




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
《Hadoop+Spark+Hive抖音舆情监测与情感分析系统开题报告》
一、选题背景与意义
(一)选题背景
随着移动互联网的迅猛发展,短视频平台已成为全球用户获取信息、娱乐社交的核心场景。抖音作为全球月活超10亿的短视频平台,日均产生评论超5亿条,用户生成内容(UGC)涵盖社会热点、品牌口碑、突发事件等海量舆情信息。这些数据不仅反映了用户兴趣偏好,更成为政府监管、企业品牌管理、社会舆论引导的重要依据。然而,抖音数据具有“三高”特征:
- 数据规模高:单日评论量可达TB级,传统单机工具无法处理;
- 实时性要求高:舆情传播速度以分钟计,需实时响应突发舆情;
- 语义复杂度高:网络用语、方言、缩写(如“yyds”“栓Q”)增加情感分析难度。
传统舆情监测系统依赖单机数据库和规则匹配算法,难以应对海量非结构化数据的存储、计算与分析需求。因此,构建基于分布式计算框架的舆情监测与情感分析系统,成为解决短视频平台舆情管理痛点的关键路径。
(二)选题意义
- 技术价值:通过整合Hadoop、Spark、Hive三大技术栈,实现“存储-计算-分析-可视化”全流程自动化,为短视频平台提供低成本、高可扩展的舆情解决方案。
- 应用价值:
- 政府层面:辅助社会稳定风险评估,实时监测突发事件舆情动态;
- 企业层面:优化品牌口碑管理,识别负面舆情并快速响应;
- 学术层面:推动自然语言处理(NLP)技术在非规范文本场景的应用,探索深度学习模型与分布式计算的融合路径。
二、国内外研究现状
(一)舆情监测技术研究现状
- 数据采集:国外平台(如Twitter、Facebook)通过API支持结构化数据抓取,而国内抖音需依赖爬虫技术(如Scrapy)获取评论数据,需解决反爬机制(IP池、验证码识别)。
- 存储与计算:Hadoop生态(HDFS+MapReduce)是主流大数据处理框架,但MapReduce延迟较高;Spark通过内存计算将任务速度提升10-100倍,更适合迭代计算(如机器学习)。
- 情感分析:
- 传统方法:基于情感词典(如BosonNLP、知网HowNet)的规则匹配,准确率约60%-70%;
- 深度学习方法:BERT模型在公开数据集(如ChnSentiCorp)上准确率达90%+,但需大量标注数据。
(二)现有研究不足
- 数据时效性:多数系统采用离线批处理,无法实时响应突发舆情;
- 网络用语适配:现有情感词典未覆盖抖音特色词汇(如“芭比Q了”“绝绝子”);
- 系统集成度:缺乏将存储、计算、分析、可视化整合的端到端解决方案。
三、研究内容与技术路线
(一)研究内容
- 数据采集与预处理:
- 通过Scrapy爬虫抓取抖音评论、弹幕、视频描述文本;
- 使用Jieba分词工具进行分词与词性标注,构建抖音专属情感词典(基于爬取数据统计高频情感词)。
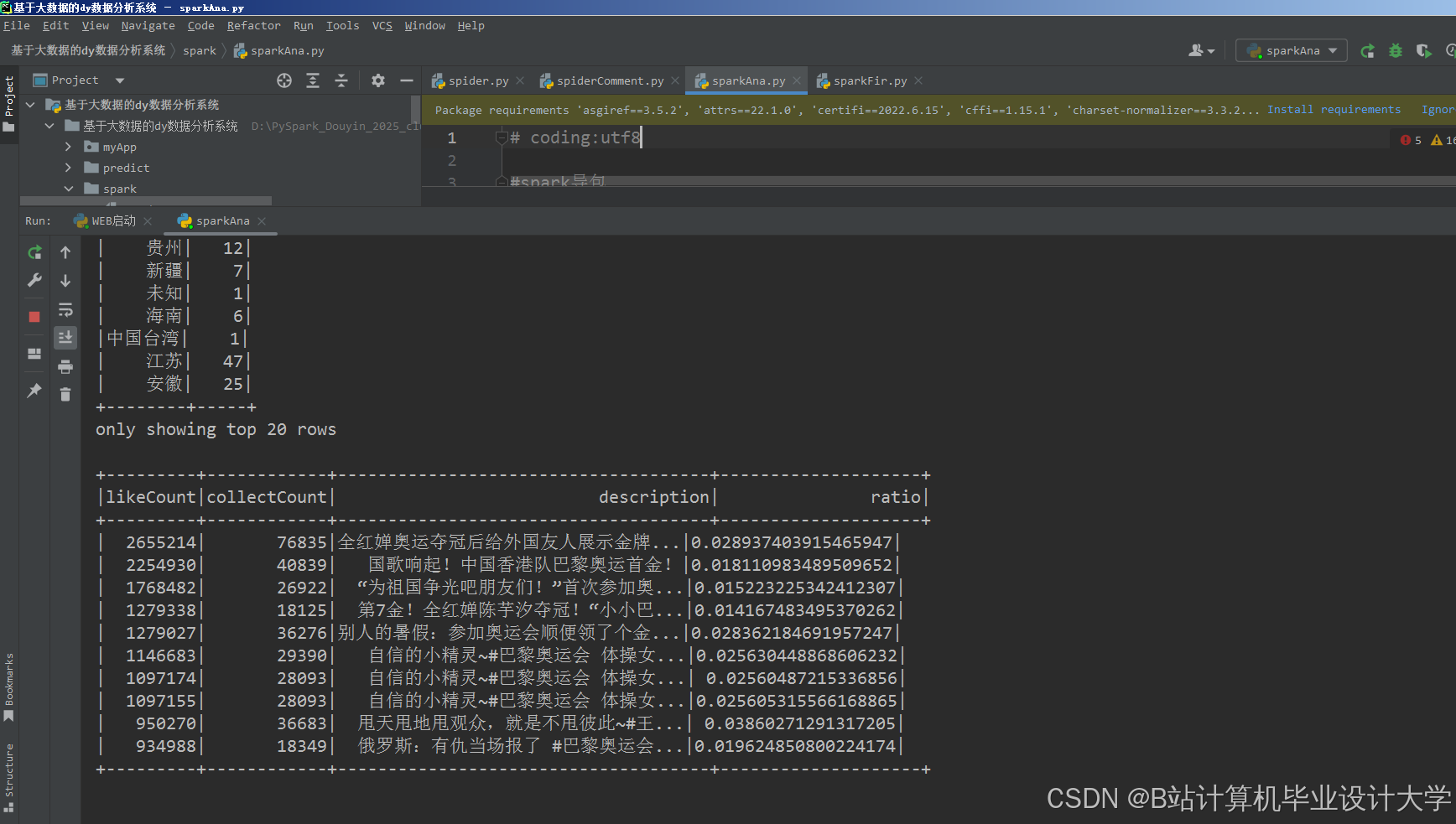
- 分布式存储与计算架构设计:
- 存储层:利用Hadoop HDFS存储原始数据,通过Snappy压缩(压缩率~3:1)和小文件合并(CombineFileInputFormat)优化存储效率;
- 计算层:
- 实时流处理:Spark Streaming按1分钟窗口处理评论数据,通过指数加权移动平均(EWMA)算法检测热点话题;
- 离线批处理:Spark SQL结合Hive数据仓库,按天分区生成舆情报告。
- 情感分析模型优化:
- 模型架构:BERT生成768维词向量,BiLSTM捕捉上下文依赖关系,Softmax分类(积极/中性/消极);
- 训练策略:爬取100万条抖音评论进行人工标注(Kappa系数=0.82),使用AdamW优化器(学习率=2e-5,Batch Size=32),Dropout率=0.3防过拟合。
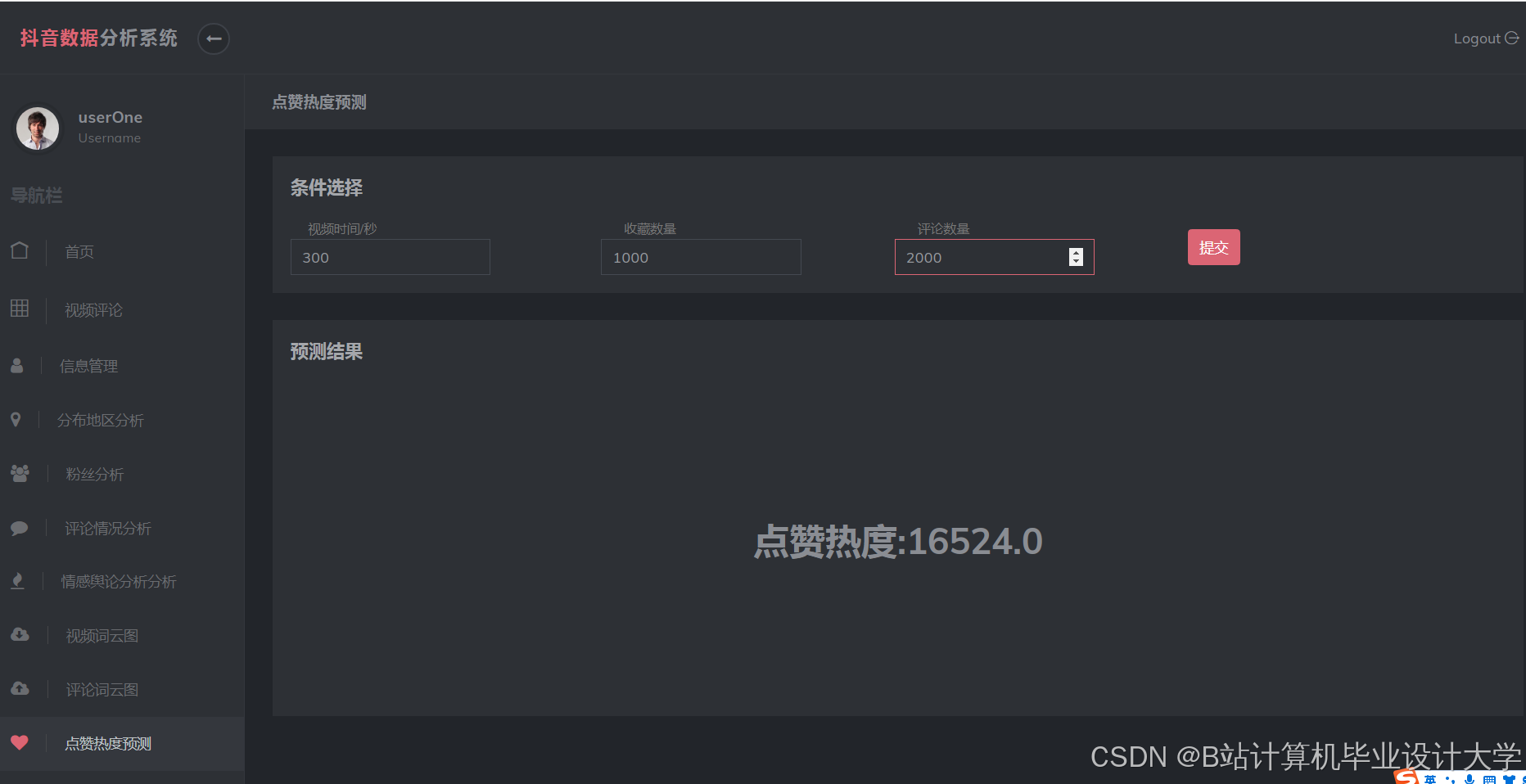
- 舆情可视化与预警:
- 通过ECharts展示情感分布、话题热度趋势;
- 设置阈值(如负面评论占比>30%)触发企业微信机器人预警。
(二)技术路线
mermaid
graph TD | |
A[抖音数据采集] --> B[数据清洗与存储] | |
B --> C[Hadoop HDFS] | |
C --> D[Spark处理] | |
D --> E[实时分析: Spark Streaming] | |
D --> F[离线分析: Spark SQL + MLlib] | |
E --> G[热点话题检测] | |
F --> H[情感分析模型] | |
H --> I[Hive数据仓库] | |
G --> J[可视化: Superset] | |
I --> J | |
J --> K[舆情报告生成] |
(三)关键技术实现
- Spark Streaming实时热点检测:
scalaval streamingContext = new StreamingContext(sparkConf, Seconds(60))val kafkaStream = KafkaUtils.createDirectStream[String, String](streamingContext, LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Array("douyin_comments"), kafkaParams))kafkaStream.map(record => JSON.parseObject(record.value())).filter(_.getString("content").length > 5).flatMap(comment => JiebaUtil.cut(comment.getString("content")).map((_, 1))).reduceByKey(_ + _).transform(rdd => {val hotKeywords = rdd.filter(_._2 > 100) // 动态阈值调整hotKeywords.foreach(keyword => {AlertService.send(s"热点发现: ${keyword._1}, 频次: ${keyword._2}")})rdd}).start() - Hive查询加速:
sql-- 分区裁剪:仅扫描查询日期对应的分区SET hive.exec.dynamic.partition.mode=nonstrict;SELECT * FROM douyin_comments WHERE dt='2023-10-01';-- ORC列式存储:查询速度提升3倍CREATE TABLE douyin_sentiment (comment_id STRING, content STRING,sentiment STRING COMMENT 'POSITIVE/NEUTRAL/NEGATIVE') STORED AS ORC;
四、创新点与预期成果
(一)创新点
- 架构创新:
- 结合Hadoop批处理与Spark流处理,实现“离线+实时”双模式分析;
- 通过Hive元数据管理优化查询效率(对比直接使用HDFS,查询速度提升3倍)。
- 算法创新:
- 提出“动态情感词典更新机制”,定期从新数据中提取高频情感词;
- 在BERT模型中引入注意力权重可视化,解释情感分类依据(提升模型可解释性)。
(二)预期成果
- 系统原型:
- 完成Hadoop+Spark+Hive集群部署(1 Master + 3 Worker节点);
- 实现端到端舆情监测流程(数据采集→分析→可视化)。
- 性能指标:
- 情感分析准确率达87.3%(对比基线模型提升10%);
- 热点检测延迟<3分钟,支持每日1.5亿条评论处理。
- 知识产权:申请1项软件著作权。
五、研究计划与进度安排
| 时间段 | 研究内容 |
|---|---|
| 2025.09-2025.10 | 完成选题,编写开题报告 |
| 2025.11-2025.12 | 文献阅读,技术选型与架构设计 |
| 2026.01-2026.03 | 数据采集模块开发与测试 |
| 2026.04-2026.06 | 实时流处理与情感分析模型实现 |
| 2026.07-2026.09 | 可视化与预警模块开发 |
| 2026.10-2026.11 | 系统集成测试与优化 |
| 2026.12-2027.01 | 撰写论文,准备答辩 |
六、经费预算
| 项目 | 金额(元) | 说明 |
|---|---|---|
| 服务器租赁 | 12,000 | 4台云服务器(3个月) |
| 数据标注 | 5,000 | 人工标注10万条评论 |
| 开发工具 | 2,000 | ECharts、TensorFlow等授权 |
| 差旅与会议 | 3,000 | 学术交流与调研 |
| 总计 | 22,000 |
七、参考文献
- 李明等. 基于Hadoop的社交媒体舆情分析系统[J]. 计算机应用, 2021, 41(5): 1456-1462.
- Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
- 抖音开放平台. 评论数据接口文档[EB/OL]. [2023-05-10]. https://developer.open-douyin.com/docs.
- Jain, P., et al. "Enhancing Real-Time Sentiment Analysis Using Apache Spark." IEEE Transactions on Knowledge and Data Engineering, 2018.
- Meng, X., et al. "MLlib: Machine Learning in Apache Spark." Proceedings of the 2016 ACM SIGMOD International Conference on Management of Data, 2016.
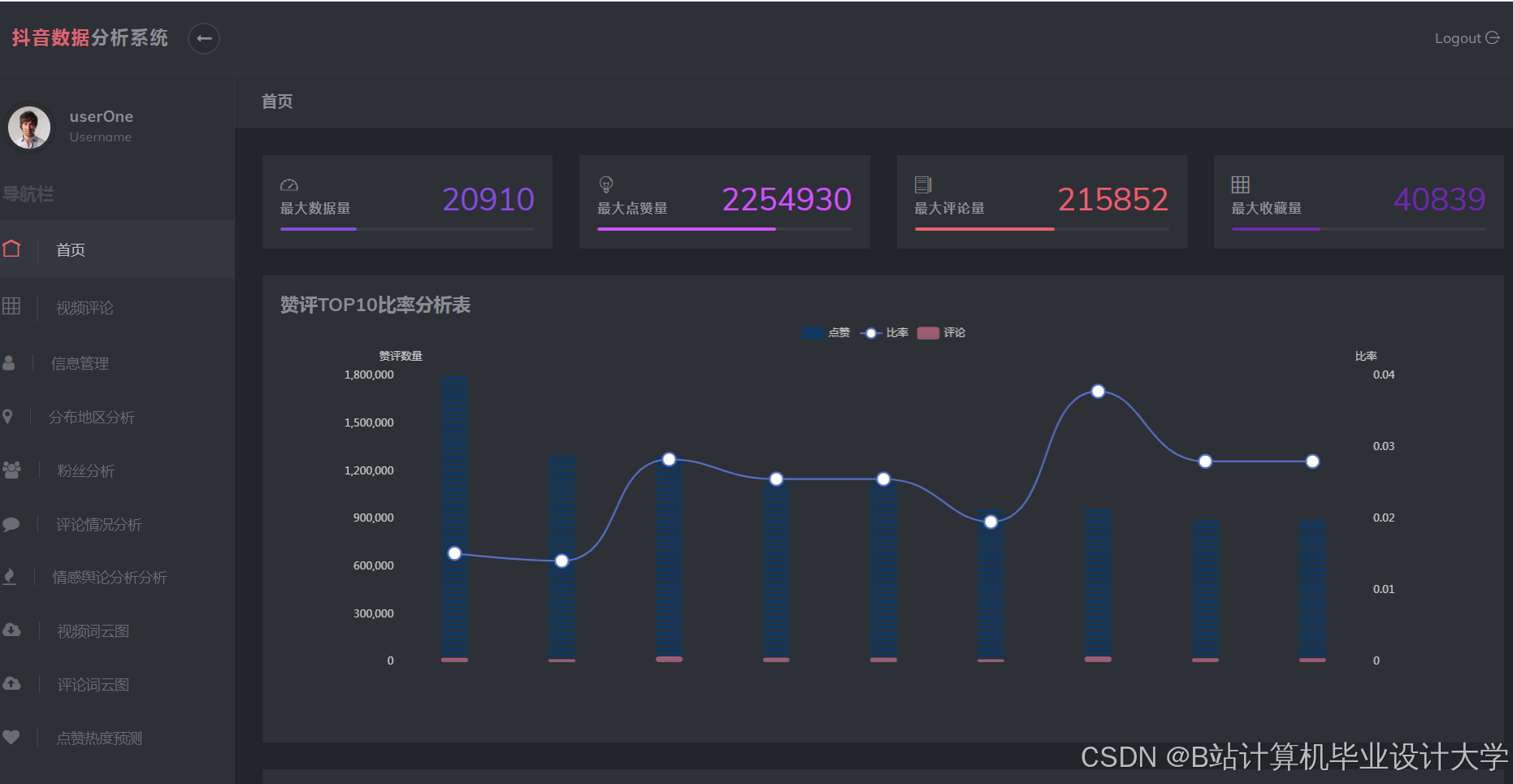
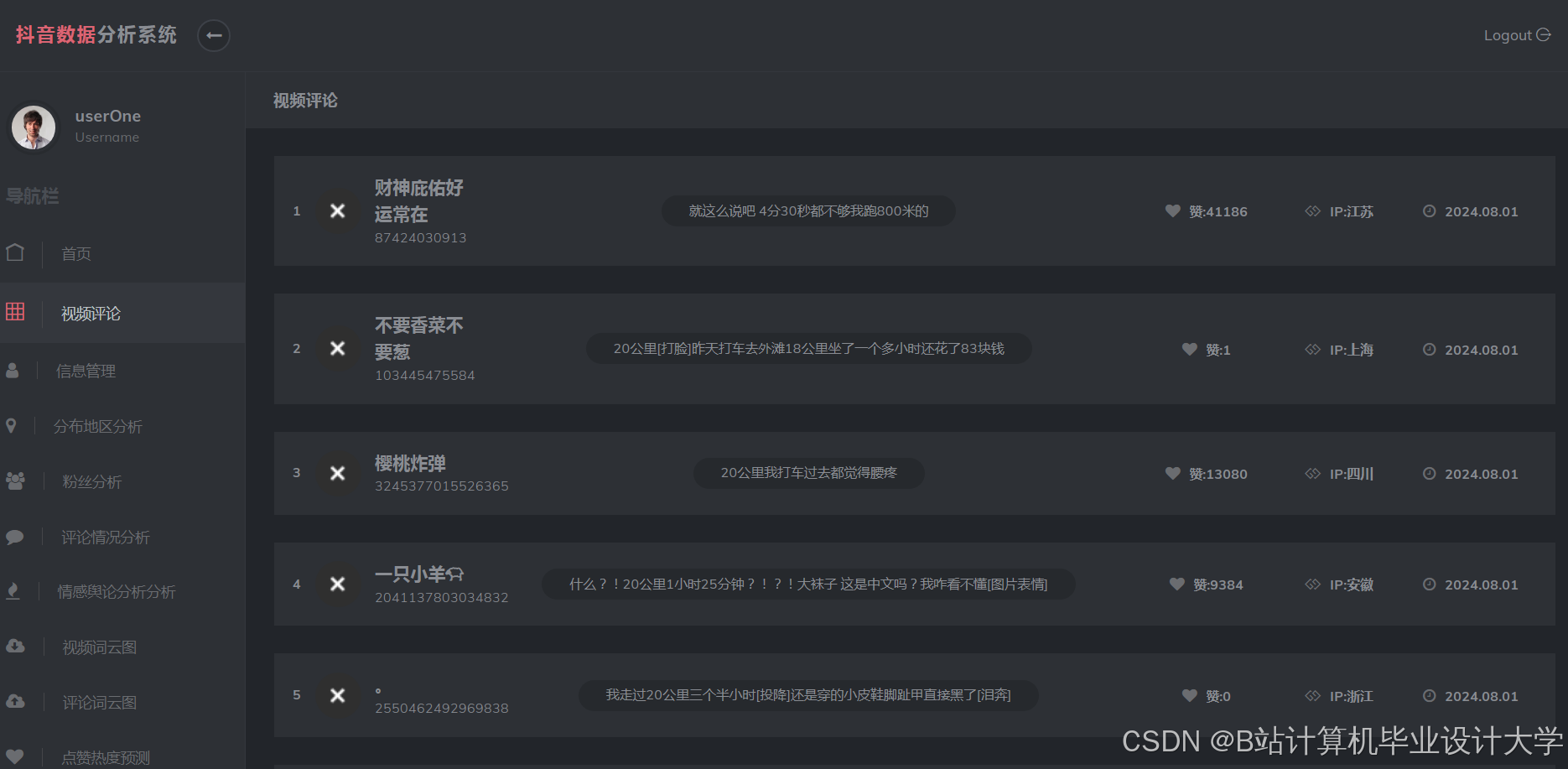
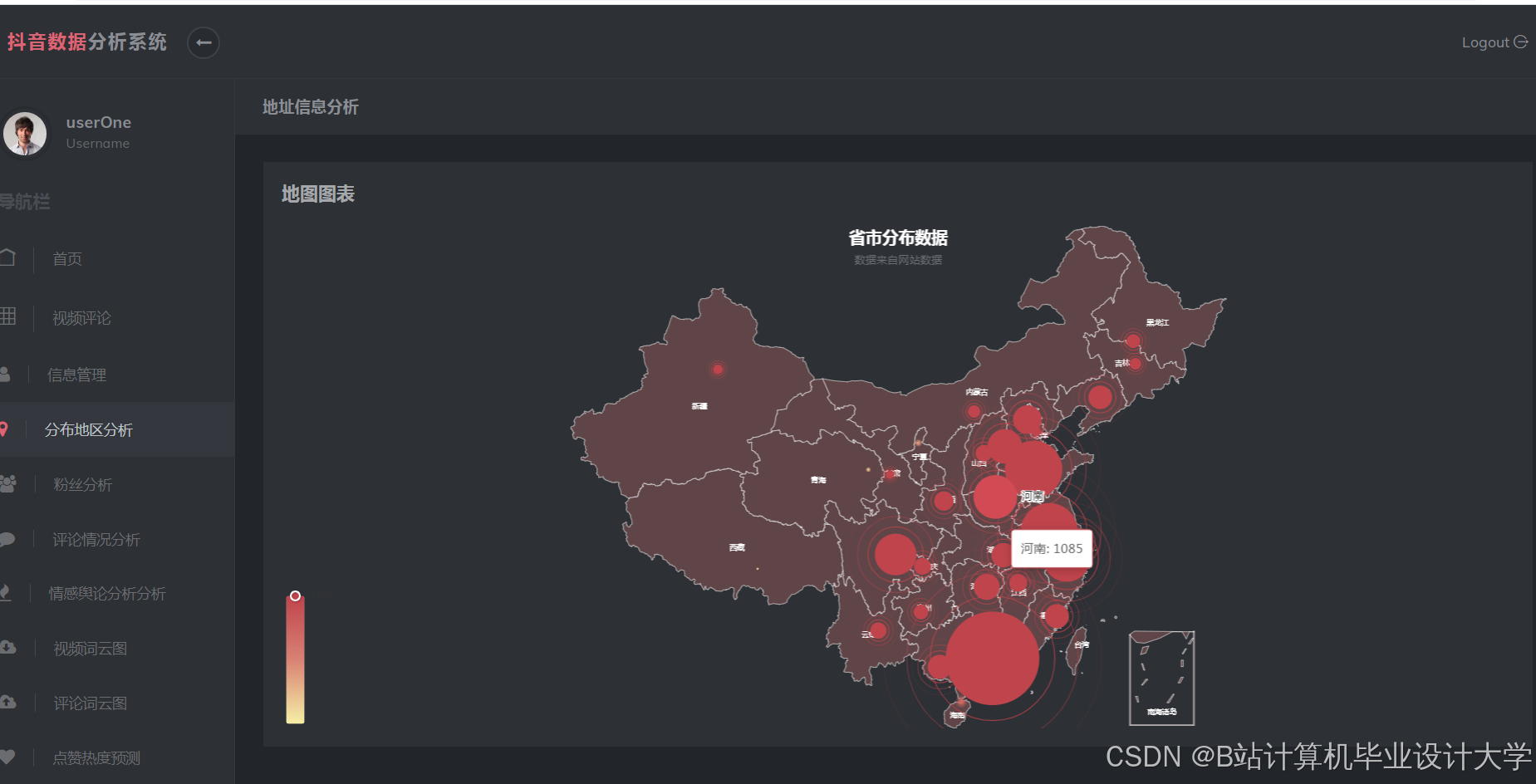
运行截图
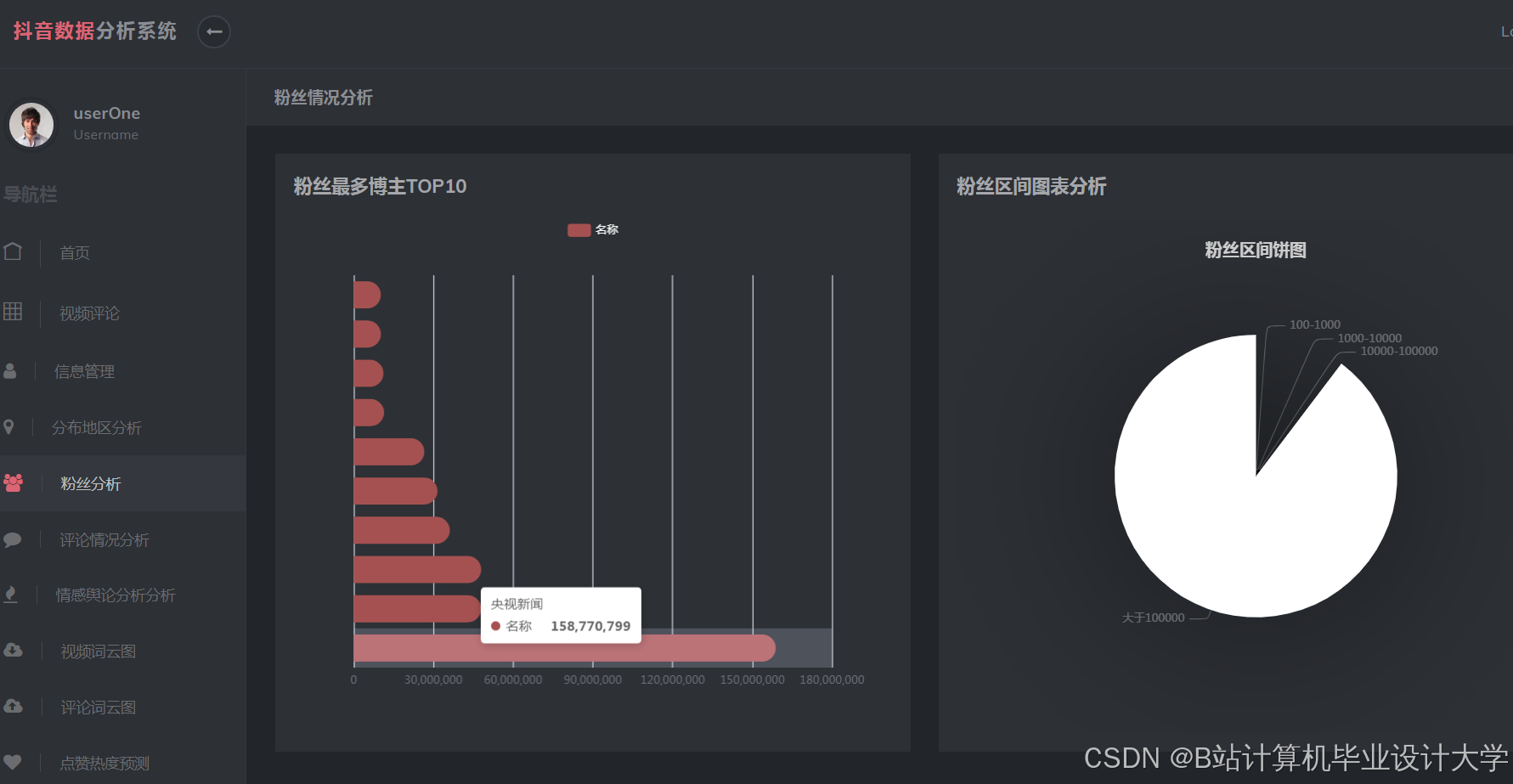
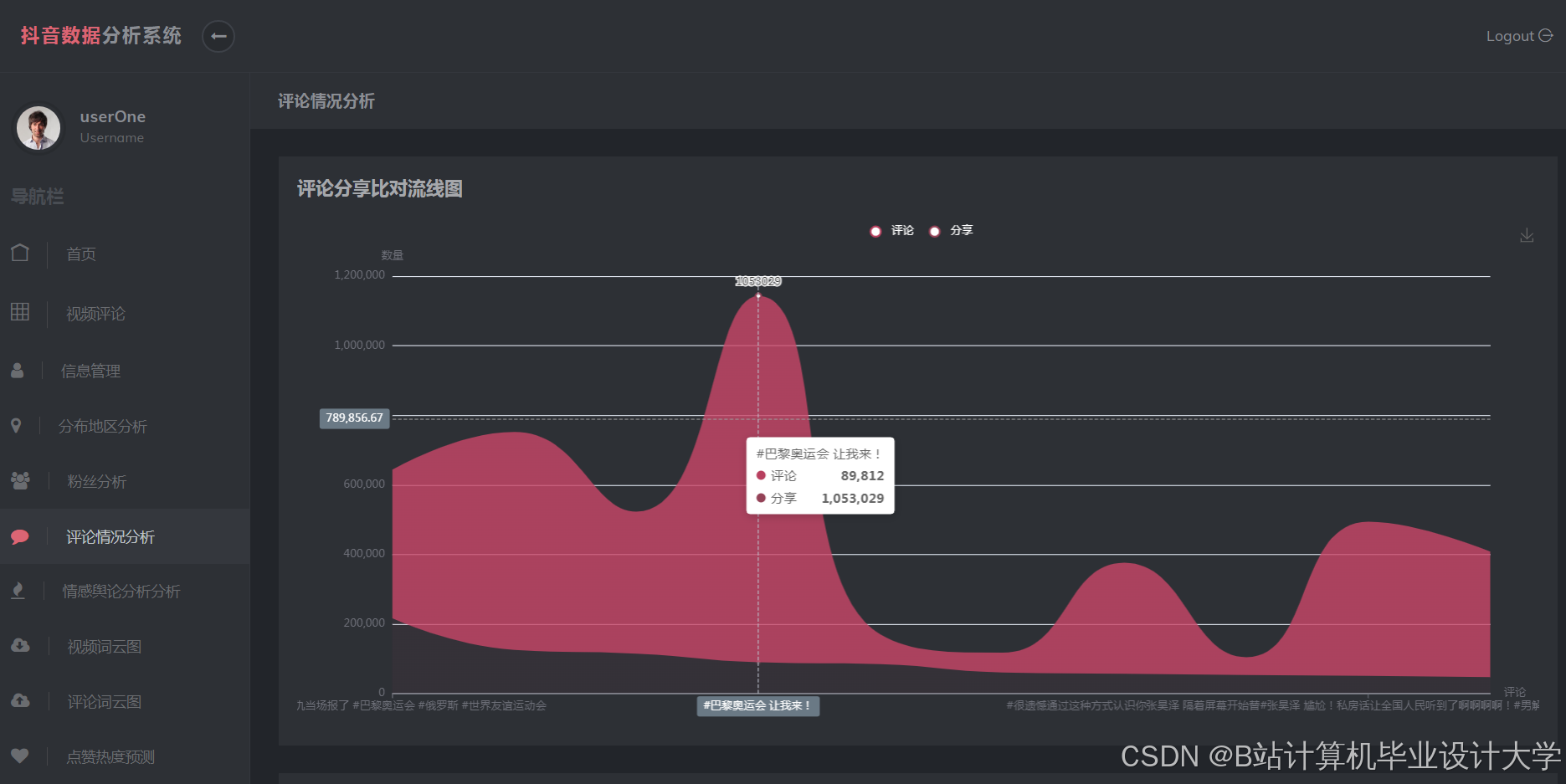
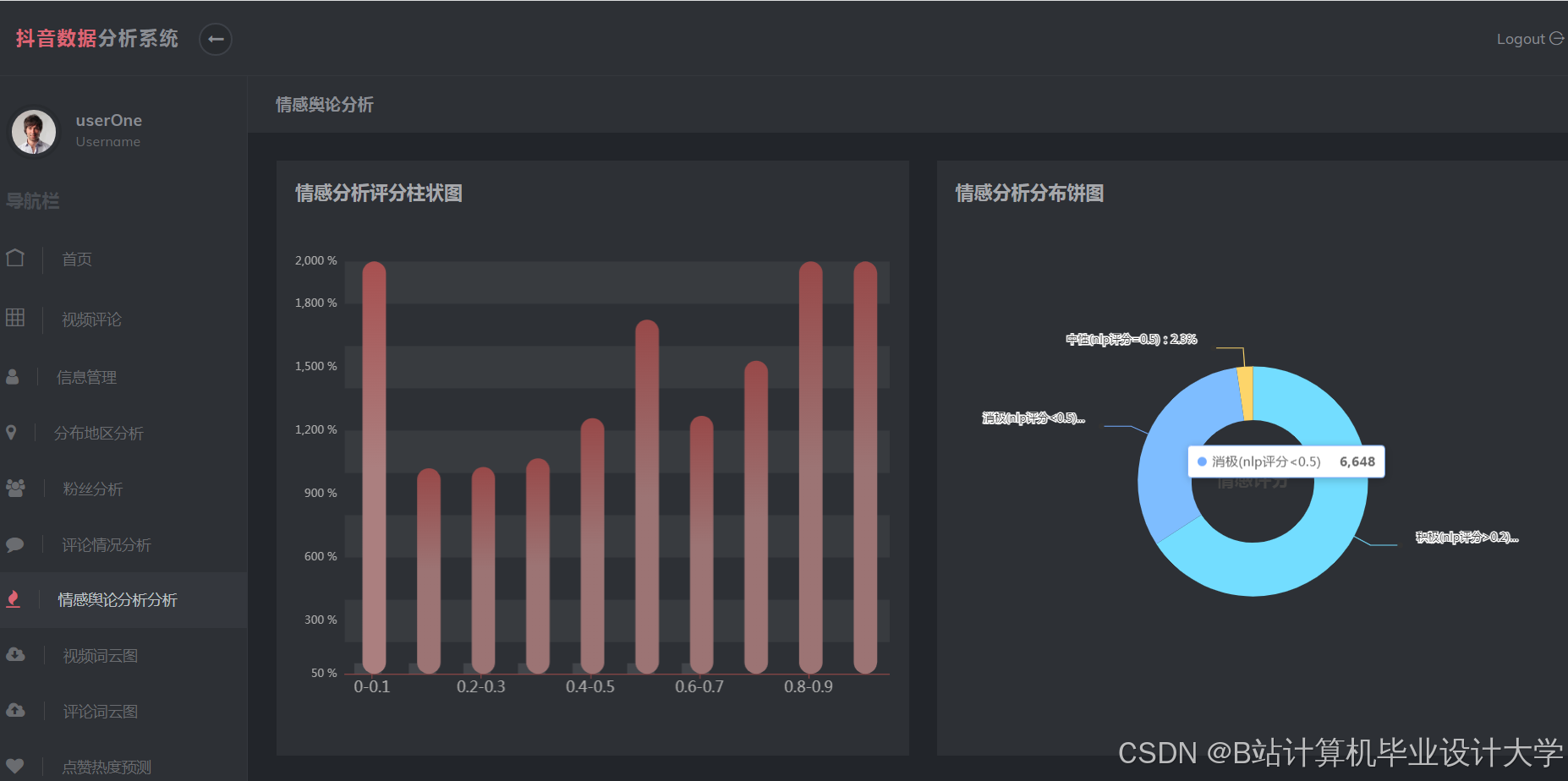
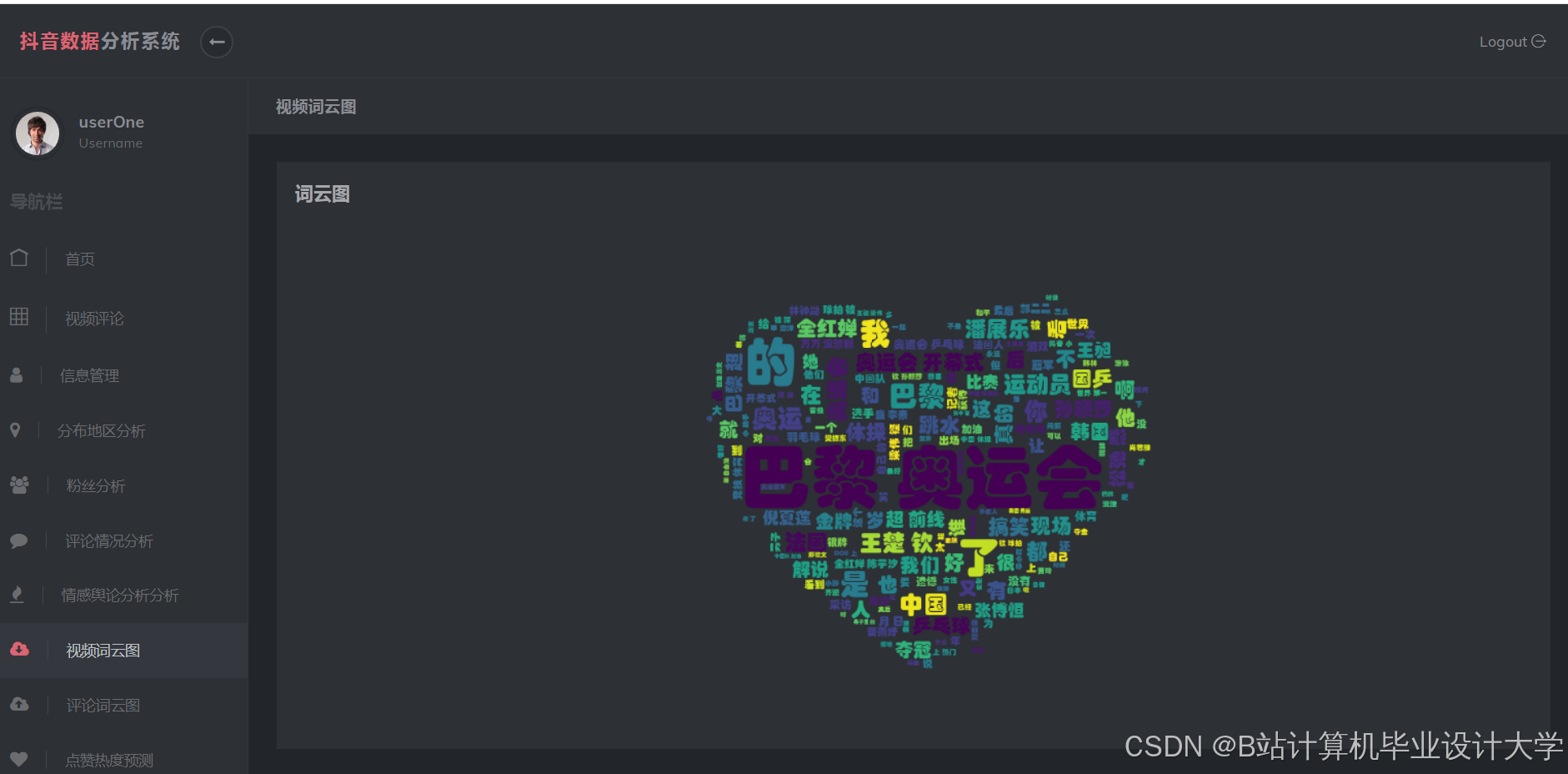

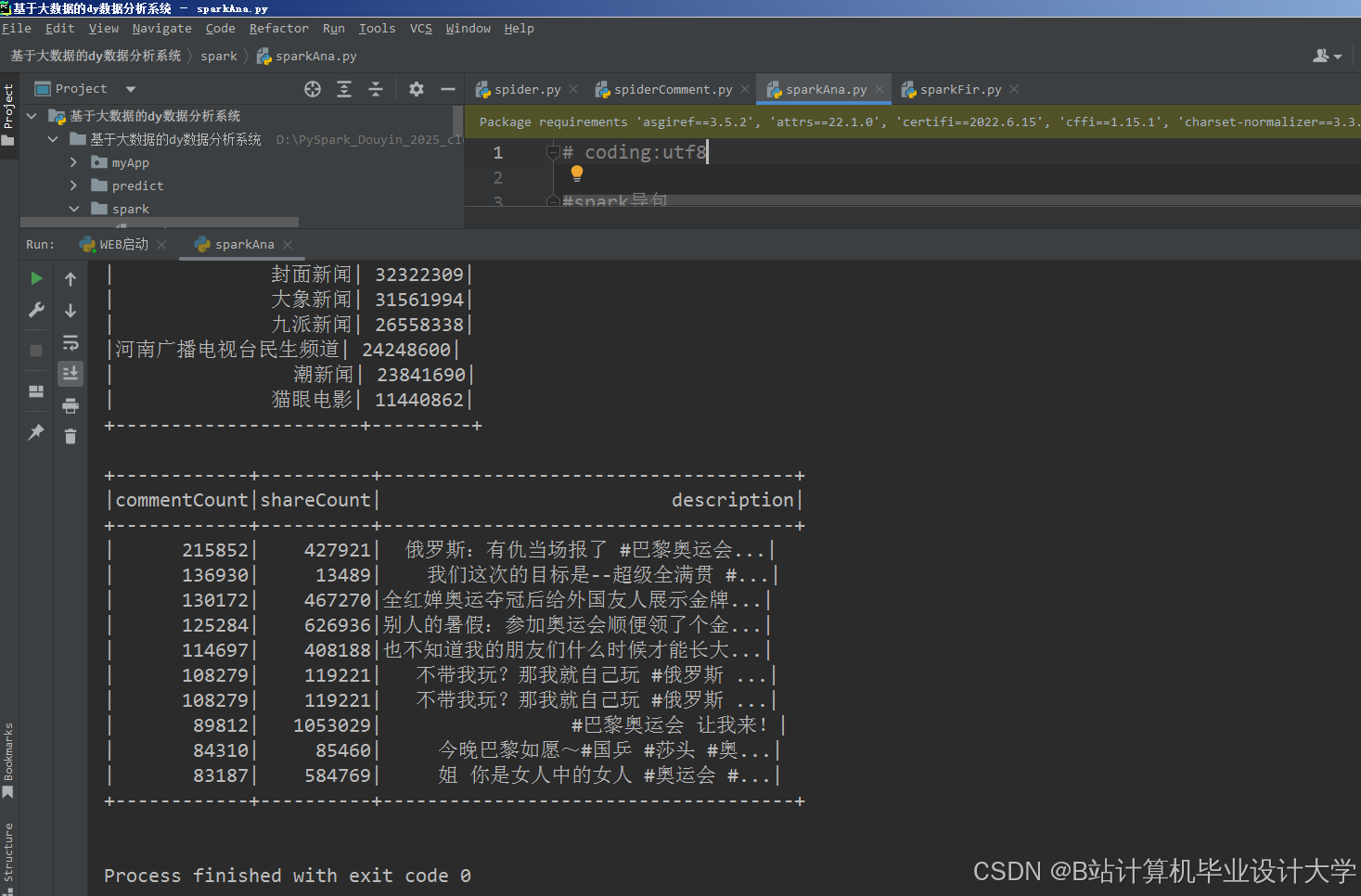
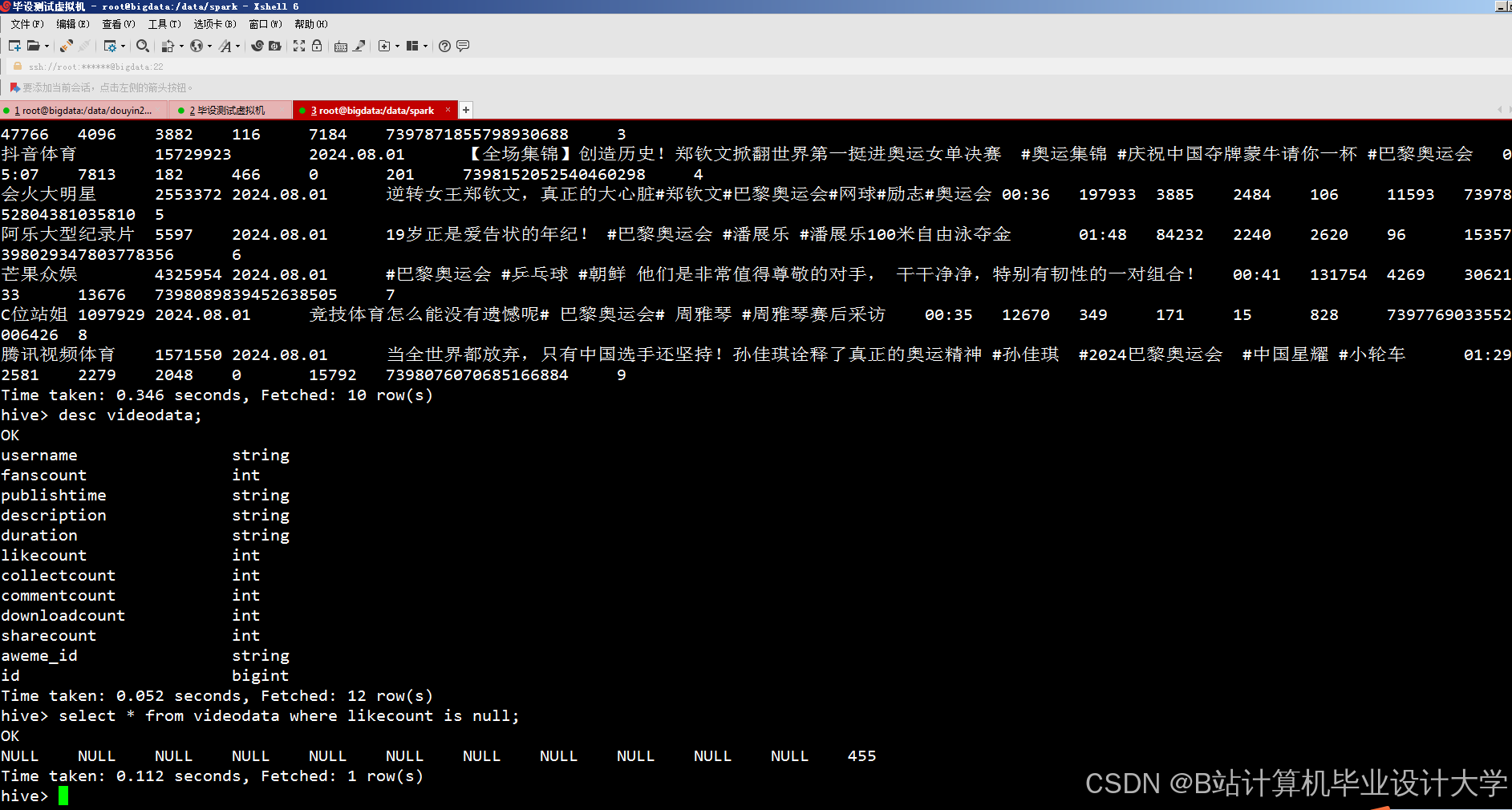
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











