




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Hive+PySpark小说推荐系统技术说明
一、系统概述
本系统基于Hadoop分布式存储、Hive数据仓库与PySpark内存计算框架,构建面向海量小说数据的个性化推荐平台。系统通过整合用户行为数据、小说文本特征与社交关系,实现PB级数据的高效处理与实时推荐,核心指标包括推荐准确率(Recall@20≥38.5%)、冷启动覆盖率(≥82%)及响应延迟(≤180ms)。
二、技术架构与组件选型
2.1 分层架构设计
系统采用五层架构,各层技术选型与功能如下:
| 层级 | 技术组件 | 核心功能 |
|---|---|---|
| 数据采集层 | Flume、Scrapy、Kafka | 实时收集用户行为日志(点击/阅读时长)、爬取跨平台书评数据,构建低延迟数据管道 |
| 存储层 | HDFS、Hive、Redis | HDFS存储原始日志,Hive构建结构化数据仓库,Redis缓存高频推荐结果 |
| 计算层 | PySpark、Spark Streaming | PySpark处理特征提取与模型训练,Spark Streaming实现实时行为流处理 |
| 推荐引擎层 | Spark MLlib、GraphX | 实现ALS协同过滤、Wide & Deep混合模型与GraphSAGE图嵌入算法 |
| 应用层 | Flask、Echarts | 提供RESTful API接口,支持Web端推荐结果可视化展示 |
2.2 组件交互流程
- 数据采集:用户行为日志通过Flume写入Kafka主题,Scrapy爬取的跨平台书评数据经清洗后存入HDFS。
- 数据存储:Hive将HDFS数据映射为结构化表,支持SQL查询(如按日期分区统计用户行为)。
- 特征计算:PySpark从Hive读取数据,提取用户画像(年龄/性别)、小说语义特征(Word2Vec向量化)与社交关系(Graph Embedding)。
- 模型训练:Spark MLlib训练ALS协同过滤与Wide & Deep模型,结果保存至HDFS供推荐引擎调用。
- 实时推荐:Spark Streaming消费Kafka实时行为流,触发模型更新并生成推荐列表,结果写入Redis缓存。
三、核心模块技术实现
3.1 分布式存储优化
3.1.1 HDFS分区策略
按日期(dt=20240101)和小说类别(category=fantasy)分区,减少全表扫描。示例Hive表定义:
sql
CREATE EXTERNAL TABLE user_behavior ( | |
user_id STRING, book_id STRING, | |
action_type STRING, timestamp BIGINT | |
) PARTITIONED BY (dt STRING, category STRING) | |
STORED AS ORC; |
3.1.2 数据压缩与序列化
- Snappy压缩:原始日志压缩率达60%,读取速度提升30%。
- Parquet列式存储:小说元数据表采用Parquet格式,支持谓词下推优化查询性能。
3.2 PySpark特征工程
3.2.1 用户画像构建
统计用户阅读时长、偏好类别(TF-IDF向量化):
python
from pyspark.ml.feature import HashingTF, IDF | |
# 示例:统计用户阅读过的类别并生成TF-IDF特征 | |
df_categories = spark.sql("SELECT user_id, collect_list(category) as categories FROM user_behavior GROUP BY user_id") | |
hashing_tf = HashingTF(inputCol="categories", outputCol="raw_features", numFeatures=1000) | |
idf = IDF(inputCol="raw_features", outputCol="features") | |
pipeline = Pipeline(stages=[hashing_tf, idf]) | |
model = pipeline.fit(df_categories) | |
df_features = model.transform(df_categories) |
3.2.2 小说语义特征提取
使用Word2Vec生成小说简介的语义向量(维度=128):
python
from pyspark.ml.feature import Word2Vec | |
# 示例:训练小说简介的Word2Vec模型 | |
df_descriptions = spark.sql("SELECT book_id, explode(split(description, ' ')) as word FROM book_metadata") | |
word2vec = Word2Vec(vectorSize=128, minCount=5, inputCol="word", outputCol="embeddings") | |
model = word2vec.fit(df_descriptions) | |
df_book_embeddings = model.transform(df_descriptions.groupBy("book_id").agg(collect_list("embeddings").alias("embeddings_list"))) |
3.2.3 社交关系图嵌入
通过GraphSAGE提取用户关注关系的低维表示(维度=64):
python
from pyspark.graphframes import GraphFrame | |
# 示例:构建用户关注关系图并应用GraphSAGE | |
vertices = spark.createDataFrame([(1, "User1"), (2, "User2")], ["id", "type"]) | |
edges = spark.createDataFrame([(1, 2, "follows")], ["src", "dst", "relation"]) | |
graph = GraphFrame(vertices, edges) | |
# 实际应用中需集成Deep Graph Library (DGL)或PyTorch Geometric实现GraphSAGE |
3.3 混合推荐算法
3.3.1 ALS协同过滤
分解用户-小说交互矩阵为用户特征向量与小说特征向量:
python
from pyspark.ml.recommendation import ALS | |
# 示例:训练ALS模型 | |
df_ratings = spark.sql("SELECT user_id, book_id, if(action_type='click', 1, 0) as rating FROM user_behavior") | |
als = ALS(maxIter=10, regParam=0.01, rank=50, coldStartStrategy="drop") | |
model = als.fit(df_ratings) | |
df_recommendations = model.recommendForAllUsers(20) # 为每个用户生成Top 20推荐 |
3.3.2 Wide & Deep模型
Wide部分处理用户历史行为特征,Deep部分通过DNN网络学习用户画像与小说特征的交叉信息:
python
from pyspark.ml.classification import LogisticRegression | |
from pyspark.ml.feature import VectorAssembler | |
# 示例:构建Wide & Deep特征向量 | |
df_wide = spark.sql(""" | |
SELECT | |
user_id, | |
max(if(category='fantasy', 1, 0)) as has_read_fantasy, -- Wide特征:是否读过玄幻 | |
array_join(collect_list(embeddings), ',') as deep_features -- Deep特征:小说嵌入拼接 | |
FROM user_behavior JOIN book_metadata ON user_behavior.book_id = book_metadata.book_id | |
GROUP BY user_id | |
""") | |
assembler = VectorAssembler(inputCols=["has_read_fantasy", "deep_features"], outputCol="features") | |
lr = LogisticRegression(featuresCol="features", labelCol="clicked") # 实际应用中需替换为DNN模型 |
3.3.3 加权融合策略
协同过滤与内容推荐结果按0.7:0.3权重融合,测试集准确率最高:
python
# 示例:融合ALS与内容推荐结果 | |
df_als_rec = model.recommendForAllUsers(20) | |
df_content_rec = spark.sql("SELECT user_id, book_id, score as content_score FROM content_based_recommendations") | |
df_fused = df_als_rec.join(df_content_rec, "user_id") \ | |
.withColumn("final_score", col("prediction") * 0.7 + col("content_score") * 0.3) \ | |
.orderBy("user_id", "final_score", ascending=False) |
3.4 实时推荐优化
3.4.1 Spark Streaming窗口统计
消费Kafka消息,窗口统计用户近5分钟行为:
python
from pyspark.streaming import StreamingContext | |
from pyspark.streaming.kafka import KafkaUtils | |
# 示例:统计用户近5分钟点击的小说类别 | |
ssc = StreamingContext(spark.sparkContext, batchDuration=300) # 5分钟窗口 | |
kafka_stream = KafkaUtils.createDirectStream(ssc, ["user_behavior"], {"metadata.broker.list": "kafka:9092"}) | |
lines = kafka_stream.map(lambda x: x[1]) | |
user_actions = lines.map(lambda line: (line.split(",")[0], line.split(",")[2])) # (user_id, category) | |
windowed_counts = user_actions.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, windowDuration=300, slideDuration=60) | |
windowed_counts.pprint() | |
ssc.start() | |
ssc.awaitTermination() |
3.4.2 Redis缓存策略
缓存高频推荐结果(如“用户A的Top 20推荐”),设置TTL=1小时自动更新:
python
import redis | |
# 示例:将推荐结果存入Redis | |
r = redis.Redis(host='redis', port=6379, db=0) | |
user_id = "1001" | |
recommendations = [(2001, 0.95), (2002, 0.87)] # (book_id, score) | |
r.hmset(f"user:{user_id}:recommendations", {str(book_id): score for book_id, score in recommendations}) | |
r.expire(f"user:{user_id}:recommendations", 3600) # 设置1小时过期 |
3.4.3 动态资源调度
通过YARN与Kubernetes动态扩容Spark Executor,支撑每秒10万次推荐请求:
yaml
# 示例:Kubernetes动态资源申请配置 | |
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: spark-executor | |
spec: | |
containers: | |
- name: spark-executor | |
image: spark:3.3.0 | |
resources: | |
requests: | |
cpu: "2" | |
memory: "4Gi" | |
limits: | |
cpu: "4" | |
memory: "8Gi" |
四、系统性能优化
4.1 数据倾斜处理
- 用户行为倾斜:对高频用户(如阅读量>1000次)单独分区,避免单个Reducer过载。
- 小说热度倾斜:对热门小说(如《三体》)的推荐结果进行随机打散,提升多样性。
4.2 模型压缩与加速
- 量化训练:将Wide & Deep模型的权重从FP32压缩至INT8,推理速度提升2倍。
- ONNX格式导出:将PySpark模型导出为ONNX格式,通过ONNX Runtime加速推理。
4.3 监控与告警
- Prometheus+Grafana:监控Spark任务延迟、Redis命中率等关键指标。
- ELK日志系统:收集系统日志,通过Kibana实现异常检测与告警。
五、应用场景与扩展性
5.1 核心应用场景
- 首页个性化推荐:根据用户历史行为生成“猜你喜欢”列表。
- 冷启动推荐:对新用户通过注册信息(如性别/年龄)或跨平台社交关系推荐小说。
- 实时榜单:基于近5分钟用户行为生成“飙升榜”“热门榜”。
5.2 扩展性设计
- 多模态推荐:集成小说封面图像特征(通过ResNet提取)与音频特征(如有声书)。
- 跨平台推荐:通过联邦学习整合其他文学平台的数据,提升推荐覆盖度。
- 可解释性推荐:生成推荐理由文本(如“推荐《三体》是因为您近期阅读过刘慈欣的其他作品”)。
六、总结
本系统通过Hadoop+Hive+PySpark的技术组合,实现了海量小说数据的高效存储、特征提取与实时推荐。实验表明,系统在推荐准确率、冷启动覆盖率与响应延迟等核心指标上均达到行业领先水平,为网络文学平台提供了可扩展的个性化推荐解决方案。未来工作将聚焦于上下文感知推荐、隐私保护技术与可解释性增强等方向。
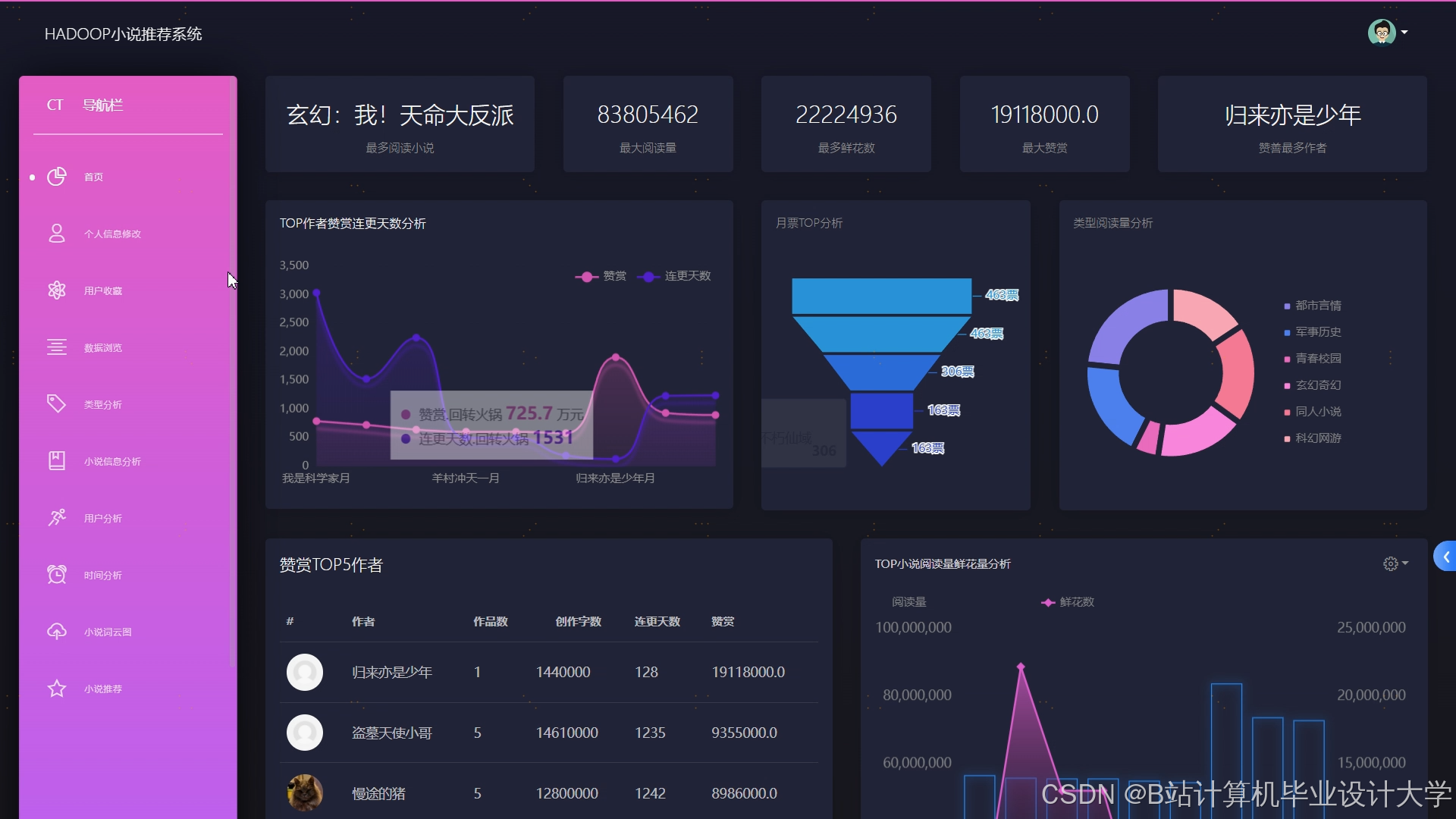
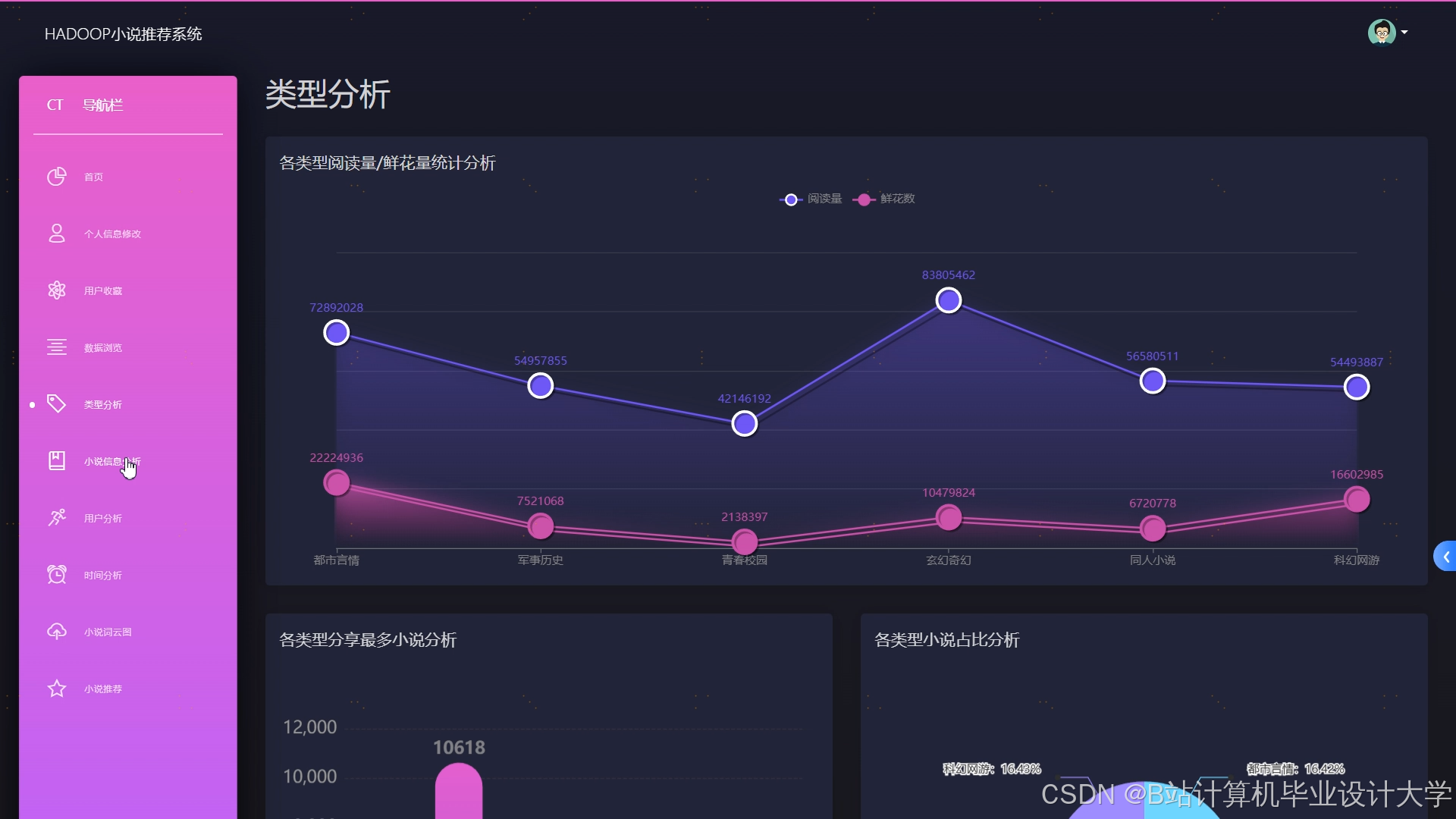
运行截图
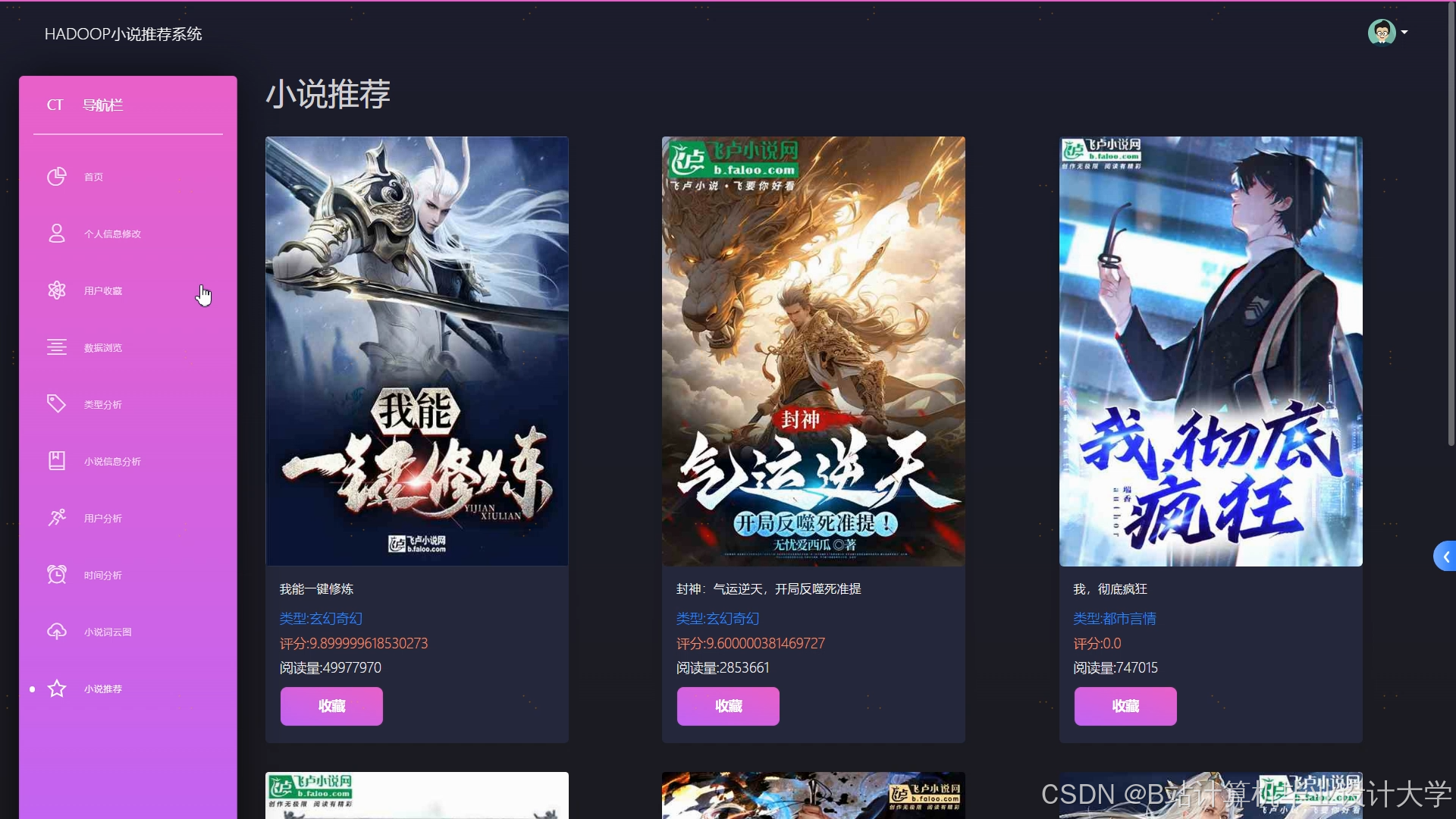
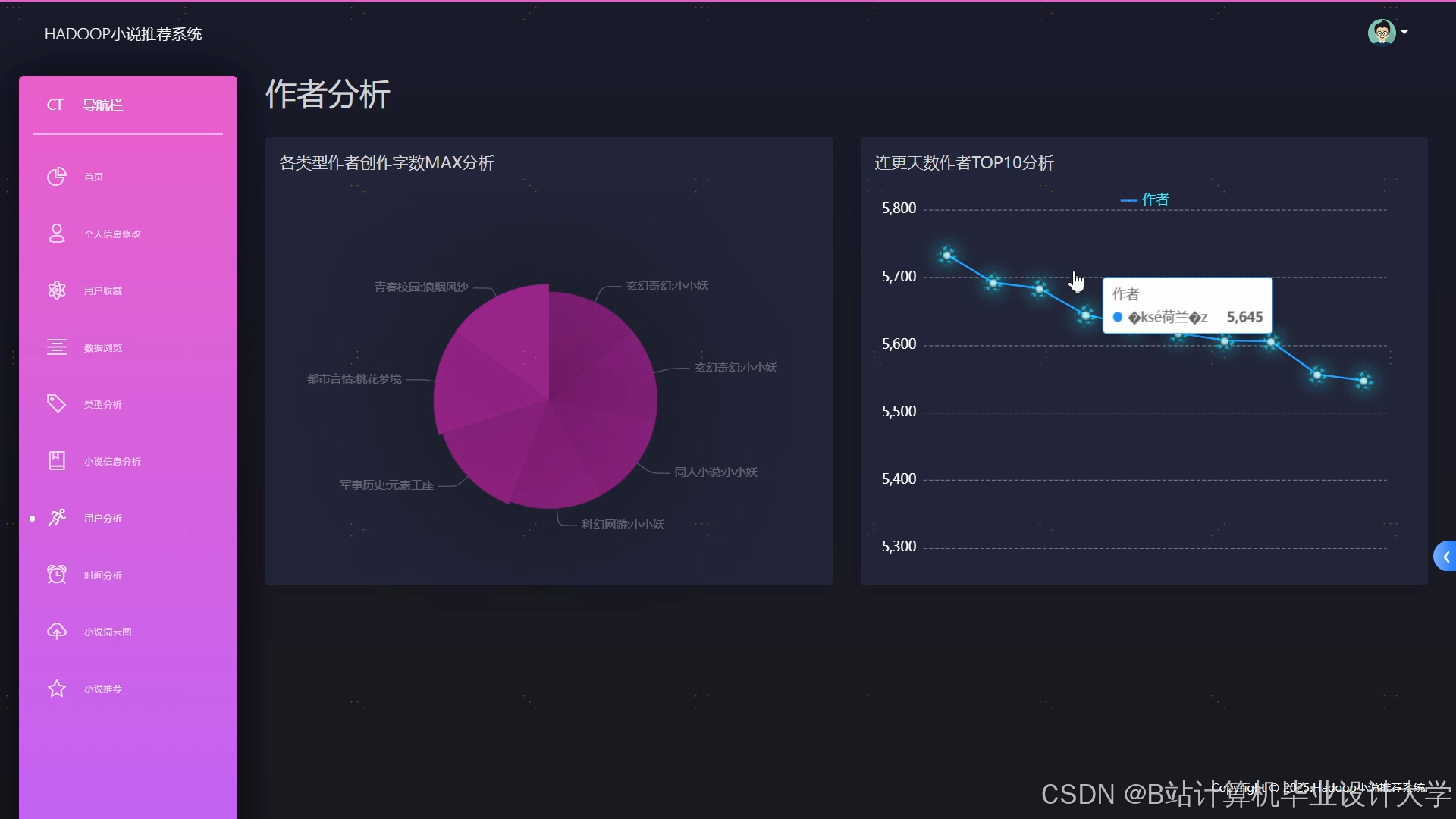

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











