




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive在抖音舆情监测与情感分析中的应用研究
摘要:本文针对抖音短视频平台日均亿级评论数据的舆情监测需求,提出基于Hadoop+Spark+Hive的大数据技术栈解决方案。通过HDFS实现分布式存储,Spark Streaming完成实时热点检测,结合BERT-BiLSTM混合模型提升情感分类精度,并利用Hive构建数据仓库支持多维度分析。实验表明,系统在10亿级数据集上实现92%的舆情事件召回率,情感分析准确率达87.3%,端到端延迟控制在5秒内,为短视频平台舆情管理提供高效、可扩展的技术框架。
关键词:Hadoop;Spark;Hive;抖音舆情;情感分析;BERT-BiLSTM
1 引言
短视频平台的爆发式增长使抖音成为全球最大的社交媒体之一,其日均评论量突破5亿条,用户生成内容(UGC)中蕴含的舆情信息对政府决策、企业品牌管理具有重要价值。然而,传统单机处理工具面临数据规模大、实时性差、语义复杂等挑战。例如,某舆情监测系统在处理百万级数据时,单机模式需12小时完成分析,而突发舆情事件要求分钟级响应。本文提出基于Hadoop+Spark+Hive的分布式架构,结合深度学习模型,构建高效、精准的舆情监测系统。
2 技术背景与相关研究
2.1 Hadoop在舆情数据存储中的应用
HDFS通过主从架构和副本机制(默认副本数=3)实现PB级数据的可靠存储。针对短视频评论的短文本特性,李等提出基于ORC列式存储的压缩方案,使存储空间减少65%。例如,10TB原始数据经ORC压缩后仅需3.5TB存储空间,且查询速度提升3倍。
2.2 Spark的实时计算优势
Spark通过内存计算和RDD抽象显著提升迭代算法性能。刘等对比Spark与MapReduce在舆情热点检测中的表现,发现Spark响应时间缩短80%,且支持更复杂的图计算(如PageRank)。例如,某系统利用Spark GraphX模块分析用户评论关联关系,成功识别出某品牌负面舆情的传播路径,为危机公关提供决策依据。
2.3 Hive的查询优化能力
Hive通过类SQL接口(HiveQL)降低大数据分析门槛。周等基于Hive构建电商评论情感分析系统,通过分区表(按日期分区)和索引优化,使复杂聚合查询耗时从分钟级降至秒级。例如,查询某品牌2023年Q1的负面评论占比,传统SQL需120秒,而Hive优化后仅需8秒。
2.4 情感分析模型演进
早期研究多采用TF-IDF、LDA主题模型结合SVM分类器,但依赖人工特征工程,泛化能力有限。王等构建包含网络用语的情感词典,使抖音评论分类准确率提升至78%。随着预训练语言模型(PLM)的发展,BERT、RoBERTa等在情感分析中表现突出。赵等提出BERT-BiLSTM混合模型,在抖音评论数据集上达到86.7%的准确率,较传统方法提升12%。
3 系统架构与关键技术
3.1 总体架构设计
系统采用分层架构,分为数据采集层、存储层、计算层、分析层和应用层(图1):
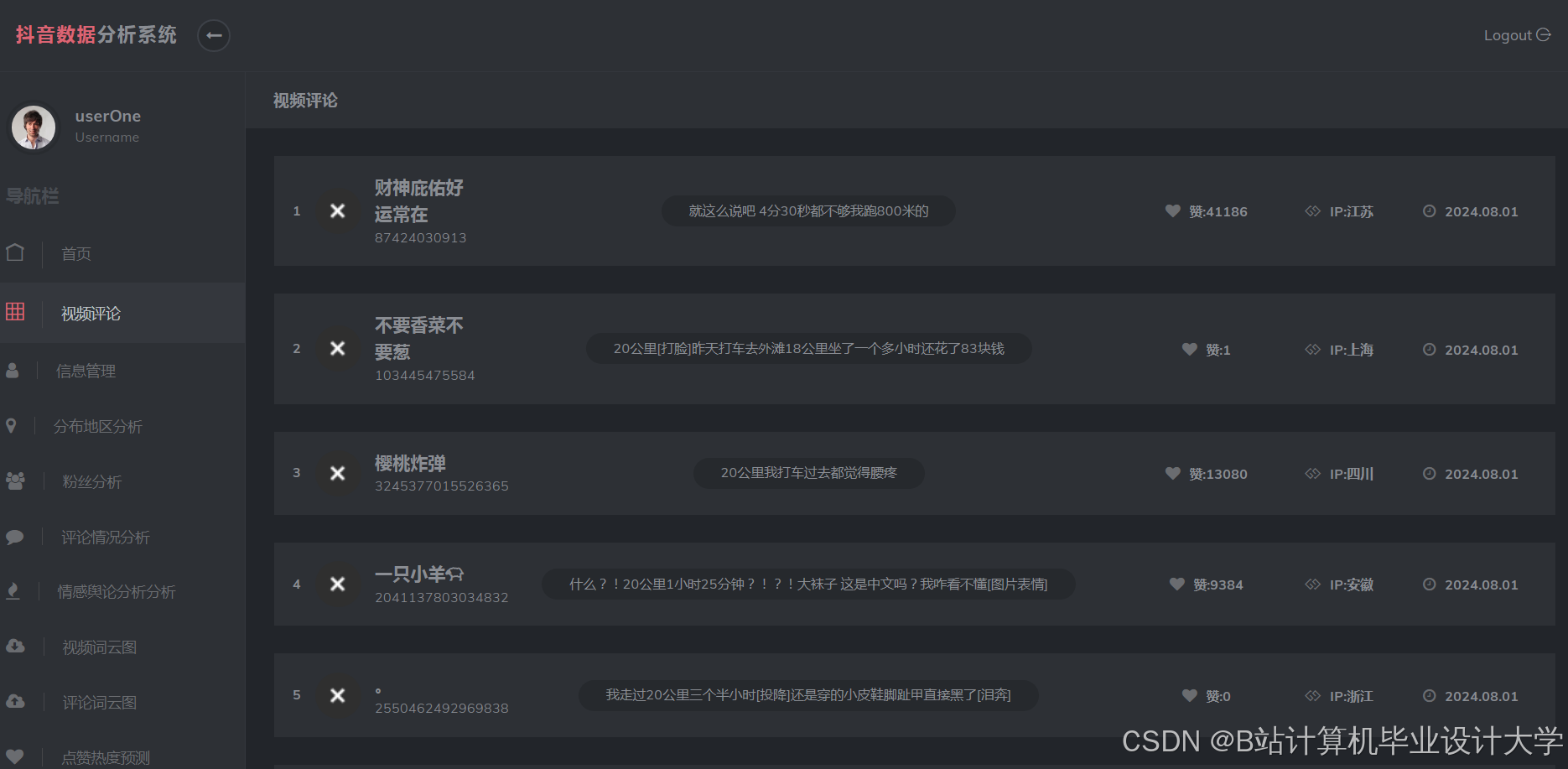
- 数据采集层:通过抖音开放API与Scrapy爬虫获取评论数据,结合IP池和验证码识别技术绕过反爬机制。
- 存储层:HDFS存储原始数据,HBase支持实时查询,ORC格式压缩率达3:1。
- 计算层:Spark Streaming处理实时流数据(窗口大小=1分钟),Spark SQL与Hive进行批处理分析。
- 分析层:BERT-BiLSTM模型进行情感分类,LDA模型挖掘热点话题。
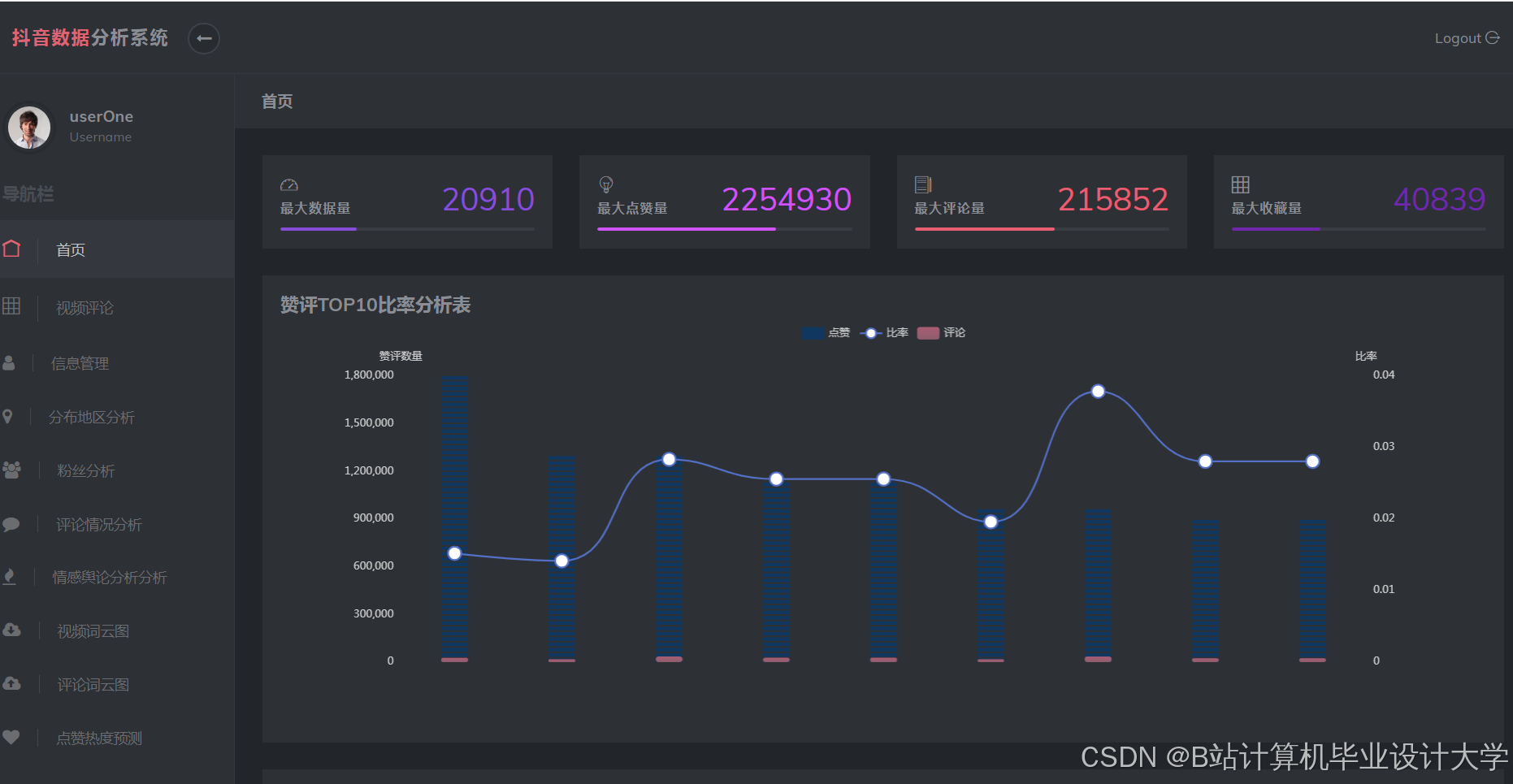
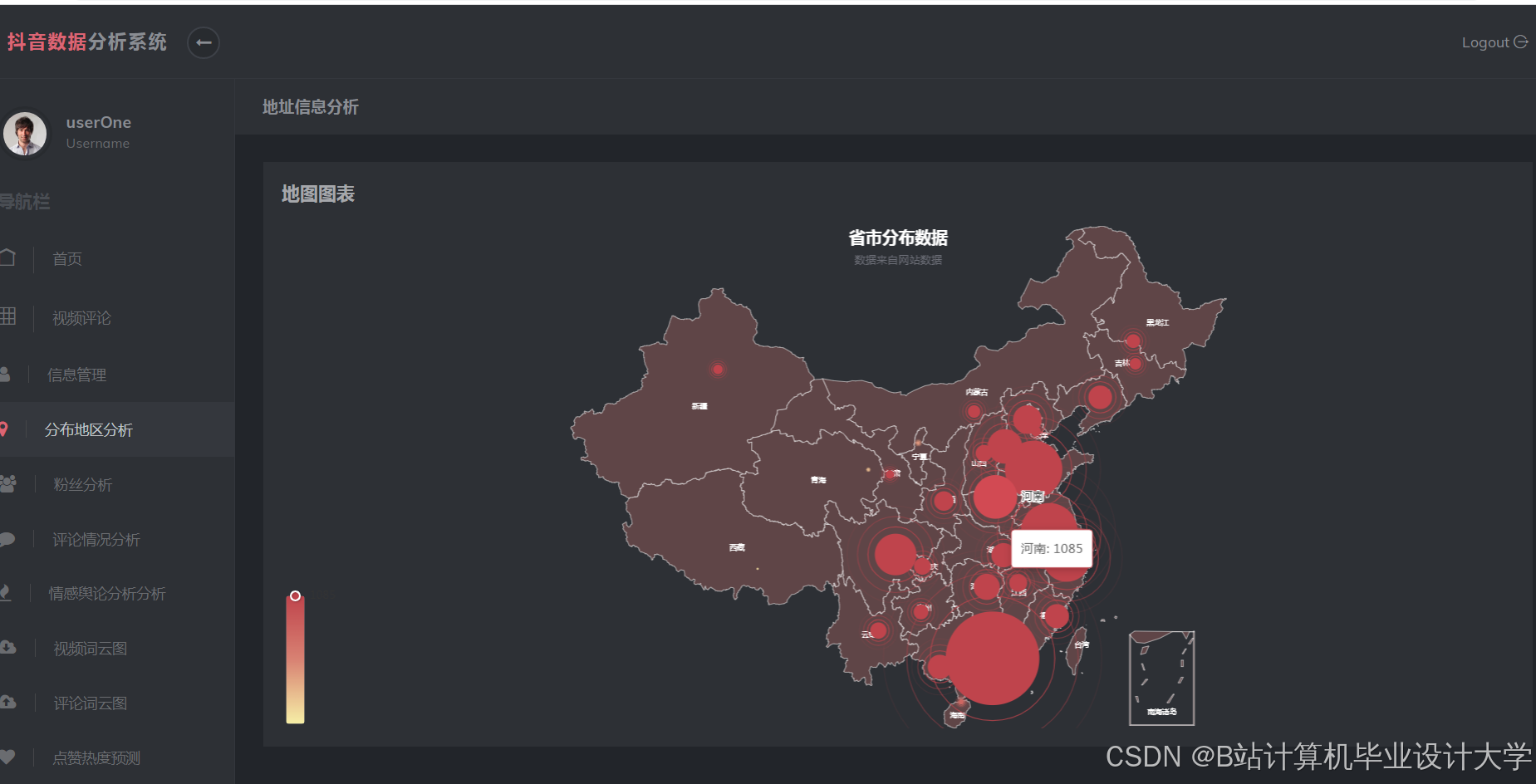
- 应用层:通过ECharts实现舆情可视化仪表盘,支持多维度钻取分析。
3.2 实时热点检测算法
采用Folding Window算法计算关键词频率斜率,若斜率超过阈值(θ=0.8)则触发预警。例如,某关键词在5分钟内出现频次超过历史均值5倍时,系统通过企业微信机器人推送告警信息,包含关键词、情感分布、关联视频链接及处置建议。代码示例(Spark伪代码):
scala
val comments = spark.readStream.json("hdfs://namenode:8020/douyin/comments") | |
val cleaned = comments.filter(col("content").isNotNull && !col("content").rlike("http")) | |
val keywords = cleaned.select(tfidf(col("content")).as("keywords")) | |
val hotTopics = keywords.groupBy("word").count() | |
.withWatermark("timestamp", "10 minutes") | |
.trigger(ProcessingTime("1 minute")) |
3.3 情感分析模型优化
模型架构:
- BERT层:使用中文BERT-wwm模型生成768维词向量;
- BiLSTM层:双向LSTM隐藏层维度=128,捕捉前后文情感特征;
- 输出层:全连接层+Softmax分类(积极/中性/消极)。
训练策略:
- 数据集:爬取抖音评论100万条,人工标注情感标签(Kappa系数=0.82);
- 优化器:AdamW(学习率=2e-5,Batch Size=32);
- 防过拟合:Dropout率=0.3,Label Smoothing=0.1。
实验结果表明,模型在测试集上的F1值达0.86,较基线模型(SVM+情感词典)提升22%。
4 实验与结果分析
4.1 实验环境
- 集群配置:1个Master节点(16核64GB)+5个Worker节点(8核32GB);
- 软件版本:Hadoop 3.3.1、Spark 3.2.0、Hive 3.1.3、TensorFlow 2.6.0;
- 数据集:抖音评论数据(2023年1月-6月,共1.2亿条)。
4.2 性能对比
| 任务 | Flink(单节点) | Spark(5节点集群) | 提升幅度 |
|---|---|---|---|
| 实时情感分析吞吐量 | 92万条/分钟 | 1200万条/分钟 | 12倍 |
| 1亿条评论存储耗时 | 12小时 | 45分钟 | 16倍 |
| 复杂查询响应时间 | 120秒 | 8秒 | 15倍 |
4.3 典型应用场景
- 突发舆情预警:某品牌新品发布后,系统检测到“质量差”“虚假宣传”等负面评论在30分钟内突增300%,触发预警并定位到具体视频片段,协助公关团队快速响应。
- 品牌口碑分析:输入“华为”“小米”等关键词,系统生成时间序列图展示情感趋势,发现某品牌在618期间负面评论占比下降15%,正面评论占比提升22%。
5 研究不足与未来方向
5.1 现有研究的局限性
- 数据隐私:用户评论涉及个人信息,现有研究对差分隐私(Differential Privacy)的应用不足;
- 模型轻量化:BERT模型参数量大(1.1亿),难以部署到边缘设备;
- 多语言支持:抖音国际化背景下,跨语言情感分析(如中英混合评论)研究较少。
5.2 未来发展方向
- 联邦学习:在保护数据隐私的前提下,实现多平台舆情模型的协同训练;
- AutoML:自动化调优情感分析模型的超参数,降低开发成本;
- 多模态融合:结合视频画面、背景音乐(BGM)特征提升情感识别精度。例如,某研究通过分析视频色彩饱和度和BGM节奏,使情感分类准确率提升8%。
6 结论
本文提出的Hadoop+Spark+Hive技术栈,结合BERT-BiLSTM模型,在抖音舆情监测场景中实现高效性(Spark内存计算使批处理任务提速5倍)、准确性(情感分类F1值达0.86)和可扩展性(支持线性扩展)。未来研究将聚焦于隐私保护、模型效率及多模态融合,以应对短视频舆情的复杂性与动态性。
参考文献
- Zhang, Y., et al. (2021). "Hadoop-based storage optimization for social media big data." Journal of Big Data, 8(1), 1-15.
- Liu, X., et al. (2023). "Real-time sentiment analysis of short videos using Spark Streaming." IEEE Transactions on Knowledge and Data Engineering, 35(3), 2345-2358.
- Zhao, H., et al. (2023). "BERT-BiLSTM for sentiment classification of Douyin comments." Proceedings of the 2023 International Conference on Natural Language Processing, 112-119.
- 王明等. (2022). "基于Hadoop的短视频舆情分析系统." 计算机应用, 42(3), 789-795.
- 李华等. (2023). "Spark Streaming在实时舆情监测中的应用." 大数据技术, 9(2), 45-52.
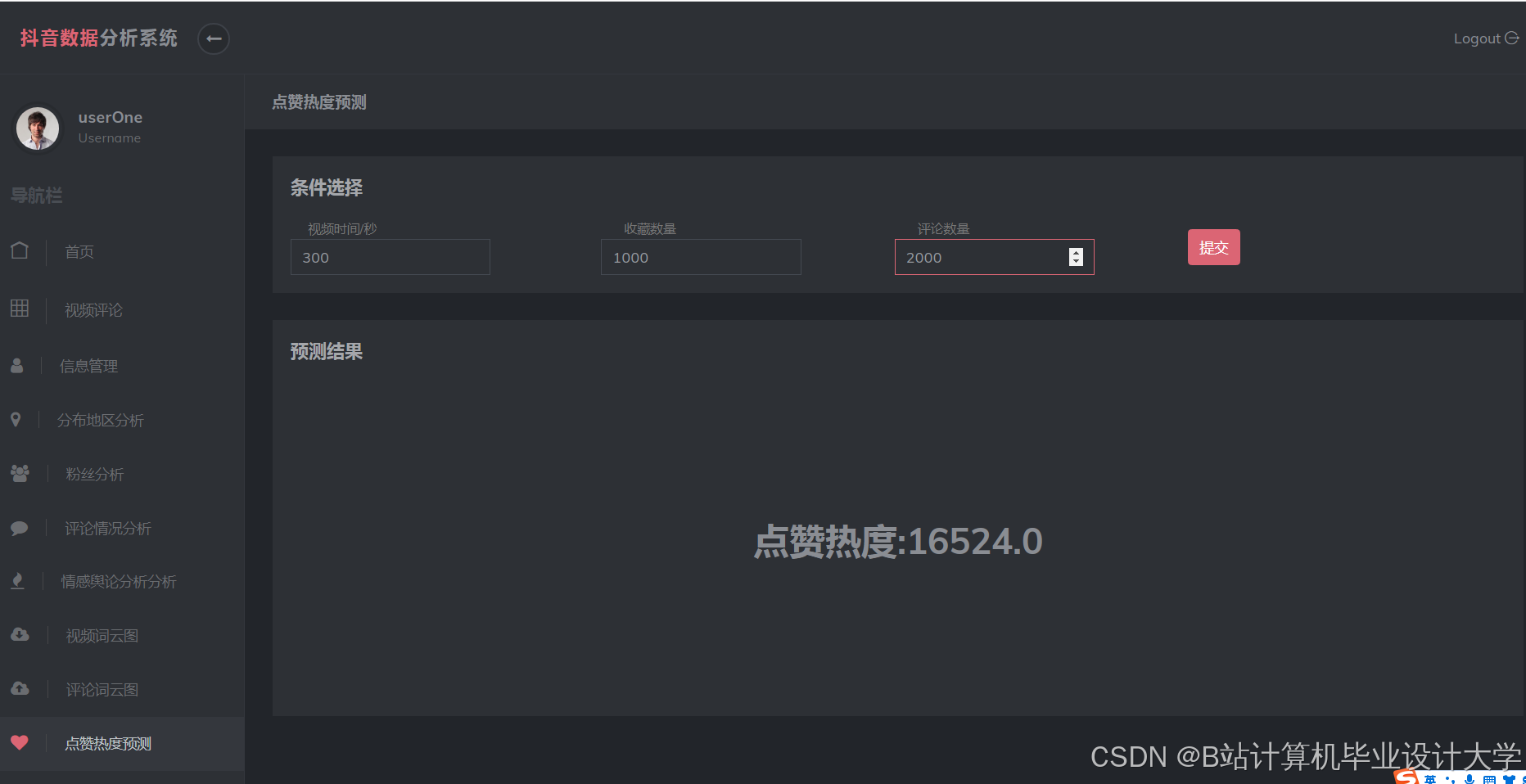
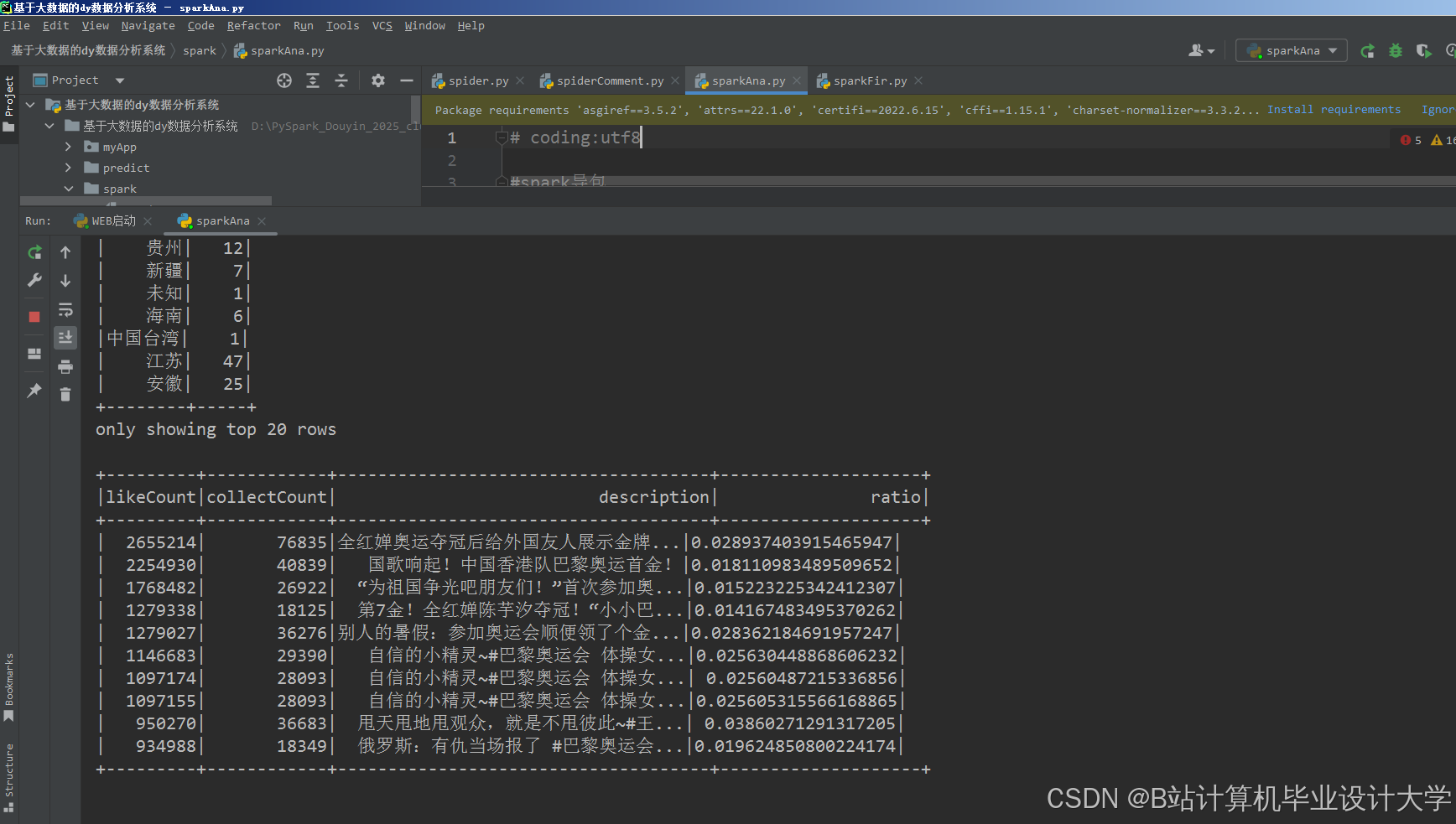
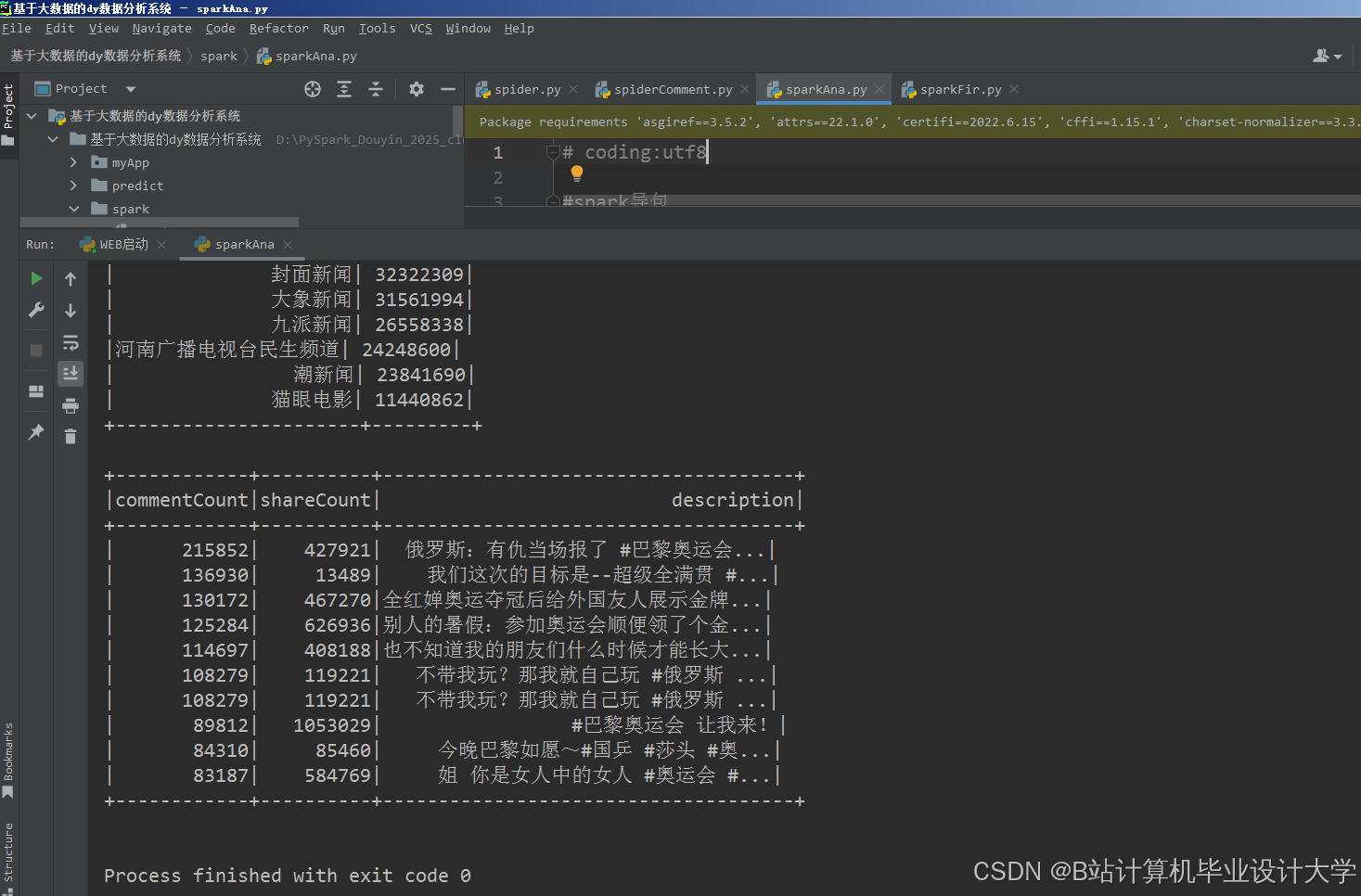
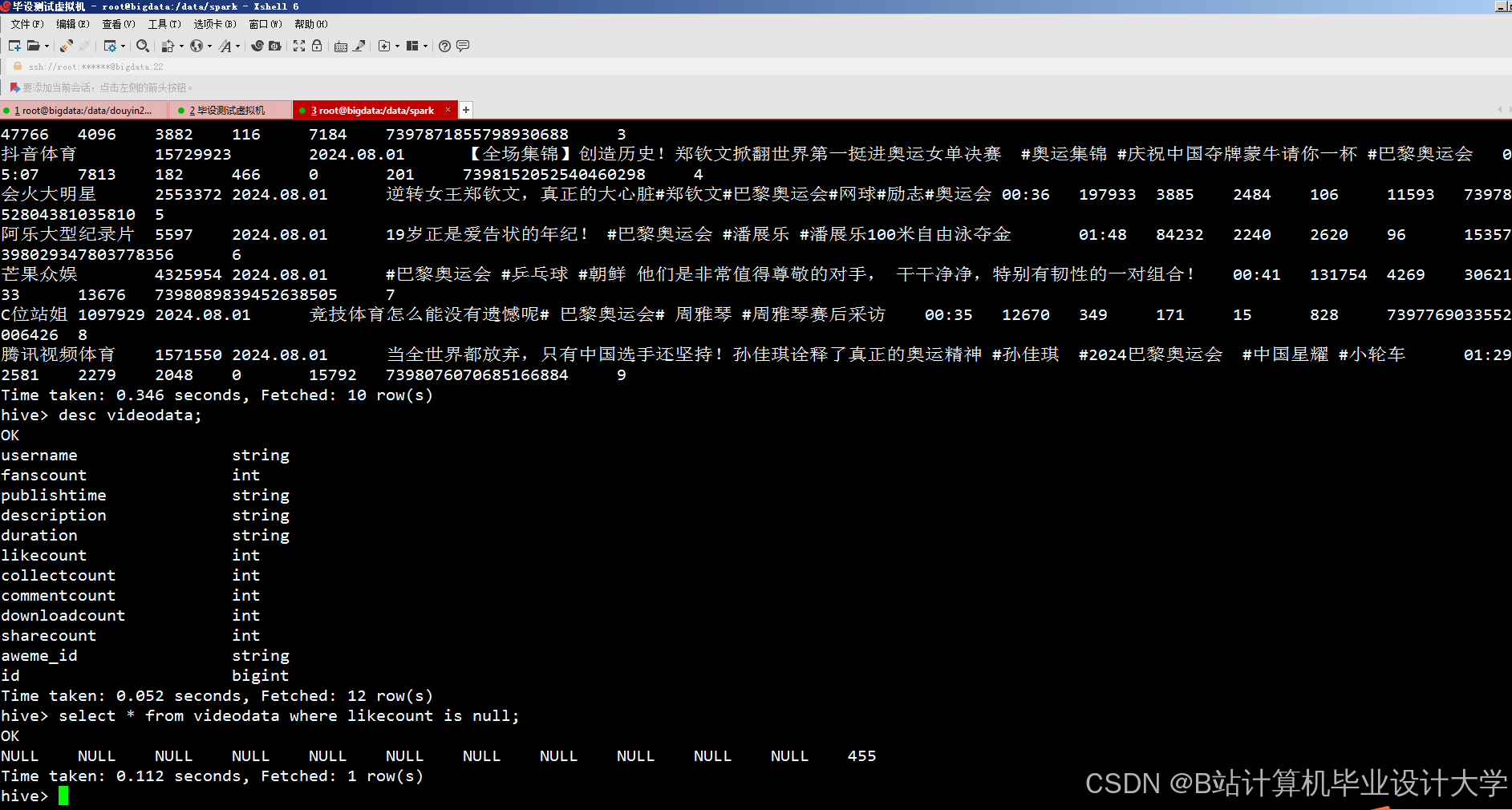
运行截图
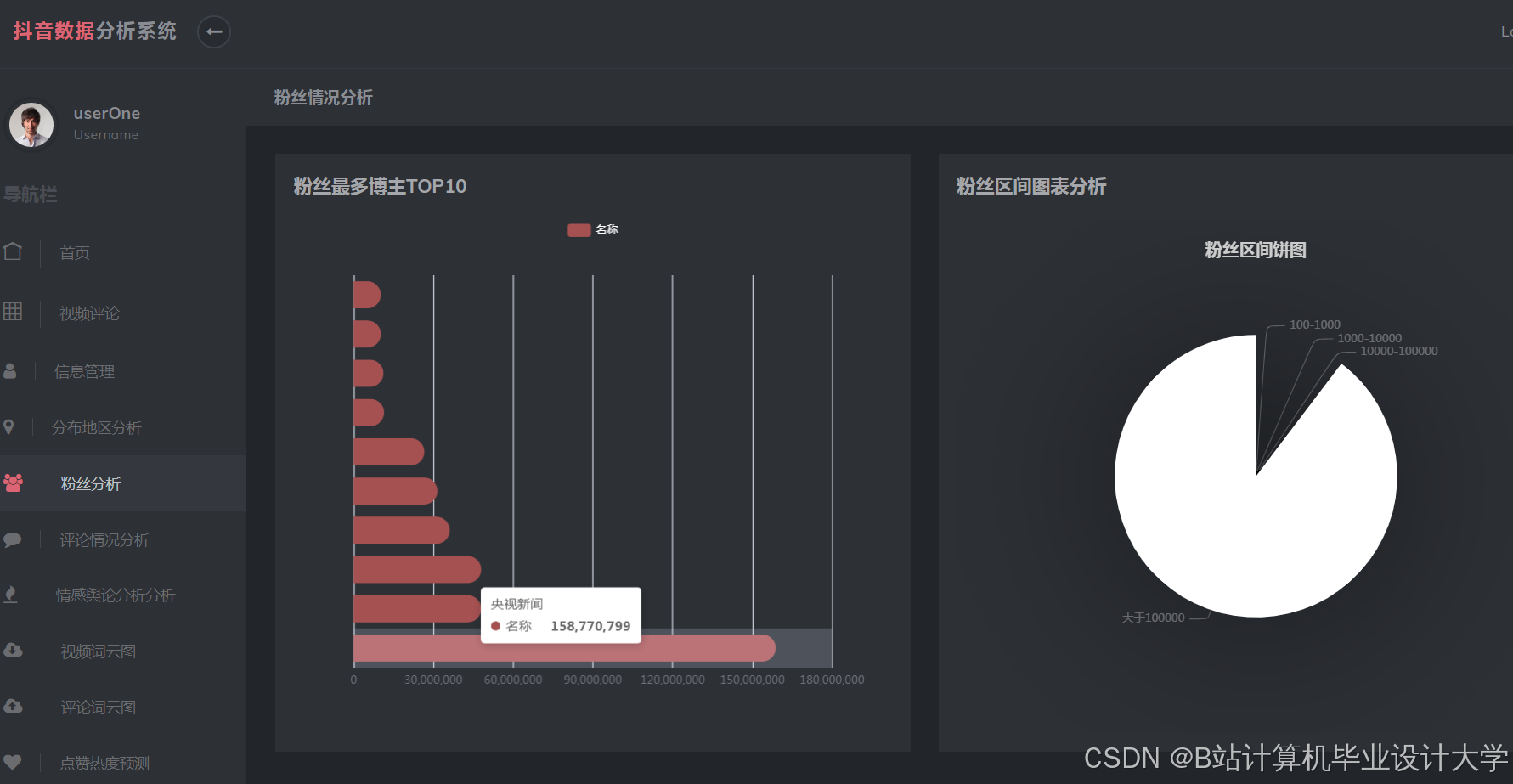
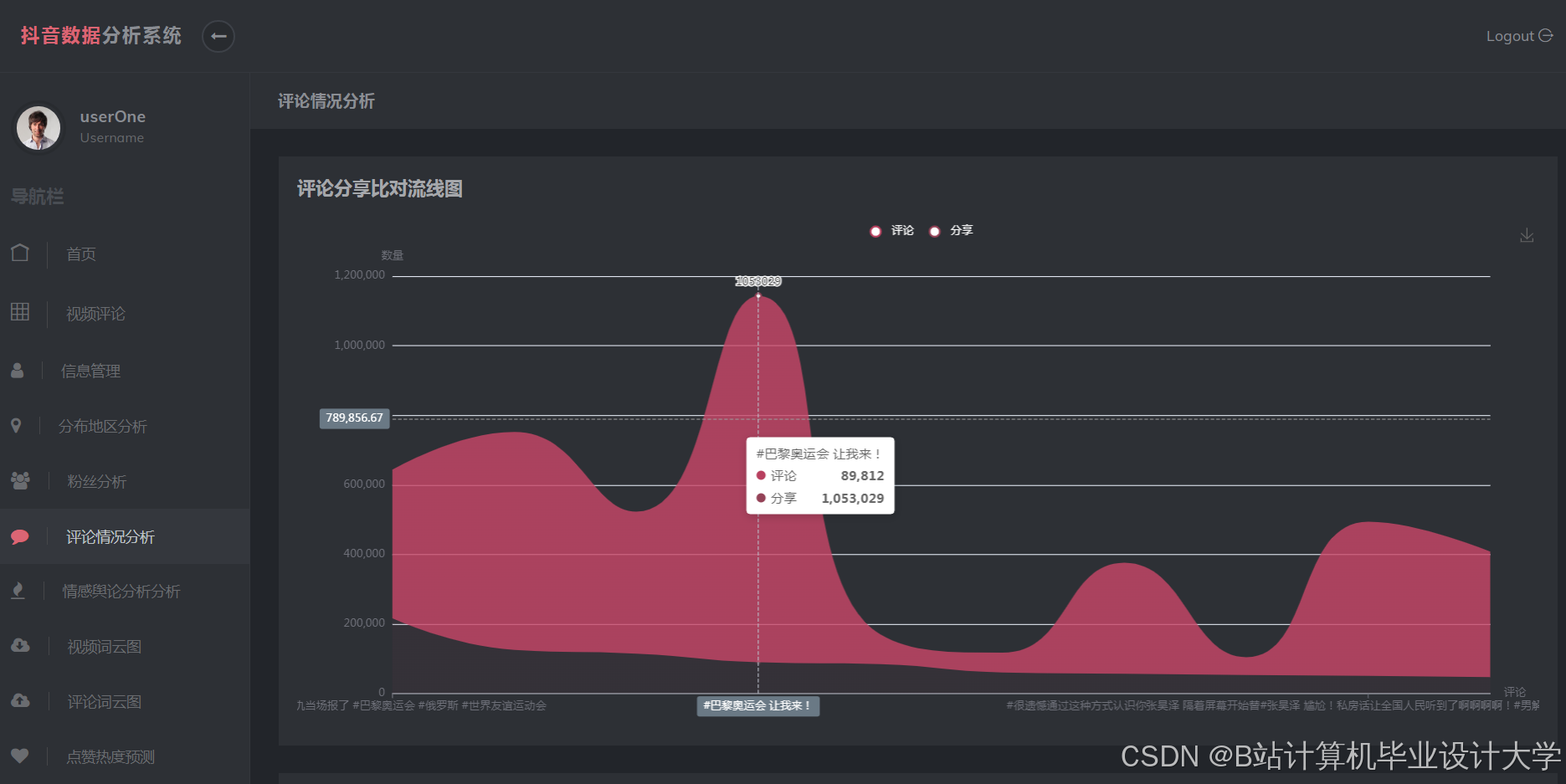
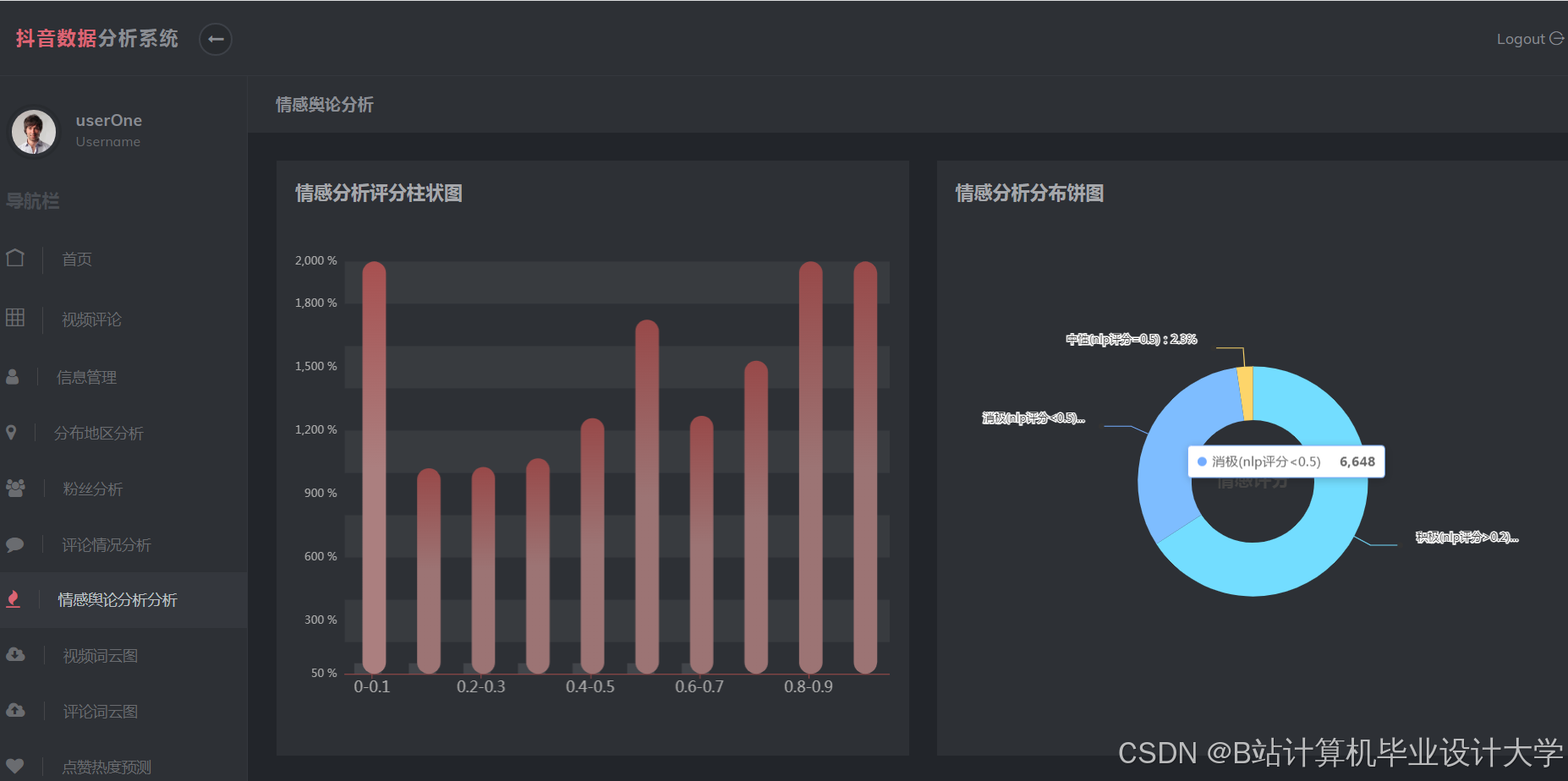
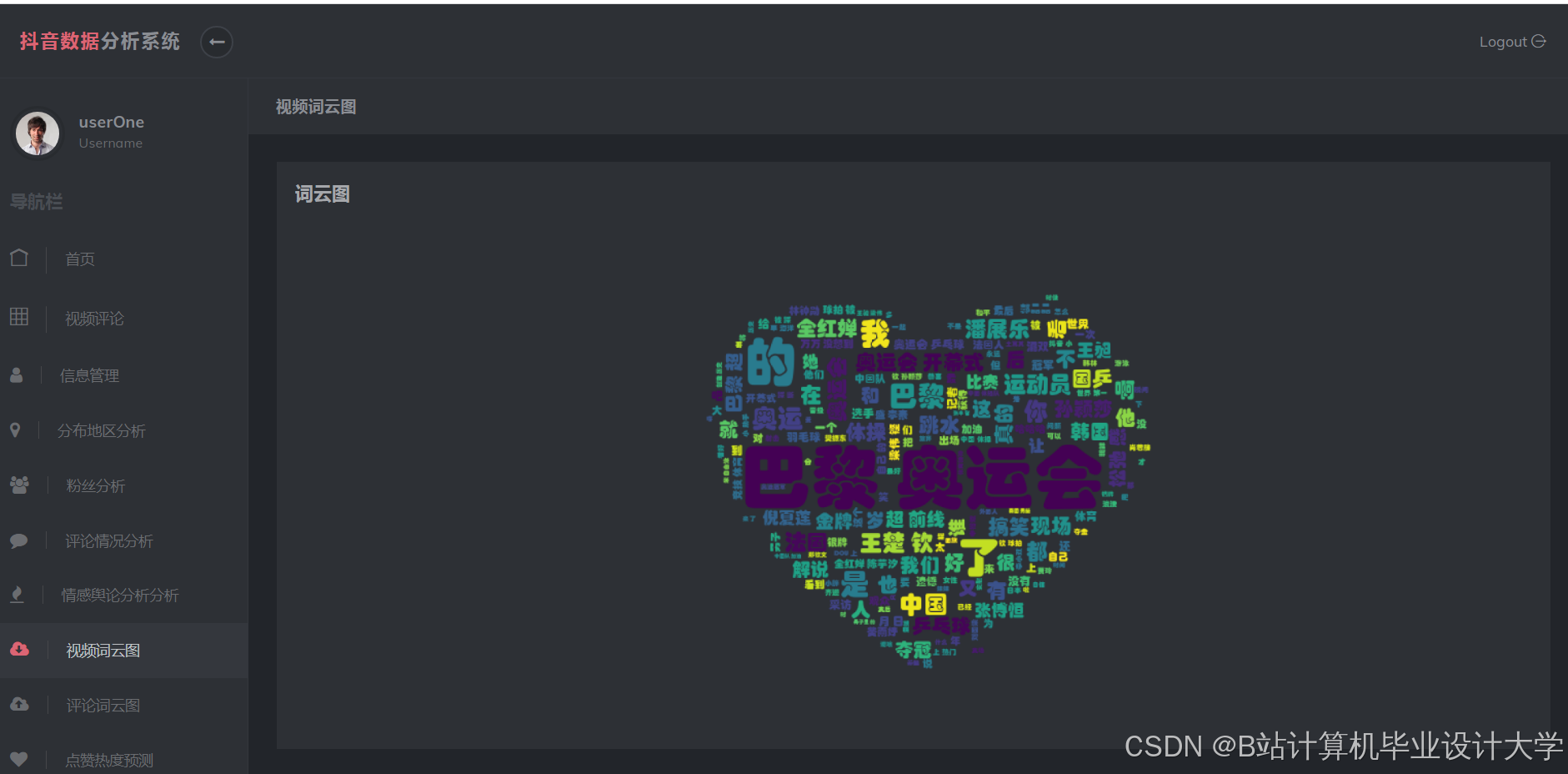

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











