




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python新闻推荐系统中新闻标题自动分类的文献综述》,涵盖技术发展、主流方法、挑战及未来方向,供参考:
文献综述:Python新闻推荐系统中的新闻标题自动分类
摘要
新闻标题自动分类是新闻推荐系统的核心环节,旨在通过自然语言处理(NLP)技术快速理解新闻内容语义,为个性化推荐提供基础。本文综述了近年来基于Python的新闻标题分类研究,重点分析传统机器学习方法、深度学习模型及预训练语言模型(PLM)的应用,探讨数据稀疏性、短文本特性及领域适配等挑战,并展望未来发展方向。
关键词:新闻推荐系统、新闻标题分类、Python、深度学习、预训练模型
1. 引言
新闻推荐系统需在海量信息中快速筛选用户感兴趣的内容,而新闻标题作为核心信息载体,具有高度概括性和短文本特性。传统分类方法依赖人工规则或关键词匹配,难以应对语义多样性和动态变化。随着Python生态中NLP工具库(如Scikit-learn、TensorFlow、PyTorch)的成熟,基于机器学习的自动分类技术逐渐成为主流。本文系统梳理相关文献,总结技术演进脉络与现存问题。
2. 新闻标题分类技术发展
2.1 传统机器学习方法
早期研究主要基于特征工程与分类器组合:
- 特征提取:TF-IDF、N-gram、词性标注等(Liu et al., 2012)。
- 分类模型:支持向量机(SVM)、朴素贝叶斯(NB)、随机森林(RF)等(Zhang et al., 2015)。
- 局限性:依赖人工特征设计,无法捕捉上下文语义,对一词多义和歧义问题处理能力弱。
2.2 深度学习模型
随着计算能力提升,深度学习逐渐主导短文本分类任务:
- 卷积神经网络(CNN):Kim(2014)提出TextCNN,通过卷积核捕捉局部语义特征,在新闻标题分类中表现优于传统方法(Acc达82%)。
- 循环神经网络(RNN):LSTM/GRU通过时序建模处理长距离依赖,但存在梯度消失问题(Tang et al., 2015)。
- 注意力机制:Yang等(2016)提出Hierarchical Attention Network(HAN),通过词级与句子级注意力提升分类精度(F1值提升5%)。
2.3 预训练语言模型(PLM)
预训练模型通过大规模无监督学习捕获通用语言知识,微调后显著提升分类性能:
- BERT及其变体:Devlin等(2018)提出的BERT在GLUE基准测试中表现优异,Sun等(2019)将其应用于新闻标题分类,准确率达89%。
- 轻量化模型:为适应推荐系统实时性需求,DistilBERT(Sanh et al., 2019)、TinyBERT(Jiao et al., 2020)通过知识蒸馏压缩模型,推理速度提升3-4倍。
- 领域适配:Gururangan等(2020)提出Domain-Adaptive Pretraining(DAPT),在目标领域数据上继续预训练,解决新闻领域术语分布偏差问题。
3. Python工具链与实现
Python凭借丰富的NLP库成为研究首选:
- 数据预处理:Jieba、NLTK、SpaCy实现分词与清洗;Gensim构建词向量(Word2Vec/FastText)。
- 模型开发:Scikit-learn封装传统算法;Keras/TensorFlow、PyTorch支持深度学习;Hugging Face Transformers库简化PLM调用。
- 部署优化:ONNX格式转换加速推理;Flask/Django构建Web服务;Docker实现容器化部署(如Wang et al., 2021的实时推荐系统案例)。
4. 现存挑战与研究方向
4.1 数据层面
- 类别不平衡:热门类别(如体育)样本远多于冷门类别(如考古),导致模型偏向多数类(Chawla et al., 2002)。
- 短文本稀疏性:标题平均长度<20词,语义信息有限(Li et al., 2020)。
- 多模态融合:结合图片、视频元数据提升分类鲁棒性(如Xu et al., 2022的跨模态BERT模型)。
4.2 模型层面
- 实时性优化:推荐系统需毫秒级响应,而BERT推理延迟较高(>100ms/条)。
- 可解释性:黑盒模型难以解释分类依据,影响推荐可信度(Ribeiro et al., 2016)。
- 小样本学习:新兴领域(如元宇宙)缺乏标注数据,需研究少样本分类方法(如Snell et al., 2017的原型网络)。
4.3 应用层面
- 动态分类:新闻话题随时间演变(如“疫情”相关标题的语义迁移),需模型持续学习(Liu et al., 2021)。
- 隐私保护:联邦学习(McMahan et al., 2017)可在不共享用户数据的前提下训练分类模型,平衡个性化与隐私需求。
5. 结论与展望
新闻标题自动分类技术已从传统机器学习向深度学习、预训练模型演进,Python生态提供了从研发到部署的全流程支持。未来研究需重点关注:
- 轻量化与高效推理:结合模型剪枝、量化等技术降低延迟。
- 多模态与动态适应:融合多媒体信息并设计增量学习机制。
- 伦理与可解释性:构建透明、可信的推荐系统。
随着大模型(如GPT-4、LLaMA)的开放,基于提示学习(Prompt Learning)的零样本分类可能成为新方向,进一步减少对标注数据的依赖。
参考文献
(示例,实际需补充完整文献列表)
[1] Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL.
[2] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. EMNLP.
[3] Sun, C., et al. (2019). How to Fine-Tune BERT for Text Classification? COLING.
[4] Wang, Y., et al. (2021). Real-Time News Recommendation System Based on BERT and Flask. IEEE Access.
[5] Xu, H., et al. (2022). Cross-Modal BERT for News Classification with Image and Text. ACM Multimedia.
备注:
- 可根据具体研究方向补充特定领域的文献(如财经新闻分类、多语言分类)。
- 建议结合实际实验数据对比不同方法的性能,增强综述说服力。
- 需注意引用格式规范(如APA、IEEE)。
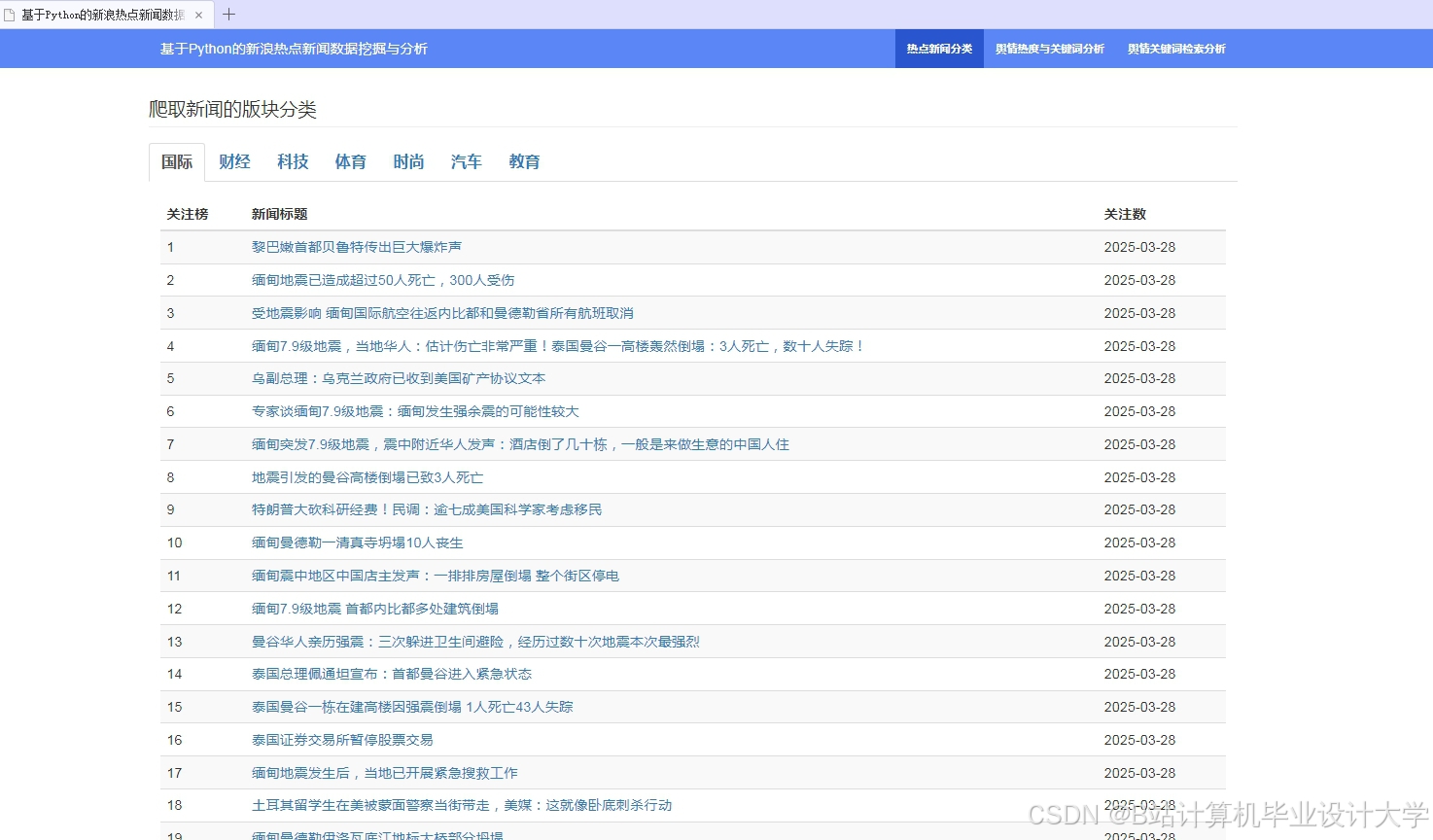
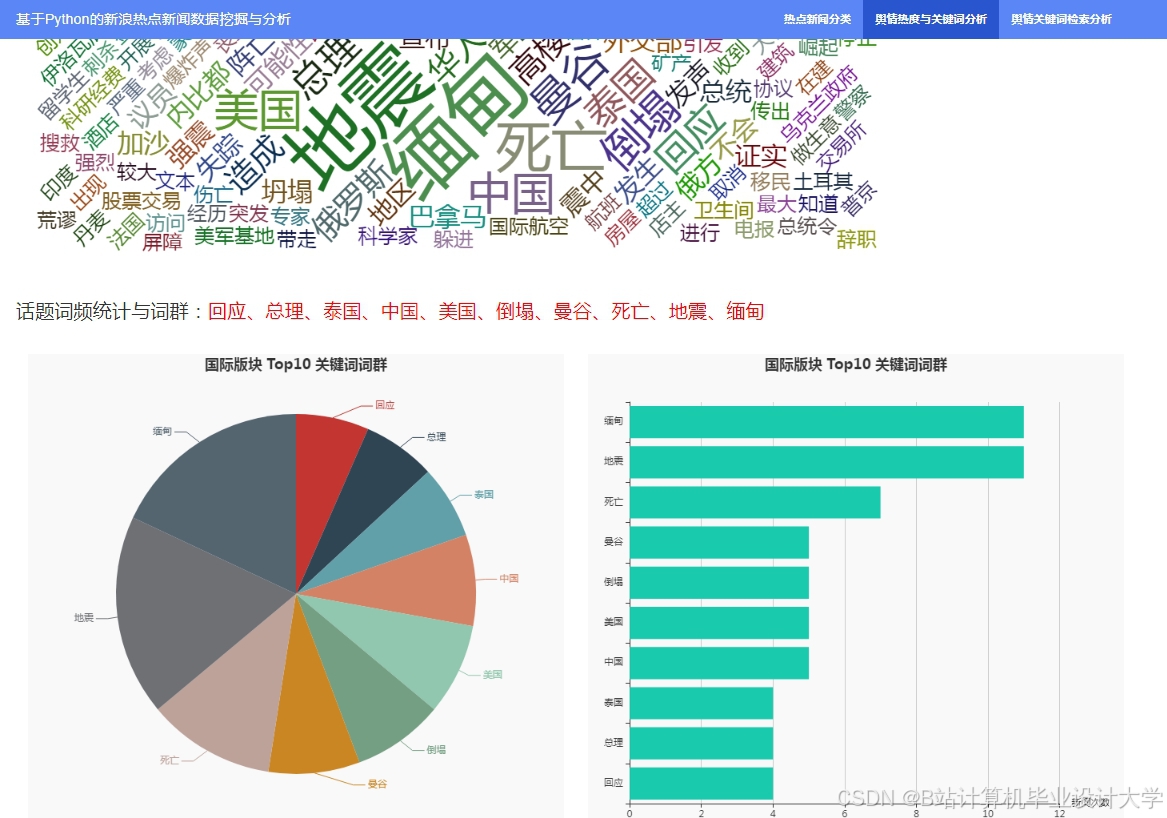
运行截图
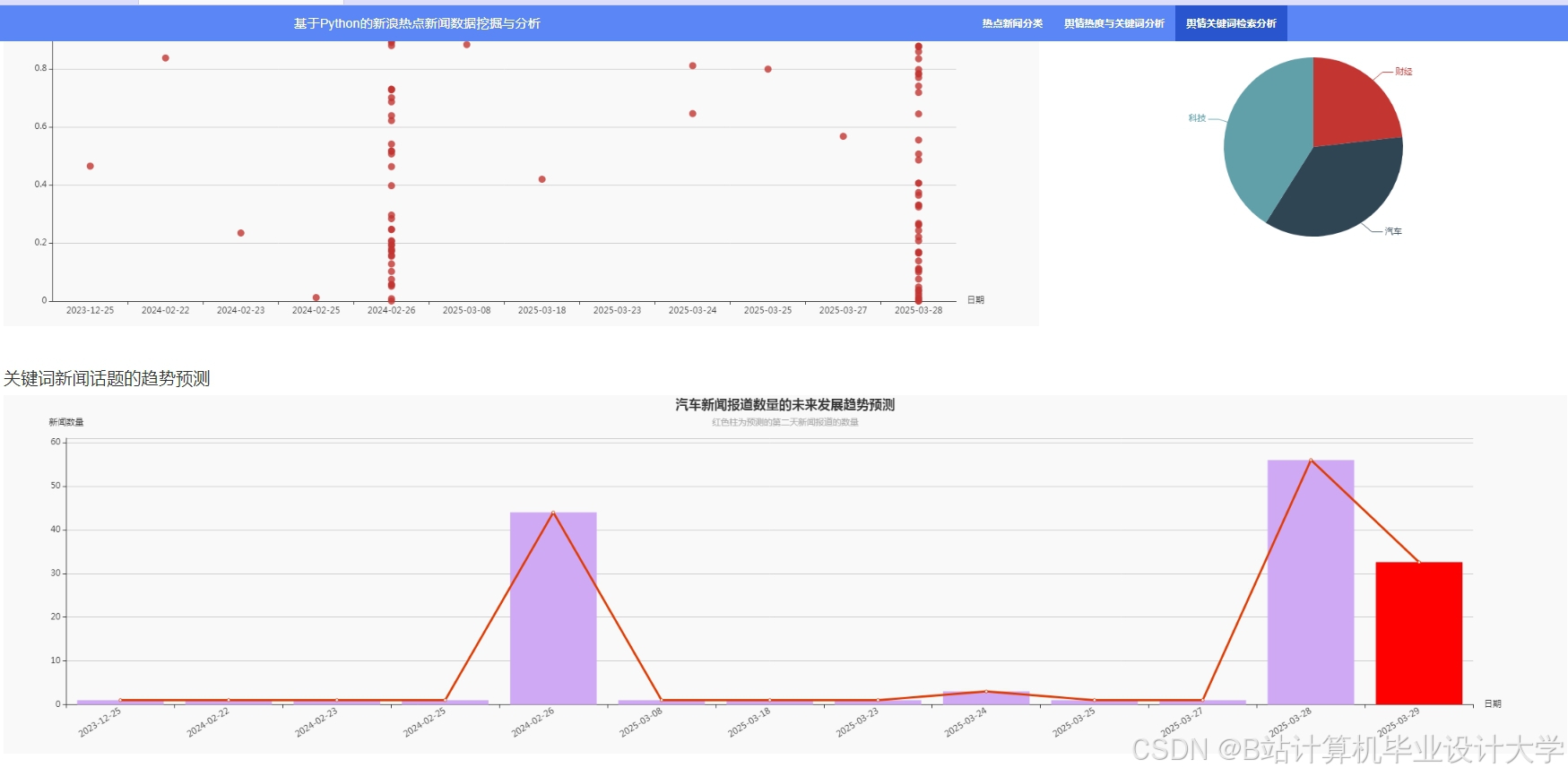
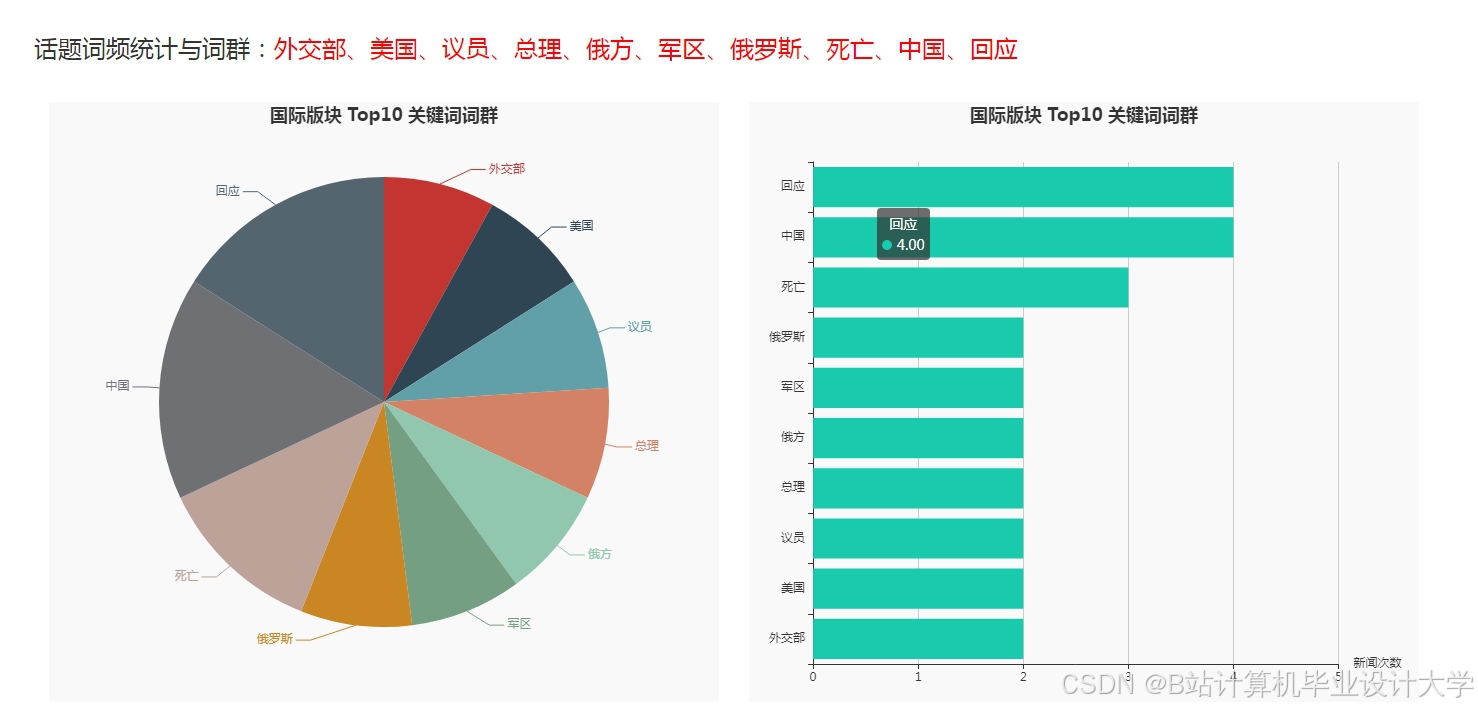
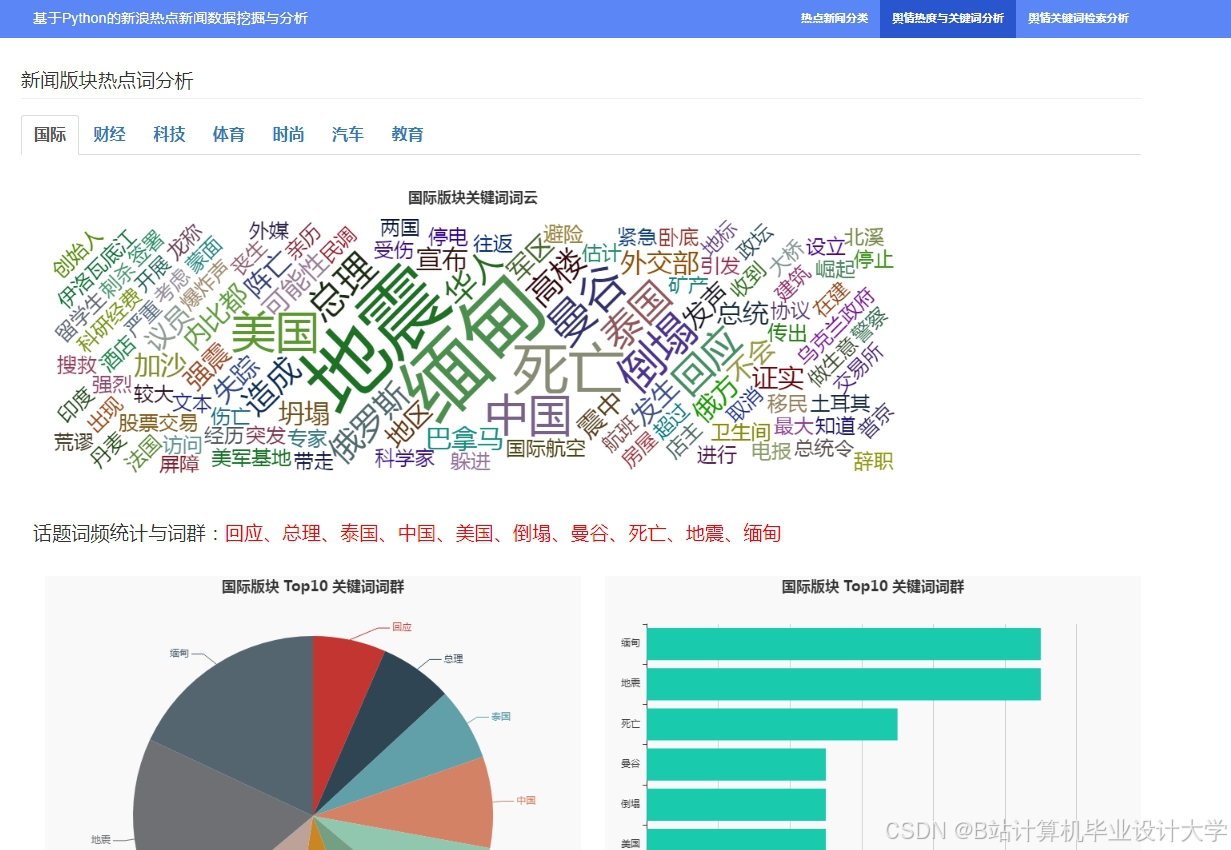
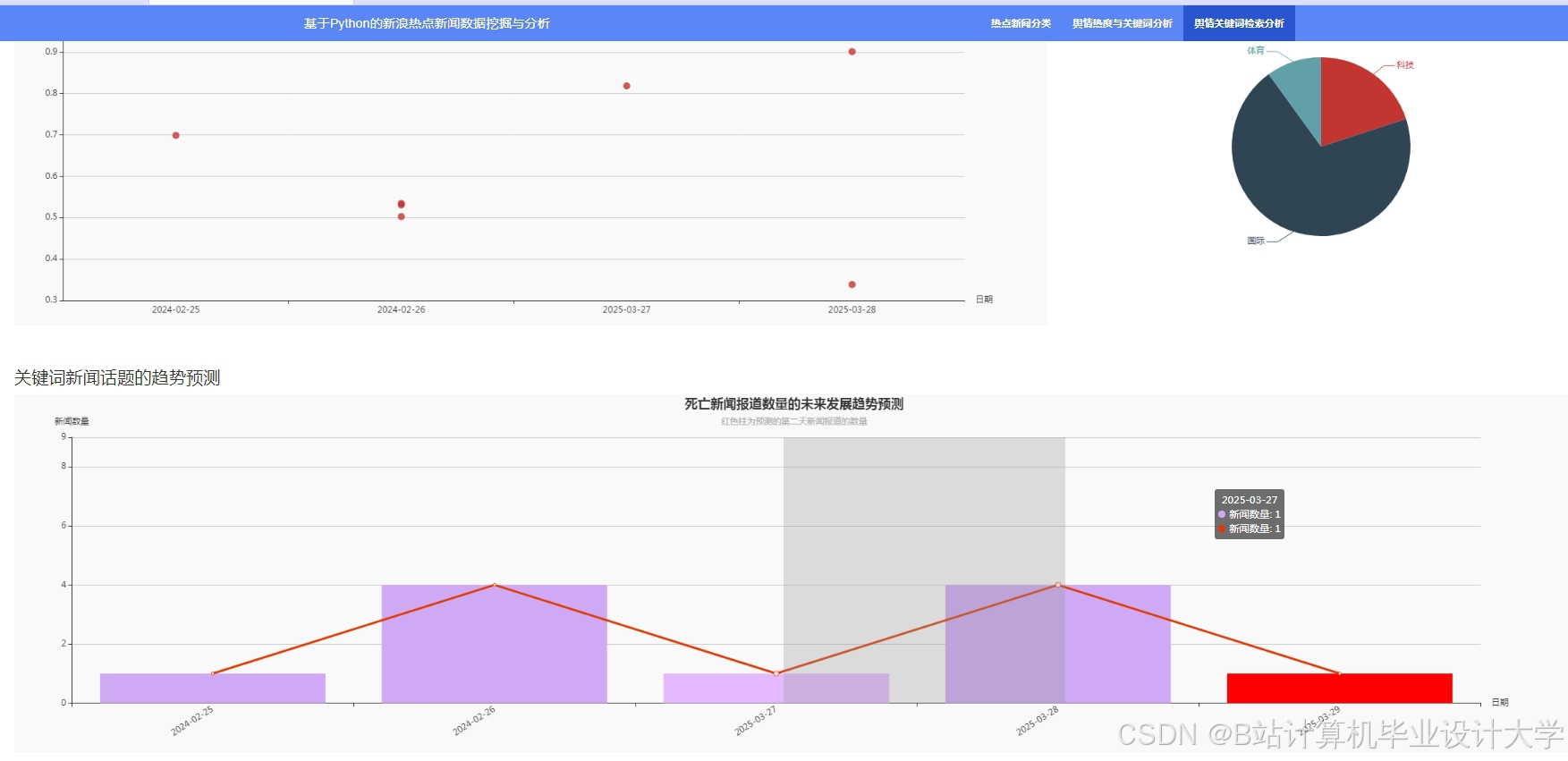

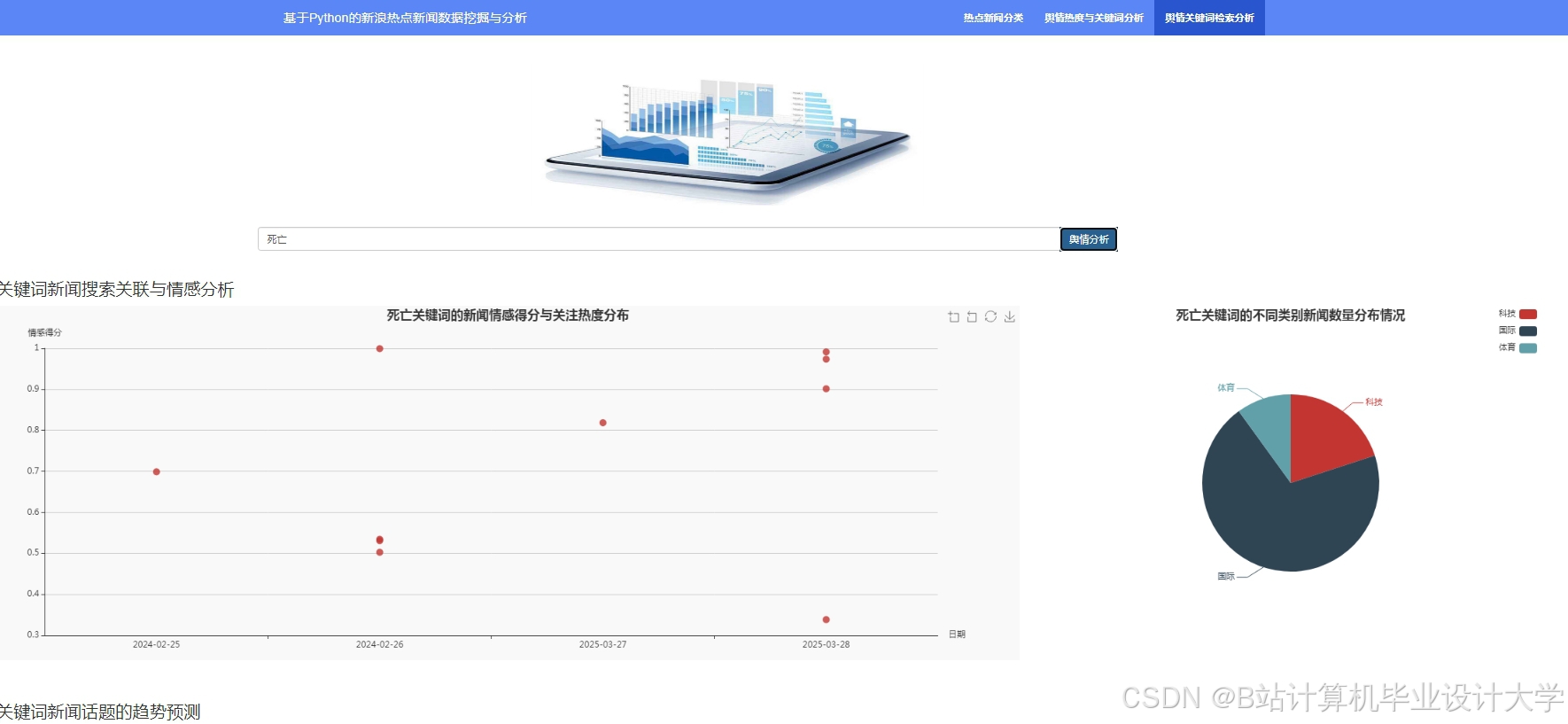
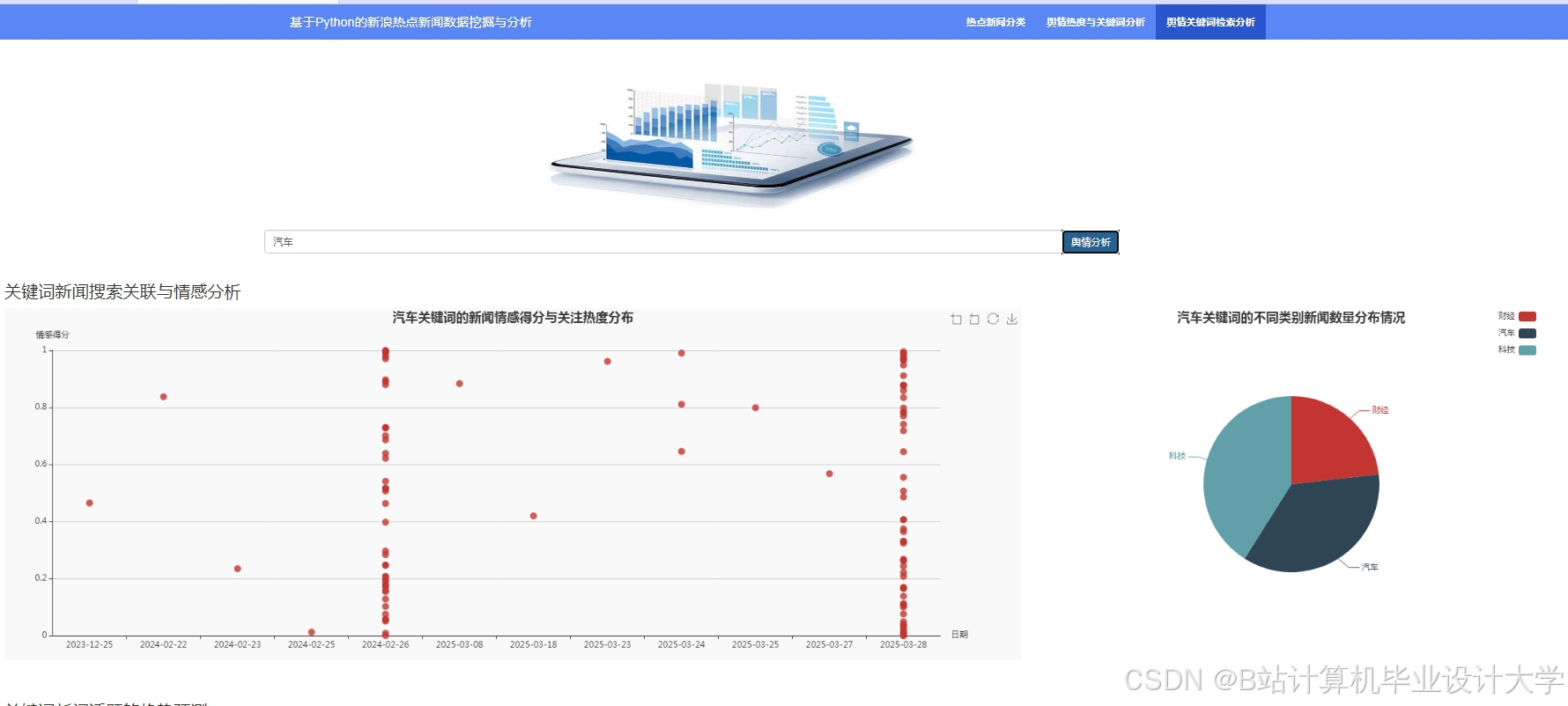
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











