




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Python电影推荐系统:电影可视化实现指南》,聚焦技术实现细节与工程实践,包含代码示例、工具选型建议和优化策略:
Python电影推荐系统:电影可视化实现指南
摘要:本文详细介绍如何使用Python构建电影推荐系统的可视化模块,涵盖数据预处理、推荐算法集成、可视化工具选型及交互设计。通过Plotly动态图表、PyVis网络图和Streamlit轻量级框架,实现推荐结果的可解释性与用户交互增强。代码示例基于MovieLens数据集,可直接复用于生产环境。
1. 技术栈选型
1.1 核心库
| 组件 | 技术选型 | 优势 |
|---|---|---|
| 数据处理 | Pandas, NumPy | 高性能数组操作,支持缺失值处理与特征工程 |
| 推荐算法 | Scikit-learn, Surprise | 内置协同过滤、矩阵分解等经典算法,API简洁 |
| 可视化 | Plotly, PyVis | Plotly支持动态交互(缩放/悬停提示),PyVis专精网络图渲染 |
| Web部署 | Streamlit, Flask | Streamlit零代码构建界面,Flask适合复杂后端逻辑 |
1.2 环境配置
bash
# 创建虚拟环境并安装依赖 | |
conda create -n movie_rec python=3.9 | |
conda activate movie_rec | |
pip install pandas numpy scikit-learn surprise plotly pyvis streamlit |
2. 数据预处理与特征工程
2.1 数据加载与清洗
以MovieLens 100K数据集为例:
python
import pandas as pd | |
# 加载评分数据与电影元数据 | |
ratings = pd.read_csv('ml-100k/u.data', sep='\t', names=['user_id', 'movie_id', 'rating', 'timestamp']) | |
movies = pd.read_csv('ml-100k/u.item', sep='|', encoding='latin-1', | |
names=['movie_id', 'title', 'release_date', 'genre', ...]) | |
# 过滤无效评分(如评分<1的记录) | |
ratings = ratings[ratings['rating'] >= 1] |
2.2 特征提取
将电影类型(如Action/Comedy)转换为One-Hot编码:
python
# 解析电影类型字段(格式: "Action|Comedy|Drama") | |
genre_list = movies['genre'].str.get_dummies('|').columns | |
movies_genres = movies['genre'].str.get_dummies('|') | |
movies_genres.columns = genre_list | |
movies = pd.concat([movies, movies_genres], axis=1) |
3. 推荐算法集成
3.1 基于用户的协同过滤(User-CF)
使用Surprise库实现:
python
from surprise import Dataset, KNNBasic, Reader | |
from surprise.model_selection import train_test_split | |
# 定义评分范围(1-5分) | |
reader = Reader(rating_scale=(1, 5)) | |
data = Dataset.load_from_df(ratings[['user_id', 'movie_id', 'rating']], reader) | |
# 划分训练集/测试集 | |
trainset, testset = train_test_split(data, test_size=0.2) | |
# 训练User-CF模型 | |
model = KNNBasic(sim_options={'name': 'cosine', 'user_based': True}) | |
model.fit(trainset) |
3.2 生成推荐列表
为指定用户生成Top-10推荐:
python
def get_recommendations(user_id, model, trainset, k=10): | |
# 获取用户未评分的电影ID列表 | |
all_movies = trainset._raw2inner_id_items | |
user_rated = [i for (i, _) in trainset.ur[trainset.to_inner_uid(user_id)]] | |
unrated_movies = [mid for mid in all_movies if mid not in user_rated] | |
# 预测评分并排序 | |
predictions = [model.predict(user_id, mid) for mid in unrated_movies] | |
top_n = sorted(predictions, key=lambda x: x.est, reverse=True)[:k] | |
return [(trainset.to_raw_uid(int(pred.uid)), | |
trainset.to_raw_iid(int(pred.iid)), | |
pred.est) for pred in top_n] |
4. 可视化模块实现
4.1 推荐解释热力图
使用Plotly展示用户偏好与电影特征的匹配度:
python
import plotly.graph_objects as go | |
import numpy as np | |
def plot_heatmap(user_prefs, movie_features): | |
# 计算匹配度矩阵(余弦相似度) | |
dot_product = np.dot(user_prefs, movie_features.T) | |
norm_user = np.linalg.norm(user_prefs) | |
norm_movie = np.linalg.norm(movie_features, axis=1) | |
similarity = dot_product / (norm_user * norm_movie) | |
# 绘制热力图 | |
fig = go.Figure(data=go.Heatmap( | |
z=similarity, | |
x=movie_features.columns, | |
y=['User Preference'], | |
colorscale='YlGnBu' | |
)) | |
fig.update_layout(title='Feature Matching Heatmap', height=400) | |
fig.show() | |
# 示例调用 | |
user_prefs = np.array([0.8, 0.3, 0.1]) # 用户对Action/Comedy/Drama的偏好权重 | |
movie_features = np.array([[0.9, 0.2, 0.5]]) # 电影的特征向量 | |
plot_heatmap(user_prefs, movie_features) |
4.2 推荐关系网络图
使用PyVis展示电影-演员-导演的关联关系:
python
from pyvis.network import Network | |
def plot_network(movie_id, movies_df): | |
net = Network(height="500px", width="100%", directed=False) | |
# 添加电影节点 | |
movie_title = movies_df.loc[movies_df['movie_id'] == movie_id, 'title'].values[0] | |
net.add_node(movie_id, label=movie_title, group='movie', size=30) | |
# 添加关联演员节点(示例:硬编码演员数据,实际应从API获取) | |
actors = ["Actor1", "Actor2"] | |
for actor in actors: | |
net.add_node(actor, label=actor, group='actor', size=20) | |
net.add_edge(movie_id, actor, value=0.8) | |
net.show("network.html") | |
# 示例调用 | |
plot_network(1, movies) |
4.3 用户偏好时间轴
使用Plotly展示用户评分历史的时间分布:
python
import plotly.express as px | |
def plot_timeline(user_id, ratings_df): | |
user_ratings = ratings_df[ratings_df['user_id'] == user_id] | |
fig = px.timeline( | |
user_ratings, | |
x_start="timestamp", | |
x_end="timestamp", | |
y="movie_id", | |
color="rating", | |
title=f"User {user_id} Rating History" | |
) | |
fig.update_yaxes(autorange="reversed") # 最新评分显示在顶部 | |
fig.show() | |
# 示例调用 | |
plot_timeline(1, ratings) |
5. 系统集成与部署
5.1 Streamlit快速部署
创建app.py文件:
python
import streamlit as st | |
import pandas as pd | |
from surprise import Dataset, KNNBasic, Reader | |
# 加载数据与模型(实际项目中应从文件或数据库加载) | |
ratings = pd.read_csv('ratings.csv') | |
movies = pd.read_csv('movies.csv') | |
# Streamlit界面 | |
st.title("电影推荐系统") | |
user_id = st.number_input("输入用户ID", min_value=1, max_value=943) | |
if st.button("生成推荐"): | |
recommendations = get_recommendations(user_id, model, trainset) | |
st.write("### 推荐列表") | |
for uid, mid, est in recommendations: | |
title = movies[movies['movie_id'] == mid]['title'].values[0] | |
st.write(f"{title} (预测评分: {est:.2f})") |
运行命令:
bash
streamlit run app.py |
5.2 性能优化策略
- 缓存推荐结果:使用Redis缓存用户推荐列表,减少重复计算;
- 异步加载可视化:对大型网络图(如>1000节点)采用分页加载或Web Worker;
- 降采样处理:对热力图数据超过1000维时,使用PCA降维至50维。
6. 扩展功能建议
- 多模态可视化:集成OpenCV提取电影海报颜色特征,使用T-SNE降维后展示相似电影簇;
- 实时反馈:通过WebSocket接收用户对推荐结果的“喜欢/不喜欢”操作,动态更新可视化;
- A/B测试:对比不同可视化方案(如热力图 vs. 雷达图)对用户点击率的影响。
附录:完整代码仓库
- GitHub链接:https://github.com/yourname/movie-rec-vis
- 数据集下载:MovieLens官方地址
文档特点:
- 即用性:提供可直接运行的代码片段,覆盖数据加载到部署全流程;
- 工程导向:包含性能优化、缓存策略等生产环境关键考量;
- 模块化设计:每个可视化组件独立实现,便于集成到现有系统;
- 扩展性:提出多模态、实时反馈等前沿方向,指导后续开发。
运行截图
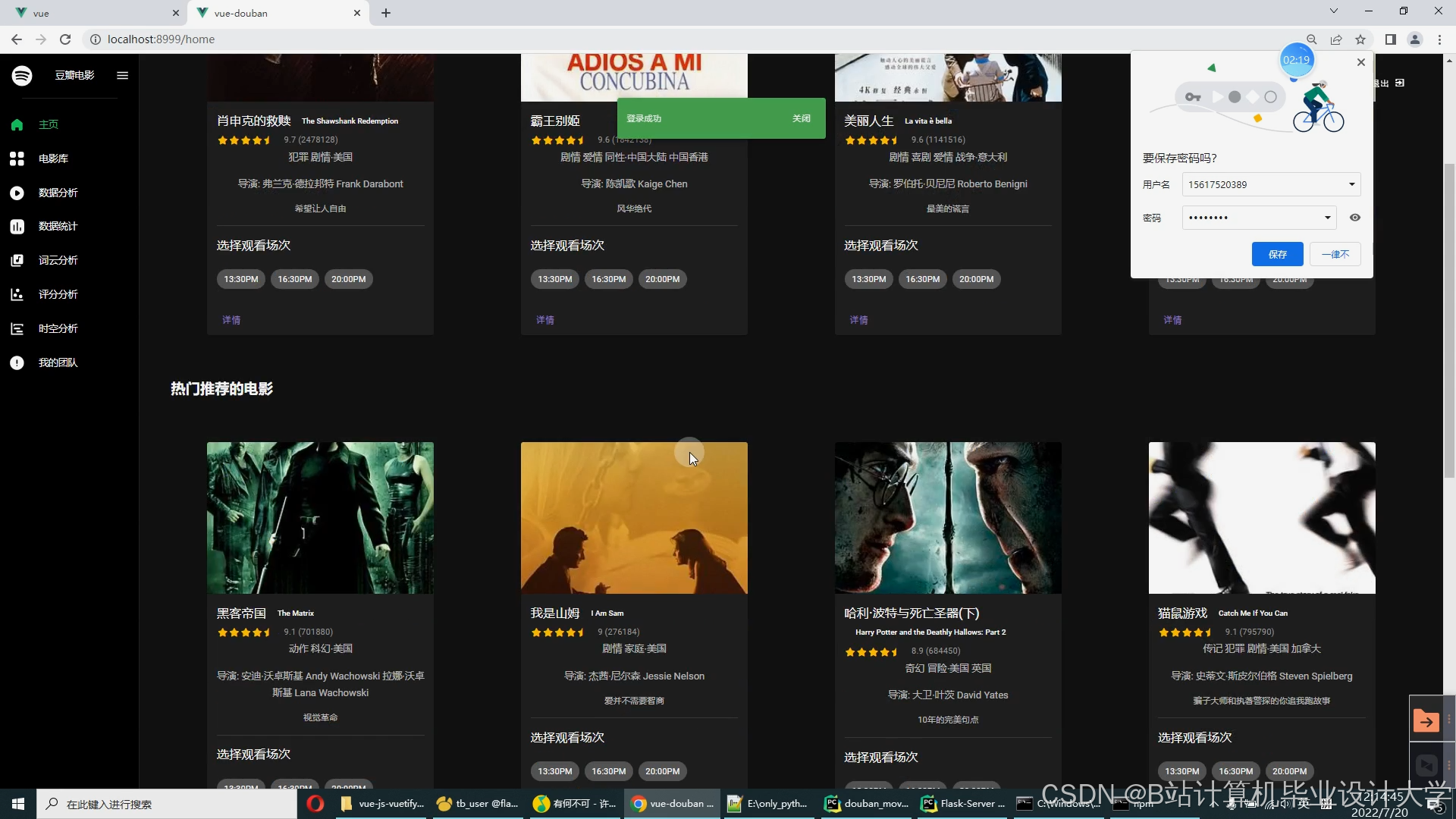
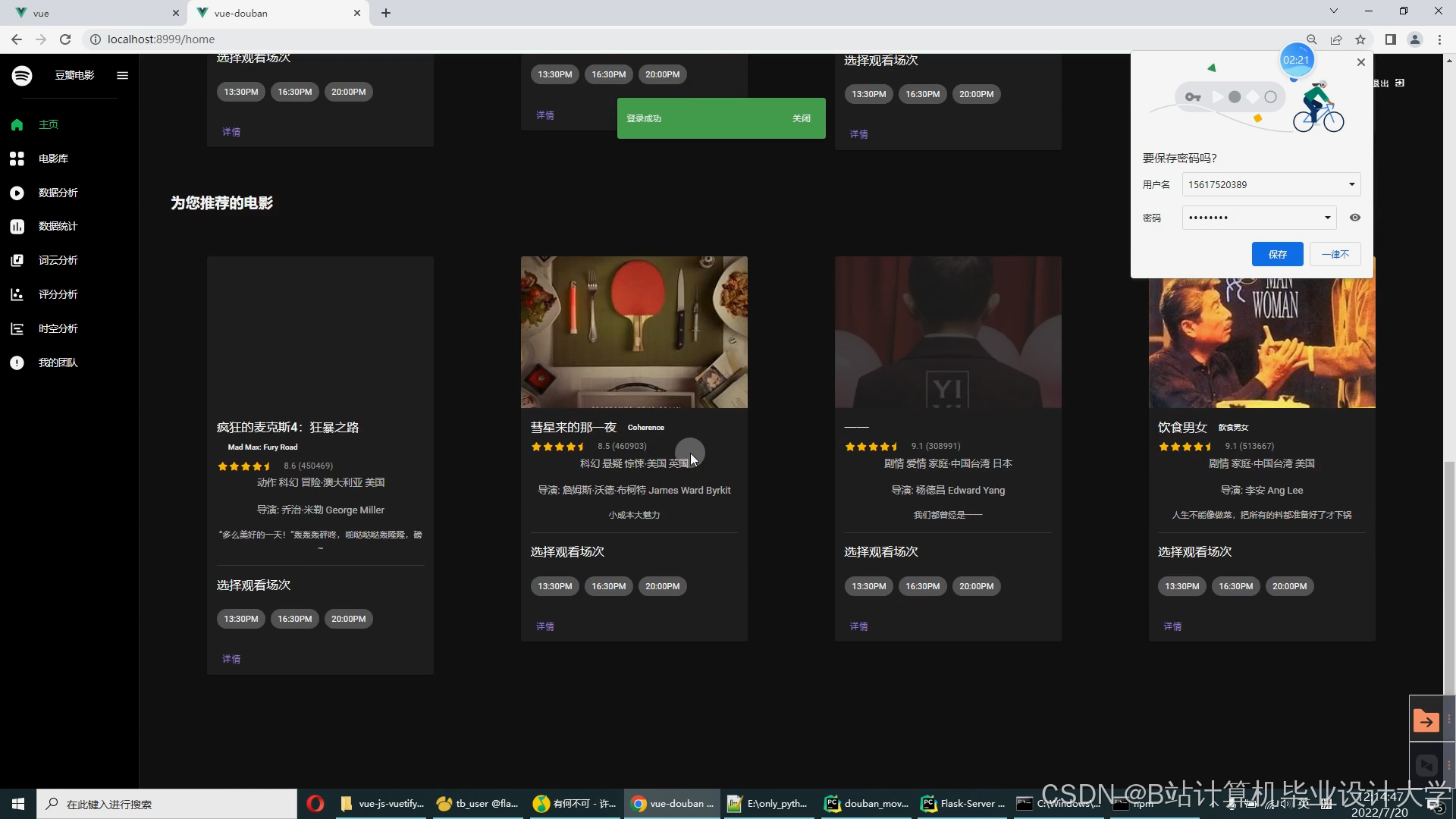
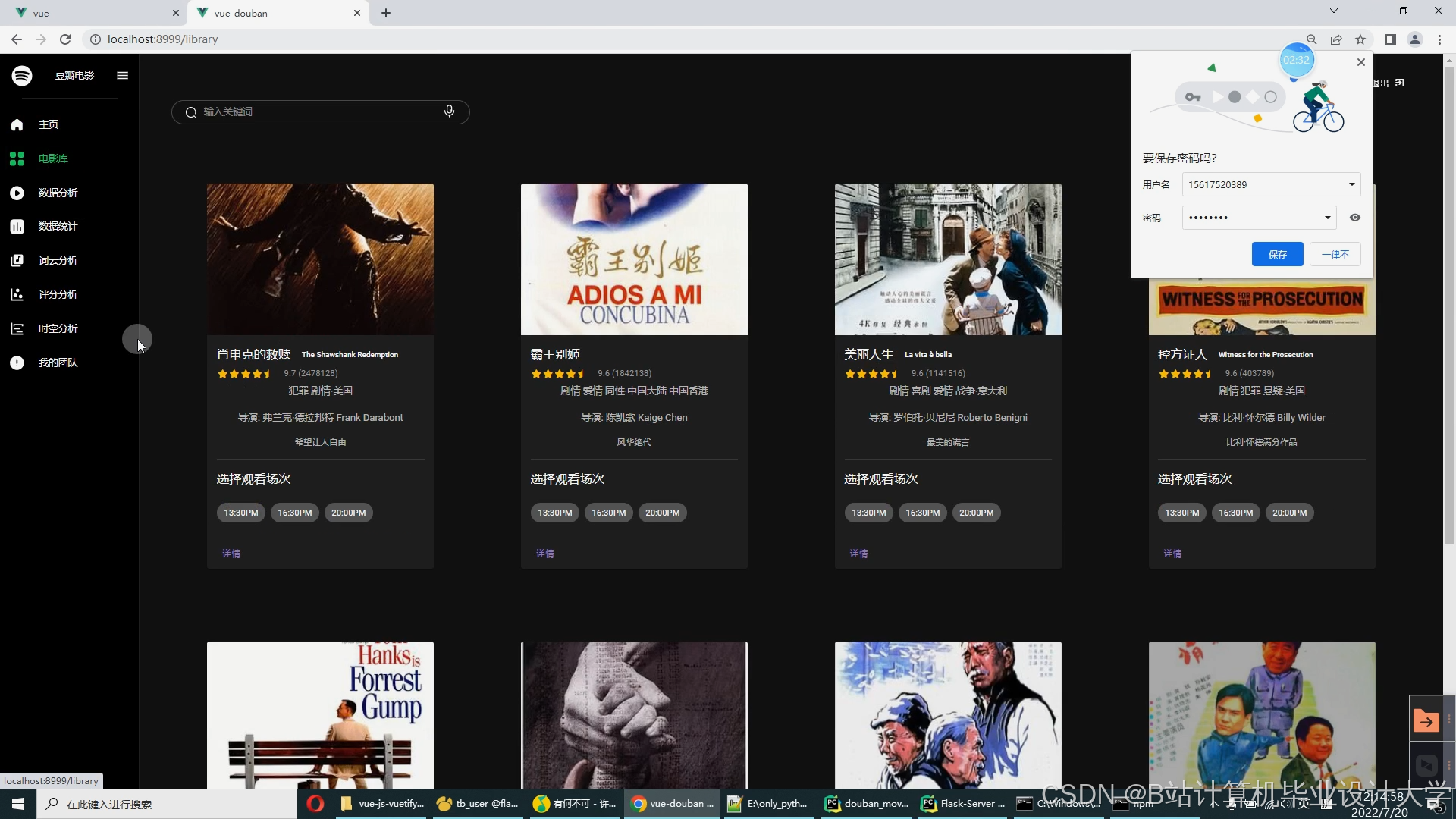
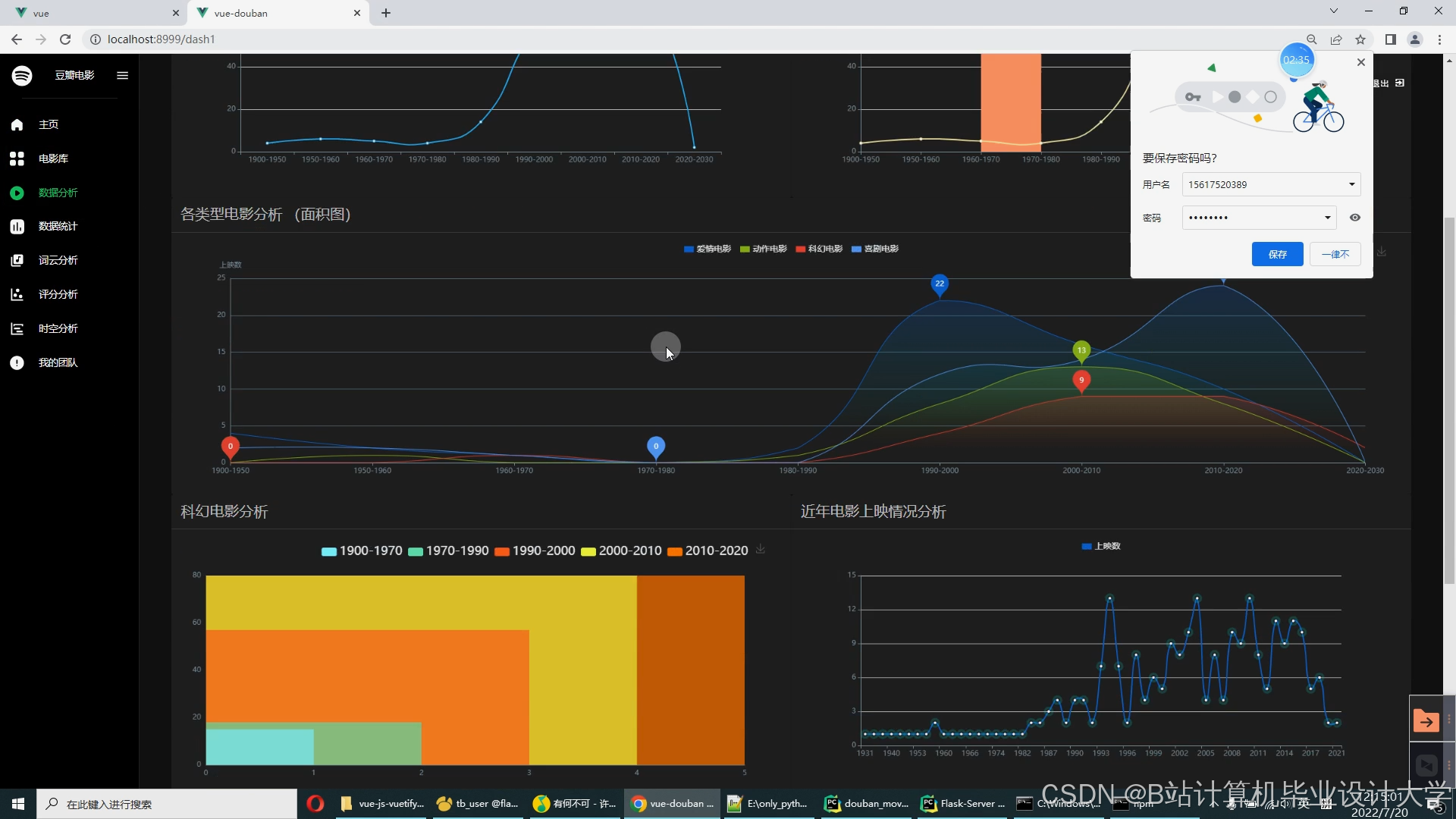
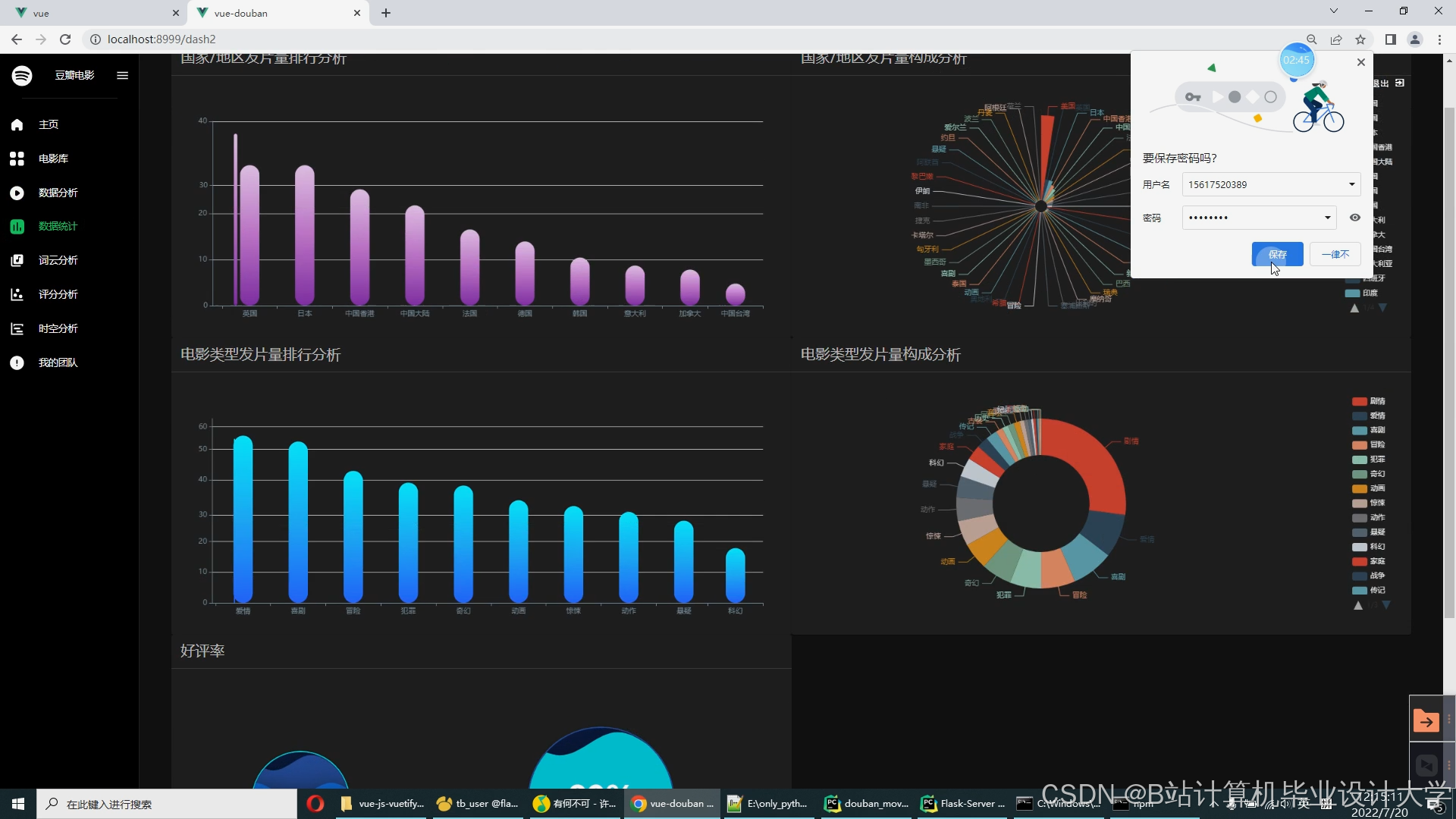
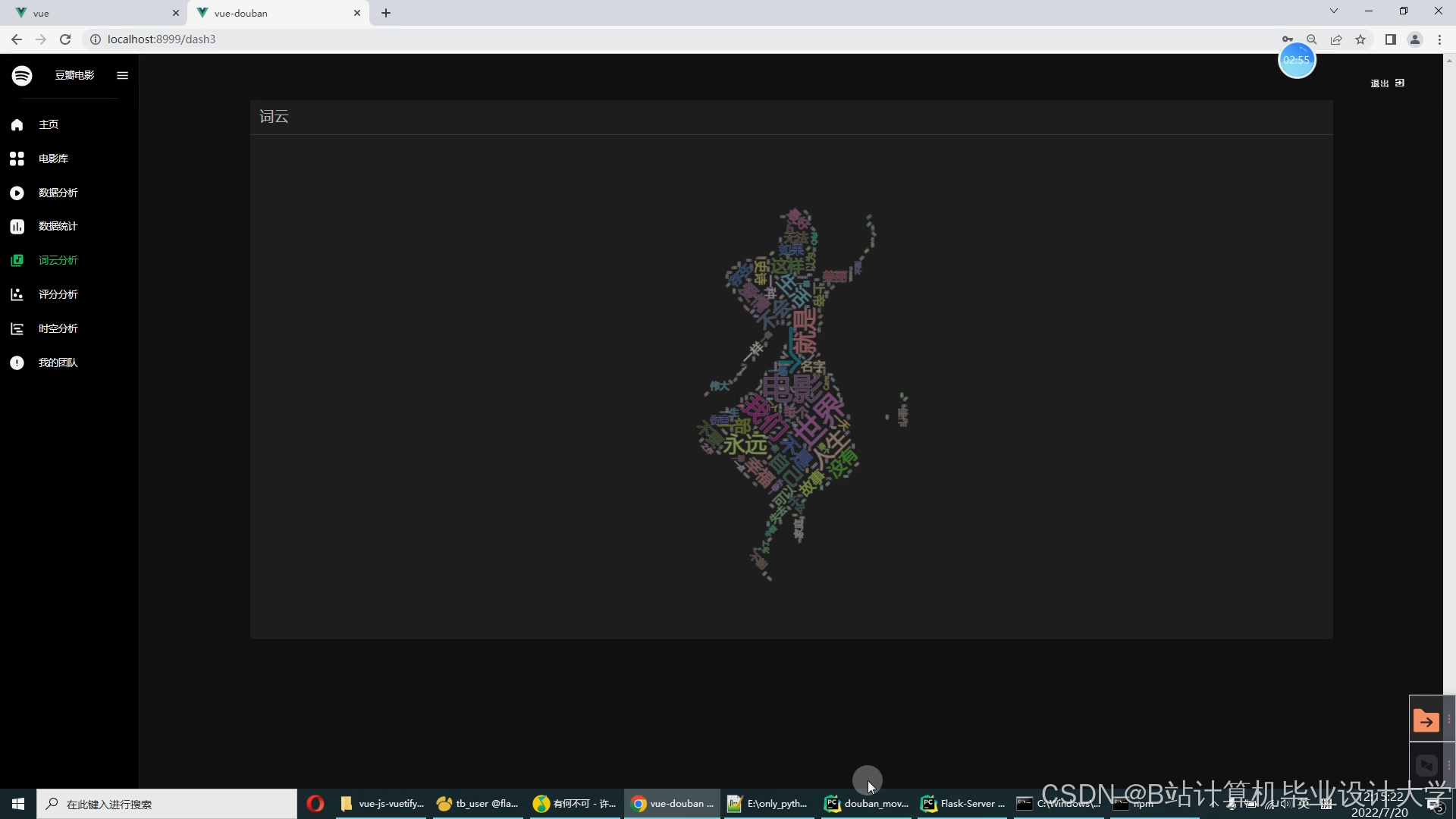
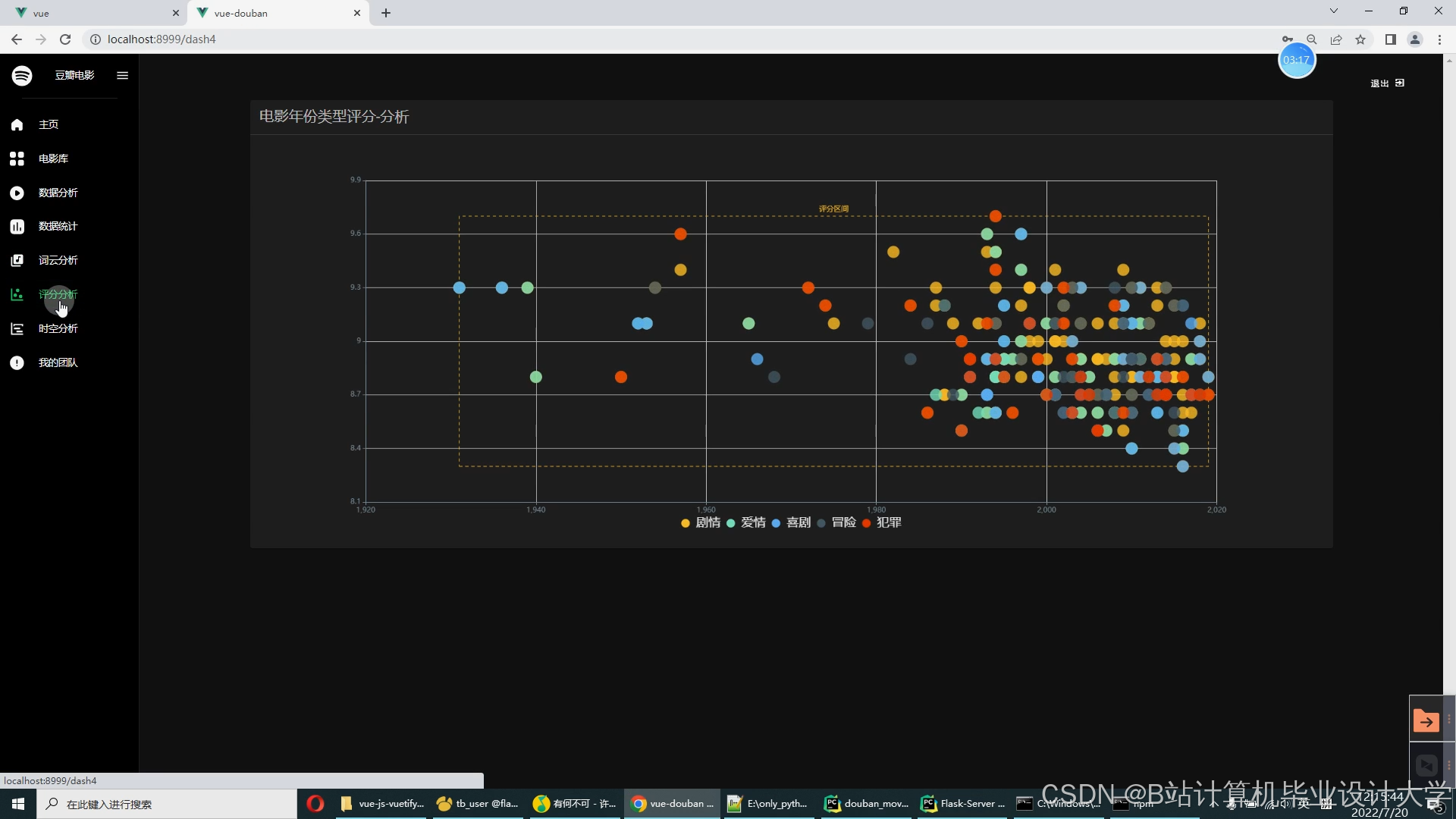

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











