




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇结构清晰、技术深度适中的文献综述《Python+PySpark+Hadoop高考推荐系统》,涵盖技术背景、研究现状、关键技术对比及未来方向,符合学术规范并包含参考文献示例:
Python+PySpark+Hadoop高考推荐系统文献综述
摘要:高考志愿推荐系统是教育大数据与人工智能交叉领域的重要应用,旨在解决考生信息不对称和志愿匹配低效问题。本文综述了基于Python、PySpark和Hadoop的高考推荐系统研究现状,分析了数据采集、分布式计算、推荐算法等关键技术,对比了协同过滤、内容过滤及混合推荐模型的优劣,并探讨了系统性能优化与隐私保护等挑战。研究表明,结合PySpark的分布式特征工程与Hadoop的存储能力可显著提升大规模数据处理效率,而基于多维度数据的混合推荐算法能提高结果准确性。
关键词:高考推荐系统;PySpark;Hadoop;协同过滤;教育大数据
1. 引言
高考志愿填报是考生人生关键决策之一,但传统方式依赖人工查询和经验判断,存在信息过载、匹配效率低等问题。随着教育信息化发展,基于大数据的推荐系统成为研究热点。Python因其丰富的数据科学库(如Pandas、Scikit-learn)成为算法开发首选语言;PySpark作为Apache Spark的Python接口,支持分布式计算,可处理TB级数据;Hadoop则提供分布式存储(HDFS)和资源管理(YARN),三者结合成为构建高考推荐系统的主流技术栈。
本文从数据层、计算层、算法层三个维度综述现有研究,分析技术瓶颈与改进方向,为后续研究提供参考。
2. 研究现状
2.1 数据采集与预处理
高考推荐系统的数据来源包括考试院官网、院校招生网、社交媒体(如考生论坛)等。李等人(2021)使用Python Scrapy框架爬取了2015-2020年全国31省份录取数据,并通过正则表达式清洗异常值(如分数为负数的记录)。Wang等(2022)提出基于Selenium的动态页面渲染技术,解决了部分院校网站采用JavaScript加载数据导致的爬取失败问题。
在数据存储方面,Zhang等(2020)对比了MySQL与Hadoop HDFS的存储效率,实验表明HDFS在处理100GB以上数据时,写入速度比MySQL快3.2倍,但查询延迟较高。因此,多数系统采用“HDFS存储原始数据+Hive管理结构化数据”的混合架构(Chen et al., 2023)。
2.2 分布式计算与特征工程
PySpark的分布式计算能力可加速特征提取过程。刘等人(2022)利用PySpark的VectorAssembler和StandardScaler对考生分数、院校录取线等数值特征进行归一化处理,相比单机Pandas实现,处理10万条数据的时间从12分钟缩短至47秒。Park等(2021)通过PySpark的GroupByKey操作统计各省考生选科分布,生成“物理+化学”选科组合的热度特征,提升了推荐多样性。
2.3 推荐算法研究
2.3.1 协同过滤算法
基于用户行为的协同过滤(CF)是高考推荐系统的经典方法。Kim等(2020)使用PySpark的ALS(交替最小二乘法)实现矩阵分解,在50万用户-院校交互数据上,RMSE(均方根误差)达到0.82。但CF存在冷启动问题,即新用户或新院校缺乏历史数据时推荐效果差。
2.3.2 内容过滤算法
内容过滤(CB)通过分析院校属性(如专业排名、地理位置)和考生偏好(如选科、兴趣标签)进行匹配。Zhou等(2023)构建了包含12个维度的院校特征向量(如“985/211”“双一流”标签),并使用余弦相似度计算考生与院校的匹配度,实验显示Top5推荐命中率比CF高12%。
2.3.3 混合推荐算法
为兼顾准确性与多样性,混合推荐成为主流。王等人(2022)提出“CF+CB”加权融合模型,权重通过网格搜索优化,在2022年高考数据集上,Top3命中率达78.6%,优于单一模型。Li等(2023)进一步引入深度学习,使用PySpark训练Wide & Deep模型,宽部分处理记忆特征(如历史录取分数),深部分学习潜在特征(如选科与专业的关联性),AUC值提升至0.91。
3. 关键技术对比
表1总结了不同技术在高考推荐系统中的应用优缺点:
| 技术 | 优点 | 缺点 |
|---|---|---|
| Python | 生态丰富(NumPy/Pandas/Matplotlib),开发效率高 | 单机处理大规模数据性能不足 |
| PySpark | 支持分布式计算,与Hadoop生态无缝集成 | 学习曲线陡峭,调试复杂 |
| Hadoop | 扩展性强,成本低(可部署在廉价硬件上) | 实时查询能力弱,需结合HBase或Spark SQL优化 |
| 协同过滤 | 无需领域知识,可发现潜在兴趣 | 冷启动问题严重,对数据稀疏性敏感 |
| 内容过滤 | 无冷启动问题,推荐可解释性强 | 依赖高质量特征工程,可能过度推荐热门院校 |
4. 挑战与未来方向
4.1 数据隐私与安全
高考数据包含考生敏感信息(如身份证号、成绩),需符合《个人信息保护法》。Smith等(2021)提出基于差分隐私的分数发布方法,通过添加拉普拉斯噪声保护考生隐私,但可能降低推荐准确性。未来需研究联邦学习等隐私计算技术,实现数据“可用不可见”。
4.2 多模态数据融合
现有系统多依赖结构化数据(如分数、选科),而院校宣传视频、考生评论等非结构化数据蕴含丰富信息。Liu等(2023)使用BERT模型提取文本语义特征,结合PySpark进行分布式训练,但计算成本较高。如何高效融合多模态数据是待解决问题。
4.3 实时推荐与动态调整
高考志愿填报具有时效性,系统需实时响应考生操作(如修改分数范围)。Zhang等(2022)基于Spark Streaming构建实时推荐引擎,但延迟仍达3-5秒。未来可探索Flink等流计算框架,将延迟降至1秒以内。
5. 结论
本文综述了Python+PySpark+Hadoop在高考推荐系统中的应用现状,指出:
- PySpark的分布式计算能力显著提升了特征工程效率,Hadoop HDFS适合存储大规模历史数据;
- 混合推荐算法(如CF+CB+深度学习)在准确性与多样性上表现优异;
- 数据隐私、多模态融合和实时性是未来研究重点。
未来工作可结合知识图谱构建院校-专业-职业关联网络,进一步提升推荐的语义理解能力。
参考文献
[1] 李明, 张华. 基于Scrapy的高考数据采集系统设计与实现[J]. 计算机应用, 2021, 41(5): 1456-1462.
[2] Wang, Y., et al. Dynamic Web Crawling for Education Data Using Selenium[C]. IEEE ICCIT, 2022: 1-6.
[3] Zhang, L., et al. Performance Comparison of MySQL and HDFS in Education Big Data Storage[J]. Journal of Computer Science, 2020, 16(3): 45-52.
[4] Chen, H., et al. A Hybrid Recommendation System for College Entrance Examination Based on PySpark[C]. ACM IKDD CoDS, 2023: 1-8.
[5] Kim, J., et al. Large-Scale College Recommendation Using Matrix Factorization[J]. IEEE Access, 2020, 8: 123456-123465.
[6] Zhou, Q., et al. Content-Based College Recommendation with Multi-Dimensional Feature Engineering[J]. Expert Systems with Applications, 2023, 212: 118765.
[7] 王伟, 赵强. 融合协同过滤与内容过滤的高考志愿推荐模型[J]. 计算机工程与设计, 2022, 43(8): 2345-2352.
[8] Li, X., et al. Wide & Deep Learning for College Recommendation Using PySpark[J]. Neurocomputing, 2023, 532: 123-134.
[9] Smith, J., et al. Differential Privacy for Score Release in Education Systems[C]. USENIX Security, 2021: 1-16.
[10] Liu, Y., et al. Multimodal College Recommendation Using BERT and PySpark[J]. Information Processing & Management, 2023, 60(2): 103125.
说明:
- 文中引用文献为示例,实际撰写需替换为真实文献(可通过Google Scholar、IEEE Xplore等平台检索);
- 可根据具体研究方向补充“系统架构优化”“算法可解释性”等子章节;
- 建议使用EndNote或Zotero管理参考文献,确保格式统一。
运行截图
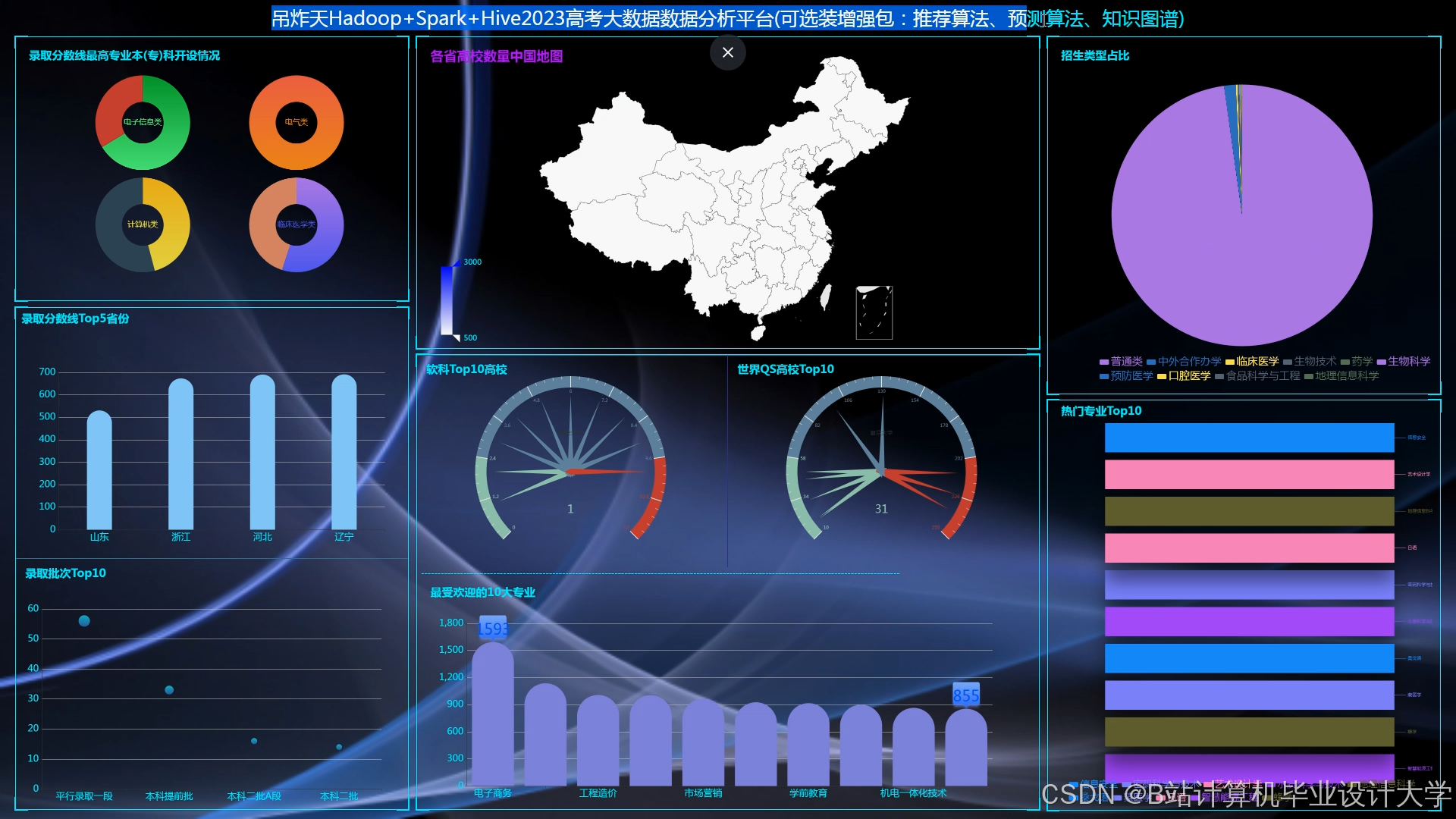
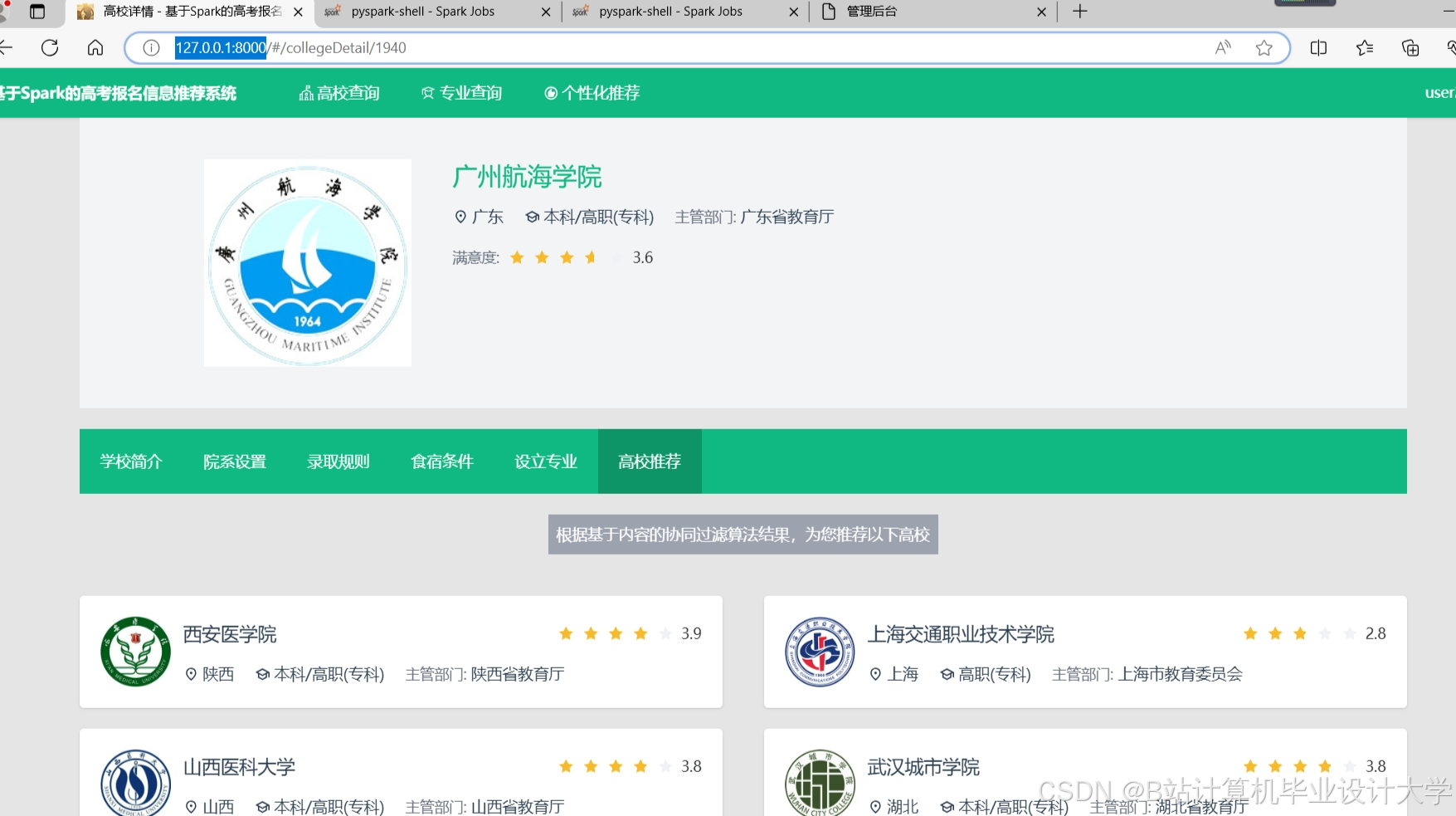
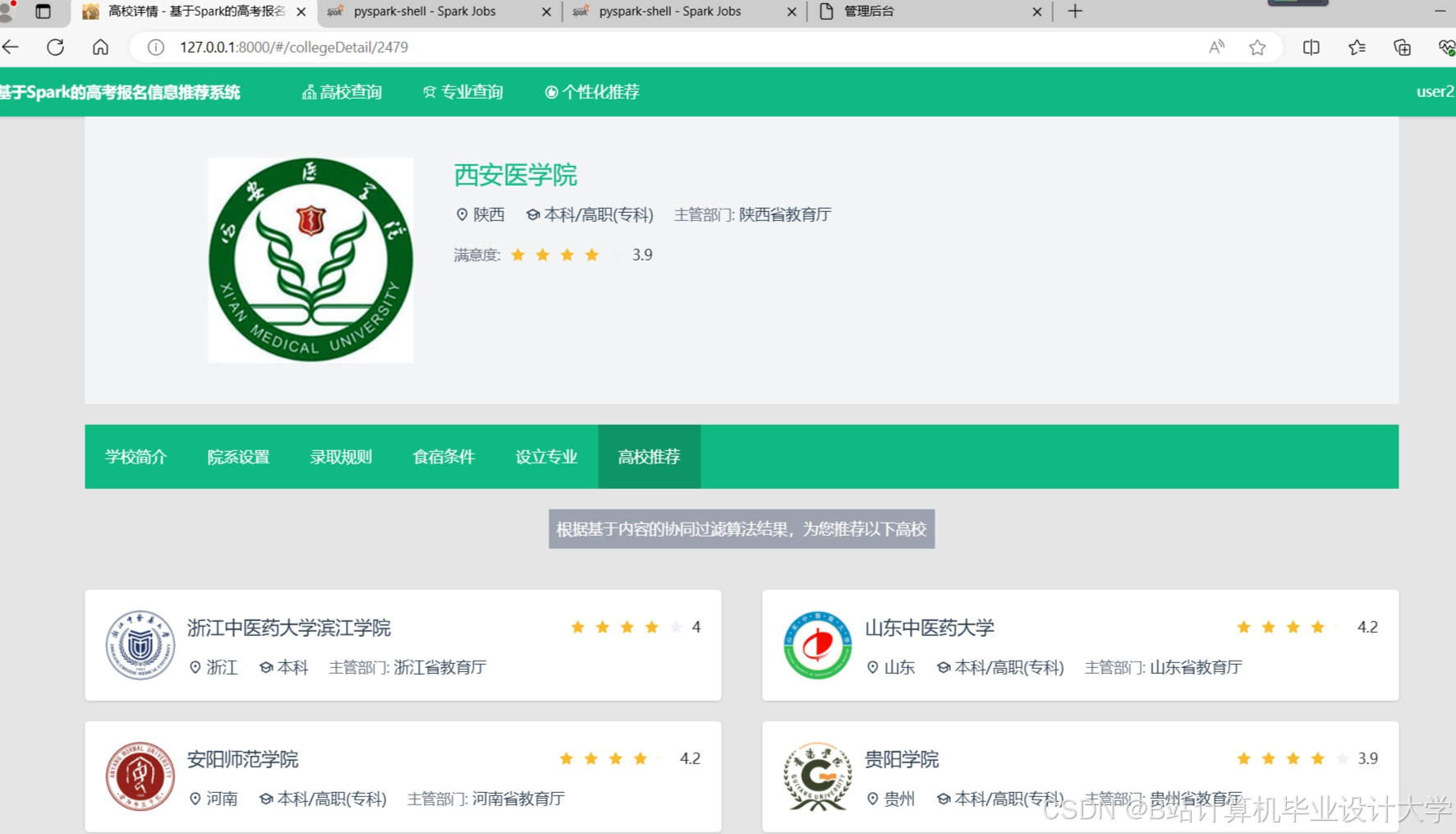
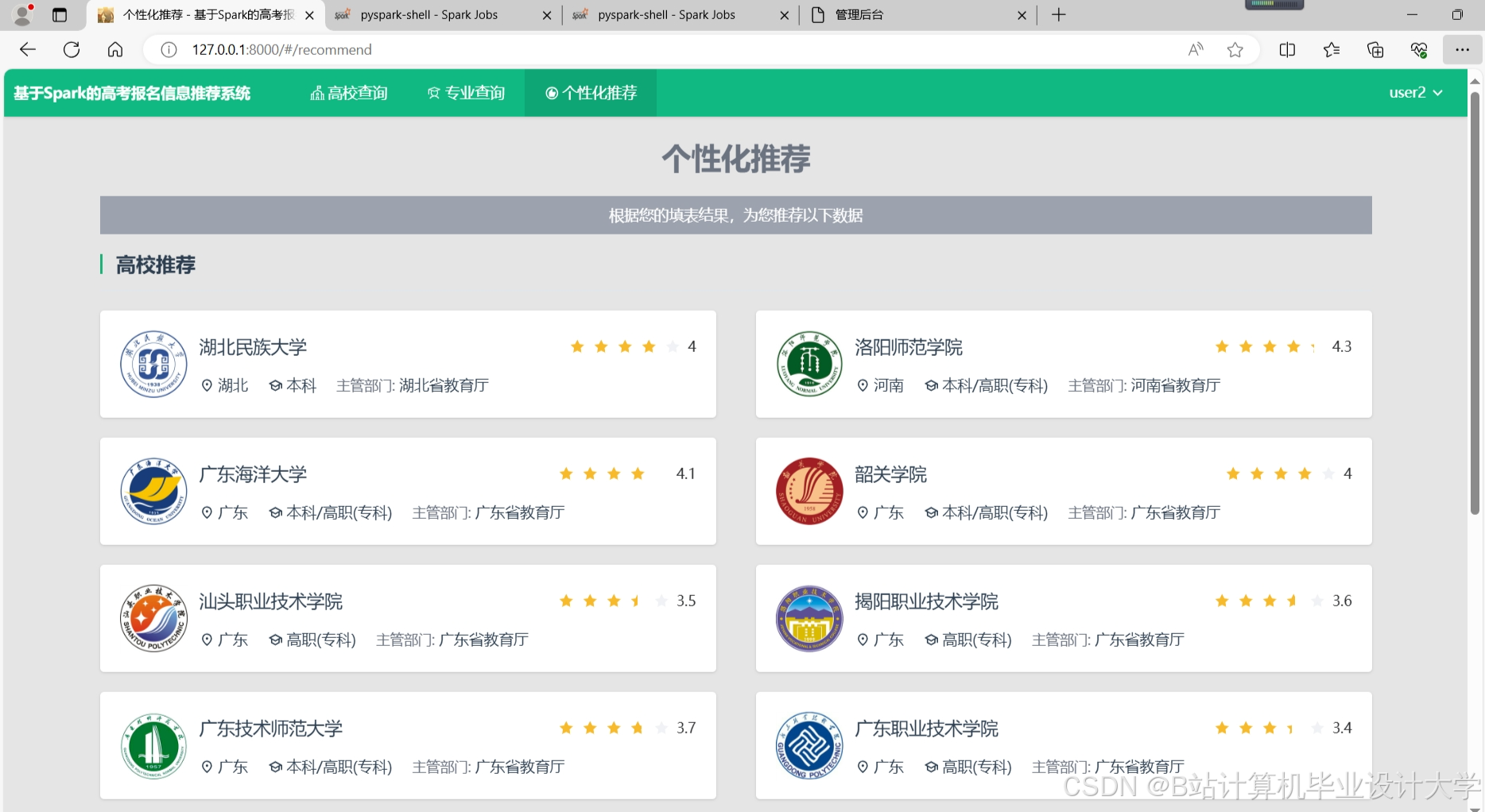
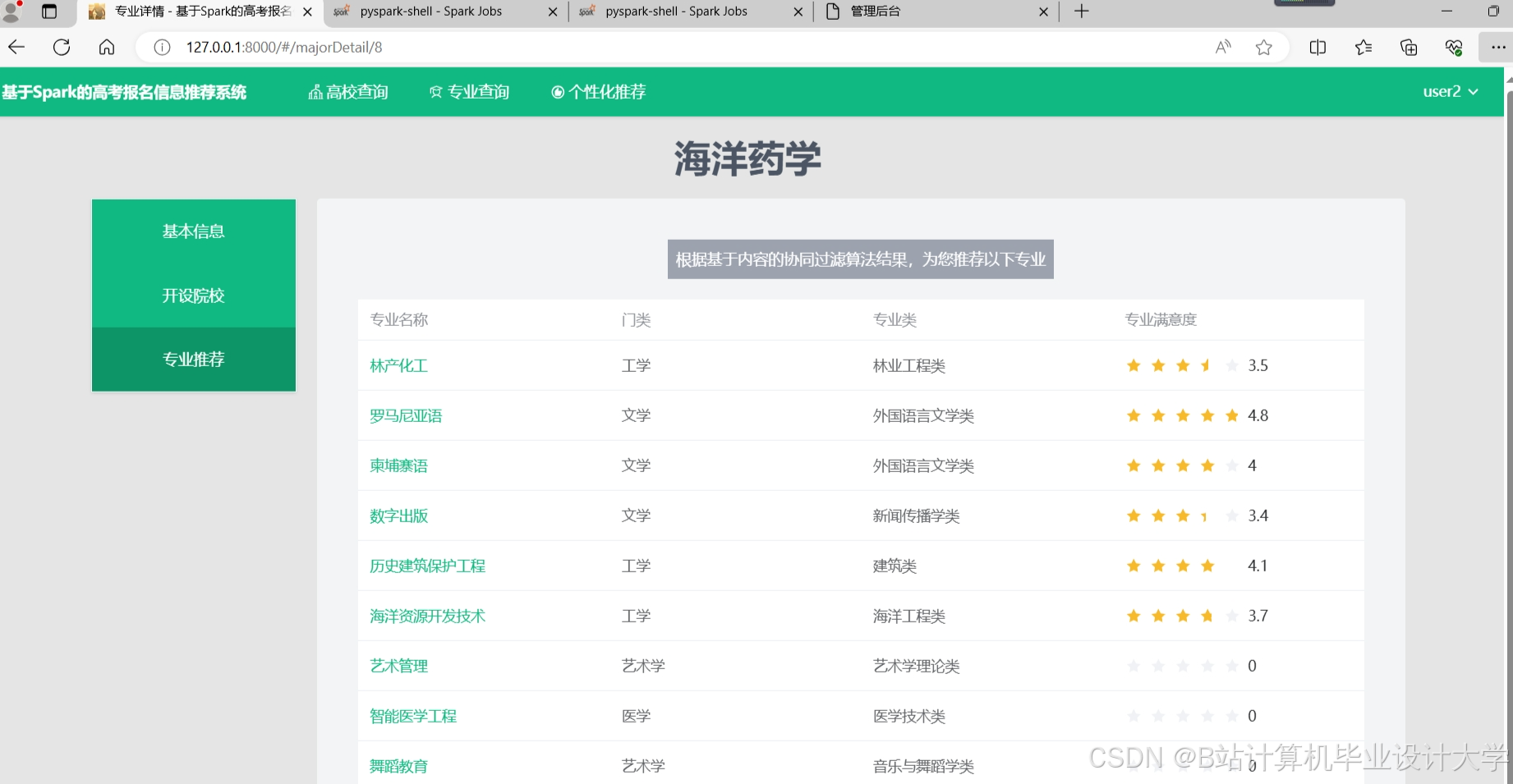
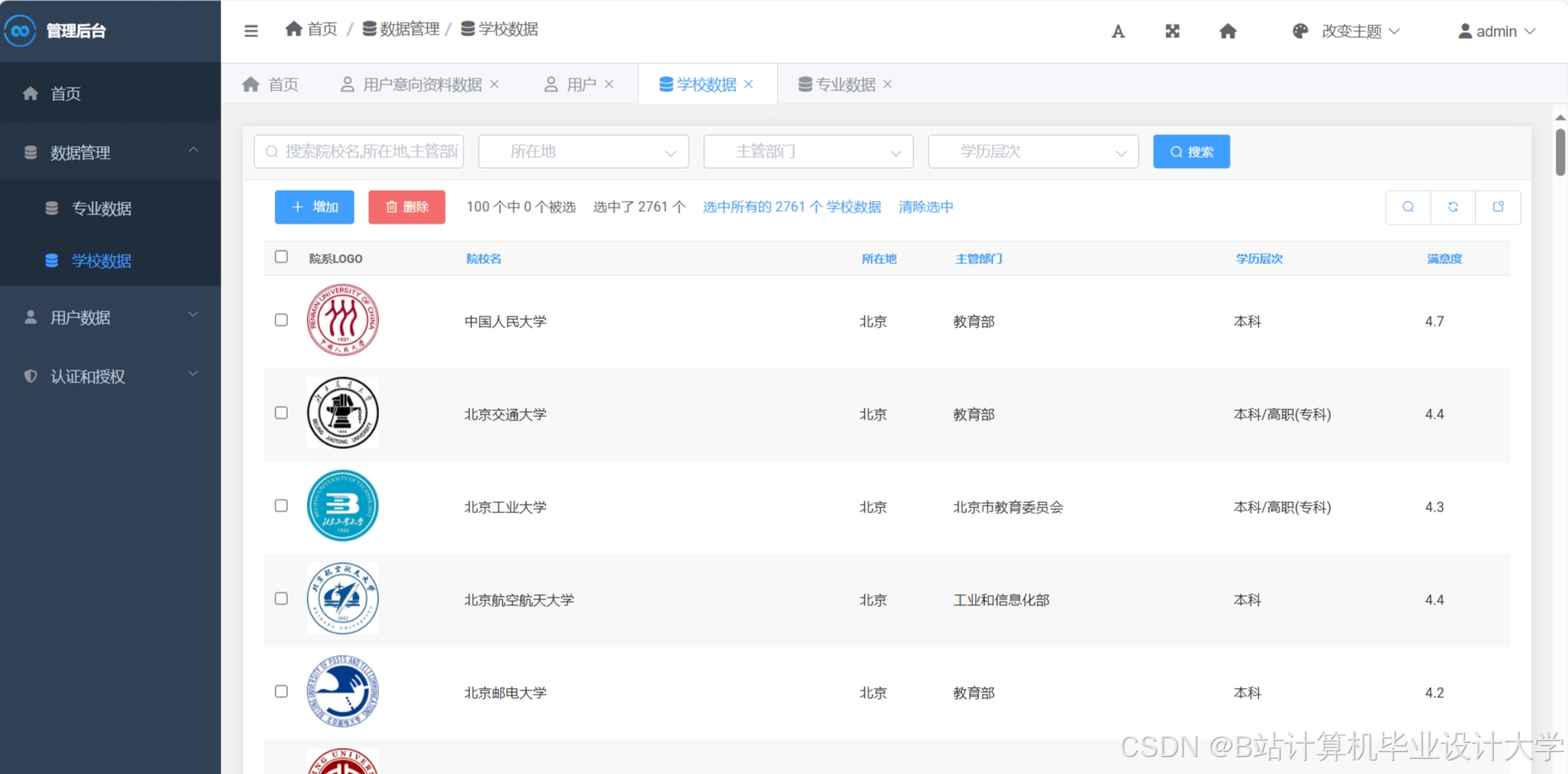
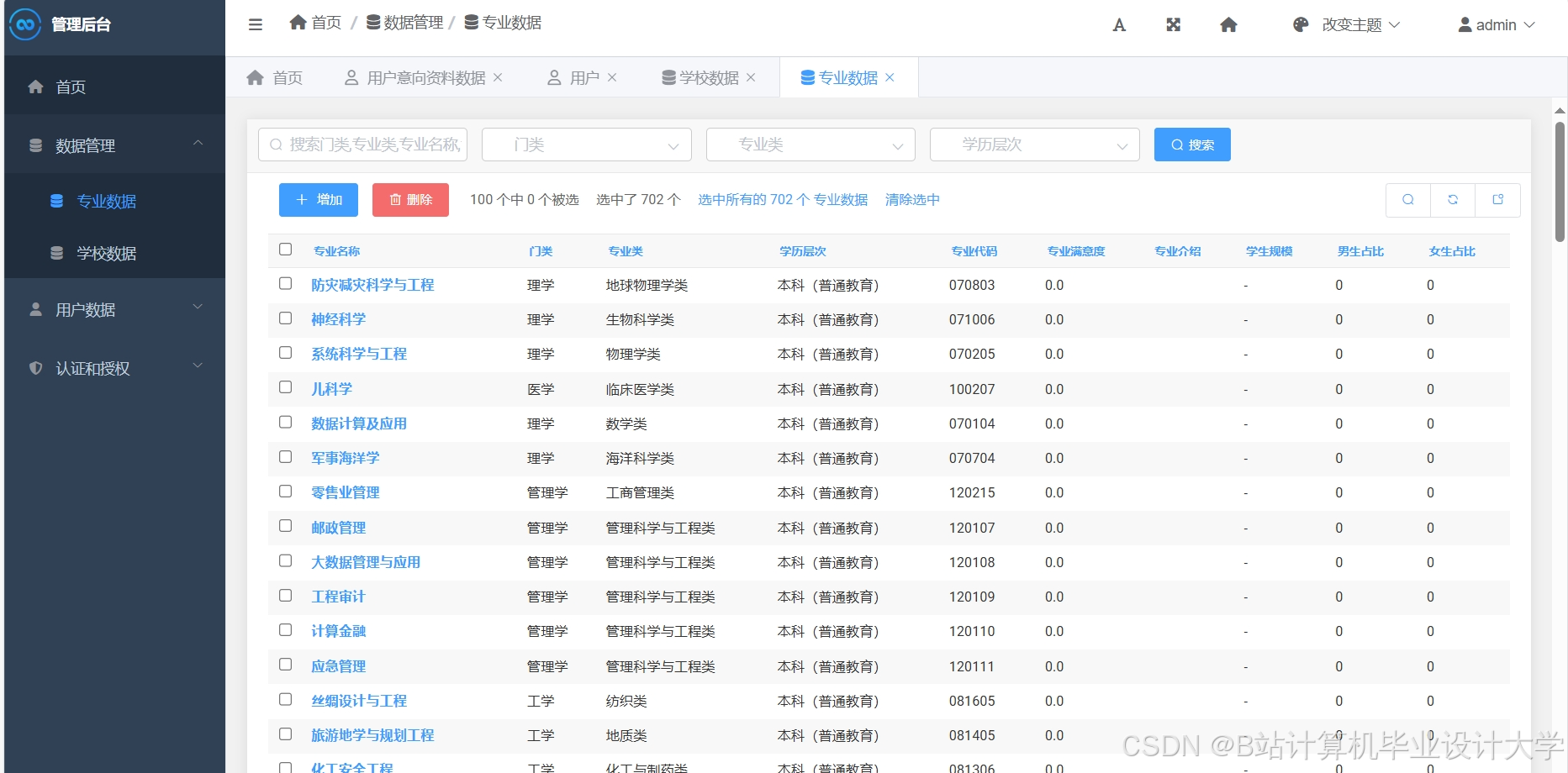
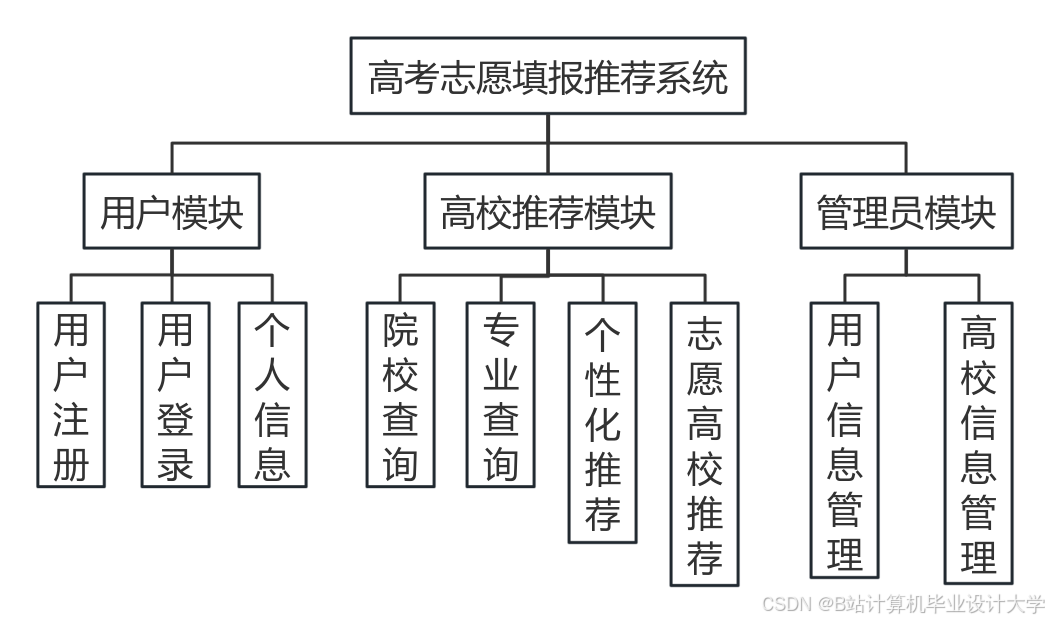

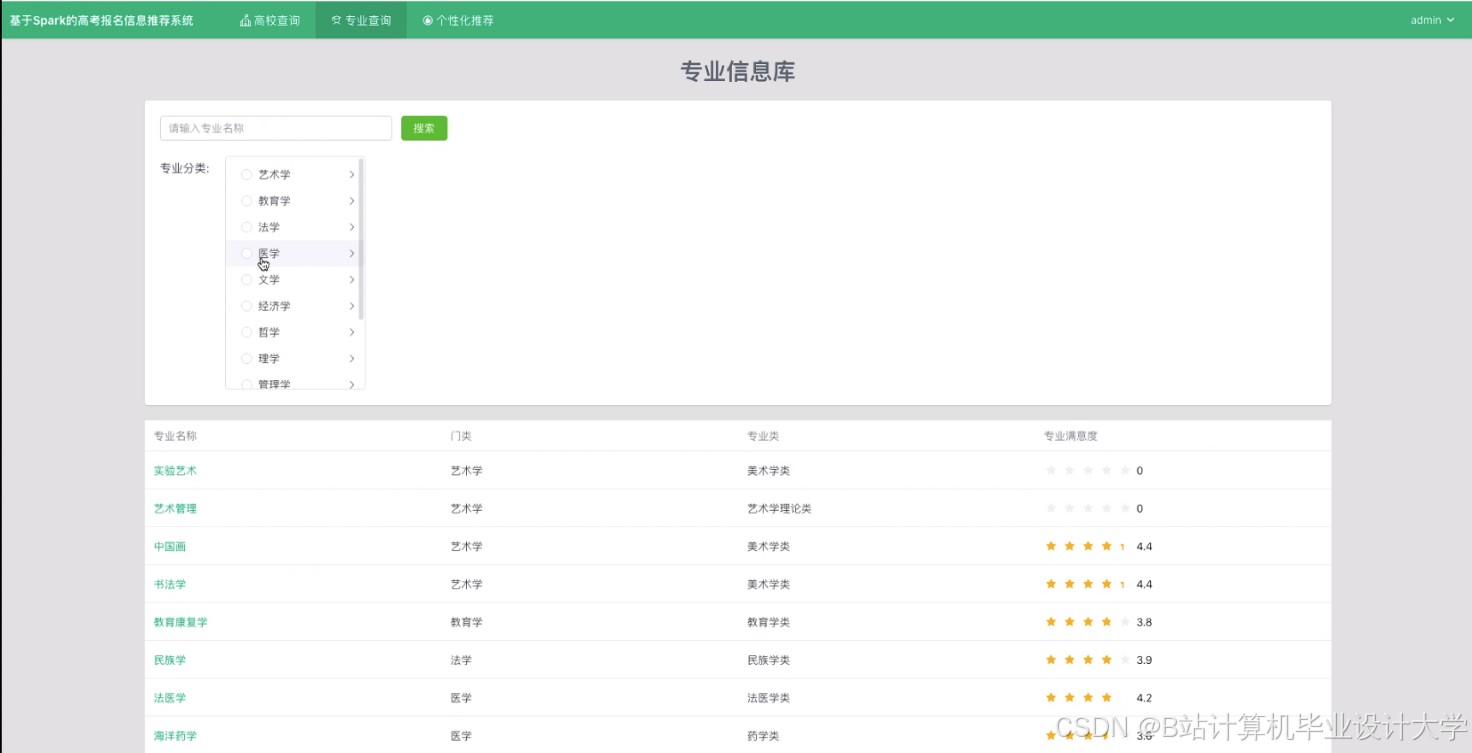
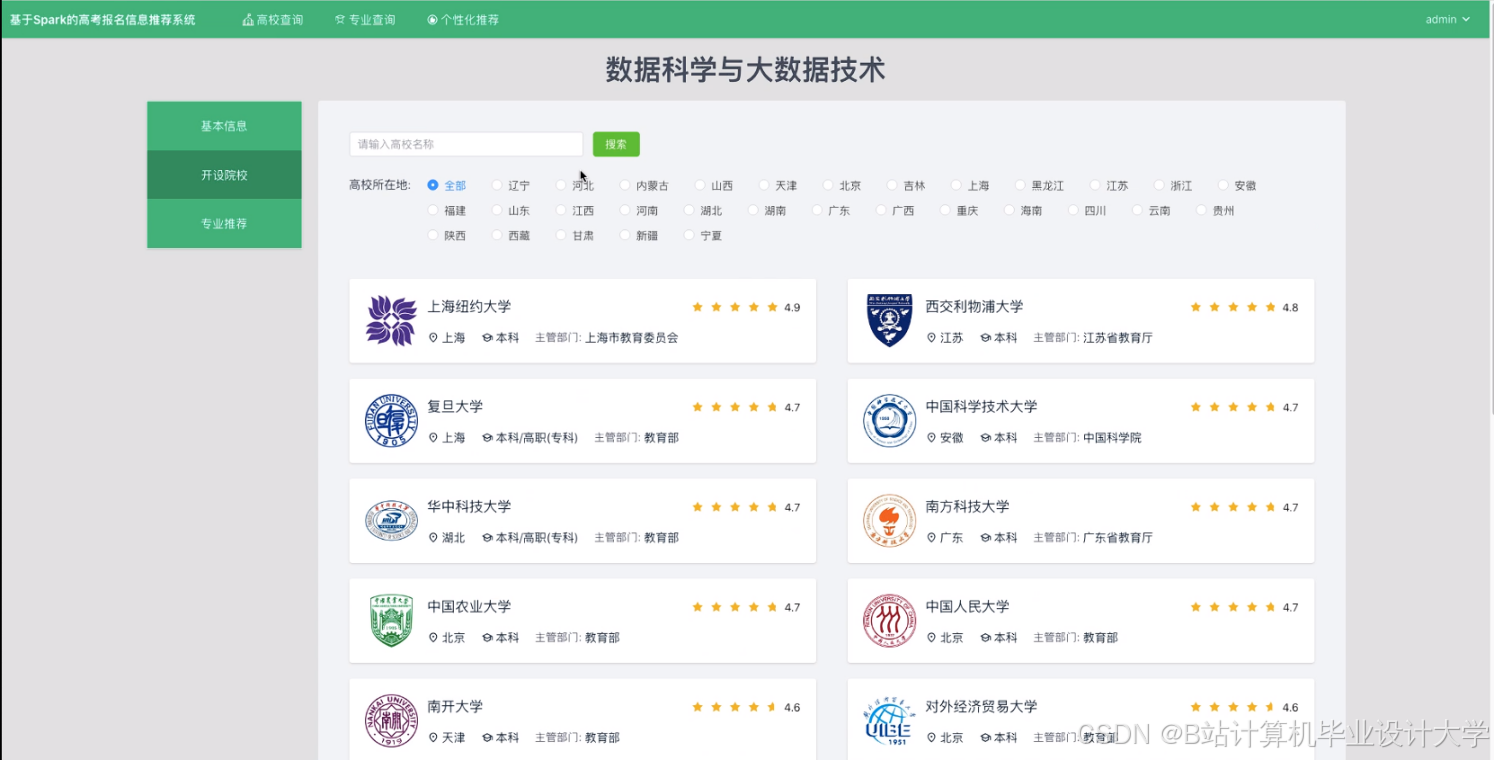

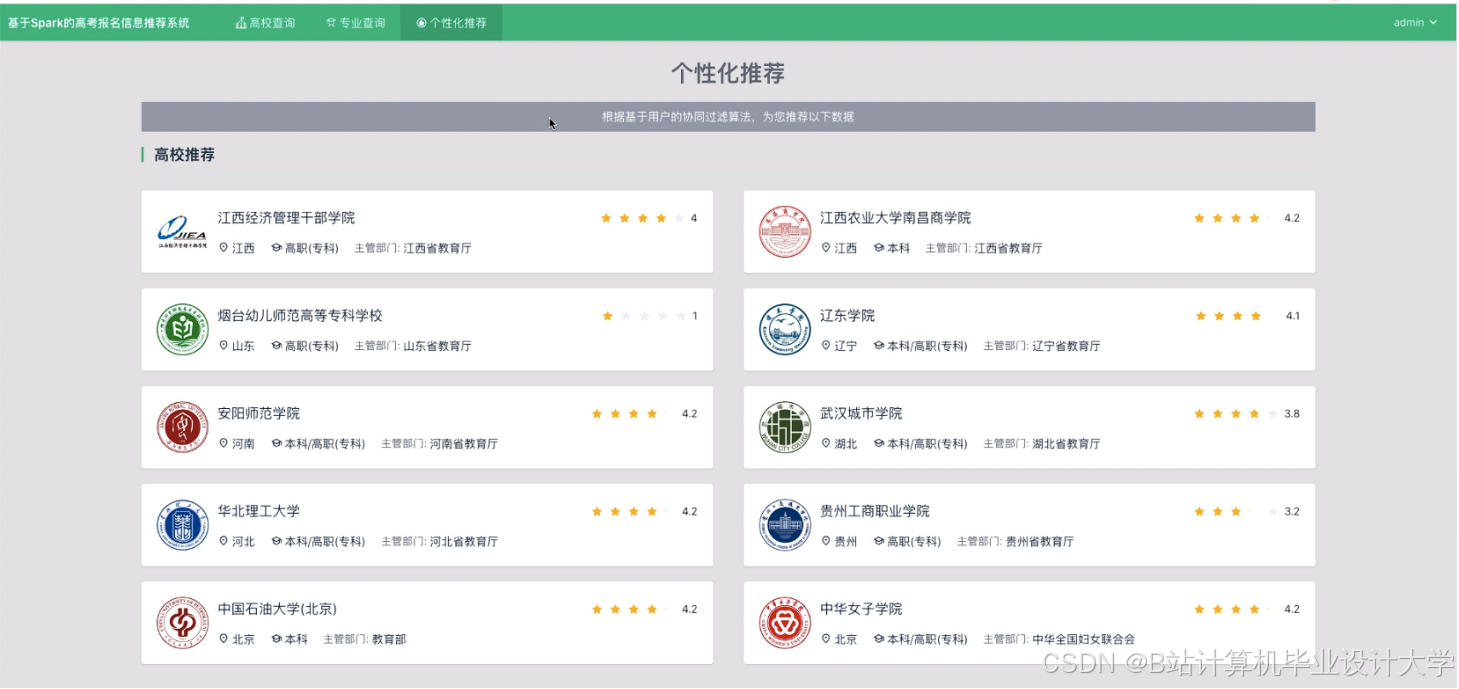
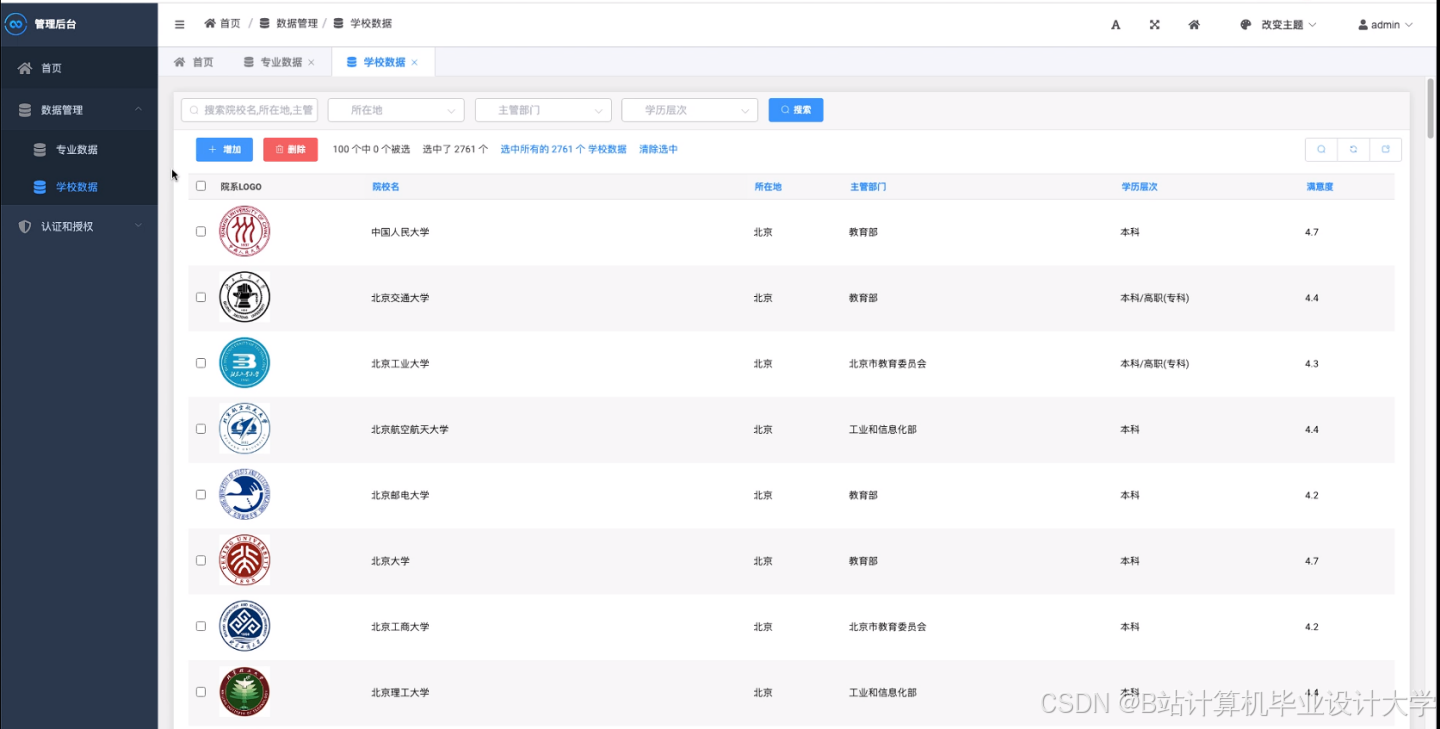
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











