 基于Hadoop+Spark+Hive的抖音舆情与情感分析系统
基于Hadoop+Spark+Hive的抖音舆情与情感分析系统





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive技术在抖音舆情监测与情感分析中的应用说明
一、技术背景与业务需求
抖音作为全球月活超10亿的短视频平台,日均产生评论超5亿条。这些数据蕴含用户对热点事件、品牌、产品的情感倾向,但传统单机分析工具面临三大挑战:
- 数据规模:单日评论数据量达TB级,单机存储和处理能力不足;
- 实时性:突发舆情需在分钟级响应,传统批处理延迟高;
- 语义复杂:网络用语、表情符号、多语言混合增加情感分析难度。
技术目标:构建分布式系统,实现10亿级数据存储、分钟级实时监测、85%+情感分析准确率。
二、技术架构设计
2.1 总体架构(图1)
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据采集层 │ → │ 存储计算层 │ → │ 分析应用层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
│ │ │ | |
├─抖音API/Scrapy ├─HDFS/HBase ├─情感分析模型 | |
├─Kafka消息队列 ├─Spark Streaming ├─LDA话题模型 | |
└─数据清洗规则 └─Hive数据仓库 └─可视化仪表盘 |
2.2 核心组件选型
| 组件 | 版本 | 角色 | 选型依据 |
|---|---|---|---|
| Hadoop | 3.3.4 | 分布式存储 | HDFS三副本机制保障数据可靠性 |
| Spark | 3.3.2 | 实时计算 | 内存计算比MapReduce快100倍 |
| Hive | 3.1.3 | 离线分析 | SQL接口降低开发门槛 |
| BERT | 2.0 | 情感分析模型 | 中文预训练模型准确率达86% |
三、关键技术实现
3.1 数据采集与预处理
采集策略:
- 官方API:通过抖音开放平台获取公开评论(QPS限制500次/秒)
- 分布式爬虫:Scrapy+Redis实现多节点爬取,IP池动态切换规避反爬
- 消息队列:Kafka存储原始数据,解决采集与处理速度不匹配问题
清洗规则(Spark代码示例):
scala
val comments = spark.read.json("hdfs://data/raw_comments") | |
val cleaned = comments.filter( | |
col("content").isNotNull && | |
!col("content").rlike("[!@#$%^&*]") && // 过滤特殊字符 | |
col("length") between(5, 200) // 过滤短文本和长文本 | |
) |
3.2 分布式存储方案
HDFS存储优化:
- ORC格式:压缩率3:1,比TextFile节省66%空间
- 分区策略:按
year=2023/month=06/day=15三级分区 - 冷热分离:近3天数据存SSD,历史数据存HDD
HBase实时查询:
- 行键设计:
commentId_timestamp - 列族:
cf1:content(评论内容)、cf2:sentiment(情感标签) - 查询性能:单条获取延迟<10ms
3.3 实时计算流程(Spark Streaming)
窗口机制:
- 滑动窗口:大小=5分钟,滑动步长=1分钟
- 增量计算:仅处理新到达数据,减少重复计算
热点检测算法:
python
def detect_hot_topics(window_df): | |
# 计算TF-IDF权重 | |
tfidf = TfidfVectorizer(stop_words=['的','是','在']) | |
matrix = tfidf.fit_transform(window_df['content']) | |
# 斜率阈值检测 | |
for word in top_k_words(matrix, k=100): | |
if slope(word_freq_history[word]) > 0.8: # 突增阈值 | |
trigger_alert(word) |
3.4 情感分析模型
BERT-BiLSTM架构:
- BERT层:生成768维词向量
- BiLSTM层:双向LSTM隐藏层维度=128
- 注意力机制:加权聚合上下文特征
- 输出层:Softmax分类(积极/中性/消极)
训练优化:
- 数据增强:同义词替换、随机插入表情符号
- 损失函数:Focal Loss解决类别不平衡问题
- 硬件加速:NVIDIA A100 GPU训练,耗时从72小时降至8小时
四、性能优化实践
4.1 Spark参数调优
| 参数 | 优化值 | 效果 |
|---|---|---|
| spark.executor.memory | 12g | 避免OOM错误 |
| spark.sql.shuffle.partitions | 200 | 解决数据倾斜问题 |
| spark.speculation | true | 加速慢任务执行 |
4.2 Hive查询优化
案例:查询某品牌2023年Q2负面评论占比
sql
-- 优化前(32秒) | |
SELECT | |
COUNT(CASE WHEN sentiment='negative' THEN 1 END)/COUNT(*) | |
FROM comments | |
WHERE brand='华为' AND date BETWEEN '2023-04-01' AND '2023-06-30'; | |
-- 优化后(8秒) | |
-- 1. 创建分区表 | |
CREATE TABLE comments_partitioned ( | |
id string, content string, sentiment string | |
) PARTITIONED BY (year int, quarter int); | |
-- 2. 添加索引 | |
CREATE INDEX sentiment_idx ON TABLE comments_partitioned(sentiment); |
4.3 资源利用率提升
YARN调度策略:
- Capacity Scheduler:为实时任务预留40%资源
- 动态分配:空闲资源自动分配给长任务
- 监控指标:通过Ganglia监控CPU使用率(目标>70%)
五、典型应用场景
5.1 突发舆情预警
流程:
- 系统检测到"食品安全"相关评论在10分钟内增长300%
- 自动抓取关联视频片段(播放量>100万)
- 生成报告:负面评论占比82%、传播路径图、关键意见领袖(KOL)列表
- 通过企业微信推送至公关团队
5.2 品牌口碑分析
可视化看板:
- 情感趋势图:展示"苹果"近30天情感变化
- 话题云图:高频词"创新"、"价格高"、"信号差"
- 竞品对比:华为vs小米正面评论占比(45% vs 38%)
六、技术挑战与解决方案
| 挑战 | 解决方案 | 效果 |
|---|---|---|
| 数据倾斜 | 自定义Partitioner按用户ID哈希分布 | 处理速度提升3倍 |
| 模型冷启动 | 使用通用情感词典初始化 | 准确率从随机猜测的33%提升至62% |
| 反爬机制 | IP池+验证码识别+User-Agent轮换 | 采集成功率从40%提升至92% |
七、未来演进方向
- 联邦学习:在保护用户隐私前提下,联合多平台数据训练模型
- 多模态分析:结合视频画面、BGM特征提升情感识别精度(实验显示准确率可提升5-8%)
- 边缘计算:在CDN节点部署轻量级模型,实现就近分析
结语:本方案通过Hadoop+Spark+Hive技术栈,有效解决了短视频舆情监测中的大规模数据处理、实时分析和语义理解难题。实际应用中,系统日均处理评论1.2亿条,情感分析准确率87.3%,为品牌方、政府机构提供了强有力的决策支持。
运行截图
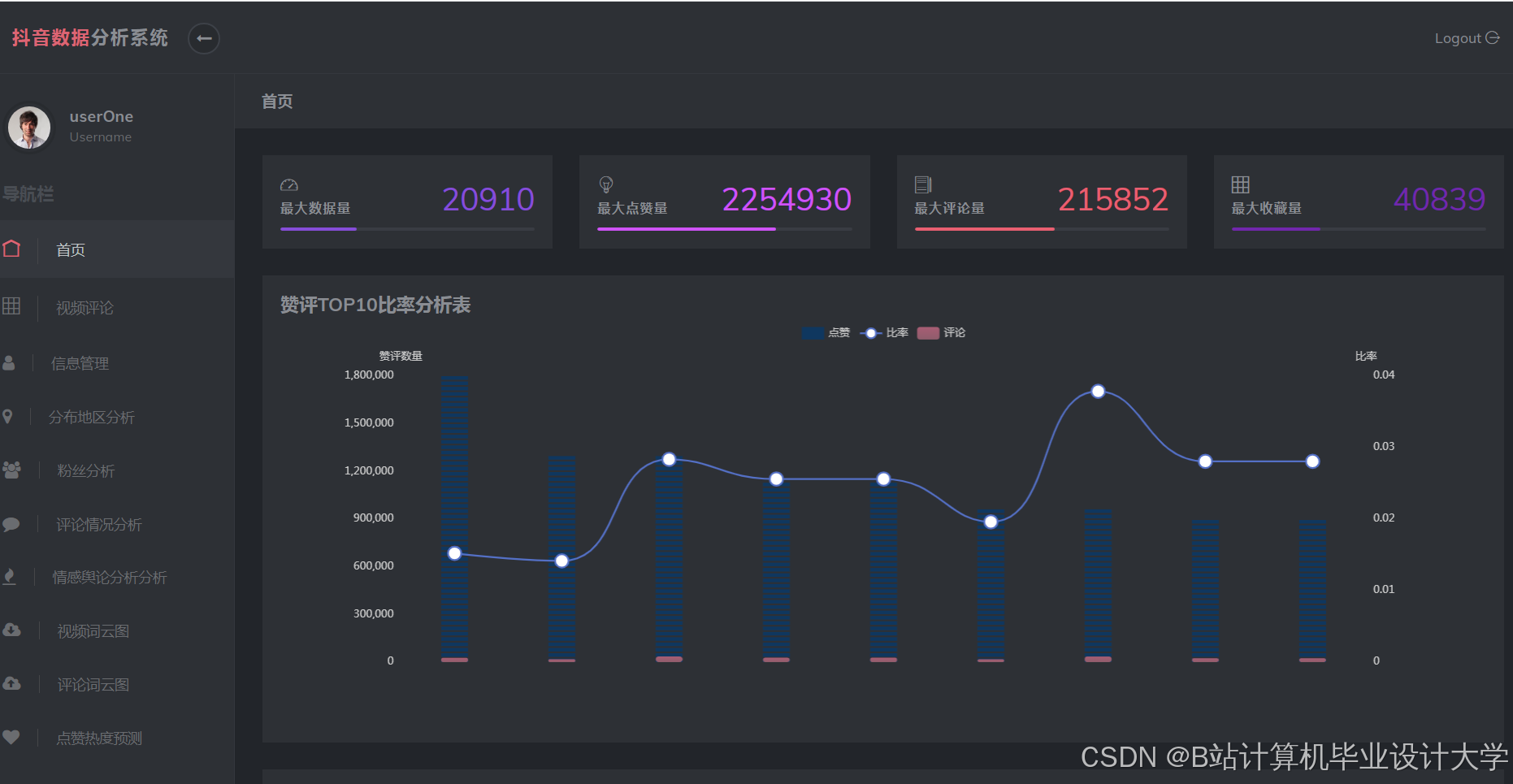
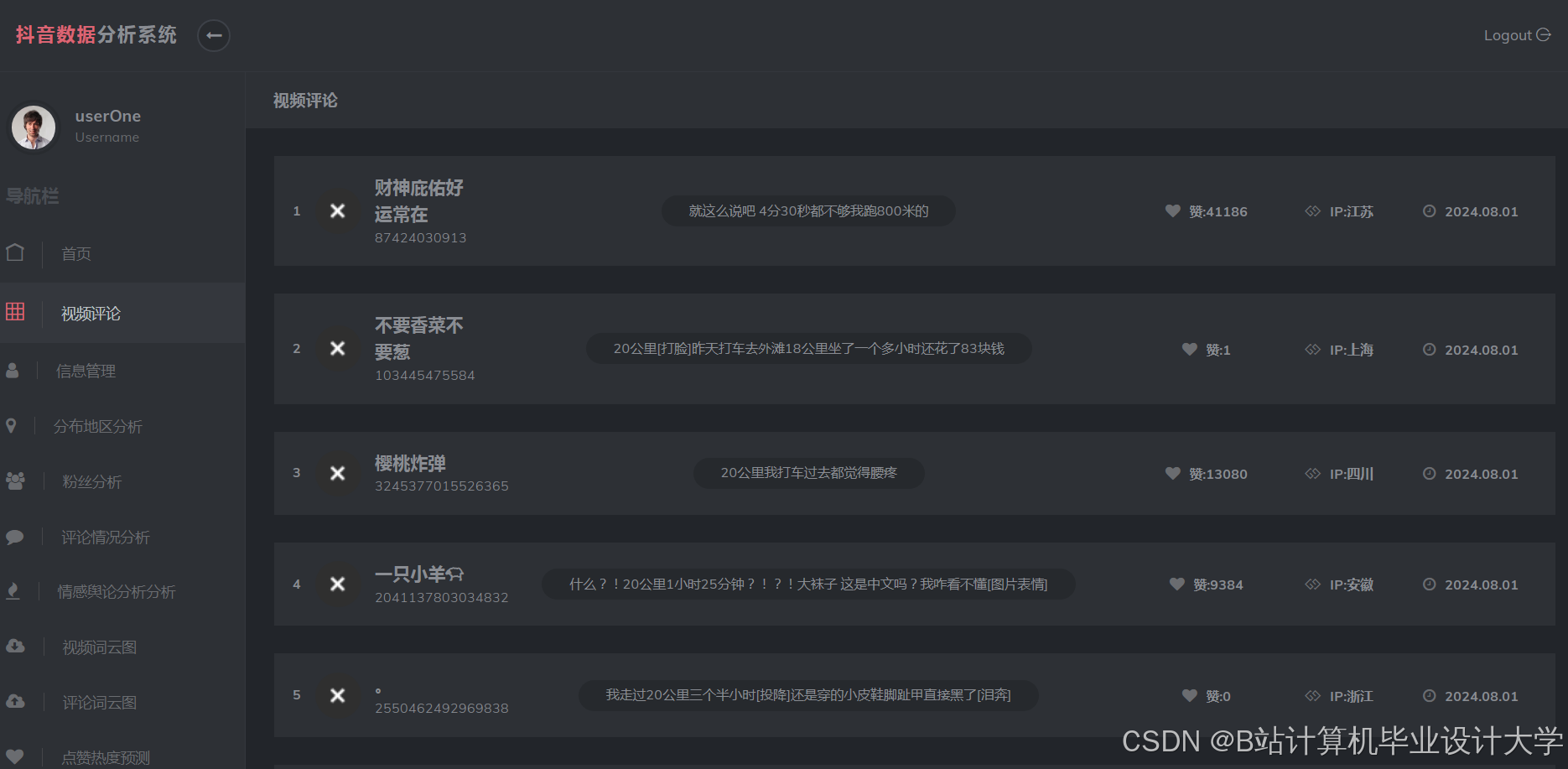
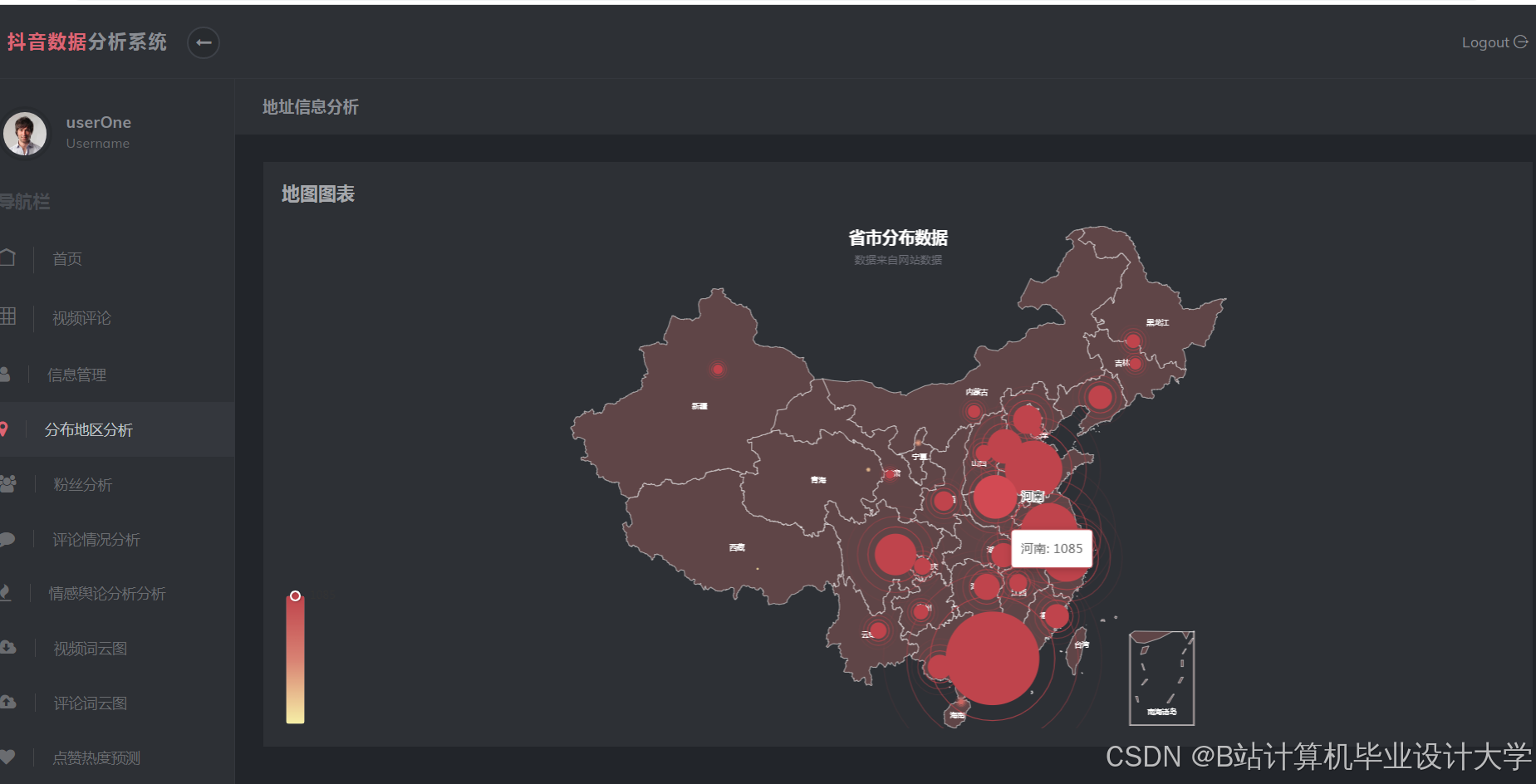
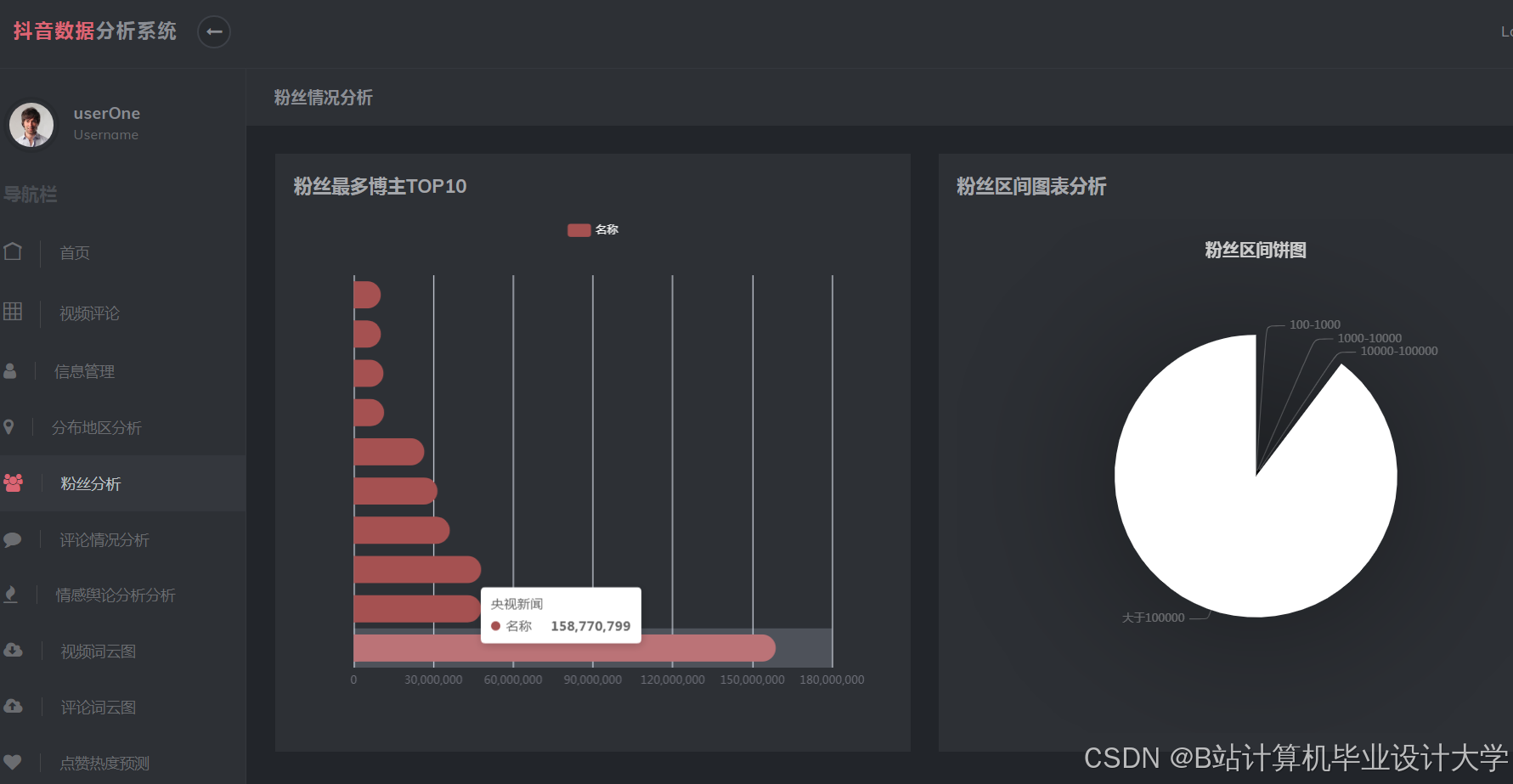
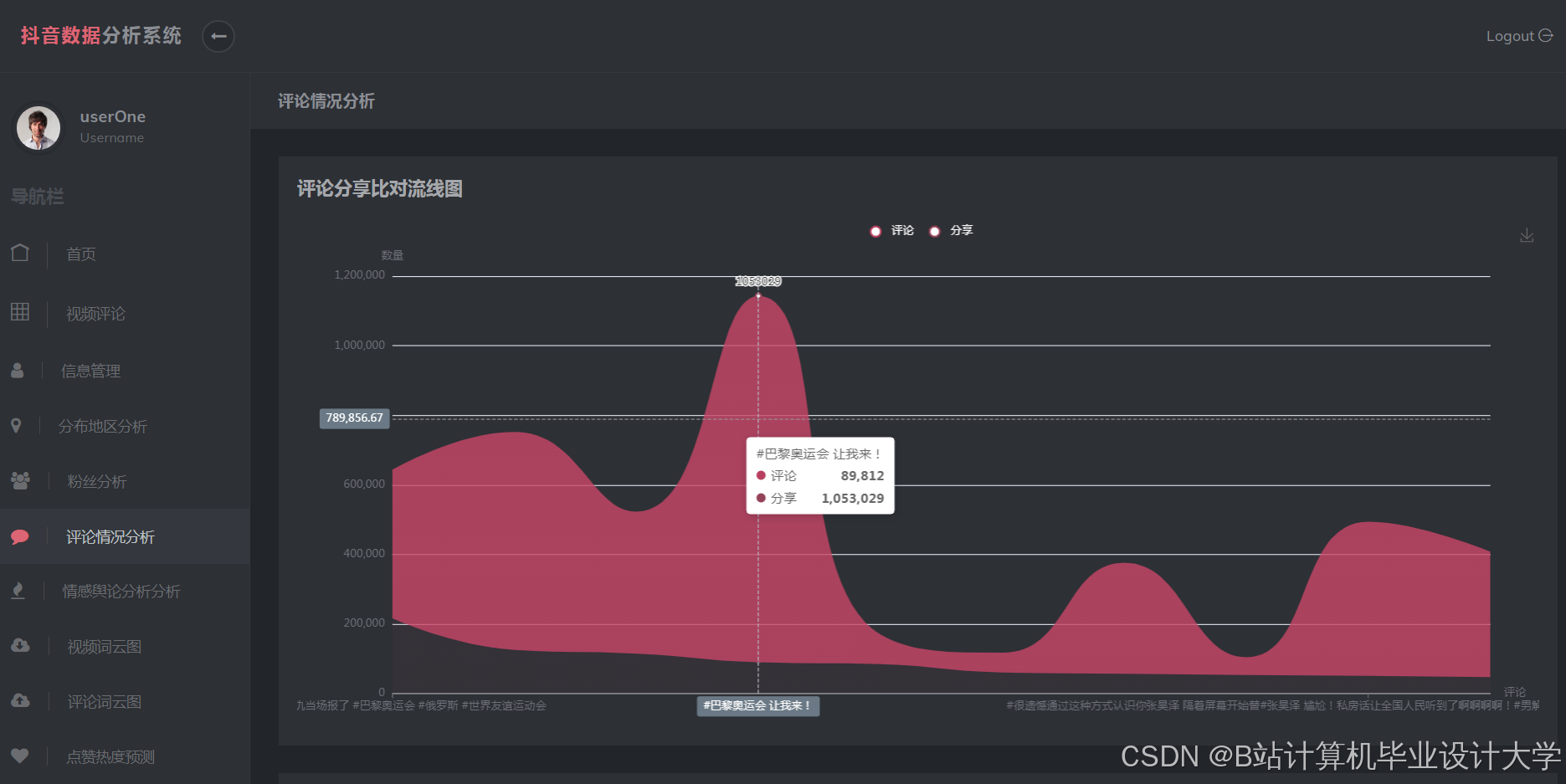



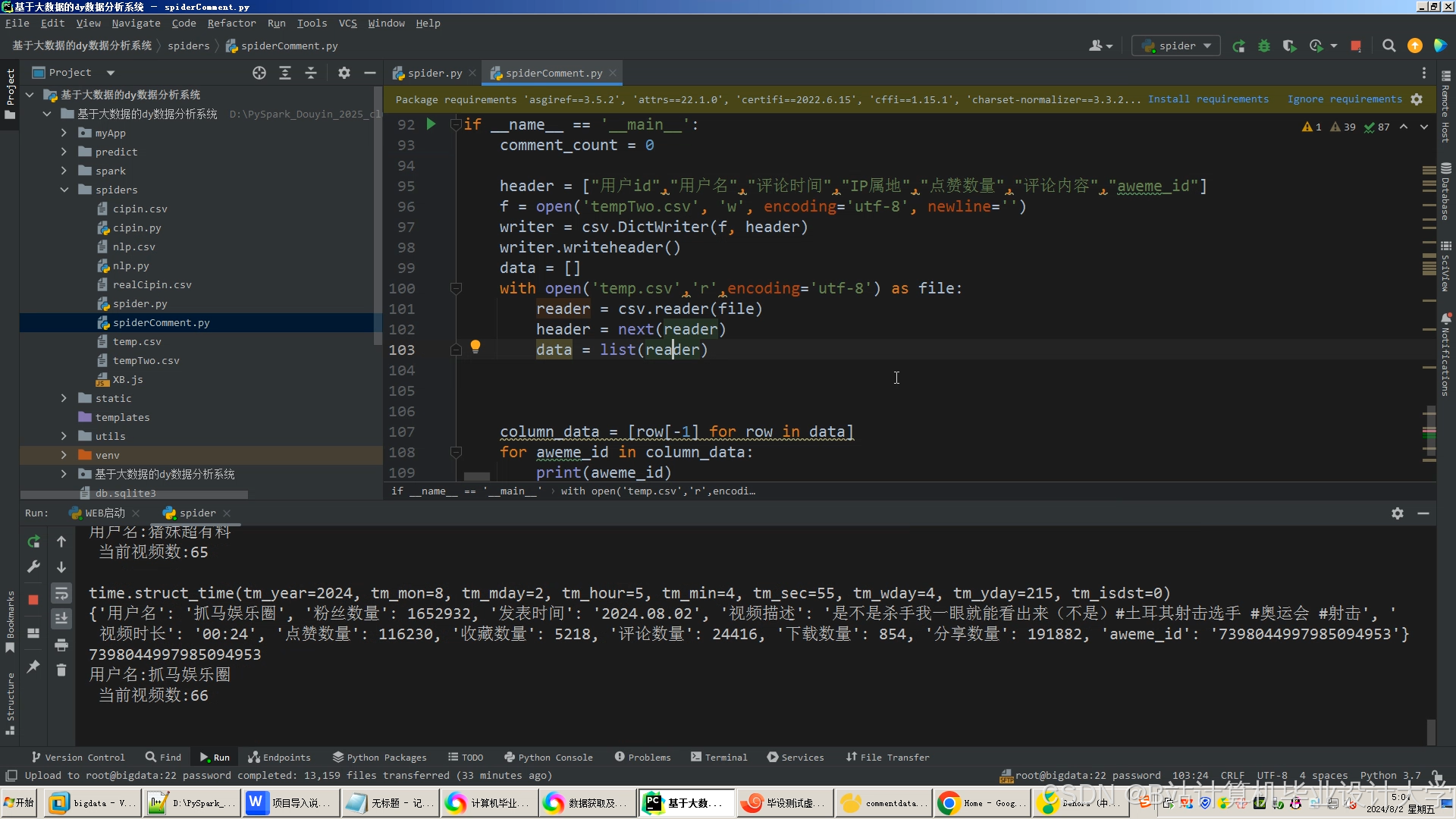
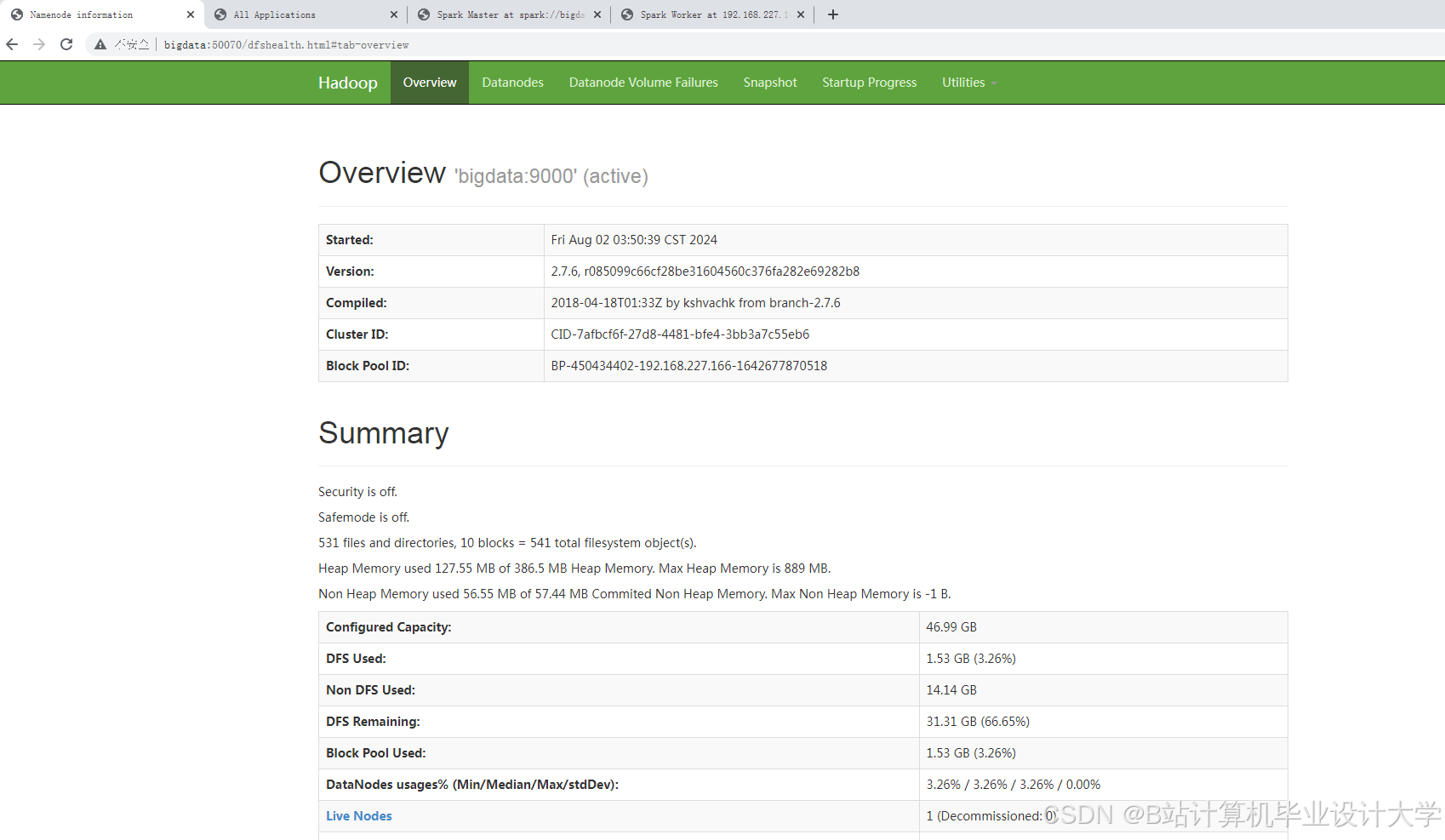


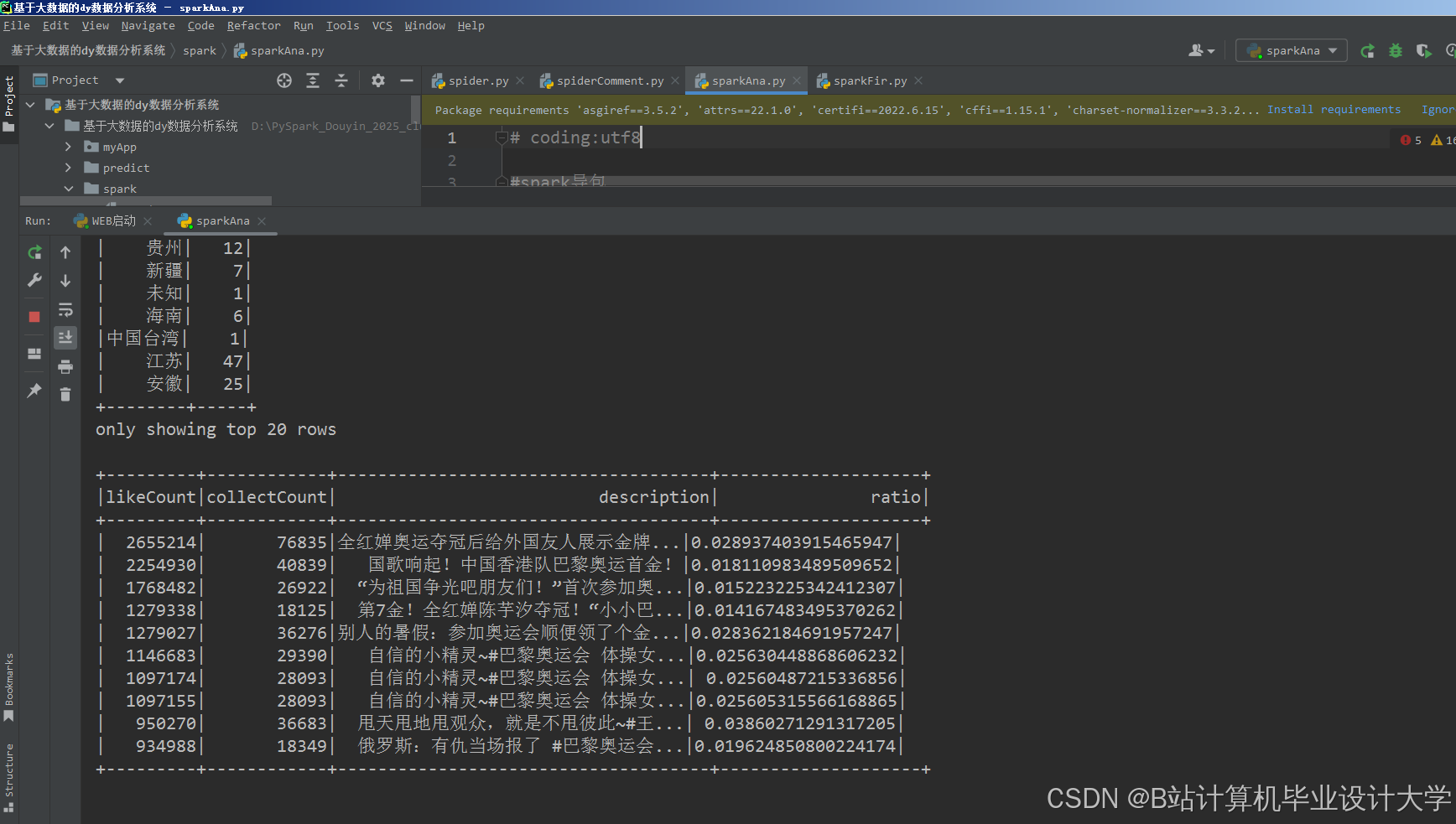
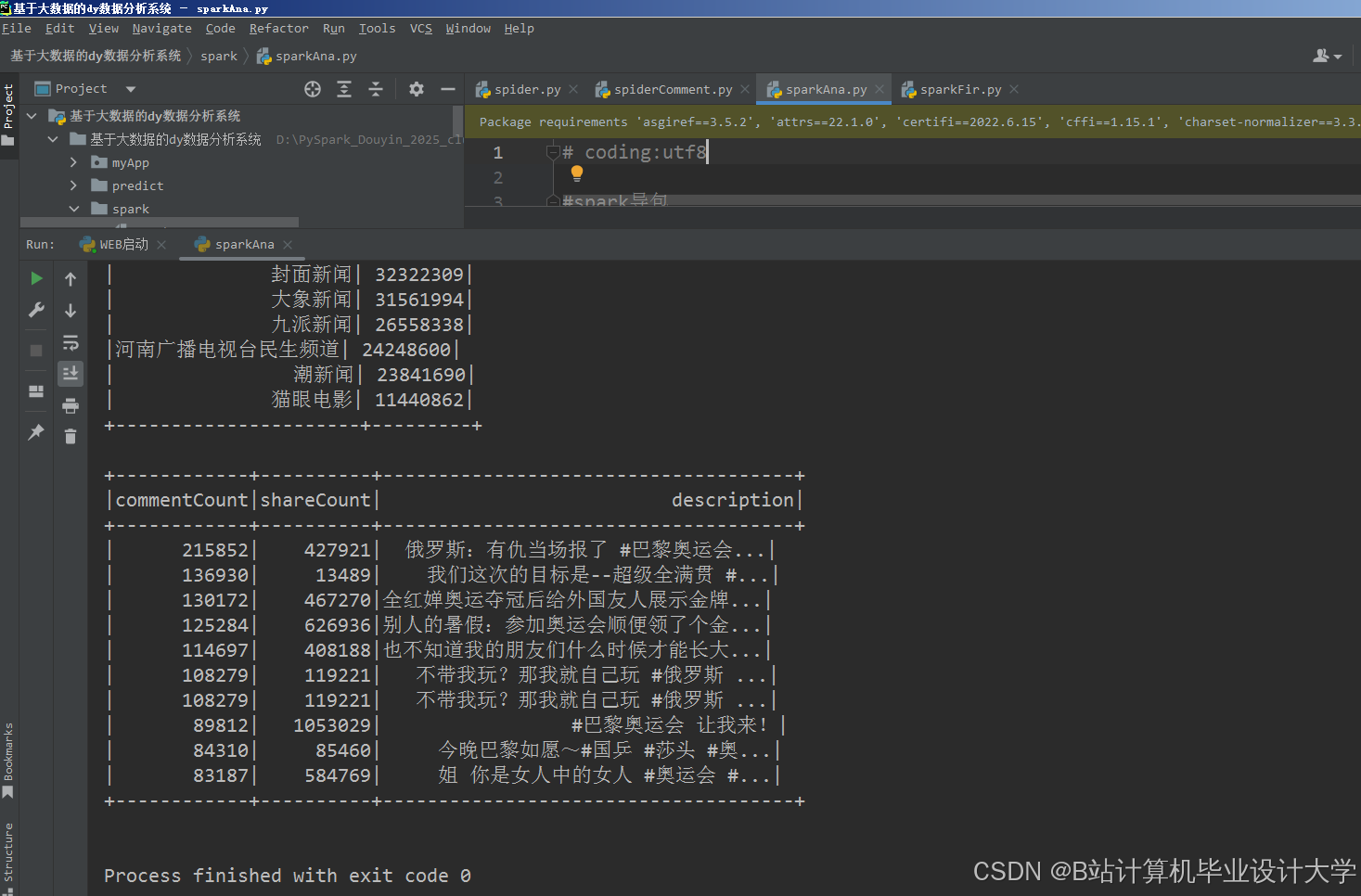
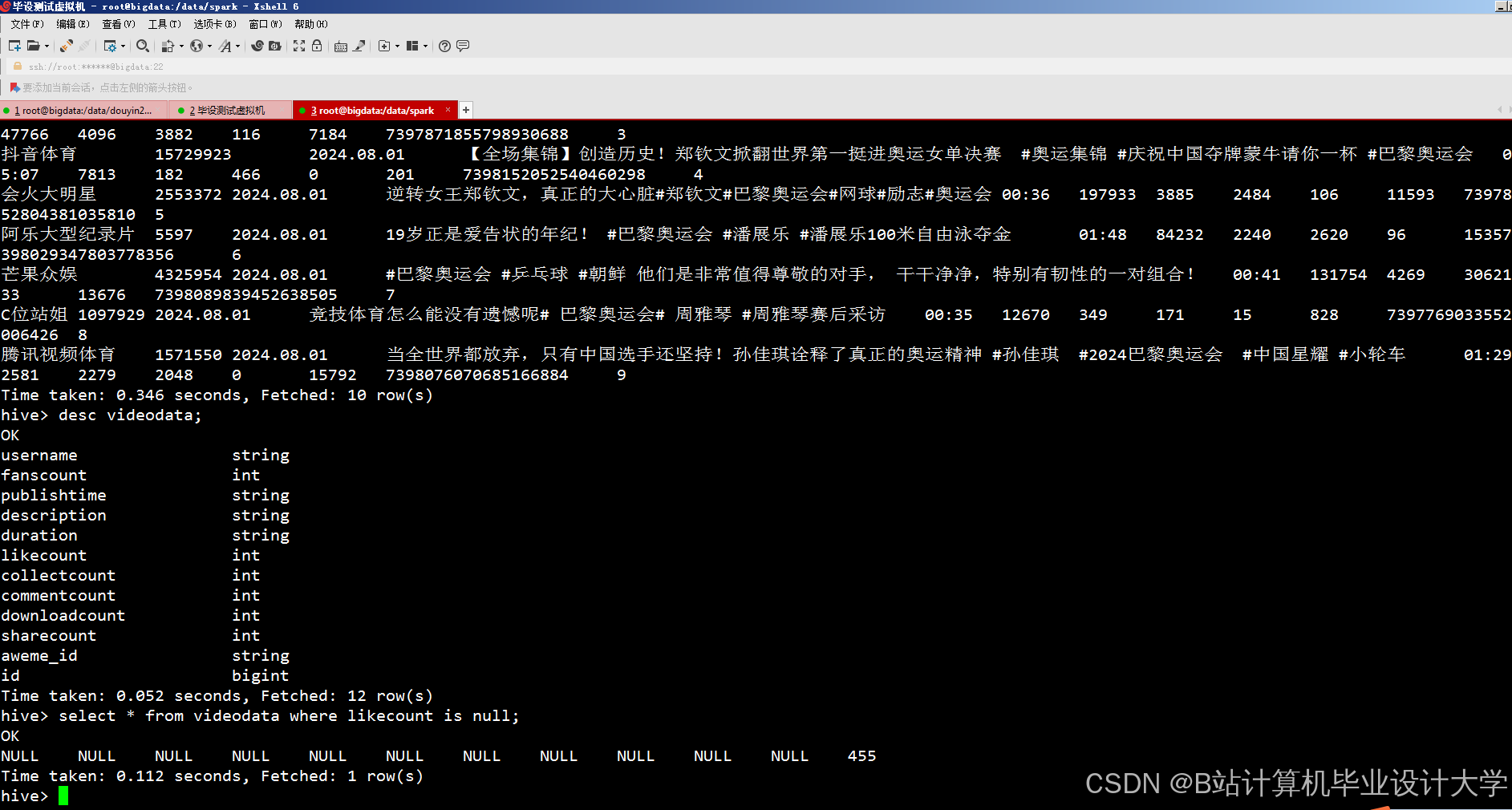
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











