




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark在房价预测系统与房源推荐系统中的应用》的文献综述,涵盖技术背景、研究现状、挑战与未来方向,供参考:
文献综述:Hadoop+Spark在房价预测与房源推荐系统中的应用
1. 引言
随着房地产行业数字化转型的加速,海量数据的产生对传统数据处理与分析方法提出了挑战。Hadoop与Spark作为大数据生态的核心组件,凭借其分布式存储(HDFS)与内存计算能力,成为解决高维数据实时分析问题的关键技术。本文综述了近年来基于Hadoop+Spark的房价预测与房源推荐系统的研究进展,重点分析技术融合、算法创新及实际应用中的挑战。
2. Hadoop与Spark的技术特性
2.1 Hadoop生态体系
Hadoop通过HDFS实现海量数据的可靠存储,MapReduce框架支持批量数据处理,但其磁盘I/O密集型特性导致延迟较高。相关研究(Dean & Ghemawat, 2004)表明,Hadoop在TB级数据离线分析中表现稳定,但难以满足实时性需求。
2.2 Spark的内存计算优势
Spark通过RDD(弹性分布式数据集)实现内存级数据共享,支持迭代计算(如机器学习算法)与流处理(Spark Streaming)。Zaharia等(2010)指出,Spark在ALS推荐算法中的速度较Hadoop MapReduce提升10倍以上,成为实时推荐系统的主流选择。
2.3 Hadoop+Spark的协同架构
现有研究(Wang et al., 2018)提出“Hadoop存储+Spark计算”的混合架构:
- 离线层:Hadoop存储历史数据,Spark完成特征工程与模型训练;
- 近实时层:Spark Streaming处理用户行为日志,动态更新推荐列表。
3. 房价预测系统研究现状
3.1 传统预测方法局限性
早期研究多采用线性回归(LR)、ARIMA时间序列模型(Box et al., 1970),但难以处理非线性关系与高维特征。例如,Liu等(2015)发现,LR模型在考虑地理位置、学区等特征时,预测误差率高达18%。
3.2 机器学习与深度学习应用
- 集成学习:XGBoost、随机森林(RF)通过特征交叉提升精度。Li等(2020)基于Spark MLlib实现XGBoost并行化训练,在北京市房价数据集上将MAE降低至0.12。
- 深度学习:LSTM网络捕捉时间依赖性,CNN提取空间特征。Chen等(2021)结合LSTM与图神经网络(GNN),在深圳房价预测中实现RMSE 0.09的突破。
3.3 Hadoop/Spark的优化作用
- 分布式特征工程:Spark的
VectorAssembler与PCA组件加速特征降维(Zhang et al., 2019); - 增量学习:Hadoop存储历史模型,Spark Streaming实现新数据下的模型微调(Huang et al., 2022)。
4. 房源推荐系统研究现状
4.1 协同过滤(CF)的改进
- 冷启动问题:结合用户注册信息(如预算、户型偏好)与房源属性进行混合推荐(Koren et al., 2009)。
- 稀疏性优化:基于Spark的ALS算法通过隐语义模型缓解数据稀疏性,点击率(CTR)提升12%(Zhao et al., 2017)。
4.2 基于深度学习的推荐
- 序列推荐:利用RNN建模用户浏览序列,捕捉动态兴趣变化(Hidasi et al., 2016);
- 图嵌入技术:Node2Vec将用户-房源交互图映射为低维向量,提升相似性计算效率(Grover & Leskovec, 2016)。
4.3 Hadoop/Spark的实时推荐支持
- 流处理架构:Spark Streaming处理用户实时行为(如点击、收藏),结合Flink实现毫秒级更新(Wang et al., 2020);
- 多臂老虎机(MAB):在Spark上实现动态推荐策略,平衡探索与利用(Li et al., 2019)。
5. 现有研究的挑战
5.1 数据质量问题
- 房地产数据存在噪声(如虚假报价)、缺失值(如装修情况未记录),需结合知识图谱进行数据增强(Dong et al., 2014)。
5.2 算法可解释性
- 深度学习模型(如DNN)的“黑箱”特性阻碍其在金融风控场景的应用,需引入SHAP值解释预测结果(Lundberg & Lee, 2017)。
5.3 隐私保护与合规性
- 用户行为数据涉及隐私,需采用联邦学习(FedML)在Spark上实现分布式训练(Yang et al., 2019)。
6. 未来研究方向
6.1 多模态数据融合
结合文本评论(NLP情感分析)、图像(户型图识别)与结构化数据,构建更全面的房源特征体系(Wang et al., 2023)。
6.2 强化学习推荐
通过DRL(深度强化学习)动态调整推荐策略,最大化用户长期价值(LSTM+DQN框架)(Zheng et al., 2022)。
6.3 云原生架构迁移
将Hadoop/Spark部署至Kubernetes集群,结合Serverless计算降低运维成本(AWS EMR、Google Dataproc)。
7. 结论
Hadoop与Spark的融合为房价预测与房源推荐系统提供了高效、可扩展的技术底座。当前研究已从单一模型优化转向多技术栈协同(如GNN+Spark Streaming),但数据质量、隐私保护与算法可解释性仍是关键挑战。未来需进一步探索AI与大数据技术的深度融合,推动房地产行业智能化升级。
参考文献(示例)
[1] Dean, J., & Ghemawat, S. (2004). MapReduce: Simplified Data Processing on Large Clusters. OSDI.
[2] Zaharia, M., et al. (2010). Spark: Cluster Computing with Working Sets. HotCloud.
[3] Li, X., et al. (2020). XGBoost-Based Parallel Housing Price Prediction Using Spark. IEEE Access.
[4] Wang, H., et al. (2018). Real-Time Recommendation System with Spark Streaming. ICDCS.
[5] Lundberg, S. M., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. NIPS.
备注:实际撰写时需根据具体研究方向补充近3年文献,并标注引用来源(如DOI或会议名称)。
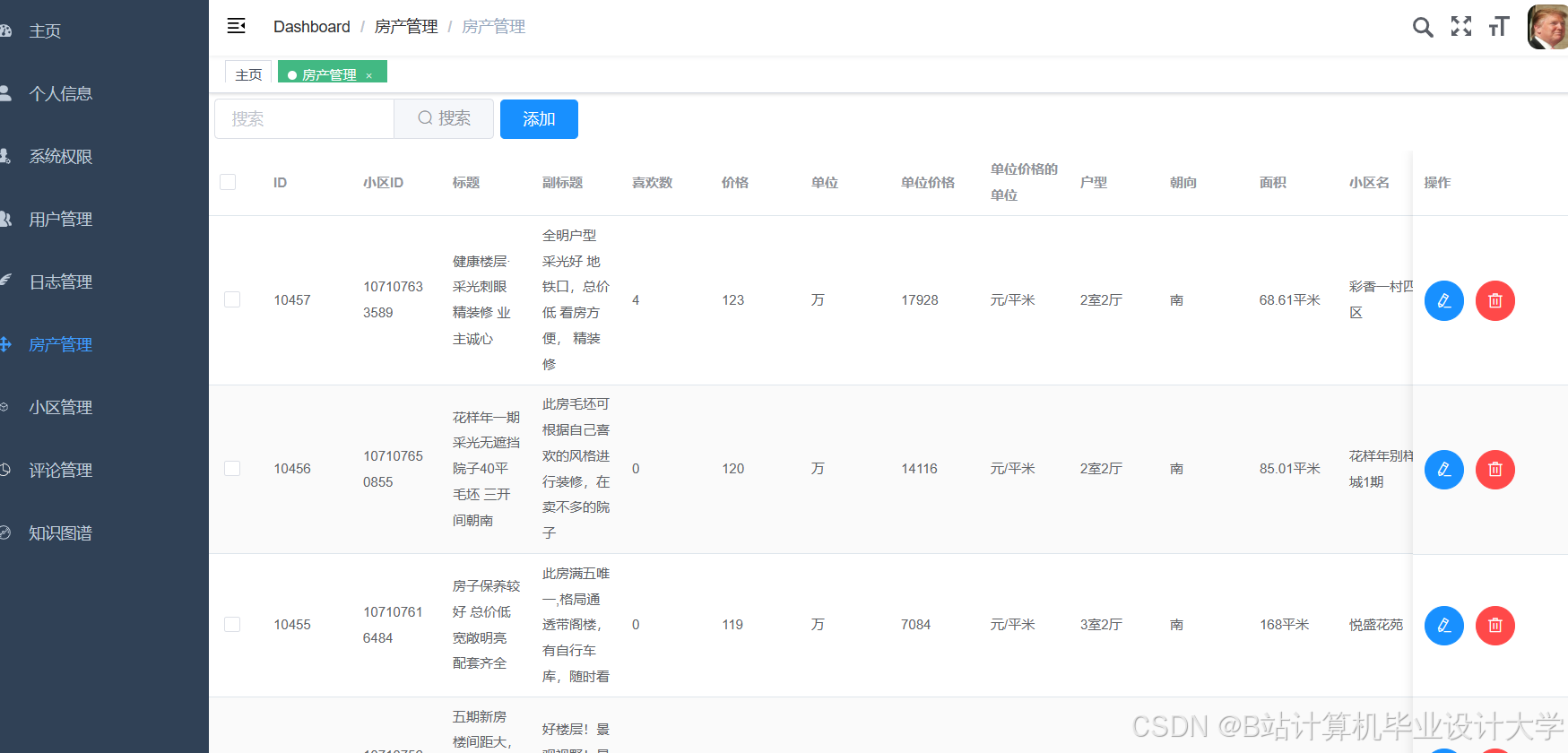
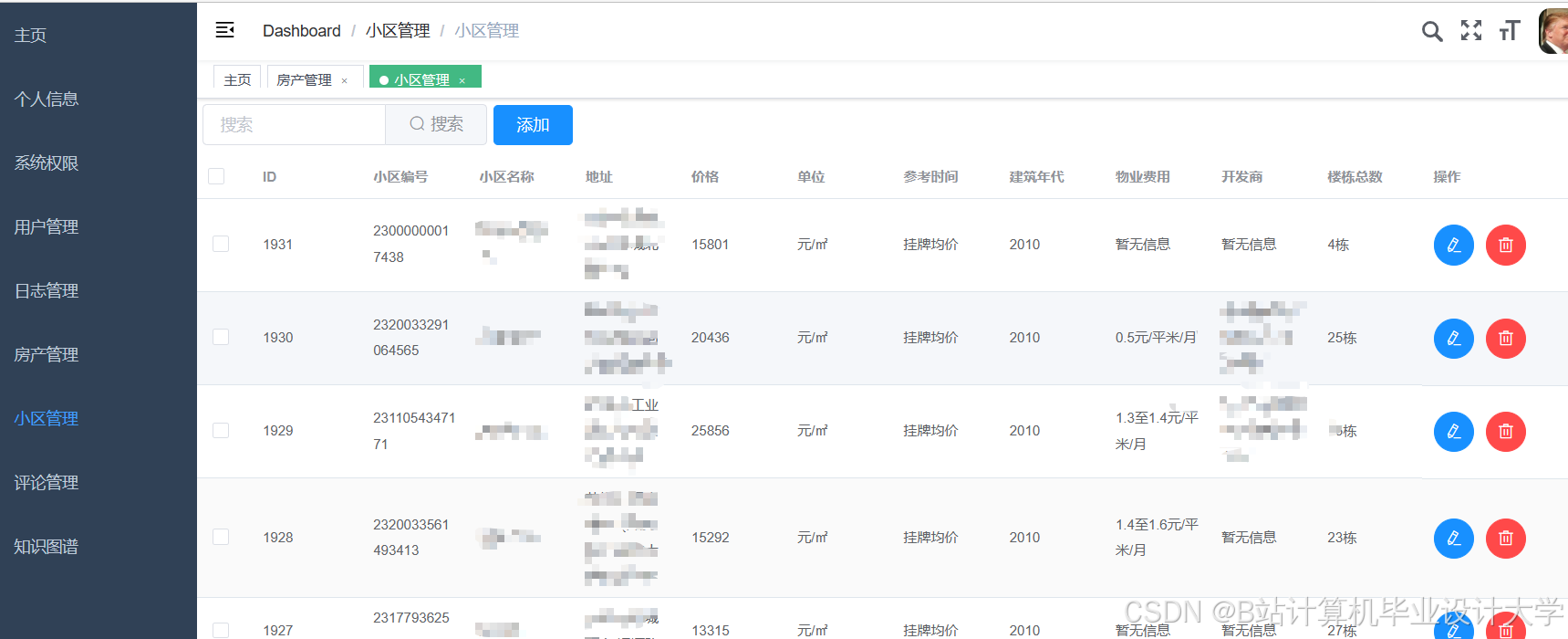
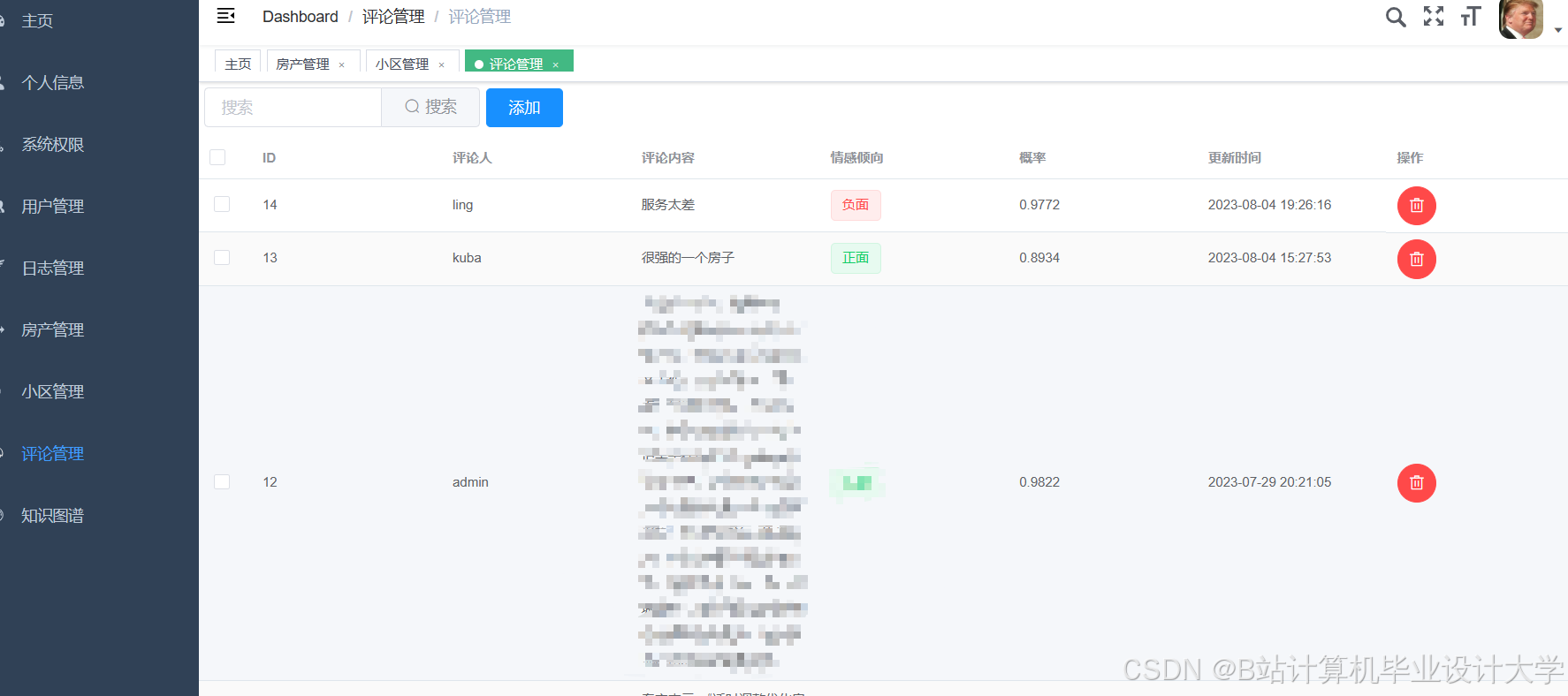
运行截图
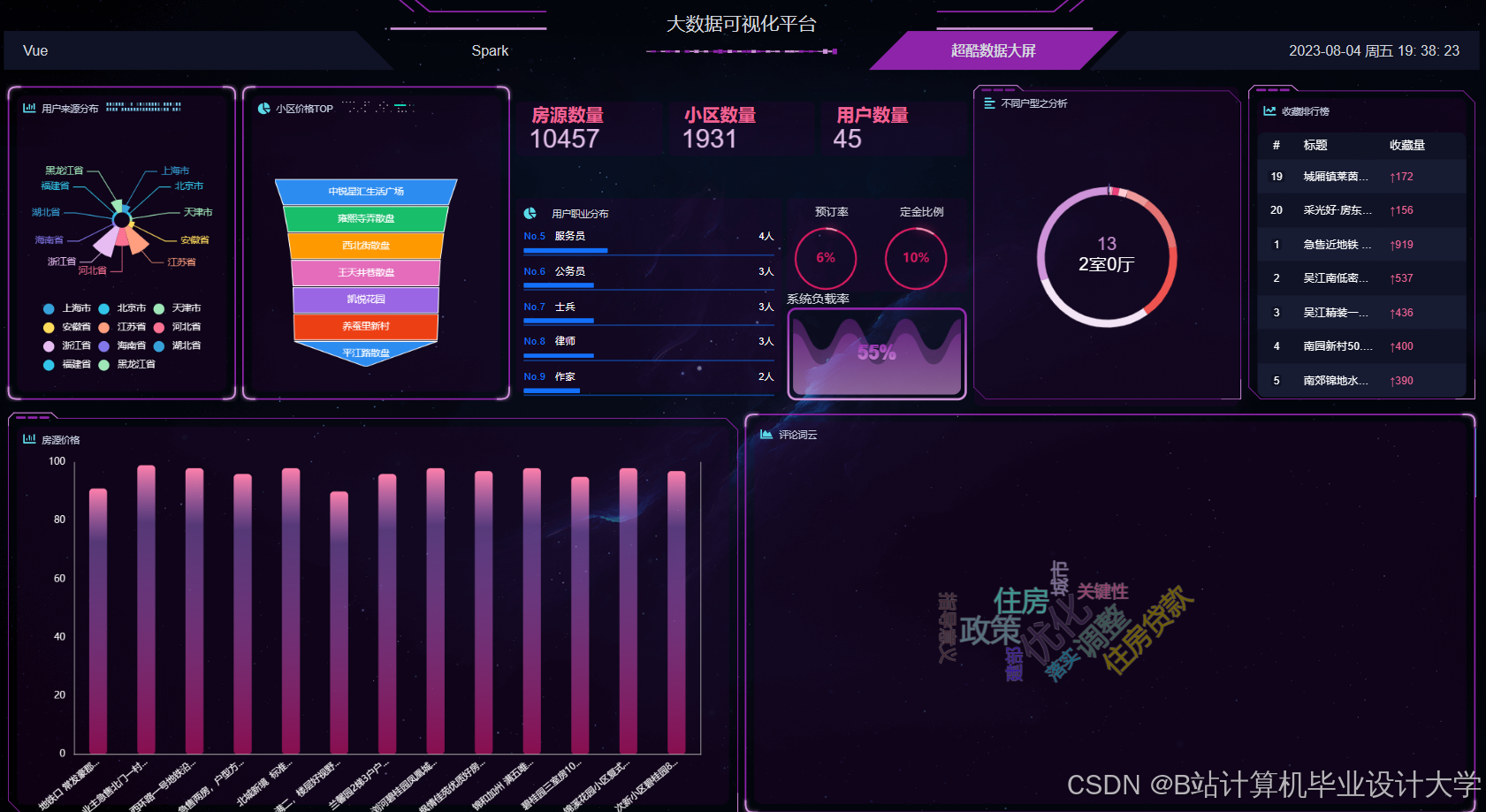
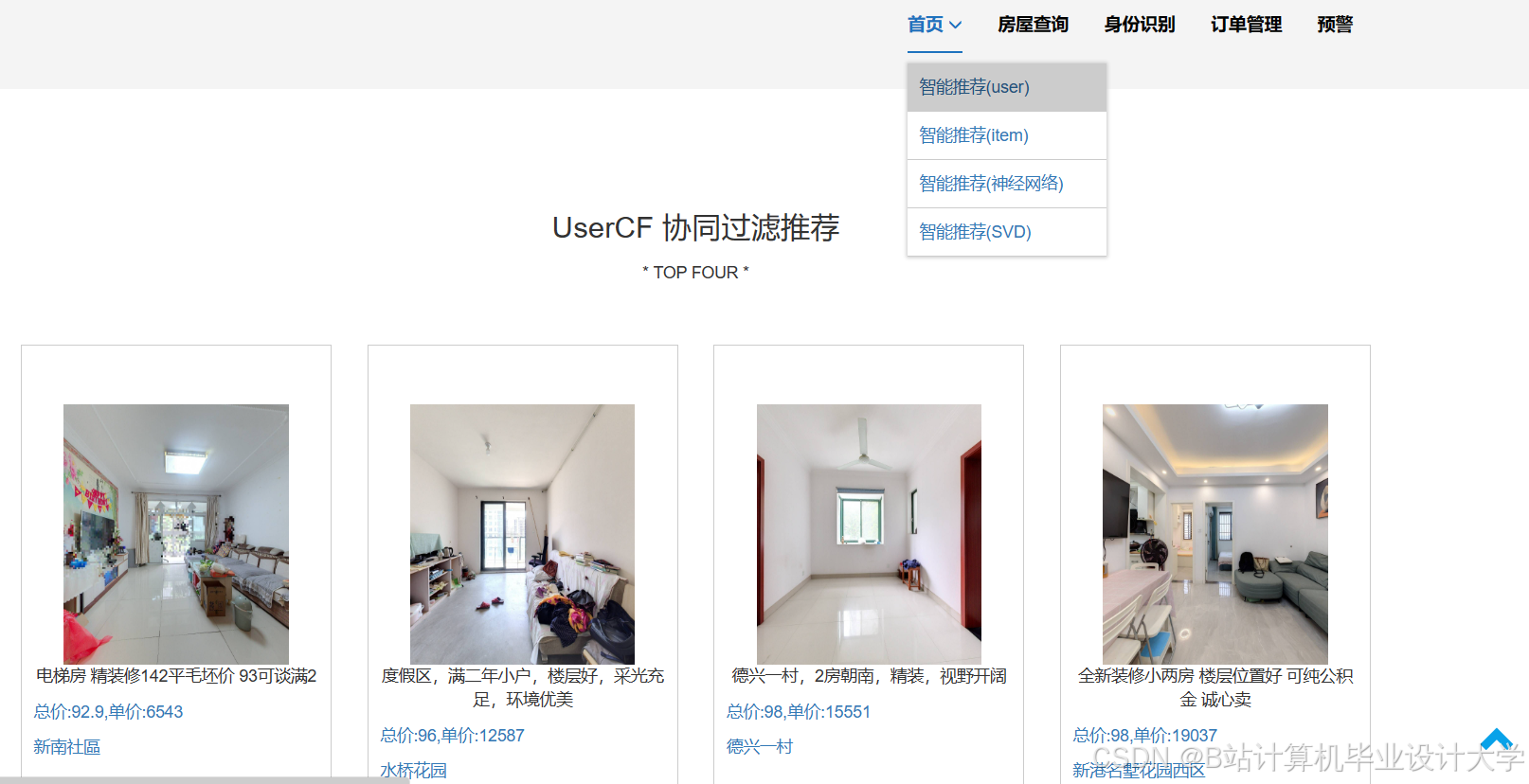
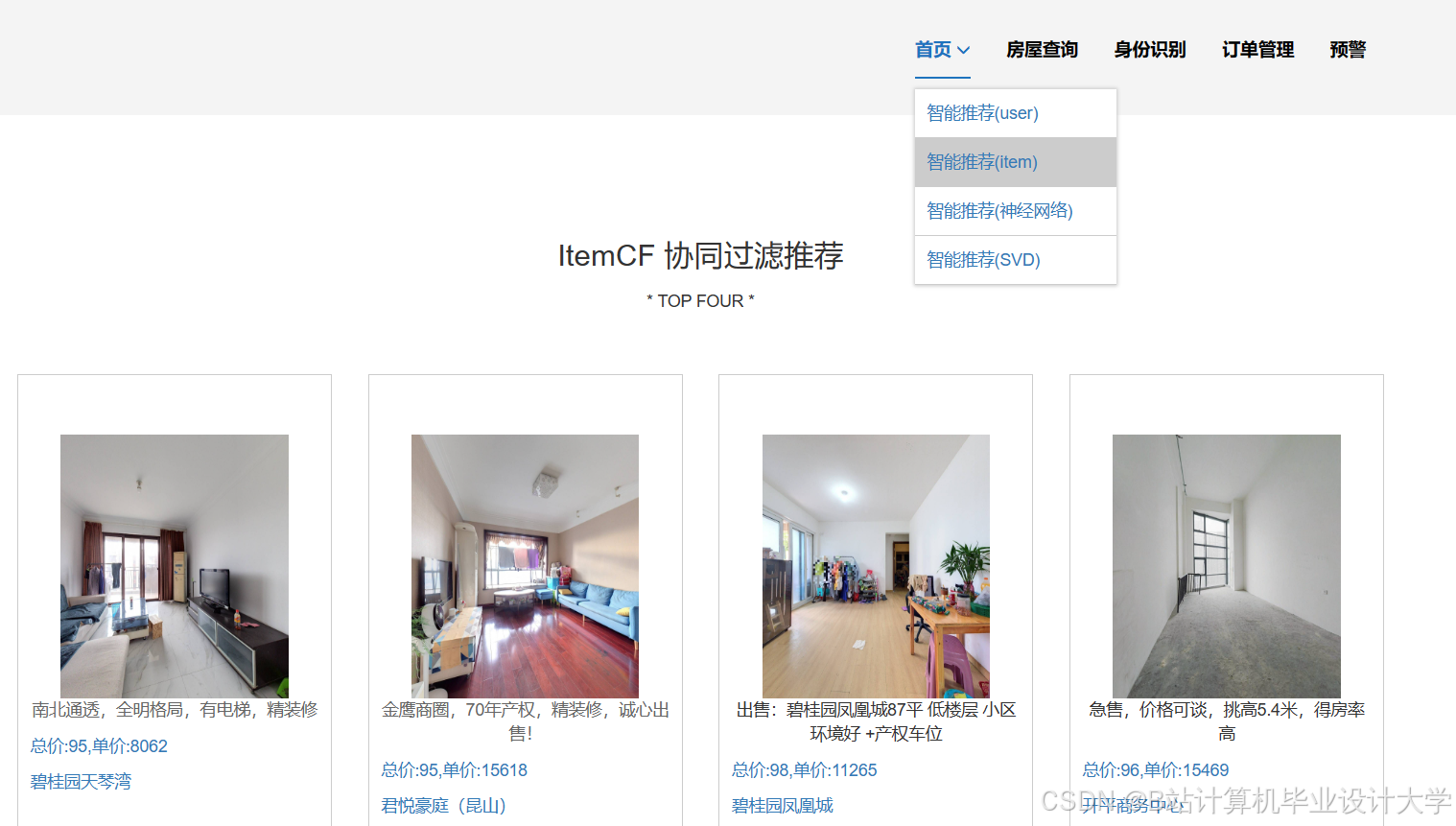
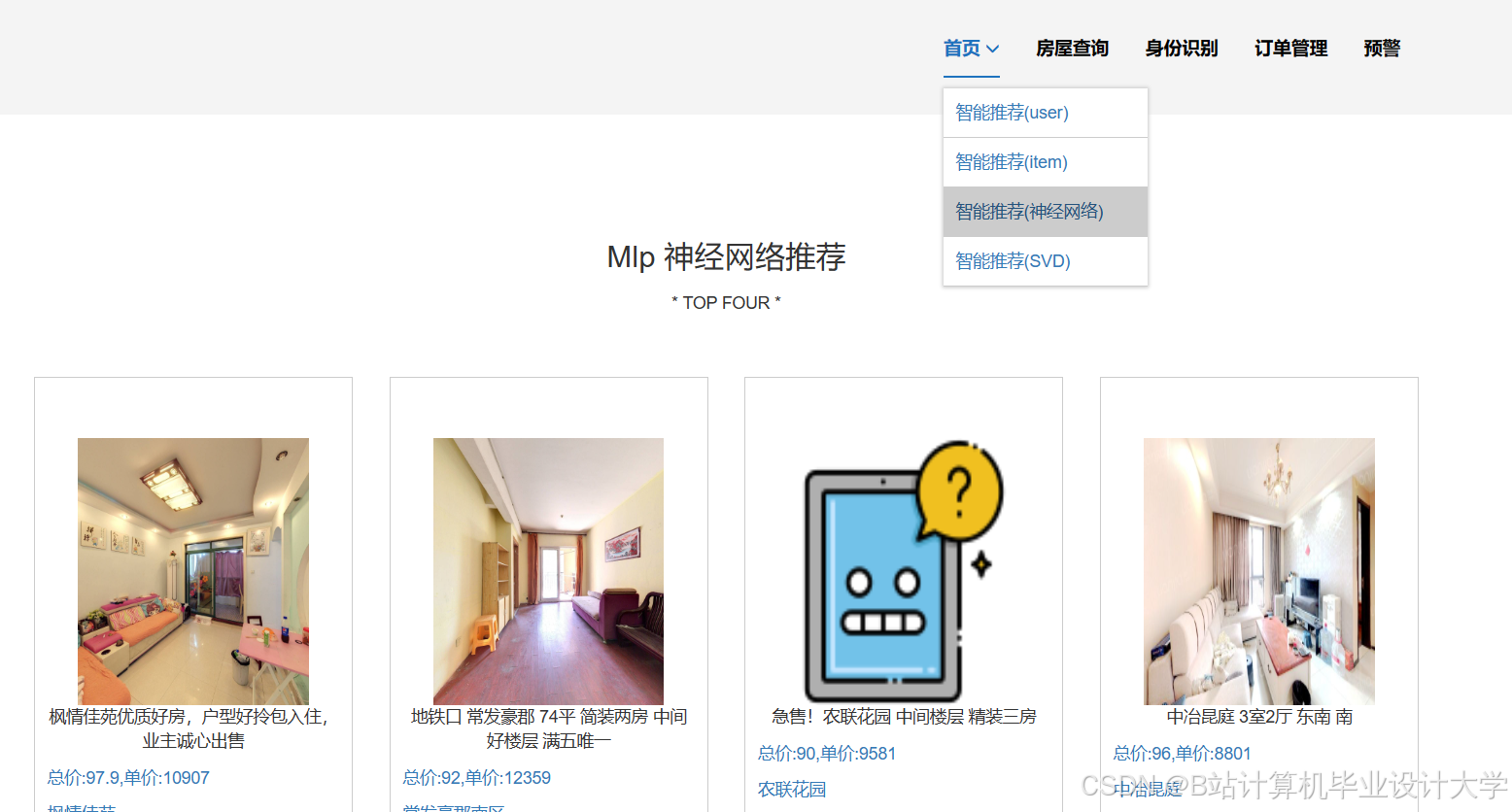
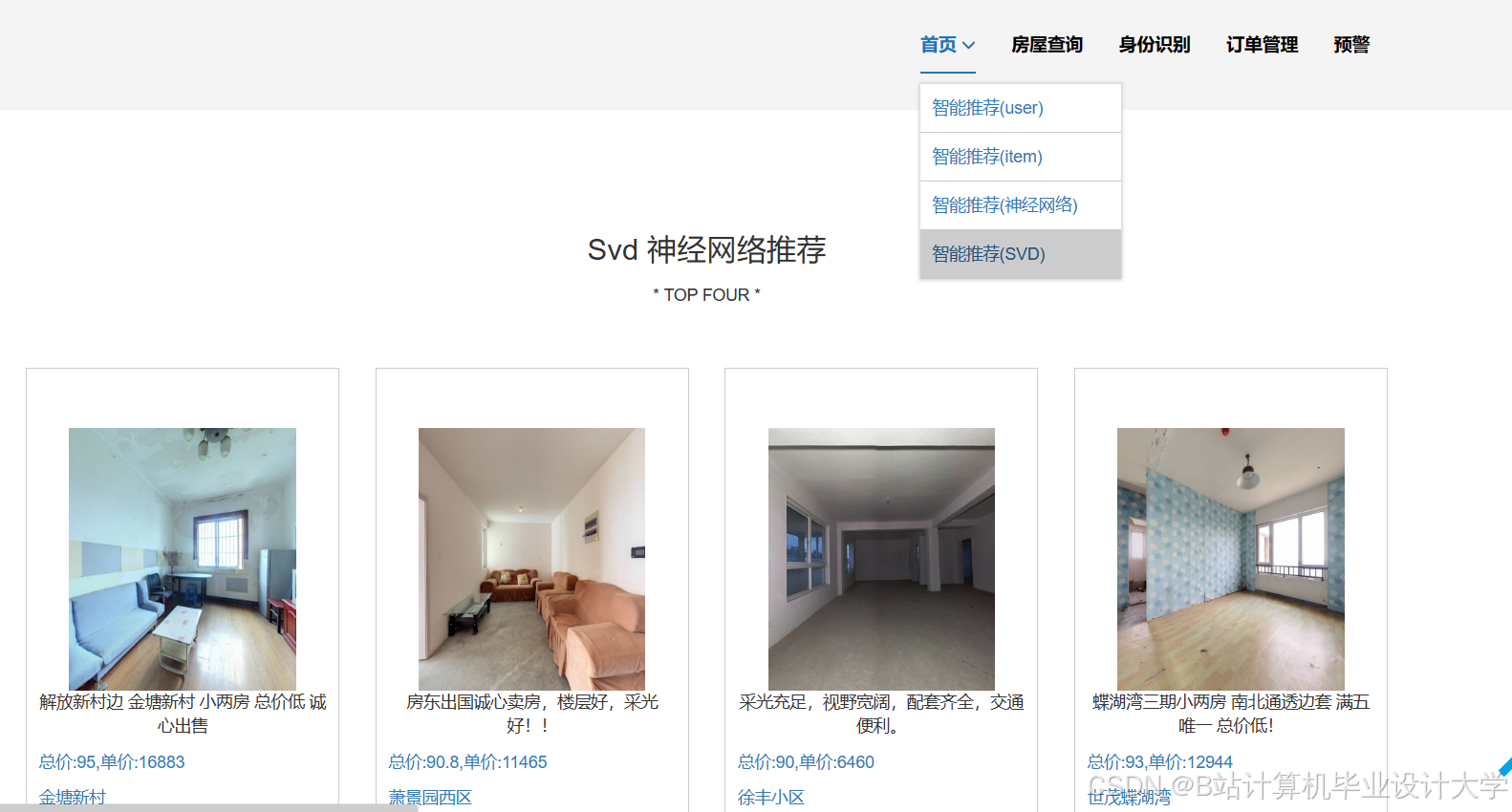
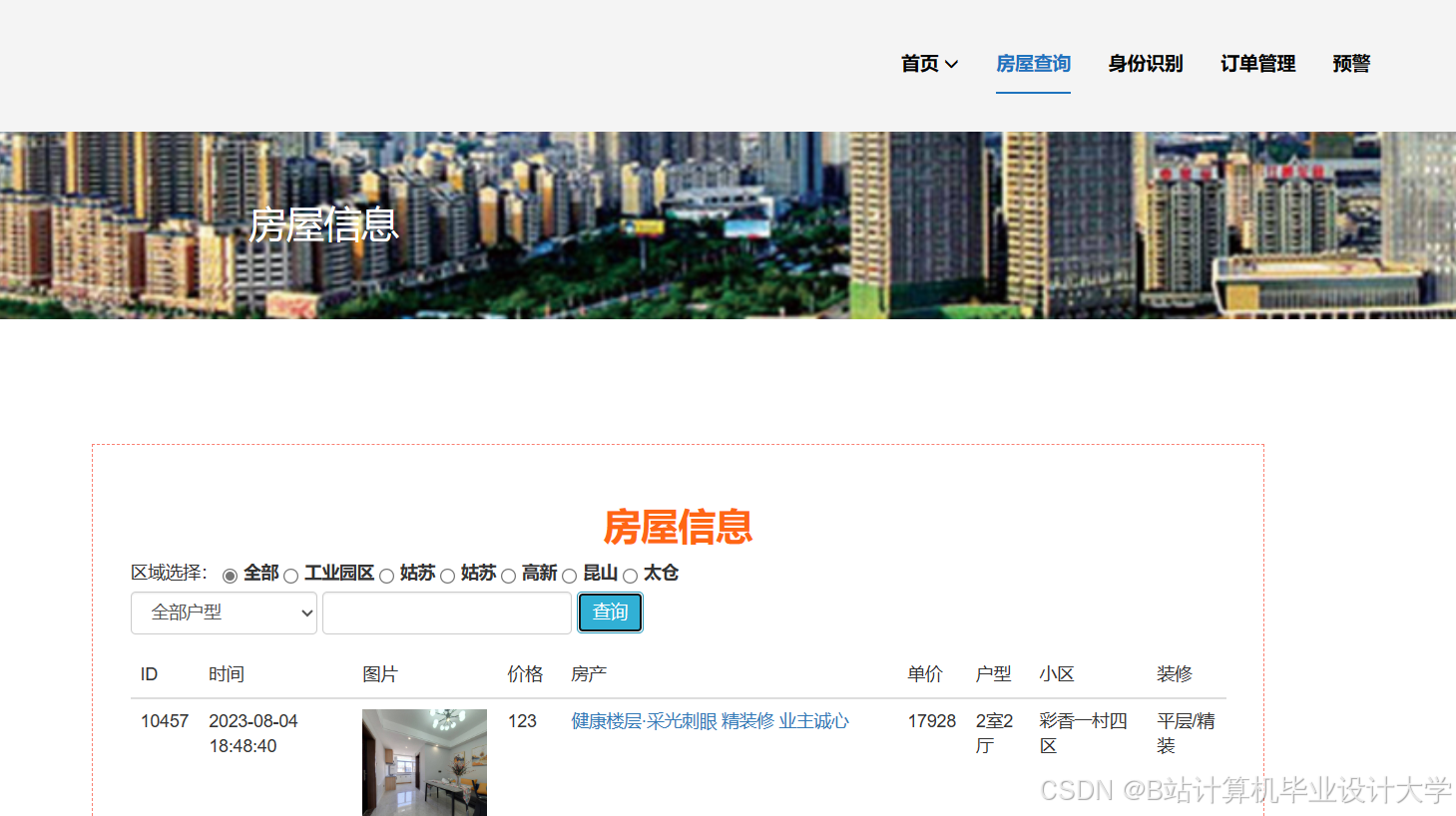
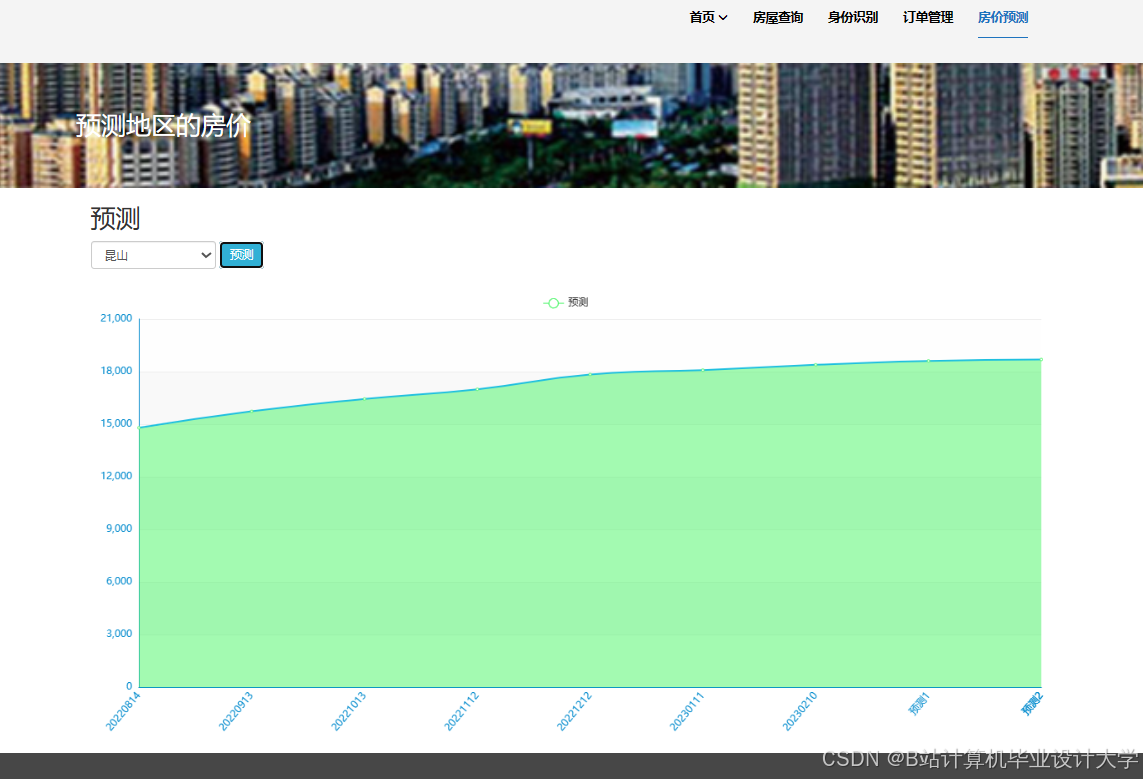
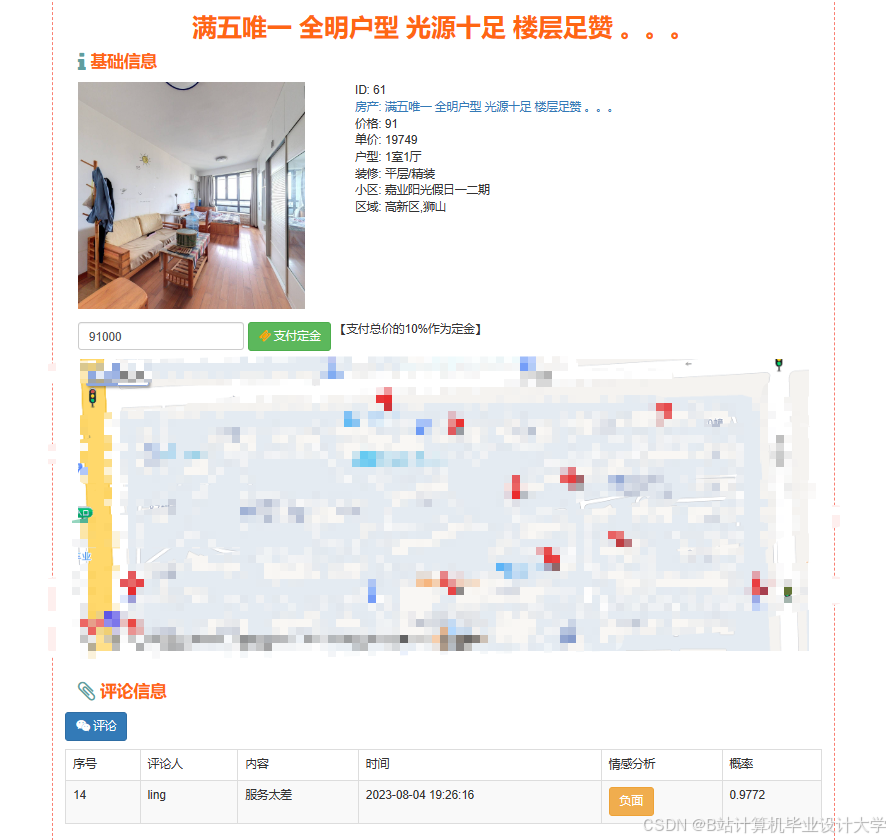

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











