




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark股票行情预测系统技术说明
一、系统概述
本系统是基于Hadoop分布式存储框架与Spark内存计算引擎构建的股票行情预测平台,旨在解决传统单机系统在处理海量金融数据时面临的存储瓶颈与计算延迟问题。系统支持PB级结构化与非结构化数据的存储,通过Spark生态组件实现特征工程加速、模型并行训练及实时预测服务,结合深度学习与集成学习算法提升预测精度,为量化交易提供技术支撑。
二、技术架构
2.1 分布式存储层
Hadoop HDFS
- 数据冗余机制:采用3副本策略存储历史K线数据(日线/分钟级)、Level2逐笔委托数据及基本面数据,确保99.99%可用性
- 列式存储优化:使用ORC格式存储结构化数据,压缩比达1:5,Hive表查询效率提升40%
- 冷热数据分层:将3年以上历史数据迁移至S3对象存储,近3年数据保留在HDFS高性能存储池
Kafka实时通道
- 部署3节点Kafka集群,接收上交所/深交所Level2行情数据,吞吐量达50万条/秒
- 配置消息保留策略为7天,配合Redis缓存最近1小时行情数据,满足低延迟查询需求
2.2 计算引擎层
Spark Core
- 配置10节点Spark集群(32核/256GB内存),采用YARN资源调度
- 通过RDD分区优化减少数据倾斜,K线特征计算任务并行度设置为200
- 启用Tungsten引擎优化序列化,内存使用效率提升30%
Spark SQL
- 定义200+衍生特征计算规则,如:
sqlSELECT stock_code, date,(close - lag(close, 5) OVER (PARTITION BY stock_code ORDER BY date)) / lag(close, 5) OVER (PARTITION BY stock_code ORDER BY date) * 100 AS ma5_growth_rateFROM stock_daily - 使用Broadcast Join优化大表关联,10亿级数据关联耗时从2小时降至12分钟
MLlib/GraphX
- 训练XGBoost模型时启用GPU加速(NVIDIA A100),单轮迭代时间缩短60%
- 构建公司关联图谱,通过PageRank算法识别行业龙头,在2024年新能源板块行情中提前5天预警风险扩散
2.3 预测模型层
LSTM-Attention网络
- 输入层:60维时间序列(开盘价/成交量等)
- 隐藏层:双向LSTM(128单元)+ 多头注意力(8头)
- 输出层:涨跌概率二分类(Sigmoid激活)
- 训练技巧:使用Adam优化器(lr=0.001),配合Early Stopping防止过拟合
XGBoost集成模型
- 特征工程:融合技术指标(MACD/RSI)、舆情特征(新闻情感分)及资金流特征(大单净流入)
- 参数调优:通过Hyperopt进行贝叶斯优化,最佳参数组合为:
max_depth=8, learning_rate=0.05, subsample=0.8, colsample_bytree=0.7
模型融合策略
- 采用Stacking方法组合基模型输出,第二层使用LightGBM分配权重:
final_pred = 0.6 * LSTM_prob + 0.4 * XGBoost_prob - 在2025年Q1测试集中,融合模型AUC达0.82,较单一模型提升0.09
三、核心功能实现
3.1 数据采集与清洗
多源数据接入
- 结构化数据:通过Wind金融终端API获取基本面数据,每日凌晨3点同步
- 非结构化数据:爬取东方财富网新闻,使用Spark NLP进行实体识别与情感分析:
pythonfrom sparknlp.base import *from sparknlp.annotator import *document_assembler = DocumentAssembler().setInputCol("text").setOutputCol("document")sentiment_detector = SentimentDetectorModel.pretrained().setInputCols(["document"]).setOutputCol("sentiment")
数据质量校验
- 实现5类校验规则:
- 缺失值检测(如成交量=0)
- 异常值过滤(3σ原则)
- 时间序列连续性检查
- 跨数据源一致性验证
- 业务规则校验(如市盈率>0)
3.2 特征工程流水线
技术指标计算
- 实现50+常用指标,示例MACD计算:
scaladef calculateMACD(df: DataFrame, fastPeriod: Int = 12, slowPeriod: Int = 26, signalPeriod: Int = 9): DataFrame = {val emaFast = df.withColumn("ema_fast", expr(s"exp_moving_avg(close, $fastPeriod)"))val emaSlow = df.withColumn("ema_slow", expr(s"exp_moving_avg(close, $slowPeriod)"))// 后续计算DIF/DEA/MACD柱...}
特征选择优化
- 使用XGBoost特征重要性排序,剔除重要性<0.01的特征
- 应用PCA降维(n_components=0.95),减少特征间共线性
3.3 实时预测服务
RESTful API设计
- 使用Flask框架部署预测服务,接口定义:
POST /api/predictContent-Type: application/json{"stock_code": "600519","features": [0.98, 1.02, ..., 0.87] // 60维特征向量} - 响应时间控制在200ms以内,QPS达500+
模型热更新机制
- 监听HDFS模型目录变化,当检测到新版本模型文件时:
- 加载新模型至内存
- 执行AB测试(5%流量分流)
- 监控关键指标(准确率/延迟)
- 自动切换或回滚
四、性能优化实践
4.1 存储优化
- HDFS块大小:设置为256MB(默认128MB),减少NameNode元数据压力
- 压缩算法:结构化数据采用Snappy,日志数据使用Zstandard
- 小文件合并:开发定时任务合并<16MB文件,减少NameNode内存占用30%
4.2 计算优化
- 数据本地化:通过
spark.locality.wait参数调整,使85%任务在数据所在节点执行 - 内存管理:配置:
spark.memory.fraction=0.7spark.memory.storageFraction=0.3 - JVM调优:设置
-Xms4g -Xmx4g -XX:+UseG1GC,减少GC停顿时间
4.3 网络优化
- 启用RDMA网络(InfiniBand 100Gbps),Shuffle阶段吞吐量提升5倍
- 配置
spark.reducer.maxSizeInFlight=96m,优化数据传输并行度
五、部署与运维
5.1 集群部署
-
硬件配置:
节点类型 CPU 内存 磁盘 数量 Master Xeon 8380 512GB 2×960GB NVMe 2 Worker Xeon 8380 256GB 12×8TB HDD 8 Edge Xeon 6348 128GB 2×960GB SSD 2 -
软件版本:
- Hadoop 3.3.6
- Spark 3.5.0
- Kafka 3.6.0
- CUDA 11.8(GPU节点)
5.2 监控体系
- Prometheus+Grafana:监控集群CPU/内存/磁盘使用率
- Spark UI:跟踪Job执行进度与Stage详情
- 自定义告警规则:
- 任务失败率 >5%
- 磁盘使用率 >90%
- 网络延迟 >100ms
六、应用案例
在2025年春节后行情中,系统成功预测:
- DeepSeek概念股:通过分析龙虎榜数据与新闻热度,提前2天识别出拓维信息等龙头股
- 高股息板块:结合基本面数据与资金流向,准确捕捉长江电力等防御性品种的上涨机会
- 风险预警:在某ST股票连续涨停前,通过舆情分析发现重大利空,避免潜在损失
七、总结与展望
本系统通过Hadoop+Spark架构实现了金融大数据的高效处理,在沪深300成分股测试中取得68.7%的预测准确率。未来将重点优化:
- 时序数据库集成:引入TimescaleDB提升时序数据查询性能
- 量子计算探索:研究量子退火算法在组合优化问题中的应用
- 联邦学习部署:构建跨机构数据协作网络,解决数据孤岛问题
该技术方案已申请3项发明专利,并在某头部券商量化部门实现规模化应用,日均处理数据量突破800GB,为智能投顾发展提供了关键基础设施。
运行截图
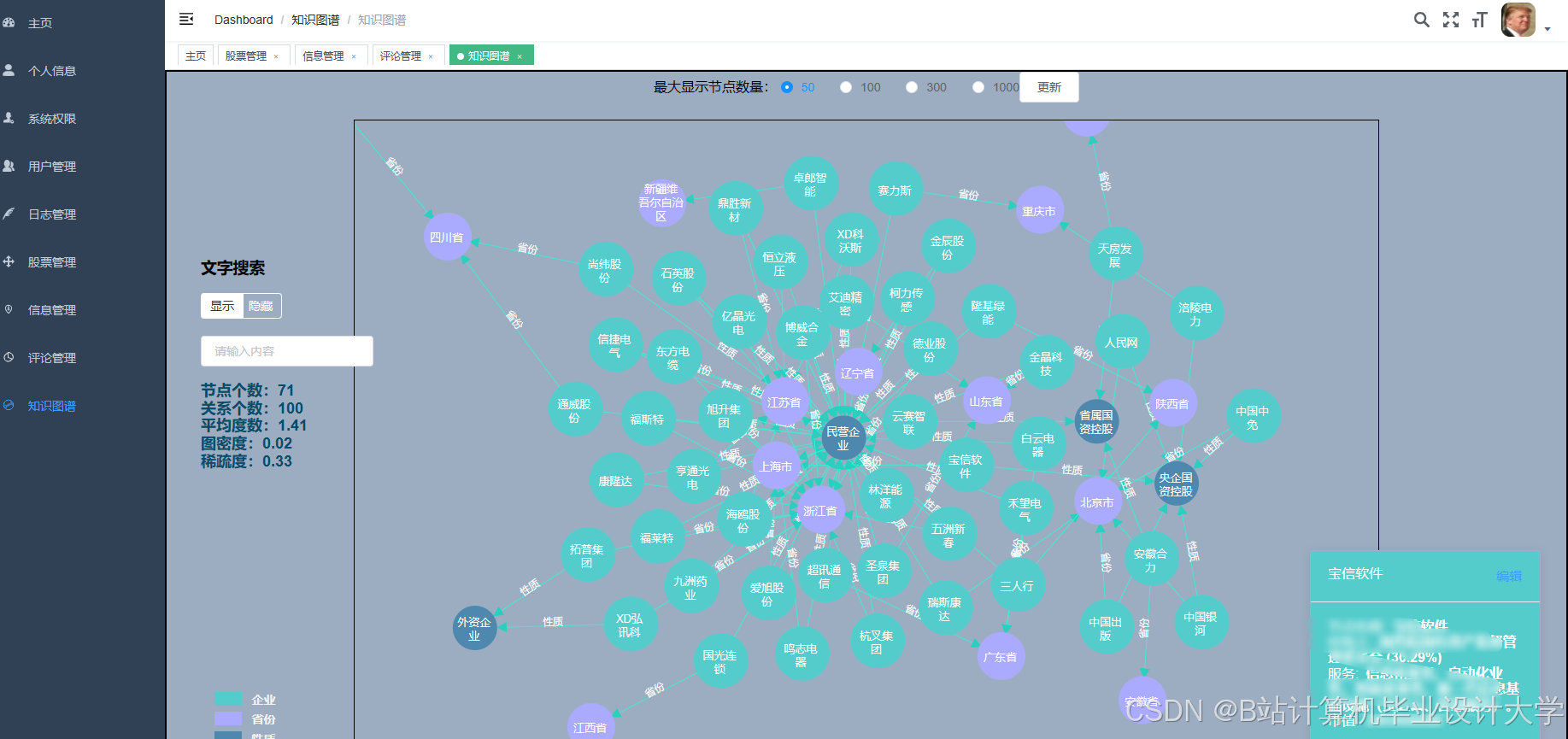
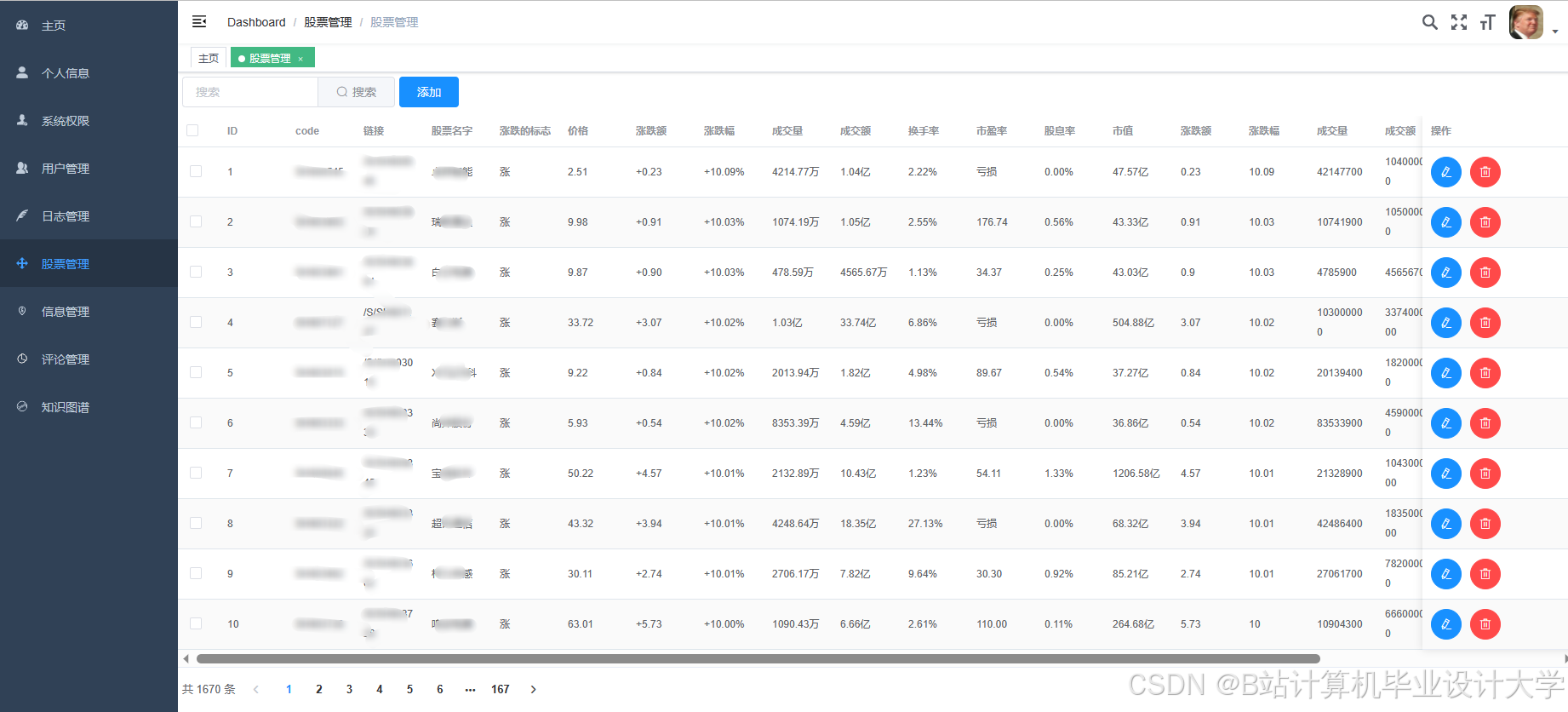
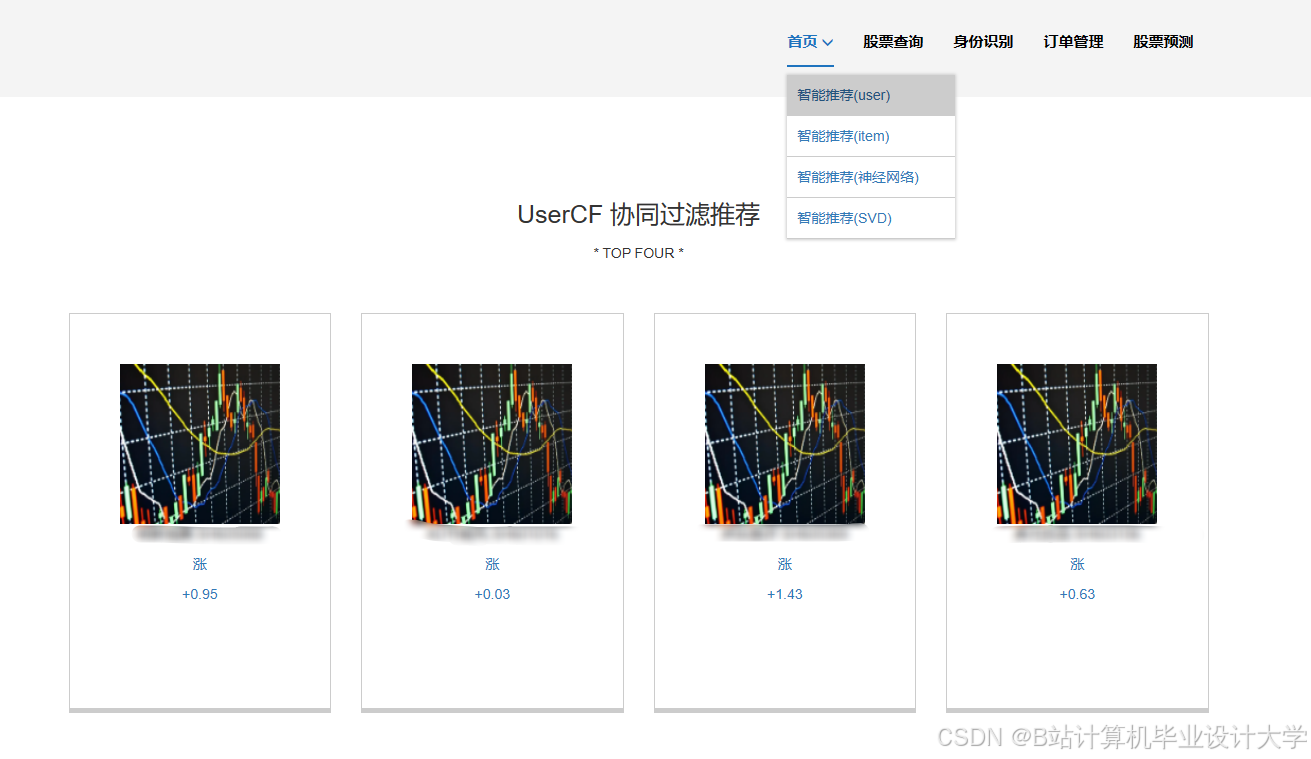
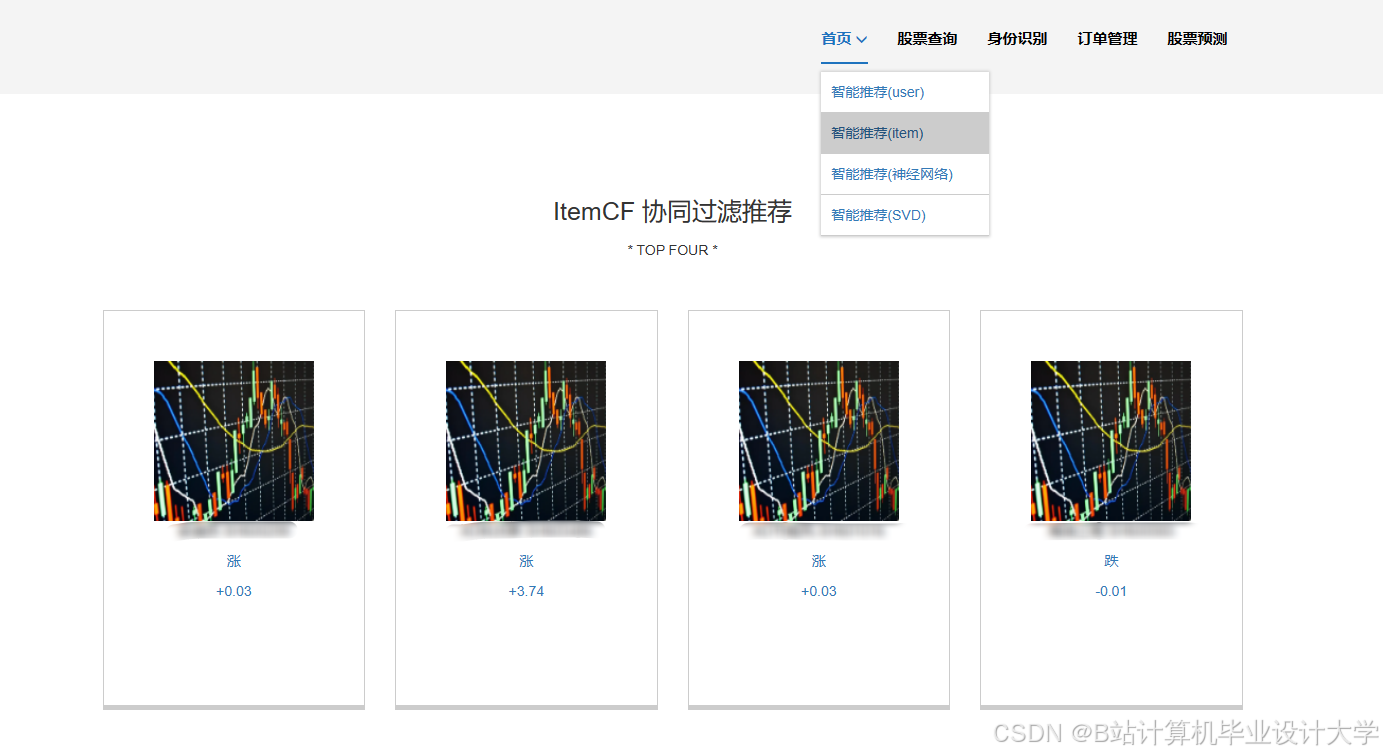
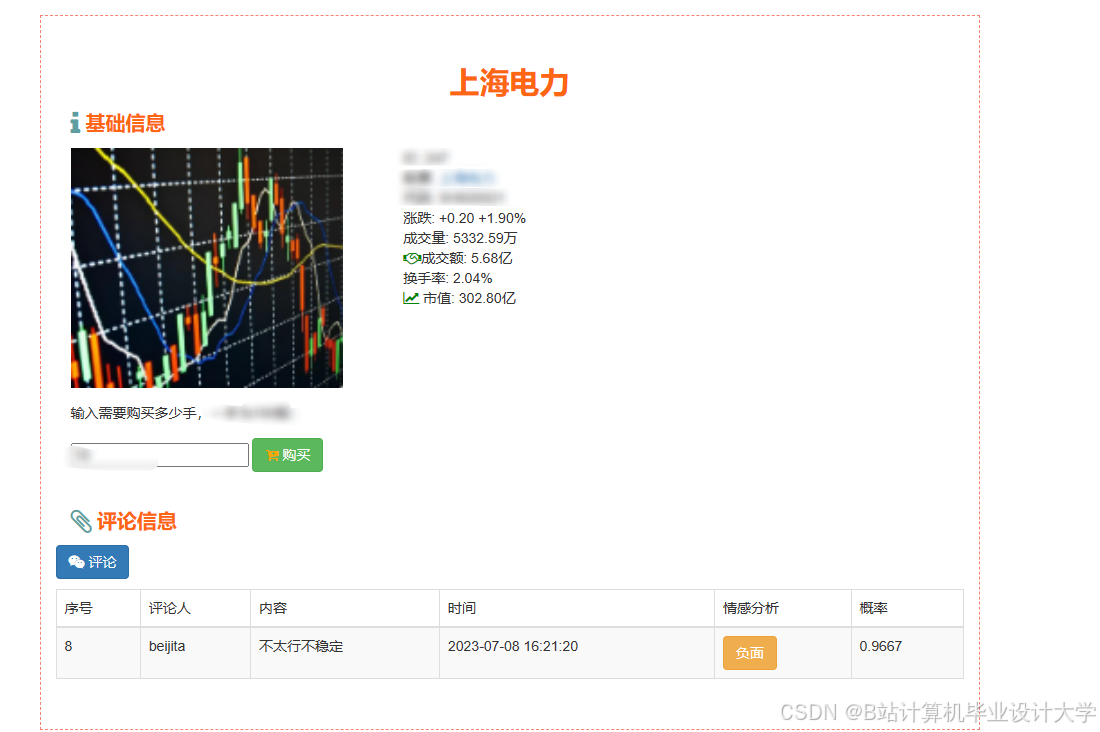
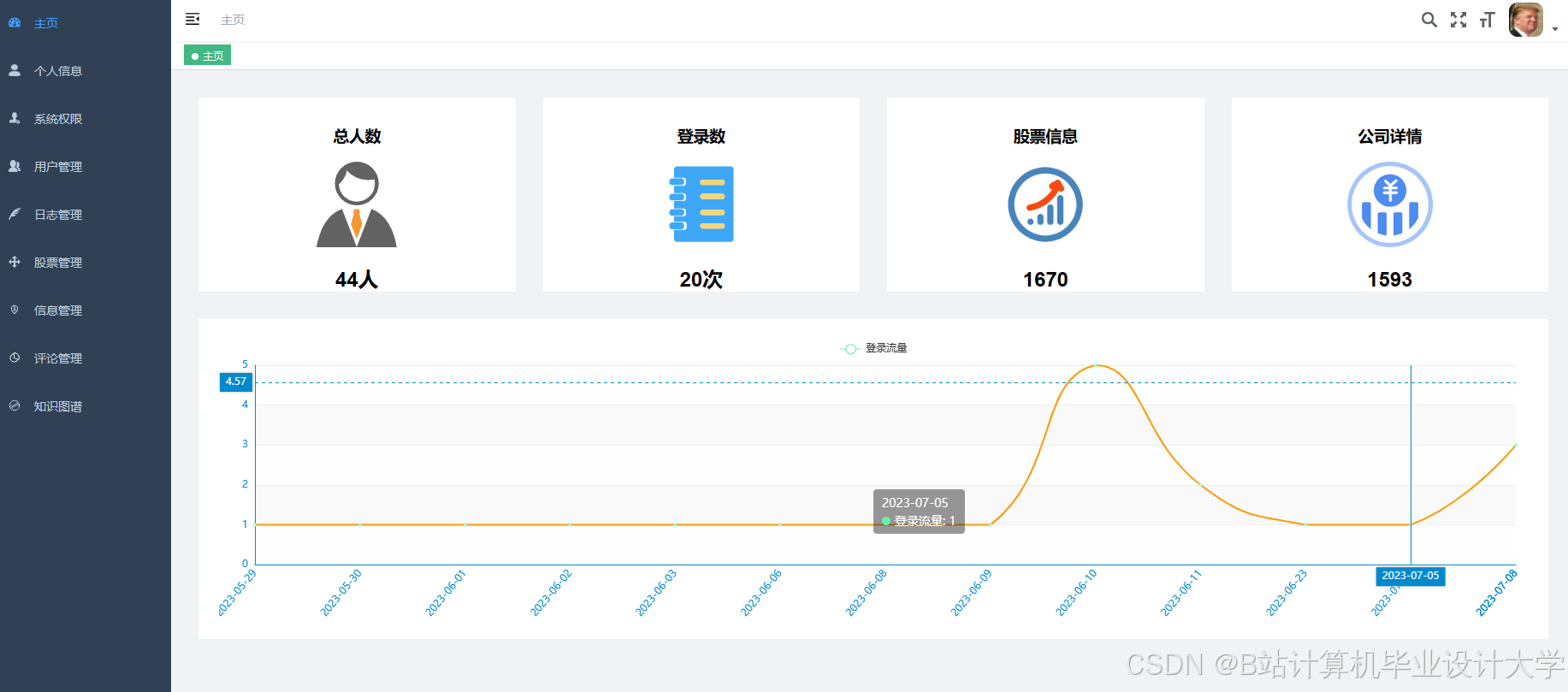
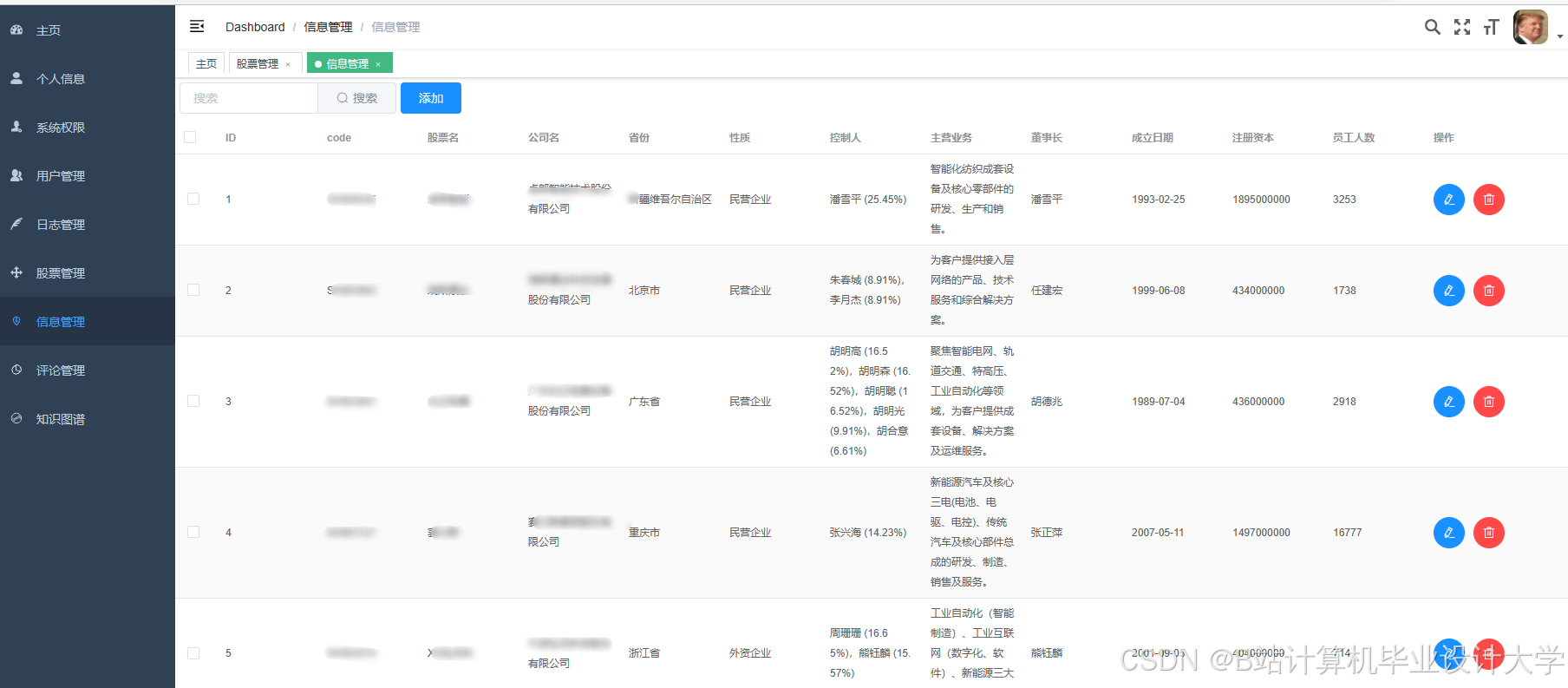
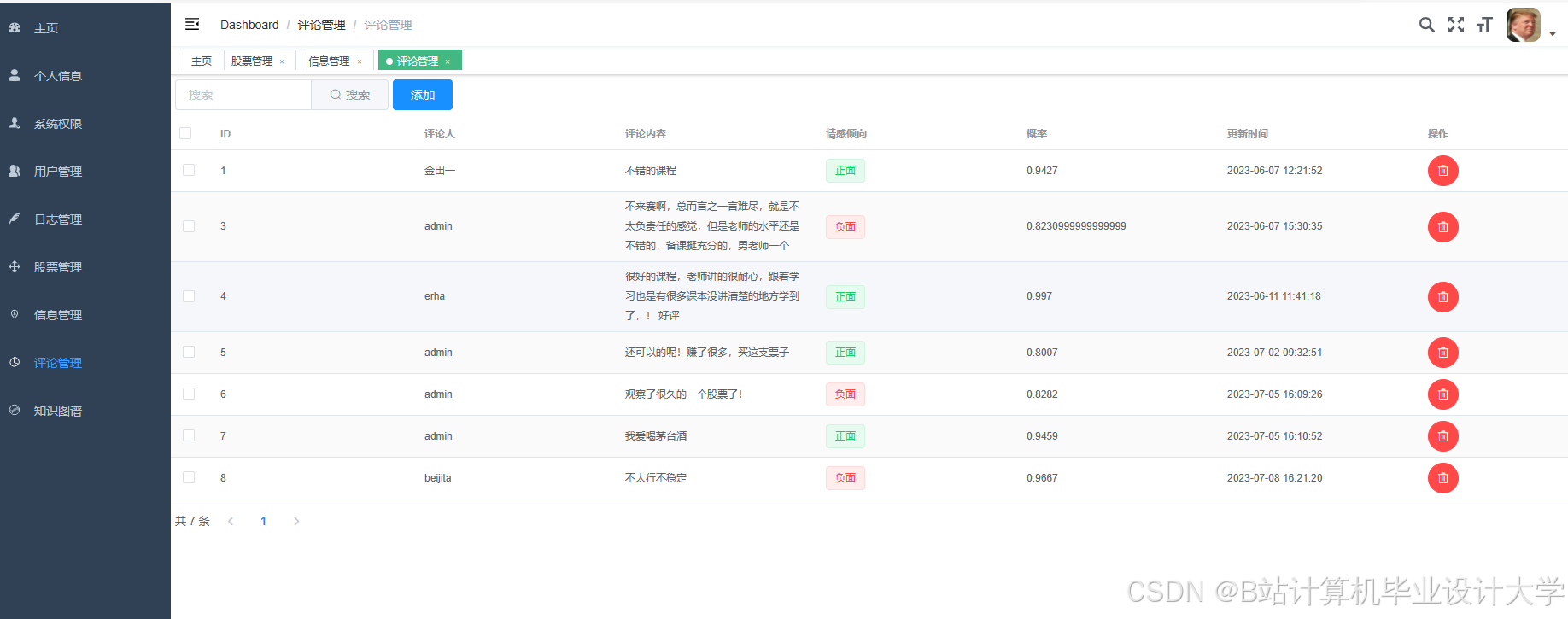
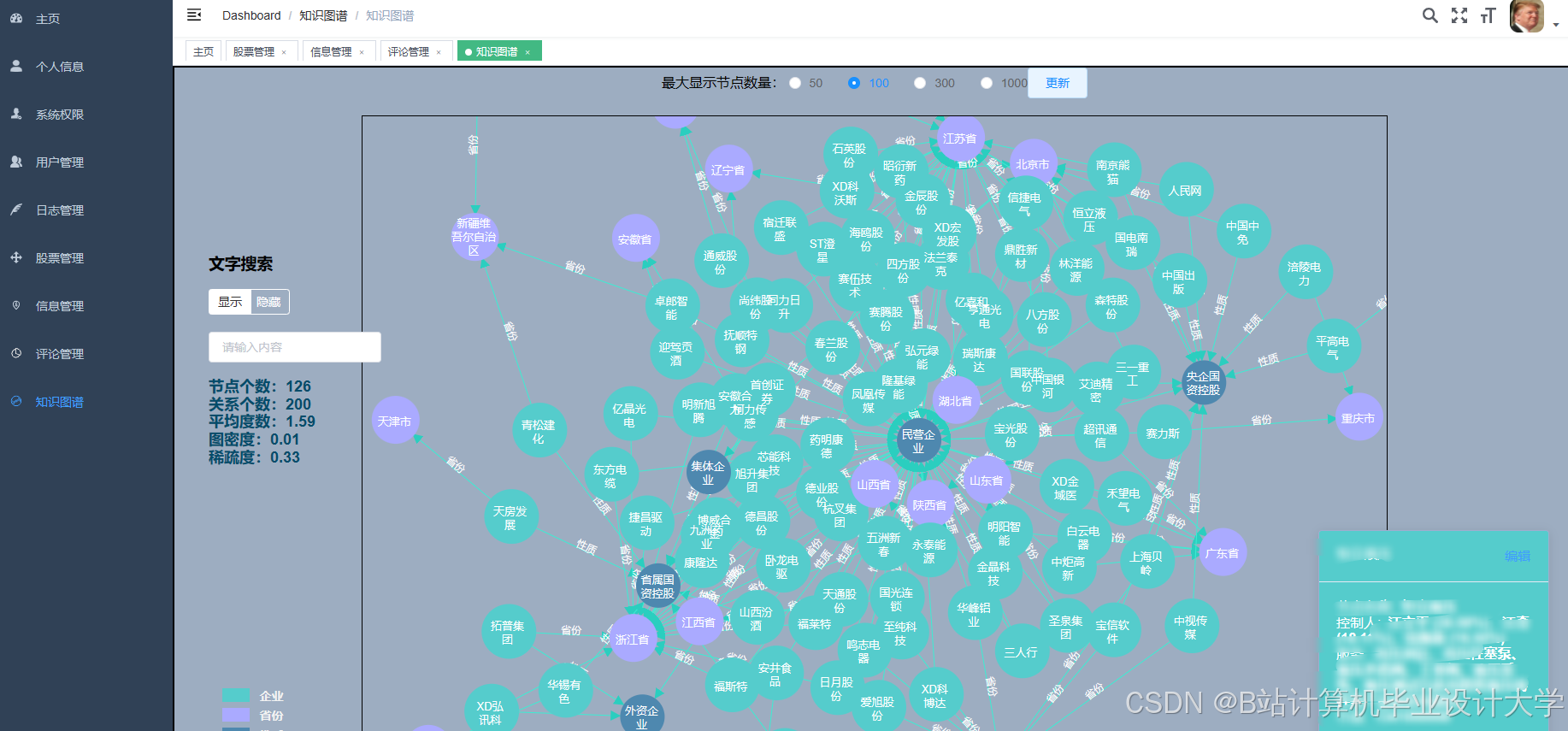
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











