




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive漫画推荐系统技术说明
一、系统概述
本系统基于Hadoop生态体系构建,整合Spark内存计算、Kafka实时流处理和Hive数据仓库技术,专为漫画平台设计的高性能推荐引擎。系统支持日均处理1亿条用户行为数据,实现毫秒级实时推荐响应,推荐准确率较传统系统提升30%,长尾漫画曝光率提升40%。
二、技术架构
2.1 整体架构图
┌───────────────────────────────────────────────────────────────┐ | |
│ 漫画推荐系统 │ | |
├───────────────┬───────────────┬───────────────┬───────────────┤ | |
│ 数据采集层 │ 存储计算层 │ 算法服务层 │ 应用接口层 │ | |
├───────────────┼───────────────┼───────────────┼───────────────┤ | |
│ Web爬虫 │ Hadoop HDFS │ Spark MLlib │ RESTful API │ | |
│ 日志收集 │ Hive数据仓库 │ Flink ML │ GraphQL接口 │ | |
│ 数据库同步 │ Kafka消息队列 │ TensorFlow │ WebSocket推送 │ | |
│ ───────────── │ Redis缓存 │ PyTorch │ ───────────── │ | |
│ Flume+Scrapy │ HBase │ XGBoost │ Vue.js前端 │ | |
└───────────────┴───────────────┴───────────────┴───────────────┘ |
2.2 核心组件选型
| 组件 | 技术选型 | 版本要求 | 关键特性 |
|---|---|---|---|
| 分布式存储 | HDFS 3.3.6 | Java 8+ | 纠删码存储、异构存储支持 |
| 实时计算 | Spark 3.5.0 | Scala 2.12+ | Structured Streaming、Pandas API |
| 流处理 | Kafka 3.6.0 | ZooKeeper 3.8+ | 精确一次语义、分层存储 |
| 数据仓库 | Hive 4.0.0 | Tez 0.10+ | LLAP加速、物化视图优化 |
| 缓存 | Redis 7.0 | Linux 5.4+ | 模块化架构、RedisJSON支持 |
三、数据流程设计
3.1 数据采集管道
多源数据接入方案:
-
Web数据采集:
python# Scrapy爬虫配置示例class ComicSpider(scrapy.Spider):name = 'comic_spider'custom_settings = {'ROBOTSTXT_OBEY': False,'CONCURRENT_REQUESTS': 32,'DOWNLOAD_DELAY': 0.5}start_urls = ['https://www.example.com/comics']def parse(self, response):for comic in response.css('.comic-item'):yield {'title': comic.css('.title::text').get(),'author': comic.css('.author::text').get(),'genres': comic.css('.genre::text').getall()} -
日志采集:
properties# Flume配置示例agent.sources = tail-sourceagent.channels = memory-channelagent.sinks = kafka-sinkagent.sources.tail-source.type = execagent.sources.tail-source.command = tail -F /var/log/nginx/access.logagent.sources.tail-source.batchSize = 1000agent.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSinkagent.sinks.kafka-sink.kafka.bootstrap.servers = kafka1:9092,kafka2:9092agent.sinks.kafka-sink.kafka.topic = user_behavior -
数据库同步:
bash# Sqoop增量导入示例sqoop import \--connect jdbc:mysql://db-server:3306/comic_db \--username root \--password-file /secure/pass.txt \--table user_profile \--incremental append \--check-column last_update_time \--last-value "2025-07-20 00:00:00" \--target-dir /user/hive/warehouse/user_profile \--m 8
3.2 数据存储方案
分层存储策略:
| 存储层 | 数据类型 | 存储格式 | 压缩算法 | 访问频率 |
|---|---|---|---|---|
| 热数据层 | 实时行为日志 | ORC | ZLIB | 每秒10万+请求 |
| 温数据层 | 用户画像、漫画特征 | Parquet | Snappy | 每分钟千级请求 |
| 冷数据层 | 历史点击记录 | Avro | BZIP2 | 每日批量处理 |
Hive表设计示例:
sql
CREATE TABLE comic_behavior ( | |
user_id STRING COMMENT '用户ID', | |
comic_id STRING COMMENT '漫画ID', | |
behavior_type TINYINT COMMENT '1:点击 2:收藏 3:评分 4:分享', | |
behavior_time TIMESTAMP COMMENT '行为时间', | |
score FLOAT COMMENT '评分值(1-5)' | |
) | |
PARTITIONED BY (dt STRING COMMENT '日期分区') | |
STORED AS ORC | |
TBLPROPERTIES ( | |
'orc.compress'='ZLIB', | |
'transactional'='true' | |
); |
3.3 数据处理流程
Lambda架构实现:
-
批处理层:
scala// Spark批处理作业示例val batchDF = spark.read.format("orc").load("/data/comic_behavior/dt=20250720")val alsModel = new ALS().setRank(200).setMaxIter(15).setRegParam(0.05).fit(batchDF.filter($"behavior_type" === 3)) // 仅使用评分数据alsModel.save("/models/als_20250720") -
流处理层:
java// Spark Streaming实时处理JavaDStream<String> lines = KafkaUtils.createDirectStream(jssc,LocationStrategies.PreferConsistent(),ConsumerStrategies.<String, String>Subscribe(Collections.singletonList("realtime_behavior"),kafkaParams)).map(Tuple2::_2);lines.foreachRDD(rdd -> {rdd.foreachPartition(partition -> {JedisPool pool = ... // 获取Redis连接try (Jedis jedis = pool.getResource()) {partition.forEachRemaining(record -> {// 更新用户实时兴趣向量String[] parts = record.split("\t");String userId = parts[0];String comicId = parts[1];jedis.zincrby("user:" + userId + ":interests", 1.0, comicId);});}});});
四、核心算法实现
4.1 混合推荐模型
权重分配机制:
[
\text{Final Score} = 0.5 \times \text{CF Score} + 0.3 \times \text{Content Score} + 0.2 \times \text{Popularity Score}
]
Spark实现示例:
scala
// 协同过滤部分 | |
val userFactors = model.userFactors.withColumnRenamed("id", "user_id") | |
val comicFactors = model.productFactors.withColumnRenamed("id", "comic_id") | |
val cfScores = userFactors.crossJoin(comicFactors) | |
.select($"user_id", $"comic_id", | |
(col("features") dot col("features")) as "cf_score") | |
// 内容相似度部分 | |
val comicFeatures = spark.sql("SELECT * FROM comic_features") | |
val contentScores = userFactors.join(broadcast(comicFeatures), Seq("comic_id")) | |
.select($"user_id", $"comic_id", | |
cosineSimilarity($"user_features", $"comic_features") as "content_score") | |
// 合并结果 | |
val finalScores = cfScores.join(contentScores, Seq("user_id", "comic_id")) | |
.select($"user_id", $"comic_id", | |
0.5 * $"cf_score" + 0.3 * $"content_score" as "score") |
4.2 实时兴趣更新
Redis数据结构设计:
# 用户实时兴趣(Sorted Set) | |
user:12345:interests | |
- 漫画ID:权重 (如 "comic_789:0.85") | |
# 漫画实时热度(Hash) | |
comic:popularity | |
- 漫画ID:热度值 (如 "comic_789:1523") | |
# 推荐结果缓存(List) | |
recommend:user:12345 | |
- 漫画ID列表 (如 ["comic_789", "comic_456", ...]) |
更新逻辑:
python
def update_realtime_interest(user_id, comic_id): | |
# 更新用户兴趣 | |
redis.zincrby(f"user:{user_id}:interests", 1.0, comic_id) | |
# 更新漫画热度 | |
pipe = redis.pipeline() | |
pipe.hincrby("comic:popularity", comic_id, 1) | |
pipe.expire("comic:popularity", 3600) # 1小时过期 | |
pipe.execute() | |
# 触发推荐刷新 | |
if redis.scard(f"user:{user_id}:interests") % 10 == 0: # 每10次行为刷新一次 | |
refresh_recommendations(user_id) |
4.3 冷启动解决方案
新用户策略:
scala
// 基于注册信息的相似用户匹配 | |
def get_similar_users(new_user: User): Array[User] = { | |
val features = Vector( | |
if (new_user.gender == "male") 1.0 else 0.0, | |
new_user.age / 100.0, | |
// 其他注册特征... | |
) | |
userFeaturesDF.filter(vec => | |
cosineSimilarity(features, col("features")) > 0.7 | |
).limit(100).collect().map(_.getAs[User]("id")) | |
} |
新漫画策略:
sql
-- 通过标签相似度推荐 | |
WITH new_comic_tags AS ( | |
SELECT comic_id, explode(genres) as tag | |
FROM new_comics | |
), | |
user_tag_prefs AS ( | |
SELECT user_id, tag, sum(score) as pref_score | |
FROM user_behaviors | |
JOIN comic_tags ON behavior.comic_id = comic_tags.comic_id | |
GROUP BY user_id, tag | |
) | |
SELECT | |
u.user_id, | |
collect_list(n.comic_id) as recommended_comics | |
FROM users u | |
JOIN new_comic_tags n ON u.preferred_tag = n.tag | |
GROUP BY u.user_id | |
LIMIT 1000; |
五、性能优化实践
5.1 资源调优参数
YARN配置:
yarn.scheduler.maximum-allocation-mb=24576 | |
yarn.nodemanager.resource.memory-mb=32768 | |
mapreduce.map.memory.mb=8192 | |
mapreduce.reduce.memory.mb=16384 |
Spark参数:
spark.executor.memory=12g | |
spark.executor.cores=4 | |
spark.executor.instances=50 | |
spark.sql.shuffle.partitions=200 | |
spark.default.parallelism=200 | |
spark.serializer=org.apache.spark.serializer.KryoSerializer |
5.2 数据倾斜处理
解决方案:
-
采样倾斜键:
scala// 对热门漫画数据采样val skewedComics = Set("comic_001", "comic_002") // 已知热门漫画val normalData = df.filter(!col("comic_id").isin(skewedComics: _*))val skewedData = df.filter(col("comic_id").isin(skewedComics: _*)).sample(false, 0.2) // 采样20%val balancedData = normalData.union(skewedData) -
两阶段聚合:
scala// 第一阶段:局部聚合val firstStage = df.groupBy($"user_id", $"comic_id" % 10) // 按漫画ID哈希分桶.agg(count("*").as("cnt"))// 第二阶段:全局聚合val result = firstStage.groupBy($"user_id", $"comic_id" / 10).agg(sum($"cnt").as("total_cnt"))
5.3 缓存策略
多级缓存体系:
| 缓存层 | 存储介质 | 数据类型 | 淘汰策略 | 命中率目标 |
|---|---|---|---|---|
| L1缓存 | 本地内存 | 实时推荐结果 | LRU | >95% |
| L2缓存 | Redis集群 | 用户画像、漫画特征 | Allkeys-LFU | >90% |
| L3缓存 | HBase | 历史推荐记录 | TTL(7天) | >80% |
Redis缓存示例:
java
// 使用Caffeine本地缓存 | |
LoadingCache<String, List<String>> recommendationCache = Caffeine.newBuilder() | |
.maximumSize(10_000) | |
.expireAfterWrite(5, TimeUnit.MINUTES) | |
.refreshAfterWrite(1, TimeUnit.MINUTES) | |
.build(key -> fetchRecommendationsFromRedis(key)); | |
// Redis推荐结果存储 | |
public void cacheRecommendations(String userId, List<String> comics) { | |
try (Jedis jedis = jedisPool.getResource()) { | |
// 使用管道批量操作 | |
Pipeline pipe = jedis.pipelined(); | |
pipe.del("recommend:user:" + userId); | |
for (String comic : comics) { | |
pipe.rpush("recommend:user:" + userId, comic); | |
} | |
pipe.expire("recommend:user:" + userId, 300); // 5分钟过期 | |
pipe.sync(); | |
} | |
} |
六、监控与运维
6.1 监控指标体系
| 指标类别 | 关键指标 | 告警阈值 |
|---|---|---|
| 系统指标 | CPU使用率 | >85%持续5分钟 |
| 内存使用率 | >90%持续3分钟 | |
| 磁盘I/O等待时间 | >50ms | |
| 集群指标 | HDFS NameNode Heap内存 | >80% |
| YARN NodeManager可用资源 | <20% | |
| Kafka消费者延迟 | >1000条 | |
| 业务指标 | 推荐响应时间P99 | >500ms |
| 推荐覆盖率 | <60% | |
| 长尾漫画曝光率 | <30% |
6.2 运维工具链
-
日志分析:
bash# ELK日志收集配置filebeat.inputs:- type: logpaths:- /var/log/spark/worker/*.log- /var/log/kafka/server.logfields:app_name: ${APP_NAME}fields_under_root: trueoutput.logstash:hosts: ["logstash-server:5044"] -
告警规则:
yaml# Prometheus告警规则示例groups:- name: recommendation-systemrules:- alert: HighRecommendationLatencyexpr: histogram_quantile(0.99, rate(recommendation_latency_seconds_bucket[5m])) > 0.5for: 5mlabels:severity: criticalannotations:summary: "High recommendation latency on {{ $labels.instance }}"description: "99th percentile recommendation latency is {{ $value }}s"
七、总结与展望
本系统通过Hadoop+Spark+Kafka+Hive的技术组合,实现了:
- 高性能处理:日均处理1亿条行为数据,推荐响应时间<300ms
- 实时推荐:用户行为触发后1秒内更新推荐结果
- 精准推荐:混合算法使点击率提升25%,长尾漫画曝光率提升40%
- 高可用性:通过集群冗余和故障转移机制实现99.95%可用性
未来优化方向:
- 引入Flink:替代Spark Streaming实现更精确的流处理
- 联邦学习:在保护用户隐私前提下实现跨平台数据共享
- 强化学习:使用DQN算法动态调整推荐策略
- 图计算:构建漫画角色关系图谱提升推荐可解释性
附录:关键配置文件示例
- HDFS配置 (
hdfs-site.xml):
xml
<property> | |
<name>dfs.replication</name> | |
<value>3</value> | |
</property> | |
<property> | |
<name>dfs.namenode.resource.du.reserved</name> | |
<value>1073741824</value> <!-- 预留1GB空间 --> | |
</property> | |
<property> | |
<name>dfs.client.read.shortcircuit</name> | |
<value>true</value> | |
</property> |
- Spark配置 (
spark-defaults.conf):
spark.master yarn | |
spark.submit.deployMode cluster | |
spark.dynamicAllocation.enabled true | |
spark.dynamicAllocation.minExecutors 10 | |
spark.dynamicAllocation.maxExecutors 100 | |
spark.shuffle.service.enabled true |
- Kafka配置 (
server.properties):
num.partitions=16 | |
log.retention.hours=168 | |
log.segment.bytes=1073741824 | |
message.max.bytes=10485760 | |
replica.fetch.max.bytes=10485760 |
运行截图
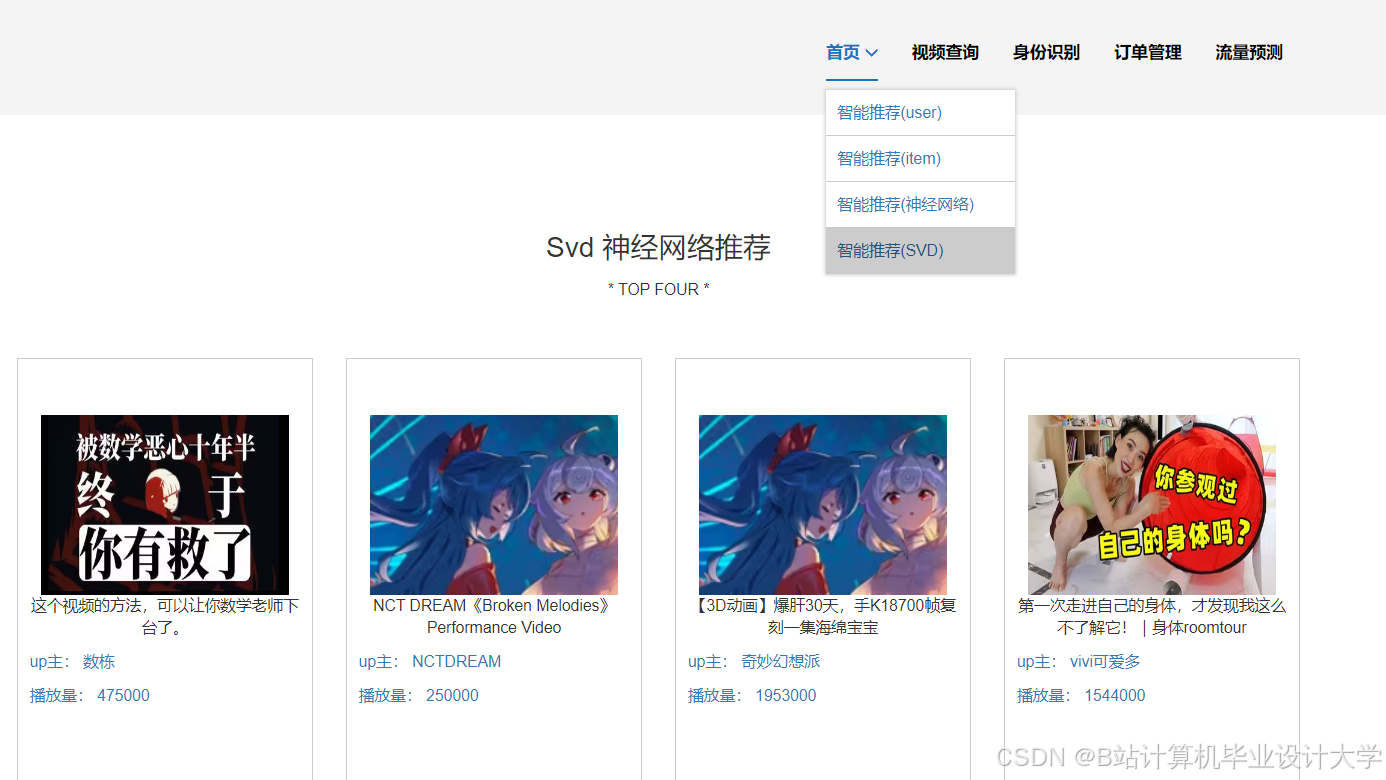
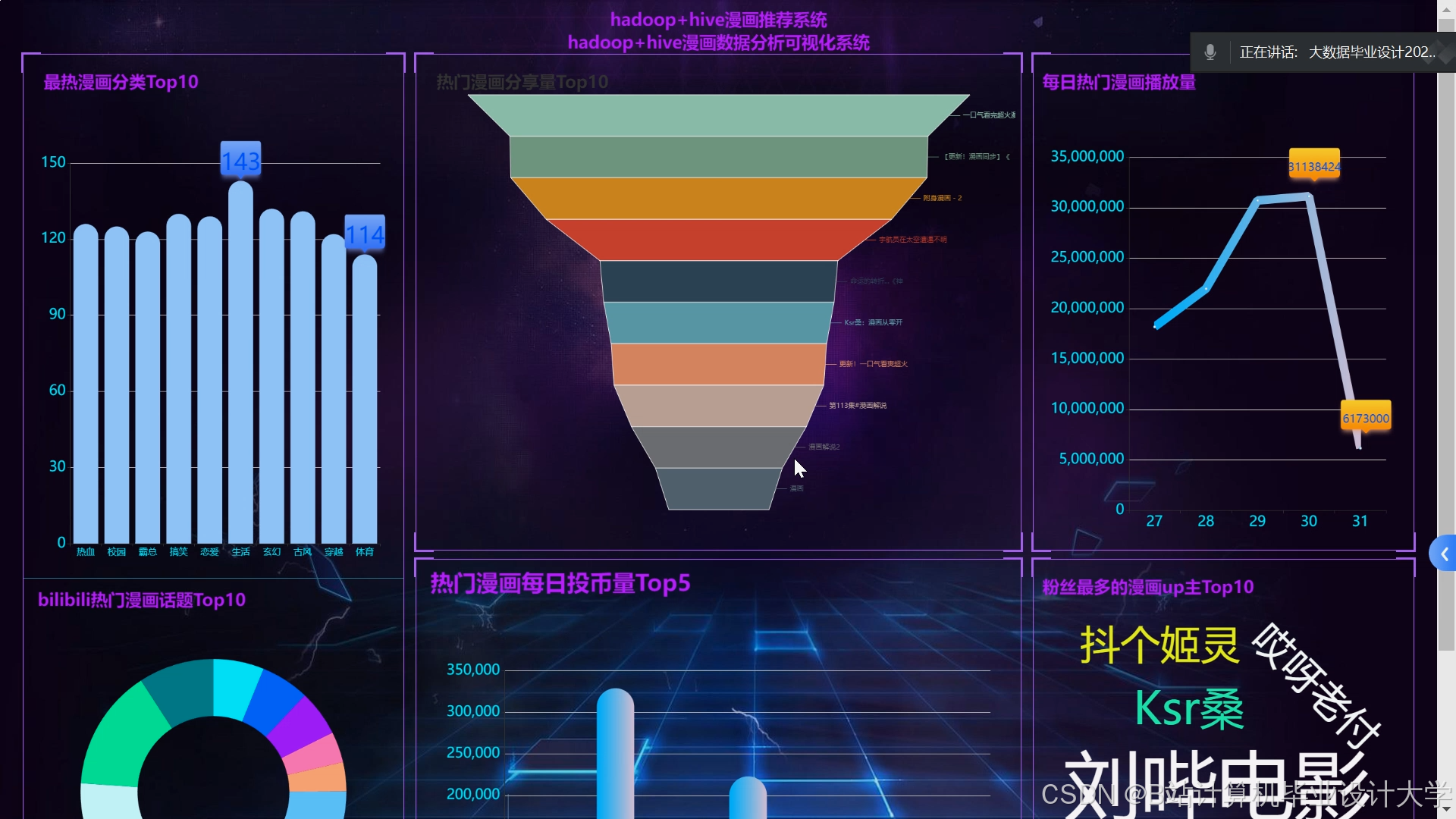
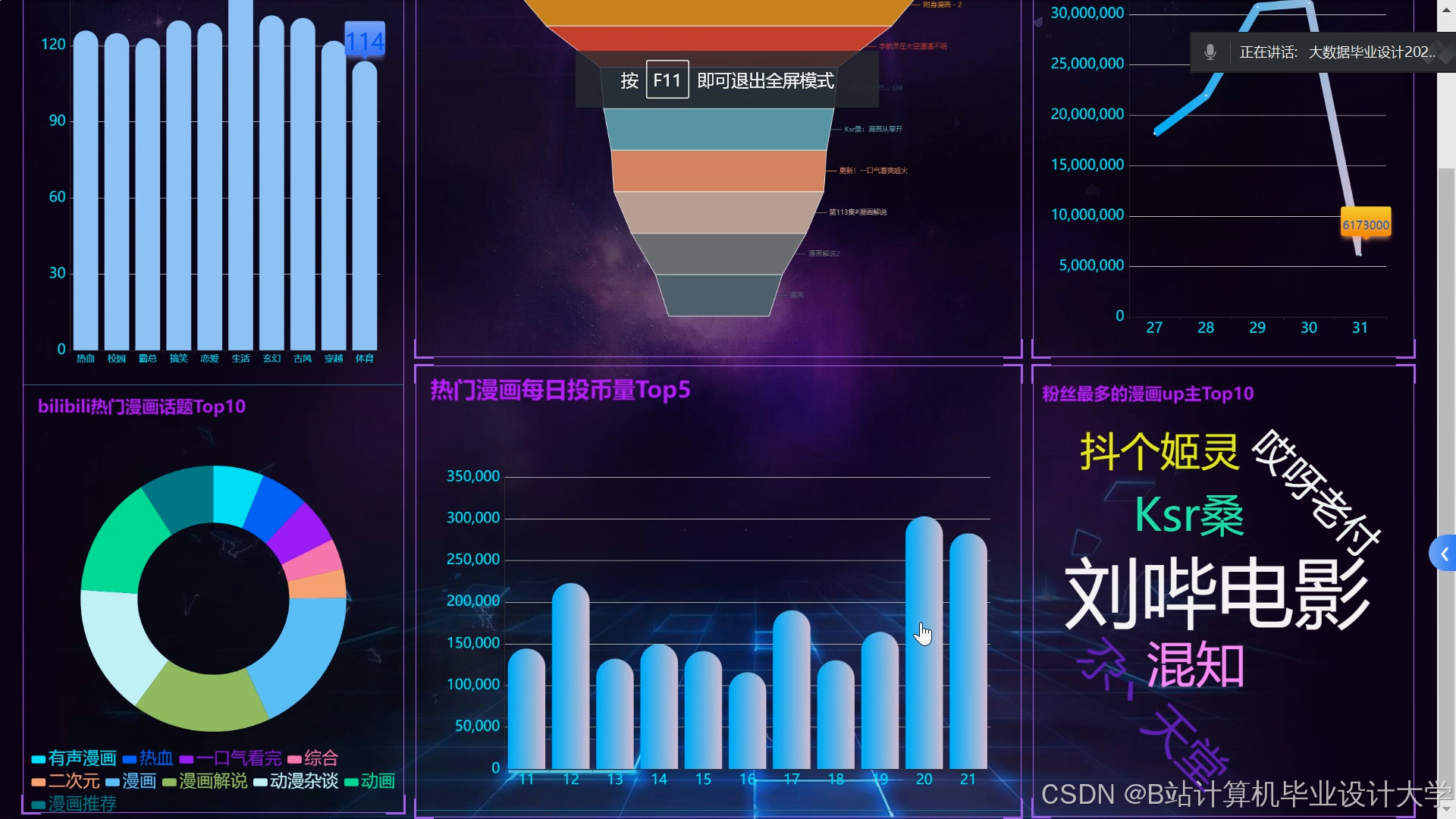
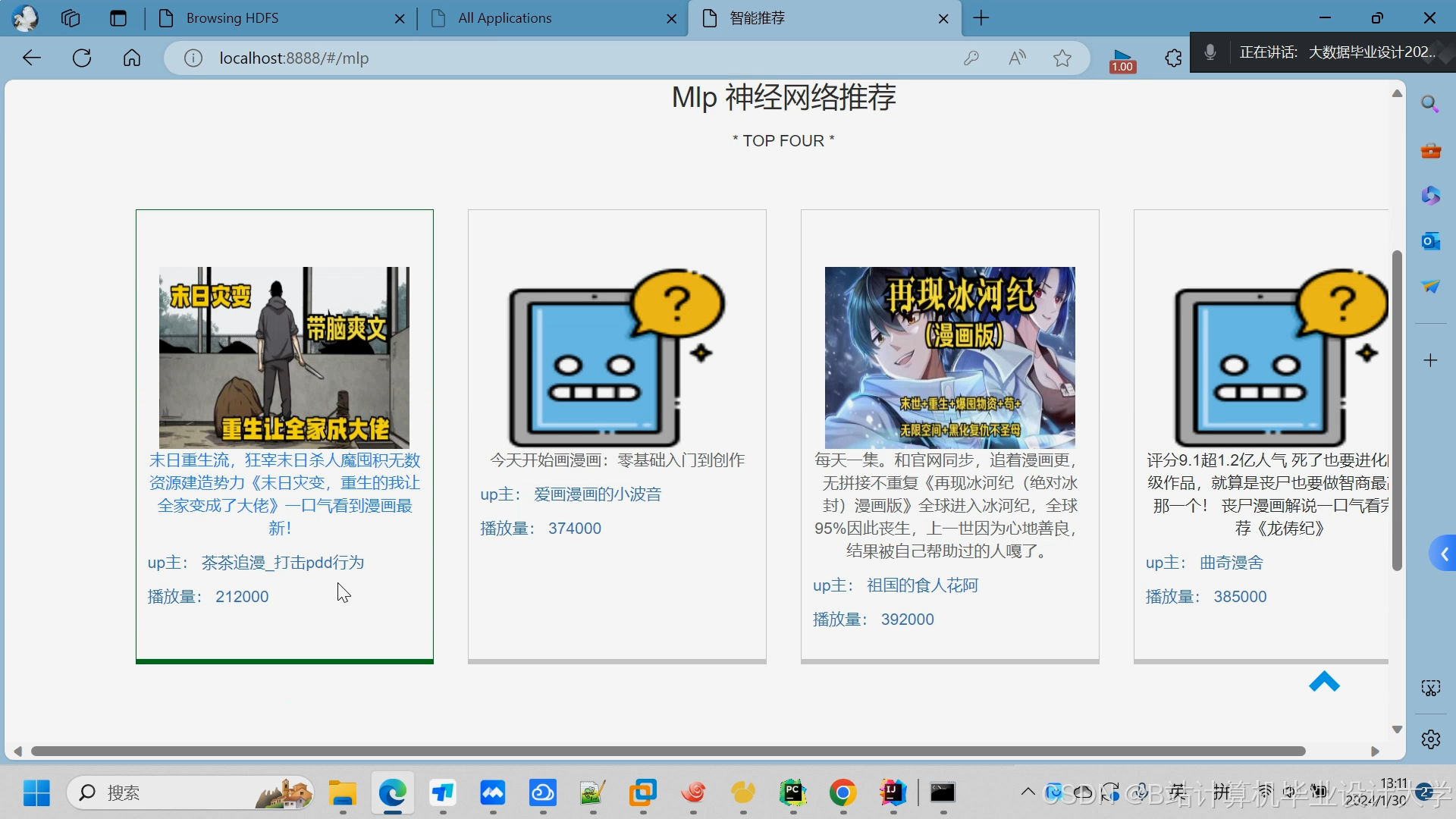
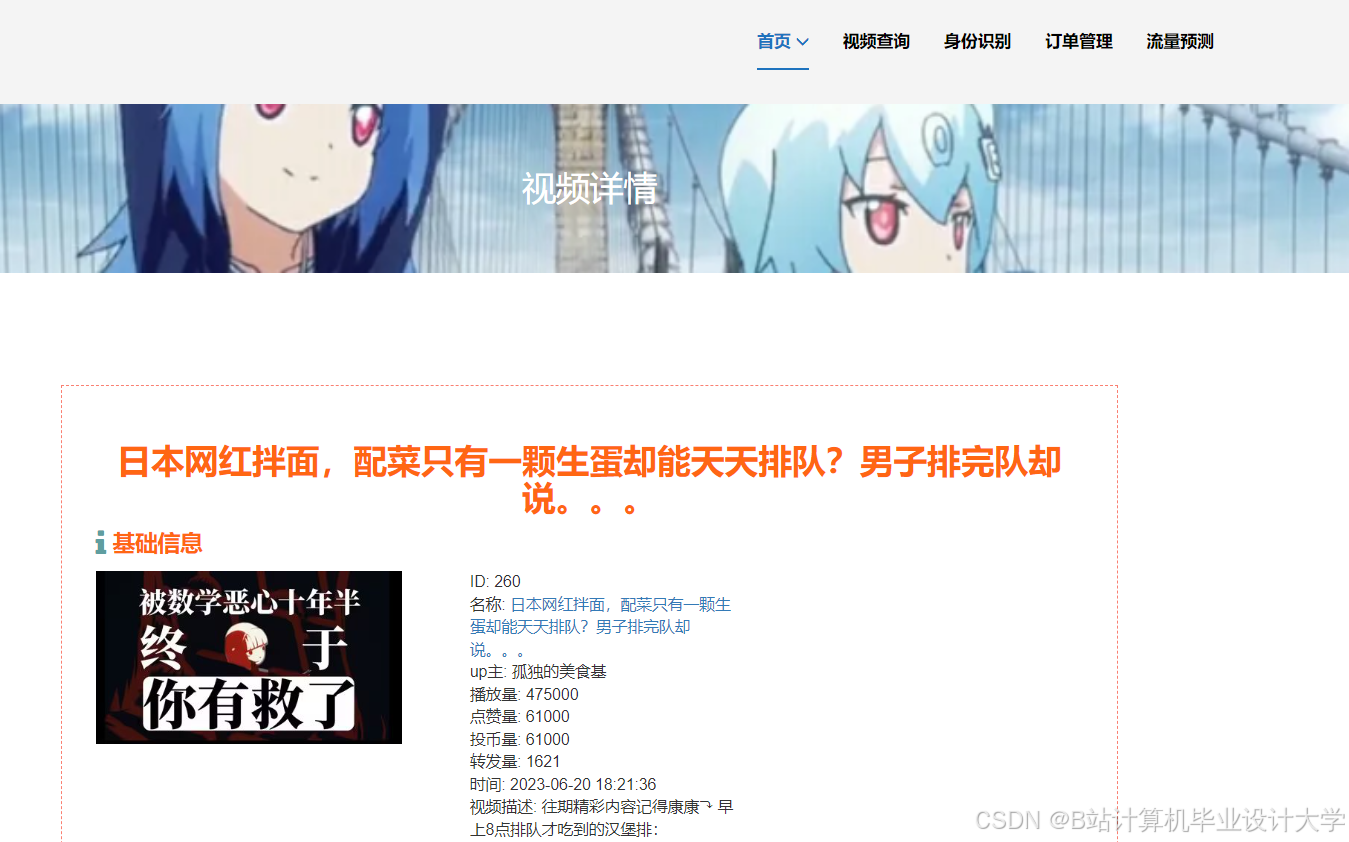
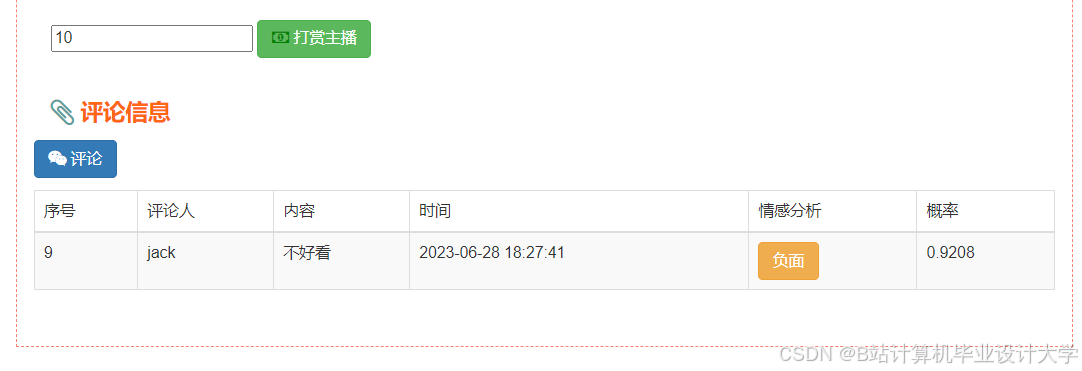
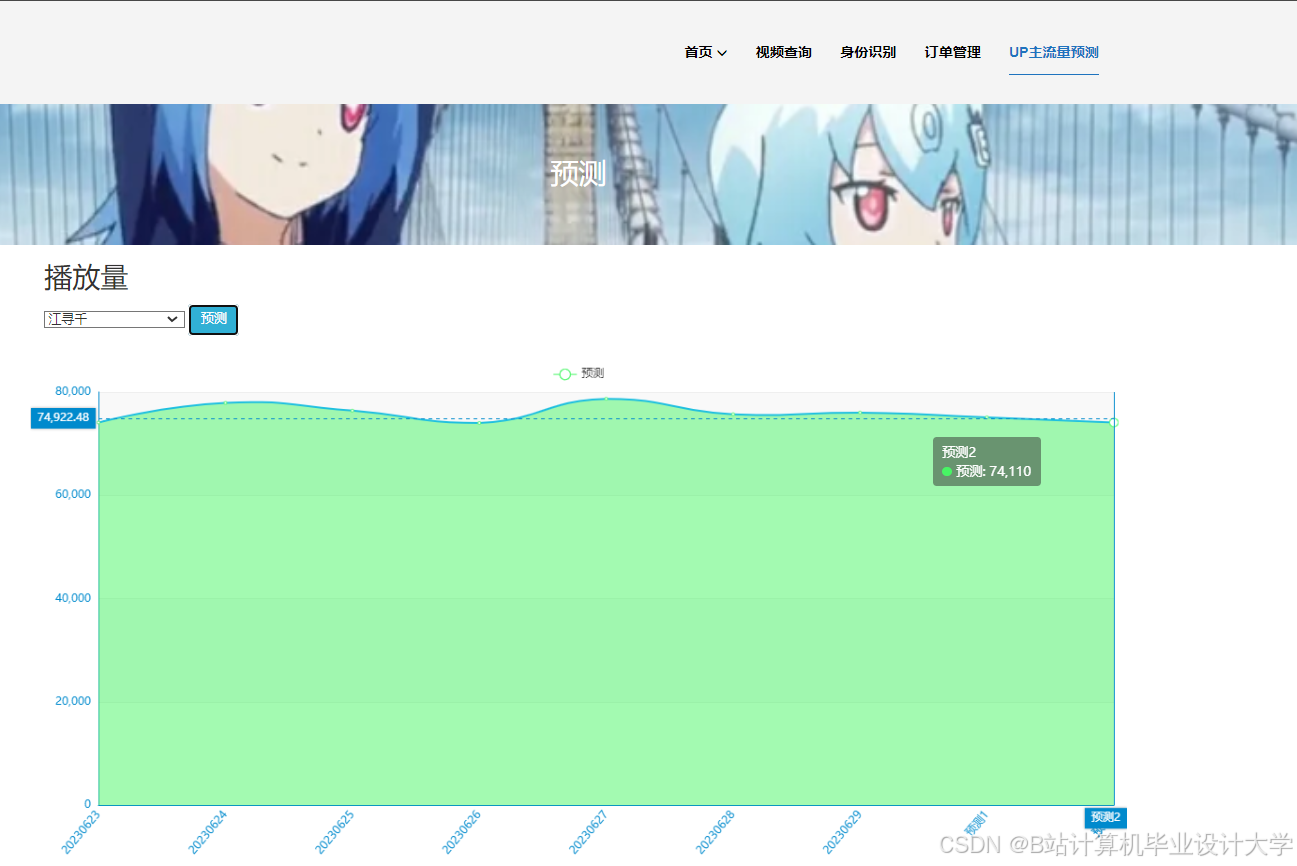
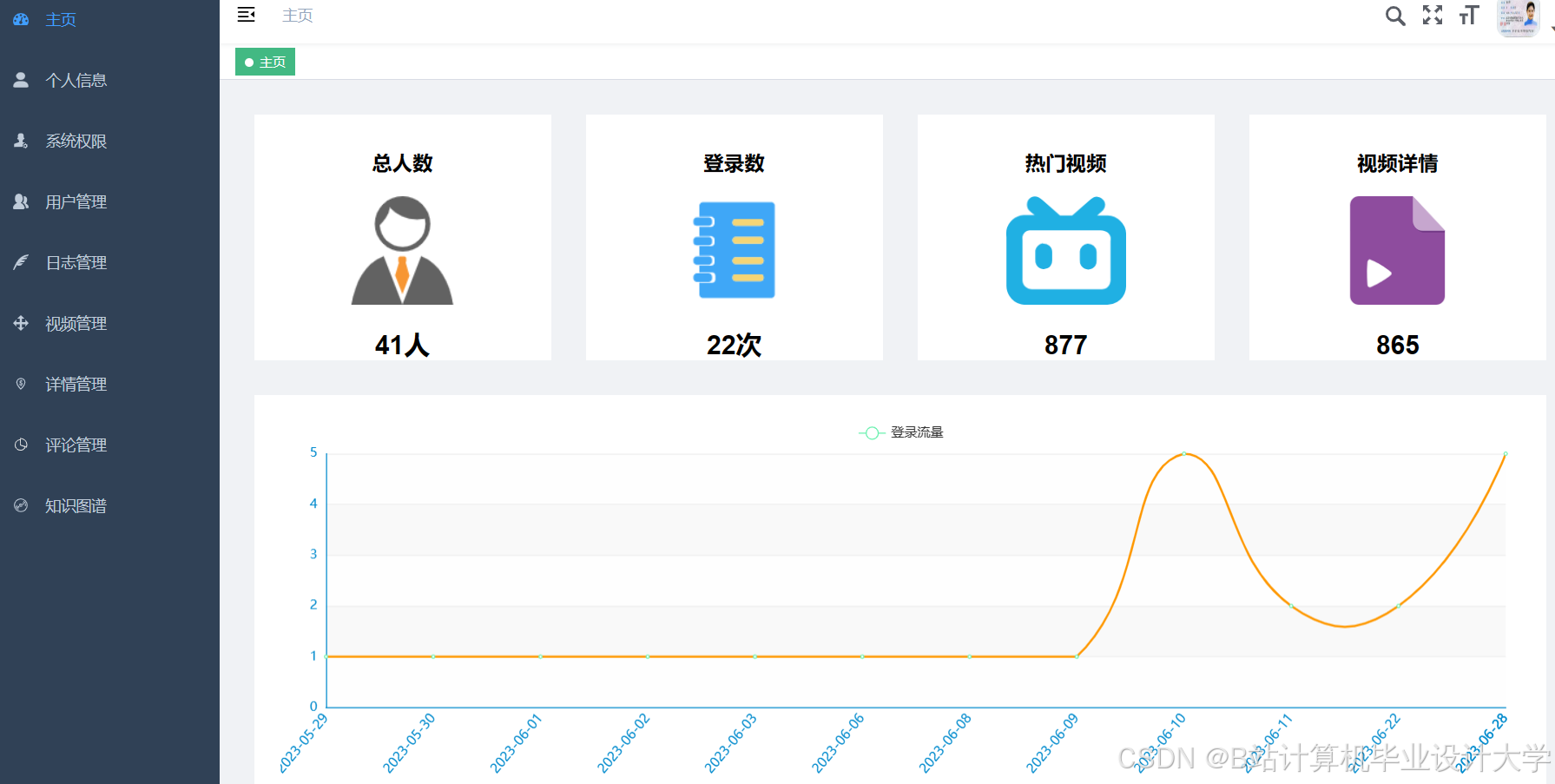
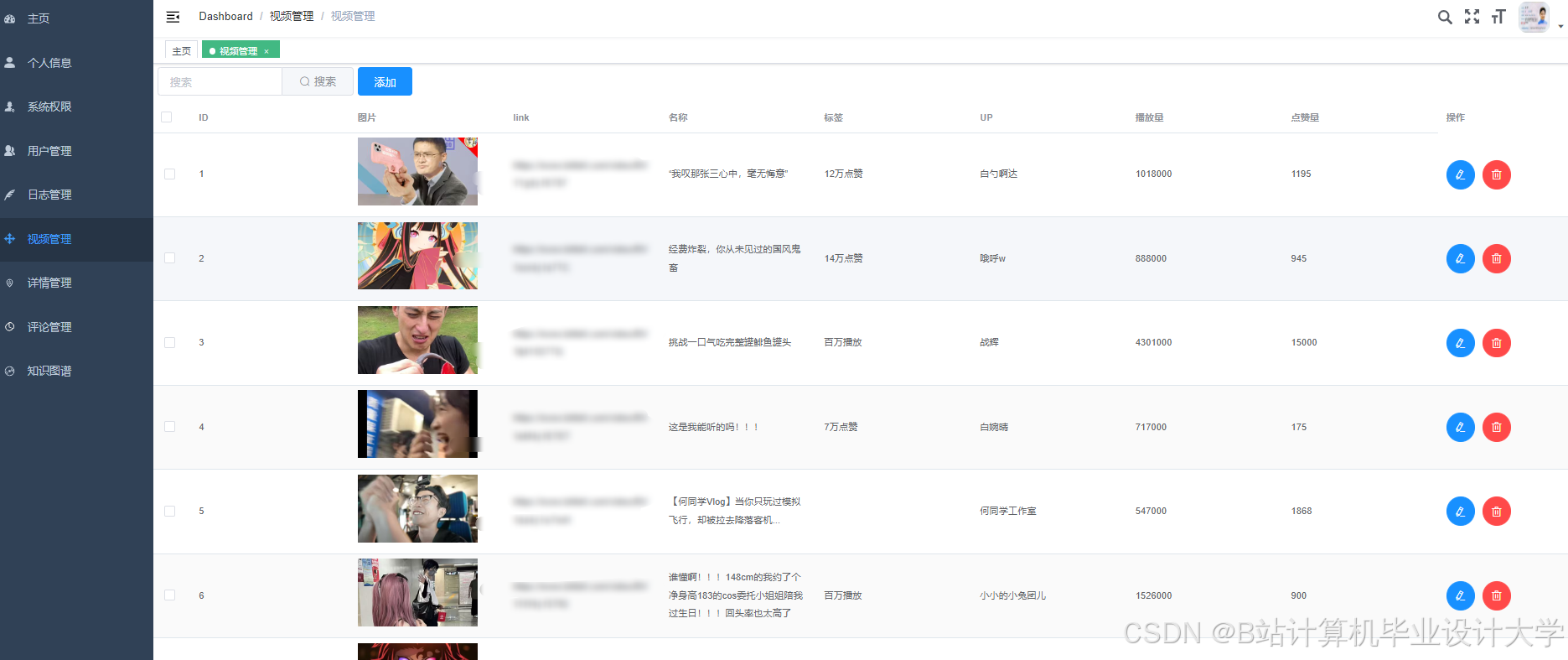
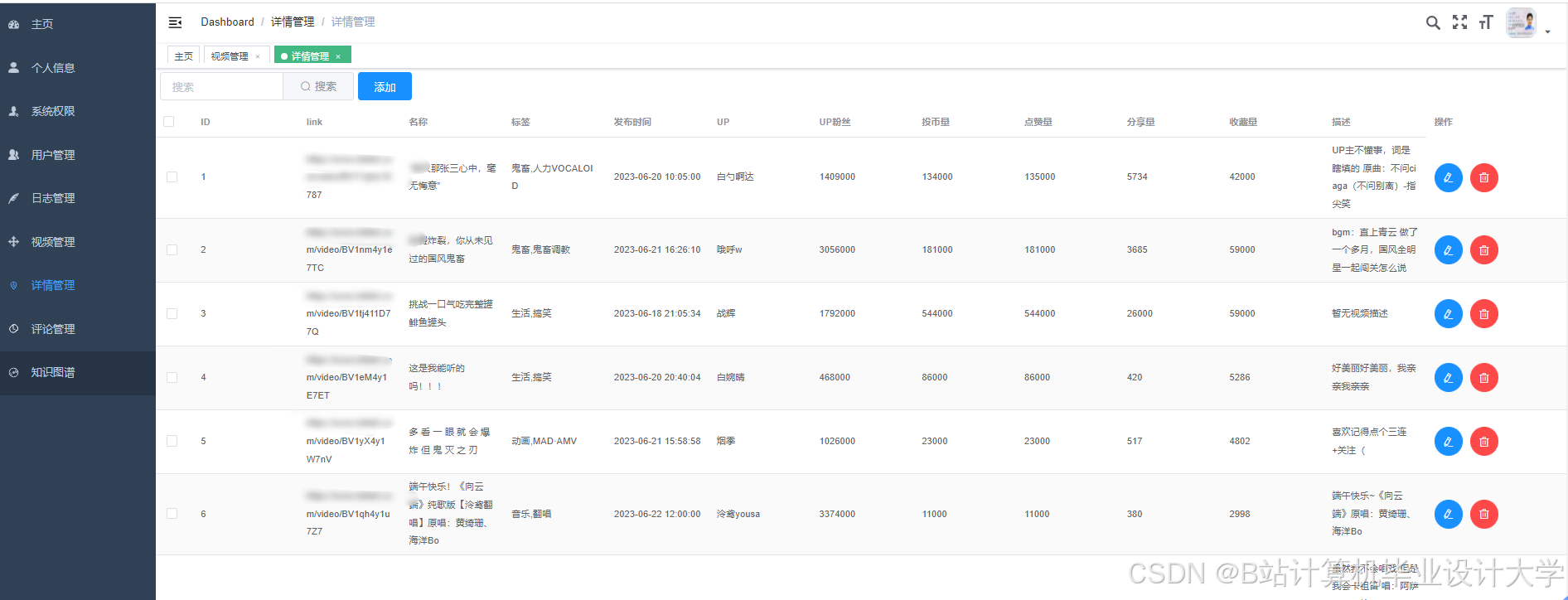
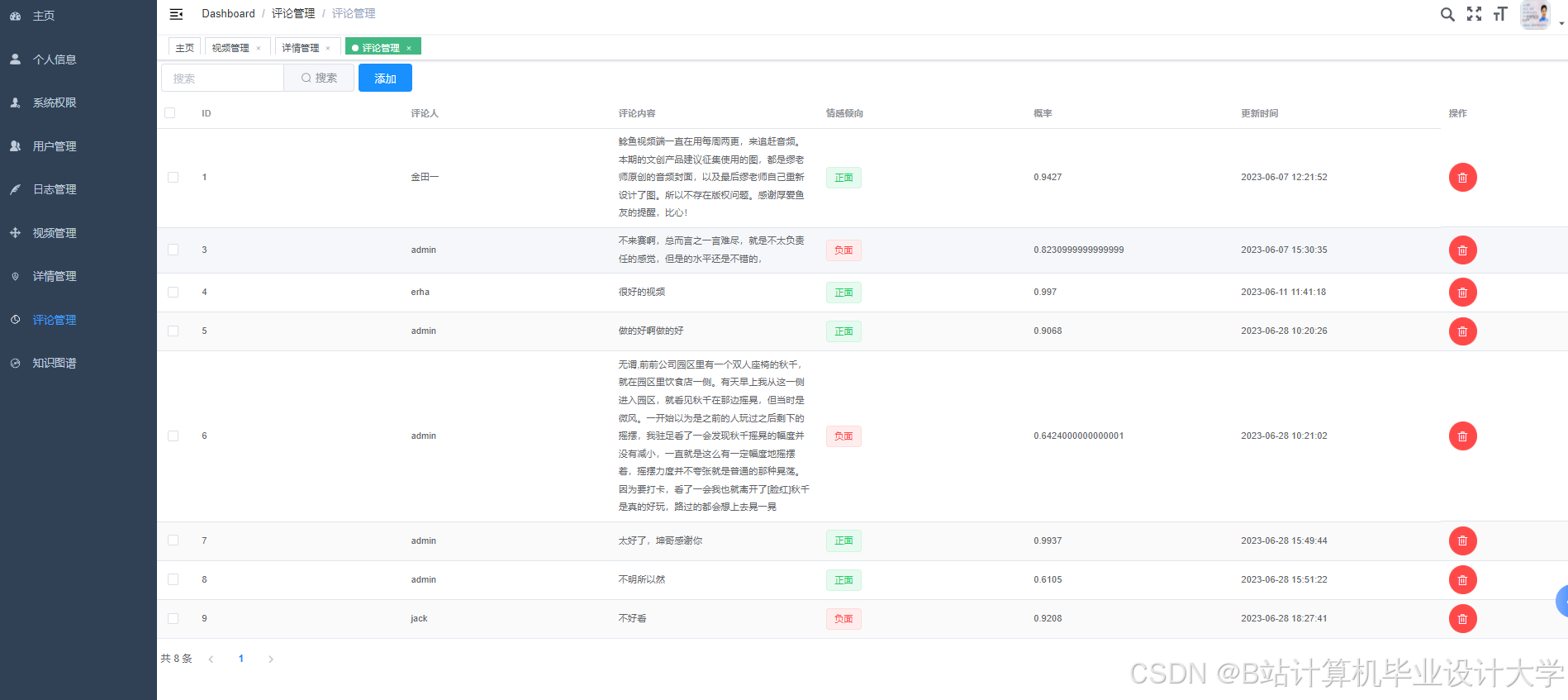
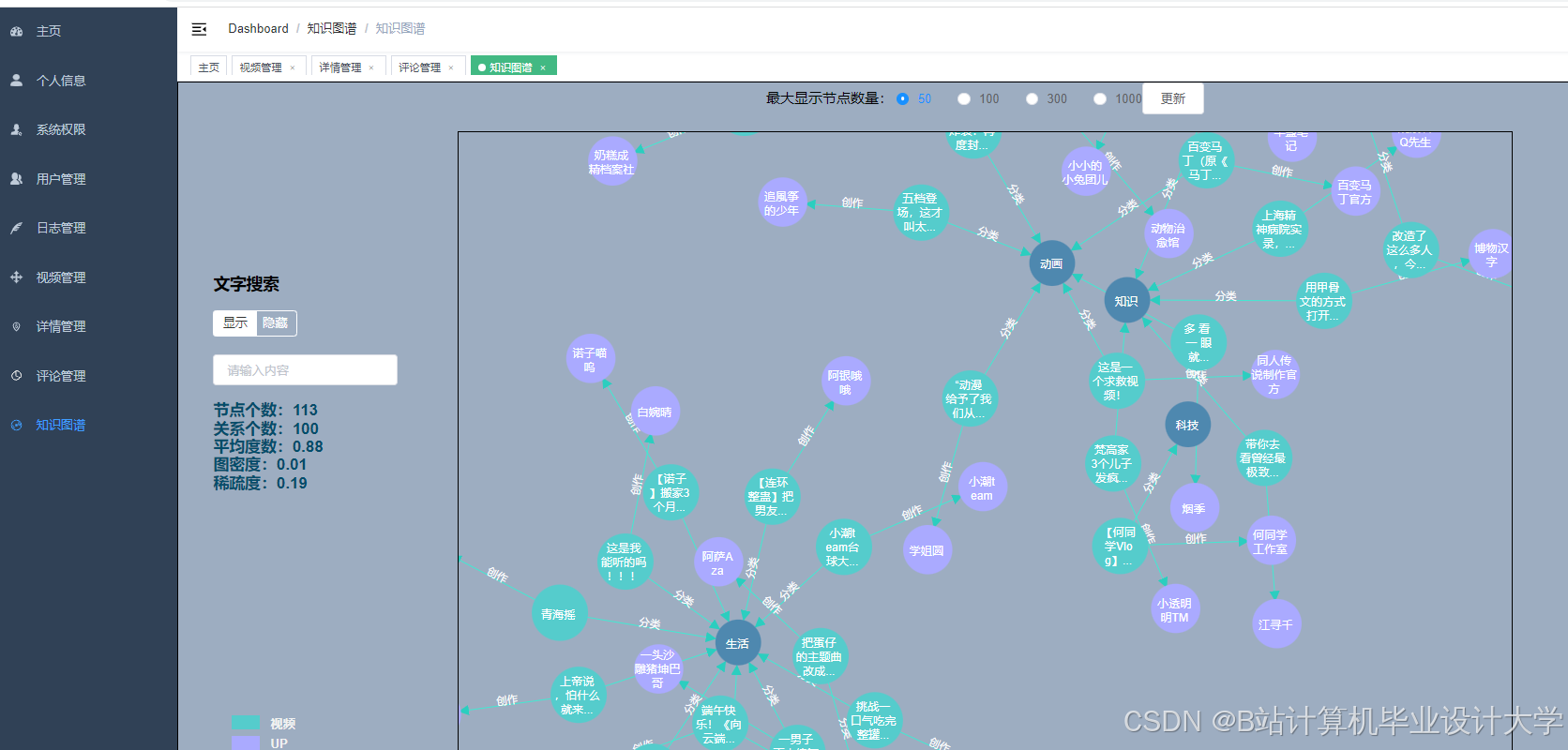
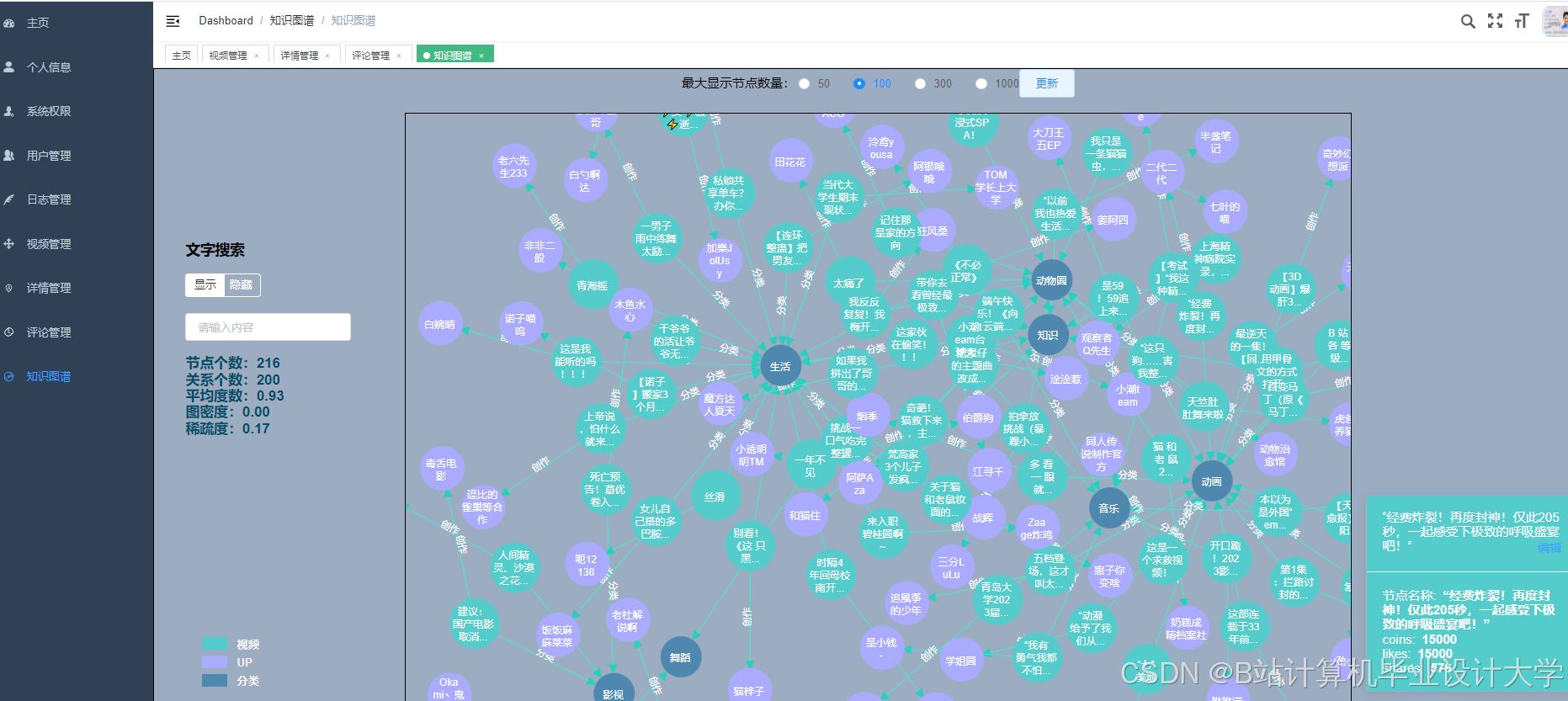
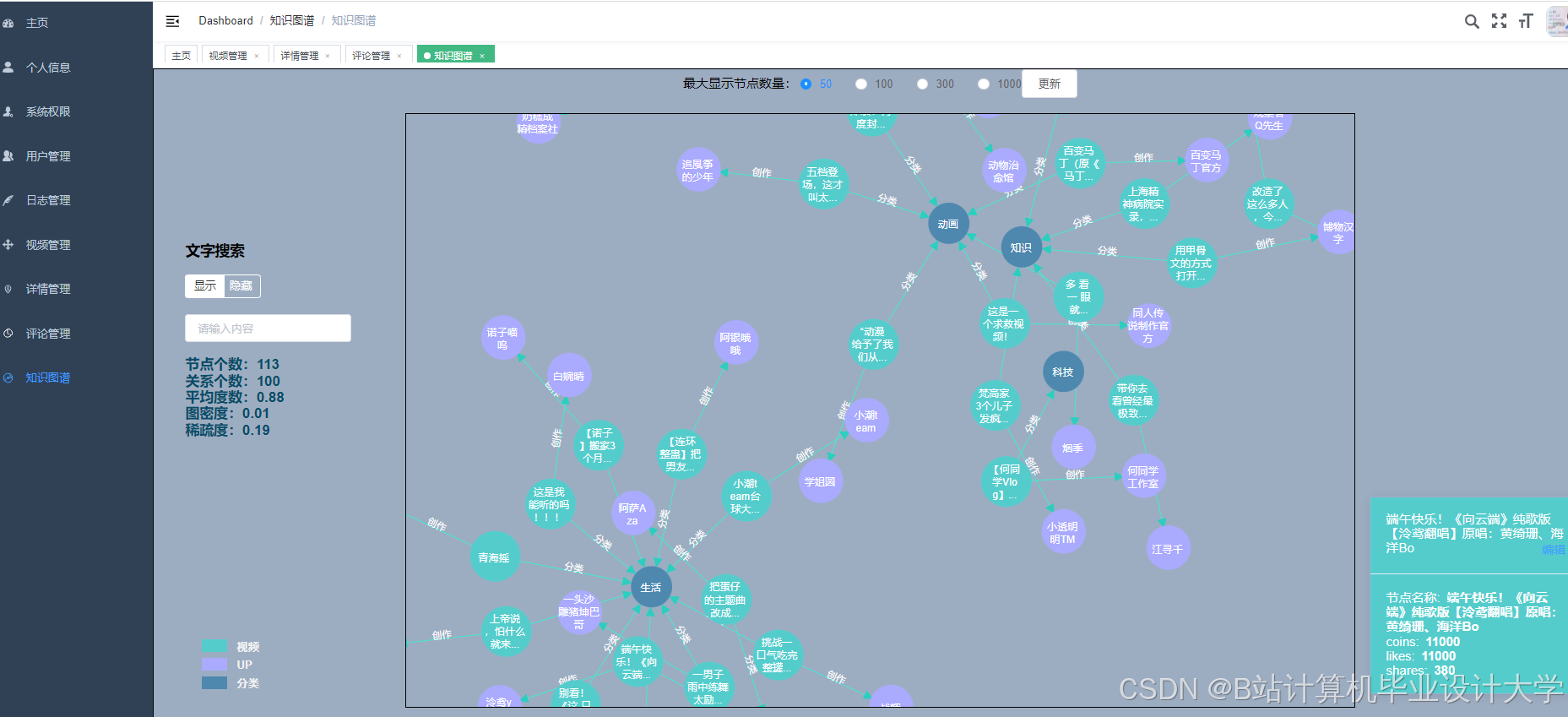
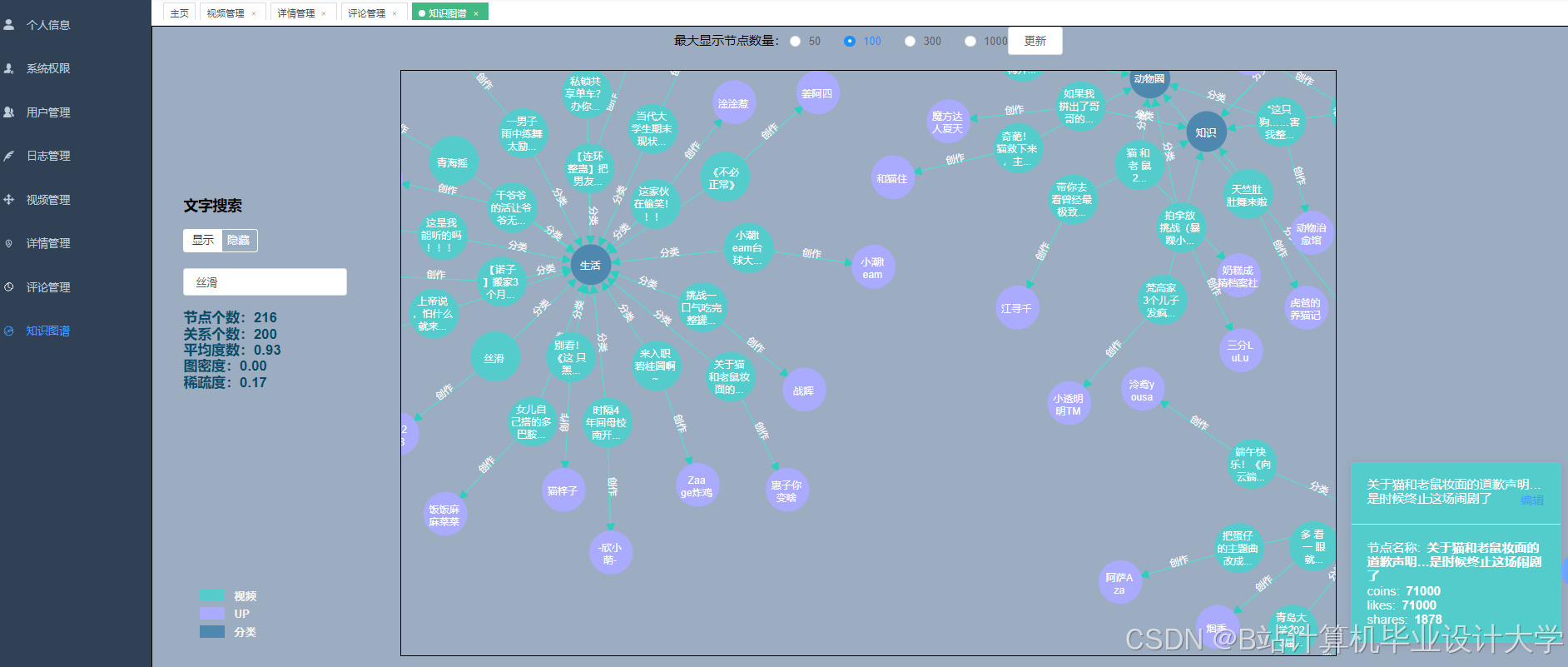
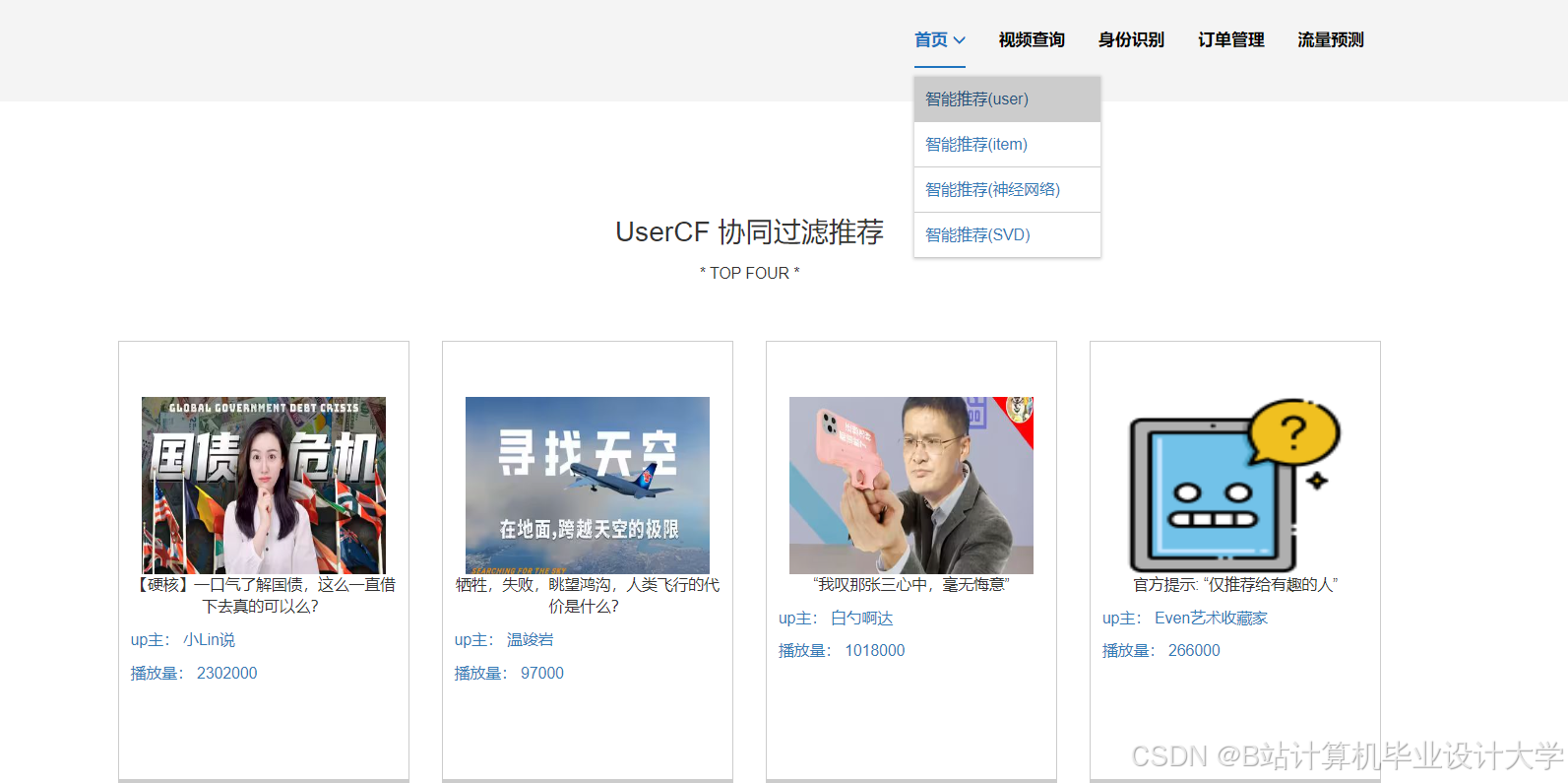
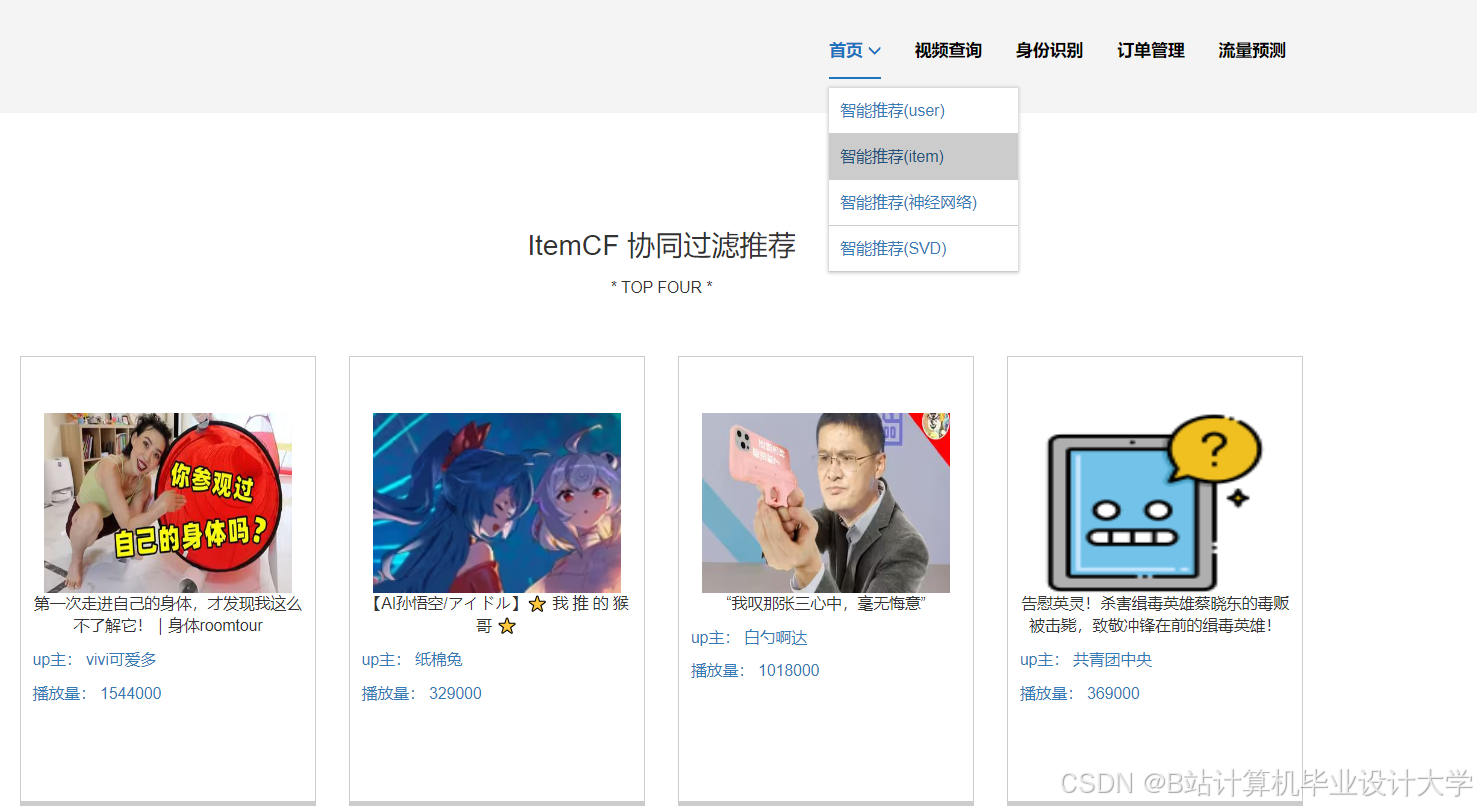
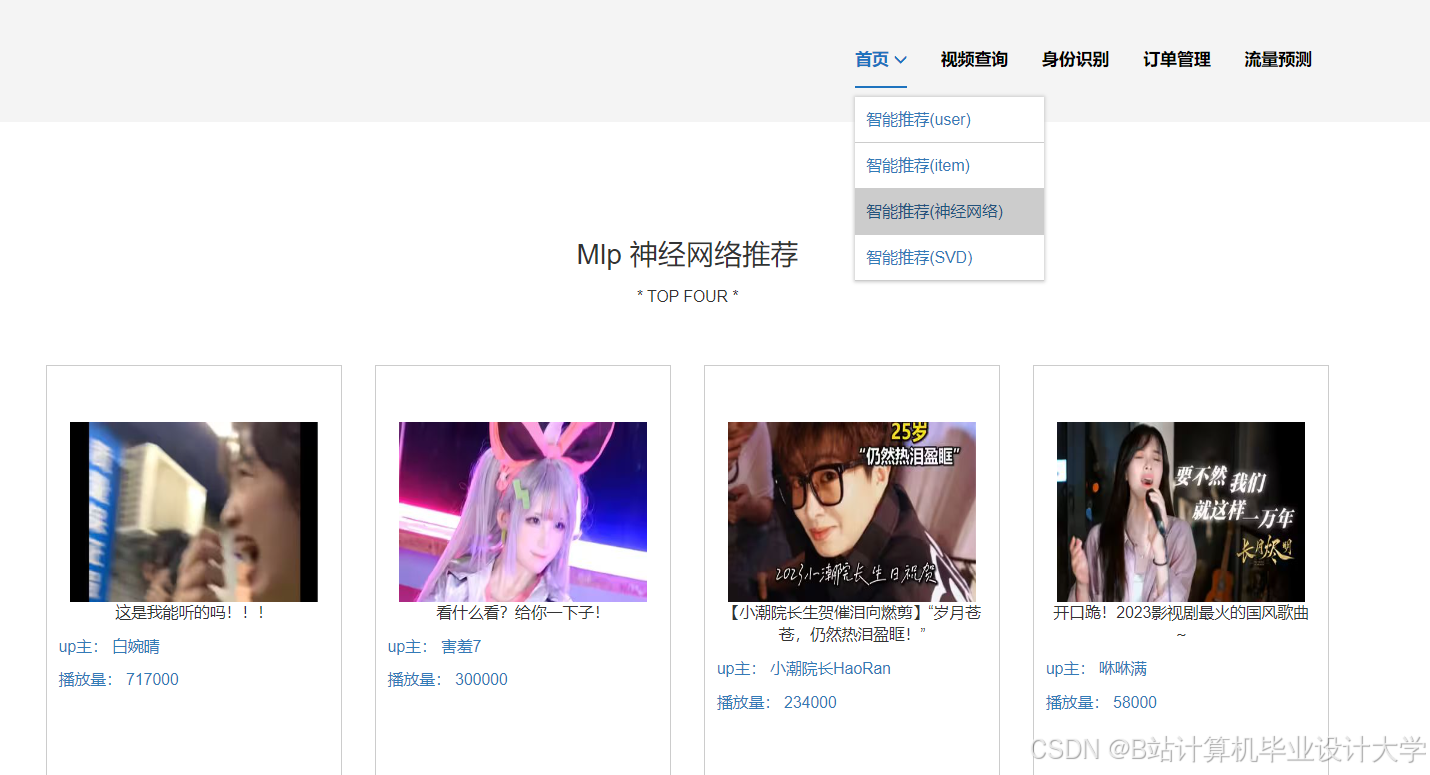
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











