




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Python + PySpark + Hadoop 视频推荐系统与弹幕情感分析》的任务书模板,结合大数据处理与自然语言处理(NLP)技术,供参考:
任务书:基于Python + PySpark + Hadoop的视频推荐系统与弹幕情感分析
一、项目背景与目标
- 背景
视频平台(如B站、YouTube)用户生成大量弹幕数据,反映实时观看情绪与兴趣点。结合视频内容特征与弹幕情感分析,可提升推荐系统的个性化程度。- 技术需求:
- Hadoop处理海量视频元数据与弹幕日志。
- PySpark实现分布式特征提取与情感分析模型训练。
- Python开发推荐算法与可视化接口。
- 技术需求:
- 目标
- 构建基于视频内容与弹幕情感的混合推荐系统。
- 实现弹幕情感分类(积极/消极/中性),分析用户兴趣变化趋势。
- 提供实时推荐接口与情感分析可视化看板。
二、任务内容与范围
1. 系统架构设计
- 整体架构
数据层:Hadoop HDFS(存储视频元数据、弹幕日志)→ 计算层:PySpark(特征工程、情感分析、推荐算法)→ 服务层:Flask API(推荐结果查询) + Grafana(情感趋势可视化)→ 应用层:Web前端展示 - 模块划分
- 数据采集模块:
- 视频数据:标题、标签、分类、播放量、上传时间(结构化)。
- 弹幕数据:时间戳、用户ID、弹幕文本、视频时间轴位置(半结构化)。
- 数据存储模块:
- HDFS存储原始日志,Hive构建数据仓库(分区表按日期优化查询)。
- 特征工程模块:
- 视频特征:TF-IDF提取标题关键词、Word2Vec生成视频标签向量。
- 弹幕特征:基于BERT的文本情感分类、时间序列聚合(每分钟情感密度)。
- 推荐算法模块:
- 离线推荐:结合视频内容相似度(余弦相似度)与用户历史行为(协同过滤)。
- 实时推荐:根据当前视频弹幕情感动态调整推荐列表(如积极情绪时推荐同类视频)。
- 情感分析模块:
- 使用PySpark MLlib训练情感分类模型,标注弹幕情感标签。
- 分析情感随视频时间轴的变化趋势(如高潮片段情感波动)。
- 数据采集模块:
2. 技术选型
- 大数据组件
- Hadoop 3.x:分布式存储(HDFS)与资源调度(YARN)。
- PySpark 3.x:基于Python的Spark API,支持结构化数据处理(Spark SQL)与MLlib机器学习。
- 自然语言处理(NLP)
- 情感分析模型:
- 预训练模型:BERT中文版(Hugging Face Transformers库)。
- 轻量级模型:PySpark的
LogisticRegression或RandomForestClassifier(快速分类)。
- 文本特征提取:
- TF-IDF、Word2Vec、FastText。
- 情感分析模型:
- 推荐算法
- 内容过滤:基于视频标题/标签的相似度匹配。
- 协同过滤:利用用户观看历史生成推荐(ALS算法)。
- 混合推荐:加权融合内容相似度与用户行为评分。
- 开发工具
- 编程语言:Python 3.8+(PySpark、Flask、Pandas)。
- 可视化:Grafana/ECharts(情感趋势图、推荐点击率热力图)。
3. 数据处理流程
- 数据采集与存储
- 视频数据:通过平台API或爬虫获取,存储为HDFS的CSV/JSON文件。
- 弹幕数据:实时流式采集(如Kafka)或批量导入历史日志。
- Hive表设计:
dim_video(视频元数据表):视频ID、标题、标签、分类。dim_user(用户画像表):用户ID、观看历史、偏好分类。fact_danmaku(弹幕事实表):弹幕ID、视频ID、时间戳、文本、情感标签。
- 特征工程
- 视频特征:
pythonfrom pyspark.ml.feature import HashingTF, IDF# 提取标题关键词TF-IDF特征hashingTF = HashingTF(inputCol="title_tokens", outputCol="raw_features")idf = IDF(inputCol="raw_features", outputCol="title_features") - 弹幕特征:
- 使用BERT模型预测情感标签(积极/消极/中性):
pythonfrom transformers import BertTokenizer, BertForSequenceClassificationtokenizer = BertTokenizer.from_pretrained("bert-base-chinese")model = BertForSequenceClassification.from_pretrained("bert-base-chinese")
- 使用BERT模型预测情感标签(积极/消极/中性):
- 视频特征:
- 情感分析模型训练
- 基于PySpark的Pipeline:
pythonfrom pyspark.ml import Pipelinefrom pyspark.ml.classification import LogisticRegression# 定义特征转换与模型pipeline = Pipeline(stages=[tokenizer, hashingTF, idf, lr])model = pipeline.fit(training_data)
- 基于PySpark的Pipeline:
4. 推荐服务实现
- 离线推荐
- 每日凌晨运行PySpark批处理作业:
- 从Hive加载用户观看历史与视频特征。
- 训练ALS模型生成用户-视频推荐列表(Top-20)。
- 存储结果至Hive表
recommend.user_video_recs。
- 每日凌晨运行PySpark批处理作业:
- 实时推荐
- 监听用户当前观看视频的弹幕情感:
- 若积极弹幕占比 > 70%,推荐同分类高评分视频。
- 使用Redis缓存实时推荐结果,降低延迟。
- 监听用户当前观看视频的弹幕情感:
三、技术路线
- 开发环境配置
- 搭建Hadoop伪分布式集群(单节点模拟)。
- 配置PySpark环境(
PYSPARK_PYTHON=python3)。
- 核心代码模块
- 数据加载:
pythonfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName("DanmakuAnalysis").getOrCreate()df = spark.read.json("hdfs://namenode:9000/danmaku_data/*.json") - 情感分析:
python# 使用预训练BERT模型预测单条弹幕情感def predict_sentiment(text):inputs = tokenizer(text, return_tensors="pt", truncation=True)outputs = model(**inputs)return ["positive", "neutral", "negative"][outputs.logits.argmax()] - 推荐接口:
pythonfrom flask import Flask, jsonifyapp = Flask(__name__)@app.route("/recommend/<user_id>")def recommend(user_id):rec_df = spark.sql(f"SELECT * FROM recommend.user_video_recs WHERE user_id={user_id}")return jsonify(rec_df.collect())
- 数据加载:
- 可视化看板
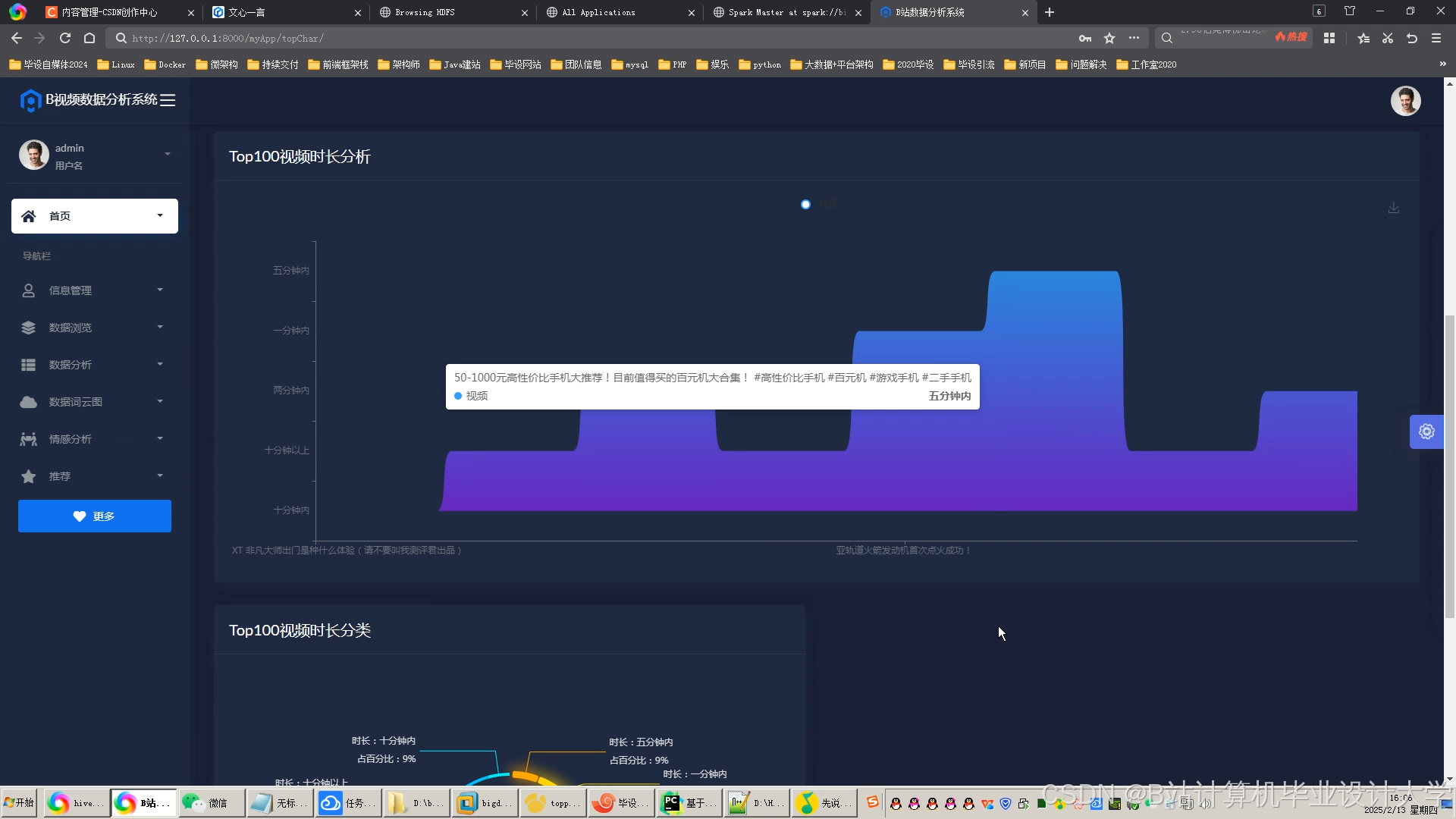
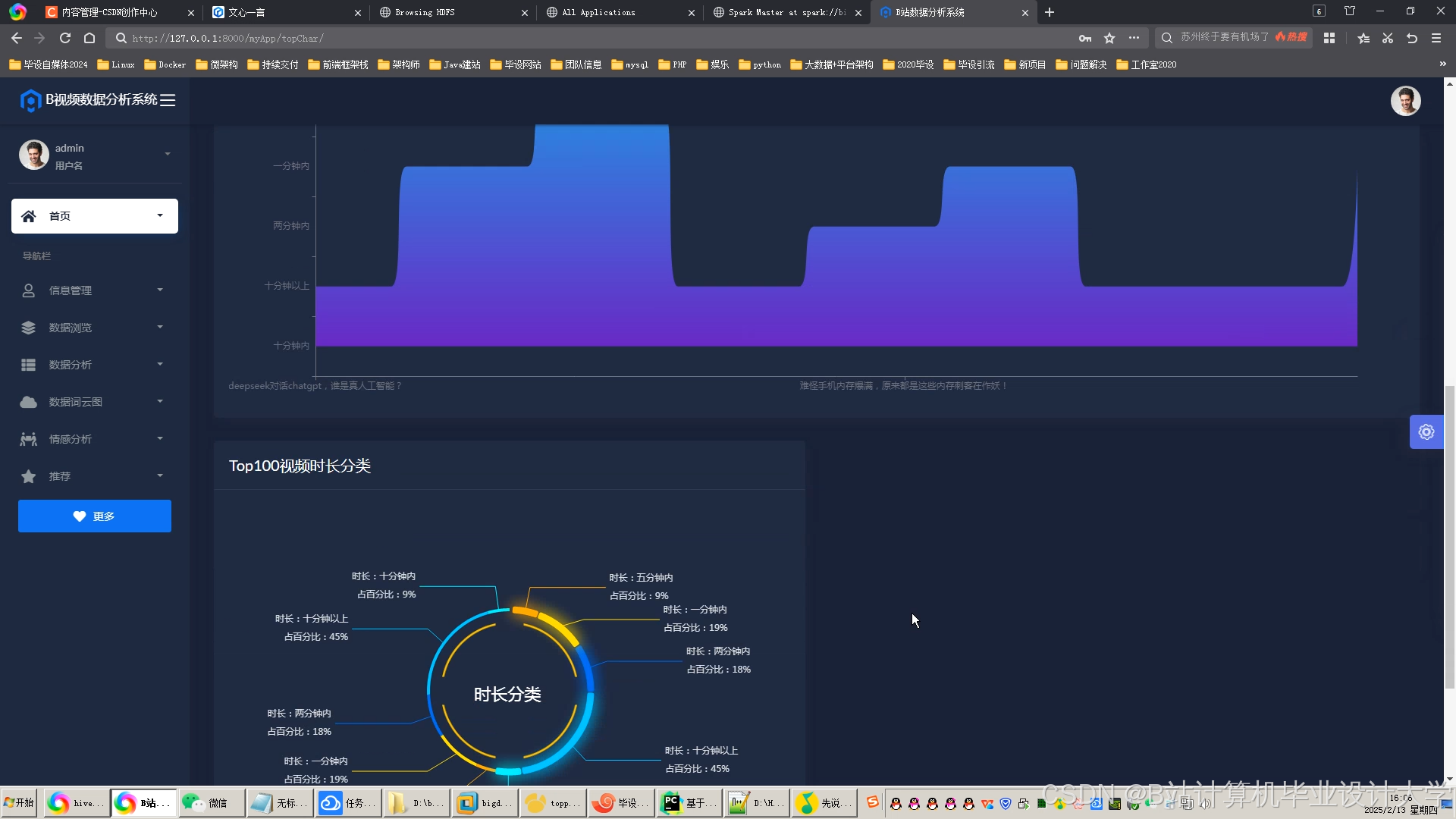
- 情感趋势图:按视频时间轴统计每分钟积极/消极弹幕数量。
- 推荐效果热力图:展示不同分类视频的推荐点击率(CTR)。
四、预期成果
- 系统部署包
- Hadoop/PySpark集群配置脚本。
- 推荐引擎Python脚本(
.py)与情感分析模型(.pkl/.h5)。
- 文档
- 技术设计文档(架构图、数据流、算法说明)。
- 用户手册(API调用示例、环境配置步骤)。
- 可视化看板
- Grafana链接或静态HTML报告(含情感趋势与推荐效果图表)。
五、时间计划
| 阶段 | 时间 | 任务内容 |
|---|---|---|
| 环境搭建 | 第1周 | 完成Hadoop/PySpark集群部署与基础测试 |
| 数据采集与存储 | 第2周 | 爬取视频/弹幕数据并导入HDFS/Hive |
| 特征工程 | 第3周 | 实现视频/弹幕特征提取与存储 |
| 情感分析模型 | 第4周 | 训练BERT/LogisticRegression情感分类模型 |
| 推荐算法开发 | 第5周 | 完成ALS协同过滤与内容过滤混合推荐 |
| 实时推荐优化 | 第6周 | 集成Redis缓存与弹幕情感实时触发推荐 |
| 系统测试与部署 | 第7周 | 压力测试、A/B测试、文档编写与可视化看板开发 |
六、资源需求
- 硬件
- 服务器:4核8G内存 × 3台(模拟集群)。
- 存储:HDFS建议至少500GB可用空间(弹幕数据量较大)。
- 数据
- 公开数据集:B站弹幕数据集(如Bilibili-Danmaku)。
- 软件
- Python库:PySpark 3.3+、Transformers 4.0+、Flask 2.0+。
- NLP模型:BERT中文预训练模型(
bert-base-chinese)。
七、风险评估与应对
- 弹幕情感分类准确率低
- 应对:结合规则引擎(如关键词匹配)与深度学习模型,提升召回率。
- 实时推荐延迟高
- 应对:优化Spark Streaming批处理间隔(如从1秒调整为5秒),减少资源竞争。
- 数据倾斜问题
- 应对:对热门视频的弹幕数据按用户ID哈希分片,均匀分配计算任务。
八、验收标准
- 情感分析指标:
- 准确率 ≥ 85%(对比人工标注测试集)。
- 推荐系统指标:
- 离线推荐生成时间 ≤ 3小时,实时推荐延迟 ≤ 1秒。
- 推荐点击率(CTR)较基准模型提升 ≥ 15%。
- 系统稳定性:
- 7×24小时运行无OOM或数据丢失,支持100+并发请求。
负责人:XXX
日期:XXXX年XX月XX日
可根据实际需求扩展功能(如加入图神经网络(GNN)分析视频关联性,或使用Flink替代Spark Streaming实现更低延迟推荐)。如需进一步细化某部分(如Hive表结构设计或BERT模型微调代码),可随时补充!
运行截图
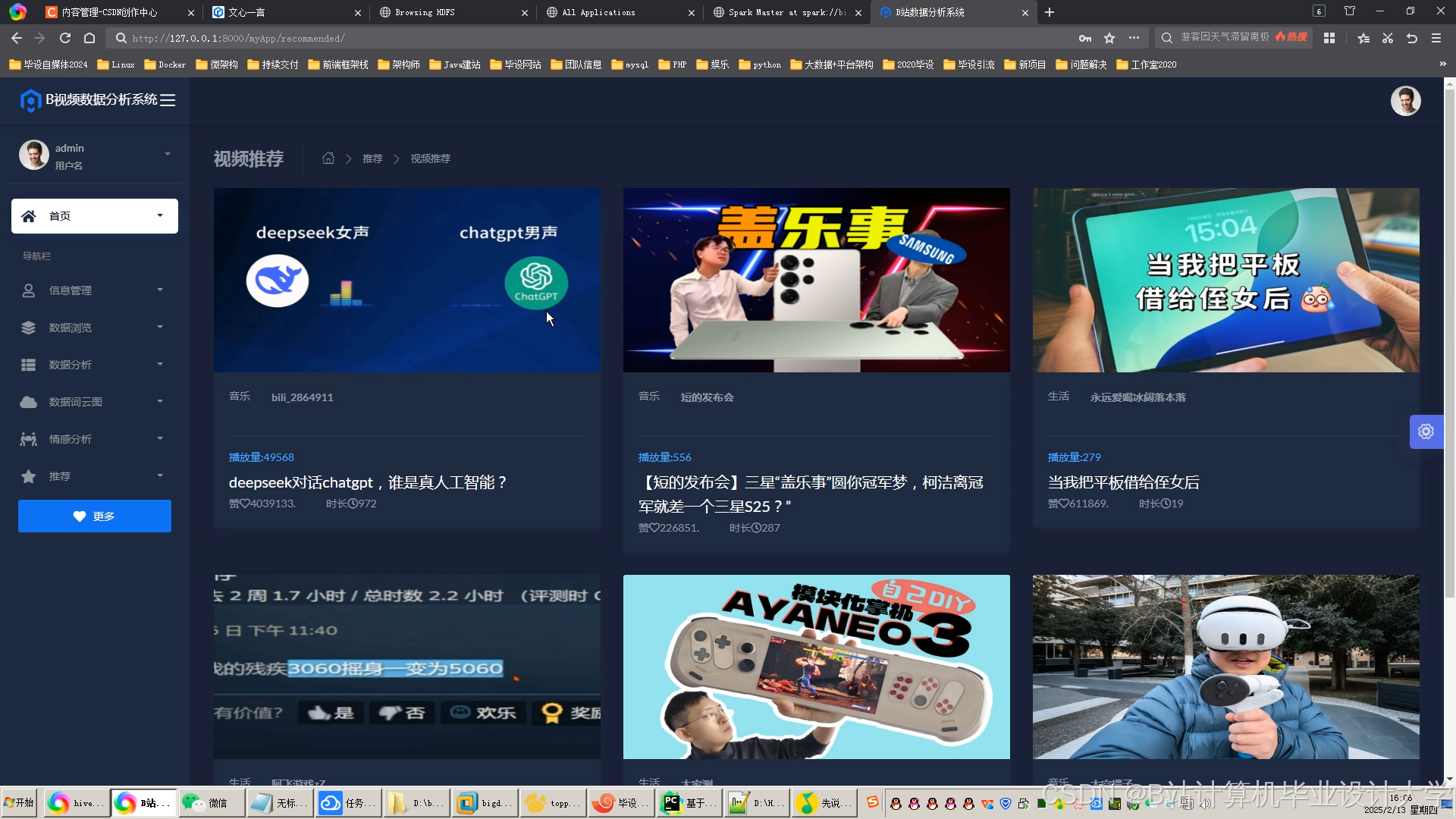
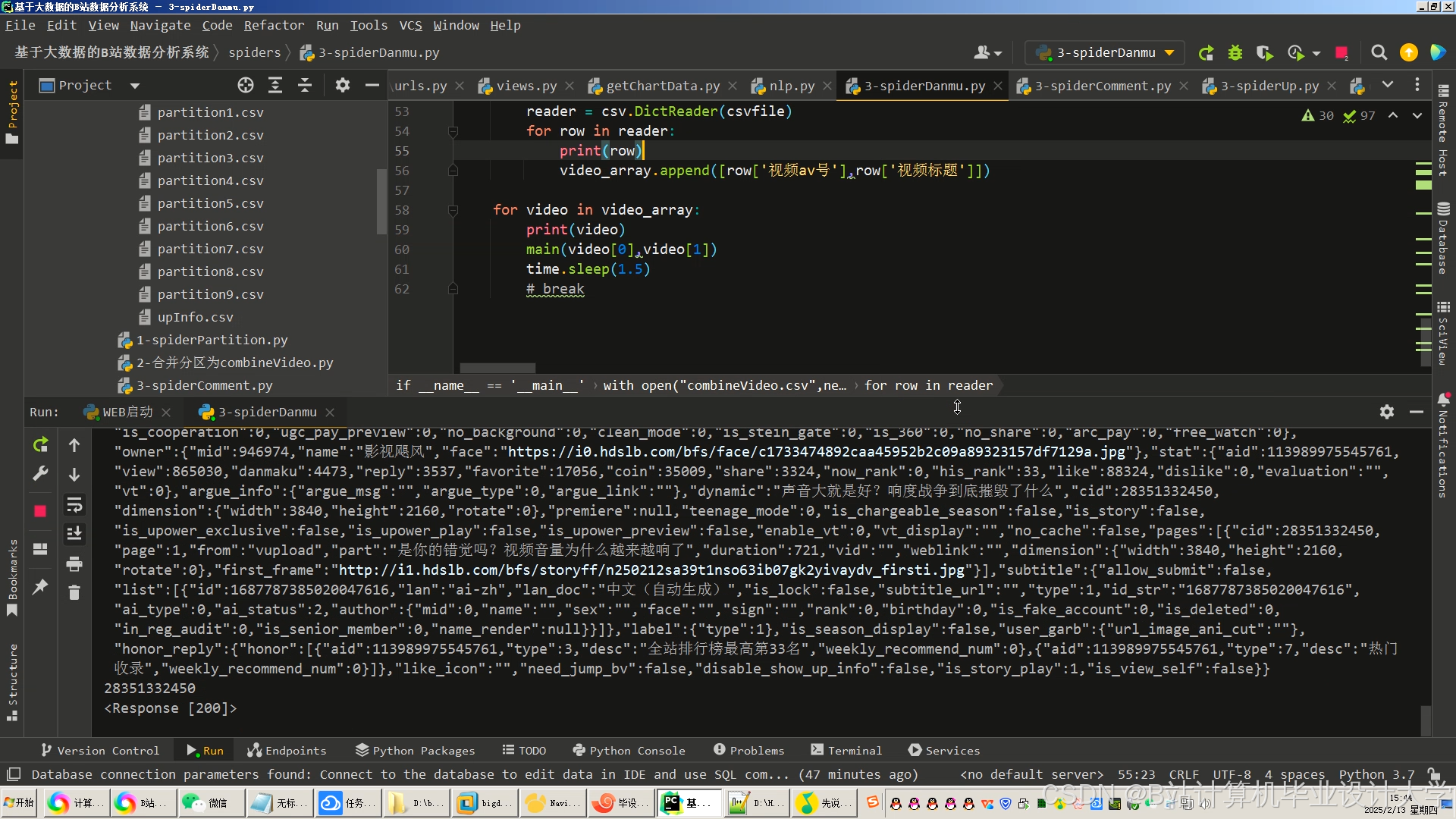
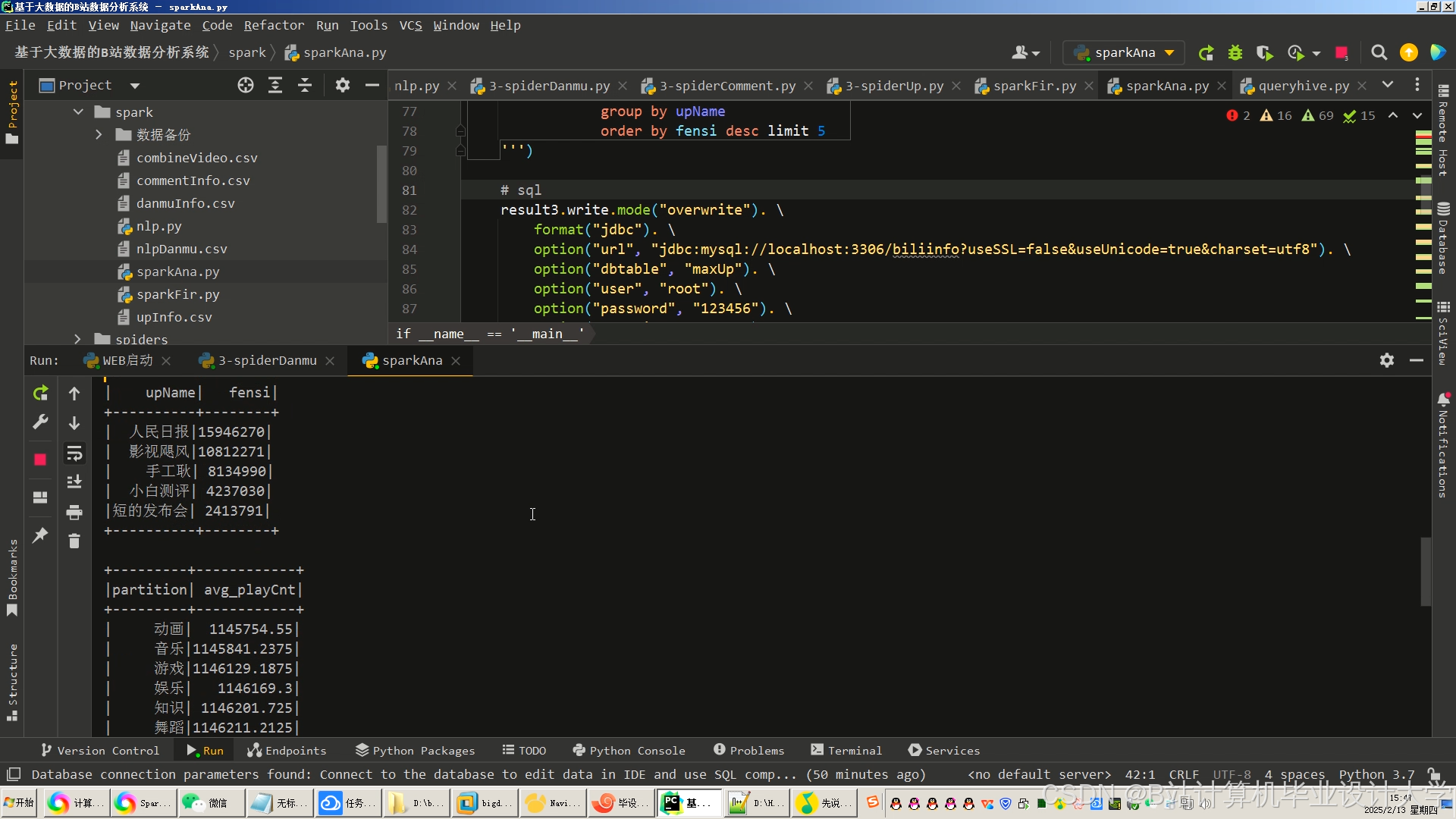
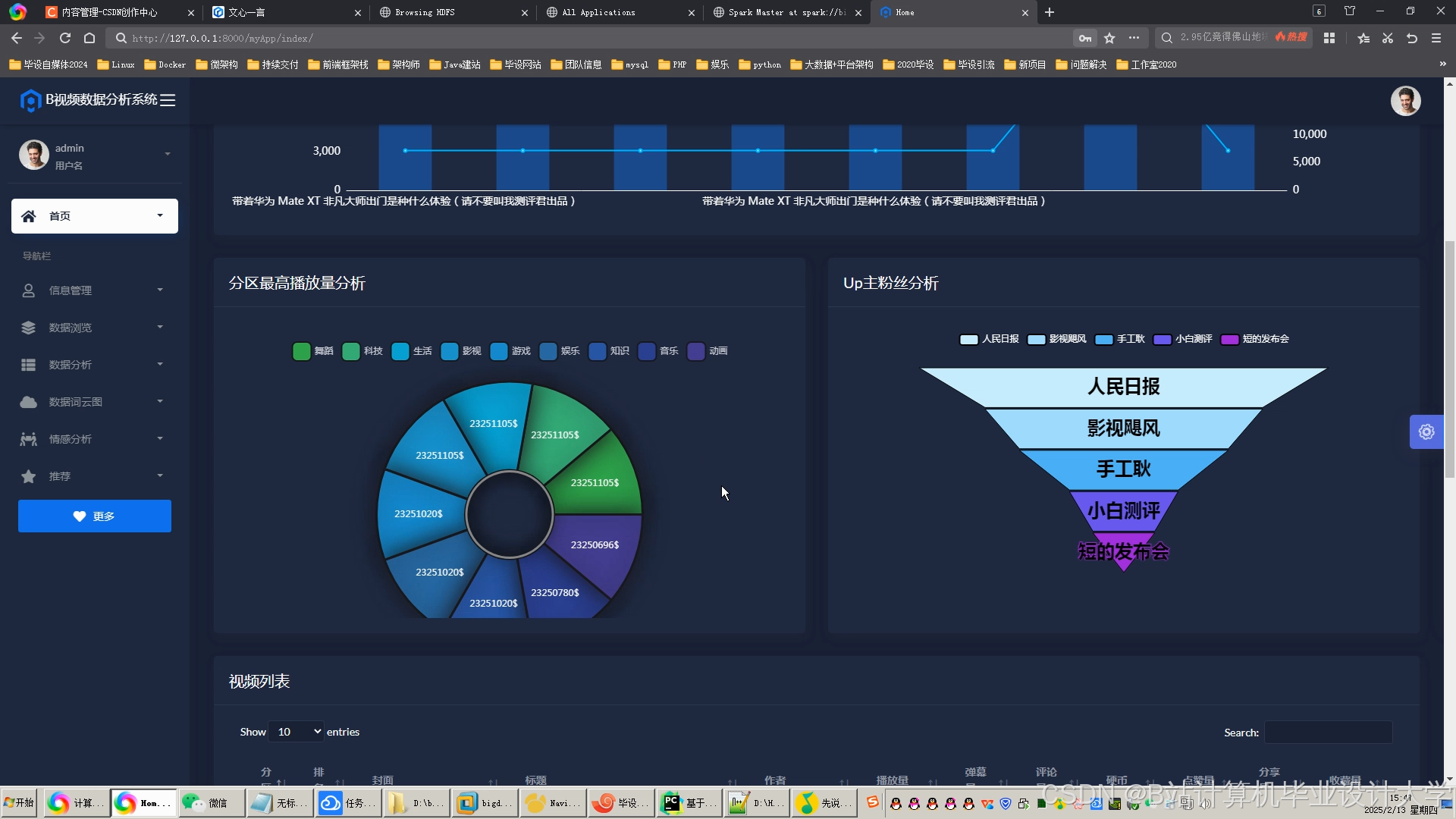
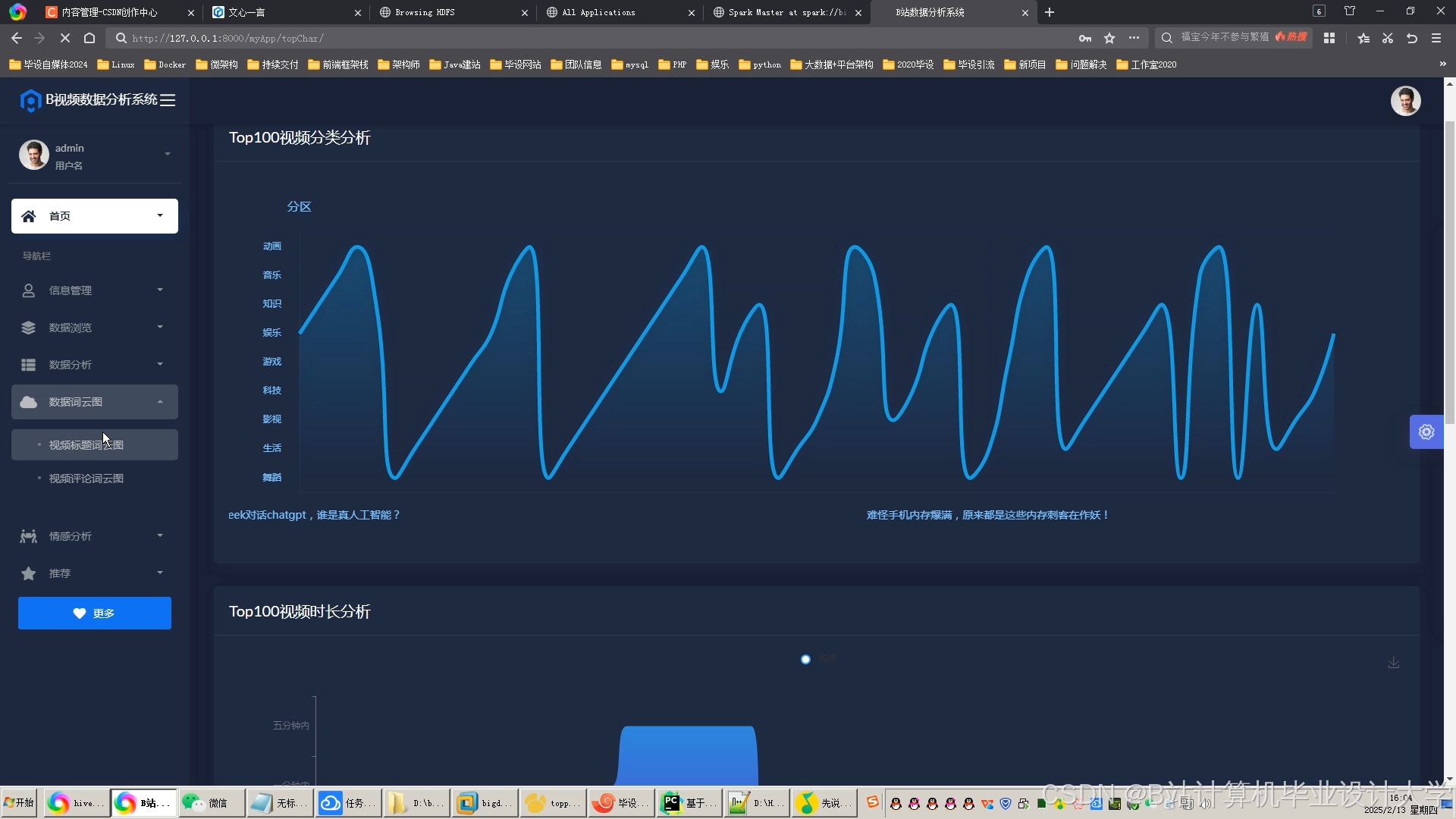
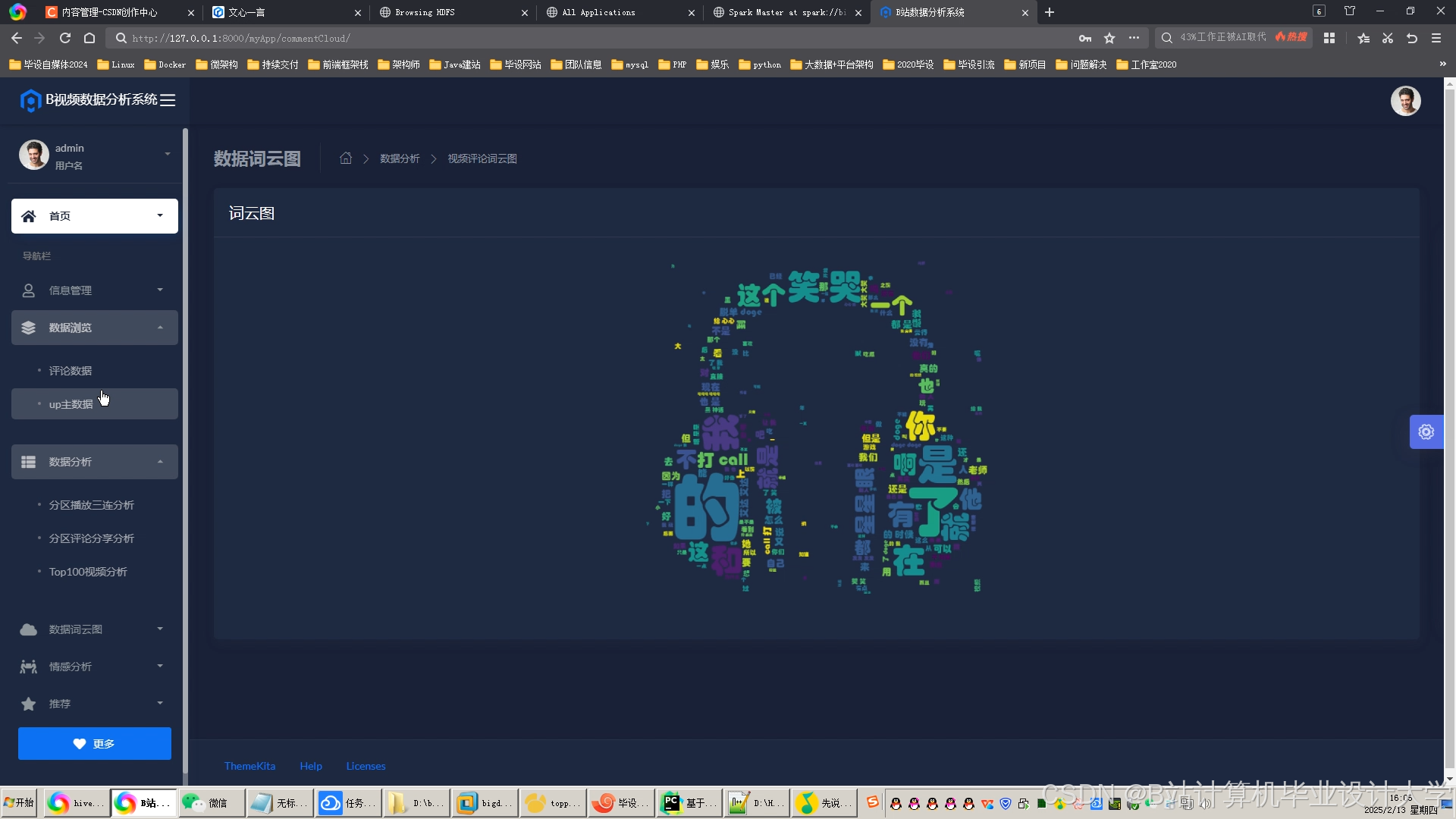
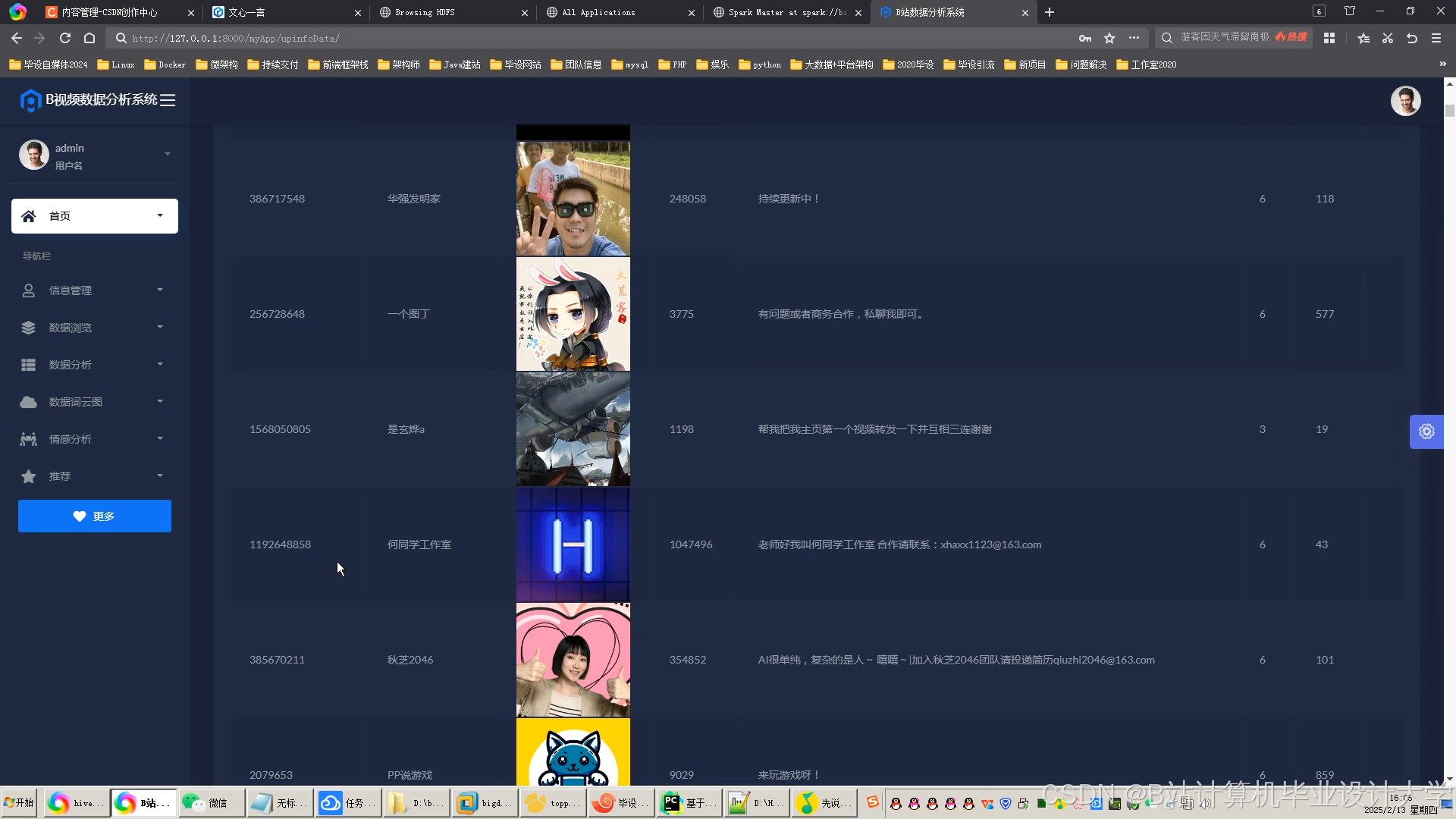
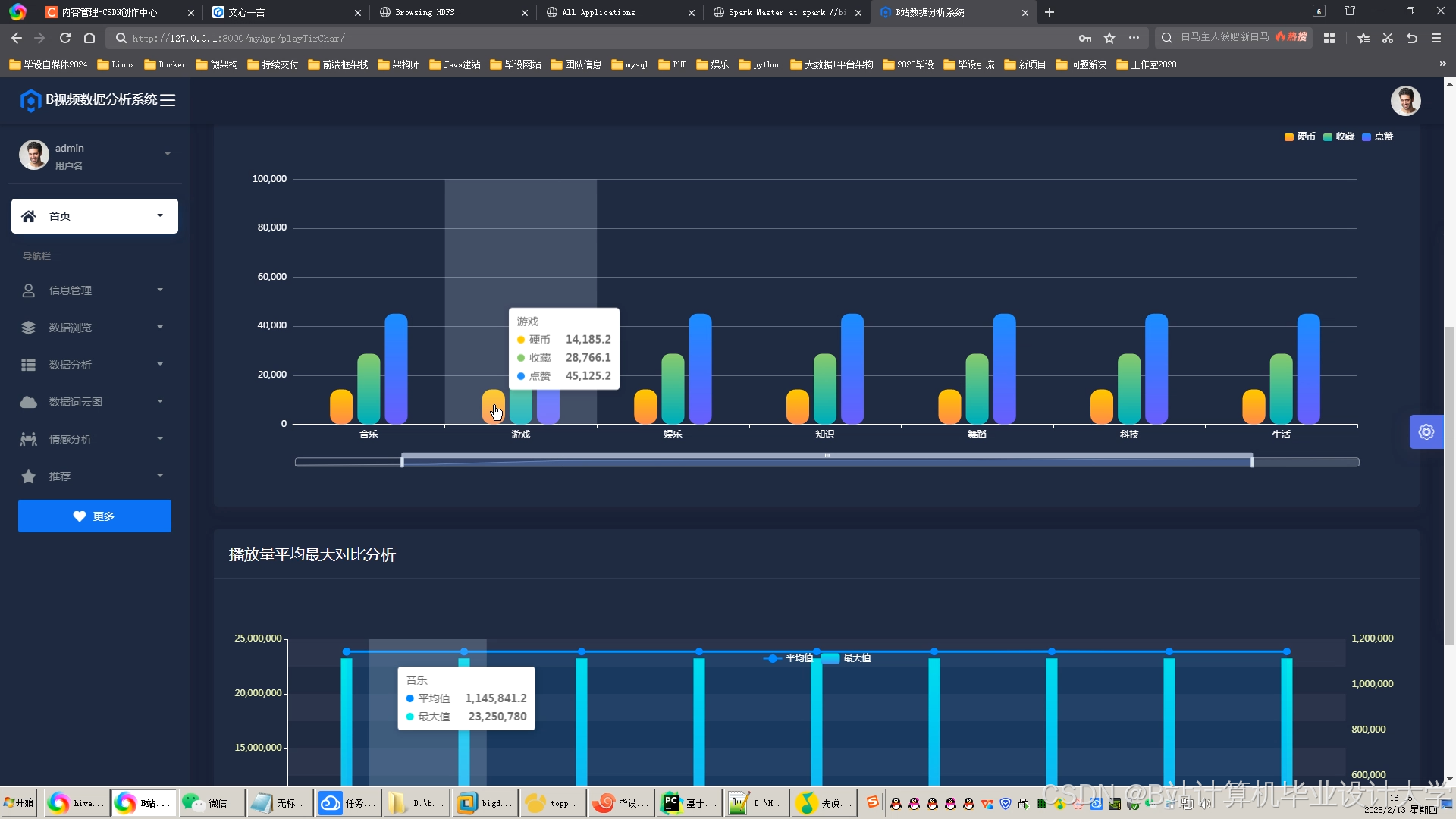
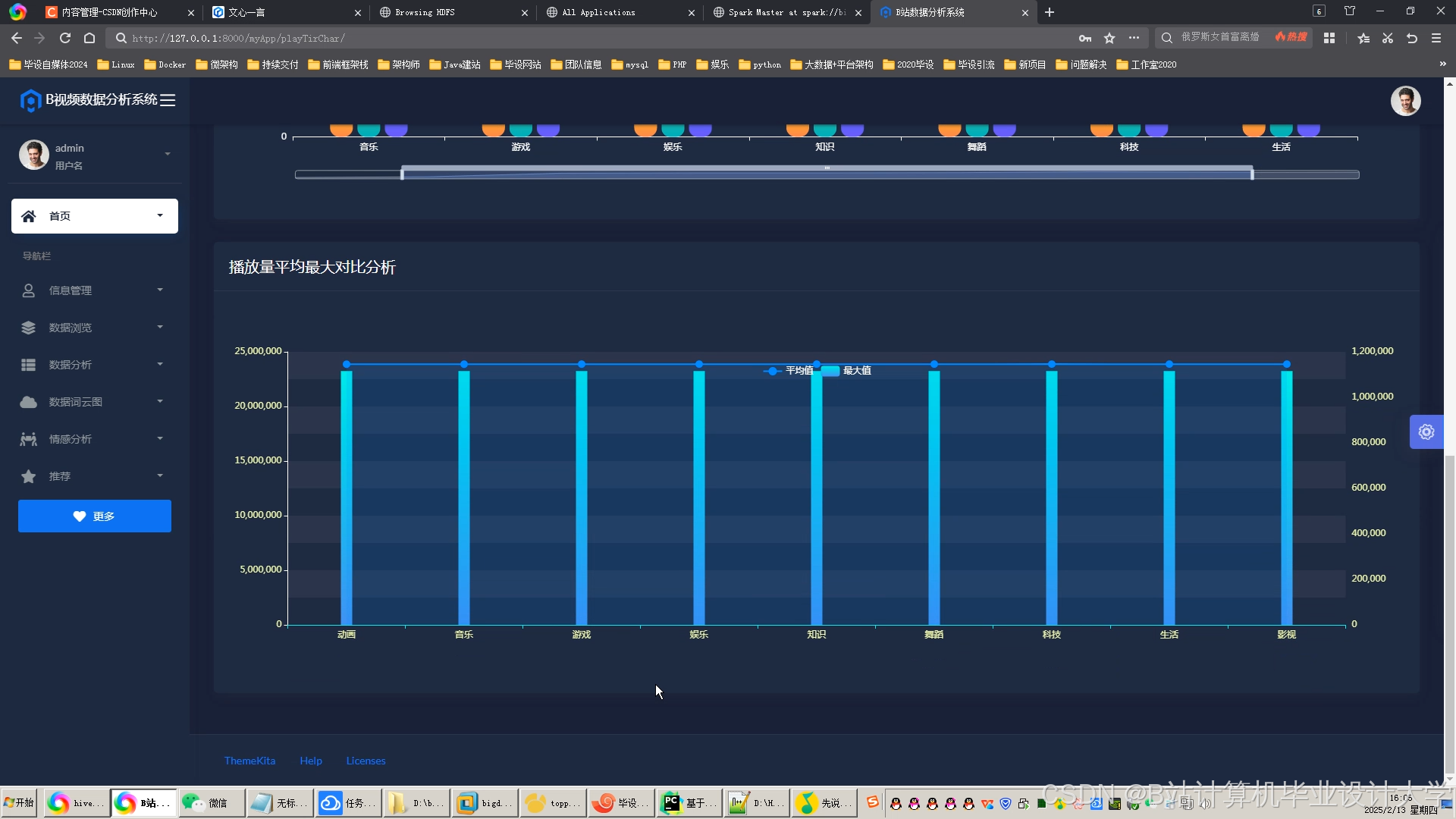
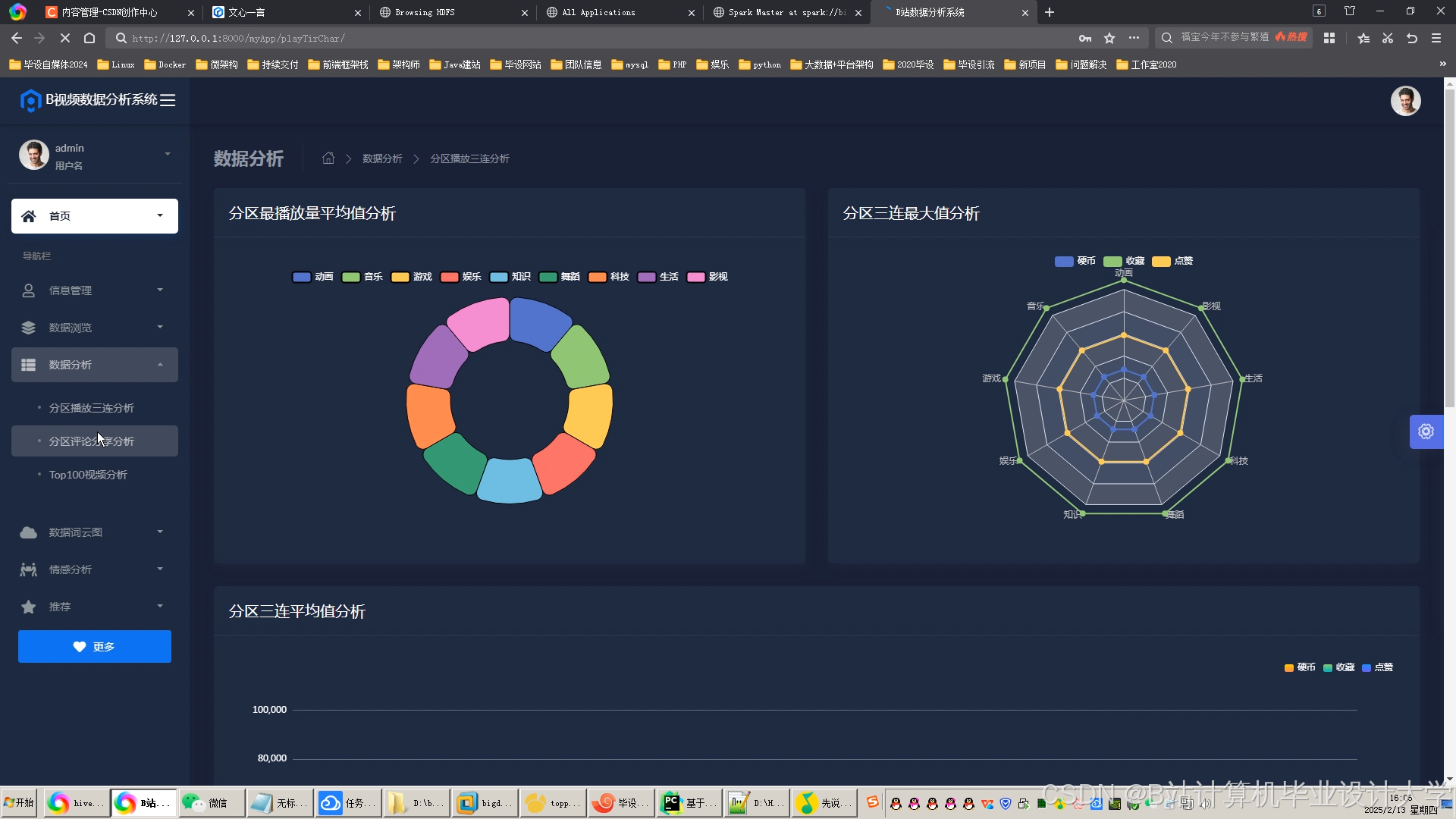
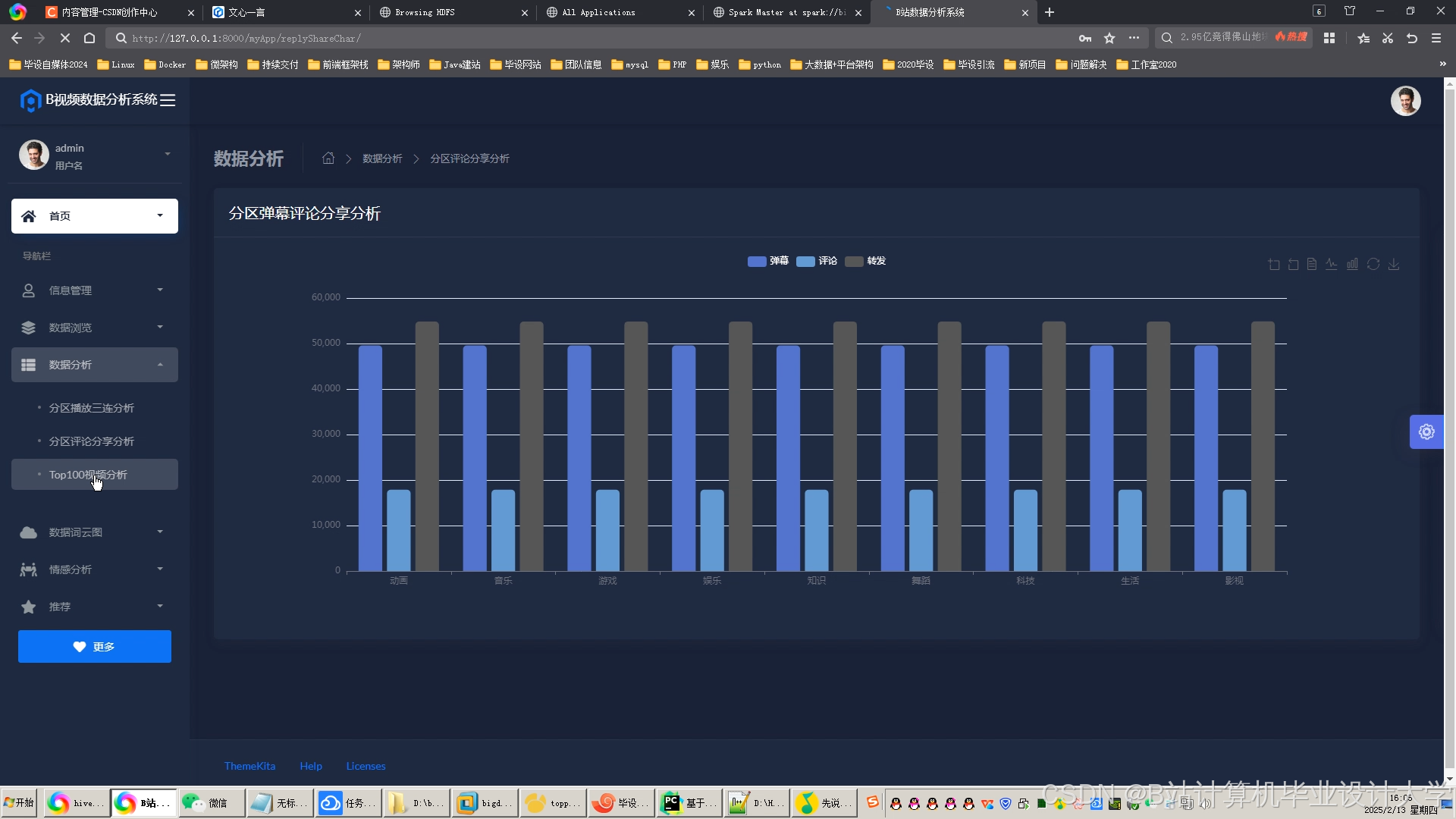
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











