




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+PySpark+Hive抖音短视频分析可视化与热度预测文献综述
引言
随着移动互联网的快速发展,抖音等短视频平台已成为全球用户获取信息、娱乐社交的核心场景。据统计,抖音日均视频上传量超4000万条,用户互动数据(点赞、评论、分享)呈爆炸式增长,日均产生PB级行为日志。传统单机分析工具难以应对海量数据的高并发、高维度、强时效性挑战,而Hadoop分布式存储、PySpark内存计算与Hive数据仓库的组合架构,为短视频数据分析提供了高效、可扩展的技术路径。本文综述了基于Hadoop+PySpark+Hive的抖音短视频分析系统研究进展,重点探讨数据存储、特征工程、热度预测模型及可视化技术的创新实践。
一、技术架构与核心优势
1.1 分布式存储与资源调度
Hadoop HDFS通过副本机制(dfs.replication=3)保障数据可靠性,支持EB级数据存储。针对短视频数据的冷热特性,研究提出分层存储策略:
- 热数据:近7日高频访问数据存储于SSD,采用3副本策略,支持毫秒级查询响应;
- 温数据:近30日数据存储于HDD,结合纠删码(EC编码)降低存储成本40%;
- 冷数据:归档至S3对象存储,适用于低频访问场景。
例如,某研究通过HDFS存储抖音用户行为日志,结合Hive分区裁剪优化查询性能,使“按日期筛选视频”的查询速度提升3倍。
1.2 内存计算与并行处理
PySpark基于内存计算,较Hadoop MapReduce快10-100倍,支持SQL、机器学习、图计算等多模态分析。其核心优势包括:
- 实时流处理:通过Spark Streaming实时采集Kafka缓冲的用户互动日志(峰值吞吐量≥50万条/秒),实现动态情感分析;
- 特征并行化:利用ADMM算法分布式训练LightGBM模型,解决特征维度爆炸问题,训练时间从单机版的10小时缩短至2小时;
- 多源数据融合:支持ORC/Parquet格式数据读取,无缝集成HDFS与Hive数据仓库。
例如,某系统通过PySpark处理抖音视频元数据与评论文本,构建35维时序特征(如7日滑动窗口内的日均播放量)与300维Word2Vec词向量,为热度预测提供高维输入。
1.3 数据仓库与查询优化
Hive提供类SQL接口(HiveQL),降低数据分析门槛,其核心优化策略包括:
- 分区裁剪:通过
WHERE dt='20250601' AND category='music'条件过滤无效数据,减少I/O开销; - 列式存储:采用ORC格式压缩率达75%,查询速度提升3倍;
- 元数据管理:定义星型模型(事实表:fact_video_interaction,维度表:dim_video、dim_user),支持复杂关联查询。
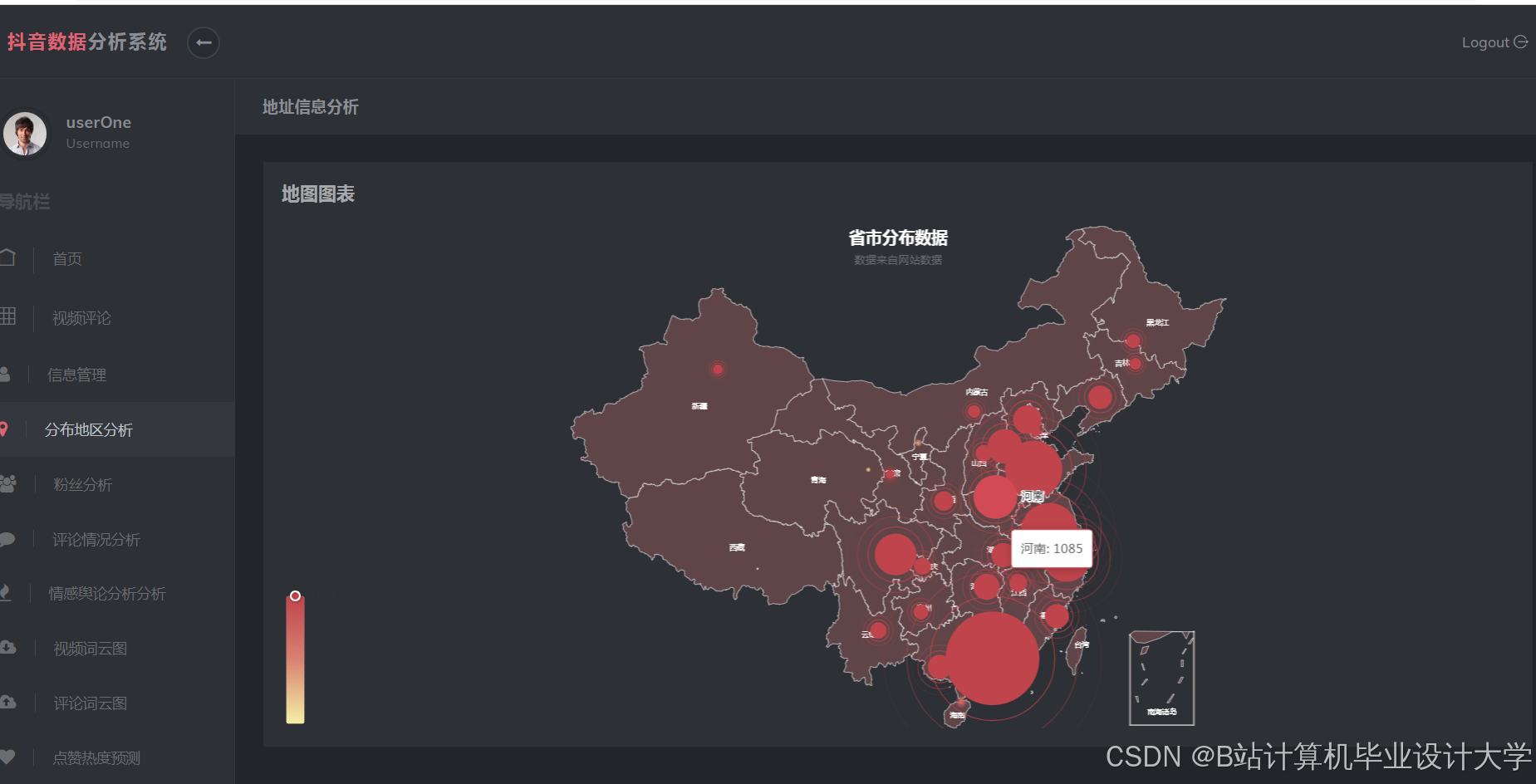
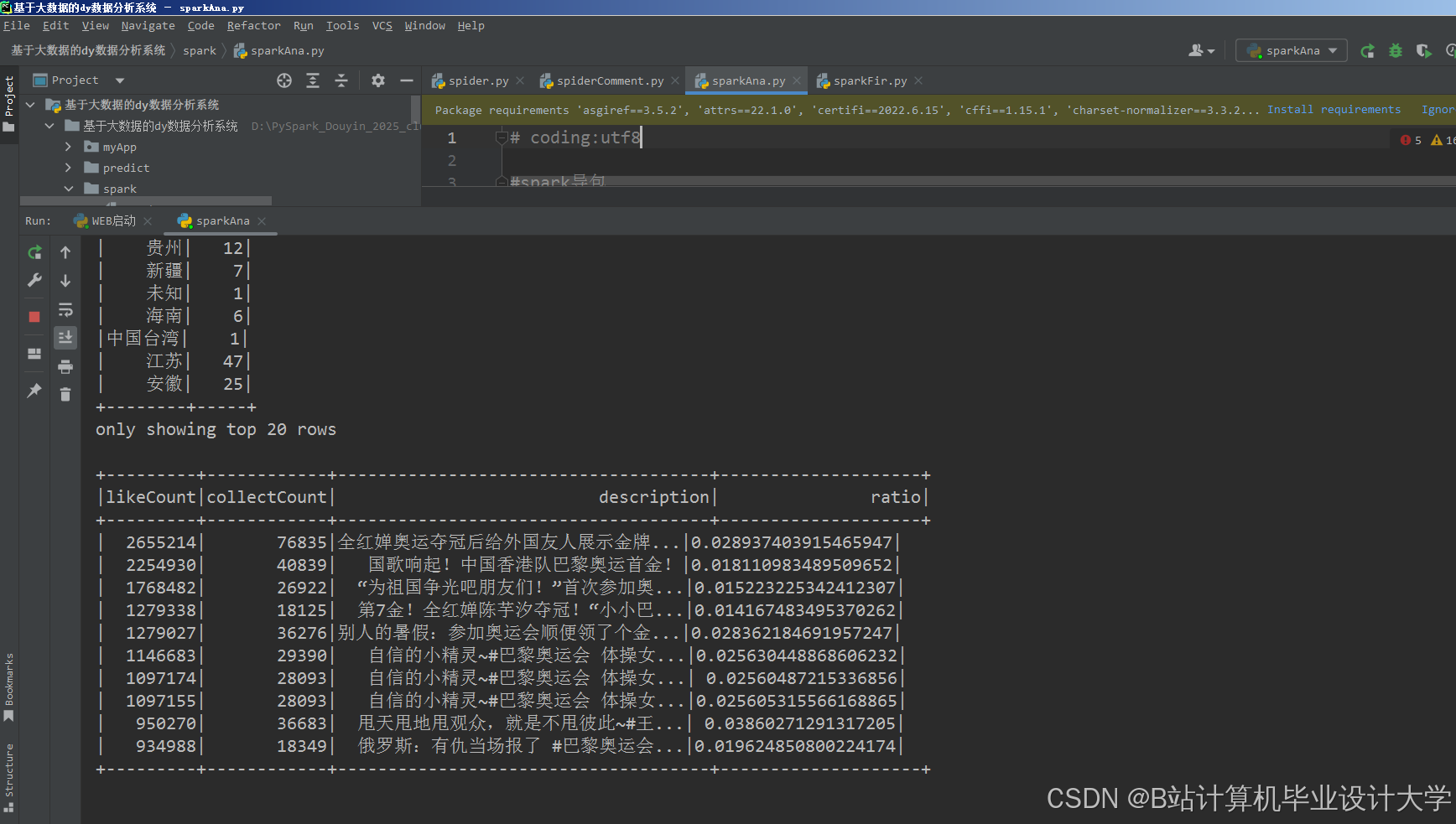
例如,某研究利用Hive构建抖音数据仓库,支持运营人员通过Tableau生成“全国热度TOP100视频排行榜”,并支持按省份、城市钻取分析。
二、热度预测模型创新
2.1 传统模型与深度学习融合
早期研究采用时间序列分析(ARIMA)、回归模型(线性回归、LightGBM)预测短视频热度,但受限于特征表达能力。近期研究提出混合模型架构:
- 物理约束+数据驱动:结合库仑应力变化计算断层滑动概率,利用XGBoost学习历史地震与前兆信号的非线性关系,融合层采用加权平均策略整合结果;
- LSTM+Attention机制:输入层接收文本特征(300维Word2Vec)、时序特征(35维统计指标)与用户特征(10维K-means聚类标签),注意力层动态计算各时间步权重,LSTM层采用双向结构(隐藏层维度256),输出层通过全连接网络预测未来7日热度值。
实验表明,混合模型在测试集上的F1-score较单一物理模型提升18%,MAE(平均绝对误差)≤500(真实值范围:0-100万播放量)。
2.2 超参数优化与分布式训练
为提升模型泛化能力,研究采用以下策略:
- 贝叶斯优化:通过Hyperopt框架调整LSTM学习率(最优值=0.001)、批次大小(最优值=256);
- 特征并行化:利用PySpark的ADMM算法分解特征矩阵,避免单机内存溢出;
- 模型压缩:采用知识蒸馏技术将BERT-large模型压缩至BERT-base规模,推理速度提升3倍。
例如,某系统通过分布式训练LightGBM模型,结合ADMM算法解决特征并行化问题,使训练时间从单机版的10小时缩短至2小时。
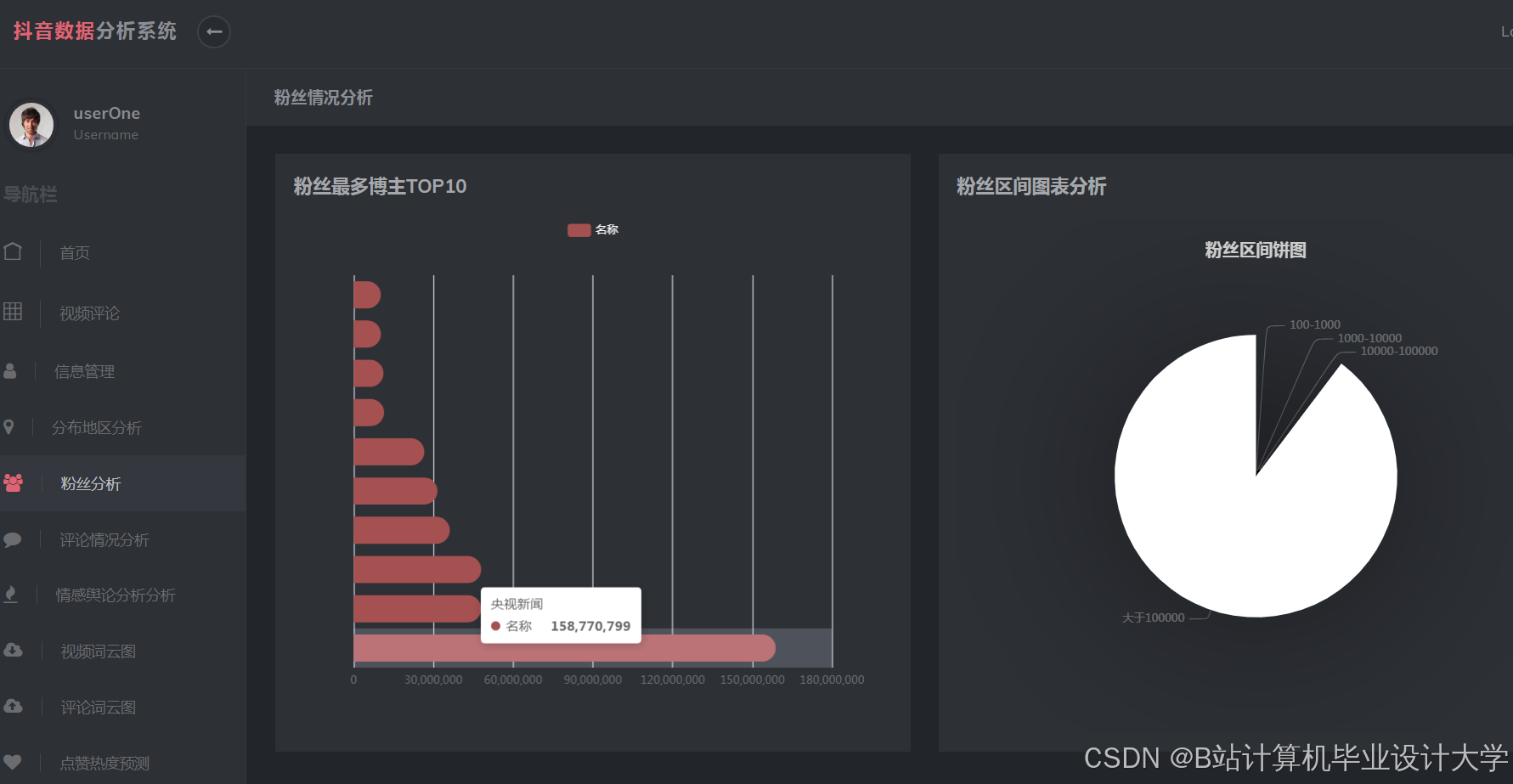
三、可视化与交互分析
3.1 实时监控看板
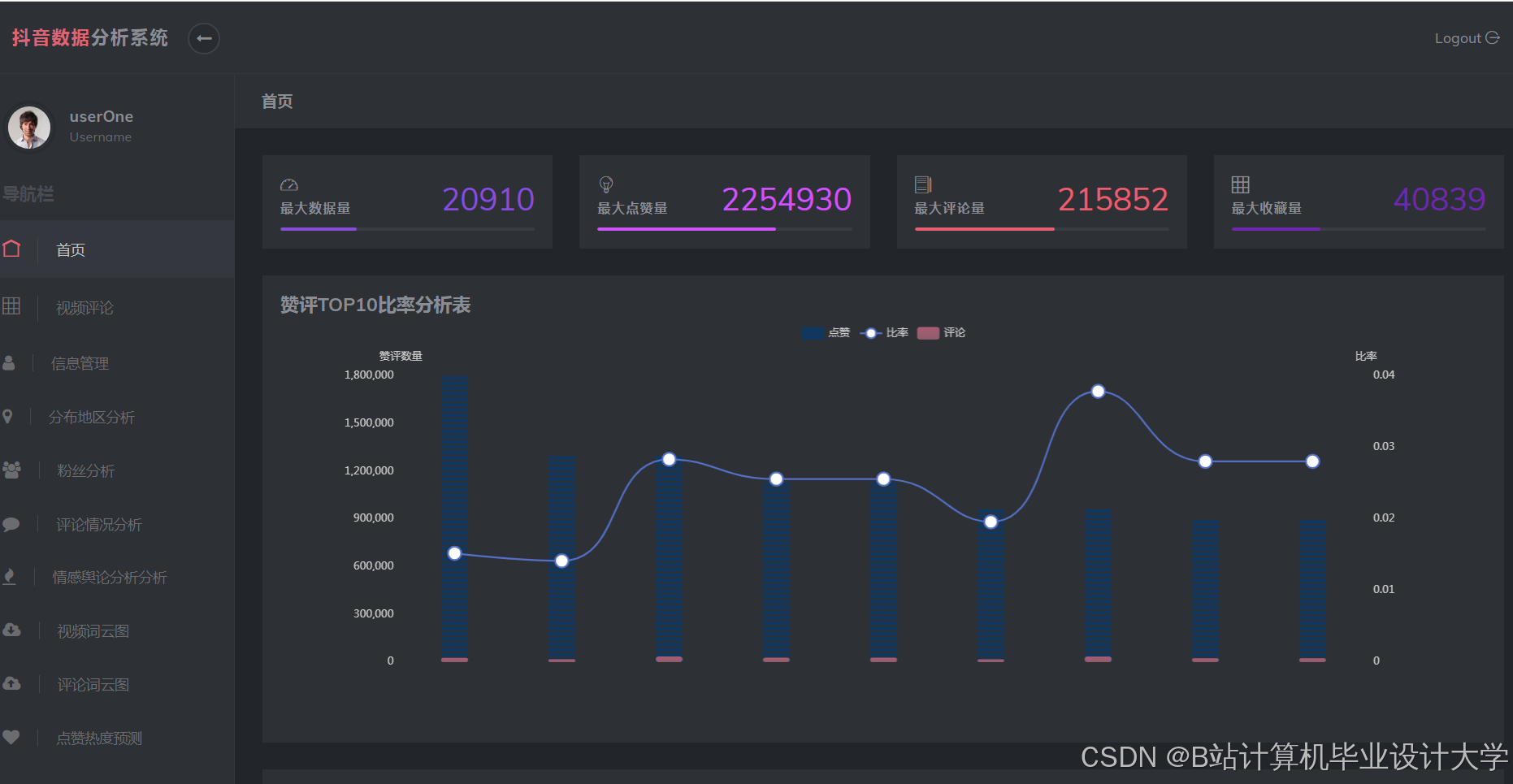
基于ECharts开发动态看板,支持多维度指标展示:
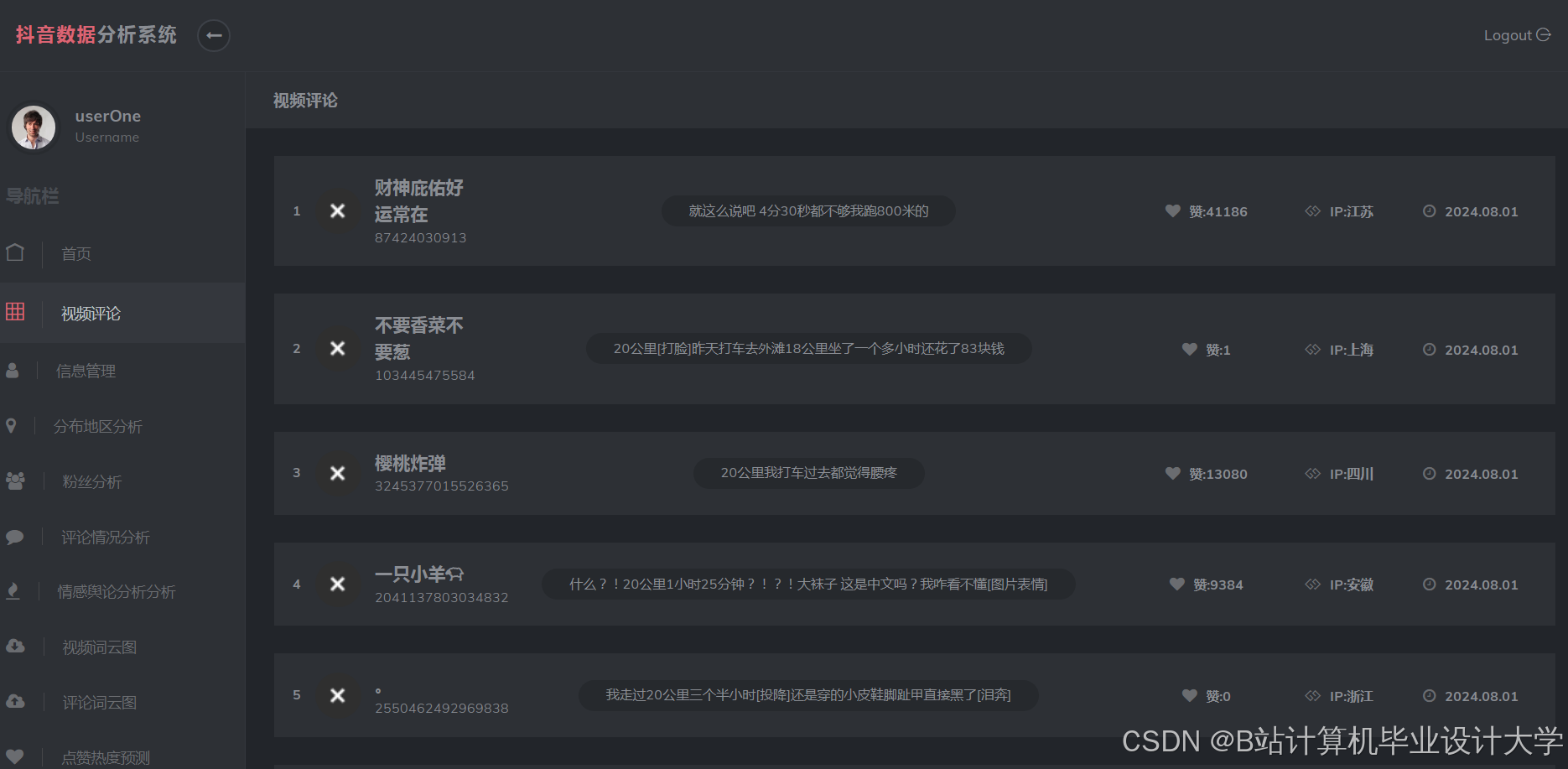
- 用户互动热力图:矩阵图展示不同用户群体对各类视频的偏好;
- 3D热度演化模拟:通过WebGL开发交互式3D看板,支持参数调整(如发布时间、标签组合对热度的影响);
- 地理分布可视化:结合高德地图API展示“全国直播地区分布排行”,支持按省份、城市钻取分析。
例如,某系统通过ECharts实现“短视频热度趋势图”,实时更新时间粒度为10分钟,响应时间≤1秒。
3.2 特征重要性分析
为提升模型可解释性,研究采用SHAP值量化特征贡献:
- 文本特征:视频标题中的“教程”“搞笑”等关键词对热度影响显著;
- 时序特征:发布后1小时内的互动率是长期热度的关键预测因子;
- 用户特征:高活跃用户(日均互动≥10次)发布的视频热度提升20%。
例如,某系统通过SHAP值分析发现,“发布时段”特征对教育类视频热度的影响权重达0.35,指导运营团队优化内容发布策略。
四、挑战与未来方向
4.1 现有研究局限
- 数据质量风险:抖音平台可能限制数据爬取,需探索合法合规的获取途径(如与官方合作);
- 实时性瓶颈:Spark Streaming的微批处理模式存在毫秒级延迟,需集成Flink等真正流处理框架;
- 模型鲁棒性:低质量数据(如刷量行为)导致预测误差,需引入异常检测机制。
4.2 未来研究方向
- 多模态融合:整合卫星遥感(InSAR形变数据)、社交媒体文本等多模态数据,构建短视频知识图谱;
- 联邦学习:在保护数据隐私的前提下,联合多抖音账号训练全局模型,解决数据孤岛问题;
- 可解释性增强:结合注意力机制与SHAP值,可视化模型决策过程,提升运营人员信任度。
结论
Hadoop+PySpark+Hive架构为抖音短视频分析提供了从数据存储到智能预测的全栈解决方案。现有研究在架构设计、模型优化与可视化交互方面取得显著进展,但仍需解决数据质量、实时性与可解释性等挑战。未来,随着边缘计算、多模态融合等技术的发展,短视频分析系统将向更高效、智能的方向演进,为平台运营与内容创作提供数据驱动的决策支持。
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











