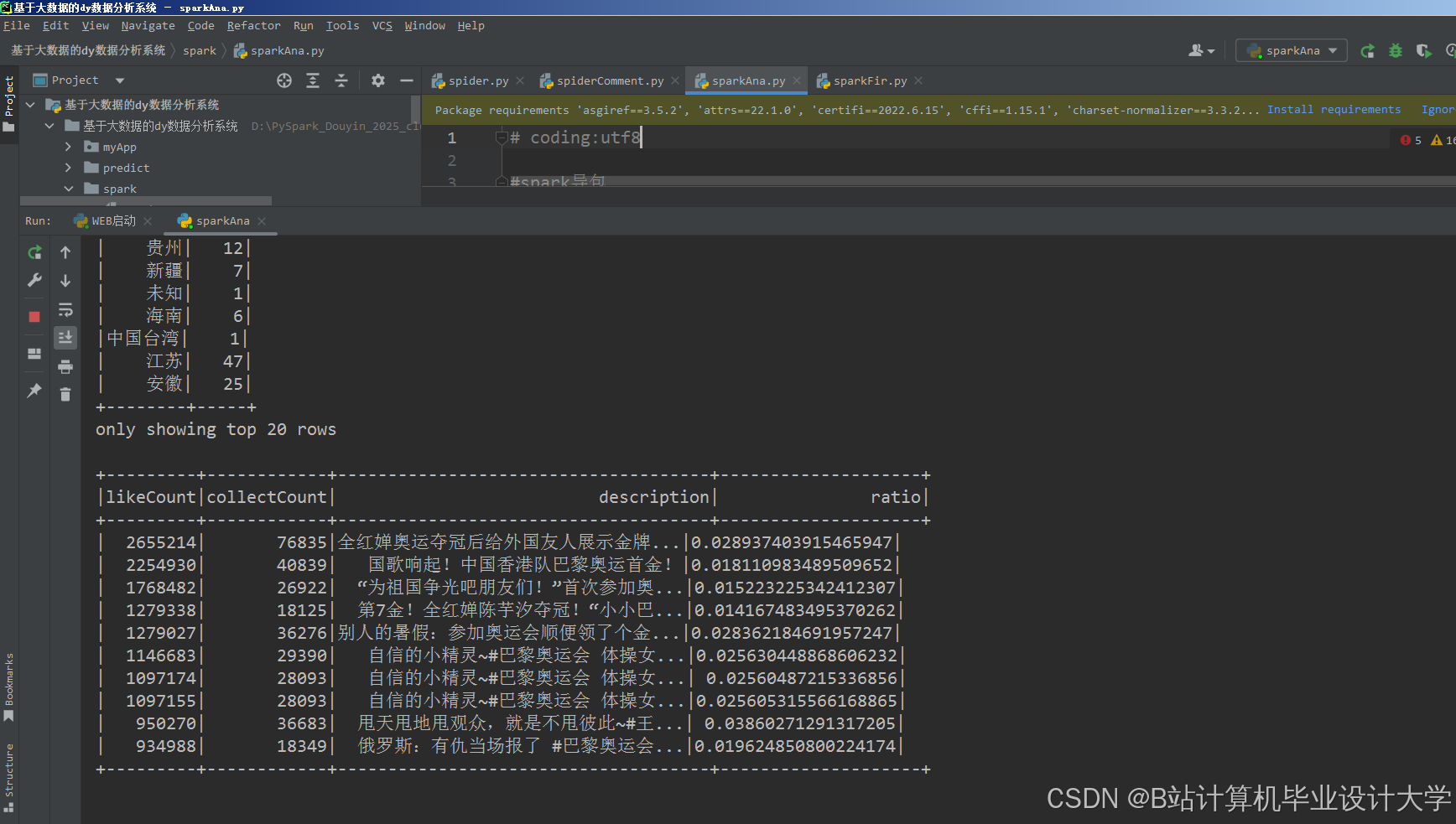
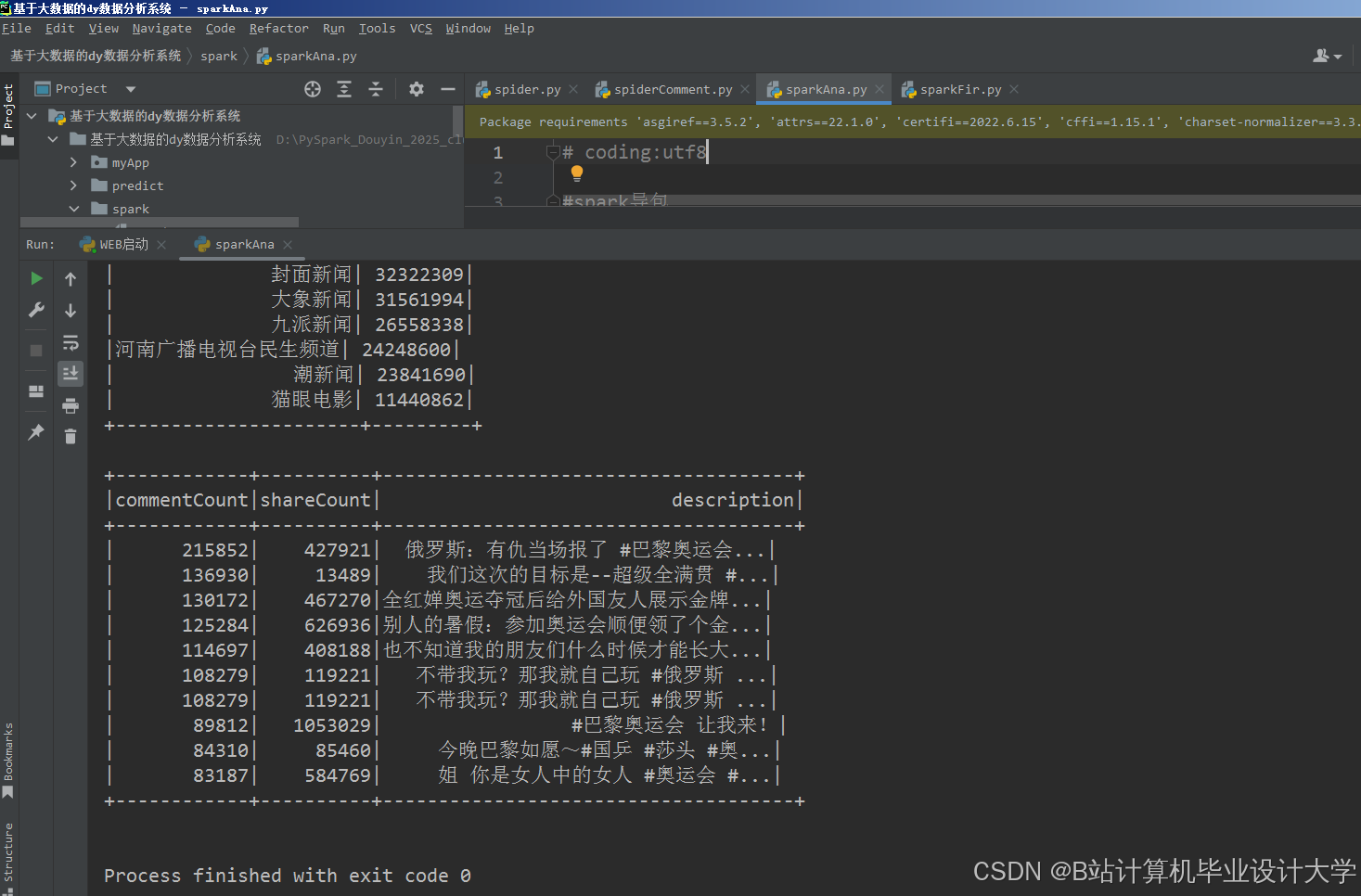
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











