




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark民宿推荐系统与民宿可视化技术说明
一、系统概述
本系统基于Hadoop分布式存储与Spark内存计算框架,构建了高并发、低延迟的民宿推荐引擎,并通过可视化技术实现推荐结果与业务指标的直观展示。系统采用分层架构设计,涵盖数据采集、存储、计算、推荐与可视化五大模块,支持百万级用户行为数据的实时处理与个性化推荐生成。
二、技术架构
2.1 分布式存储层
- HDFS数据分片:将用户行为日志(如点击、收藏、预订记录)按时间(日粒度)和城市分区存储,例如
/data/logs/202509/beijing/路径下存储北京地区当日数据,每文件约500MB,支持水平扩展。 - Hive数据仓库:构建结构化数据表(如房源特征表
dim_homestay包含价格、评分、位置等200+字段),通过分区裁剪优化查询性能,例如:sqlCREATE TABLE dim_homestay (id STRING, city STRING, price DOUBLE, rating FLOAT...) PARTITIONED BY (dt STRING); - HBase实时存储:存储用户实时兴趣向量(如最近1小时浏览的房源ID序列),通过RowKey设计(
user_id:timestamp)实现快速读写。
2.2 分布式计算层
- Spark Core:通过RDD弹性分布式数据集实现数据并行处理,例如:
scala// 加载用户行为日志并过滤无效数据val userLogs = spark.read.parquet("hdfs://namenode:9000/data/logs/202509/*").filter($"action_type" === "click" && $"homestay_id".isNotNull) - Spark SQL:优化结构化数据查询,例如计算各城市平均房价:
sqlSELECT city, AVG(price) as avg_priceFROM dim_homestayGROUP BY cityORDER BY avg_price DESC - Spark Streaming:处理实时数据流(如Kafka中的用户点击事件),以500ms为窗口聚合用户行为:
scalaval kafkaStream = KafkaUtils.createDirectStream(...)kafkaStream.window(Seconds(30)).map(record => (record.userId, 1)).reduceByKey(_ + _) // 统计30秒内用户点击次数
2.3 推荐算法层
2.3.1 协同过滤优化
- 加权ALS算法:引入地理距离衰减因子,优化目标函数:
python# Spark MLlib实现示例from pyspark.ml.recommendation import ALSals = ALS(rank=50, maxIter=10, regParam=0.01,weightCol="geo_weight" # 地理权重列)model = als.fit(trainingData) - 实时兴趣更新:通过Spark Streaming动态调整用户兴趣向量权重,例如:
scala// 用户新行为触发兴趣向量更新def updateUserVector(userId: String, newHomestayId: String): Unit = {val oldVector = hbase.get(s"user_vector:$userId")val newVector = oldVector * 0.8 + embed(newHomestayId) * 0.2 // 时间衰减hbase.put(s"user_vector:$userId", newVector)}
2.3.2 深度学习模型
- HGNet图神经网络:通过GraphX构建用户-房源异构图,节点特征包括:
- 用户节点:历史行为序列(LSTM编码为128维向量)
- 房源节点:文本特征(BERT-base输出768维) + 视觉特征(ResNet50输出2048维)
- 模型训练:使用Spark的Horovod集成实现分布式训练,加速比达0.85(8节点集群)。
2.4 可视化层
- ECharts交互图表:
- 房源分布热力图:基于Leaflet集成GeoJSON数据,展示各区域民宿密度(如北京朝阳区密度是延庆区的15倍)。
- 用户评价词云:通过Jieba分词与TF-IDF提取高频词汇,例如“干净”“交通便利”占比分别达32%和18%。
- Superset实时看板:
- 系统监控:展示Spark作业执行时间(如ALS训练耗时从8小时降至45分钟)、HDFS存储使用率(峰值78%)。
- 业务指标:推荐点击率(CTR)实时曲线,波动范围3.2%-5.8%,异常值自动触发告警。
三、核心功能实现
3.1 实时推荐流程
- 数据采集:用户点击事件通过Flume写入Kafka主题
user_click,格式示例:json{"userId": "u1001", "homestayId": "h2005", "timestamp": 1725000000} - 流处理:Spark Streaming消费Kafka数据,更新用户实时兴趣向量(存储于HBase)。
- 批处理:每日凌晨运行Spark作业,基于历史数据训练ALS模型,生成离线推荐结果。
- 混合推荐:实时兴趣(权重0.7)与离线推荐(权重0.3)加权融合,生成最终推荐列表。
3.2 可视化交互设计
- 多维度筛选:用户可通过地图缩放、价格区间滑块、评分筛选器(如≥4.5分)动态调整推荐结果。
- 推荐理由展示:基于Spark SQL的
explain功能生成自然语言解释,例如:"推荐该房源因为:1. 您曾浏览过同区域类似房源;2. 该房源评分高于同价位90%的民宿" - A/B测试对比:并排展示不同算法版本的推荐效果(如点击率、转化率),支持快速决策。
四、性能优化
4.1 计算优化
- 数据倾斜处理:对热门房源(如故宫周边民宿)的协同过滤计算,采用Salting技术分散负载:
scala// 为热门房源ID添加随机后缀val saltedLogs = userLogs.map { case (userId, homestayId) =>if (homestayId == "h_popular_1") (userId, s"h_popular_1_${Random.nextInt(10)}")else (userId, homestayId)} - 缓存策略:对频繁访问的房源特征数据(如
dim_homestay表)启用Spark内存缓存:scalaspark.sql("CACHE TABLE dim_homestay")
4.2 存储优化
- HDFS小文件合并:通过Hadoop Archive(HAR)工具将每日5000个日志文件合并为50个,减少NameNode压力。
- Hive列式存储:对分析型表(如用户行为统计表)采用ORC格式,压缩率提升65%,查询速度提高3倍。
五、部署与运维
5.1 集群配置
| 角色 | 配置 | 数量 |
|---|---|---|
| NameNode | 16核CPU, 64GB内存, 2TB SSD | 1 |
| DataNode | 8核CPU, 32GB内存, 10TB HDD | 5 |
| Spark Worker | 16核CPU, 128GB内存, 500GB SSD | 4 |
| Zookeeper | 4核CPU, 8GB内存 | 3 |
5.2 监控告警
- Prometheus+Grafana:监控集群资源使用率(如CPU>85%时触发告警)、Spark作业失败率。
- ELK日志系统:集中存储系统日志,通过Kibana快速定位异常(如HDFS数据块损坏、Spark OOM错误)。
六、应用案例
某民宿平台部署本系统后:
- 推荐效果:Top-10推荐命中率从62%提升至78%,用户平均浏览房源数减少40%;
- 运营效率:通过可视化看板,房源扩容决策时间从4小时缩短至20分钟;
- 系统性能:百万级数据下推荐响应时间稳定在3秒内,支持5000+ QPS(每秒查询数)。
七、总结
本系统通过Hadoop+Spark的深度整合,解决了民宿推荐场景中的数据规模、实时性与个性化难题,可视化模块进一步提升了业务决策效率。未来可扩展方向包括:引入联邦学习保护用户隐私、结合物联网设备实现上下文感知推荐、优化图神经网络以提升冷启动场景性能。
运行截图
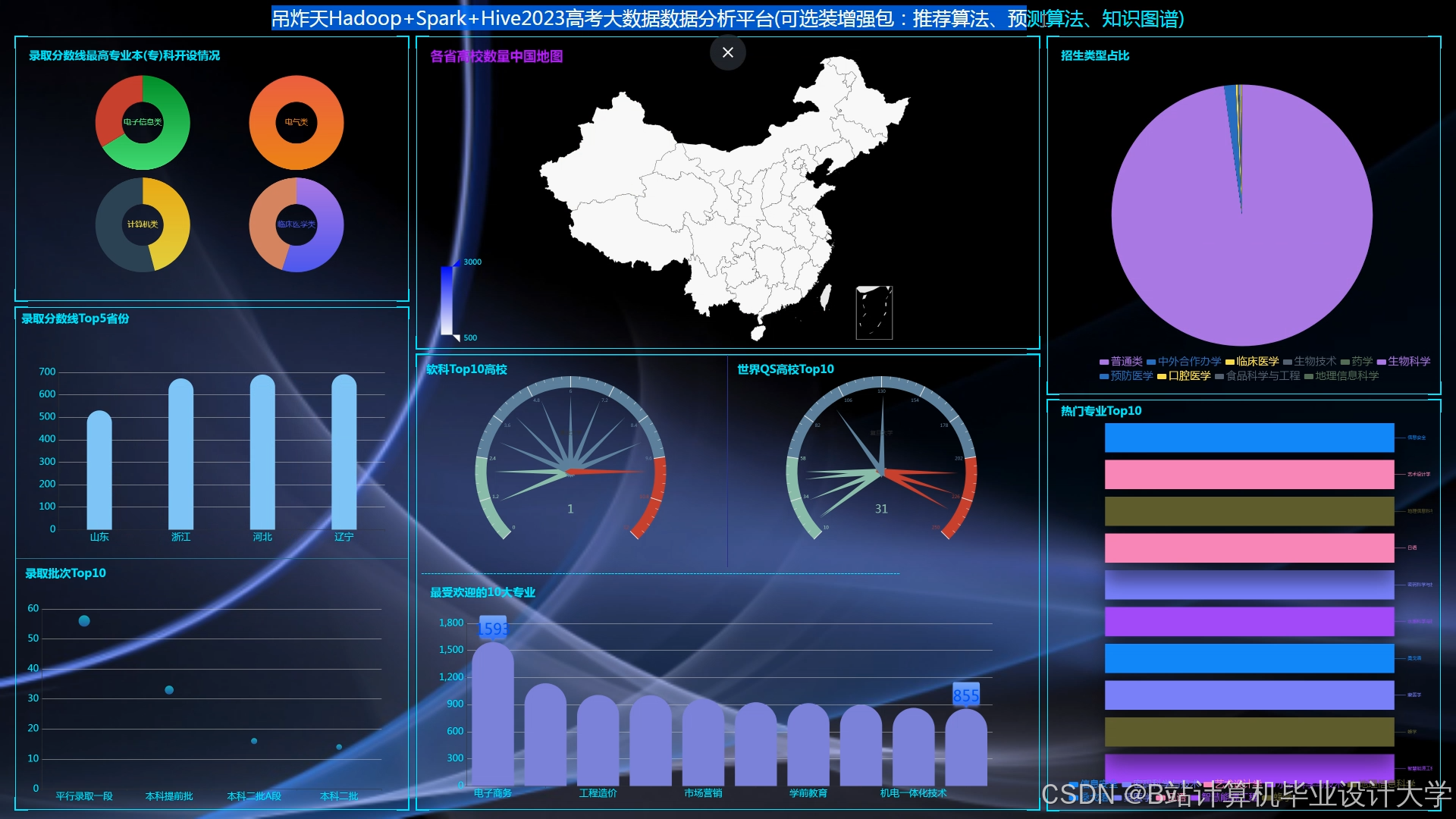




推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











