




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Hadoop + Spark + Hive 酒店推荐系统》的任务书模板,涵盖大数据处理、分布式计算与数据仓库技术,适用于酒店预订场景的个性化推荐系统开发:
任务书:基于Hadoop + Spark + Hive的酒店推荐系统
一、项目背景与目标
1. 背景
随着在线旅游平台(如携程、Booking)用户量激增,酒店数据呈现海量、高维、异构特点(用户行为日志、酒店属性、评价文本等)。传统单机推荐算法难以处理PB级数据,需结合分布式计算框架(Spark)与数据仓库(Hive)实现高效推荐。
- 技术需求:
- Hadoop:分布式存储(HDFS)与资源调度(YARN)。
- Spark:基于内存的分布式计算,加速特征工程与推荐模型训练。
- Hive:构建结构化数据仓库,支持SQL查询优化与历史数据回溯。
2. 目标
- 构建基于用户历史行为与酒店属性的混合推荐系统,支持离线批量推荐与近实时增量更新。
- 实现推荐结果可解释性(如“根据您常住的商务型酒店推荐”)。
- 提升推荐点击率(CTR)与转化率(CVR),降低用户搜索成本。
二、任务内容与范围
1. 系统架构设计
数据层:HDFS(存储原始日志、酒店元数据) | |
→ 计算层:Spark(特征提取、模型训练、推荐生成) | |
→ 数据仓库层:Hive(结构化数据存储、ETL处理) | |
→ 服务层:Flask API(推荐查询接口) + Redis(缓存热门推荐结果) | |
→ 应用层:Web前端(展示推荐列表与推荐理由) |
2. 模块划分
(1) 数据采集与存储模块
- 数据来源:
- 用户行为数据:浏览记录、搜索关键词、预订历史、停留时长(日志文件)。
- 酒店属性数据:价格、位置、评分、设施(如WiFi、泳池)、标签(商务/度假/亲子)。
- 上下文数据:时间(工作日/节假日)、地理位置(用户当前城市)。
- 存储方案:
- HDFS:存储原始JSON/CSV格式的日志文件(如
/data/raw/user_logs/)。 - Hive:构建分层数据仓库:
- ODS层:原始数据表(
ods_user_behavior、ods_hotel_info)。 - DWD层:清洗后的明细数据(去重、缺失值填充)。
- DWS层:聚合统计表(如用户每日活跃度、酒店月度评分趋势)。
- ODS层:原始数据表(
- HDFS:存储原始JSON/CSV格式的日志文件(如
(2) 特征工程模块
- 用户特征:
- 静态特征:年龄、性别、会员等级。
- 动态特征:
- 历史行为序列(Spark SQL实现):
sqlSELECT user_id, collect_list(hotel_id) as history_hotelsFROM dwd_user_behaviorGROUP BY user_id; - 偏好标签(TF-IDF提取搜索关键词):
pythonfrom pyspark.ml.feature import HashingTF, IDFhashingTF = HashingTF(inputCol="search_keywords", outputCol="raw_features")idf = IDF(inputCol="raw_features", outputCol="user_preferences")
- 历史行为序列(Spark SQL实现):
- 酒店特征:
- 结构化特征:价格区间、距离市中心距离(数值型)。
- 非结构化特征:评价文本情感分析(Spark NLP库):
pythonfrom sparknlp.base import DocumentAssemblerfrom sparknlp.annotator import SentimentDetectorModeldocument_assembler = DocumentAssembler().setInputCol("review_text").setOutputCol("document")sentiment_detector = SentimentDetectorModel.pretrained().setInputCols(["document"]).setOutputCol("sentiment")
(3) 推荐算法模块
- 离线推荐(每日凌晨运行):
- 基于用户的协同过滤(User-CF):
- 计算用户相似度矩阵(Spark RDD实现):
pythonuser_pairs = user_hotel_df.cartesian(user_hotel_df) # 用户两两组合similarity = user_pairs.filter(lambda x: x[0][0] != x[1][0]) # 排除自身.map(lambda x: ((x[0][0], x[1][0]), len(set(x[0][1]) & set(x[1][1])))) # 共同浏览酒店数
- 计算用户相似度矩阵(Spark RDD实现):
- 基于内容的推荐(Content-Based):
- 计算酒店特征向量余弦相似度(Spark MLlib):
pythonfrom pyspark.ml.feature import VectorAssemblerassembler = VectorAssembler(inputCols=["price", "distance", "score"], outputCol="features")hotel_features = assembler.transform(hotel_df)from pyspark.ml.linalg import Vectorsfrom pyspark.mllib.linalg.distributed import RowMatrixmatrix = RowMatrix(hotel_features.select("features").rdd.map(lambda x: Vectors.dense(x[0].toArray)))
- 计算酒店特征向量余弦相似度(Spark MLlib):
- 混合推荐:
- 加权融合User-CF与Content-Based得分(权重通过A/B测试确定)。
- 基于用户的协同过滤(User-CF):
- 近实时推荐(用户行为触发):
- 当用户浏览某酒店时,Spark Streaming实时计算相似酒店列表:
pythonfrom pyspark.streaming import StreamingContextssc = StreamingContext(spark.sparkContext, batchDuration=10) # 10秒批处理user_stream = ssc.socketTextStream("localhost", 9999) # 模拟用户行为流user_stream.foreachRDD(lambda rdd: rdd.foreachPartition(update_recommendations))
- 当用户浏览某酒店时,Spark Streaming实时计算相似酒店列表:
(4) 推荐服务模块
- API设计:
- 请求:
GET /recommend?user_id=123&city=上海&checkin_date=2024-01-01 - 响应:
json{"recommendations": [{"hotel_id": 1001,"name": "上海外滩W酒店","score": 4.8,"reason": "根据您常住的豪华型酒店推荐"}],"timestamp": "2024-01-01T10:00:00Z"}
- 请求:
- 缓存策略:
- 使用Redis存储热门用户(如过去7天活跃用户)的推荐结果,TTL设置为1小时。
3. 数据处理流程
- 数据采集:
- 通过Flume采集用户行为日志,写入HDFS的
/data/raw/user_logs/目录。 - 酒店属性数据通过Sqoop从MySQL导入Hive的
ods_hotel_info表。
- 通过Flume采集用户行为日志,写入HDFS的
- ETL处理:
- 使用Hive SQL清洗数据(去重、格式转换):
sqlINSERT OVERWRITE TABLE dwd_user_behaviorSELECT DISTINCT user_id, hotel_id, action_type, create_timeFROM ods_user_behaviorWHERE user_id IS NOT NULL;
- 使用Hive SQL清洗数据(去重、格式转换):
- 特征计算:
- Spark作业生成用户偏好向量与酒店特征矩阵,存储至Hive的
dws_user_features与dws_hotel_features表。
- Spark作业生成用户偏好向量与酒店特征矩阵,存储至Hive的
- 模型训练:
- 每日凌晨触发Spark MLlib作业,更新User-CF相似度矩阵与Content-Based模型参数。
- 推荐生成:
- 离线推荐结果写入Hive的
dws_user_recommendations表,供API查询。
- 离线推荐结果写入Hive的
三、技术路线
1. 开发环境配置
- 集群部署:
- Hadoop 3.3.4(1 NameNode + 2 DataNodes)。
- Spark 3.3.2(Standalone模式,4核8G × 3节点)。
- Hive 3.1.3(Metastore使用MySQL存储元数据)。
- 依赖库:
- PySpark 3.3.2、Hive JDBC驱动、Redis-py、Flask 2.0.1。
2. 核心代码示例
(1) Hive表设计
sql
-- 用户行为明细表 | |
CREATE TABLE dwd_user_behavior ( | |
user_id STRING, | |
hotel_id STRING, | |
action_type STRING COMMENT '浏览/预订/收藏', | |
create_time TIMESTAMP | |
) PARTITIONED BY (dt STRING COMMENT '按天分区') STORED AS ORC; | |
-- 用户特征表 | |
CREATE TABLE dws_user_features ( | |
user_id STRING, | |
preferences ARRAY<STRING> COMMENT '用户偏好标签', | |
avg_price DOUBLE COMMENT '历史预订平均价格' | |
) STORED AS PARQUET; |
(2) Spark推荐生成逻辑
python
from pyspark.sql import SparkSession | |
spark = SparkSession.builder.appName("HotelRecommendation").getOrCreate() | |
# 加载用户特征与酒店特征 | |
user_features = spark.table("dws_user_features") | |
hotel_features = spark.table("dws_hotel_features") | |
# 生成推荐(简化版:基于价格相似度) | |
recommendations = user_features.join(hotel_features, on=[], how="cross") \ | |
.filter("abs(avg_price - price) / price < 0.2") \ # 价格波动20%以内 | |
.groupBy("user_id").agg(collect_list("hotel_id").alias("recommended_hotels")) | |
recommendations.write.saveAsTable("dws_user_recommendations") |
(3) Flask推荐接口
python
from flask import Flask, request, jsonify | |
import pyhive.presto | |
app = Flask(__name__) | |
conn = pyhive.presto.connect(host="localhost", port=8080, database="hive") | |
@app.route("/recommend") | |
def recommend(): | |
user_id = request.args.get("user_id") | |
cursor = conn.cursor() | |
cursor.execute(f""" | |
SELECT hotel_id, name, score | |
FROM dws_user_recommendations | |
JOIN dim_hotel ON hotel_id = id | |
WHERE user_id = '{user_id}' | |
LIMIT 10 | |
""") | |
results = [{"hotel_id": row[0], "name": row[1], "score": row[2]} for row in cursor.fetchall()] | |
return jsonify(recommendations=results) |
四、预期成果
- 系统部署包:
- Hadoop/Spark/Hive集群配置脚本(
deploy.sh)。 - 推荐引擎Python脚本(
recommend.py)与Hive SQL脚本(etl.sql)。
- Hadoop/Spark/Hive集群配置脚本(
- 文档:
- 技术设计文档(含架构图、数据流、算法说明)。
- 用户手册(API调用示例、环境配置步骤)。
- 可视化看板:
- Grafana链接展示推荐CTR趋势、热门推荐酒店排名。
五、时间计划
| 阶段 | 时间 | 任务内容 |
|---|---|---|
| 环境搭建 | 第1周 | 完成Hadoop/Spark/Hive集群部署与基础测试 |
| 数据采集与ETL | 第2周 | 配置Flume/Sqoop采集数据,编写Hive ETL脚本 |
| 特征工程 | 第3周 | 实现用户/酒店特征提取与存储至Hive |
| 推荐算法开发 | 第4周 | 完成User-CF与Content-Based推荐逻辑 |
| 实时推荐优化 | 第5周 | 集成Spark Streaming实现近实时推荐 |
| 系统测试与部署 | 第6周 | 压力测试、A/B测试、文档编写与可视化看板开发 |
六、资源需求
- 硬件:
- 服务器:4核8G内存 × 3台(模拟集群)。
- 存储:HDFS建议至少1TB可用空间(日志数据量较大)。
- 数据:
- 模拟数据集:生成100万用户、10万酒店的随机行为数据(可用Python脚本生成)。
- 软件:
- Python库:PySpark 3.3+、PyHive 0.6+、Flask 2.0+。
- 大数据组件:Hadoop 3.3+、Spark 3.3+、Hive 3.1+。
七、风险评估与应对
- 数据倾斜问题:
- 风险:热门酒店(如全季、希尔顿)的浏览记录过多,导致Spark任务卡顿。
- 应对:对热门酒店ID进行哈希分片,均匀分配计算任务。
- 推荐冷启动:
- 风险:新用户无历史行为,无法生成推荐。
- 应对:基于用户注册信息(如城市、会员等级)推荐热门酒店。
- 实时推荐延迟:
- 风险:Spark Streaming批处理间隔过长(如1分钟),导致推荐更新不及时。
- 应对:优化为Kafka + Flink实现毫秒级流处理(可选扩展)。
八、验收标准
- 推荐质量指标:
- 离线推荐生成时间 ≤ 2小时(100万用户数据)。
- 推荐CTR较基准模型(随机推荐)提升 ≥ 20%。
- 系统稳定性:
- 7×24小时运行无OOM或数据丢失,支持50+并发API请求。
- 可扩展性:
- 新增10万用户数据时,推荐生成时间增加 ≤ 30%。
负责人:XXX
日期:XXXX年XX月XX日
可根据实际需求扩展功能(如加入图计算(GraphX)分析用户社交关系,或使用XGBoost替代协同过滤提升准确性)。如需进一步细化某部分(如Hive表分区策略或Spark任务调优参数),可随时补充!
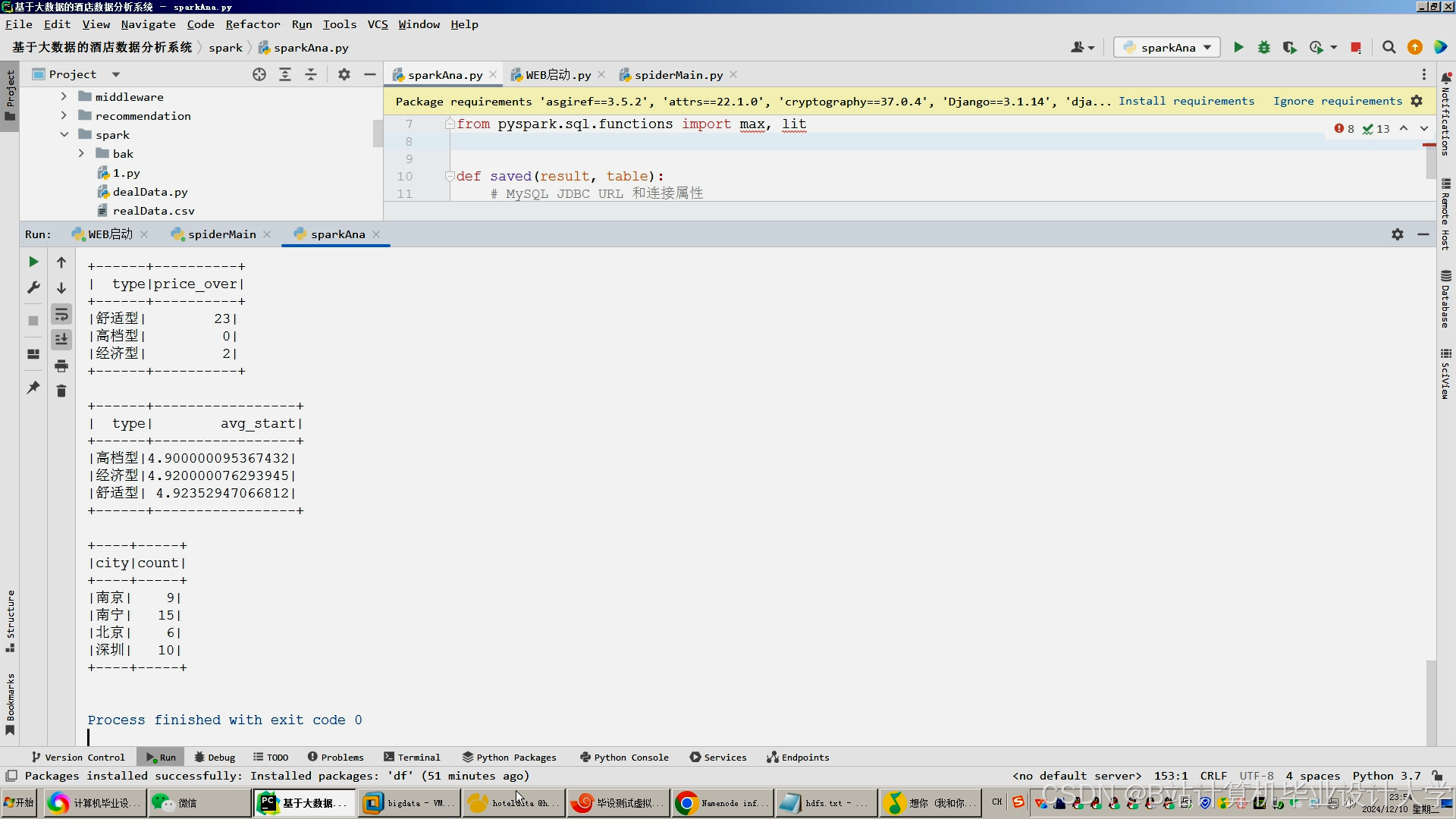
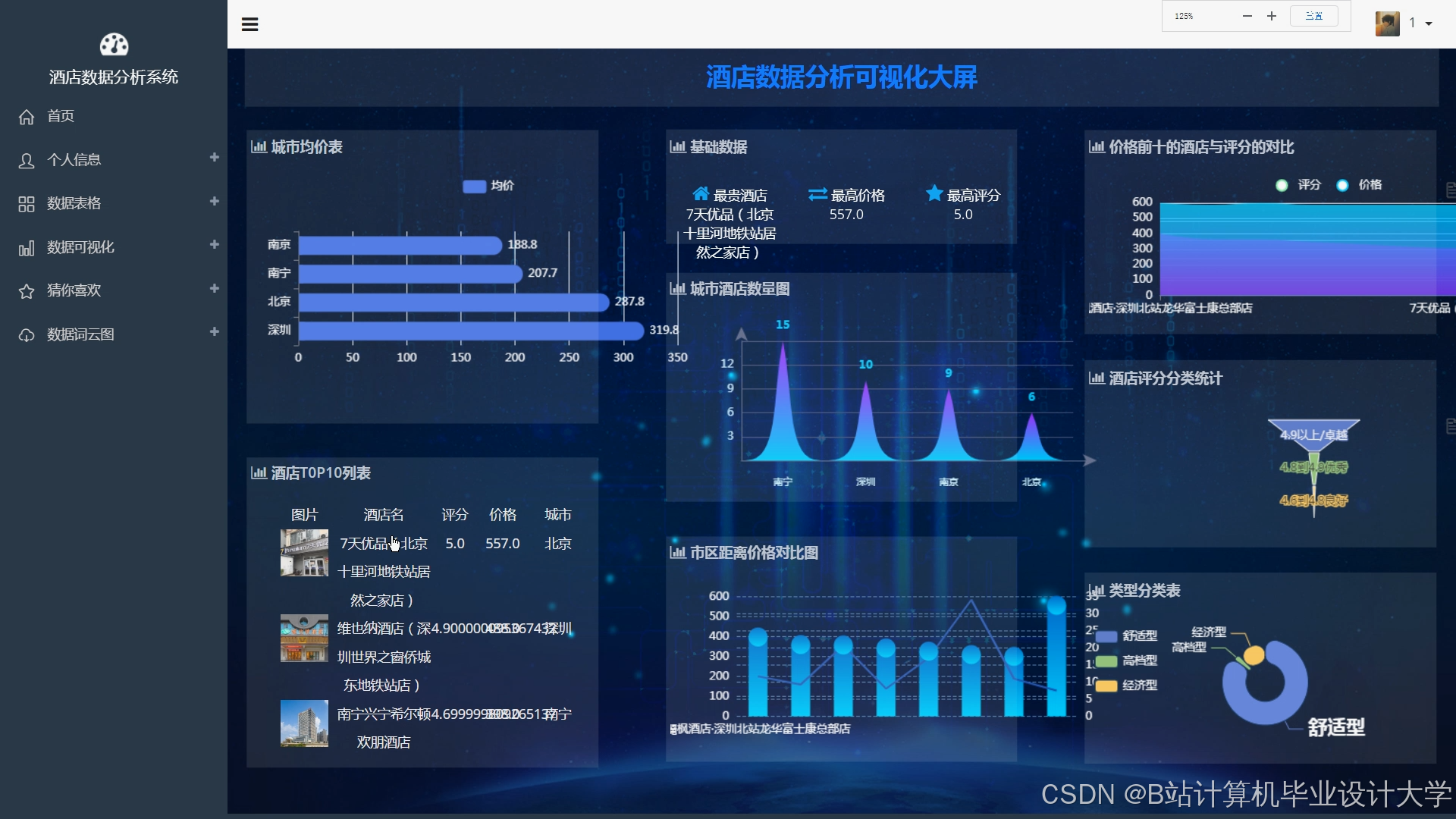
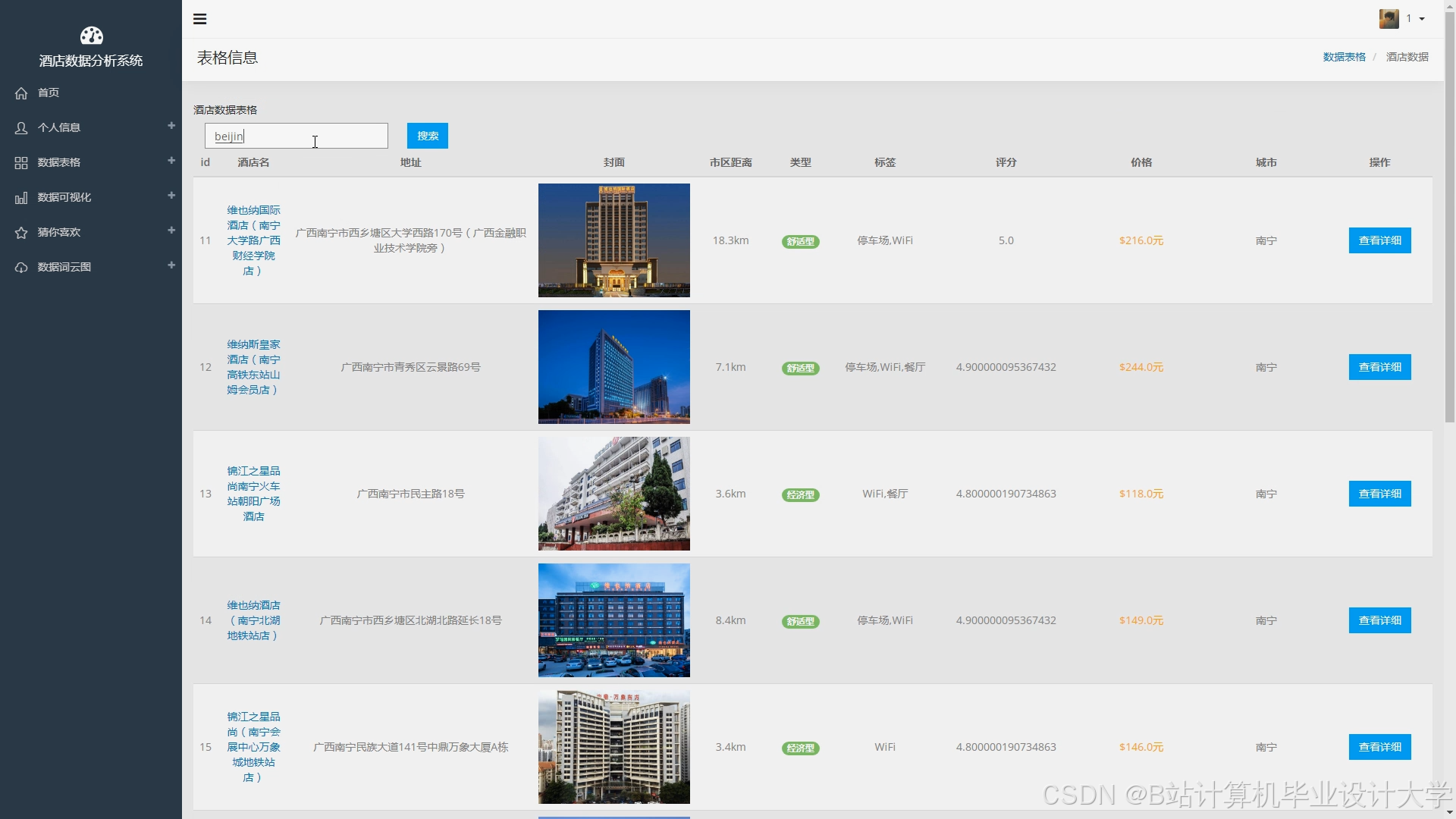
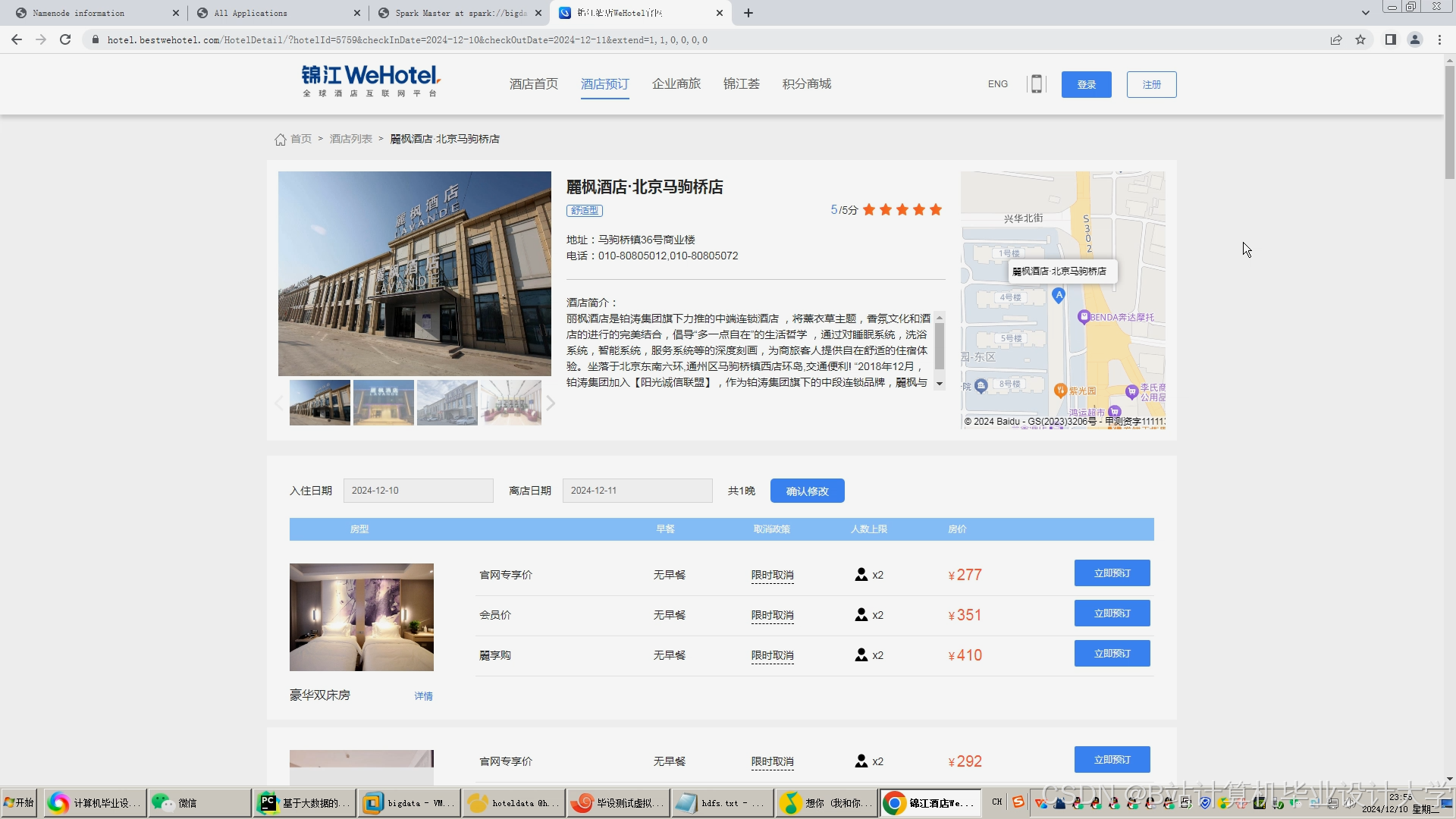
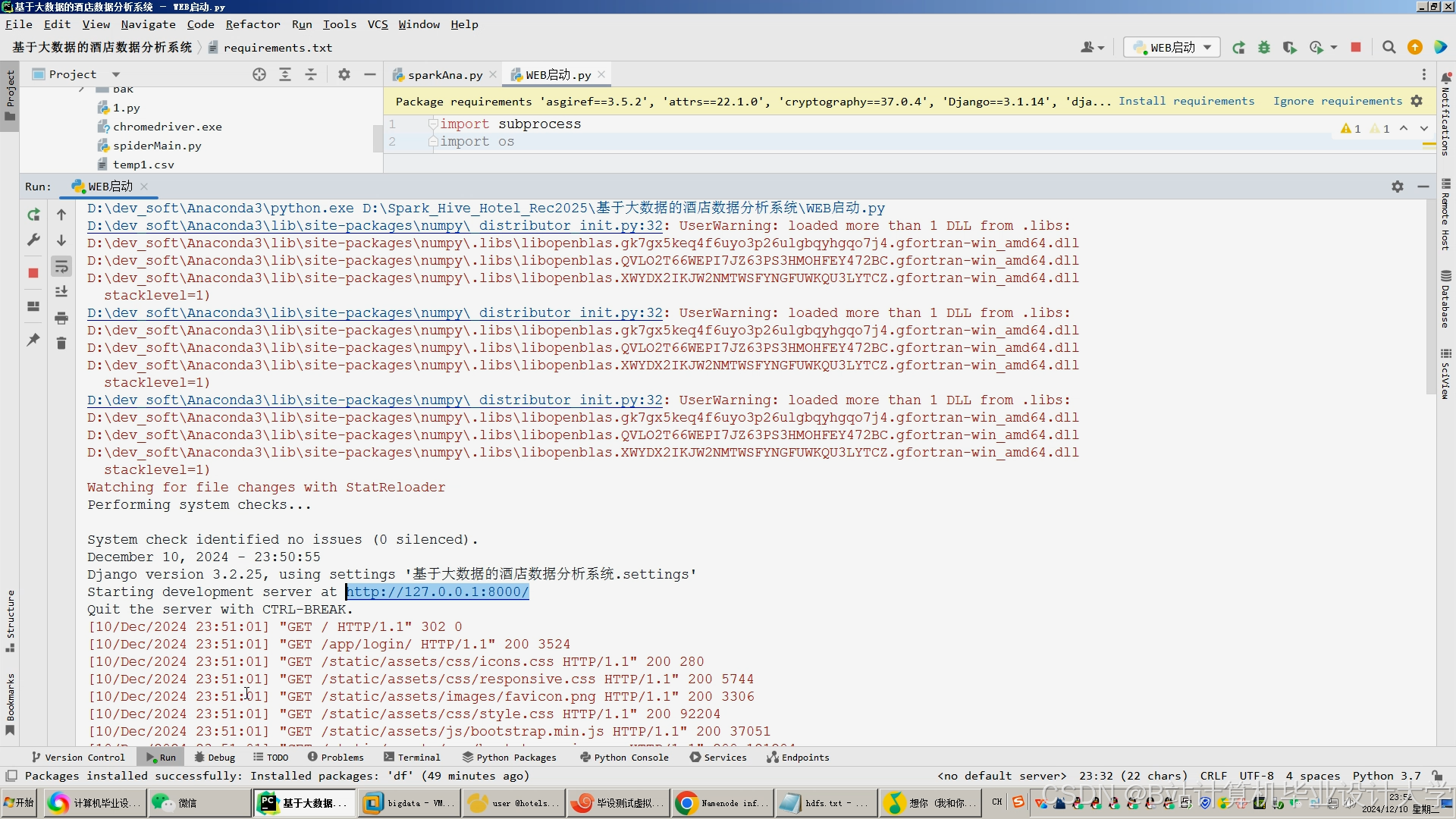
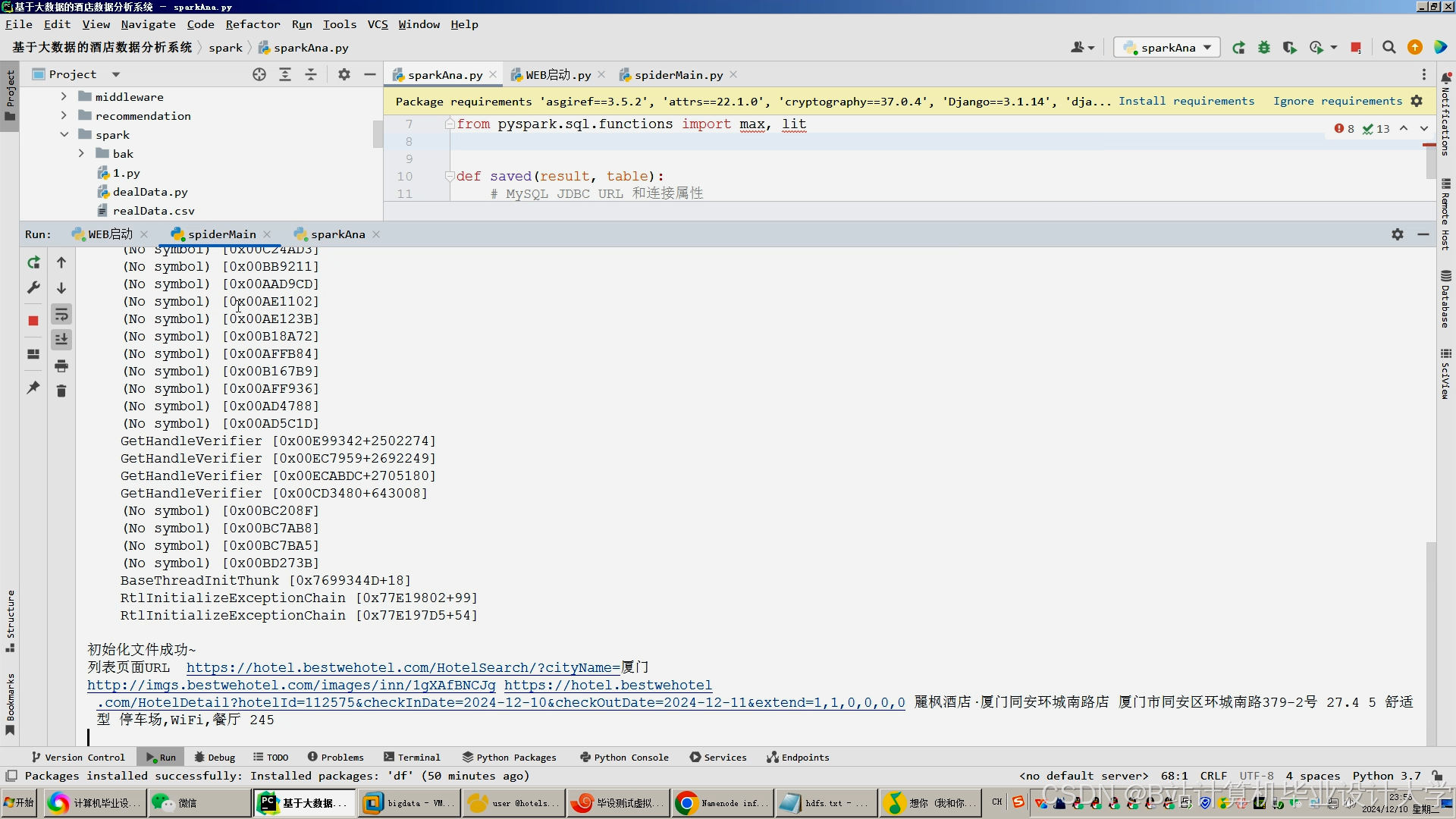
运行截图
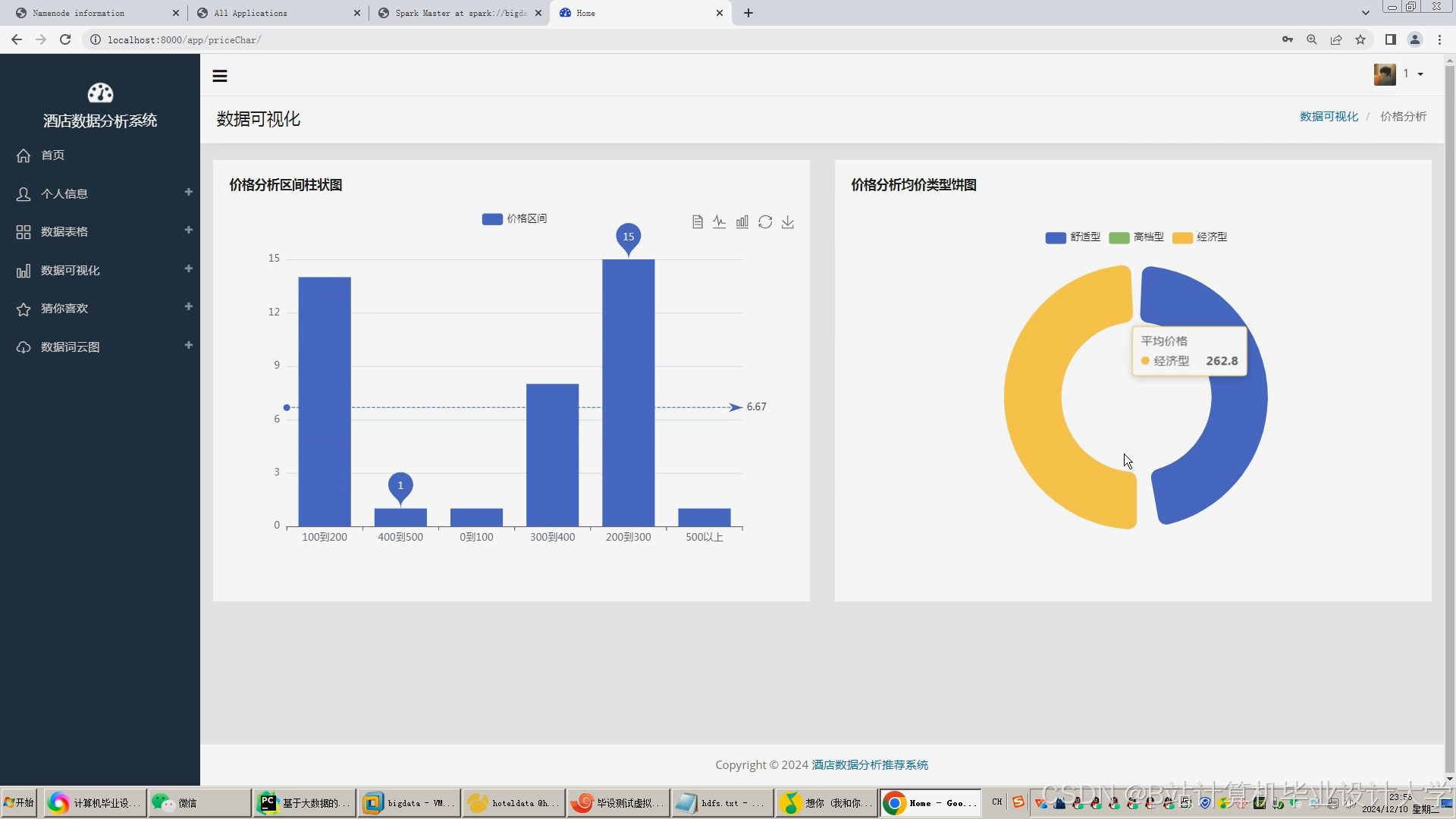
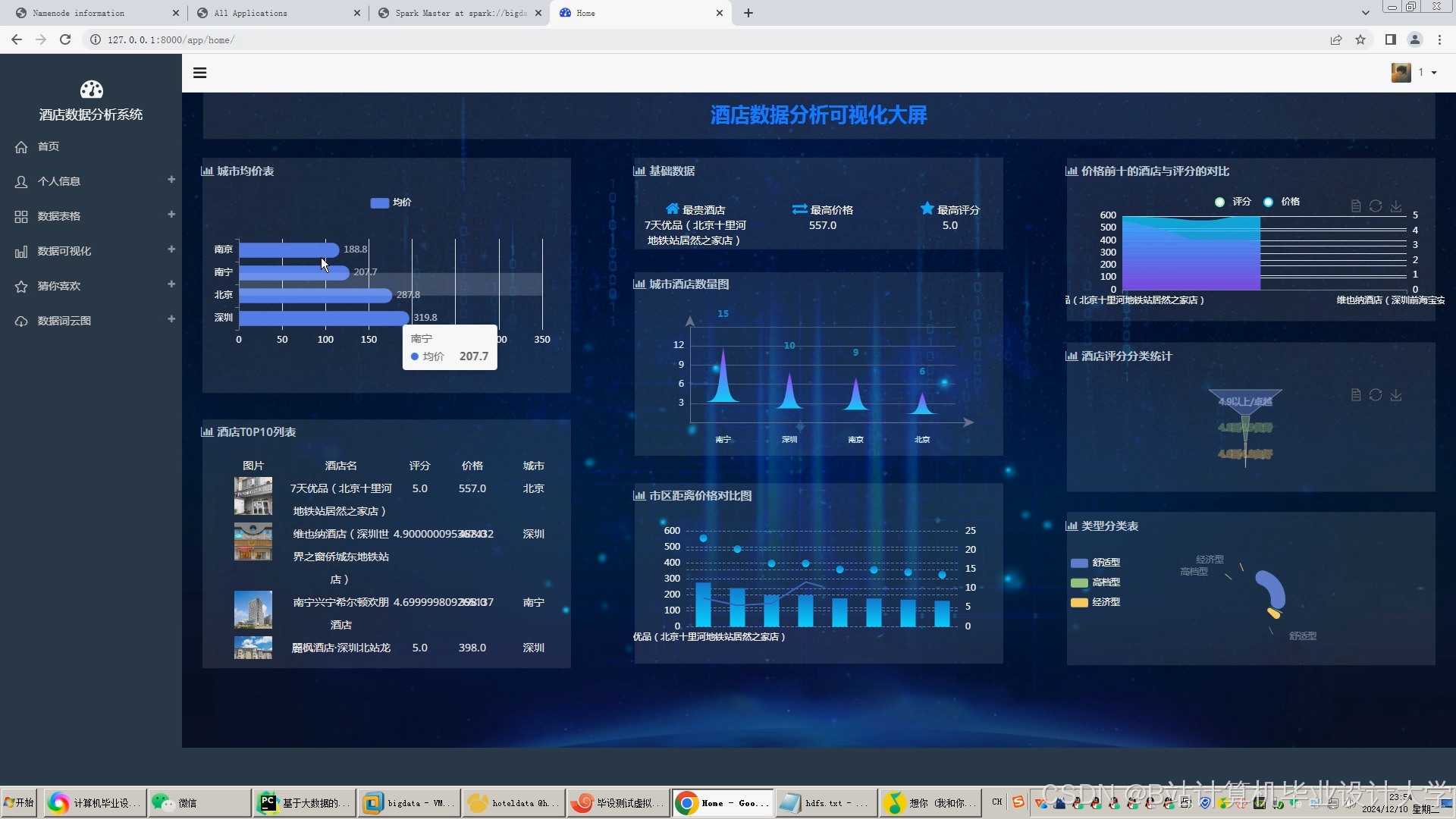
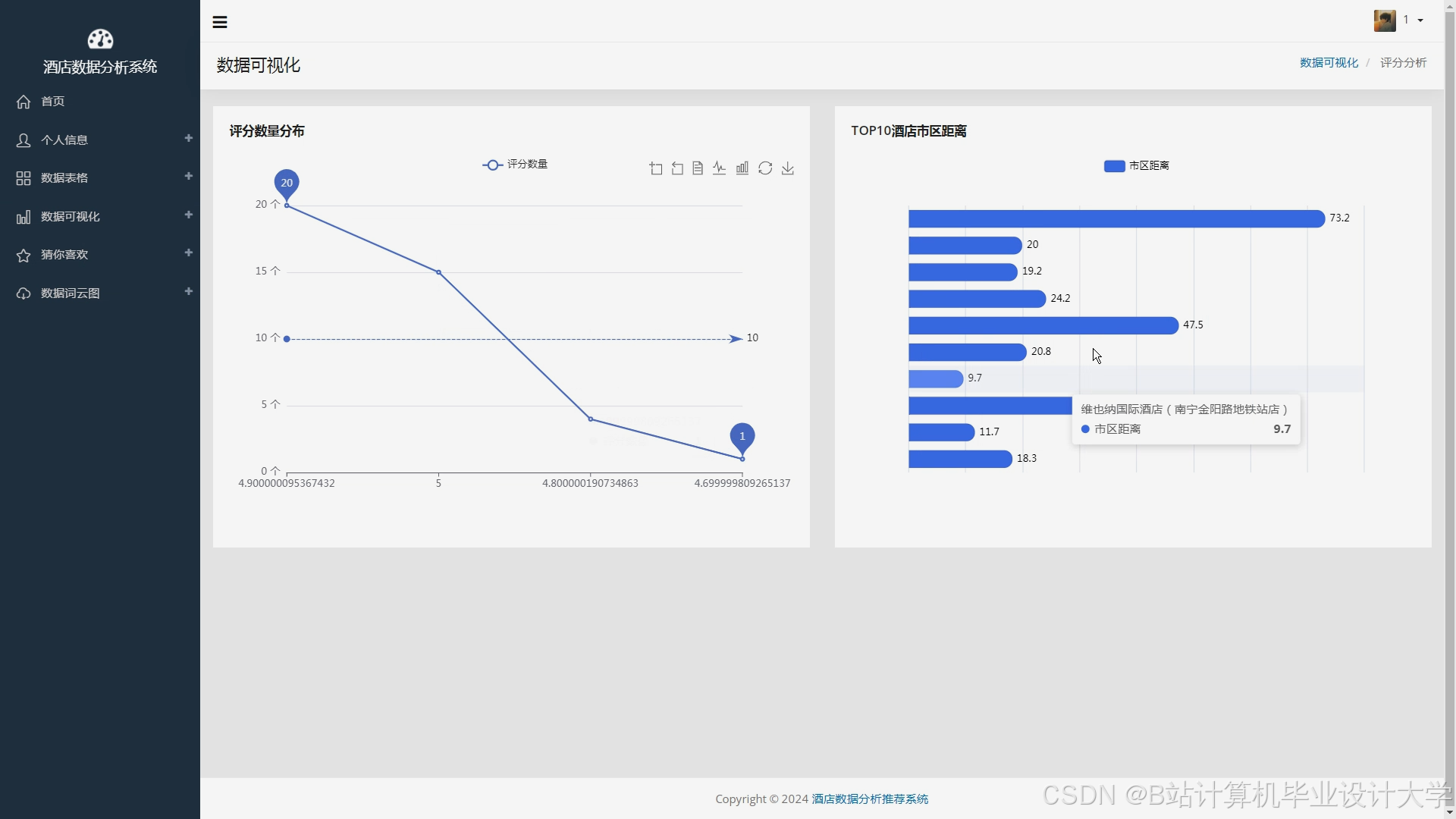
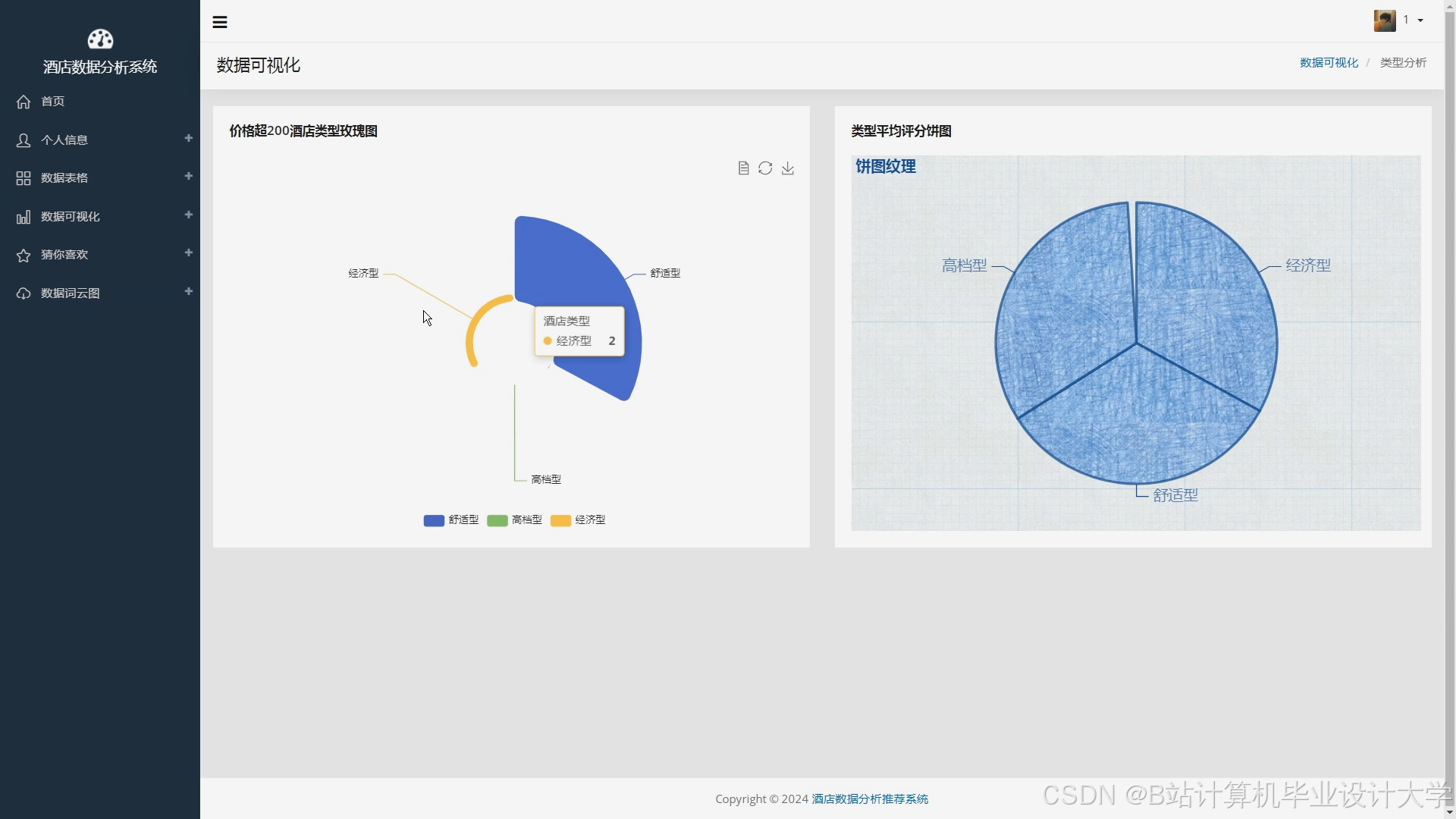
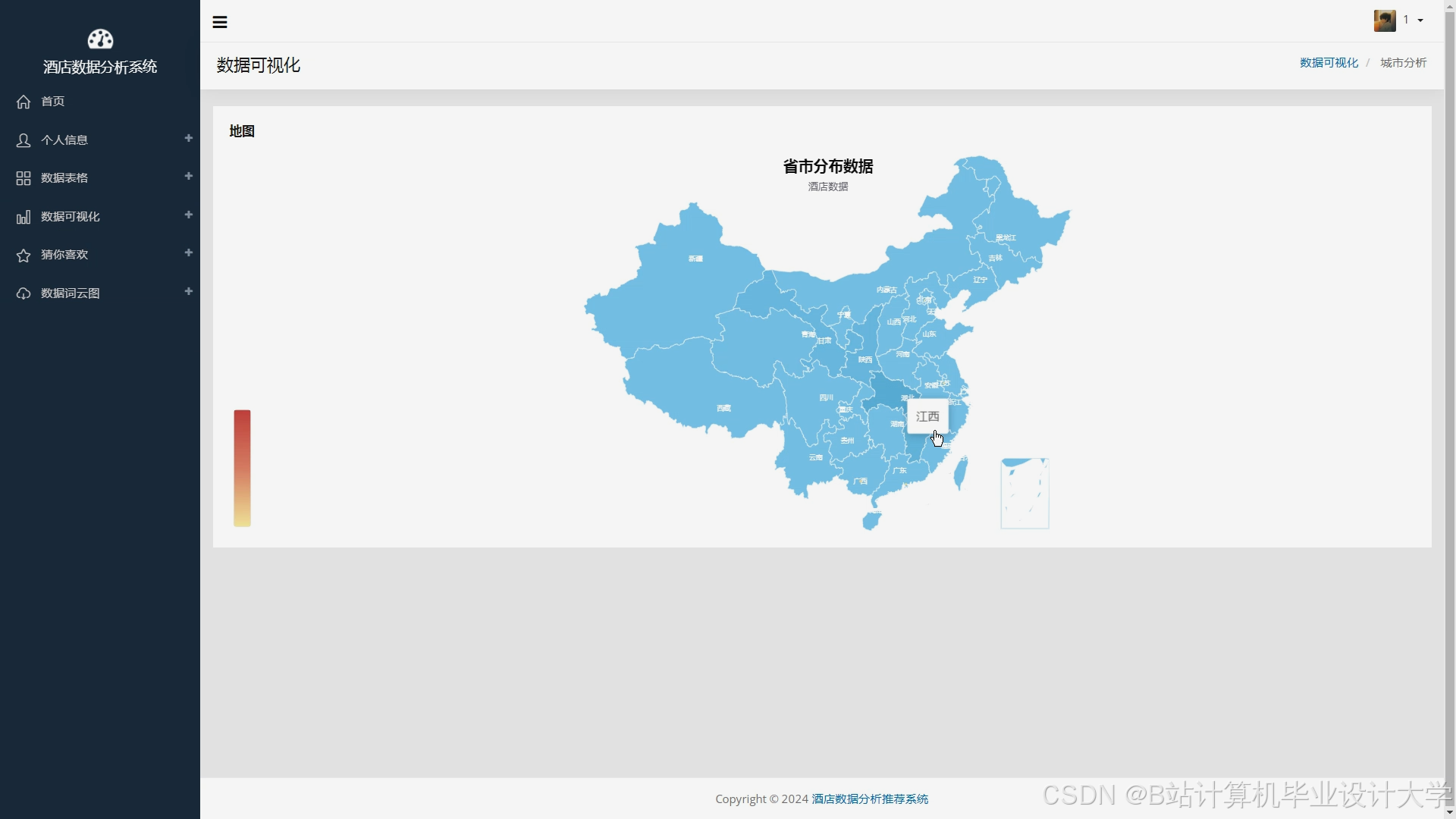
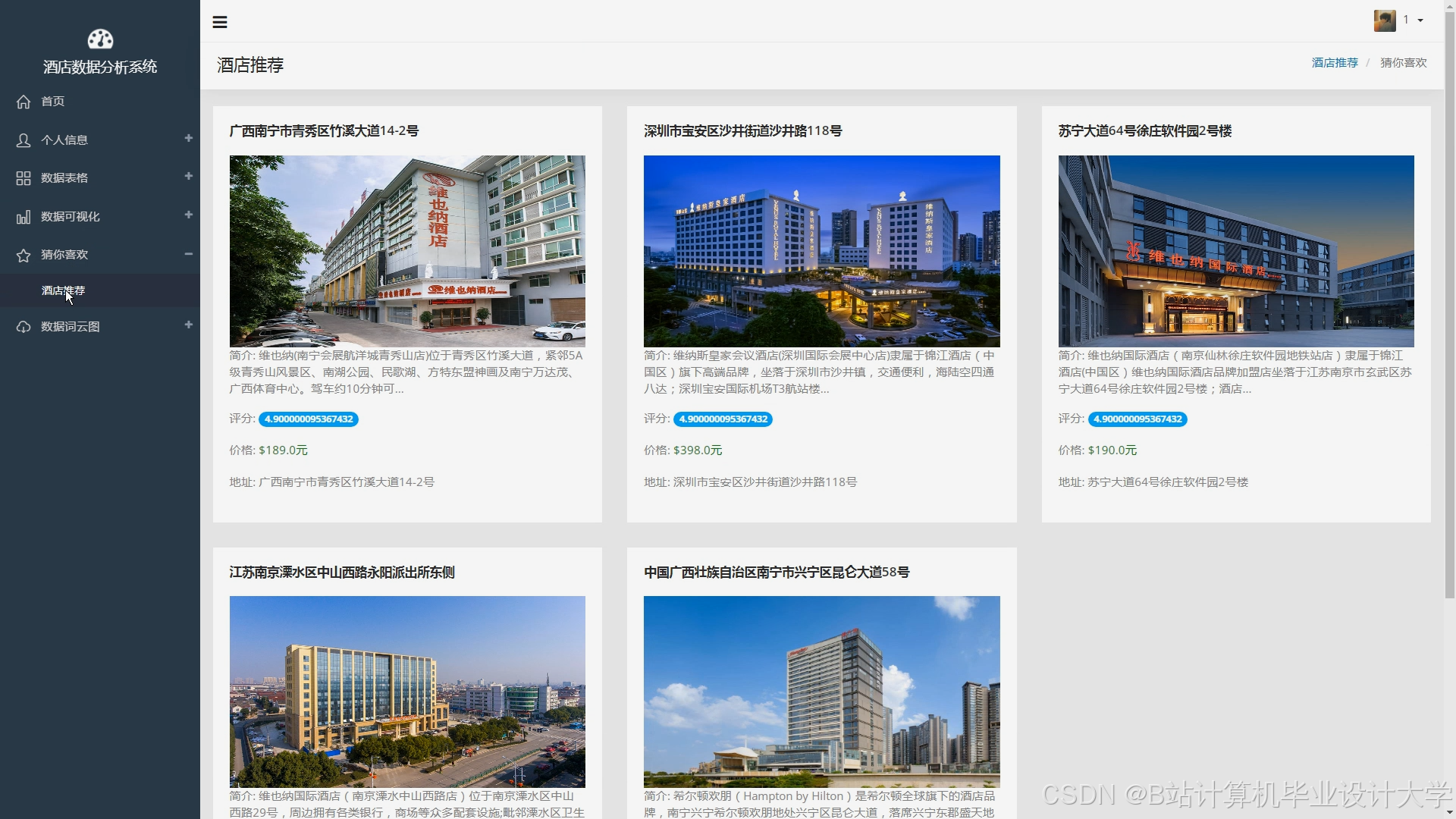


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











