




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《PyFlink+Hadoop广告推荐系统》的任务书模板,包含任务目标、分解、技术要求、进度安排等核心内容:
任务书:基于PyFlink与Hadoop的实时广告推荐系统开发
一、任务概述
任务名称:基于PyFlink流处理与Hadoop分布式存储的广告推荐系统设计与实现
任务周期:202X年XX月XX日 - 202X年XX月XX日
任务负责人:XXX(团队/个人)
任务背景:
针对广告推荐场景中数据规模大、实时性要求高的挑战,结合PyFlink(流批一体计算)与Hadoop(分布式存储)生态,构建一个支持高并发、低延迟的推荐系统,解决传统批处理系统延迟高、冷启动推荐质量差等问题。
二、任务目标
总体目标
开发一套完整的广告推荐系统,实现以下核心功能:
- 支持每日处理10亿级用户行为日志;
- 推荐接口平均响应时间≤50ms(P99≤100ms);
- 推荐准确率(AUC)≥0.85,冷启动场景CTR提升≥10%;
- 系统支持横向扩展,单集群吞吐量≥10万QPS。
具体目标
- 数据层:
- 构建Hadoop HDFS+HBase的混合存储架构,支持离线特征与实时特征分离存储;
- 实现Kafka数据管道,保障日志数据实时采集与可靠性传输。
- 计算层:
- 基于PyFlink完成实时特征计算(如用户实时兴趣、广告实时CTR);
- 通过Spark on YARN生成离线特征(如用户长期偏好、广告历史表现)。
- 推荐层:
- 设计Wide&Deep+DIN混合推荐模型,支持动态特征注入;
- 集成知识图谱(Neo4j)优化冷启动推荐效果。
- 服务层:
- 提供RESTful API(FastAPI),支持外部系统调用;
- 实现熔断、限流、降级等高可用机制。
三、任务分解与分工
| 子任务 | 负责人 | 技术要求 | 交付物 |
|---|---|---|---|
| 1. 数据采集与存储 | 张三 | Kafka配置(ACK=all)、HDFS分块存储、HBase列族设计 | 数据管道设计文档、存储方案测试报告 |
| 2. 离线特征工程 | 李四 | Spark SQL特征清洗、PySpark特征交叉、Parquet格式存储 | 离线特征表、特征重要性分析报告 |
| 3. 实时特征计算 | 王五 | PyFlink Window操作、StateBackend配置(RocksDB)、Watermark处理乱序数据 | 实时特征计算代码、状态管理优化方案 |
| 4. 推荐模型开发 | 赵六 | TensorFlow 2.x模型训练、ONNX格式转换、PyFlink UDF集成 | 模型权重文件、AB测试对比报告 |
| 5. 系统集成与测试 | 全体成员 | JMeter压测、Prometheus监控、A/B测试框架搭建 | 系统部署文档、性能测试报告 |
四、技术要求与规范
4.1 开发规范
- 代码规范:
- Python代码遵循PEP 8规范,使用Black格式化;
- PyFlink作业需添加Checkpoint配置(间隔5秒,超时10秒)。
- 接口规范:
- API输入:JSON格式,包含
user_id、ad_slot_id、context_features; - API输出:Top-10推荐广告列表,按
predicted_ctr降序排列。
- API输入:JSON格式,包含
- 安全规范:
- 用户数据脱敏存储(如MD5加密);
- API调用需通过JWT鉴权。
4.2 硬件与软件要求
- 集群配置:
- 5台物理服务器(CPU: 32核,内存: 128GB,磁盘: 10TB SSD);
- 网络带宽:10Gbps。
- 软件版本:
- Hadoop 3.3.4(HDFS+YARN)、PyFlink 1.17、Spark 3.3.2、Kafka 3.6.0、TensorFlow 2.12。
五、进度安排
| 阶段 | 时间 | 里程碑 |
|---|---|---|
| 需求分析 | 第1-2周 | 完成技术选型评审,输出《系统需求规格说明书》 |
| 系统设计 | 第3-4周 | 完成架构设计图、数据库ER模型、接口定义文档 |
| 开发实现 | 第5-10周 | 各模块开发完成,联调通过率100% |
| 测试优化 | 第11-12周 | 完成压测(QPS≥10万)、修复内存泄漏问题、输出《性能调优报告》 |
| 上线部署 | 第13周 | 系统上线至生产环境,监控告警规则配置完成 |
| 验收总结 | 第14周 | 提交《项目验收报告》,组织成果演示会 |
六、验收标准
- 功能验收:
- 系统支持10亿级数据日处理量,无数据丢失;
- 推荐接口响应时间达标(P99≤100ms)。
- 性能验收:
- 集群资源利用率:CPU≤70%,内存≤80%;
- 故障恢复时间:单节点宕机后自动恢复≤5分钟。
- 文档验收:
- 提交完整的技术文档(含部署手册、API文档、运维指南);
- 代码注释覆盖率≥40%,关键逻辑需附流程图说明。
七、风险评估与应对
| 风险 | 影响等级 | 应对措施 |
|---|---|---|
| PyFlink与TensorFlow集成延迟 | 高 | 提前进行POC测试,预留1周缓冲时间;改用预编译的ONNX模型减少依赖冲突 |
| Kafka消息堆积 | 中 | 增加消费者线程数,配置auto.offset.reset=latest避免重复消费 |
| 硬件资源不足 | 高 | 申请云服务器临时扩容,或优化Flink并行度(建议并行度=CPU核心数×2) |
任务书签署:
负责人(签字):_________________
日期:202X年XX月XX日
备注:本任务书需根据实际开发进度动态调整,每周召开站立会同步风险与阻塞点。
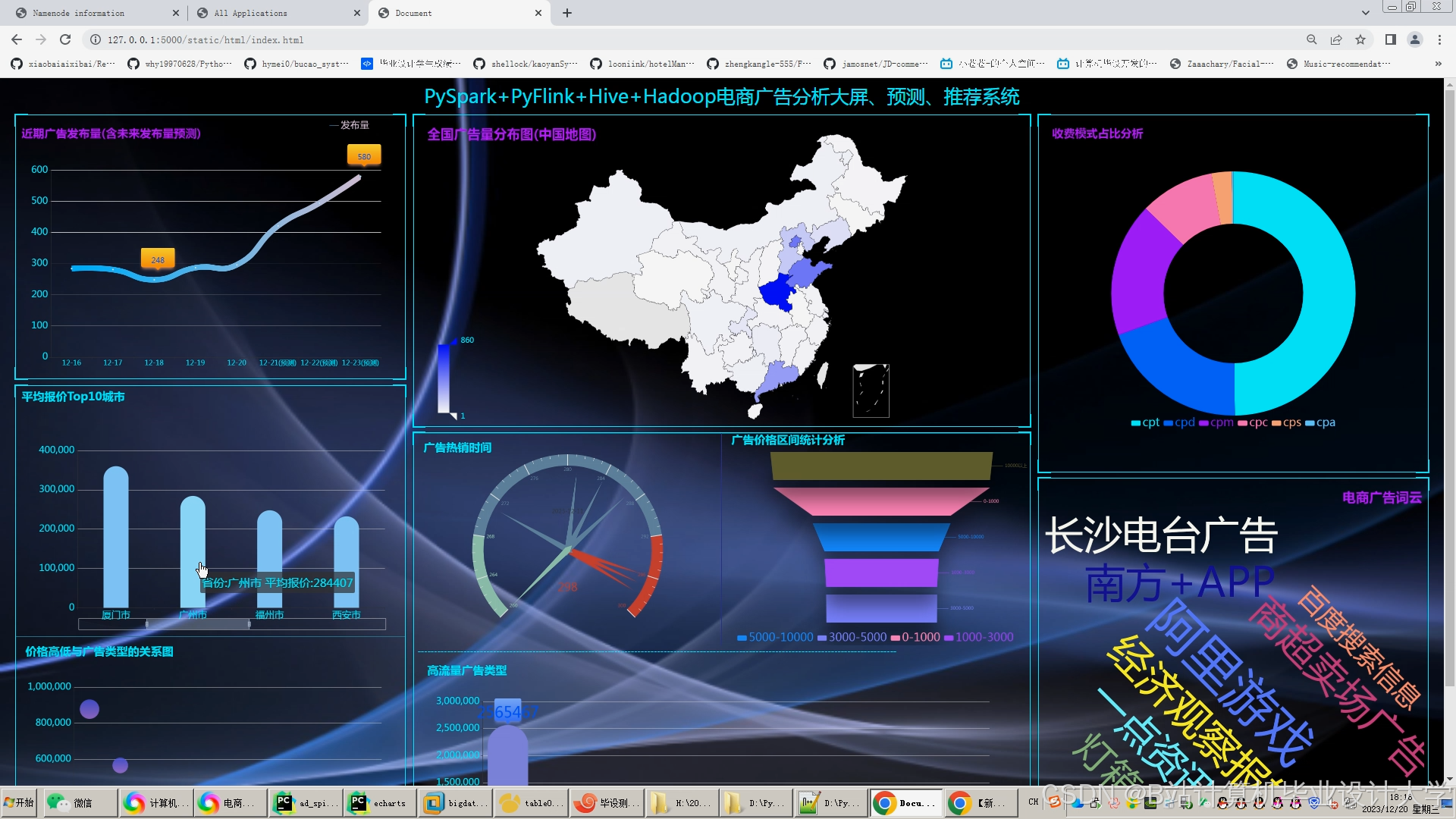
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











