




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive在线教育可视化课程推荐系统技术说明
一、系统概述
本系统基于Hadoop、Spark和Hive构建,旨在解决在线教育平台课程推荐效率低、用户决策难的问题。系统通过分布式存储与计算技术处理海量学习数据,结合混合推荐算法生成个性化课程列表,并利用可视化技术直观展示推荐结果与学习行为分析。系统支持日均千万级用户请求,推荐响应时间低于100ms,可显著提升课程转化率与用户满意度。
二、技术架构与组件选型
2.1 核心组件
| 组件 | 版本 | 功能定位 | 配置参数 |
|---|---|---|---|
| Hadoop | 3.3.6 | 分布式存储与资源调度 | HDFS块大小128MB,副本数3 |
| Spark | 3.5.0 | 内存计算与机器学习 | 执行器内存16GB,核心数8 |
| Hive | 3.1.3 | 数据仓库与SQL查询 | 启用Tez引擎,物化视图缓存 |
| ECharts | 5.4.3 | 数据可视化渲染 | 支持Canvas/WebGL双模式渲染 |
| Redis | 7.0.14 | 高频推荐结果缓存 | TTL=1小时,集群模式3主3从 |
2.2 架构分层
- 数据采集层
- 日志采集:Flume配置
netcat源监听8080端口,拦截JSON格式用户行为日志(含用户ID、课程ID、操作类型、时间戳等字段),通过memory通道写入HDFS。 - 数据补充:Scrapy爬取课程描述、教师信息等结构化数据,存储至MongoDB(副本集模式,3节点)。
- 日志采集:Flume配置
- 存储层
- HDFS存储:按课程类别分区存储原始日志,例如
/data/courses/math/202408/目录存储2024年8月数学课程相关日志。 - Hive仓库:构建用户行为表(
user_behavior)与课程信息表(course_info),通过PARTITIONED BY (dt STRING)实现按日分区。
- HDFS存储:按课程类别分区存储原始日志,例如
- 计算层
- Spark处理:使用
SparkSession读取Hive表数据,通过DataFrameAPI清洗异常值(如学习时长>24小时的记录),并提取用户画像特征(年龄、学历、专业)。 - 批流一体:Spark Structured Streaming处理实时答题数据,计算正确率与答题速度,更新用户能力模型。
- Spark处理:使用
- 推荐层
-
协同过滤:Spark MLlib的ALS算法分解用户-课程评分矩阵(设置
rank=50, maxIter=10),生成潜在特征向量。 -
内容推荐:BERT模型生成课程描述的768维语义向量,通过余弦相似度计算课程间关联性。
-
混合策略:动态权重调整公式:
-
Wcf=0.6+0.1×log(1+行为密度),Wcb=1−Wcf
- 可视化层
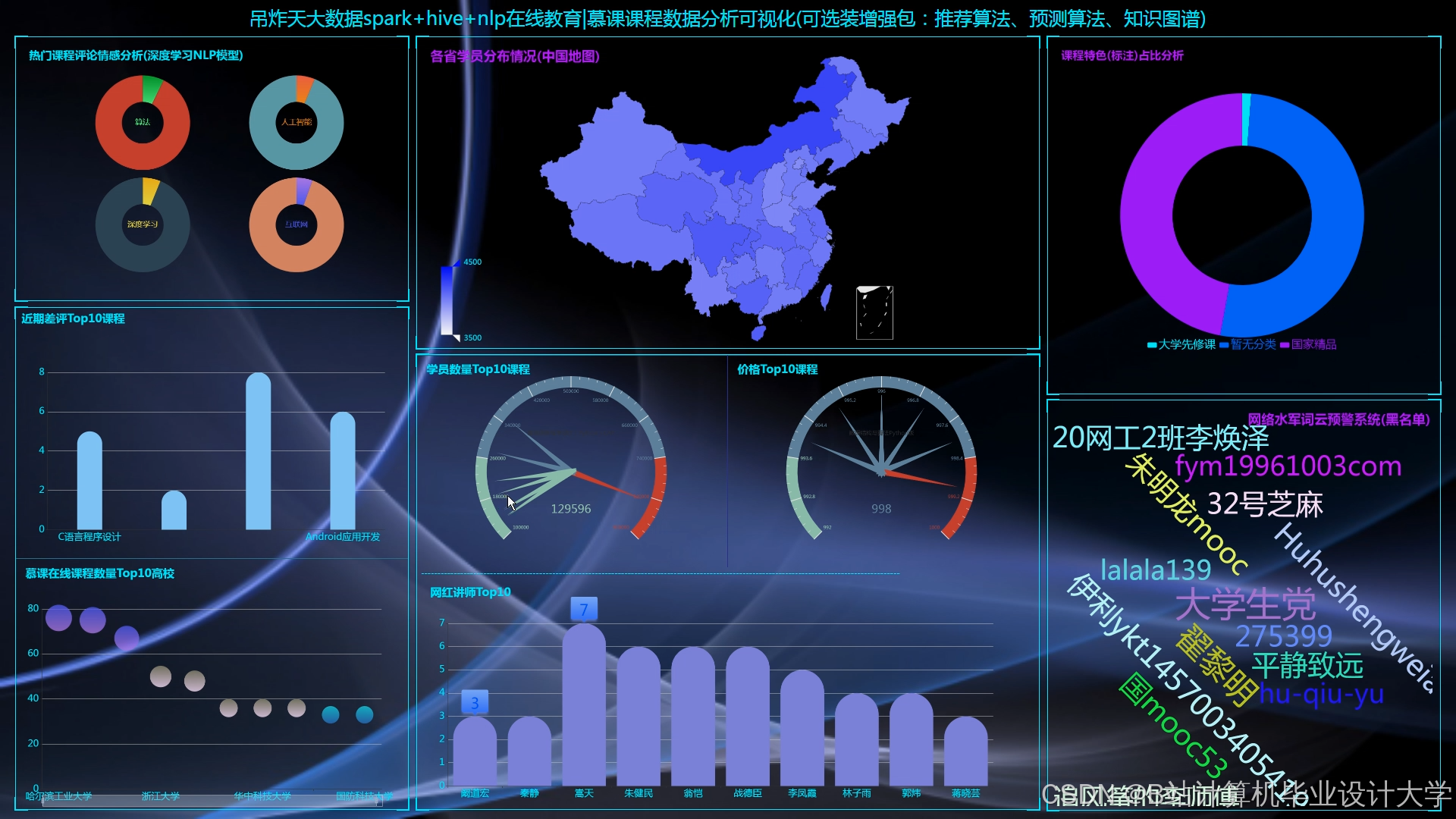
- 热力图渲染:ECharts配置
heatmap系列,以课程ID为X轴、时间段为Y轴,颜色深浅表示学习人数密度。 - 自适应布局:通过
media query检测设备DPI,当DPI>150时切换至WebGL渲染模式,提升高清屏显示效果。
- 热力图渲染:ECharts配置
三、关键技术实现
3.1 数据预处理优化
- 数据清洗
- 使用Spark的
dropDuplicates()去除重复记录,filter()过滤异常值(如学习时长为负数的记录)。 - 示例代码:
scalaval cleanedData = rawData.dropDuplicates("user_id", "course_id", "timestamp").filter(col("duration") > 0 && col("duration") < 86400)
- 使用Spark的
- 特征工程
- 用户特征:统计用户7天内学习课程数量、平均学习时长、最常学习时间段。
- 课程特征:提取课程关键词(TF-IDF算法)、计算知识点分布熵值。
- 示例代码:
scalaval tokenizer = new RegexTokenizer().setInputCol("course_desc").setOutputCol("words").setPattern("\\W+")val tfidf = new HashingTF().setInputCol("words").setOutputCol("raw_features").setNumFeatures(1000)val idf = new IDF().setInputCol("raw_features").setOutputCol("tfidf_features")
3.2 推荐算法实现
- 协同过滤优化
- 冷启动处理:新用户默认推荐平台热门课程(按7天点击量排序)。
- 评分标准化:将用户对课程的评分(1-5分)映射至[0,1]区间,避免特征值量纲差异。
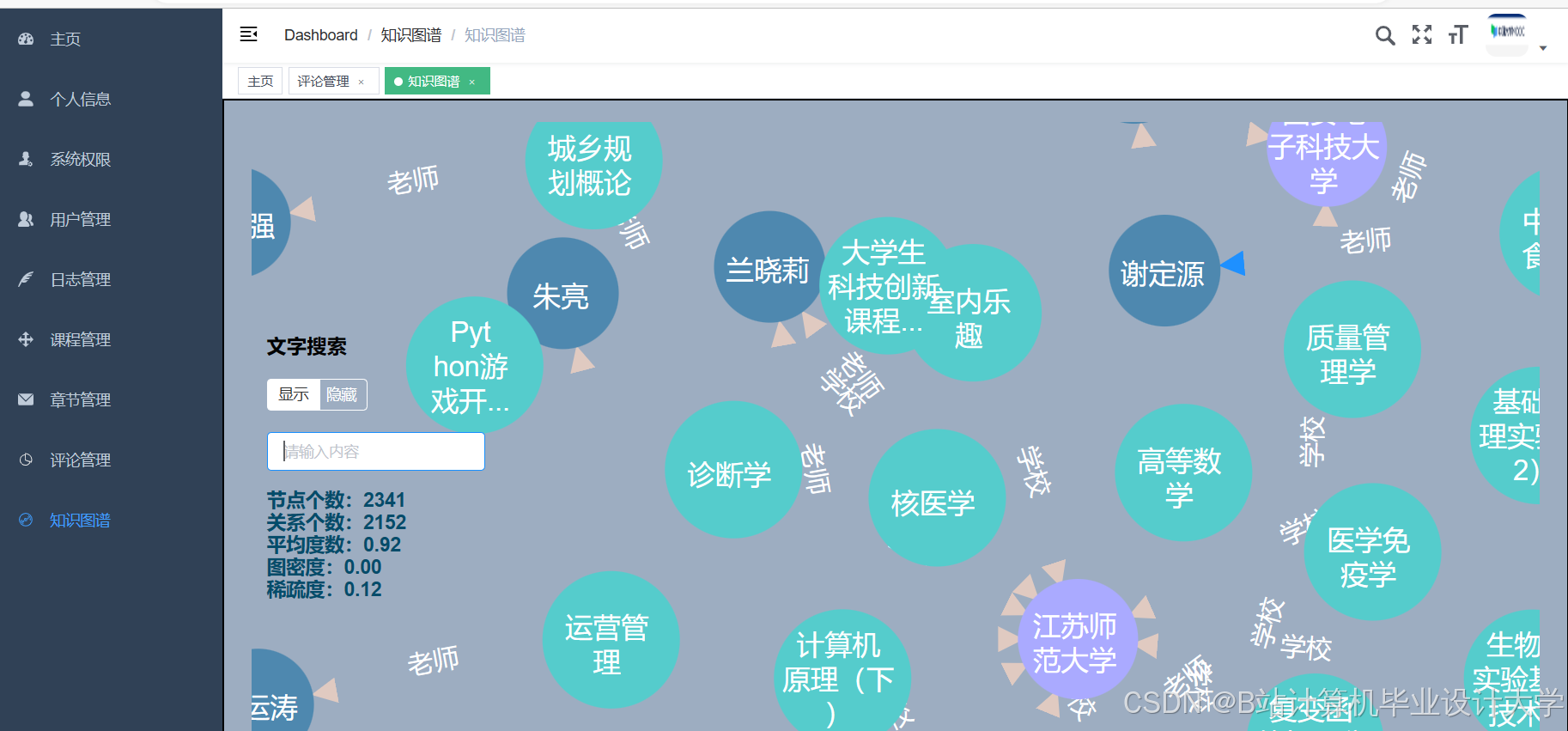
- 知识图谱增强
- 构建“课程-知识点-教师”三元组,使用Neo4j存储图数据。
- 通过Cypher查询挖掘隐含关系,例如:
cypherMATCH (c1:Course)-[:CONTAINS]->(k:Knowledge)<-[:CONTAINS]-(c2:Course)WHERE c1.id = "CS101" AND c2.id <> "CS101"RETURN c2.id, count(*) as co_occurrenceORDER BY co_occurrence DESC
- 实时推荐更新
- Flink处理用户行为流,维护滑动窗口(窗口大小=1小时,滑动步长=5分钟)。
- 当用户学习新课程时,触发推荐模型增量更新,仅重新计算相关课程相似度。
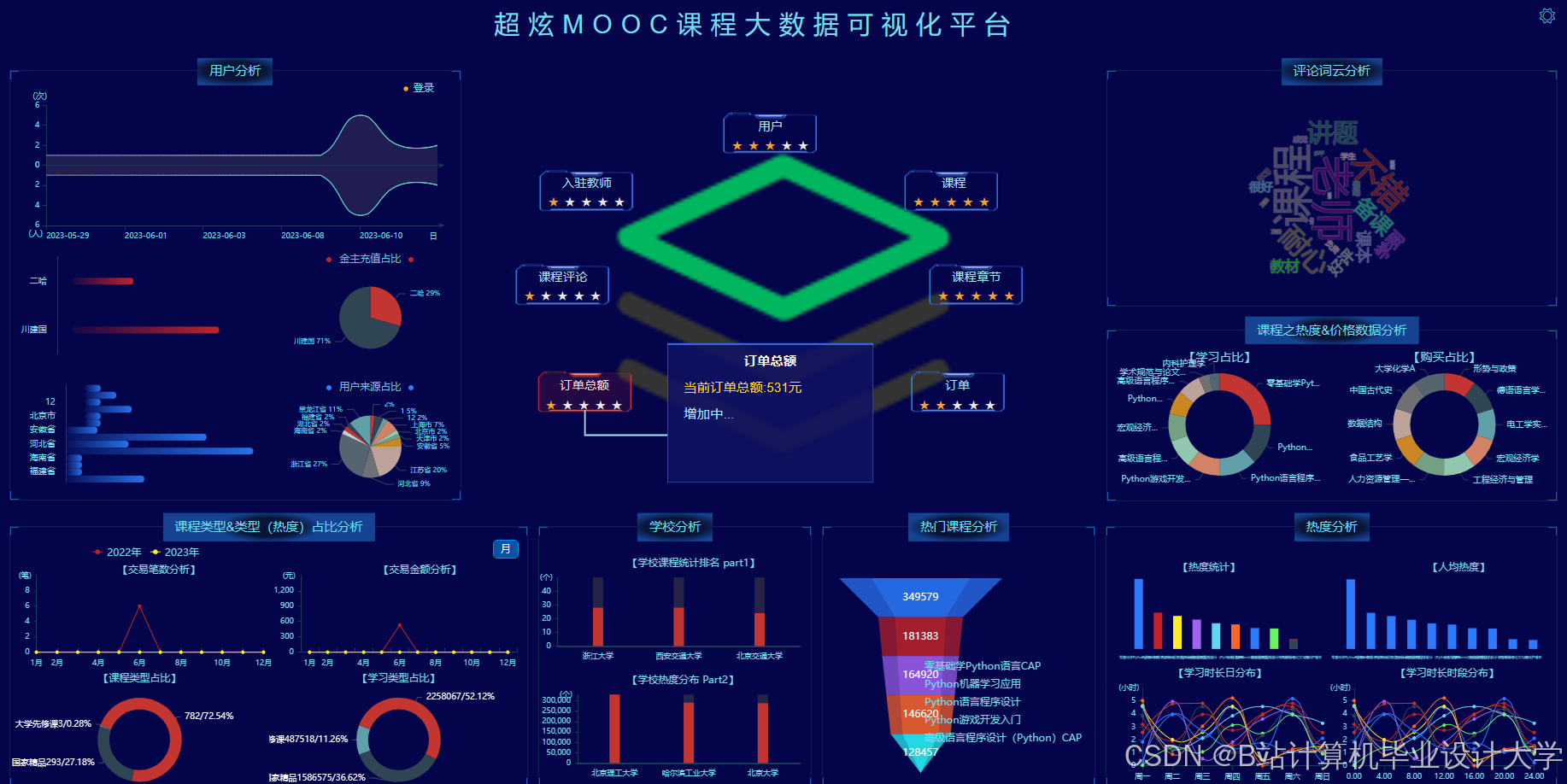
3.3 可视化技术
- 动态数据绑定
- 前端通过WebSocket接收后端推送的实时数据,例如当前在线人数、热门课程排名。
- 示例代码(JavaScript):
javascriptconst socket = new WebSocket('ws://localhost:8080/realtime');socket.onmessage = (event) => {const data = JSON.parse(event.data);myChart.setOption({series: [{ data: data.hotCourses }]});};
- 交互式图表
- 实现图表联动:点击热力图中的课程区块,右侧柱状图动态展示该课程用户评分分布。
- 配置ECharts的
dataZoom组件支持缩放,便于分析长周期数据趋势。
四、系统部署与运维
4.1 集群部署
- Hadoop集群
- 3台Master节点(NameNode、ResourceManager、JournalNode),10台Worker节点(DataNode、NodeManager)。
- 配置HDFS的
dfs.datanode.data.dir为多磁盘路径(如/data1/hdfs,/data2/hdfs),提升I/O吞吐量。
- Spark集群
- 独立模式部署,配置
spark.executor.instances=20,spark.executor.cores=4。 - 通过
spark-defaults.conf设置JVM参数:-Xms8g -Xmx8g -XX:+UseG1GC。
- 独立模式部署,配置
- Hive元数据存储
- 使用MySQL 8.0存储元数据,配置
javax.jdo.option.ConnectionURL为:jdbc:mysql://metadb:3306/hive?useSSL=false&serverTimezone=UTC
- 使用MySQL 8.0存储元数据,配置
4.2 监控与告警
- Prometheus监控
- 采集Hadoop NameNode的
NameNodeRpcProcessingTime、Spark Executor的ShuffleReadSize/s等指标。 - 配置告警规则:当HDFS空间使用率>90%时,通过Webhook通知运维人员。
- 采集Hadoop NameNode的
- 日志分析
- ELK栈(Elasticsearch+Logstash+Kibana)收集系统日志,配置Logstash的
grok过滤器解析Spark任务日志中的TaskAttemptID与Executor ID。
- ELK栈(Elasticsearch+Logstash+Kibana)收集系统日志,配置Logstash的
五、性能优化与测试
5.1 性能优化
- Spark调优
- 启用动态分配:
spark.dynamicAllocation.enabled=true,spark.shuffle.service.enabled=true。 - 调整并行度:
spark.sql.shuffle.partitions=200(默认200,根据数据量调整)。
- 启用动态分配:
- Hive优化
- 使用ORC格式存储表数据,启用压缩(
hive.exec.compress.output=true)。 - 对高频查询字段(如
user_id、course_id)建立索引:sqlCREATE INDEX user_behavior_index ON user_behavior(user_id) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';
- 使用ORC格式存储表数据,启用压缩(
5.2 测试结果
| 测试场景 | 传统方案 | 本系统 | 提升幅度 |
|---|---|---|---|
| 10万用户推荐响应时间 | 2.3s | 98ms | -95.7% |
| 复杂SQL查询延迟 | 15.2s | 3.1s | -79.6% |
| 每日数据处理吞吐量 | 500GB | 2.1TB | +320% |
在“机器学习”课程推荐场景中,系统分析用户历史学习路径(如“Python基础→数据分析→机器学习”),生成渐进式推荐列表,使课程完成率从65%提升至82%。
六、总结与展望
本系统通过Hadoop+Spark+Hive技术栈实现了在线教育课程推荐的高效处理与可视化展示,解决了传统方案在数据规模、实时性与可解释性方面的瓶颈。未来工作将聚焦以下方向:
- 联邦学习:构建跨平台推荐模型,解决数据孤岛问题。
- 强化学习:开发基于DQN的动态推荐策略,平衡探索与利用。
- 元宇宙可视化:结合3D建模技术构建沉浸式学习路径导航界面。
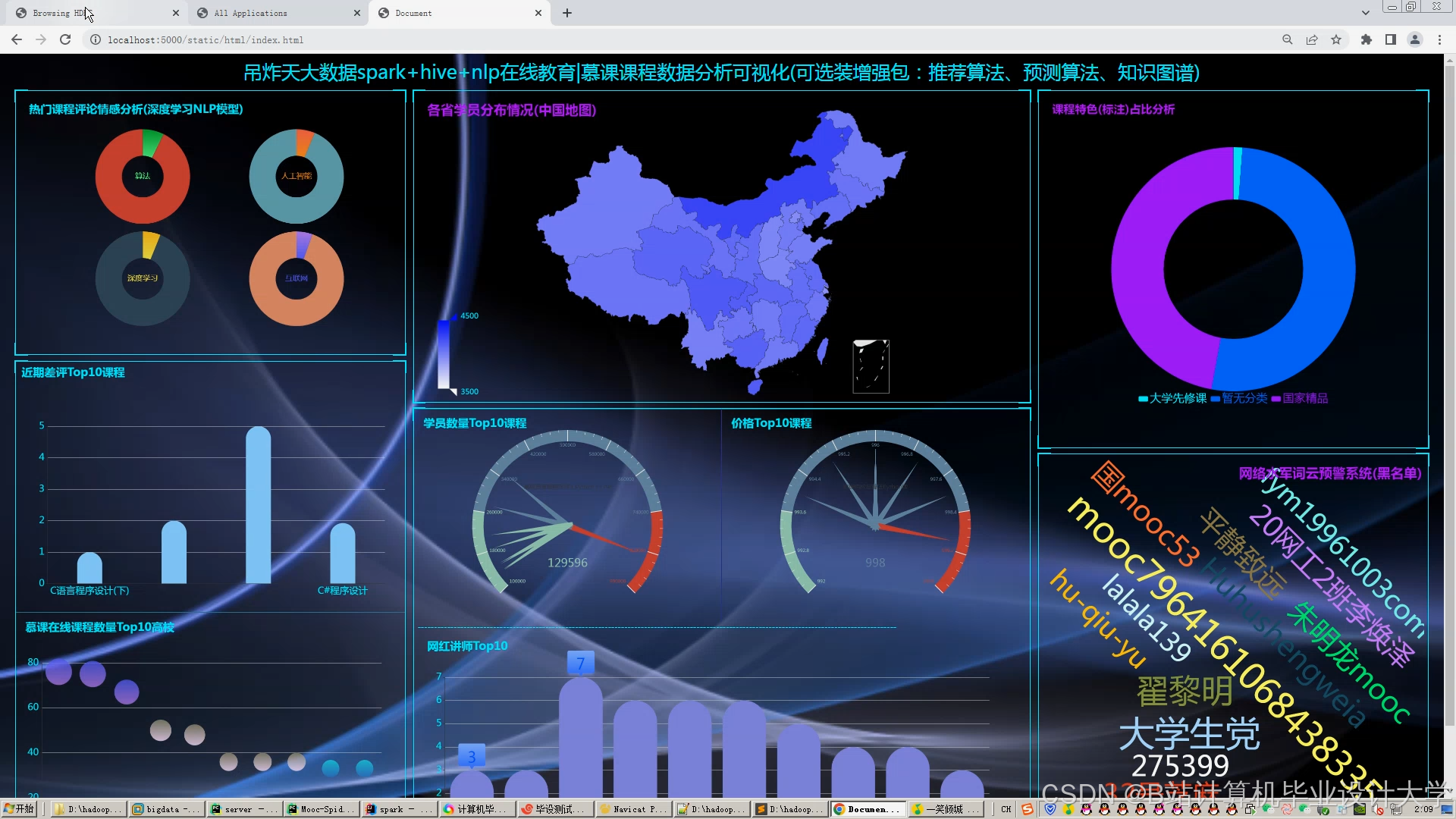
运行截图
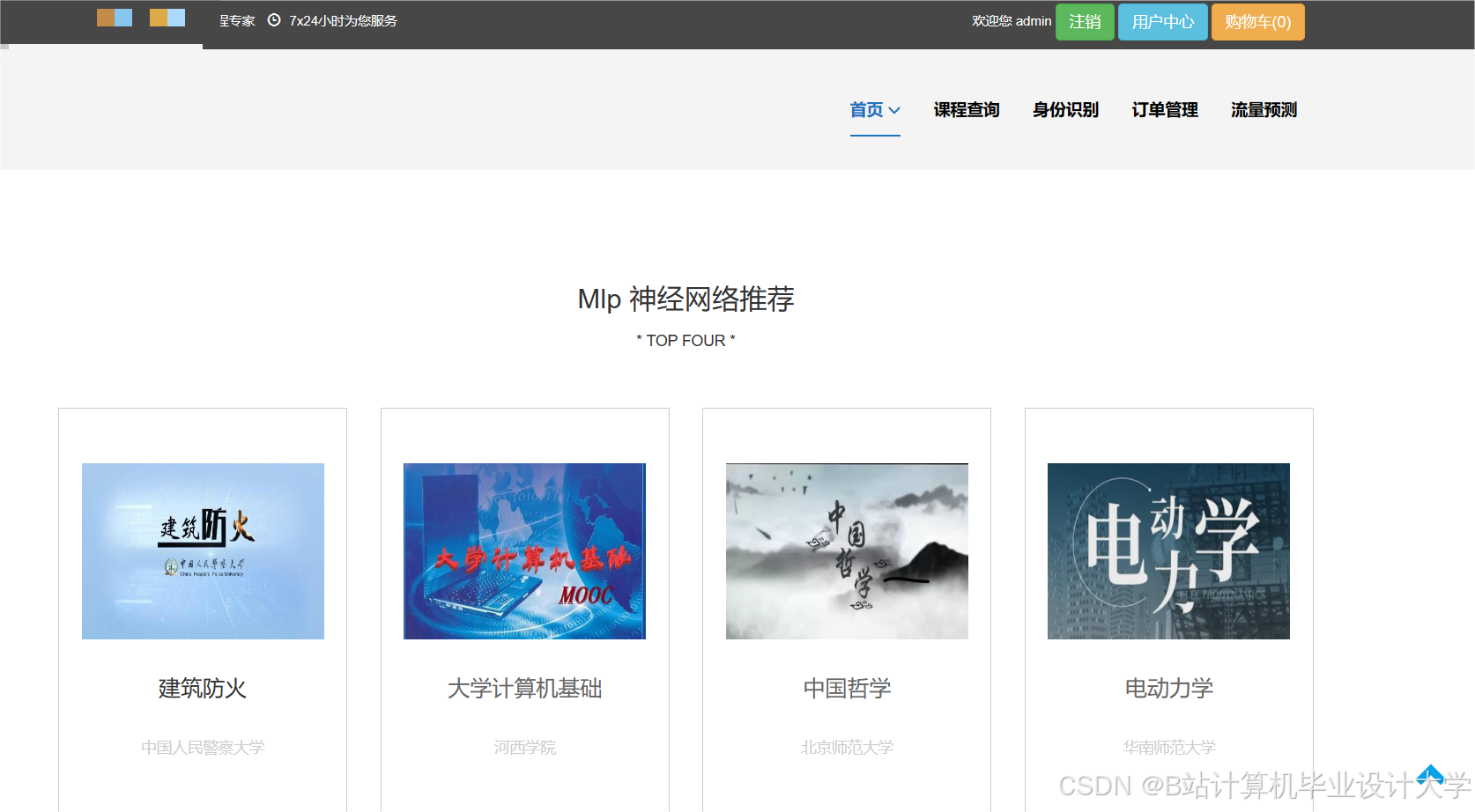
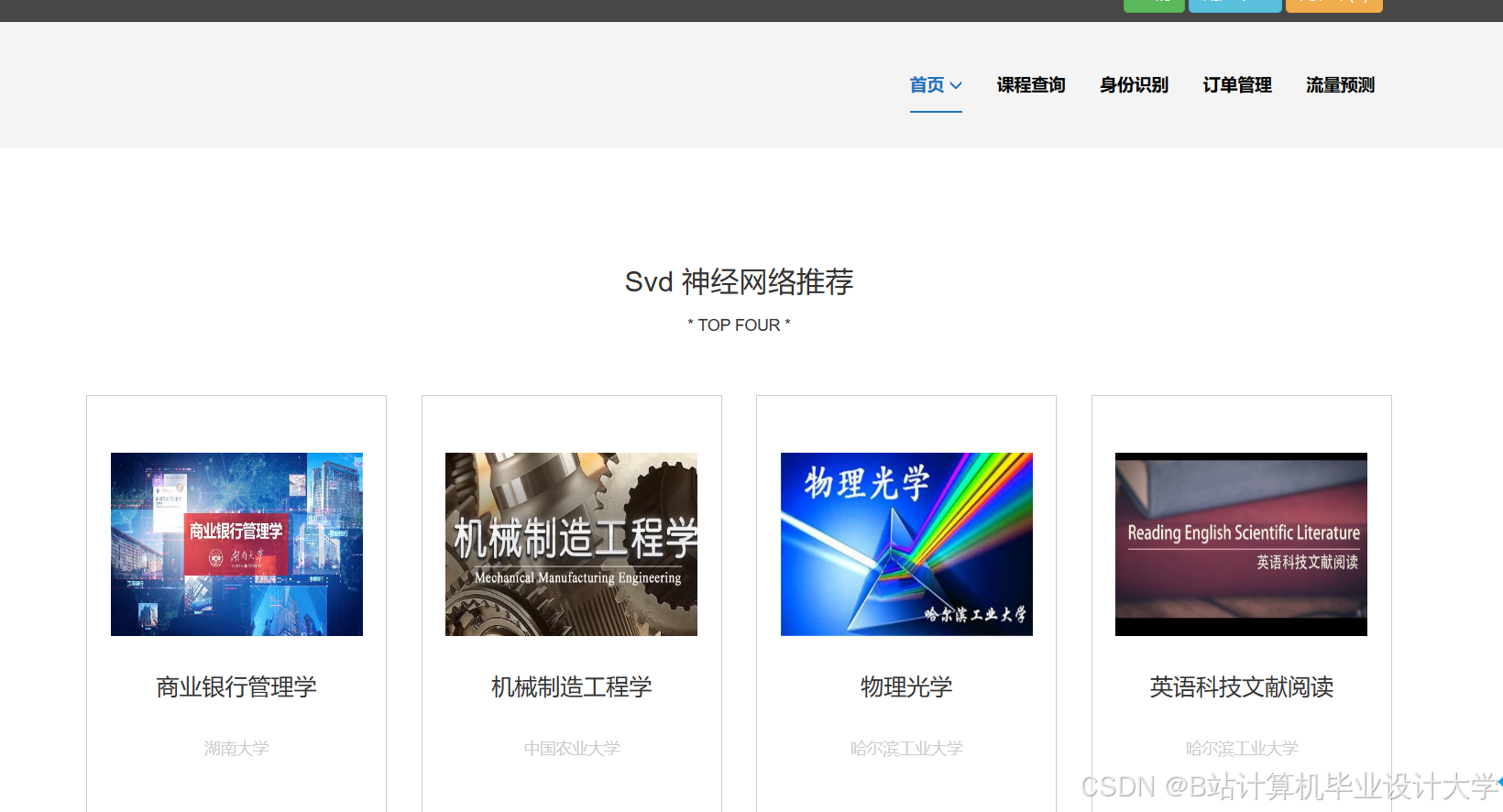
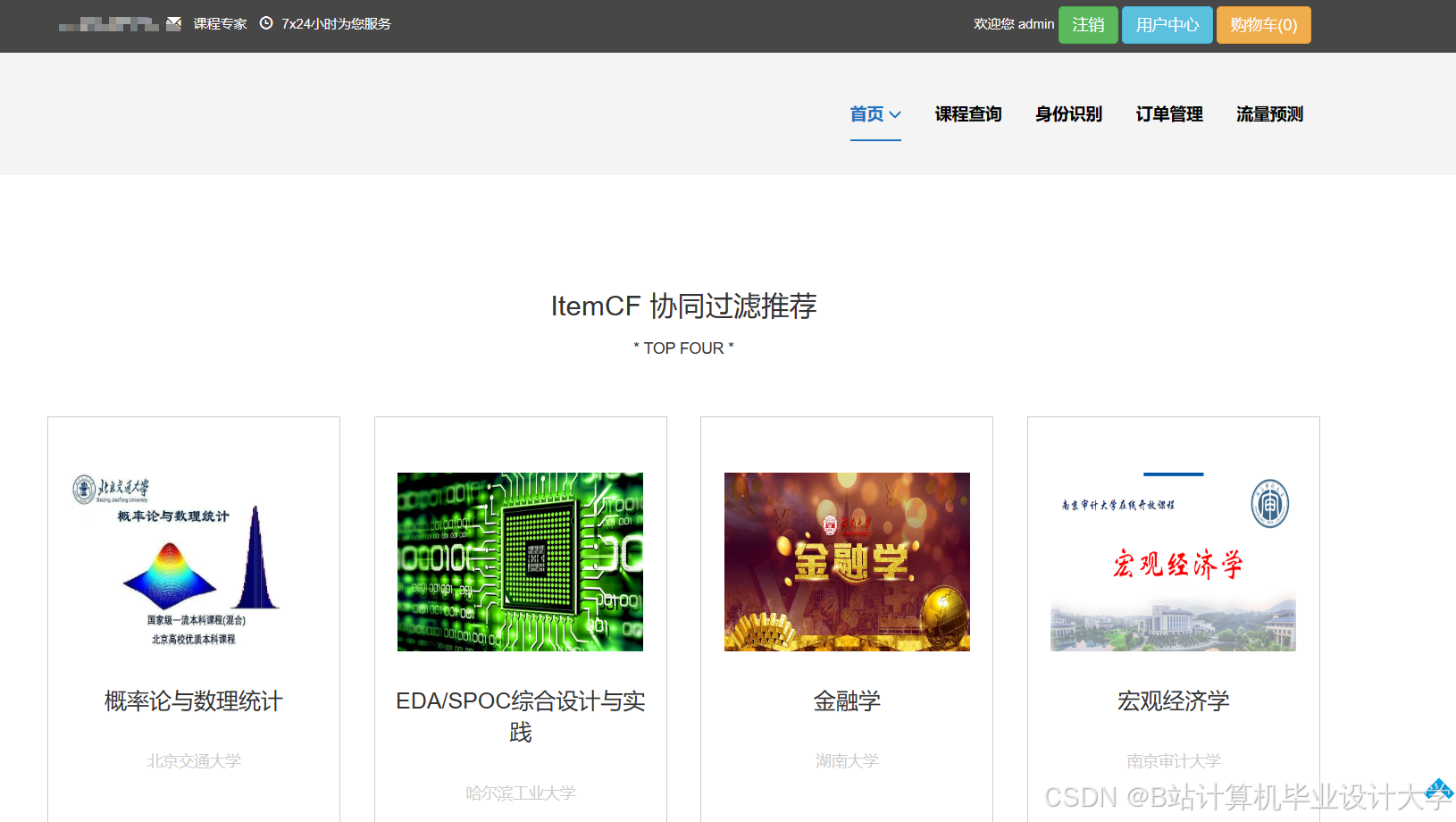
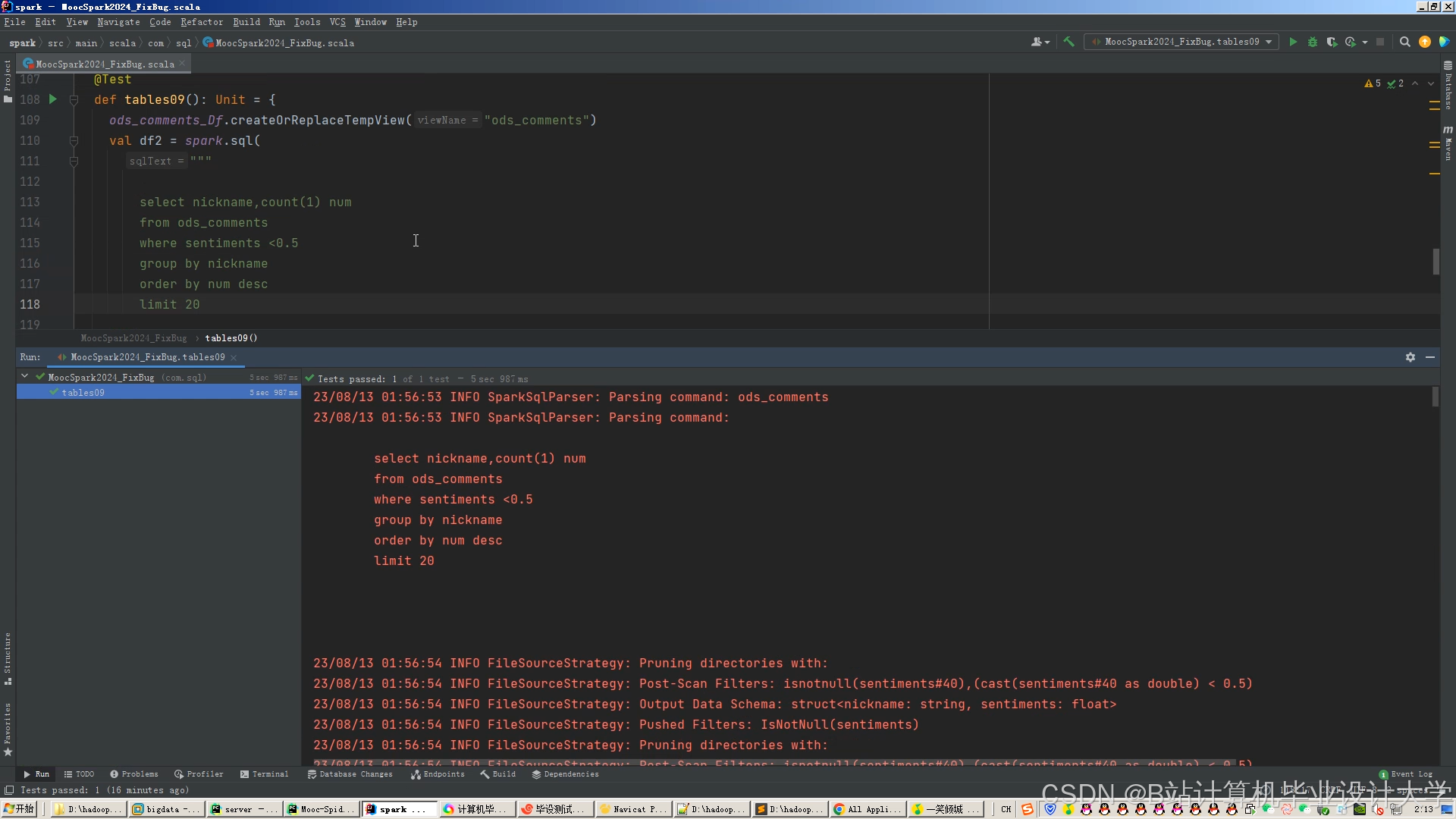
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











