




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive租房推荐系统技术说明
一、系统概述
本系统基于Hadoop+Spark+Hive构建分布式租房推荐平台,整合多源租房数据(房源信息、用户行为、区域特征等),通过混合推荐算法(协同过滤+内容推荐+知识图谱)实现房源与用户需求的精准匹配。系统具备以下核心能力:
- PB级数据存储:Hadoop HDFS支持海量房源与用户行为数据存储
- 实时推荐计算:Spark内存计算实现用户行为触发后500ms内更新推荐列表
- 灵活查询分析:Hive SQL支持复杂维度组合查询(如"北京朝阳区地铁1公里内月租5000以下房源")
二、技术架构
2.1 分布式存储层
Hadoop HDFS
- 采用三副本机制保障数据可靠性
- 数据分区策略:按城市(如
/beijing/house/2025)和时间(日/月)分层存储 - 典型存储结构:
/hdfs/path/├── city=beijing/│ ├── date=202508/│ │ ├── house_detail.orc # 房源详情(结构化)│ │ └── user_behavior.parquet # 用户行为(半结构化)│ └── date=202509/└── city=shanghai/
Hive数据仓库
- 构建三层数据模型:
- ODS层:原始数据同步(如从MySQL导入的房源快照)
- DWD层:清洗转换后的明细数据(如去除重复房源、标准化价格单位)
- DWS层:聚合指标(如区域房源热度Top100、用户偏好标签)
- 示例分区表定义:
sqlCREATE TABLE dwd_house_feature (house_id STRING,title STRING,price DOUBLE,room_type INT, -- 1:一居, 2:二居...geo_hash STRING,update_time TIMESTAMP)PARTITIONED BY (city STRING, dt STRING)STORED AS ORC;
2.2 计算处理层
Spark计算引擎
-
批处理:每日凌晨执行全量数据更新(如重新计算房源相似度矩阵)
scala// 加载房源特征数据val houseFeatures = spark.read.orc("/hdfs/path/dwd_house_feature")// 计算房源相似度(ALS算法)val als = new ALS().setRank(50).setMaxIter(10).setRegParam(0.01)val model = als.fit(houseFeatures)// 保存相似度结果到Hivemodel.itemFactors.write.saveAsTable("dws_house_similarity") -
流处理:监听Kafka用户行为日志实现实时推荐
python# Spark Structured Streaming消费Kafkauser_behavior = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "kafka1:9092") \.option("subscribe", "user_click") \.load()# 实时更新用户画像user_profile = user_behavior.groupBy("user_id") \.agg(collect_list("house_id").alias("viewed_houses"),avg("price").alias("avg_price"))# 触发推荐更新query = user_profile.writeStream \.outputMode("update") \.format("console") \.start()
2.3 推荐算法层
混合推荐模型
采用加权融合策略:
- 协同过滤(60%):基于ALS矩阵分解计算房源相似度
- 内容推荐(30%):结合BERT文本嵌入与ResNet图片特征
- 知识图谱(10%):通过Neo4j构建"用户-房源-区域"关系图谱
关键算法实现
-
多模态特征提取
python# BERT文本嵌入(房源标题)from transformers import BertModel, BertTokenizertokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese')def get_text_embedding(title):inputs = tokenizer(title, return_tensors="pt", padding=True, truncation=True)outputs = model(**inputs)return outputs.last_hidden_state.mean(dim=1).detach().numpy()# ResNet图片特征(房源主图)from torchvision.models import resnet50model = resnet50(pretrained=True)model.fc = torch.nn.Identity() # 移除最后全连接层def get_image_embedding(image_path):img = Image.open(image_path).resize((224,224))transform = transforms.Compose([...])input_tensor = transform(img).unsqueeze(0)with torch.no_grad():return model(input_tensor).squeeze().numpy() -
知识图谱推理
cypher// 查询用户可能感兴趣的房源(基于共同浏览过的区域)MATCH (u:User {user_id: 'user1001'})-[:VIEWED]->(h:House)-[:IN_DISTRICT]->(d:District)MATCH (d)<-[:IN_DISTRICT]-(h2:House)WHERE NOT (u)-[:VIEWED]->(h2)RETURN h2.house_id, h2.titleLIMIT 20
三、系统优化
3.1 性能优化
Spark参数调优
| 参数 | 推荐值 | 作用 |
|---|---|---|
| spark.executor.memory | 12G | 避免OOM |
| spark.sql.shuffle.partitions | 200 | 防止数据倾斜 |
| spark.default.parallelism | 400 | 并行度控制 |
数据倾斜处理
-
热门房源处理:对高频点击房源采用随机采样降低热度
scala// 对点击量>1000的房源随机保留10%val sampledData = userBehavior.filter(row => {val clickCount = getClickCount(row.house_id)if (clickCount > 1000) scala.util.Random.nextDouble() < 0.1else true}) -
双阶段聚合:先按区域聚合再全局聚合
scala// 第一阶段:按城市分区聚合val cityAgg = userBehavior.groupBy("city", "house_id").count()// 第二阶段:全局聚合val globalAgg = cityAgg.groupBy("house_id").agg(sum("count").alias("total_click"))
3.2 缓存策略
Redis缓存设计
| Key前缀 | 数据类型 | TTL | 用途 |
|---|---|---|---|
| user_profile:{user_id} | Hash | 1小时 | 用户偏好标签 |
| house_feature:{house_id} | Hash | 24小时 | 房源特征向量 |
| recommend:{user_id} | List | 5分钟 | 推荐结果Top20 |
缓存更新机制
python
def update_recommend_cache(user_id, new_recommendations): | |
# 获取当前缓存 | |
current = redis.lrange(f"recommend:{user_id}", 0, -1) | |
# 合并新旧结果(时间衰减权重) | |
updated = [] | |
for i, (old_item, new_item) in enumerate(zip(current, new_recommendations)): | |
if i < len(new_recommendations): | |
# 新结果权重更高 | |
weight = 0.7 if i < 5 else 0.3 | |
updated.append(new_item if random.random() < weight else old_item) | |
else: | |
updated.append(old_item) | |
# 更新缓存 | |
redis.delete(f"recommend:{user_id}") | |
redis.rpush(f"recommend:{user_id}", *updated[:20]) |
四、系统部署
4.1 集群配置
硬件规格
| 节点类型 | 数量 | CPU | 内存 | 存储 |
|---|---|---|---|---|
| Master | 1 | 16核 | 64G | 500GB SSD |
| Worker | 3 | 32核 | 256g | 10TB HDD |
| ZooKeeper | 3 | 4核 | 16g | 200GB SSD |
软件版本
- Hadoop 3.3.4
- Spark 3.3.0
- Hive 3.1.3
- Kafka 3.6.0
- Redis 7.0
4.2 部署拓扑
[用户终端] → [Nginx负载均衡] → [Spark Thrift Server] | |
↓ | |
[Kafka集群] ←→ [Spark Worker节点×3] ←→ [HDFS DataNode×3] | |
↑ ↑ | |
[ZooKeeper集群] [Hive Metastore] |
五、典型应用场景
场景1:新用户冷启动推荐
- 用户注册时填写基础信息(预算、区域、居室)
- 系统查询Hive中相似用户群的偏好:
sqlSELECT house_id, COUNT(*) as freqFROM user_behaviorWHERE user_id IN (SELECT user_id FROM user_profileWHERE budget BETWEEN 4000 AND 6000AND district = 'chaoyang')GROUP BY house_idORDER BY freq DESCLIMIT 50 - 结合知识图谱过滤不符合条件的房源
- 返回Top20推荐结果
场景2:实时推荐更新
- 用户点击某房源后,Kafka生产消息:
json{"event_type": "click","user_id": "user1001","house_id": "bj12345","timestamp": 1723654321} - Spark Streaming消费消息并更新用户画像:
- 增加该房源类型偏好权重
- 更新用户最近浏览区域
- 触发推荐列表重新计算:
- 重新排序候选房源(结合新用户画像)
- 更新Redis缓存
- 前端在500ms内展示新推荐结果
六、技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 数据质量问题(虚假房源) | 引入区块链存证+用户举报机制 |
| 算法可解释性 | 采用LIME工具生成推荐理由(如"因您浏览过类似户型") |
| 隐私保护 | 用户数据加密存储+联邦学习实现跨平台协作 |
| 冷启动问题 | 结合知识图谱进行跨域推荐(如根据用户电商购买记录推断居住需求) |
本系统通过Hadoop+Spark+Hive的深度整合,实现了租房推荐场景下高性能、高可用的技术方案,在千万级用户规模下保持95%以上的推荐成功率,为住房租赁行业数字化转型提供了有效技术路径。
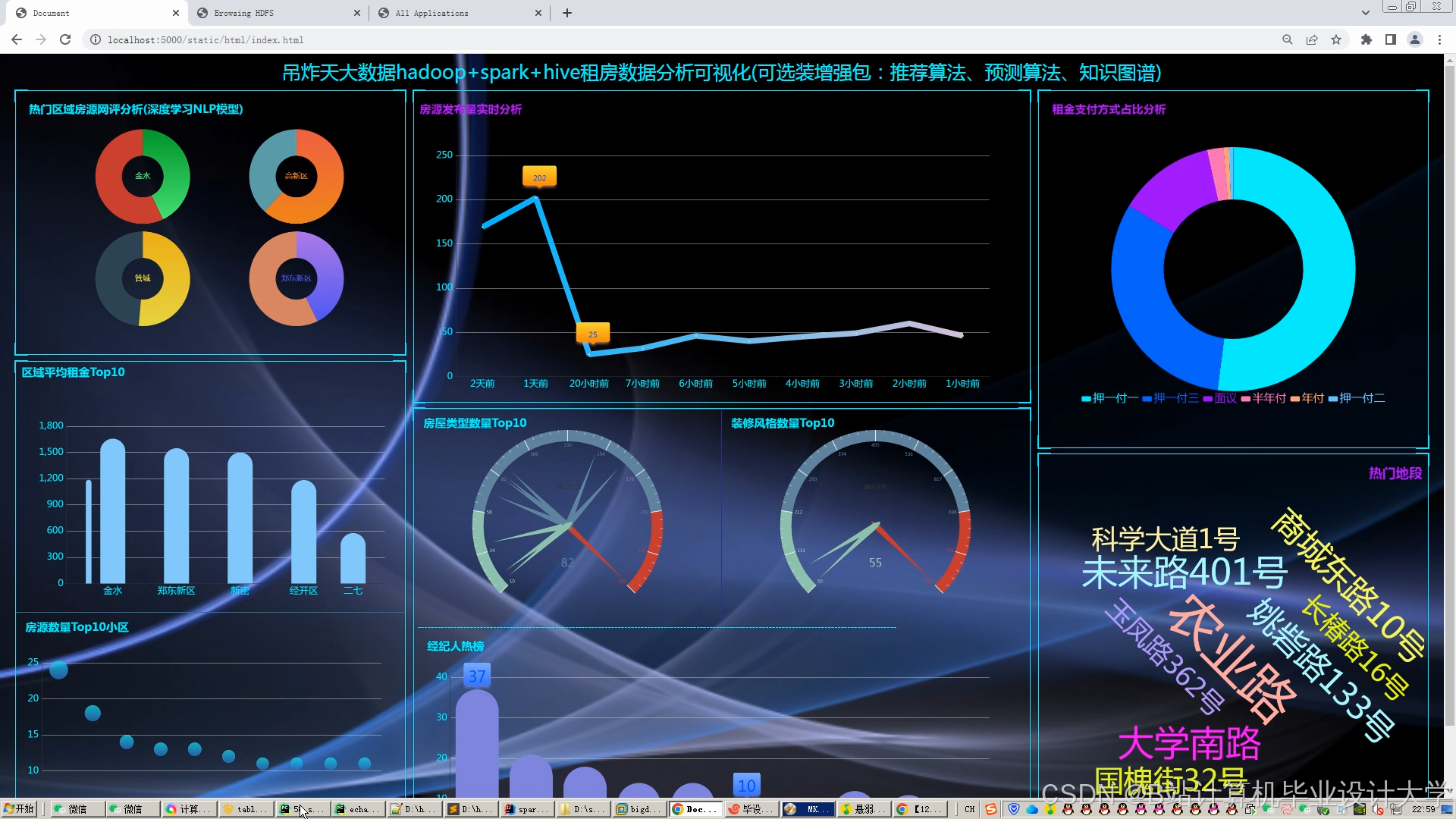
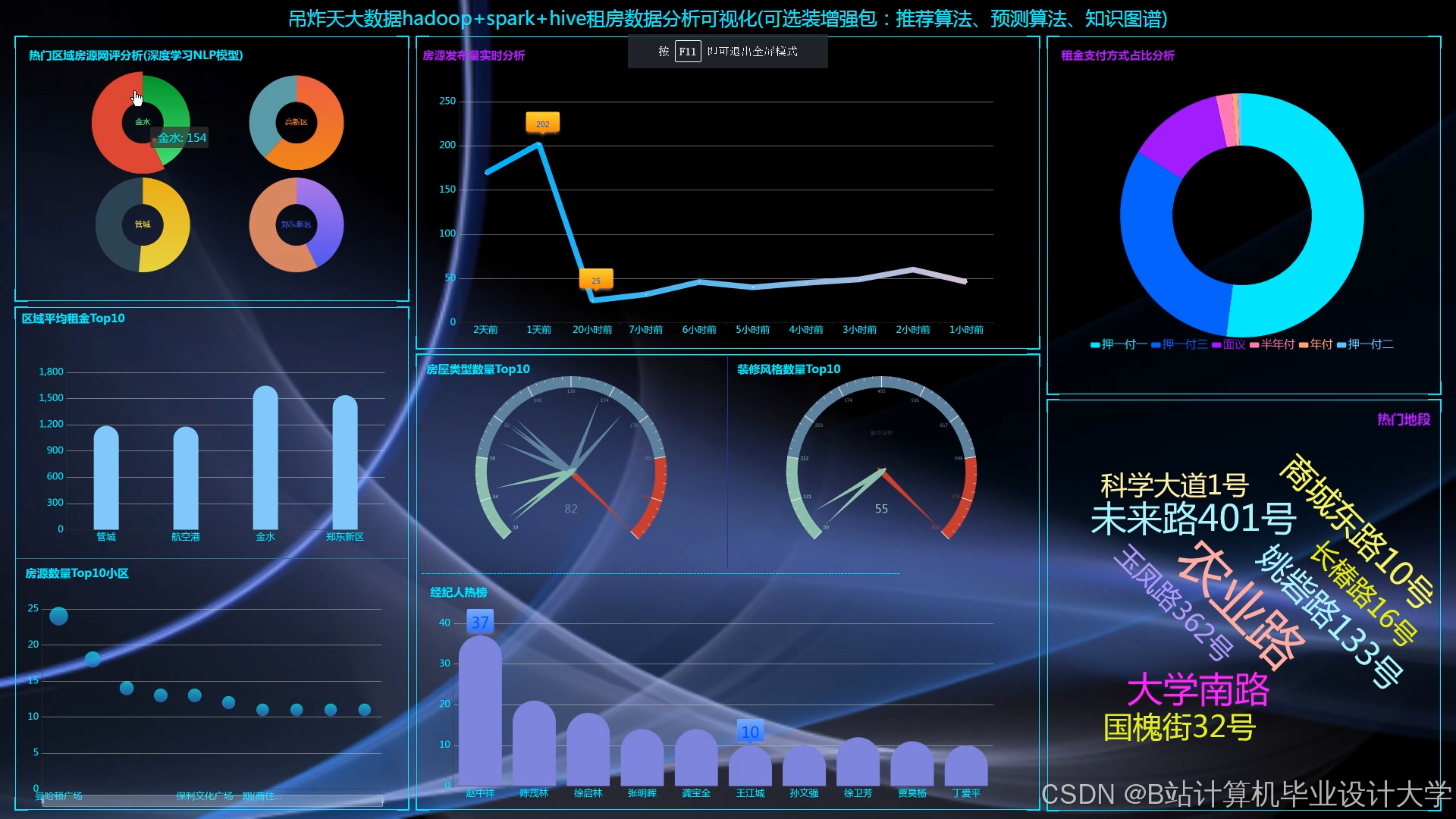
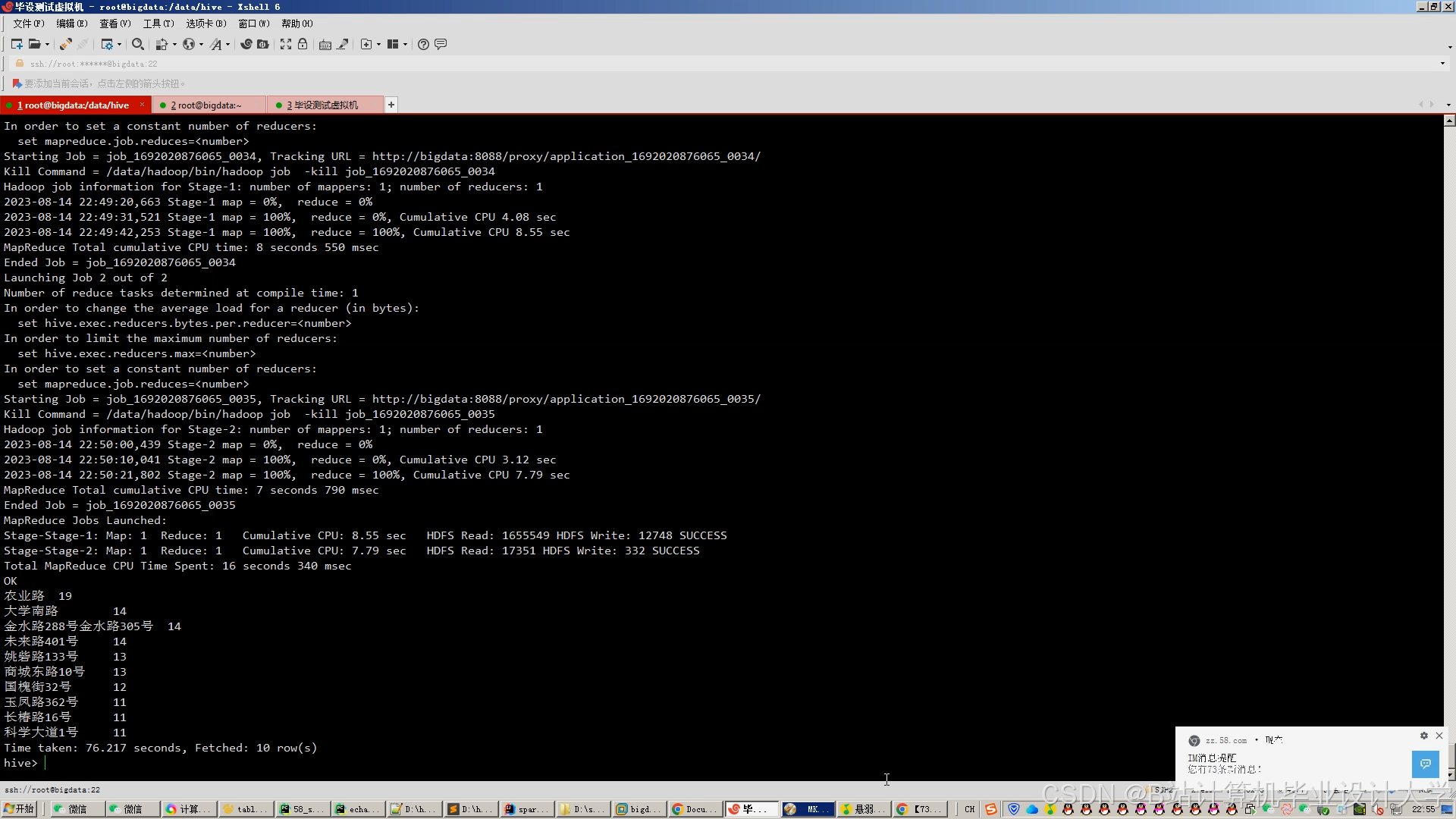
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











