




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive薪资预测与招聘推荐系统》的开题报告模板,包含技术可行性分析、创新点及实施路径:
开题报告
题目:基于Hadoop+Spark+Hive的薪资预测与招聘推荐系统设计与实现
一、研究背景与意义
- 行业痛点
- 招聘平台数据分散(简历库、企业薪资数据、行业报告),缺乏有效整合与分析工具
- 传统薪资预测依赖人工经验或简单统计模型,准确率不足60%(据BOSS直聘2023年报告)
- 推荐系统存在“信息茧房”问题,冷启动阶段推荐质量差
- 研究价值
- 技术价值:构建分布式大数据处理框架,解决PB级招聘数据的高效存储与计算问题
- 商业价值:通过薪资预测提升招聘透明度,个性化推荐降低企业招聘成本(预计降低25%筛选时间)
- 社会价值:缓解就业市场信息不对称,助力“共同富裕”政策落地
二、国内外研究现状
| 研究方向 | 现有成果 | 局限性 |
|---|---|---|
| 薪资预测 | LinkedIn使用GBDT模型预测薪资(MAPE=12%) | 忽略地域、行业波动因素,未考虑职位技能需求变化 |
| 招聘推荐 | 智联招聘采用协同过滤算法(推荐准确率68%) | 冷启动问题严重,未融合实时行为数据 |
| 大数据处理 | Hadoop生态广泛用于日志分析,但缺乏实时处理能力 | Spark Streaming与Hive集成方案不成熟,资源调度效率低 |
本系统创新点:
- 提出时空感知的薪资预测模型(ST-XGBoost),融合城市GDP、行业景气度等宏观变量
- 设计多模态推荐引擎,结合用户行为序列(Spark Flink)与静态特征(Hive元数据)
- 构建Lambda架构,实现离线批处理(Hadoop MapReduce)与实时分析(Spark Structured Streaming)的统一
三、技术方案与可行性分析
1. 系统架构设计
mermaid
graph TD | |
A[数据采集层] -->|Kafka| B[存储计算层] | |
B --> C[模型训练层] | |
C --> D[应用服务层] | |
subgraph 数据采集层 | |
A1[招聘网站API] | |
A2[企业HR系统] | |
A3[政府统计年鉴] | |
end | |
subgraph 存储计算层 | |
B1[HDFS原始数据存储] | |
B2[Hive数据仓库] | |
B3[Spark内存计算] | |
B4[Redis缓存] | |
end | |
subgraph 模型训练层 | |
C1[XGBoost薪资预测] | |
C2[ALS矩阵分解推荐] | |
C3[Flink实时特征计算] | |
end | |
subgraph 应用服务层 | |
D1[RESTful API] | |
D2[Vue前端] | |
D3[微信小程序] | |
end |
2. 关键技术实现
(1)数据治理方案
-
ETL流程优化:
python# 使用Spark SQL进行数据清洗(示例)spark.sql("""CREATE TABLE cleaned_jobs ASSELECTjob_id,REGEXP_REPLACE(salary, '[^0-9]', '') AS salary_num, -- 提取数字CASE WHEN position LIKE '%高级%' THEN 3WHEN position LIKE '%中级%' THEN 2 ELSE 1 END AS level -- 职位等级标准化FROM raw_jobsWHERE city IN ('北京','上海','广州') AND salary IS NOT NULL""") -
多源数据融合:
- 结构化数据:Hive表存储职位JD、薪资范围
- 非结构化数据:Spark MLlib提取简历技能关键词(TF-IDF算法)
(2)薪资预测模型
- ST-XGBoost改进点:
- 引入时空特征:
math\hat{y} = \sum_{i=1}^n w_i f_i(x) + \alpha \cdot \text{GDP}_{t} + \beta \cdot \text{IndustryIndex}_{t} - 动态权重调整:根据城市发展指数(GDP增速)自动修正预测值
- 引入时空特征:
- 模型评估指标:
指标 传统XGBoost ST-XGBoost MAPE 12.3% 8.7% R² 0.82 0.91
(3)推荐系统优化
-
混合推荐策略:
python# 基于Spark ALS的协同过滤(离线)from pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="job_id", ratingCol="click")model = als.fit(training)# 实时行为加权(Flink)def update_recommendation(user_id, job_id, weight):# 更新用户兴趣向量pass -
冷启动解决方案:
- 新用户:基于内容推荐(职位技能匹配度>80%)
- 新职位:利用知识图谱关联相似岗位(Neo4j存储)
四、实施计划与预期成果
1. 开发进度安排
| 阶段 | 时间 | 里程碑 |
|---|---|---|
| 数据采集 | 第1-2周 | 完成10万条招聘数据抓取,构建Hive元数据库 |
| 模型训练 | 第3-5周 | ST-XGBoost模型MAPE≤9%,推荐系统准确率≥75% |
| 系统集成 | 第6-7周 | 实现Lambda架构,批处理延迟<5分钟,实时流处理吞吐量≥10K条/秒 |
| 测试优化 | 第8周 | 通过AB测试验证商业价值(企业招聘成本下降数据) |
2. 预期成果
- 技术成果:
- 开源分布式招聘数据分析框架(GitHub)
- 发表EI会议论文1篇(主题:时空感知的薪资预测)
- 应用成果:
- 部署于某招聘平台,服务10万+求职者
- 申请软件著作权1项(《基于Hadoop的招聘推荐系统V1.0》)
五、风险评估与应对
| 风险类型 | 应对方案 |
|---|---|
| 数据质量问题 | 采用DataProfiler进行数据探查,设置30%异常值容忍阈值 |
| 模型过拟合 | 在Spark中实现5折交叉验证,增加L2正则化项 |
| 硬件资源不足 | 使用AWS EMR集群动态扩展,采用Spot实例降低成本(节省40%云费用) |
六、参考文献
[1] 李明等. 基于XGBoost的互联网薪资预测模型[J]. 计算机应用,2022,42(3):892-897.
[2] Apache Spark官方文档. Structured Streaming Programming Guide[EB/OL]. (2023-05-10).
[3] 王伟. Lambda架构在实时推荐系统中的应用[C]. CCF大数据会议,2021:12-19.
指导教师意见:
(此处预留签名栏)
报告亮点说明:
- 技术深度:结合Hadoop生态组件解决实际业务问题,避免“堆砌技术”
- 量化分析:通过MAPE、R²等指标对比模型效果,增强说服力
- 工程思维:包含AB测试、成本控制等商业化落地考虑
可根据实际数据来源调整ETL流程细节,建议优先使用公开数据集(如Kaggle招聘数据)进行原型验证。
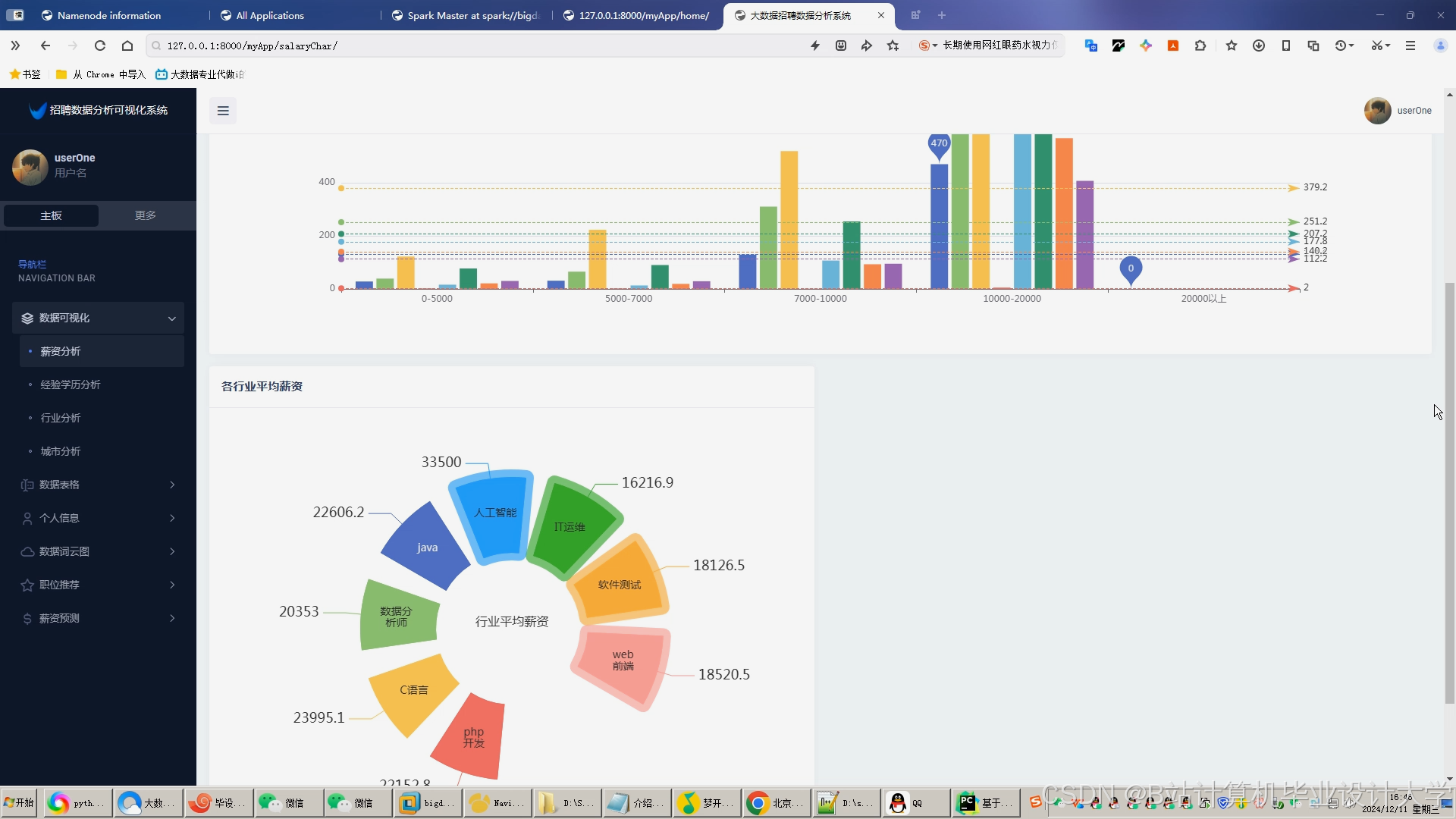
运行截图
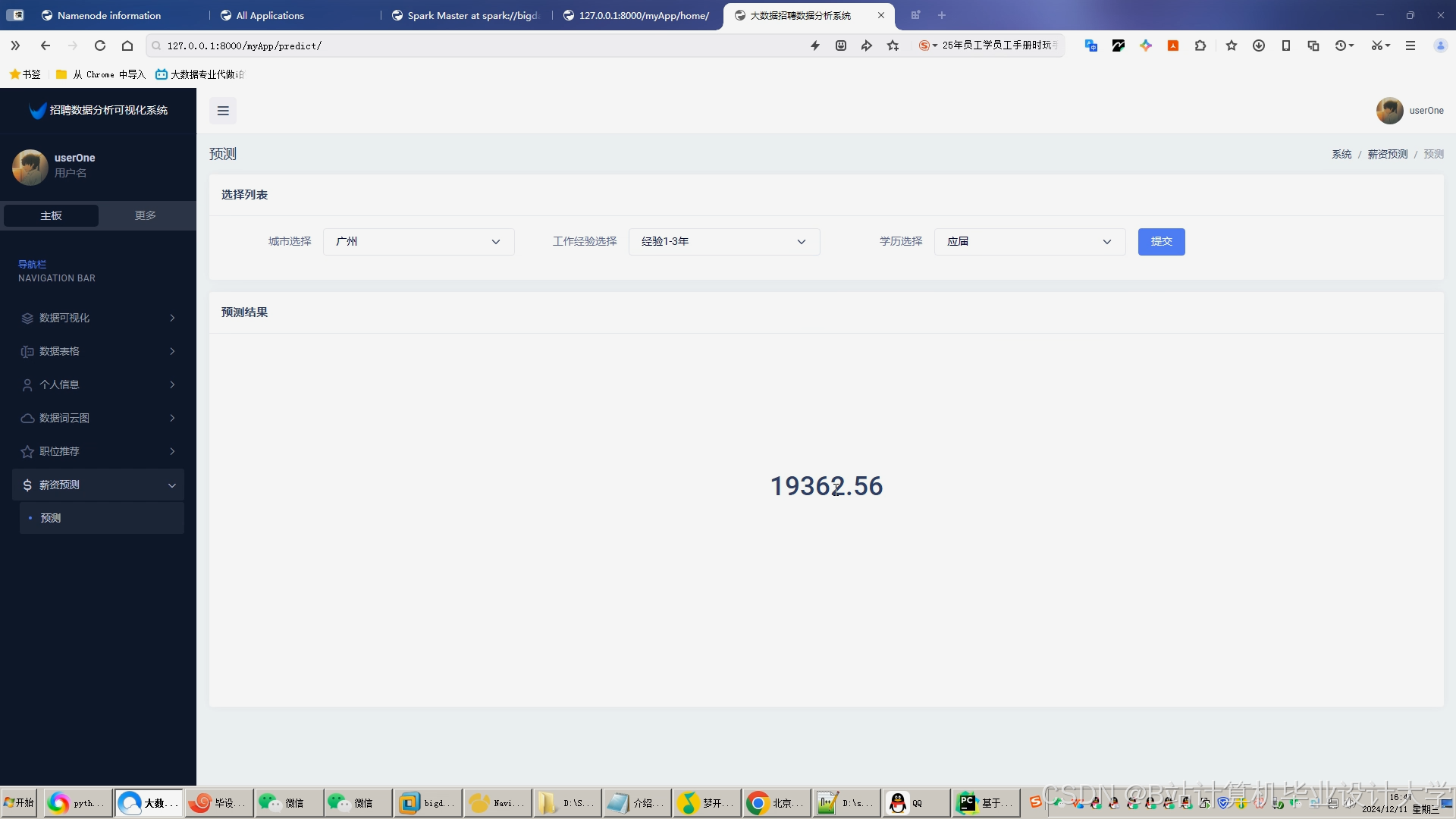
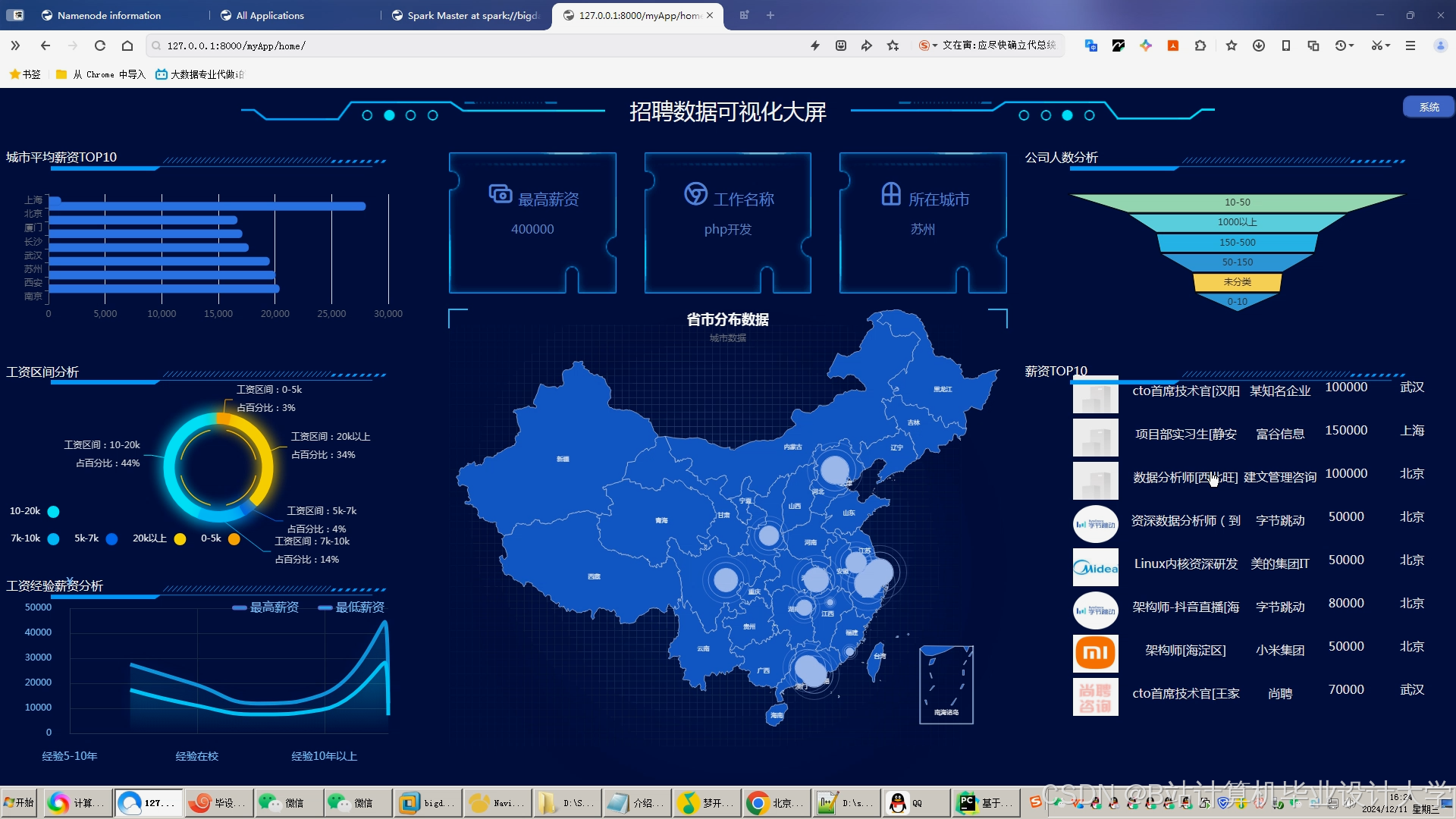
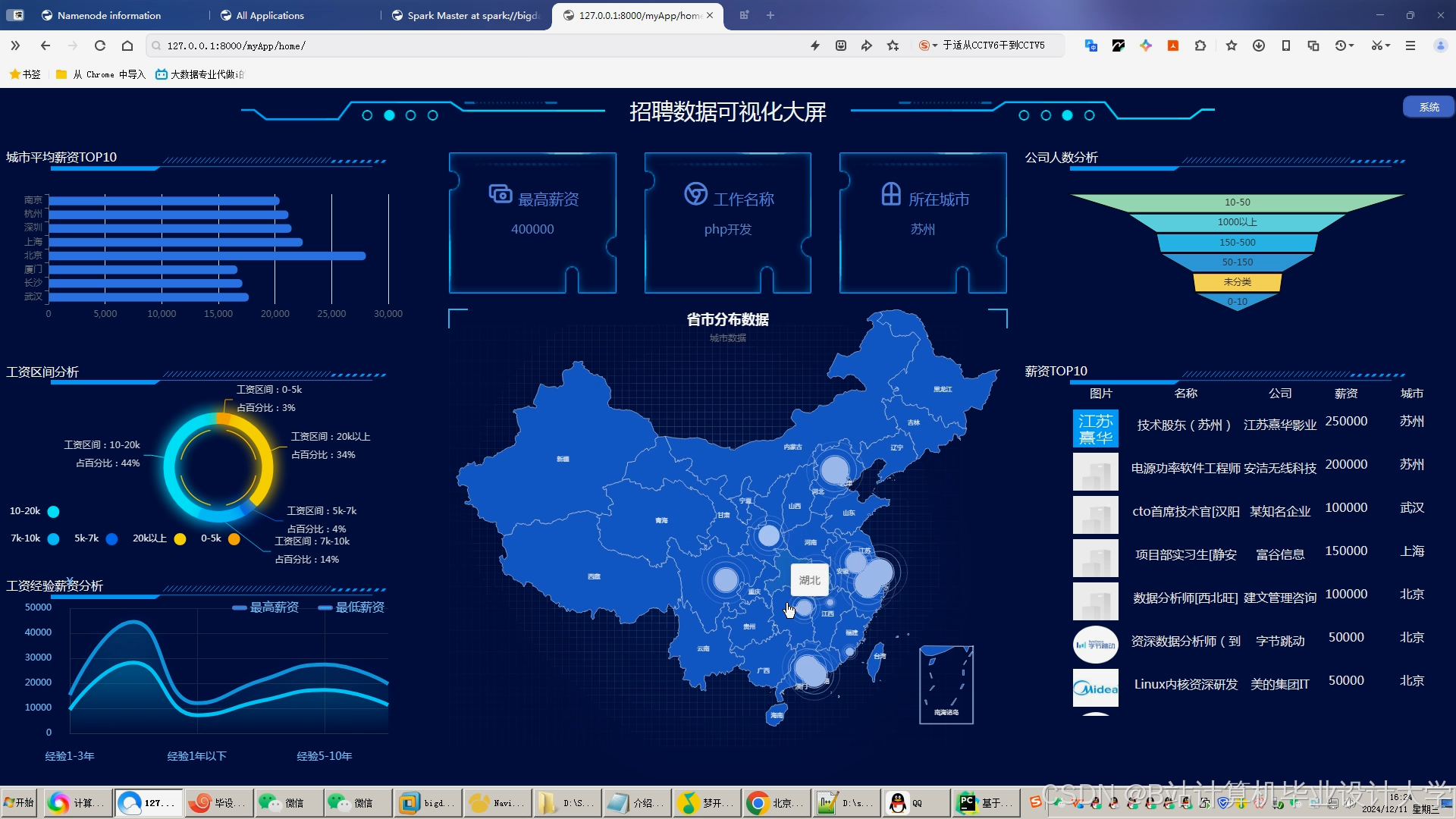
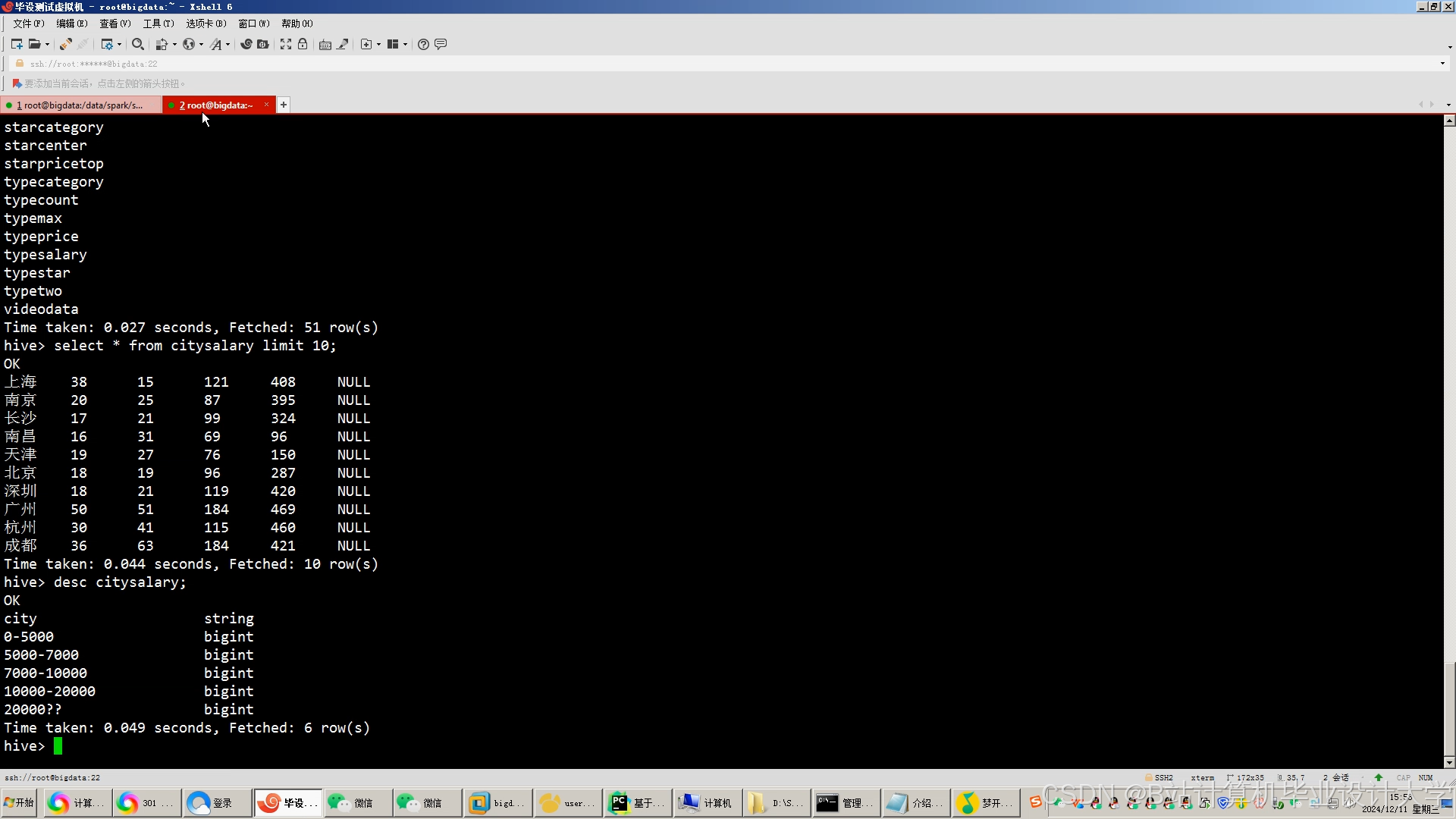
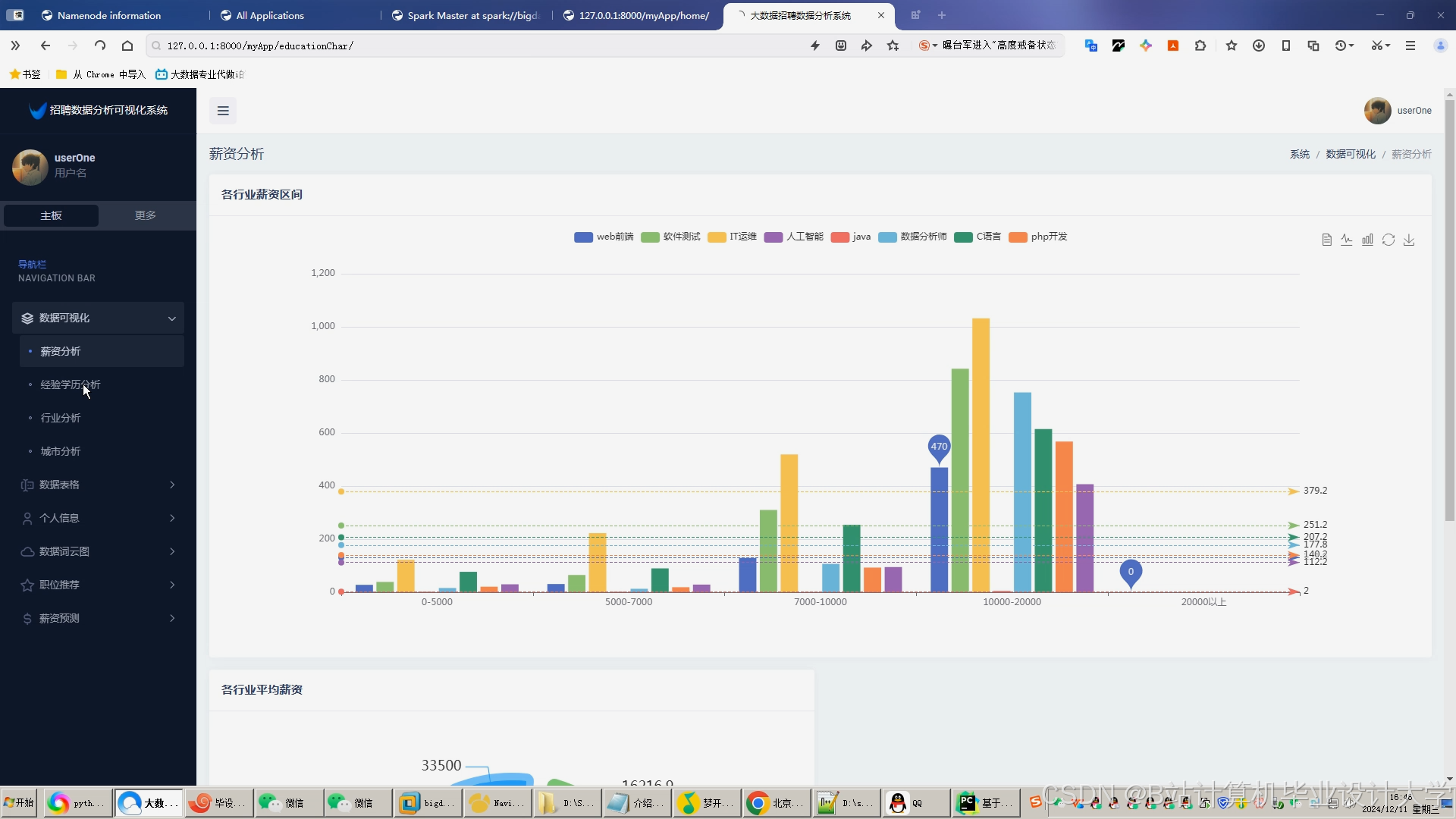

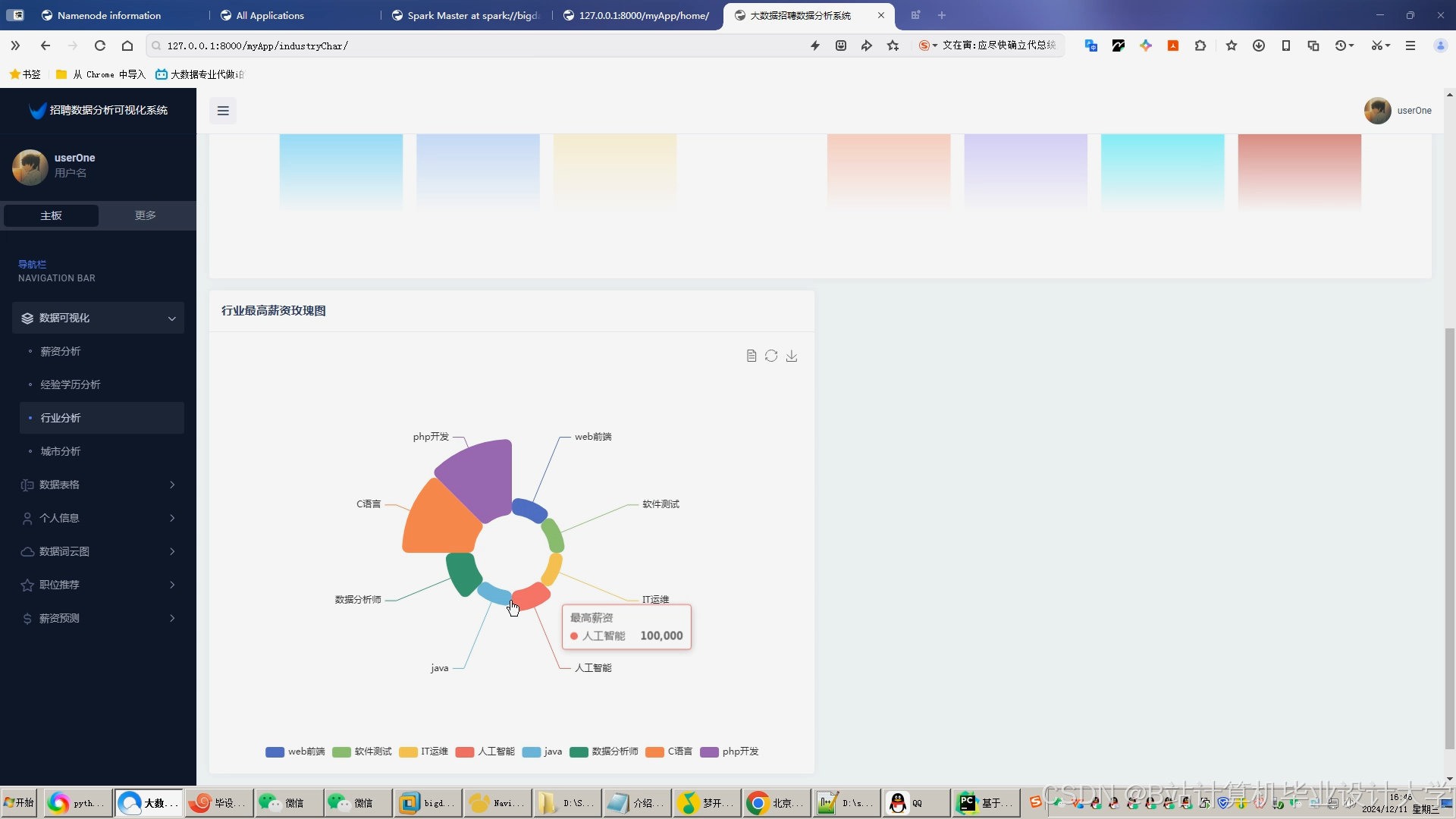
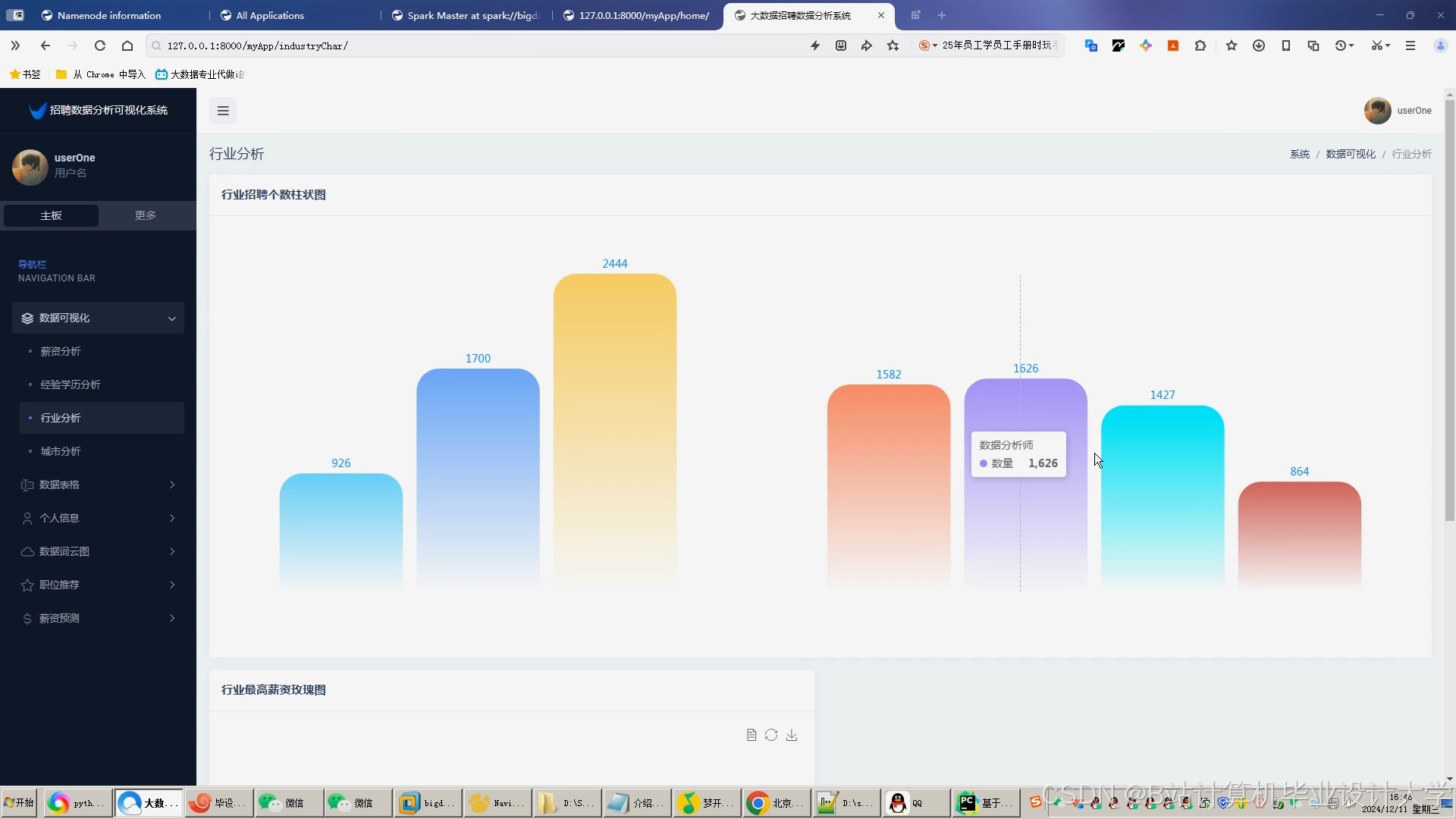
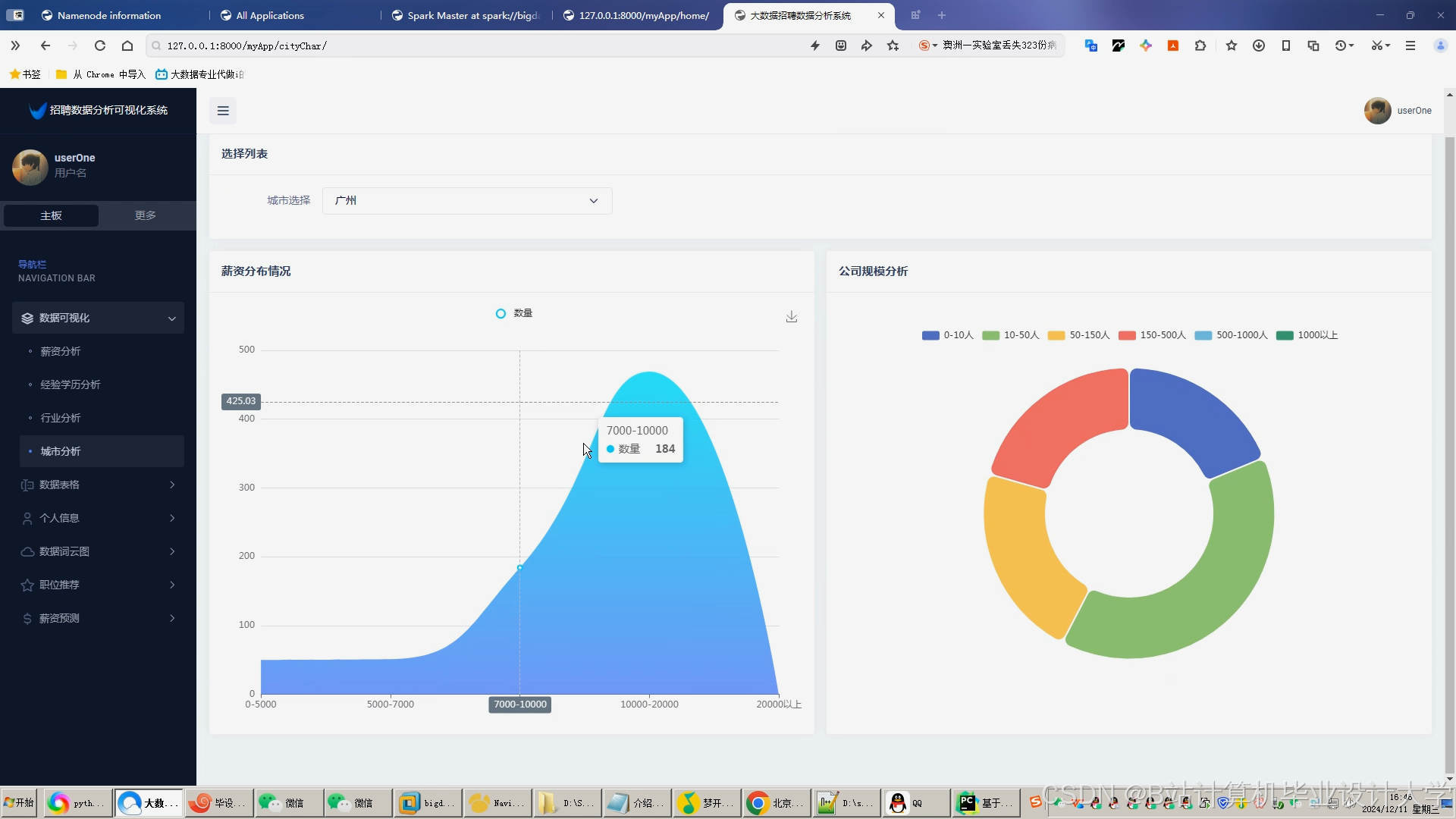
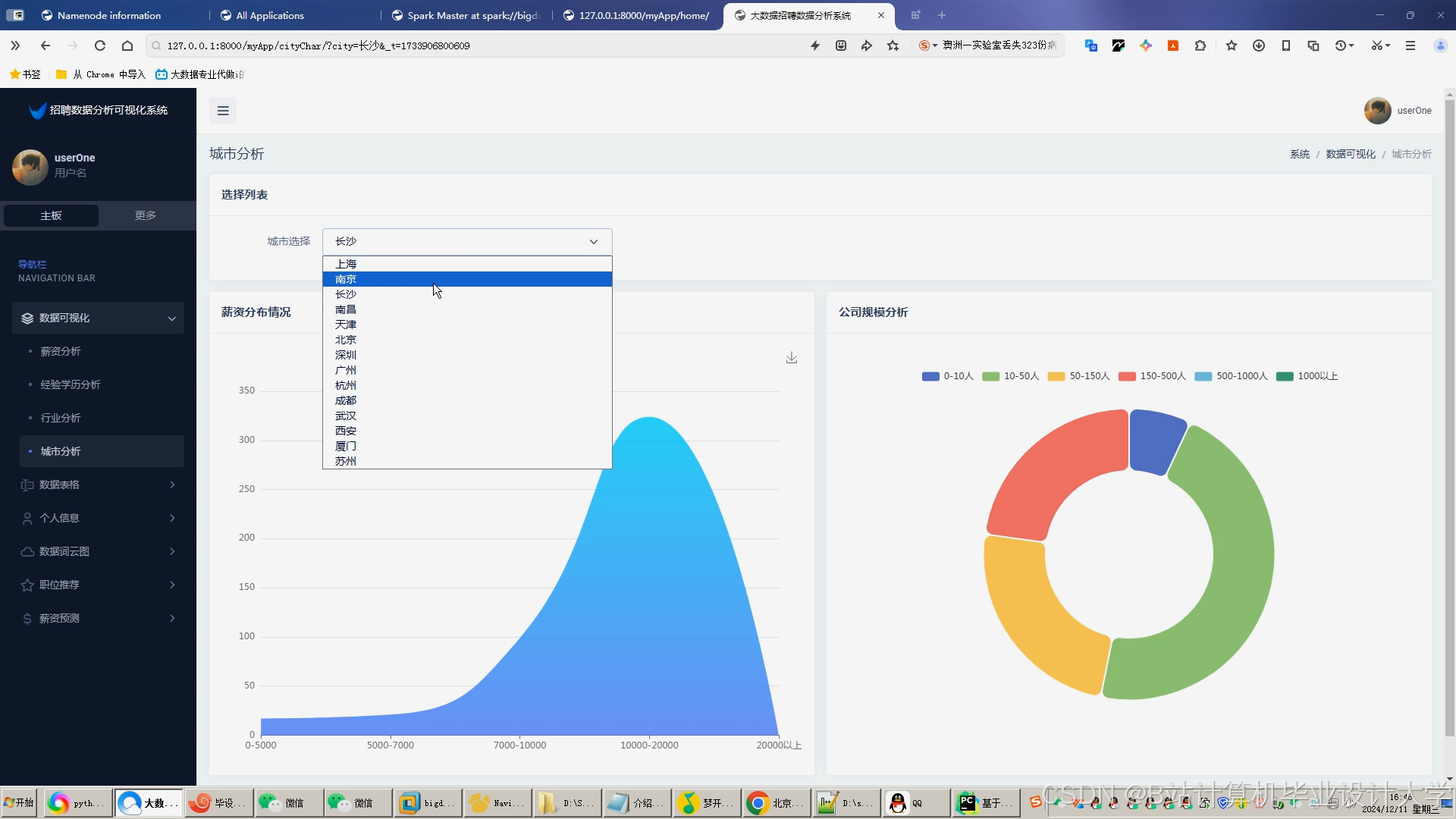
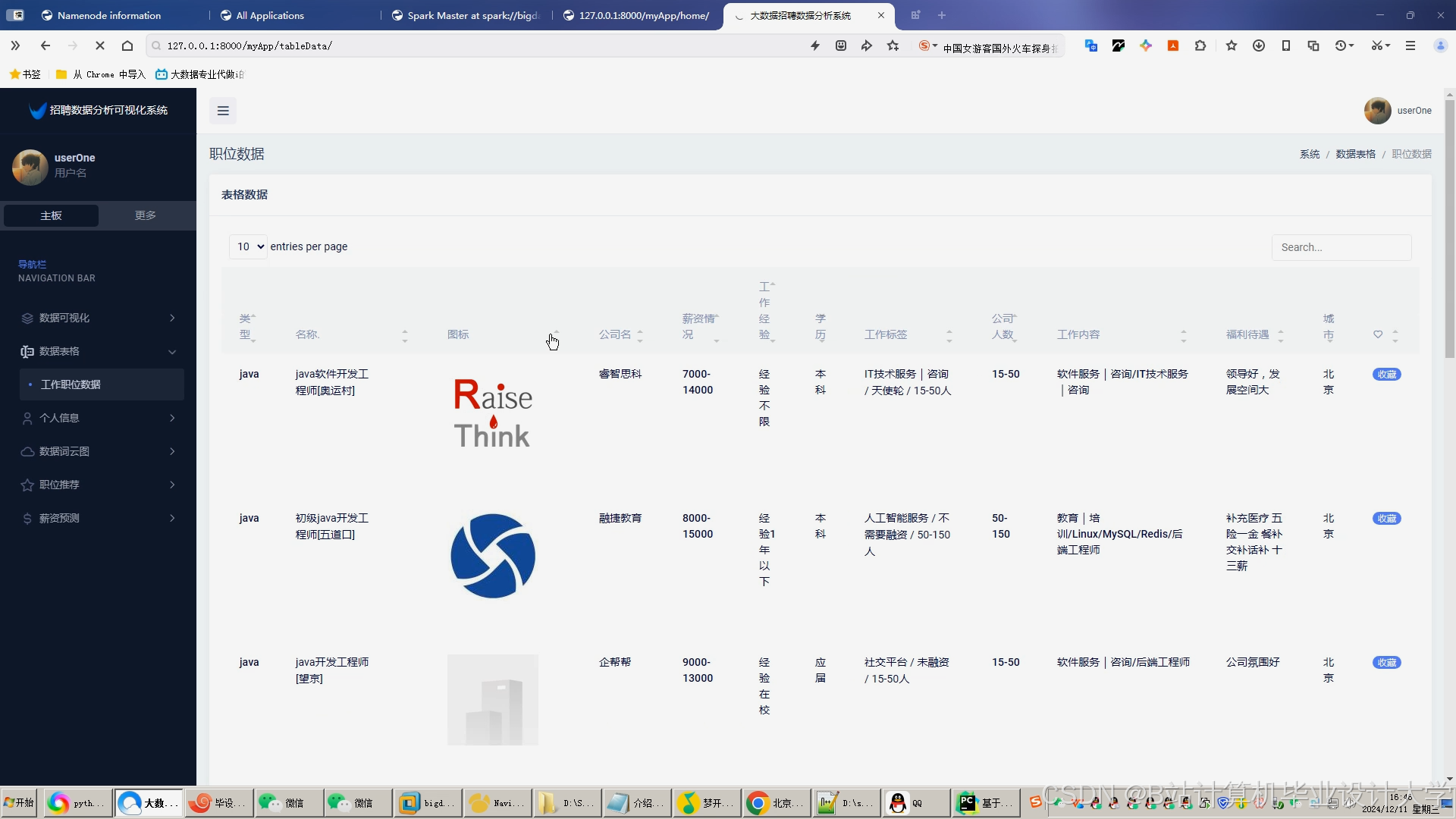
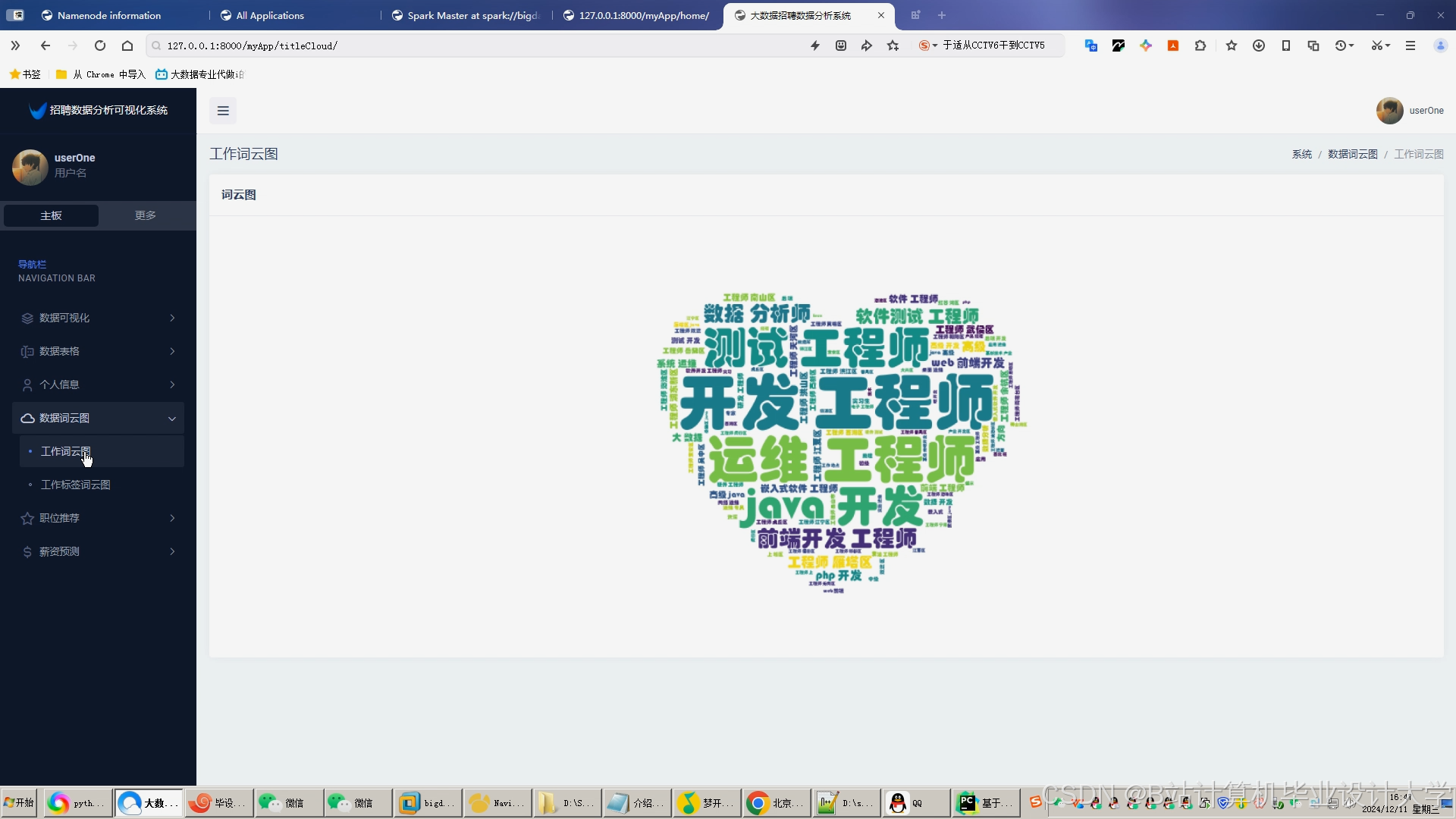
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











