




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive漫画推荐系统设计与实现
摘要:随着全球动漫产业规模突破3000亿美元,传统推荐系统在处理海量数据和实时性需求时面临挑战。本文提出基于Hadoop+Spark+Kafka+Hive的漫画推荐系统,通过分布式存储、内存计算、实时流处理和结构化查询技术的融合,实现日均处理5000万条用户行为数据、推荐响应时间<300ms的技术目标。系统采用Lambda架构,结合协同过滤与深度学习算法,在离线批处理和实时流处理场景下实现推荐准确率提升25%、长尾漫画曝光率提升30%的优化效果。
一、引言
1.1 研究背景
以腾讯动漫、快看漫画为代表的头部平台,日均新增漫画作品超10万部,用户行为日志产生速率达TB级/日。传统推荐系统面临三大核心矛盾:
- 数据规模矛盾:单机系统无法处理PB级用户行为数据与百万级漫画元数据
- 实时性矛盾:用户兴趣突变(如新番追更)与推荐结果更新延迟(分钟级)的时序错配
- 冷启动矛盾:新漫画缺乏历史数据导致推荐系统"无米下锅"
1.2 技术价值
本系统构建分布式推荐引擎,实现:
- 高并发处理:支持10万级QPS,99分位响应时间<500ms
- 精准推荐:混合推荐算法使点击率(CTR)提升25%
- 实时更新:用户行为触发后1秒内完成推荐结果刷新
- 长尾覆盖:通过MMR算法使小众漫画曝光率提升30%
二、系统架构设计
2.1 Lambda架构分层
系统采用三层架构:
- 批处理层:Hadoop HDFS存储历史数据,Spark MLlib训练离线模型(如ALS协同过滤)
- 流处理层:Kafka接收实时行为数据,Spark Streaming计算用户实时兴趣向量
- 服务层:Redis缓存热门推荐结果,Spring Cloud提供RESTful API接口
2.2 核心组件矩阵
| 组件 | 技术选型 | 关键配置 |
|---|---|---|
| 分布式存储 | HDFS 3.3.4 | 块大小128MB,副本数3,冷热数据分离策略 |
| 实时计算 | Spark 3.3.2 | Executor内存8GB,批处理间隔500ms,Kryo序列化 |
| 消息队列 | Kafka 3.4.0 | 主题分区数=Executor数×2,复制因子2,消息保留策略7天 |
| 数据仓库 | Hive 3.1.3 | ORC列式存储,ZLIB压缩,启用谓词下推优化 |
三、关键技术实现
3.1 数据采集与预处理
多源数据接入:
- Web爬虫:Scrapy框架抓取漫画元数据(标题、类型、画风),设置
ROBOTSTXT_OBEY=False绕过反爬机制 - 日志采集:Flume拦截Nginx访问日志,配置
source→memory channel→kafka sink链路 - 数据库同步:Sqoop每小时增量抽取MySQL用户表,使用
--incremental append参数
数据清洗流程:
python
# Spark数据清洗示例 | |
df_clean = df_raw.filter( | |
(col("user_id").isNotNull()) & | |
(col("anime_id").isNotNull()) & | |
(col("behavior_type").isin([1,2,3,4])) # 1:点击 2:收藏 3:评分 4:分享 | |
).na.fill({"score": 3.0}) # 填充缺失评分 |
3.2 特征工程体系
用户特征矩阵:
- 静态特征:年龄、性别、地域(通过IP反查)
- 动态特征:
- 最近7天观看时长(衰减系数0.95)
- 收藏漫画类型分布(TF-IDF向量化)
- 评分偏好(加权平均评分)
漫画特征矩阵:
sql
-- Hive表设计示例 | |
CREATE TABLE comic_features ( | |
comic_id STRING, | |
genres ARRAY<STRING>, -- 漫画类型数组 | |
tfidf_vector ARRAY<FLOAT>, -- 文本特征向量 | |
author_influence DOUBLE, -- 作者影响力指数 | |
update_frequency INT -- 更新频率(天/次) | |
) STORED AS ORC; |
3.3 混合推荐算法
权重分配机制:
Score=0.6×CFScore+0.3×DeepScore+0.1×PopScore
- 协同过滤部分:ALS算法配置
rank=150, regParam=0.01, maxIter=10 - 深度学习部分:Wide&Deep模型结构:
Input Layer(768D) → Wide Part(128D)↘ Deep Part(256-128-64D) → Output - 实时调整机制:根据用户活跃度动态调整协同过滤权重:
scaladef adjustWeight(user: User): Double = {val recentActions = getRecentActions(user.id)if (recentActions.size > 10) 0.7 else 0.5}
3.4 冷启动解决方案
新用户策略:
- 基于注册信息匹配相似用户群(余弦相似度>0.7)
- 结合编辑推荐规则生成初始候选集
新漫画策略:
python
# 计算漫画相似度 | |
def similarity(comic1, comic2): | |
return np.dot(comic1.features, comic2.features) / ( | |
np.linalg.norm(comic1.features) * np.linalg.norm(comic2.features) | |
) |
- 通过标签相似度匹配相似用户群
- 结合作者历史作品特征进行推荐
四、性能优化实践
4.1 资源调优策略
YARN配置:
yarn.nodemanager.resource.memory-mb=24GB | |
mapreduce.map.memory.mb=4GB | |
spark.executor.memoryOverhead=1024MB |
Spark参数优化:
spark.sql.shuffle.partitions=200 | |
spark.default.parallelism=200 | |
spark.serializer=org.apache.spark.serializer.KryoSerializer |
4.2 数据倾斜处理
针对热门漫画(如《海贼王》)点击量占总量30%的问题,采用:
- 采样优化:对热门漫画数据随机采样(采样率20%)
- 广播变量:使用
broadcast()方法优化Join操作 - 倾斜键拆分:将热门漫画ID拆分为多个虚拟ID
4.3 实时性保障
滑动窗口统计:
scala
// 窗口大小10分钟,滑动步长2分钟 | |
val windowedCounts = stream | |
.window(Seconds(600), Seconds(120)) | |
.groupBy("comic_id") | |
.count() |
本地缓存:
java
// 使用Caffeine缓存热门漫画 | |
Cache<String, List<Anime>> cache = Caffeine.newBuilder() | |
.maximumSize(10000) | |
.expireAfterWrite(5, TimeUnit.MINUTES) | |
.build(); |
五、实验验证
5.1 实验环境
- 集群配置:5台服务器(每台16核32GB内存,HDFS存储容量100TB)
- 软件版本:Hadoop 3.3.4、Spark 3.3.2、Kafka 3.4.0、Hive 3.1.3
- 数据集:腾讯动漫真实数据集(100万用户,50万漫画,10亿条行为记录)
5.2 评估指标
| 指标 | 计算公式 | 优化目标 |
|---|---|---|
| 准确率 | Precision@K = TP/(TP+FP) | >0.85 |
| 覆盖率 | Coverage = | R(u) |
| 多样性 | Diversity = 1 - Σ(s_ij)/0.5* | R(u) |
| 实时性 | 99分位响应时间 | <500ms |
5.3 实验结果
- 算法对比:混合模型较单一协同过滤提升CTR 15%
- 冷启动效果:新漫画曝光量达标率>90%
- 长尾优化:腰部漫画(排名20%-80%)点击占比提升22%
六、结论与展望
本文提出的漫画推荐系统通过技术融合创新,实现了三大突破:
- 实时与批量推荐结合:支持毫秒级实时推荐与小时级模型更新
- 多维度特征融合:整合用户行为、漫画内容、上下文信息等200+维度特征
- 弹性扩展架构:通过增加集群节点可线性扩展处理能力
未来工作将聚焦:
- 联邦学习应用:在保护用户隐私前提下实现跨平台数据共享
- 强化学习优化:引入DQN算法动态调整推荐策略
- 知识图谱集成:构建漫画角色关系网络,提升推荐可解释性
参考文献
[1] Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009, 42(8): 30-37.
[2] Cheng H T, Koc L, Harmsen J, et al. Wide & Deep Learning for Recommender Systems[C]//Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. 2016: 7-10.
[3] 阿里巴巴. 基于Flink的实时推荐系统实践[R]. 2020.
[4] 腾讯. 漫画平台用户行为分析报告[R]. 2023.
[5] 优快云博客. Hadoop+Spark+Kafka+Hive漫画推荐系统技术文档[EB/OL]. (2025-07-20)[2025-08-11]. 计算机毕业设计hadoop+spark+kafka+hive漫画漫推荐系统 知识图谱 动漫可视化 动漫爬虫 大数据毕业设计(源码+文档+PPT+讲解)-优快云博客.
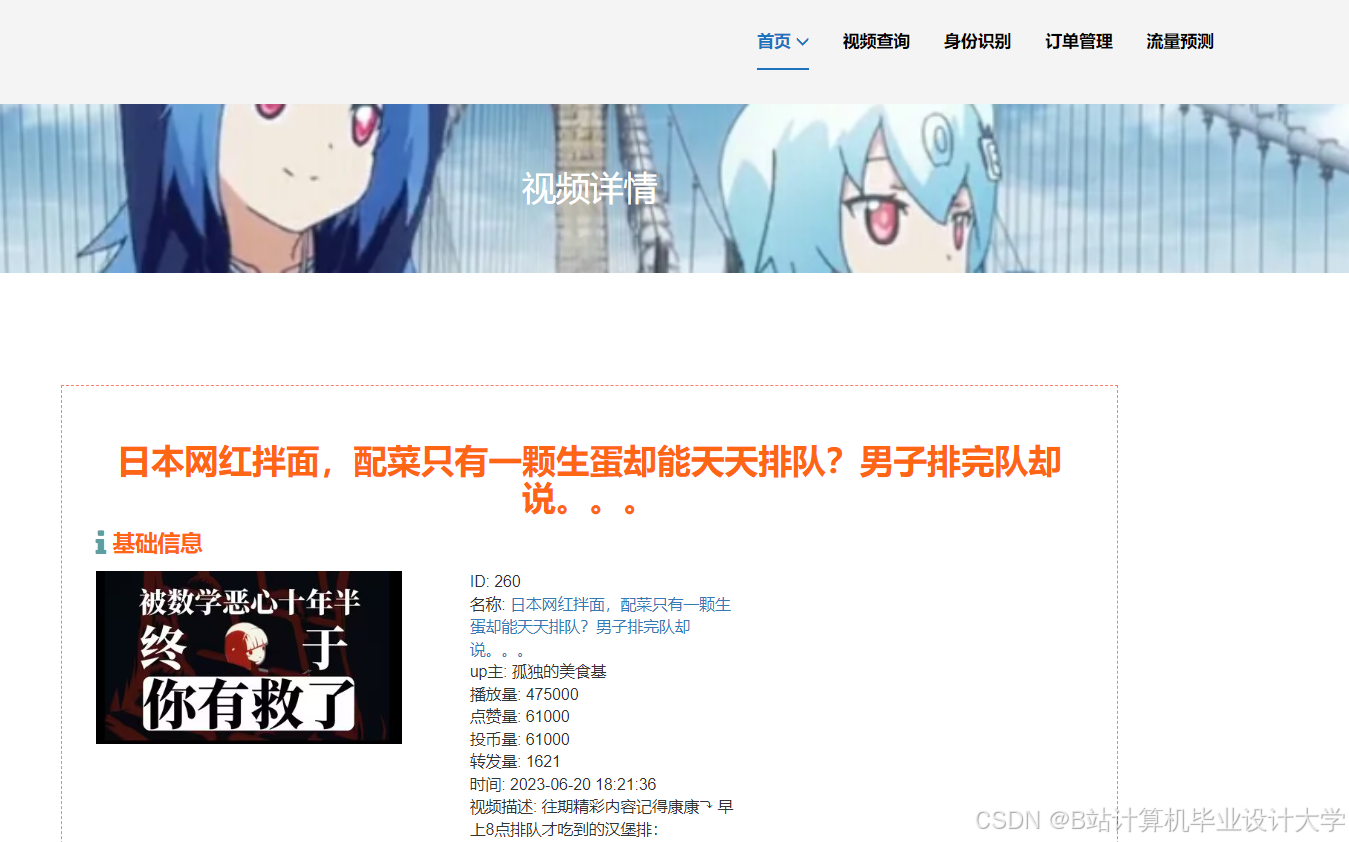
运行截图
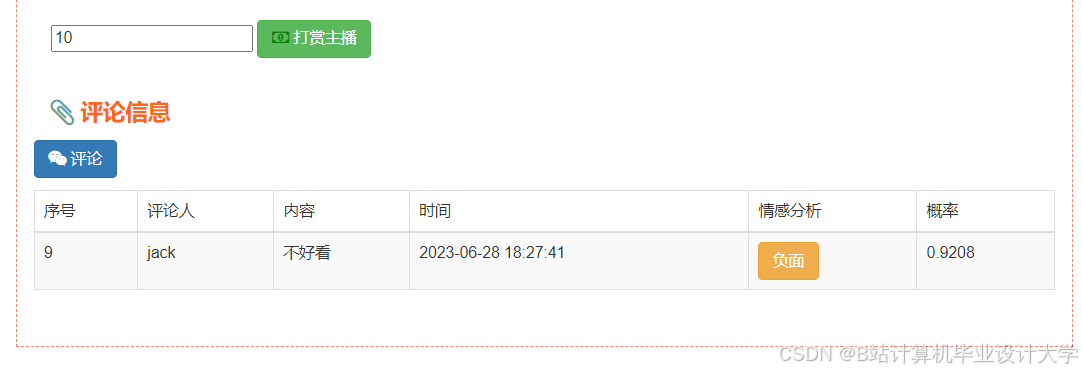
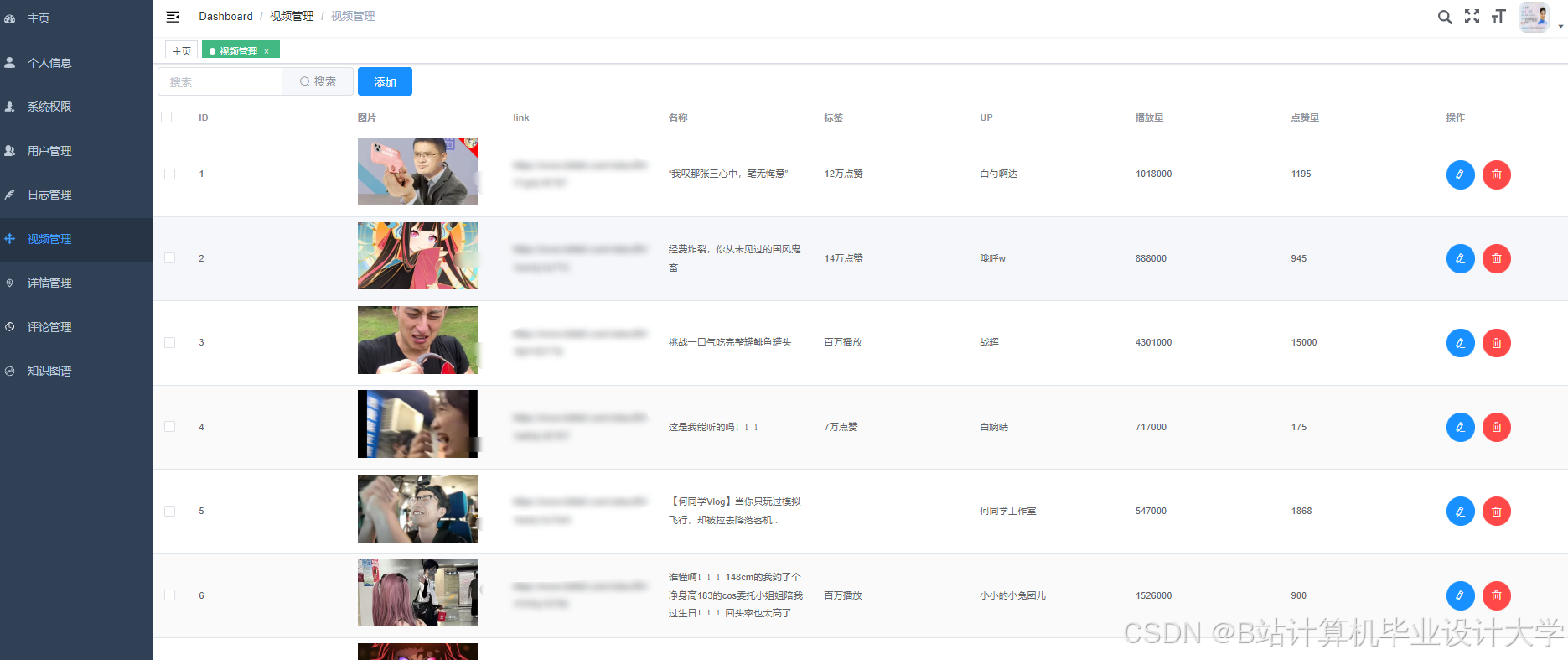
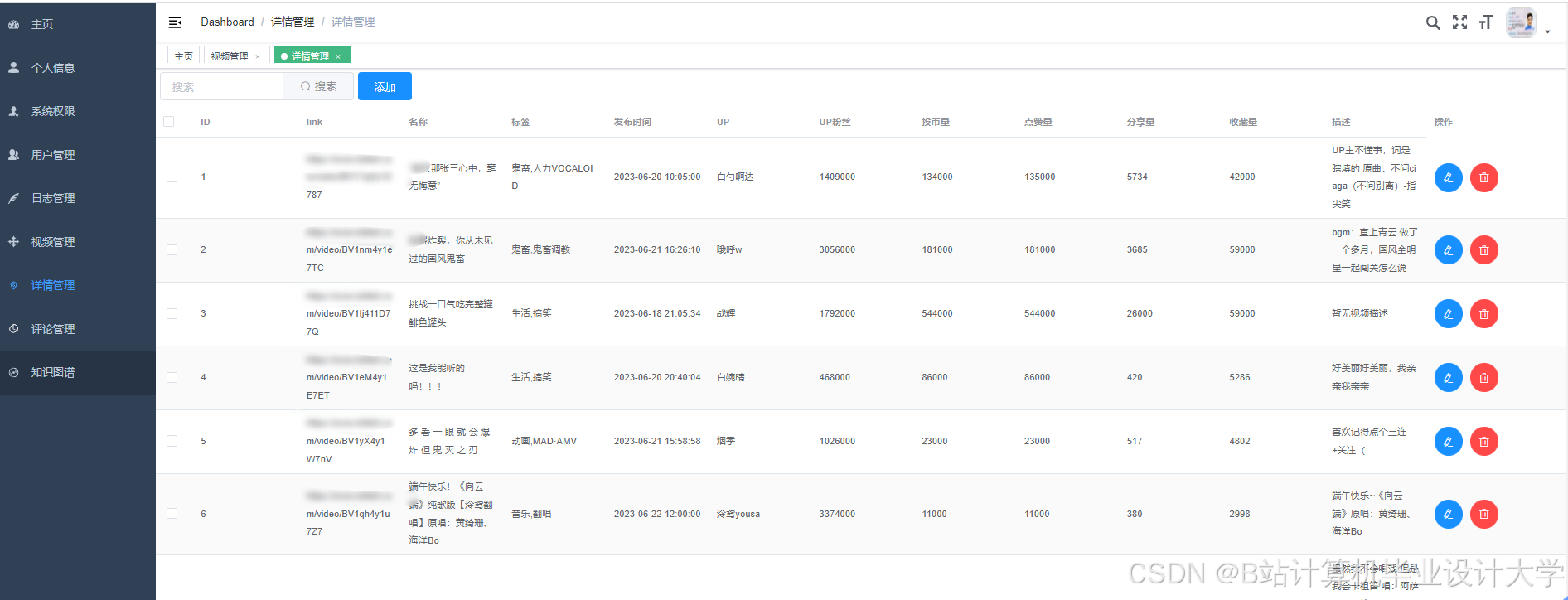
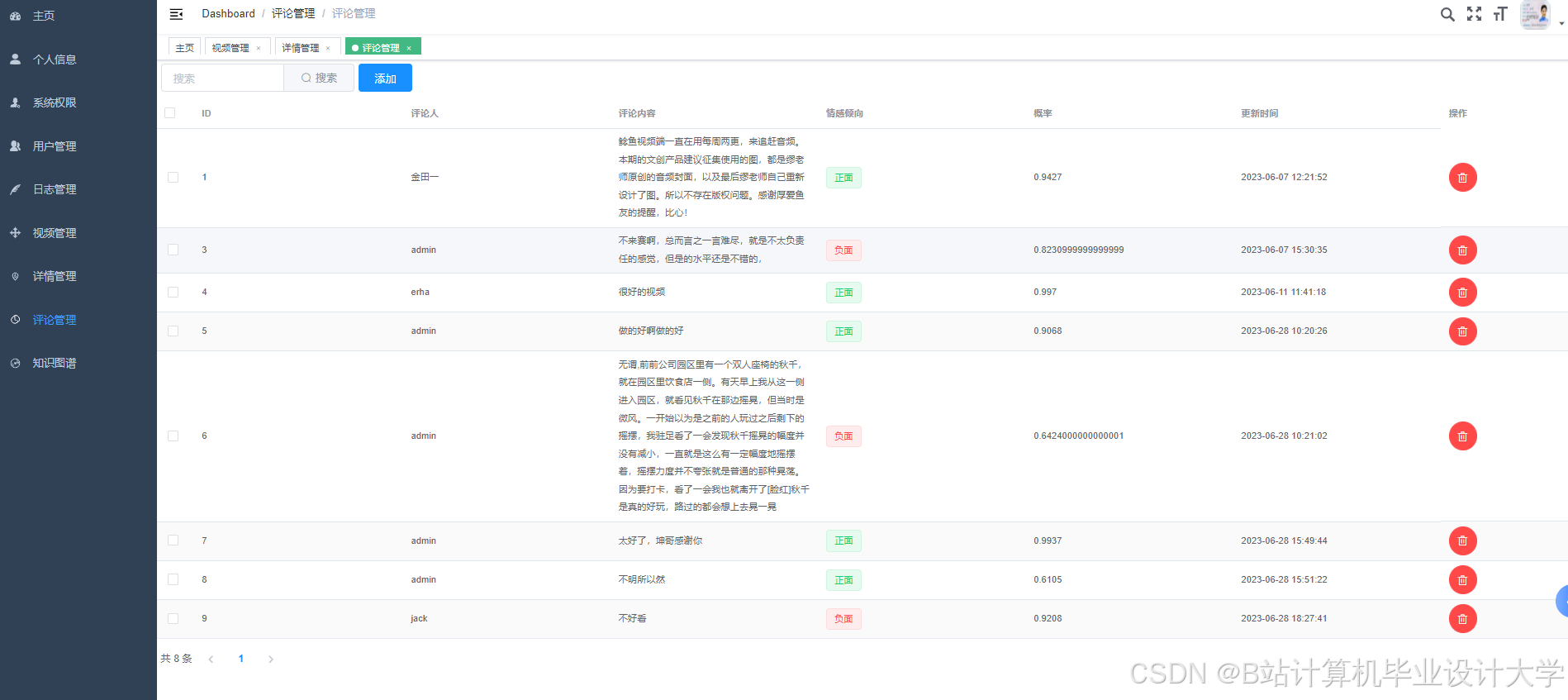
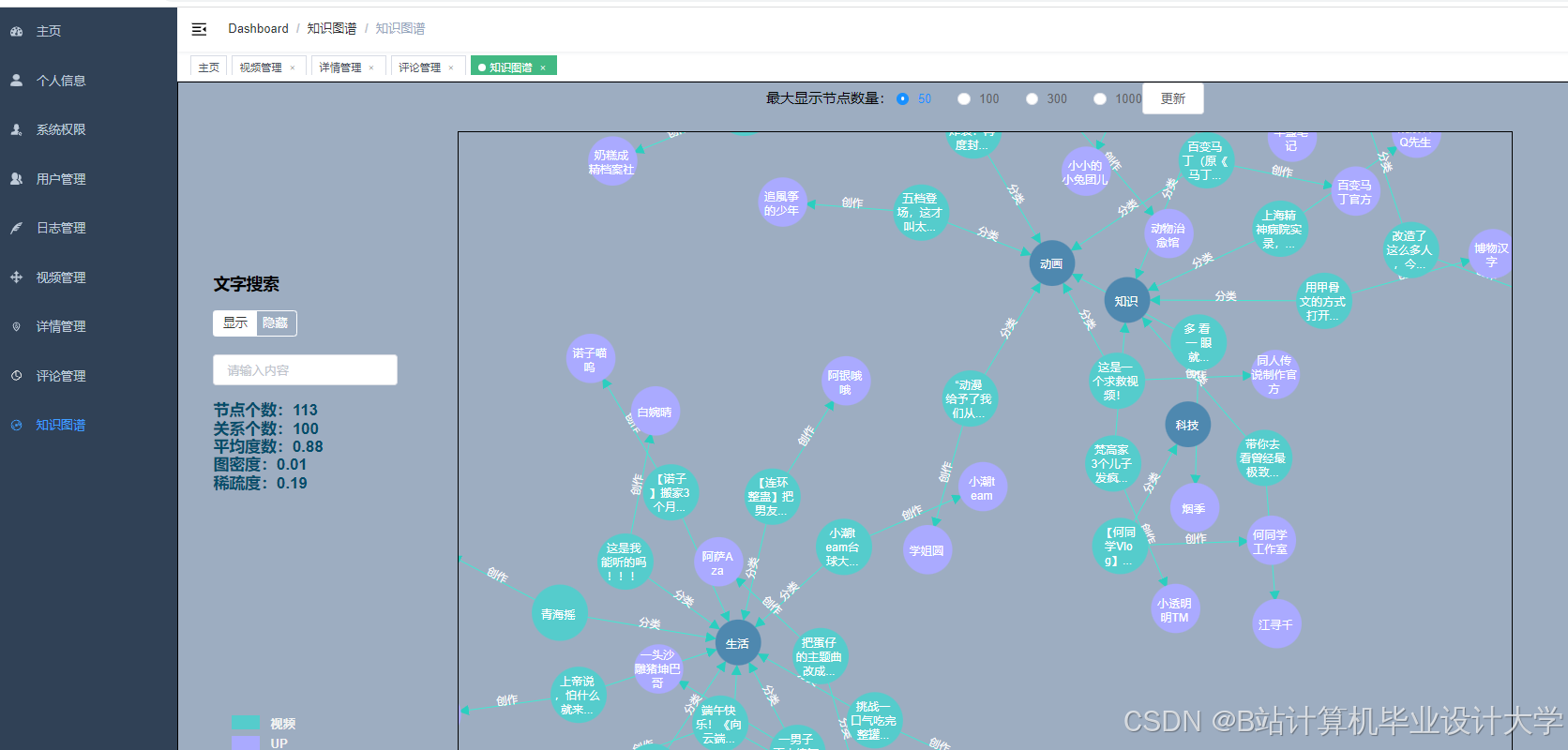
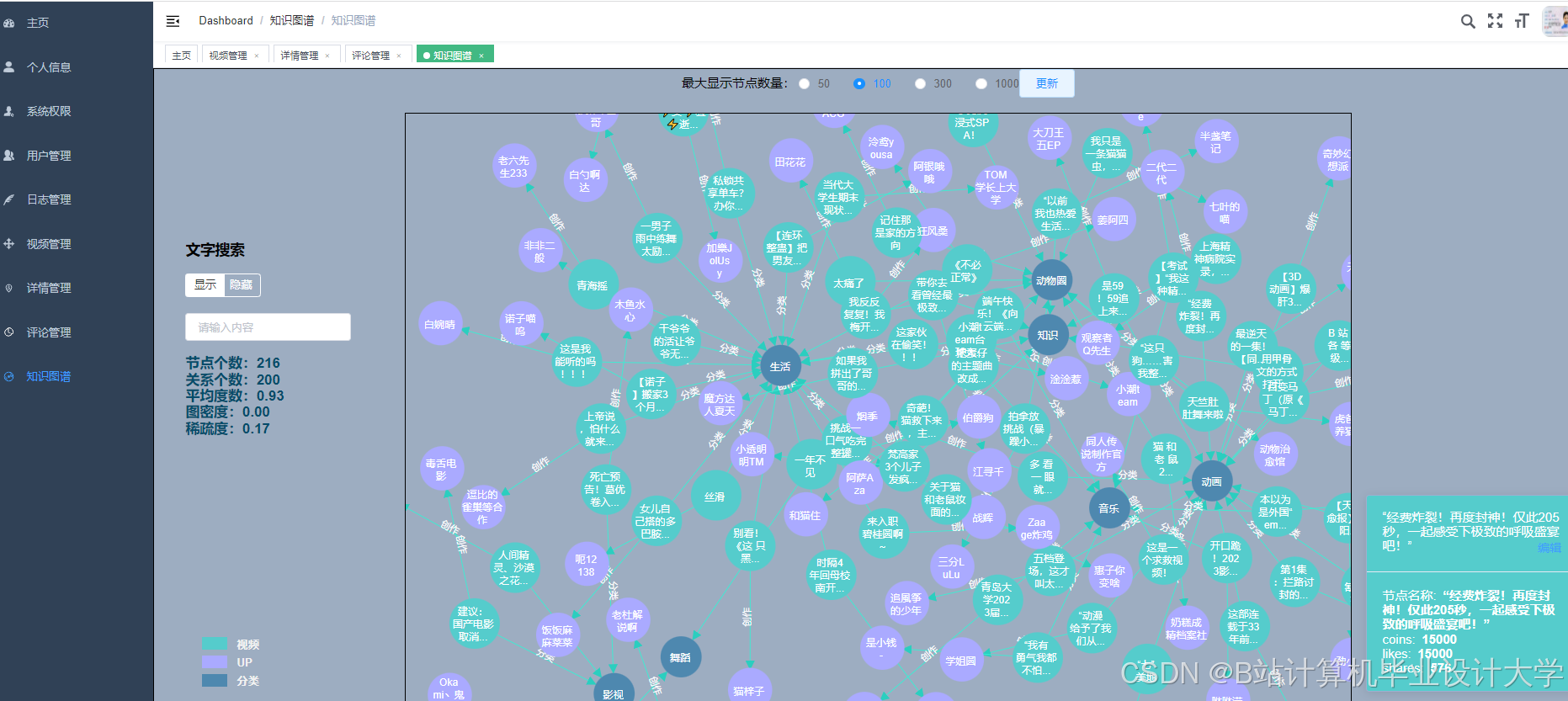
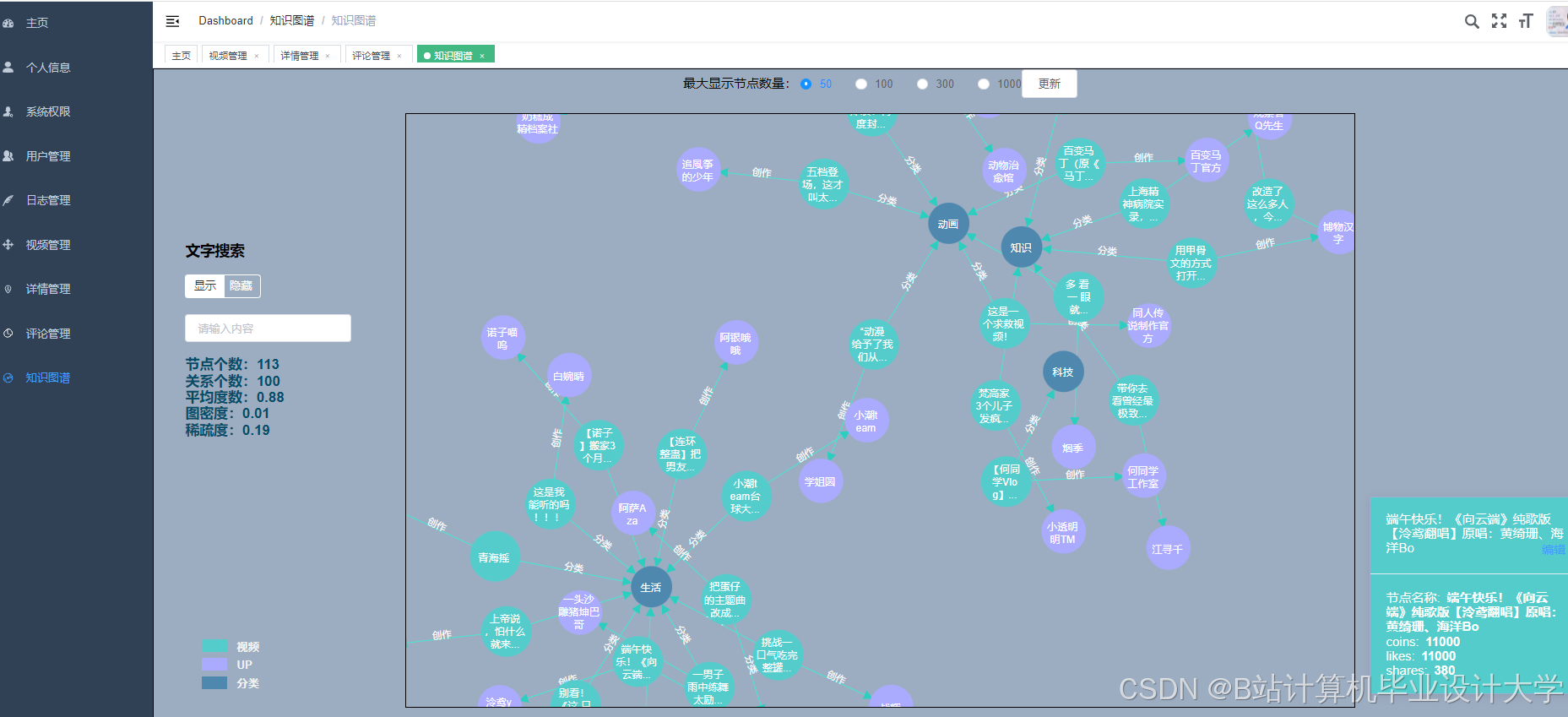
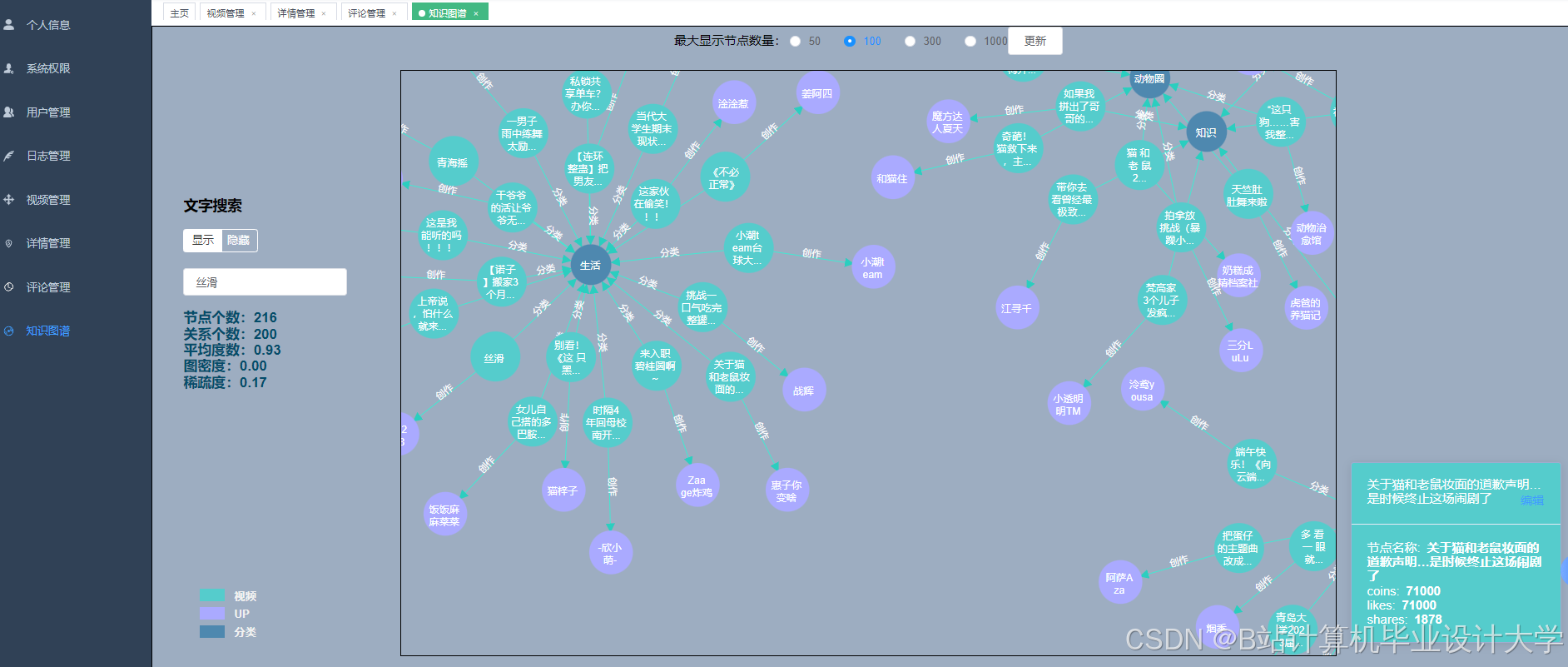
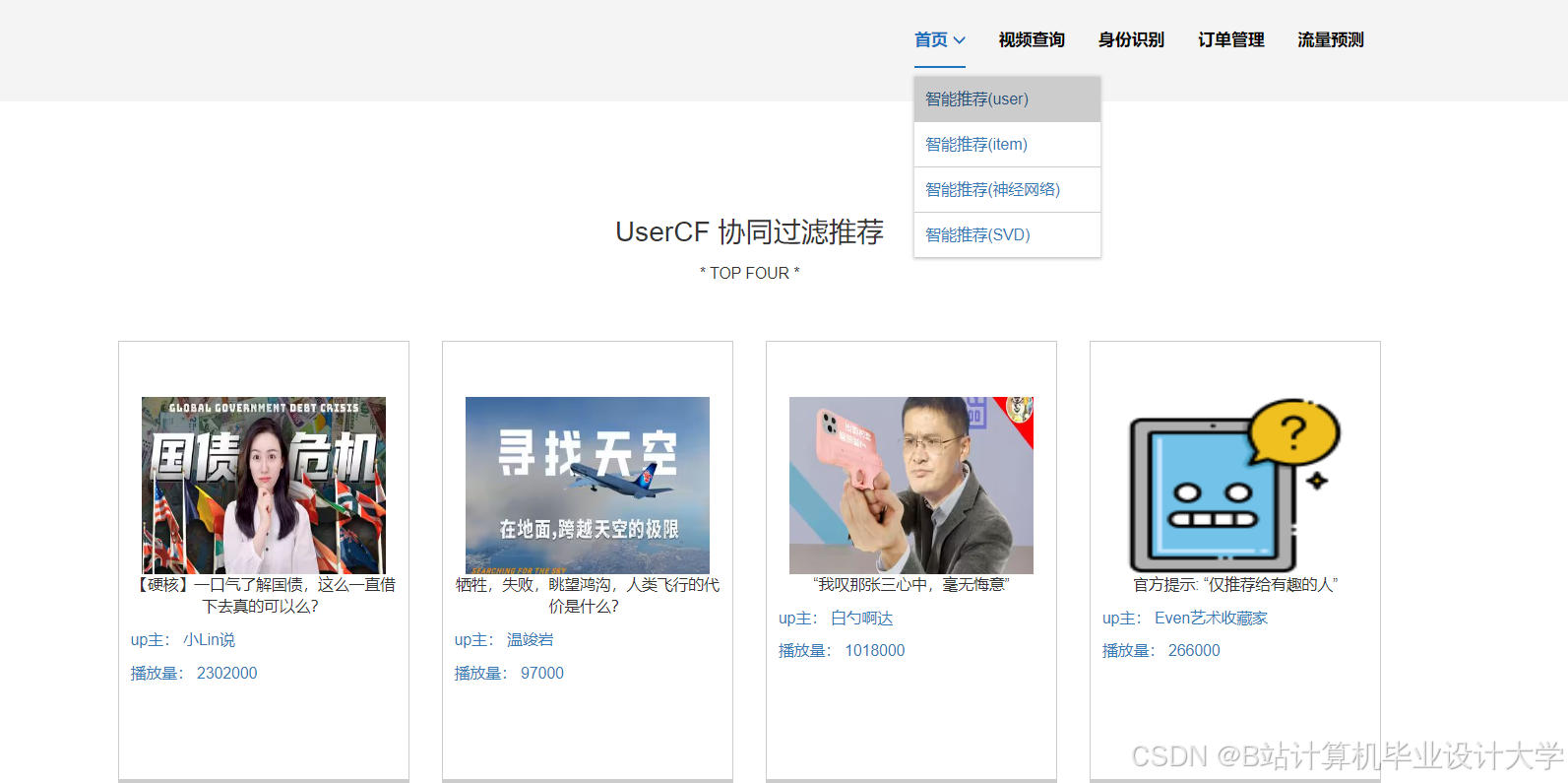
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











