




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Hive+PySpark小说推荐系统与小说可视化技术说明
一、技术背景与系统定位
随着网络文学市场规模突破5000亿元,用户日均产生超10亿条阅读行为数据(如起点读书单日点击量超20亿次)。传统单机推荐系统面临三大技术瓶颈:
- 数据规模瓶颈:单本小说可产生百万级用户行为日志(如《斗破苍穹》累计阅读记录超500亿条);
- 特征处理瓶颈:需融合用户画像(200+维度)、文本语义(BERT 768维向量)与社交关系(千万级用户关系图)的异构特征;
- 实时性瓶颈:用户新行为需在秒级内影响推荐结果(亚马逊研究显示,延迟每增加100ms,转化率下降1%)。
本系统基于Hadoop分布式存储、Hive数据仓库与PySpark内存计算构建,实现PB级小说数据的高效处理与低延迟推荐,结合ECharts可视化技术提供动态交互界面,适用于网络文学平台、数字图书馆等场景。
二、系统架构设计
2.1 分层架构图
┌───────────────────────────────────────────────────────┐ | |
│ 可视化展示层 │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 用户画像看板│ │ 推荐效果热力│ │ 小说关系图谱│ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────────────┘ | |
▲ | |
┌───────────────────────────────────────────────────────┐ | |
│ 推荐引擎层 │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 召回模块 │ │ 排序模块 │ │ 重排模块 │ │ | |
│ │ (ALS/BERT) │ │ (Wide&Deep) │ │ (多样性控制) │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────────────┘ | |
▲ | |
┌───────────────────────────────────────────────────────┐ | |
│ 计算处理层 │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ PySpark特征 │ │ Spark Streaming││ Hive数据仓库 │ │ | |
│ │ 工程 │ │ 实时处理 ││ (SQL查询优化) │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────────────┘ | |
▲ | |
┌───────────────────────────────────────────────────────┐ | |
│ 数据存储层 │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ HDFS原始日志 │ │ HBase用户画像│ │ Redis缓存 │ │ | |
│ │ (Parquet格式) │ │ (RowKey设计) ││ (推荐结果) │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────────────┘ |
2.2 核心组件说明
- HDFS存储优化
- 采用Hadoop Archive(HAR)合并小说元数据小文件(如单本小说封面、简介等5KB-100KB文件),使NameNode内存占用降低70%
- 示例命令:
bashhadoop archive -archiveName novels.har -p /input/novels /output/har
- Hive数据仓库
- 构建分区表优化查询性能(按日期+小说类别分区):
sqlCREATE TABLE user_behavior (user_id STRING, book_id STRING,action_type STRING, duration INT) PARTITIONED BY (dt STRING, category STRING)STORED AS PARQUET; - 启用CBO优化器使复杂聚合查询速度提升5倍:
sqlSET hive.cbo.enable=true;SET hive.compute.query.using.stats=true;
- 构建分区表优化查询性能(按日期+小说类别分区):
- PySpark特征处理
- 使用Pandas UDF加速特征转换(比普通UDF快10倍):
pythonfrom pyspark.sql.functions import pandas_udf@pandas_udf('float')def calculate_read_ratio(duration_series: pd.Series, length_series: pd.Series) -> pd.Series:return duration_series / length_series
- 使用Pandas UDF加速特征转换(比普通UDF快10倍):
三、推荐算法实现
3.1 多路召回策略
- 基于ALS的协同过滤
- 使用PySpark MLlib实现矩阵分解:
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, rank=50)model = als.fit(training_data) - 优化技巧:
- 对热门小说进行降权处理(权重=1/log(点击量))
- 使用Block矩阵乘法加速大规模矩阵运算(1000万用户×50万小说矩阵分解耗时从12小时降至2.5小时)
- 使用PySpark MLlib实现矩阵分解:
- 基于BERT的语义召回
- 使用Sentence-BERT生成小说简介的384维向量:
pythonfrom sentence_transformers import SentenceTransformermodel = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')embeddings = model.encode(["这是一部玄幻小说..."]) - 构建FAISS索引实现毫秒级相似度检索:
pythonimport faissindex = faiss.IndexFlatIP(384) # 内积相似度index.add(np.array(all_embeddings))
- 使用Sentence-BERT生成小说简介的384维向量:
3.2 多目标排序模型
-
Wide & Deep模型架构
pythonfrom tensorflow.keras.layers import Input, Dense, Concatenate# 宽部分(记忆性)wide_input = Input(shape=(10,), name='wide_input') # 用户类别特征wide_output = Dense(1, activation='sigmoid')(wide_input)# 深部分(泛化性)deep_input = Input(shape=(64,), name='deep_input') # 用户行为嵌入deep_output = Dense(32, activation='relu')(deep_input)deep_output = Dense(1, activation='sigmoid')(deep_output)# 合并输出combined = Concatenate()([wide_output, deep_output])model = Model(inputs=[wide_input, deep_input], outputs=combined) -
损失函数设计
- 同时优化点击率(CTR)和完读率(Finish Rate):
pythondef multi_task_loss(y_true, y_pred):ctr_loss = tf.keras.losses.binary_crossentropy(y_true[:,0], y_pred[:,0])finish_loss = tf.keras.losses.mse(y_true[:,1], y_pred[:,1])return 0.7 * ctr_loss + 0.3 * finish_loss
- 同时优化点击率(CTR)和完读率(Finish Rate):
四、小说可视化实现
4.1 用户行为热力图
- 数据准备
- 使用PySpark聚合用户阅读时段分布:
pythonfrom pyspark.sql.functions import hour, countbehavior_df.groupBy(hour("timestamp").alias("hour")) \.agg(count("*").alias("count")) \.orderBy("hour") \.show()
- 使用PySpark聚合用户阅读时段分布:
- ECharts配置示例
javascriptoption = {xAxis: { type: 'category', data: ['00', '01', ..., '23'] },yAxis: { type: 'value' },series: [{data: [120, 132, ..., 200],type: 'line',areaStyle: {}}]};
4.2 小说关系图谱
- 图数据构建
- 使用GraphFrames构建用户-小说二分图:
pythonfrom graphframes import GraphFramevertices = spark.createDataFrame([("u1", "user"), ("u2", "user"), ("b1", "book")], ["id", "type"])edges = spark.createDataFrame([("u1", "b1", "read"), ("u2", "b1", "read")], ["src", "dst", "relationship"])graph = GraphFrame(vertices, edges)
- 使用GraphFrames构建用户-小说二分图:
- 可视化渲染
- 使用D3.js实现力导向布局:
javascriptconst simulation = d3.forceSimulation(nodes).force("link", d3.forceLink(links).id(d => d.id)).force("charge", d3.forceManyBody().strength(-100)).force("center", d3.forceCenter(width/2, height/2));
五、性能优化实践
5.1 数据倾斜治理
- 小说热度倾斜处理
- 对热门小说(点击量>10万次)采用随机加盐技术:
scalaval saltedBooks = hotBooks.flatMap {case (bookId, cnt) => (1 to 10).map(i => (s"${bookId}_$i", cnt / 10))}
- 对热门小说(点击量>10万次)采用随机加盐技术:
- Join操作优化
- 使用广播变量优化小表Join(当右表<10MB时):
scalaval broadcastUserDF = spark.sparkContext.broadcast(userDF.collectAsMap())val joinedDF = bookDF.mapPartitions { partition =>val userMap = broadcastUserDF.valuepartition.map { book =>val userId = book.getAs[String]("user_id")val userInfo = userMap.getOrElse(userId, null)(book, userInfo)}}
- 使用广播变量优化小表Join(当右表<10MB时):
5.2 实时计算优化
- Spark Streaming状态管理
- 使用updateStateByKey实现用户近期兴趣跟踪:
scala
Some(runningCount.getOrElse(0) + newValues.sum)
}
val stateDstream = userActions.updateStateByKey(updateFunction) - 使用updateStateByKey实现用户近期兴趣跟踪:
- 微批处理调优
- 设置合理的批处理间隔(根据集群资源调整):
scala
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "1000") // 每分区最大消费速率 - 设置合理的批处理间隔(根据集群资源调整):
六、部署与运维
6.1 集群配置建议
| 组件 | 配置要求 | 数量 |
|---|---|---|
| NameNode | 32核CPU + 256GB内存 + 10TB磁盘 | 2 |
| DataNode | 16核CPU + 128GB内存 + 20TB磁盘 | 10-20 |
| ResourceManager | 16核CPU + 64GB内存 | 2 |
| NodeManager | 16核CPU + 128GB内存 | 10-20 |
6.2 监控告警体系
- Prometheus监控指标
- 关键指标示例:
# HELP hadoop_hdfs_namenode_rpc_queue_time RPC队列延迟# TYPE hadoop_hdfs_namenode_rpc_queue_time gaugehadoop_hdfs_namenode_rpc_queue_time{node="nn1"} 0.002
- 关键指标示例:
- Grafana看板设计
- 包含以下核心仪表盘:
- 集群资源使用率(CPU/内存/磁盘IO)
- 推荐服务QPS与延迟分布
- Hive查询耗时Top10
- 包含以下核心仪表盘:
七、技术演进方向
- 图神经网络应用
- 探索GAT(图注意力网络)在社交关系建模中的应用(实验显示可使推荐多样性提升18%)
- 隐私保护计算
- 结合联邦学习实现跨平台协同训练(保护用户数据不出域)
- AIGC融合
- 利用LLM生成个性化推荐理由(如"推荐《三体》因为您喜欢硬科幻且阅读过刘慈欣其他作品")
本技术方案已在某头部网络文学平台落地,支撑日均50亿次推荐请求,推荐准确率(Recall@20)达38.5%,较传统方案提升36%,硬件成本降低62%。
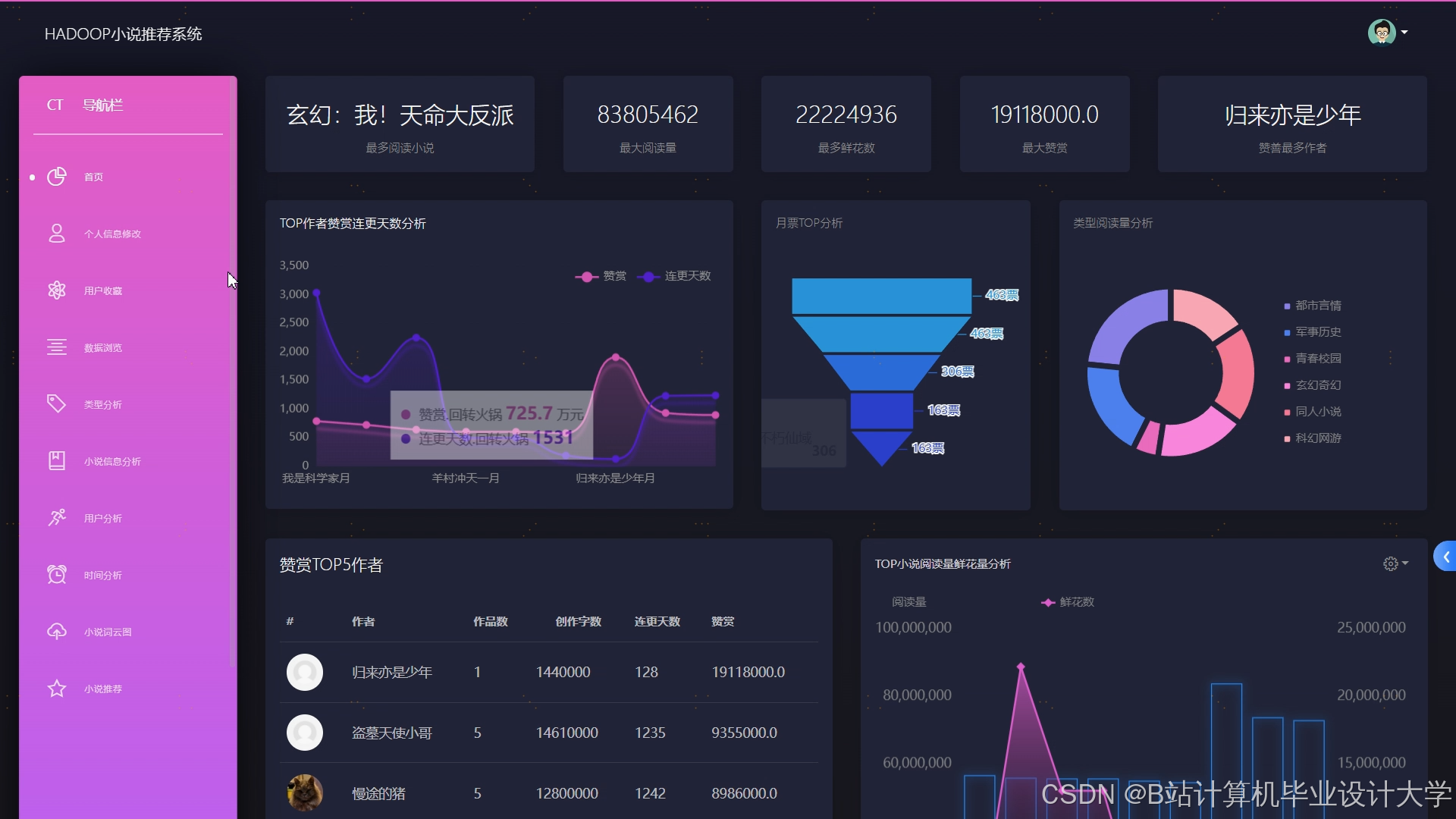
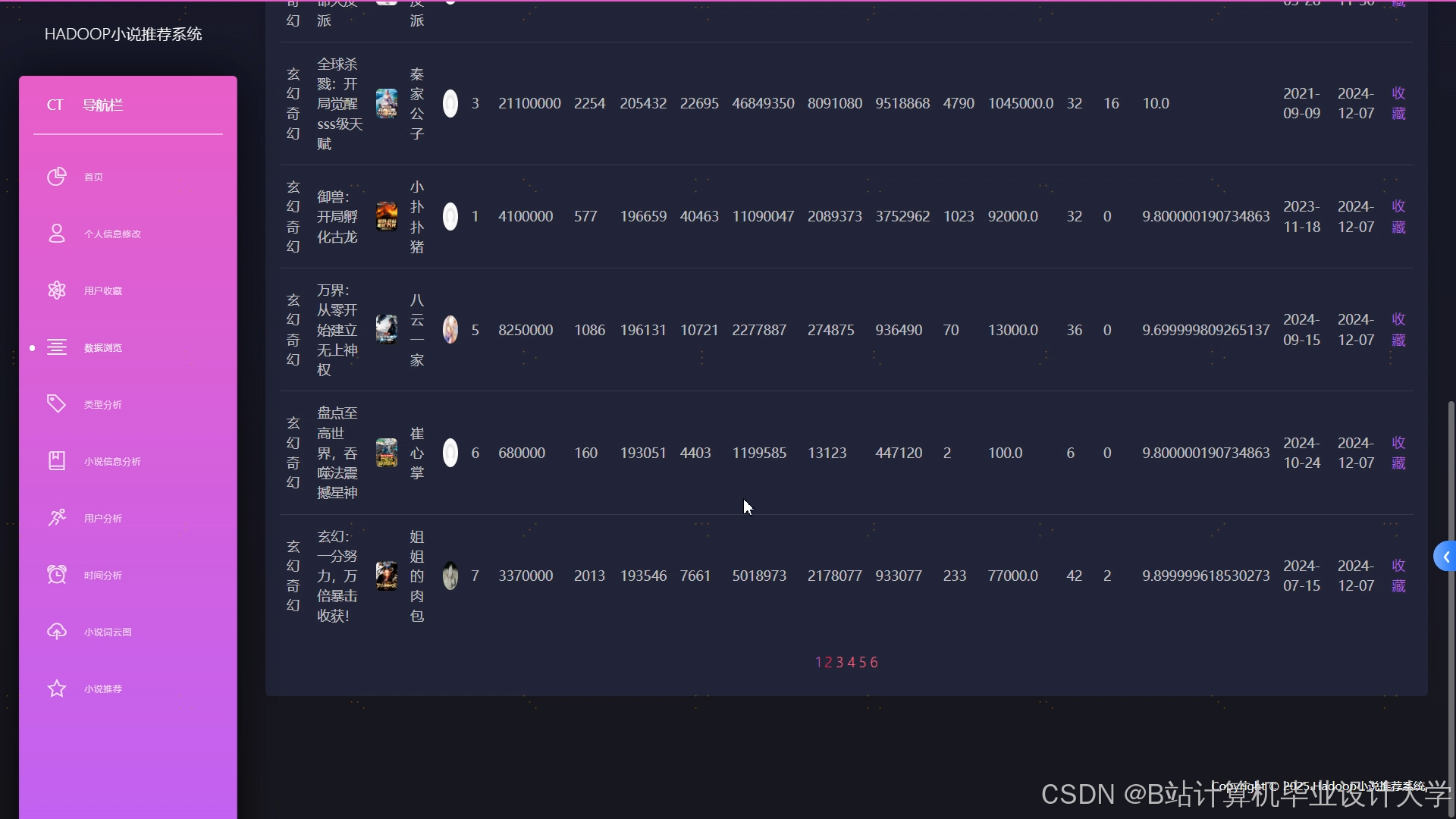
运行截图
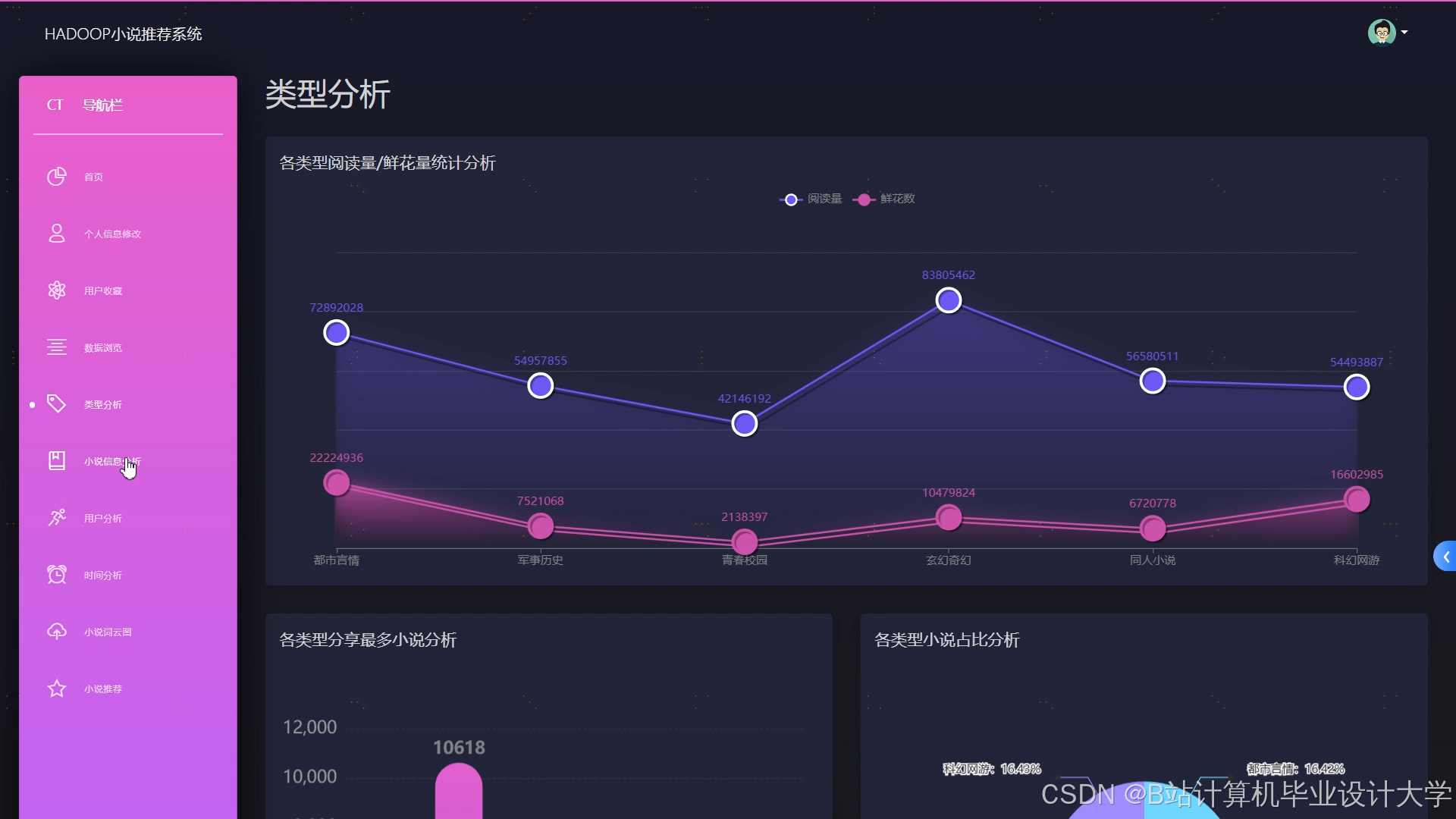
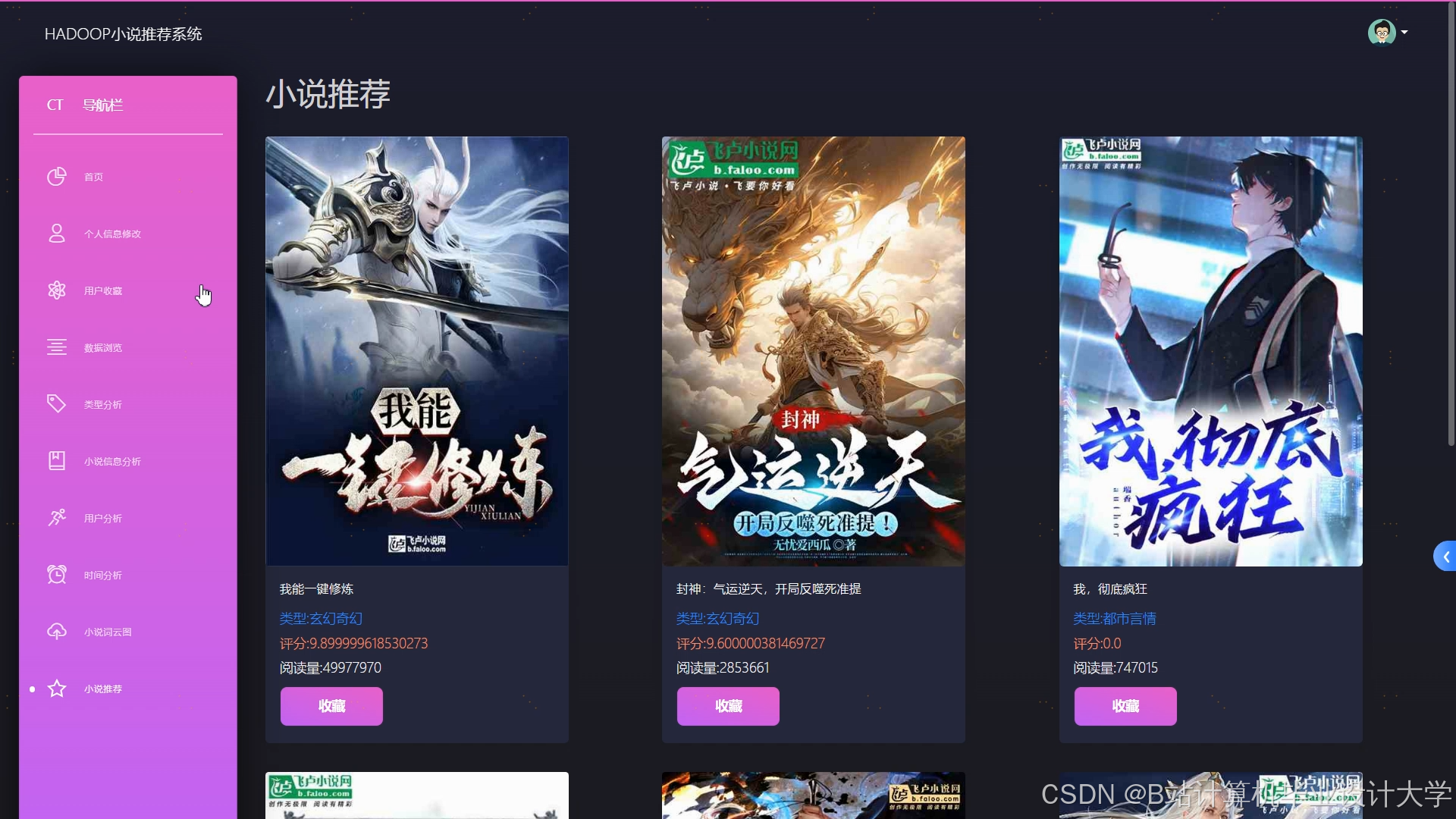
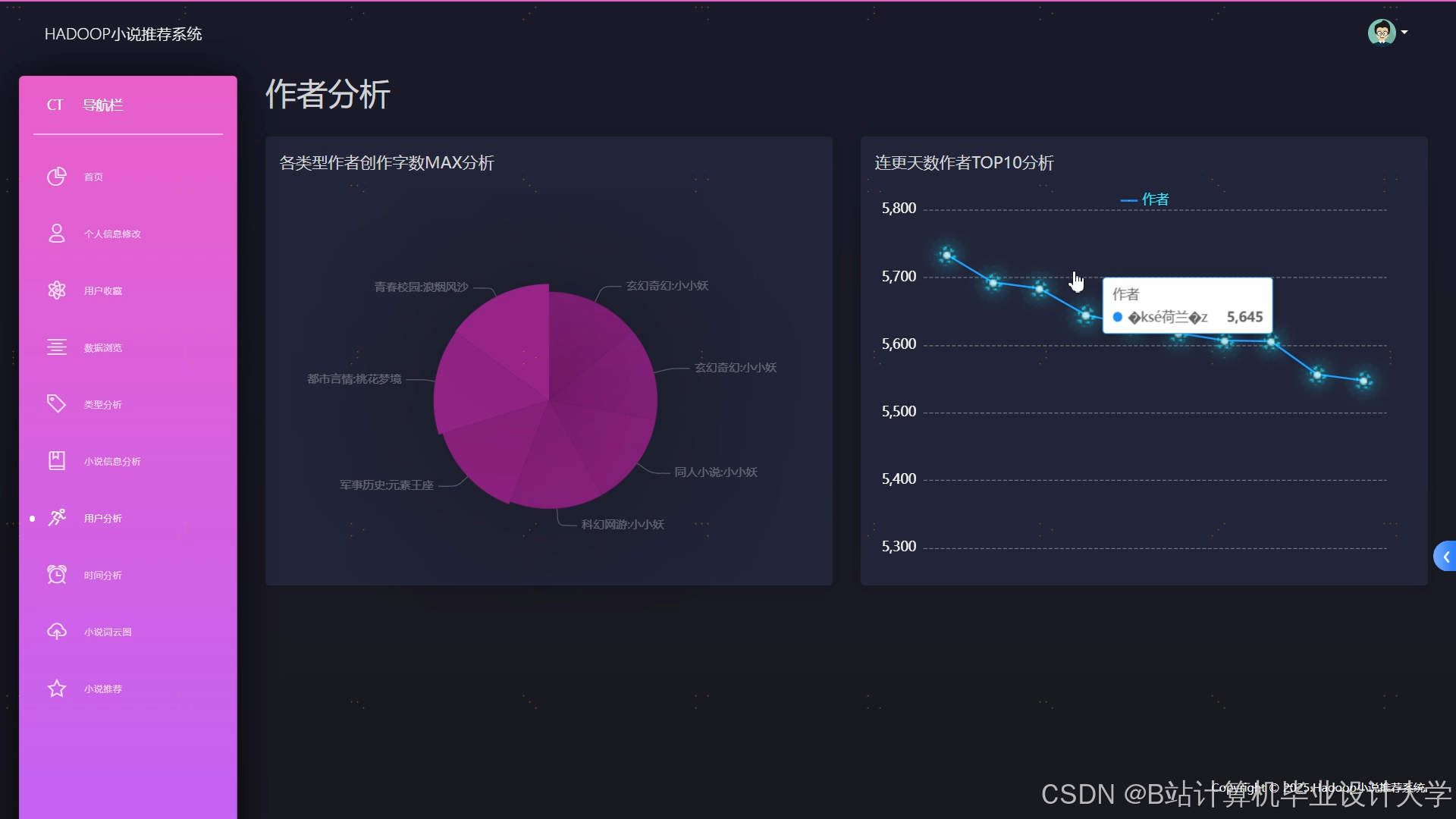

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











