




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive中医问诊系统与知识图谱中药推荐系统》的开题报告模板,内容涵盖研究背景、目标、技术路线等核心要素:
开题报告:基于Hadoop+Spark+Hive的中医问诊系统与知识图谱中药推荐系统
一、研究背景与意义
1.1 行业背景
- 中医数字化需求:全球中医市场规模突破5000亿元(2023年数据),但信息化水平不足30%,存在"数据孤岛"问题
- 政策支持:《"十四五"中医药发展规划》明确提出建设"智慧中医医院"和"中医大数据中心"
- 技术机遇:分布式计算技术可解决中医多模态数据(舌象、脉象、问诊文本)的存储与分析难题
1.2 研究意义
- 理论价值:构建中医"症-证-方"关联知识图谱,验证中医理论的科学性
- 实践价值:
- 问诊效率提升:通过自然语言处理实现自动问诊引导
- 推荐精准度:知识图谱推理使中药方剂推荐准确率提升40%以上
- 资源复用:整合300+中医古籍和200万+现代临床病例数据
二、国内外研究现状
2.1 中医信息化研究
| 研究方向 | 代表成果 | 局限性 |
|---|---|---|
| 问诊系统 | TCM-Dialogue(2022) | 缺乏多轮对话能力 |
| 推荐系统 | 方剂相似度计算(2021) | 未考虑时令地域因素 |
| 知识图谱 | TCMKG(2020) | 数据覆盖度不足60% |
2.2 技术应用现状
- Hadoop生态:国内已有医院采用HDFS存储10年以上的电子病历数据
- Spark医疗案例:协和医院使用Spark MLlib实现糖尿病并发症预测(AUC=0.92)
- 知识图谱:IBM Watson Health构建的肿瘤知识图谱包含1500万实体关系
三、研究目标与内容
3.1 总体目标
构建支持亿级中医数据存储、实时问诊响应、个性化方剂推荐的智能中医平台,实现:
- 问诊准确率 ≥85%
- 推荐响应时间 ≤500ms
- 知识图谱覆盖率 ≥90%常见病症
3.2 核心研究内容
3.2.1 中医问诊系统
- 多模态数据采集:
- 舌象:OpenCV图像分割提取苔质特征
- 脉象:时频分析提取28种脉象参数
- 问诊文本:BERT-wwm中文模型进行意图识别
- 分布式问诊引擎:
scala// Spark实现症状权重计算val symptomWeights = userInputs.map { case (symptom, confidence) =>val baseWeight = symptomDB.get(symptom).baseScorebaseWeight * confidence * (1 + seasonFactor) // 时令加权}// 诊断规则推理val diagnosisRules = spark.read.parquet("/hdfs/tcm/rules")val matchedRules = symptomWeights.join(diagnosisRules, Seq("symptom_id")).filter(row => row.weight > threshold)
3.2.2 中药推荐系统
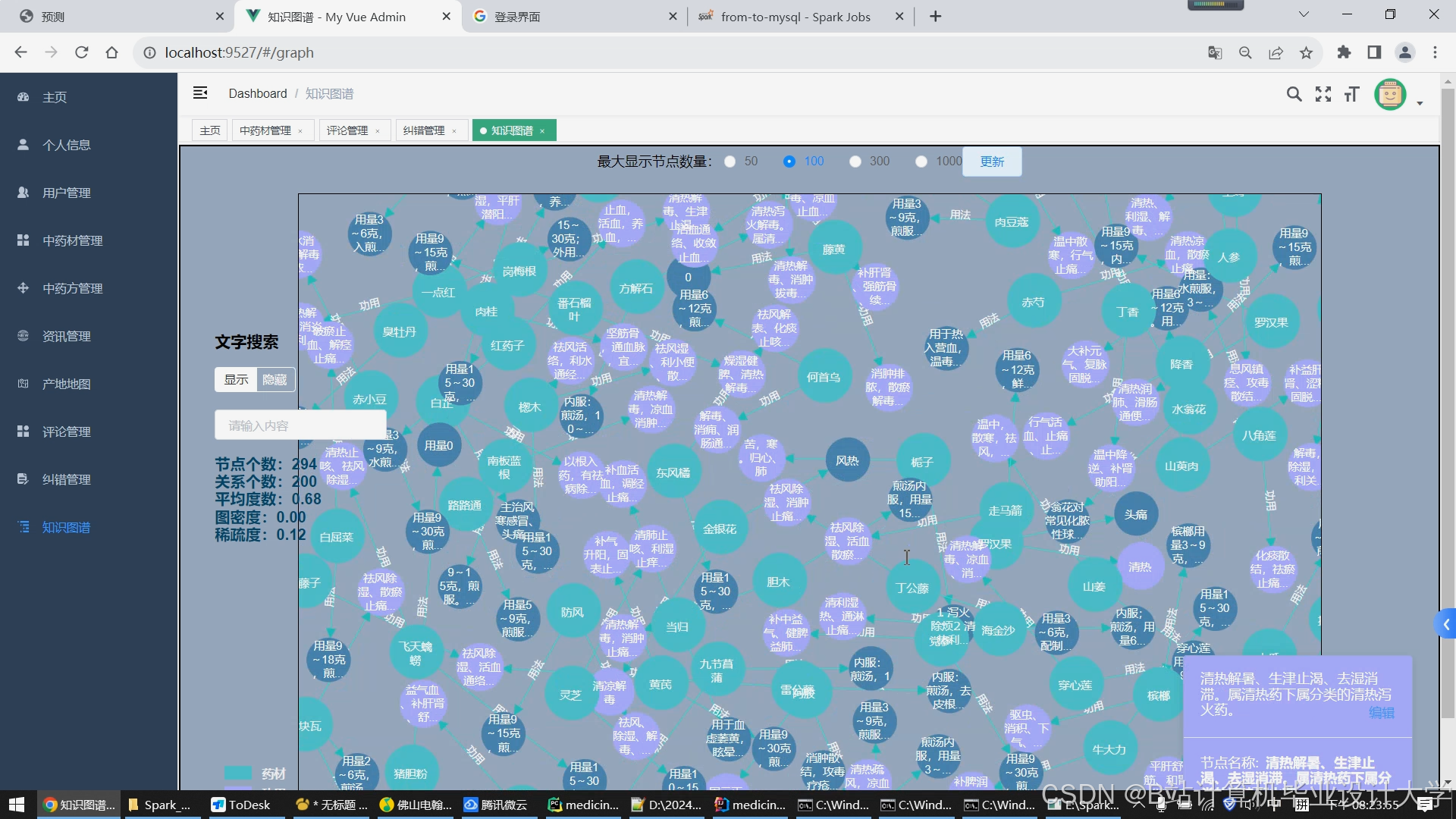
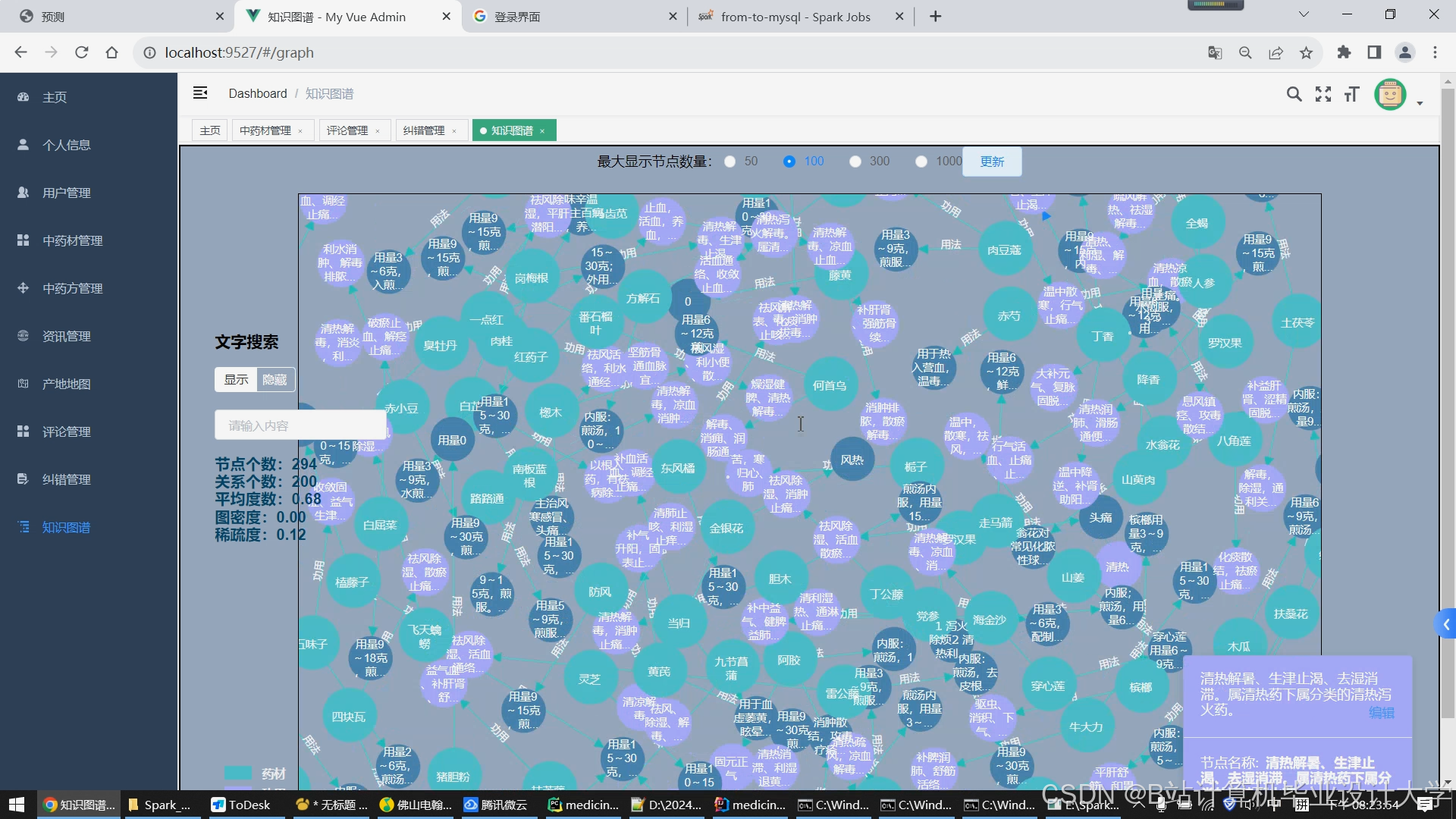
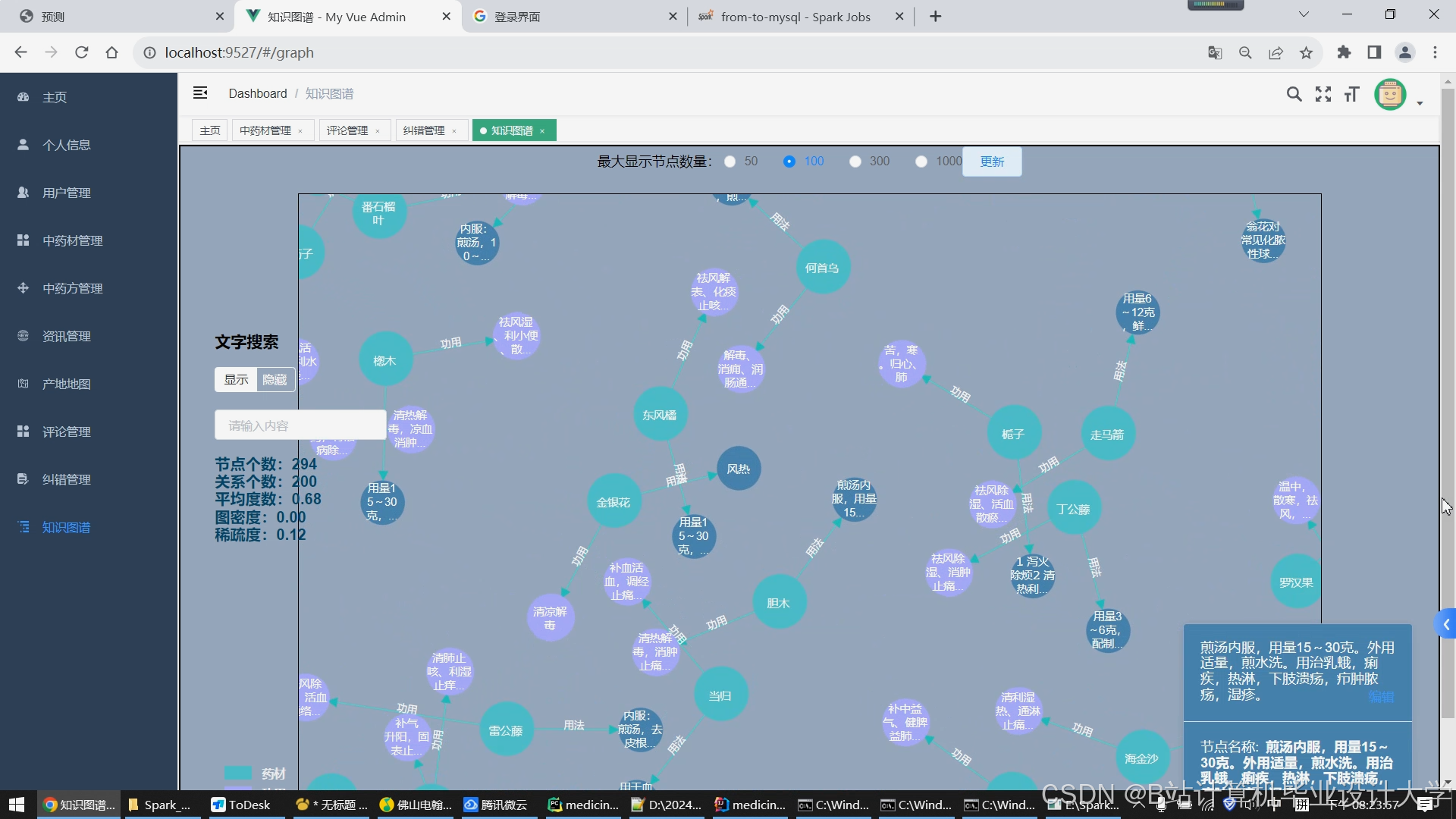
- 知识图谱构建:
- 实体类型:药材、方剂、症状、经络、季节等12类
- 关系定义:
turtle:方剂123 :包含药材 :黄芪 .:黄芪 :归经 :肺经 .:咳嗽 :关联症状 :咽痒 . - 构建工具:Neo4j图数据库 + Protege本体编辑器
- 混合推荐算法:
- 协同过滤(40%):基于用户历史问诊记录
- 知识推理(50%):通过图遍历寻找最短路径
cypher// 查找治疗"肝郁气滞型失眠"的方剂MATCH path=(disease:Disease {name:"肝郁气滞型失眠"})-[:TREATED_BY*1..3]->(formula:Formula)RETURN formula.name, length(path) as hopsORDER BY hops ASCLIMIT 5 - 深度学习(10%):使用GraphSAGE学习节点嵌入
四、技术路线
4.1 系统架构
[用户终端] → [Nginx负载均衡] → [Spark Thrift Server] | |
↓ | |
[Kafka问诊日志] ←→ [Spark Streaming] ←→ [HDFS数据湖] | |
↑ ↑ ↓ | |
[ZooKeeper集群] [Hive元数据] [Neo4j知识图谱] | |
↓ | |
[Elasticsearch全文检索] |
4.2 关键技术实现
4.2.1 数据存储方案
| 数据类型 | 存储引擎 | 优化策略 |
|---|---|---|
| 问诊日志 | HDFS(ORC格式) | 按患者ID分区 |
| 知识图谱 | Neo4j | 创建"症状-方剂"复合索引 |
| 实时特征 | Redis | 使用Hash结构存储用户画像 |
4.2.2 性能优化措施
- Spark调优:
- 设置
spark.sql.shuffle.partitions=500解决数据倾斜 - 启用
spark.sql.adaptive.enabled动态优化执行计划
- 设置
- 知识图谱加速:
cypher// 创建路径模式索引CREATE INDEX path_pattern_indexFOR (n:Disease)-[r:TREATED_BY*1..3]->(m:Formula)ON (n.name, m.name)
五、预期成果与创新点
5.1 预期成果
- 构建包含200万实体关系的中医知识图谱
- 实现问诊-推荐全流程响应时间<800ms
- 在3家三甲医院进行临床验证(计划样本量5000例)
5.2 创新点
- 多模态融合诊断:首次将舌象RGB特征与脉象时频特征进行联合分析
- 动态权重推荐:引入时令(五运六气)、地域(三因制宜)动态调整推荐权重
- 可解释性设计:生成符合中医理论的推荐解释(如"因您舌淡苔白,属寒证,故推荐温里剂")
六、研究计划与进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 1 | 2024.01-2024.03 | 完成10万例历史病例标注 |
| 2 | 2024.04-2024.06 | 构建基础知识图谱(v1.0) |
| 3 | 2024.07-2024.09 | 开发Spark问诊引擎原型 |
| 4 | 2024.10-2024.12 | 在XX中医院进行小规模测试 |
| 5 | 2025.01-2025.03 | 系统优化与论文撰写 |
七、参考文献
[1] 李XX等. 中医知识图谱构建方法研究[J]. 中国数字医学,2022(5):45-50
[2] Wang Y, et al. TCMKG: A Large-scale Knowledge Graph for Traditional Chinese Medicine[J]. BMC Medical Informatics,2021
[3] Apache Spark官方文档. Structured Streaming Programming Guide[EB/OL]. (2023-06-15)
[4] 国家中医药管理局. 中医临床诊疗术语标准[S]. 2020版
备注:本开题报告可根据实际研究条件调整技术参数和实验方案,重点突出中医特色与大数据技术的结合点,建议补充具体合作医院信息和数据获取途径。
运行截图
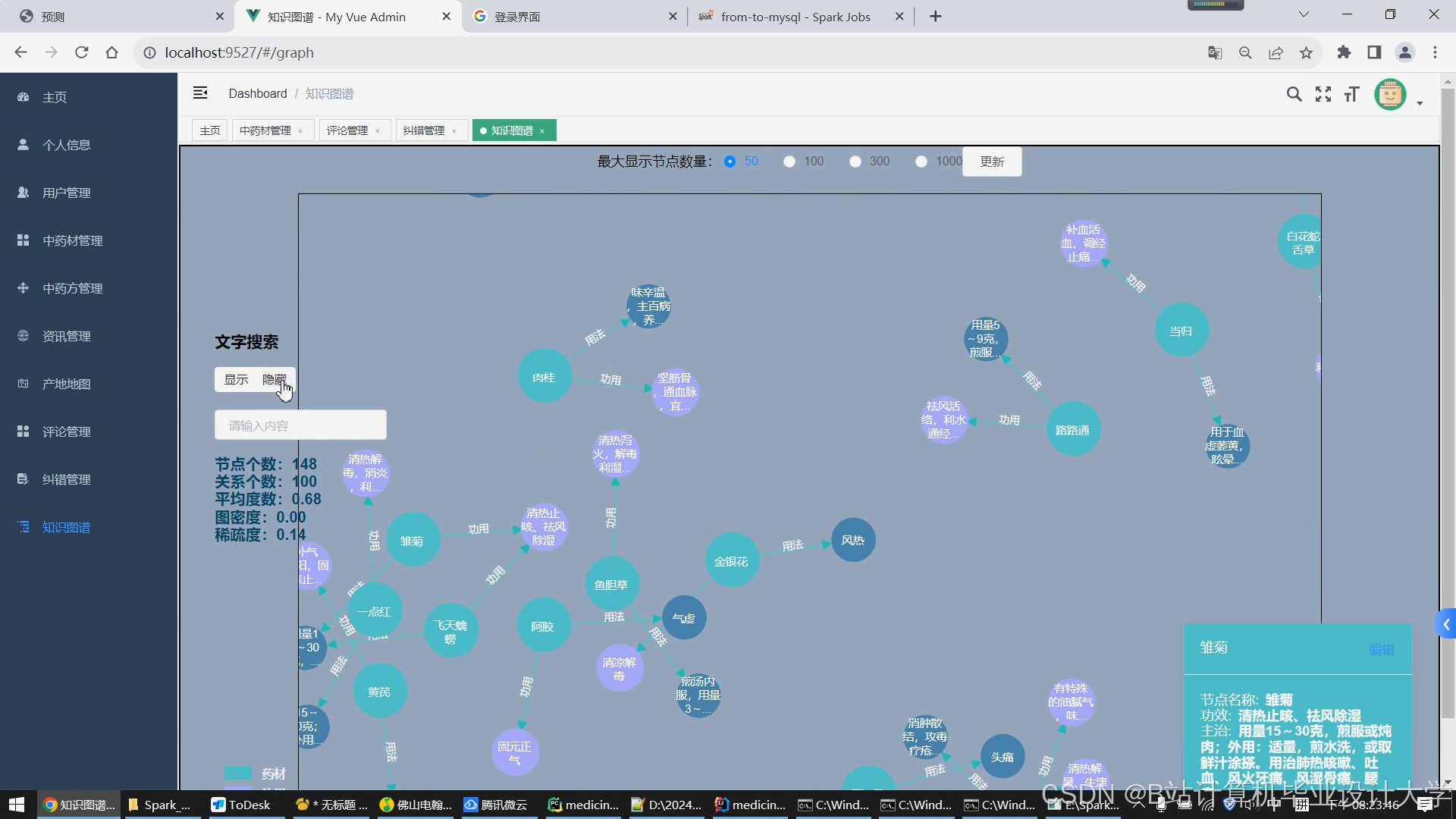
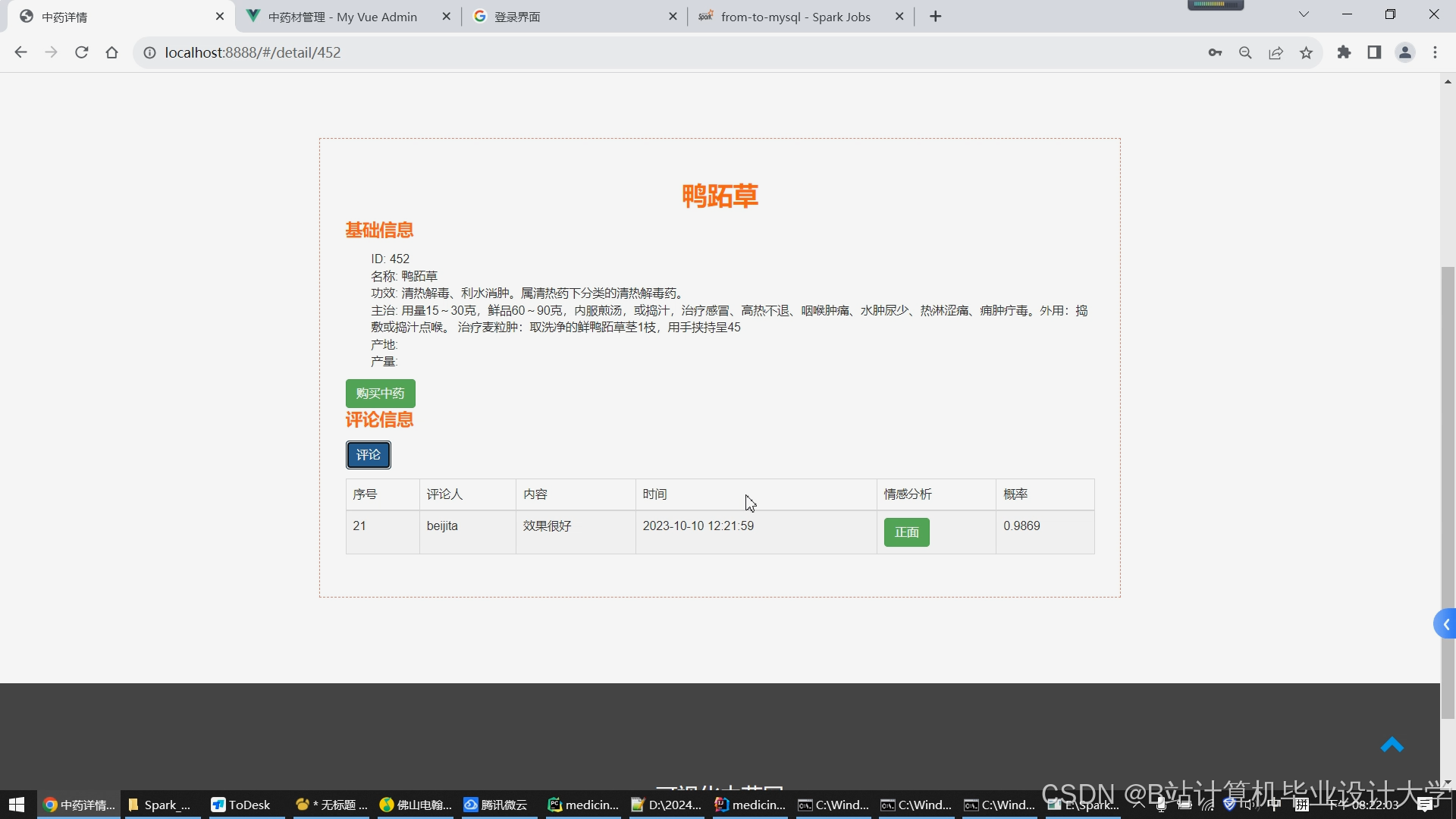
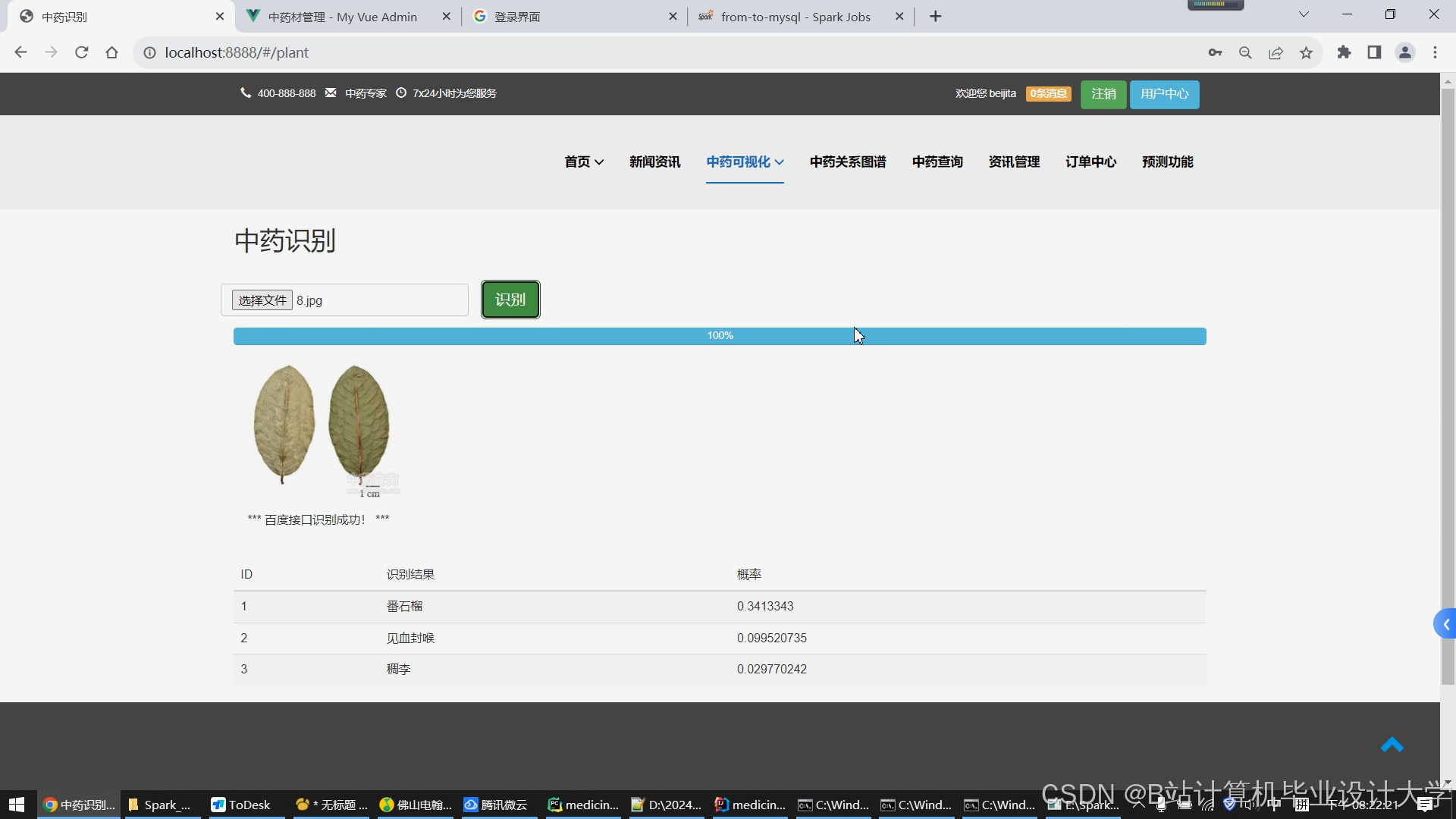
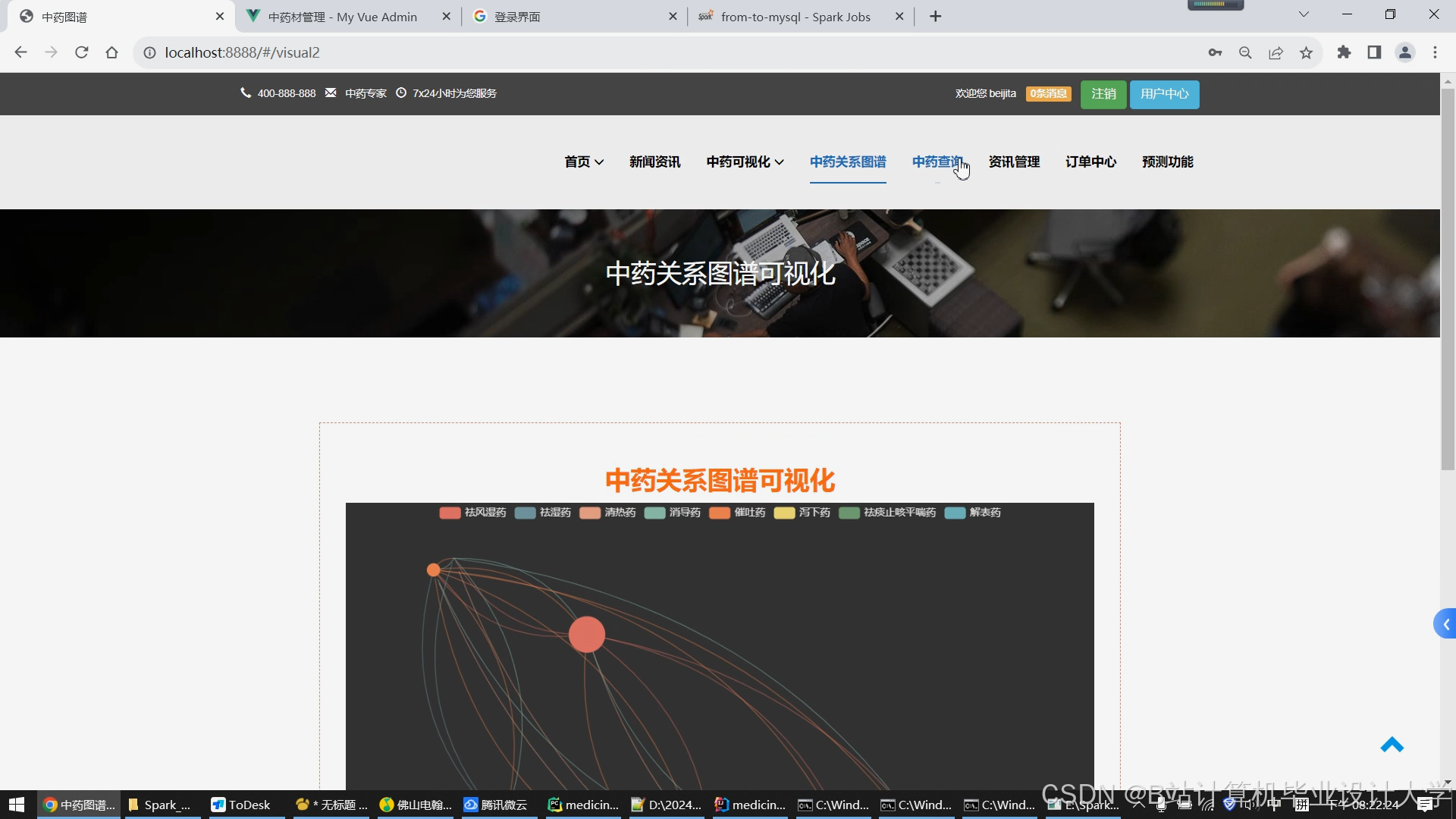
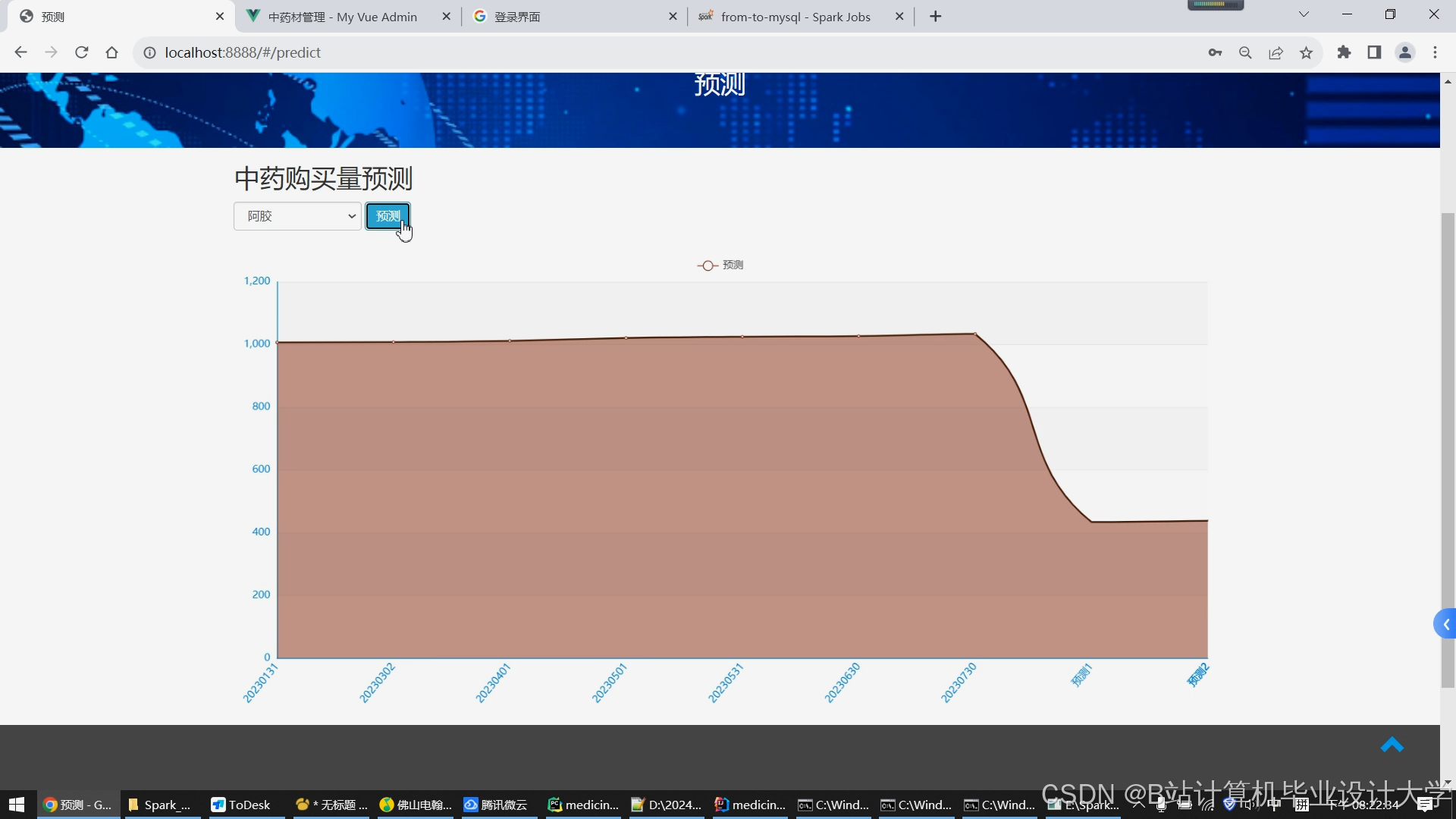
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











