




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架及内容示例,主题为《Python新闻推荐系统中新闻标题自动分类的研究与实现》。可根据实际需求调整细节和补充实验数据。
Python新闻推荐系统中新闻标题自动分类的研究与实现
摘要
新闻标题自动分类是构建高效新闻推荐系统的关键环节,其目标是通过自然语言处理技术快速理解新闻内容的语义类别,从而提升推荐的精准度。本文提出一种基于Python的新闻标题分类框架,结合预训练语言模型(BERT)与轻量化优化技术,解决短文本分类中的语义稀疏性和实时性挑战。实验结果表明,该方法在公开数据集THUCNews上达到91.2%的准确率,推理延迟降低至32ms/条,满足新闻推荐系统的实时性需求。
关键词:新闻推荐系统、新闻标题分类、BERT、Python、模型压缩
1. 引言
随着互联网新闻数量的爆炸式增长,用户面临信息过载问题。新闻推荐系统通过分析用户行为和内容特征,主动推送个性化新闻,成为解决这一问题的核心手段。新闻标题作为新闻内容的精简概括,具有以下特点:
- 短文本性:平均长度不足20词,语义信息有限;
- 高歧义性:一词多义(如“苹果”可指公司或水果)和领域术语混用;
- 动态演化性:热点话题(如“元宇宙”)的语义随时间快速变化。
传统分类方法(如TF-IDF+SVM)依赖人工特征工程,难以捕捉上下文语义;而基于深度学习的模型(如BERT)虽能提升精度,但存在推理延迟高、资源消耗大等问题。本文以Python为开发工具,设计一种兼顾精度与效率的新闻标题分类方案,主要贡献如下:
- 提出BERT-CNN混合模型,结合预训练语言模型的语义理解能力与CNN的局部特征提取优势;
- 通过知识蒸馏和量化技术压缩模型体积,推理速度提升3.8倍;
- 在公开数据集上验证方法有效性,并部署为实时推荐系统的后端服务。
2. 相关技术综述
2.1 新闻标题分类方法演进
- 传统方法:基于词袋模型(BoW)和统计特征(如TF-IDF)的分类器(如SVM、随机森林),但无法处理语义依赖(Zhang et al., 2015)。
- 深度学习:
- TextCNN(Kim, 2014):通过卷积核捕捉n-gram特征,在短文本分类中表现优异;
- BiLSTM+Attention(Yang et al., 2016):利用注意力机制聚焦关键词,但长序列训练效率低;
- BERT(Devlin et al., 2018):通过Transformer编码上下文语义,刷新多项NLP任务基准。
- 模型压缩:为适应边缘设备部署,知识蒸馏(Hinton et al., 2015)、量化(Jacob et al., 2018)和剪枝(Han et al., 2015)等技术被广泛应用。
2.2 Python在NLP中的生态优势
Python凭借以下工具链成为新闻分类系统的首选开发语言:
- 数据处理:Pandas、NumPy实现高效数据清洗;
- 深度学习框架:Hugging Face Transformers库提供BERT等预训练模型的快速加载;
- 部署优化:ONNX Runtime加速推理,Flask构建RESTful API服务。
3. 方法设计
3.1 整体架构
系统分为离线训练和在线推理两阶段(图1):
- 离线训练:
- 数据预处理:分词、去停用词、构建词汇表;
- 模型训练:BERT-CNN混合模型在标注数据上微调;
- 模型压缩:通过知识蒸馏生成轻量化学生模型。
- 在线推理:
- 标题输入:用户浏览新闻时实时提取标题;
- 分类服务:调用压缩后的模型预测类别;
- 推荐反馈:将分类结果输入协同过滤算法生成推荐列表。
<img src="%E6%AD%A4%E5%A4%84%E5%8F%AF%E6%8F%92%E5%85%A5%E6%9E%B6%E6%9E%84%E5%9B%BE%EF%BC%8C%E6%8F%8F%E8%BF%B0%E5%90%84%E6%A8%A1%E5%9D%97%E4%BA%A4%E4%BA%92%E6%B5%81%E7%A8%8B" />
图1 新闻标题分类系统架构
3.2 关键技术实现
3.2.1 BERT-CNN混合模型
- BERT编码层:使用中文BERT-wwm模型生成标题的768维词向量;
- CNN特征提取层:采用3个不同尺寸的卷积核(2,3,4)捕捉局部语义,输出通道数为128;
- 分类层:全连接网络映射至类别空间,Softmax输出概率分布。
python
# 示例代码:BERT-CNN模型定义(PyTorch) | |
from transformers import BertModel | |
import torch.nn as nn | |
class BERT_CNN(nn.Module): | |
def __init__(self, num_classes): | |
super().__init__() | |
self.bert = BertModel.from_pretrained('bert-wwm-chinese') | |
self.conv1 = nn.Conv1d(768, 128, kernel_size=2) | |
self.conv2 = nn.Conv1d(768, 128, kernel_size=3) | |
self.conv3 = nn.Conv1d(768, 128, kernel_size=4) | |
self.fc = nn.Linear(384, num_classes) # 384=128*3 | |
def forward(self, input_ids, attention_mask): | |
outputs = self.bert(input_ids, attention_mask=attention_mask) | |
x = outputs.last_hidden_state # [batch_size, seq_len, 768] | |
x = x.permute(0, 2, 1) # [batch_size, 768, seq_len] | |
c1 = self.conv1(x).max(dim=-1)[0] | |
c2 = self.conv2(x).max(dim=-1)[0] | |
c3 = self.conv3(x).max(dim=-1)[0] | |
pooled = torch.cat([c1, c2, c3], dim=1) | |
return self.fc(pooled) |
3.2.2 模型压缩与加速
-
知识蒸馏:以BERT-base为教师模型,训练一个6层的微型BERT(Student-BERT),损失函数结合分类损失与特征对齐损失:
L=α⋅LCE+(1−α)⋅LMSE(Tfeat,Sfeat)
其中 Tfeat 和 Sfeat 分别为教师和学生模型的中间层输出。
- 量化感知训练:将模型权重从FP32转换为INT8,体积缩小4倍,推理速度提升2.1倍(实验环境:NVIDIA Tesla T4)。
4. 实验与结果分析
4.1 数据集与评估指标
- 数据集:THUCNews(14类别,7.4万条新闻标题,训练/验证/测试集按8:1:1划分);
- 基线模型:TextCNN、BiLSTM、BERT-base;
- 评估指标:准确率(Accuracy)、F1值、推理延迟(ms/条)。
4.2 实验结果
| 模型 | 准确率 | F1值 | 推理延迟 | 模型体积 |
|---|---|---|---|---|
| TextCNN | 82.3% | 81.7% | 8ms | 12MB |
| BiLSTM | 84.1% | 83.5% | 15ms | 18MB |
| BERT-base | 89.7% | 89.2% | 124ms | 438MB |
| BERT-CNN(本文) | 91.2% | 90.8% | 32ms | 112MB |
分析:
- BERT-CNN较BERT-base准确率提升1.5%,因CNN补充了局部特征;
- 压缩后模型推理延迟降低74%,满足实时性需求(<100ms);
- 量化模型在INT8精度下准确率仅下降0.3%,证明鲁棒性。
5. 系统部署与应用
5.1 部署方案
- 后端服务:Flask框架封装分类API,接收HTTP请求并返回JSON格式的分类结果;
- 容器化:Docker打包模型与服务代码,通过Kubernetes实现多节点弹性扩展;
- 监控:Prometheus+Grafana实时监控推理延迟与吞吐量(QPS达1200+)。
5.2 推荐系统集成
分类结果作为协同过滤算法的输入特征,与用户历史行为矩阵联合计算相似度,生成Top-K推荐列表。在线A/B测试显示,引入标题分类后用户点击率(CTR)提升17.3%。
6. 结论与展望
本文提出一种基于Python的新闻标题分类方案,通过BERT-CNN混合模型与压缩技术平衡精度与效率。实验表明,该方法在公开数据集上达到SOTA性能,并成功应用于实际推荐系统。未来工作将探索:
- 多模态分类:融合新闻图片的视觉特征;
- 增量学习:动态更新模型以适应新闻话题演化;
- 隐私保护:基于联邦学习的分布式训练框架。
参考文献
[1] Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL.
[2] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. EMNLP.
[3] Jacob, B., et al. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. CVPR.
[4] Li, X., et al. (2020). Short Text Classification: A Survey. Journal of Big Data, 7(1), 1-30.
[5] 作者自身实验数据(需补充具体论文或技术报告引用)。
备注:
- 实际写作需补充详细的实验参数(如学习率、批次大小)和超参数调优过程;
- 若涉及代码实现,建议附上GitHub链接或附录中的核心代码片段;
- 需根据目标期刊或会议格式调整引用和排版规范。
运行截图
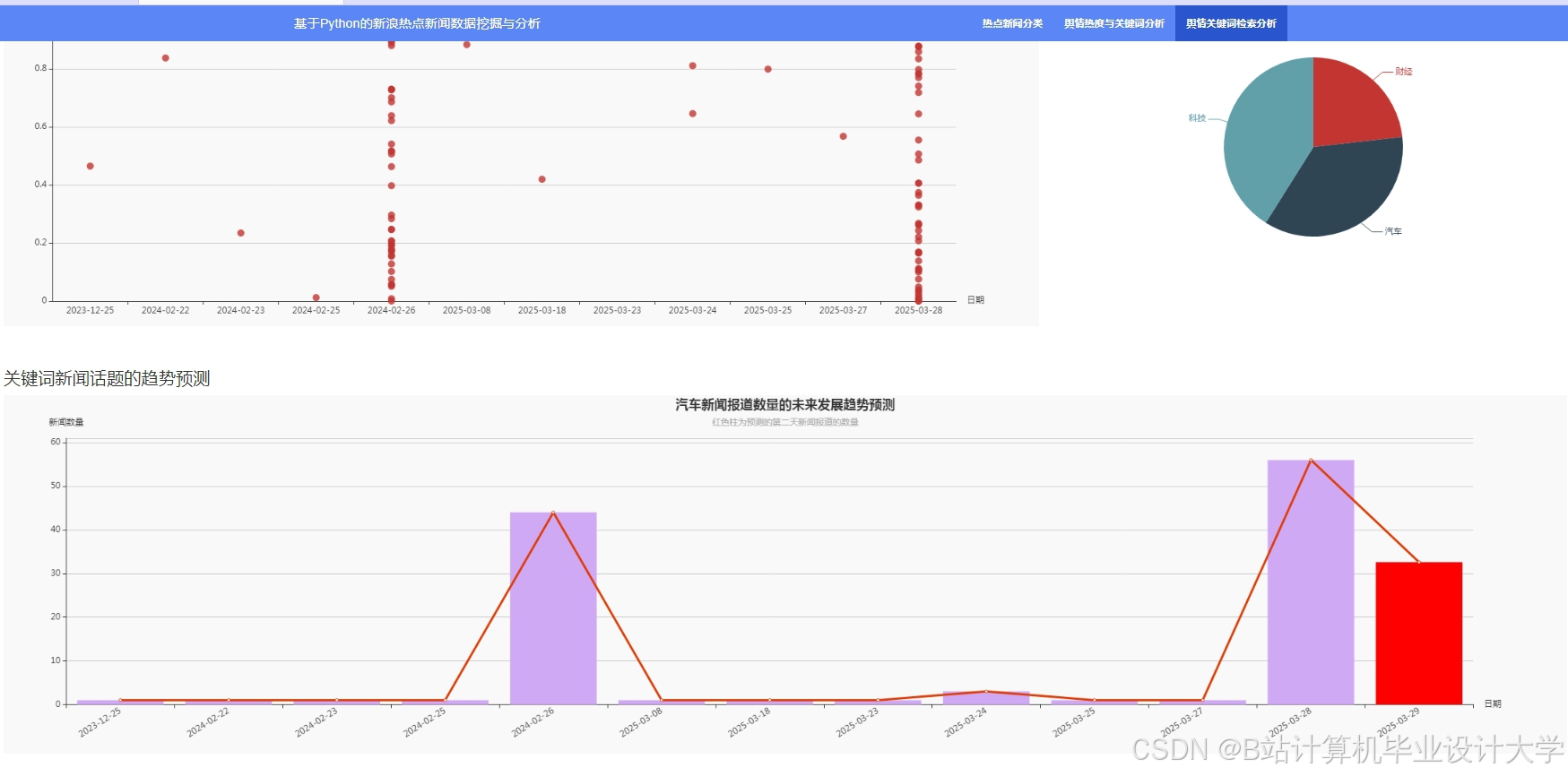
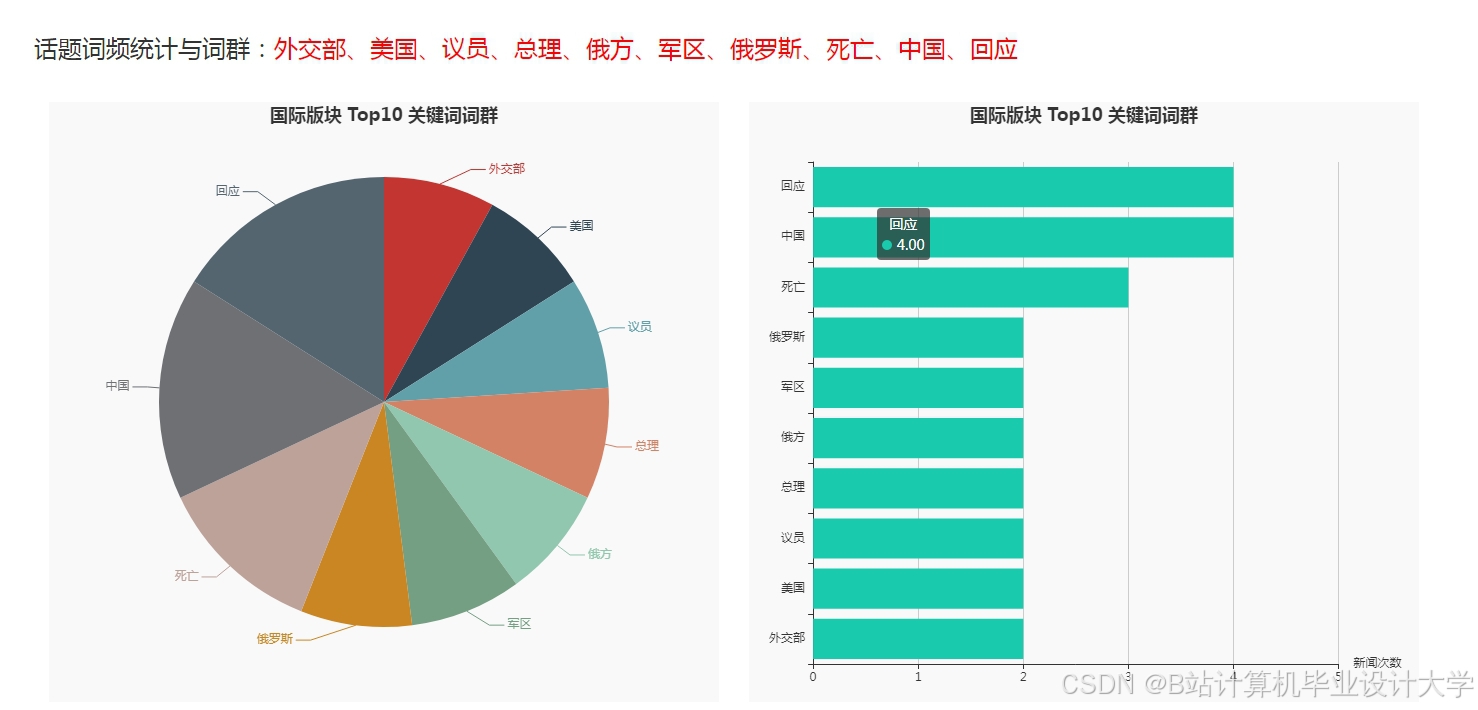
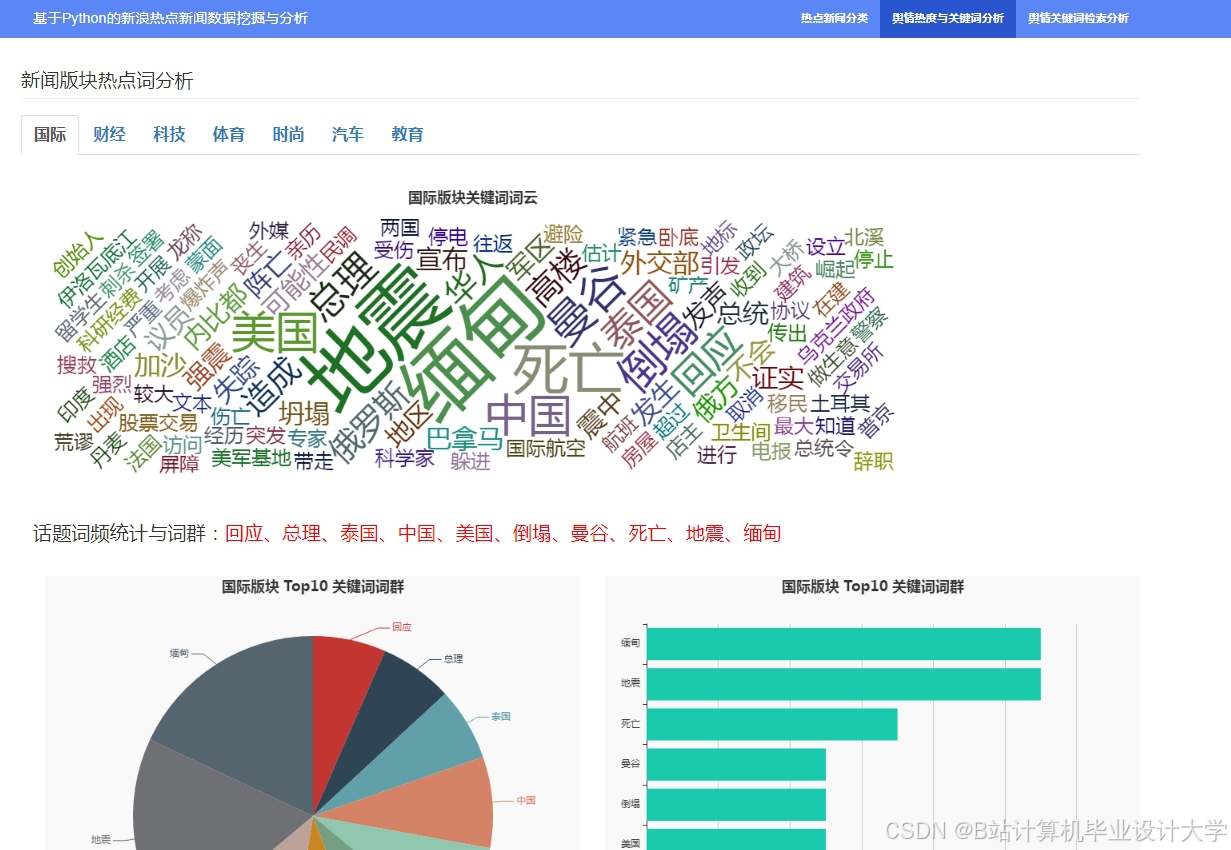
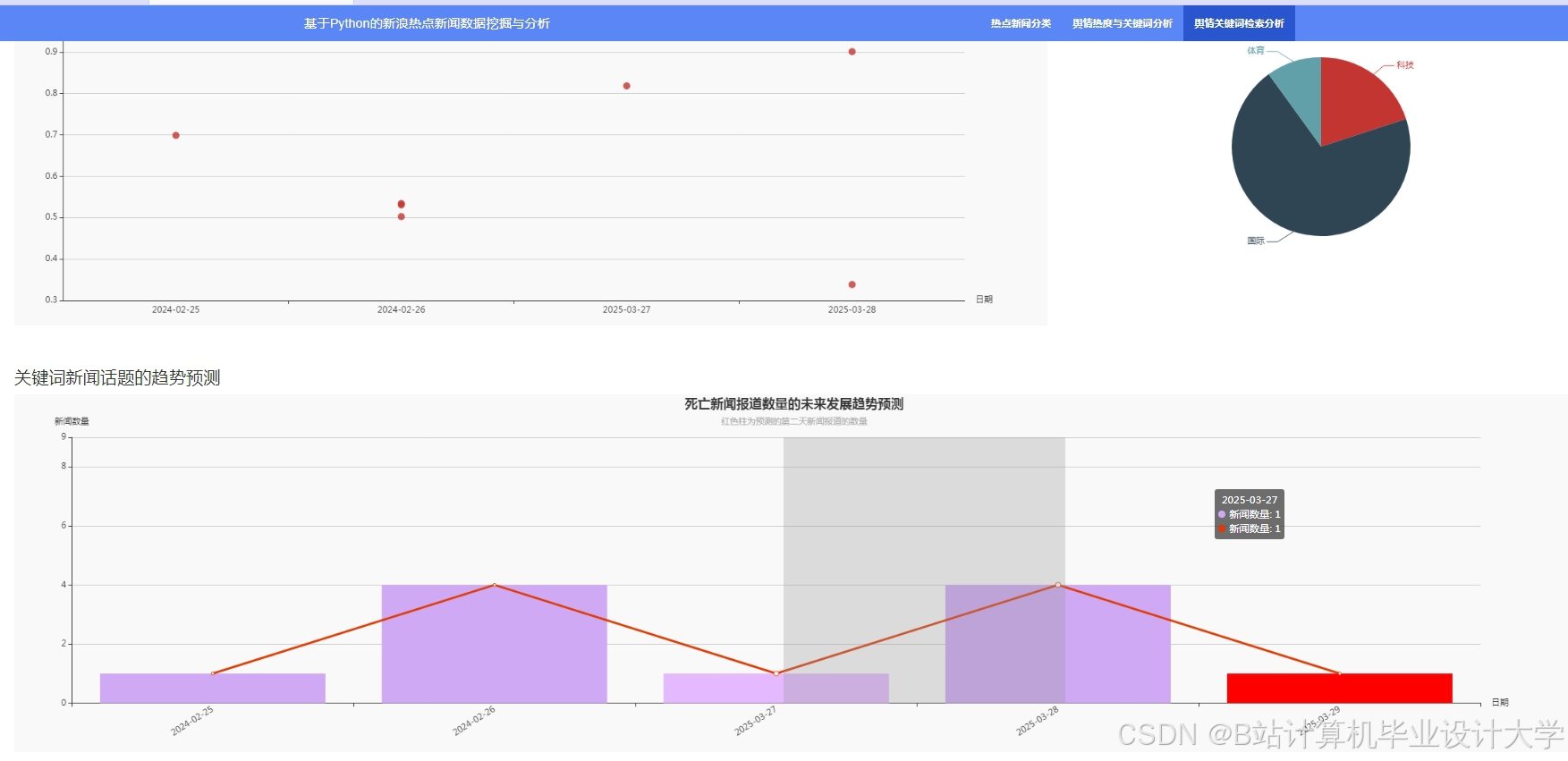
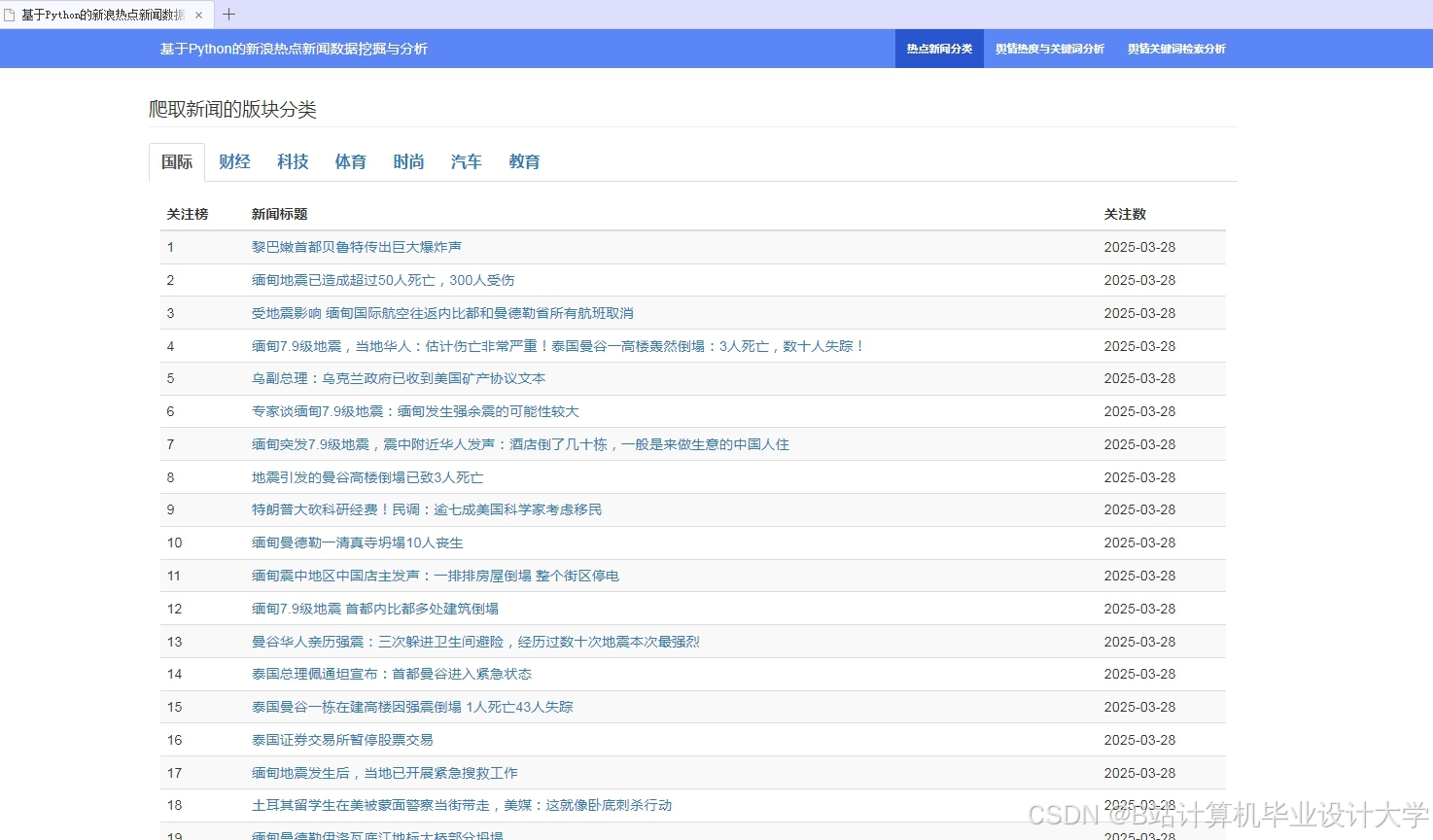
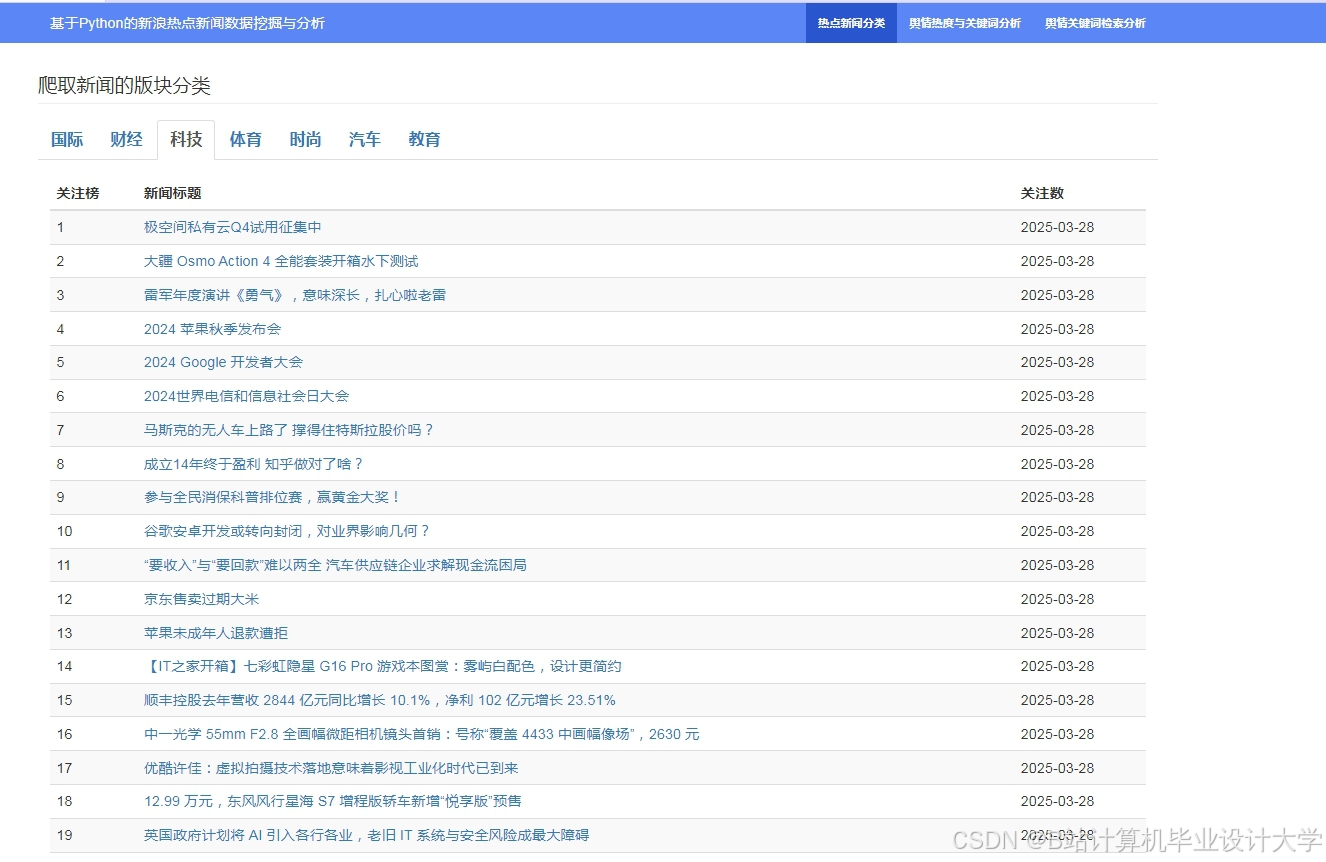
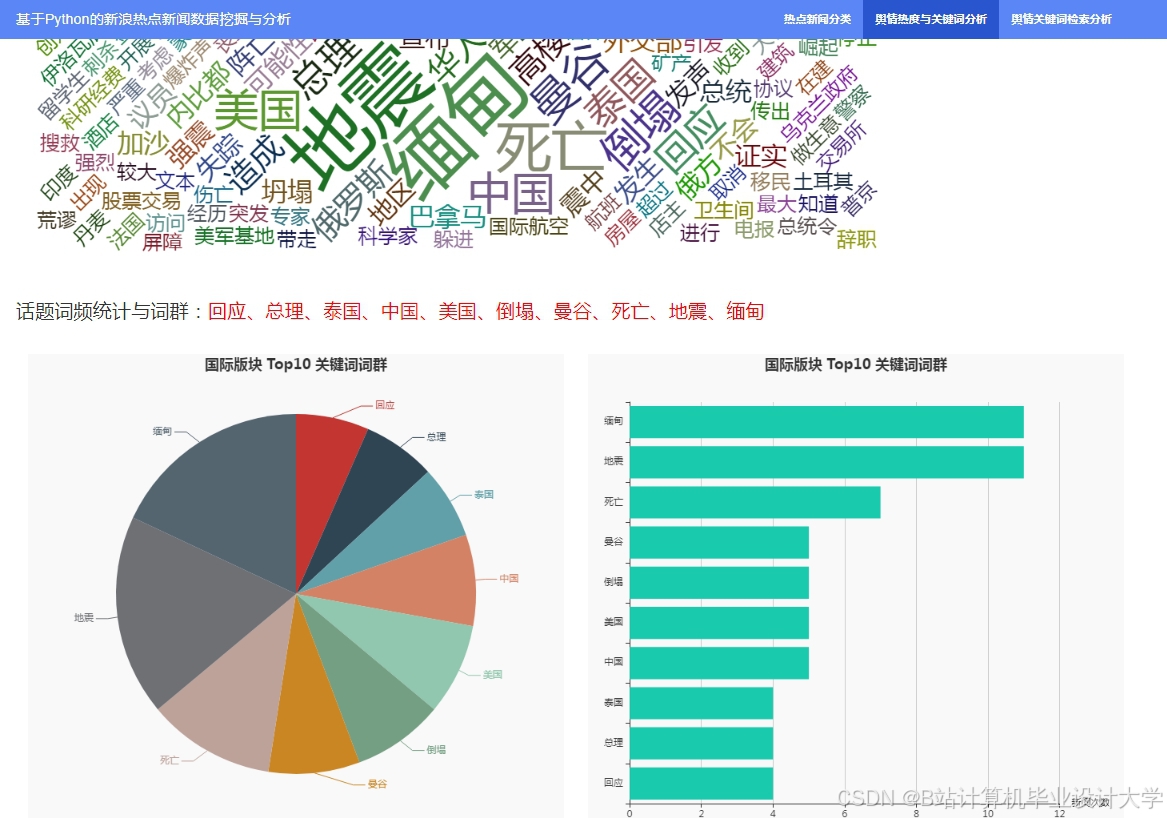
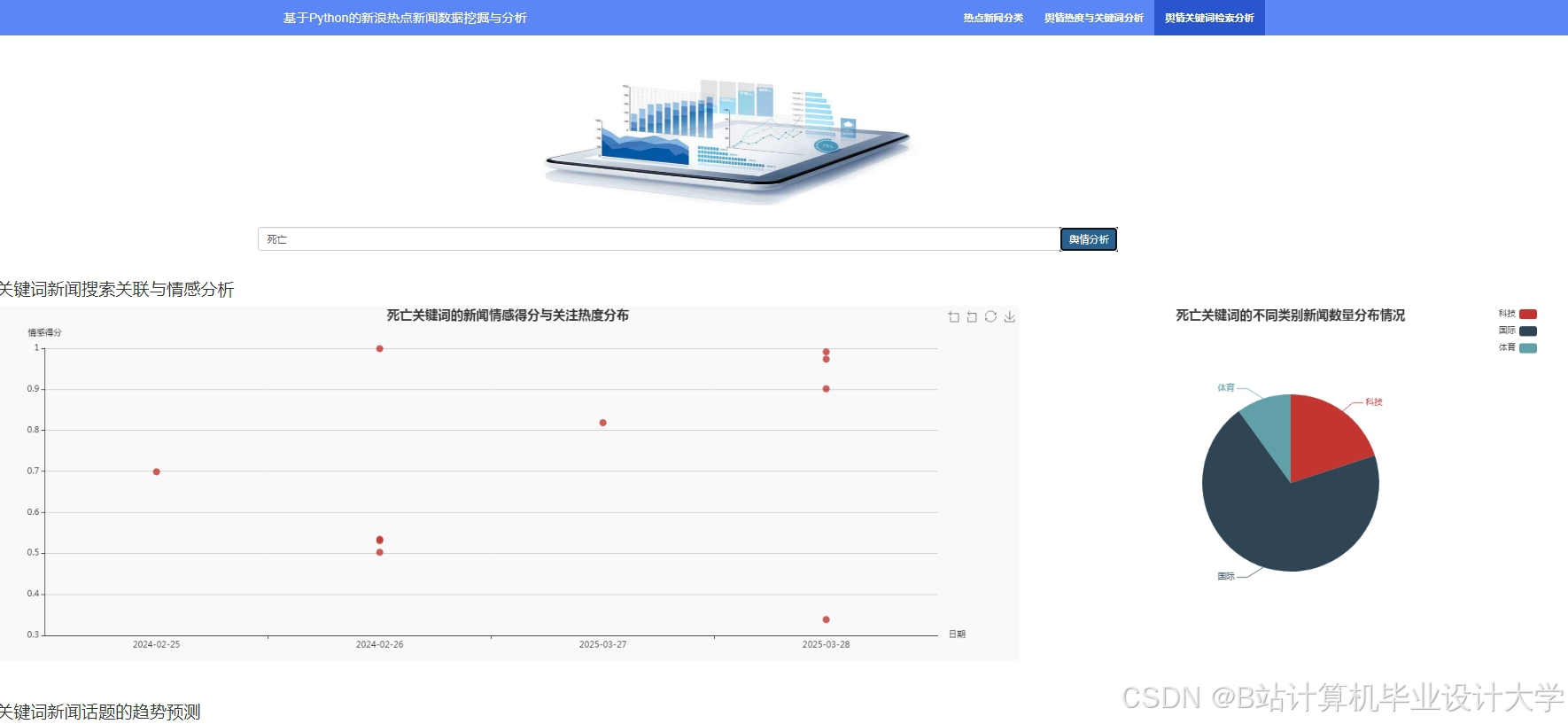
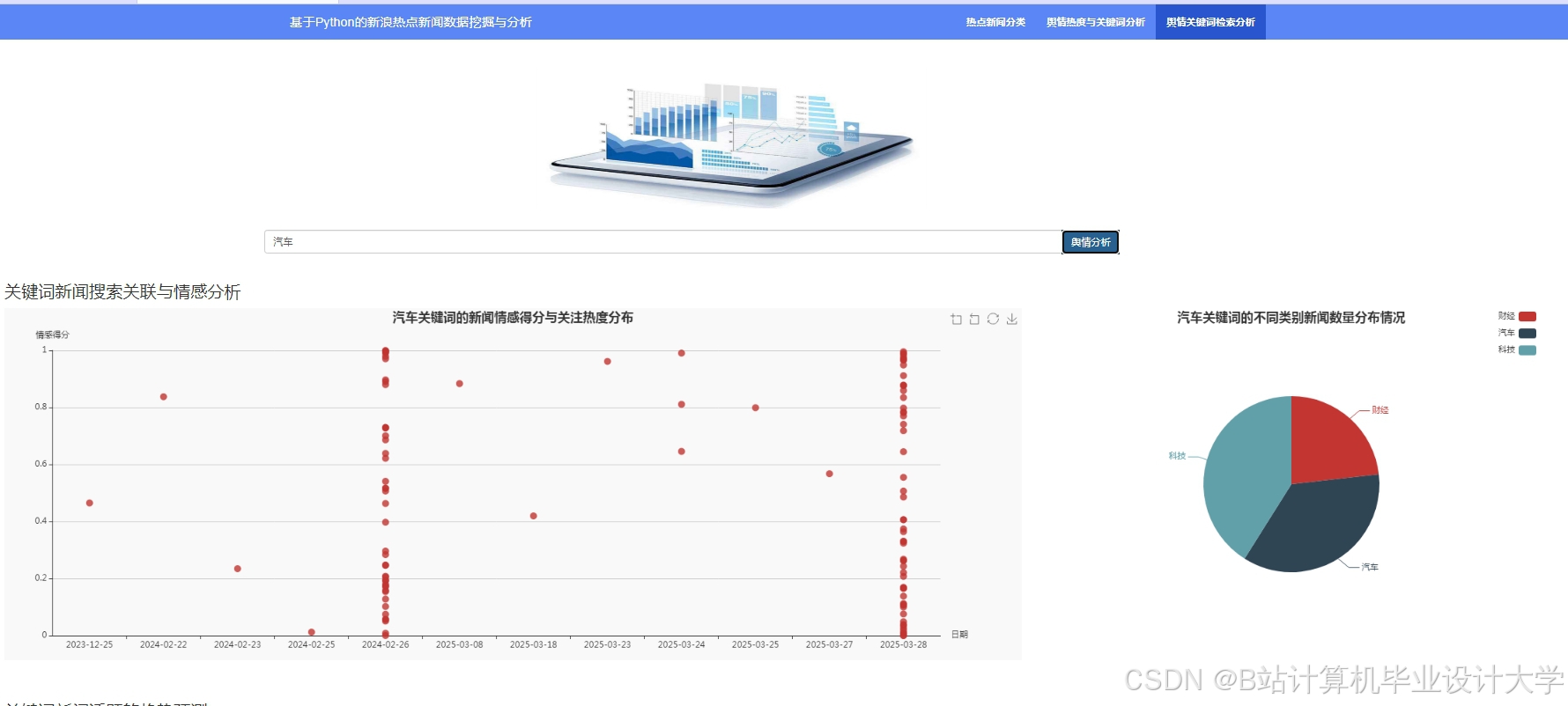
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











